
Всем привет, меня зовут Юрий Буйлов, я руковожу разработкой в CarPrice. Коротко расскажу как и почему мы пришли к микросервисам на PHP и Golang. Что используем, как инструментируем и мониторим наши приложения в production. Далее расскажу о распределенном трейсинге, который обеспечивает нам прозрачность работы сервисов.

В последнее время микросервисы довольно трендовая тема и многие их хотят даже там где это не нужно. Это довольно скользкий путь, ступая на который надо понимать что вас ждёт впереди. Мы же пришли к микросервисам не в угоду трендам, а по необходимости, с осознанием всех сложностей с которыми нам придется столкнуться.
Изначально CarPrice был собран как монолитное приложение на Битриксе с привлечением аутсорс разработчиков и упором на скорость разработки. В определённый период это сыграло одну из важных ролей в успешном выходе проекта на рынок.
Со временем поддерживать стабильную работу монолита стало невозможно — каждый релиз превращался в испытание для тестировщиков, разработчиков и админов. Разные процессы мешали нормальной работе друг друга. К примеру, девочка из документооборота могла запустить генерацию документов на завершенные аукционы и в этот момент дилеры не могли нормально торговаться из-за тормозов на бекенде.
Мы начали меняться. Крупные части бизнес логики выносились в отдельные сервисы: логистика, сервис проверки юридической чистоты автомобиля, сервис обработки изображений, сервис записи дилеров на осмотр и выдачу, биллинг, сервис приема ставок, сервис аутентификации, рекомендательная система, апи для наших мобильных и реакт приложений.
На данный момент мы имеем несколько десятков сервисов на разных технологиях, коммуницирующих по сети.
В основном это небольшие приложения на Laravel (php) решающие определенную бизнес задачу. Такие сервисы предоставляют HTTP API и могут иметь административный Web UI (Vue.js)
Общие компоненты мы стараемся оформлять в библиотеки, которые доставляет composer. Кроме того сервисы наследуют общий php-fpm docker-образ. Это снимает головную боль при обновлении. Например у нас почти везде php7.1.
Критичные по скорости сервисы мы пишем на Golang.
Например, сервис jwt-аутентификации выписывает и проверяет токены, а также умеет разлогинить недобросовестного дилера, которого руководство за грехи отключает от аукционной платформы.
Сервис приёма ставок обрабатывает ставки дилеров, сохраняет их в базу и отложено отправляет события в rabbitmq и сервис RT-нотификаций.
Для сервисов на Golang мы используем go-kit и gin/chi.
go-kit привлек своими абстракциями, возможностью использовать различные транспорты и обертки для метрик, но немного утомляет любовью к функциональщине и многословностью, поэтому его используем в капитальных постройках с богатой бизнес логикой.
На gin и chi удобно собирать простые http-сервисы. Это идеальный вариант быстро и с минимальными усилиями запустить мелкий сервис в production. Если у нас появляются сложные сущности, то мы стараемся перевести сервис на go-kit.
Во времена монолита нам хватало newrelic. Заскочив на ступеньку микросервисов число серверов увеличилось и мы отказались от него по финансовым соображениям и бросились во все тяжкие: Zabbix – для железа, ELK, Grafana и Prometheus – для APM.

Первым делом мы сложили логи nginx со всех сервисов в ELK, построили графики в Grafana, а за запросами, что портили нам 99-й перцентиль ходили в Kibana.
И вот тут начинался квест — понять что происходило с запросом.
В монолитном приложении было все просто — если это php, то раньше был xhprof, вооружившись которым можно было понять что же там происходило. При микросервисах, где запрос проходит через несколько сервисов да ещё и на разных технологиях — такой трюк не пройдет. Где-то сеть, где-то синхронные запросы или протухший кеш.
Допустим, мы нашли медленный запрос нашего API. По коду установили, что запрос обратился к трем сервисам, собрал и вернул результат. Теперь надо по косвенным признакам (timestamp, параметры запроса) найти нижестоящие запросы чтоб понять какой из сервисов был причиной медленного запроса. Даже если мы нашли тот сервис — надо идти в метрики или логи сервиса и искать причину там, а ведь нередко бывает так, что нижние сервисы работают быстро, а результирующий запрос тормозит. Вобщем это так себе удовольствие.
И мы поняли, что пора – нужен распределенный трейсинг.
Мотивация:
Вспомнив про Google’s Dapper мы первым делом пришли к Opentracing – универсальный стандарт для распределенного трейсинга. Его поддерживают несколько трейсеров. Самые известные – это Zipkin (Java) и Appdash (Golang).
Однако недавно среди трейсеров-старожилов, поддерживающих стандарт появился новый и многообещающий Jaeger от Uber Technologies. О нем мы и поговорим.
Бекенд – Go
UI – React
Storage – Cassandra/Elasticsearch
Изначально разрабатывался под стандарт OpenTracing.
В отличие от того же Zipkin, модель Jaeger нативно поддерживает key-value logging и трейсы представлены как направленный ациклический граф (DAG) а не просто дерево спанов.
Кроме того совсем недавно на Open Source саммите в LA Jaeger был поставлен на одну полку с такими почетными проектами как Kubernetes и Prometheus.

Каждый сервис собирает тайминги и доп.инфу в спаны и скидывает их в рядом стоящий jaeger-agent по udp. Тот, в свою очередь, отправляет их в jaeger-collector. После этого трейсы доступны в jaeger-ui. На оф.сайте архитектура изображена так:
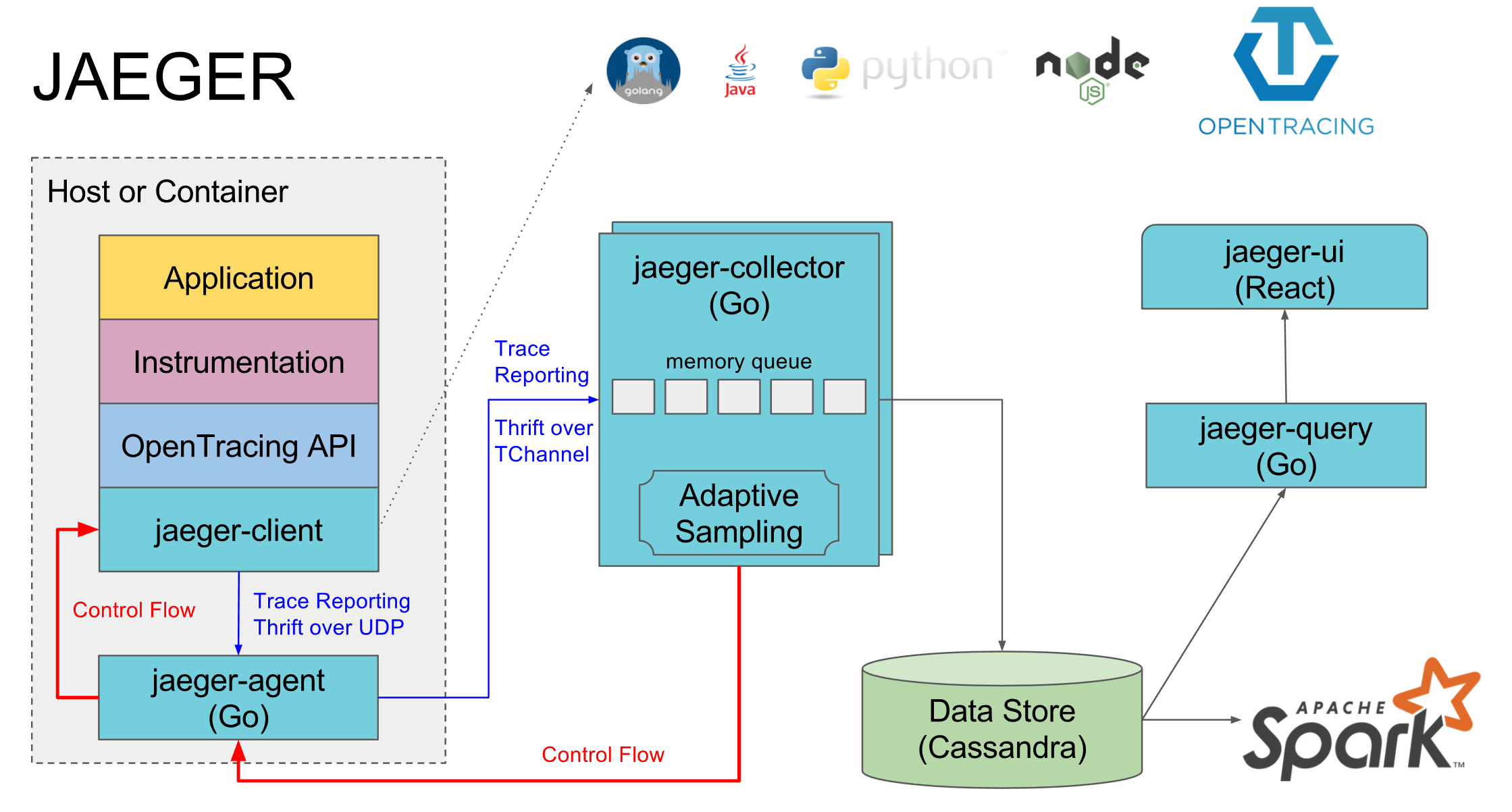
Большинство наших сервисов развернуты в Docker-контейнерах. Собирает их Drone, а деплоит Ansible. К сожалению (нет), мы еще не перешли на системы оркестрации типа k8s, nomad или openshift и контейнеры работают под управлением Docker Compose.
Типичные наши сервисы в связке с jaeger выглядит так:
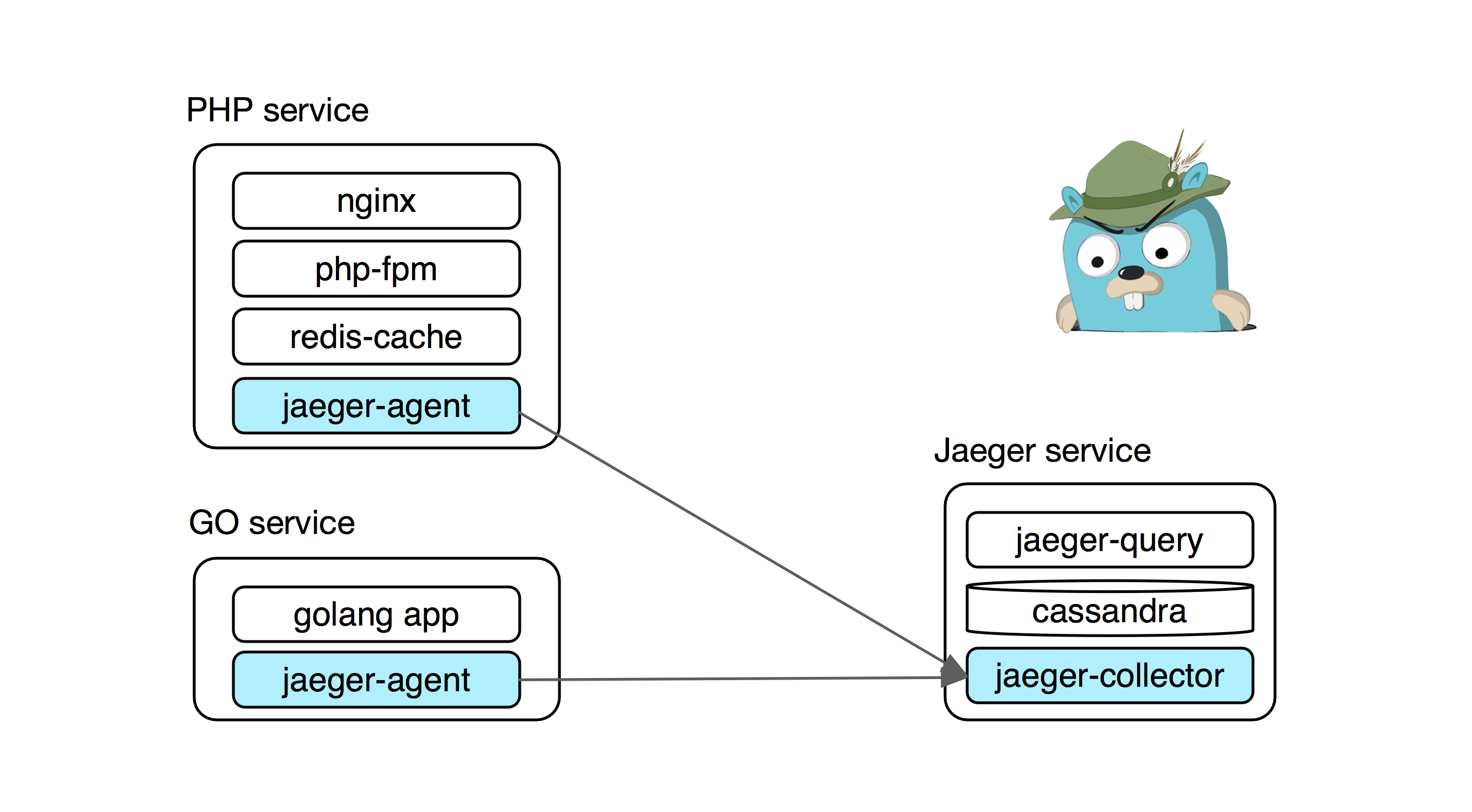
Инсталляция Jaeger в production представляет собой набор нескольких сервисов и storage.
> collector – принимает спаны от сервисов и записывает их в storage
> query – Web UI и API для чтения спанов из storage
> storage – хранит все спаны. Можно использовать либо cassandra либо elasticsearch
Для девов и локальной разработки удобно использовать билд Jaeger “все в одном” с in-memory storage под трейсы
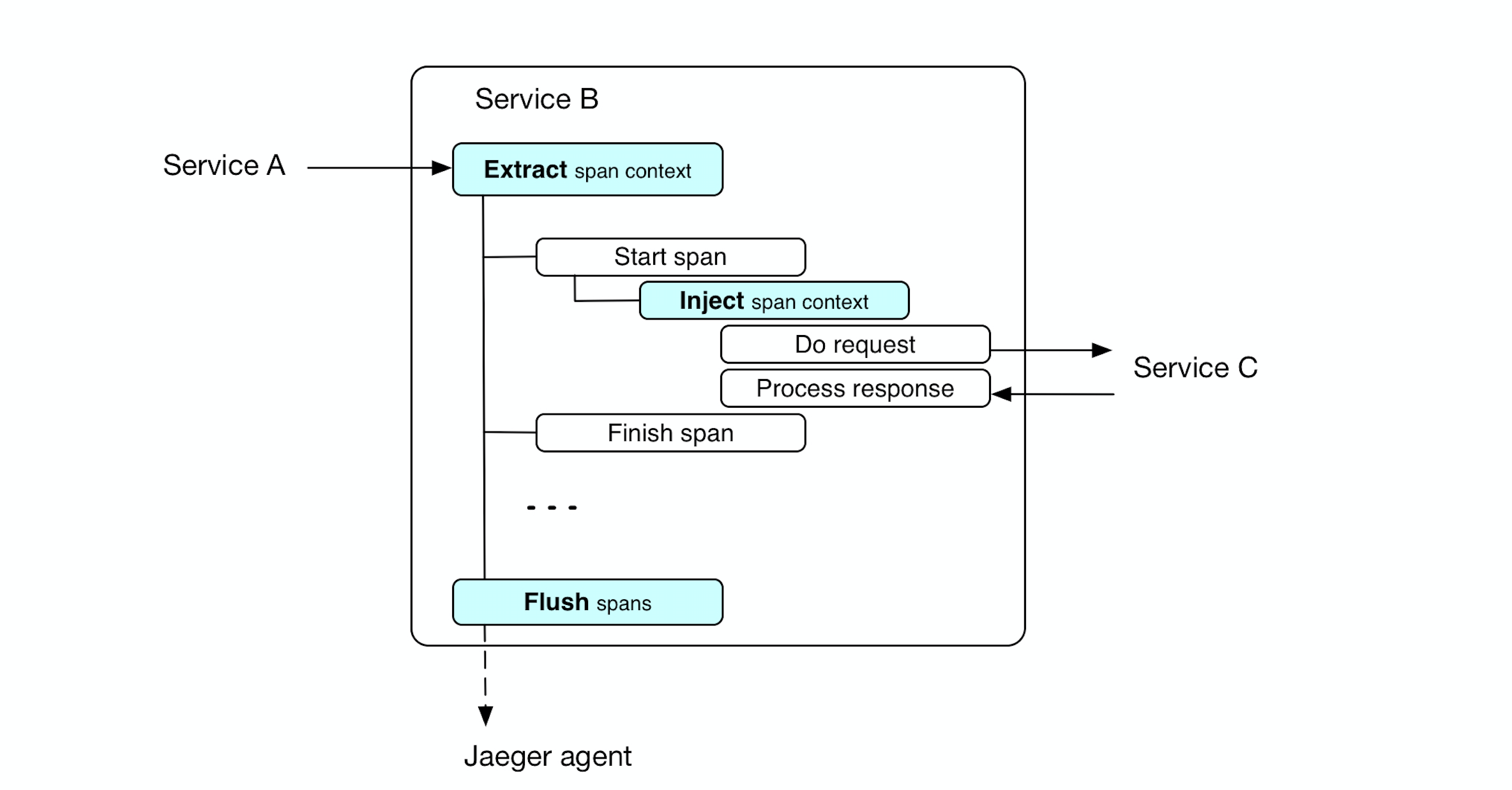
Сервис собирает информацию по таймингам и мета информацию запроса в спаны. Спан передается между методами через контекст, а нижестоящим сервисам через инъекцию контекста в хедер.
Для демонстрации команда uber подготовила хороший пример, иллюстрирующий трейсинг в сервисе поиска водителя: Hotrod
Для начала нам нужно создать сам трейсер
Добавляем middleware (opentracing.TraceServer) – создает корневой спан для метода api. Все вложенные спаны будут привязаны к нему.
Кроме того мы извлекаем (Extract) контекст трейса из заголовка входящего запроса (opentracing.FromHTTPRequest). Таким образом наш сервис будет связан с вышестоящим сервисом при условии, что тот передал контекст трейса в запросе (Inject).
Далее мы инструментируем наши методы:
Ну и сам старт спана выглядит так
Это все. Теперь мы можем в реальном времени наблюдать за работой нашего сервиса.
(Большая картинка)

Например, на картинке выше мы нашли тормозящий запрос и увидели, что половину времени отъела сеть между сервисами, а вторую половину – update в базу. С этим уже можно работать.
Спасибо за внимание. Надеюсь, данная заметка будет полезна, а Jaeger кому-то поможет привнести прозрачность в работу сервисов.
> Оф сайт проекта
> Репозиторий
> Сайт Opentracing
> Пример
Почему микросервисы
В последнее время микросервисы довольно трендовая тема и многие их хотят даже там где это не нужно. Это довольно скользкий путь, ступая на который надо понимать что вас ждёт впереди. Мы же пришли к микросервисам не в угоду трендам, а по необходимости, с осознанием всех сложностей с которыми нам придется столкнуться.
Изначально CarPrice был собран как монолитное приложение на Битриксе с привлечением аутсорс разработчиков и упором на скорость разработки. В определённый период это сыграло одну из важных ролей в успешном выходе проекта на рынок.
Со временем поддерживать стабильную работу монолита стало невозможно — каждый релиз превращался в испытание для тестировщиков, разработчиков и админов. Разные процессы мешали нормальной работе друг друга. К примеру, девочка из документооборота могла запустить генерацию документов на завершенные аукционы и в этот момент дилеры не могли нормально торговаться из-за тормозов на бекенде.
Мы начали меняться. Крупные части бизнес логики выносились в отдельные сервисы: логистика, сервис проверки юридической чистоты автомобиля, сервис обработки изображений, сервис записи дилеров на осмотр и выдачу, биллинг, сервис приема ставок, сервис аутентификации, рекомендательная система, апи для наших мобильных и реакт приложений.
На чем пишем
На данный момент мы имеем несколько десятков сервисов на разных технологиях, коммуницирующих по сети.
В основном это небольшие приложения на Laravel (php) решающие определенную бизнес задачу. Такие сервисы предоставляют HTTP API и могут иметь административный Web UI (Vue.js)
Общие компоненты мы стараемся оформлять в библиотеки, которые доставляет composer. Кроме того сервисы наследуют общий php-fpm docker-образ. Это снимает головную боль при обновлении. Например у нас почти везде php7.1.
Критичные по скорости сервисы мы пишем на Golang.
Например, сервис jwt-аутентификации выписывает и проверяет токены, а также умеет разлогинить недобросовестного дилера, которого руководство за грехи отключает от аукционной платформы.
Сервис приёма ставок обрабатывает ставки дилеров, сохраняет их в базу и отложено отправляет события в rabbitmq и сервис RT-нотификаций.
Для сервисов на Golang мы используем go-kit и gin/chi.
go-kit привлек своими абстракциями, возможностью использовать различные транспорты и обертки для метрик, но немного утомляет любовью к функциональщине и многословностью, поэтому его используем в капитальных постройках с богатой бизнес логикой.
На gin и chi удобно собирать простые http-сервисы. Это идеальный вариант быстро и с минимальными усилиями запустить мелкий сервис в production. Если у нас появляются сложные сущности, то мы стараемся перевести сервис на go-kit.
Эволюция мониторинга
Во времена монолита нам хватало newrelic. Заскочив на ступеньку микросервисов число серверов увеличилось и мы отказались от него по финансовым соображениям и бросились во все тяжкие: Zabbix – для железа, ELK, Grafana и Prometheus – для APM.
Первым делом мы сложили логи nginx со всех сервисов в ELK, построили графики в Grafana, а за запросами, что портили нам 99-й перцентиль ходили в Kibana.
И вот тут начинался квест — понять что происходило с запросом.
В монолитном приложении было все просто — если это php, то раньше был xhprof, вооружившись которым можно было понять что же там происходило. При микросервисах, где запрос проходит через несколько сервисов да ещё и на разных технологиях — такой трюк не пройдет. Где-то сеть, где-то синхронные запросы или протухший кеш.
Допустим, мы нашли медленный запрос нашего API. По коду установили, что запрос обратился к трем сервисам, собрал и вернул результат. Теперь надо по косвенным признакам (timestamp, параметры запроса) найти нижестоящие запросы чтоб понять какой из сервисов был причиной медленного запроса. Даже если мы нашли тот сервис — надо идти в метрики или логи сервиса и искать причину там, а ведь нередко бывает так, что нижние сервисы работают быстро, а результирующий запрос тормозит. Вобщем это так себе удовольствие.
И мы поняли, что пора – нужен распределенный трейсинг.
Jaeger, добро пожаловать!
Мотивация:
- Поиск аномалий – почему зафейлен 99-й перцентиль, например таймауты сети, падения сервисов или блокировки в базе.
- Диагностика массовых проблем (50 или 75-й перцентиль) после деплоя, изменения конфигурации сервиса или количества инстансов
- Распределенный профайлинг – найти медленные сервисы, компоненты или функции.
Визуализация (Gantt) этапов запроса – можно понять что происходит внутри
Вспомнив про Google’s Dapper мы первым делом пришли к Opentracing – универсальный стандарт для распределенного трейсинга. Его поддерживают несколько трейсеров. Самые известные – это Zipkin (Java) и Appdash (Golang).
Однако недавно среди трейсеров-старожилов, поддерживающих стандарт появился новый и многообещающий Jaeger от Uber Technologies. О нем мы и поговорим.
Бекенд – Go
UI – React
Storage – Cassandra/Elasticsearch
Изначально разрабатывался под стандарт OpenTracing.
В отличие от того же Zipkin, модель Jaeger нативно поддерживает key-value logging и трейсы представлены как направленный ациклический граф (DAG) а не просто дерево спанов.
Кроме того совсем недавно на Open Source саммите в LA Jaeger был поставлен на одну полку с такими почетными проектами как Kubernetes и Prometheus.
Архитектура
Каждый сервис собирает тайминги и доп.инфу в спаны и скидывает их в рядом стоящий jaeger-agent по udp. Тот, в свою очередь, отправляет их в jaeger-collector. После этого трейсы доступны в jaeger-ui. На оф.сайте архитектура изображена так:
Jaeger в production
Большинство наших сервисов развернуты в Docker-контейнерах. Собирает их Drone, а деплоит Ansible. К сожалению (нет), мы еще не перешли на системы оркестрации типа k8s, nomad или openshift и контейнеры работают под управлением Docker Compose.
Типичные наши сервисы в связке с jaeger выглядит так:
Инсталляция Jaeger в production представляет собой набор нескольких сервисов и storage.
> collector – принимает спаны от сервисов и записывает их в storage
> query – Web UI и API для чтения спанов из storage
> storage – хранит все спаны. Можно использовать либо cassandra либо elasticsearch
Для девов и локальной разработки удобно использовать билд Jaeger “все в одном” с in-memory storage под трейсы
jaegertracing/all-in-one:latestКак это работает
Сервис собирает информацию по таймингам и мета информацию запроса в спаны. Спан передается между методами через контекст, а нижестоящим сервисам через инъекцию контекста в хедер.
Для демонстрации команда uber подготовила хороший пример, иллюстрирующий трейсинг в сервисе поиска водителя: Hotrod
Как в коде
Для начала нам нужно создать сам трейсер
import (
"github.com/uber/jaeger-client-go"
"github.com/uber/jaeger-client-go/config"
...
)
jcfg := config.Configuration{
Disabled: false, // Nop tracer if True
Sampler: &config.SamplerConfig{
Type: "const",
Param: 1,
},
Reporter: &config.ReporterConfig{
LogSpans: true,
BufferFlushInterval: 1 * time.Second,
// Адрес рядом стоящего jaeger-agent, который будет репортить спаны
LocalAgentHostPort: cfg.Jaeger.ReporterHostPort,
},
}
tracer, closer, err := jcfg.New(
cfg.Jaeger.ServiceName,
config.Logger(jaeger.StdLogger),
)
Добавляем middleware (opentracing.TraceServer) – создает корневой спан для метода api. Все вложенные спаны будут привязаны к нему.
endpoint := CreateEndpoint(svc)
// Middleware создает корневой спан для метода api
endpoint = opentracing.TraceServer(tracer, opName)(endpoint)
Кроме того мы извлекаем (Extract) контекст трейса из заголовка входящего запроса (opentracing.FromHTTPRequest). Таким образом наш сервис будет связан с вышестоящим сервисом при условии, что тот передал контекст трейса в запросе (Inject).
r.Handle(path, kithttp.NewServer(
endpoint,
decodeRequestFn,
encodeResponseFn,
// Извлекает контекст трейса из хедера и помещает в context.Context
append(opts, kithttp.ServerBefore(opentracing.FromHTTPRequest(tracer, opName, logger)))...,
)).Methods("POST")
Далее мы инструментируем наши методы:
func (s Service) DoSmth() error {
span := s.Tracing.StartSpan("DoSmth", ctx)
defer span.Finish()
// do smth
return nil
}
Ну и сам старт спана выглядит так
func (t AppTracing) StartSpan(name string, ctx context.Context) opentracing.Span {
span := opentracing.SpanFromContext(ctx);
if span != nil {
span = t.Tracer.StartSpan(name, opentracing.ChildOf(span.Context()))
} else {
span = t.Tracer.StartSpan(name)
}
return span
}
Это все. Теперь мы можем в реальном времени наблюдать за работой нашего сервиса.
(Большая картинка)
Например, на картинке выше мы нашли тормозящий запрос и увидели, что половину времени отъела сеть между сервисами, а вторую половину – update в базу. С этим уже можно работать.
Спасибо за внимание. Надеюсь, данная заметка будет полезна, а Jaeger кому-то поможет привнести прозрачность в работу сервисов.
Полезные ссылки
> Оф сайт проекта
> Репозиторий
> Сайт Opentracing
> Пример
Комментарии (6)

koluchiy01
26.10.2017 14:17Промежуточным решением для связывания логов разных сервисов может быть пробрасывание в запросах некоторого идентификатора и добавление его во все логи, но все равно кибана не позволяет красиво и быстро понять кто кого куда и почему так долго.
koluchiy01
26.10.2017 14:18А вообще идеология спанов может быть использована в простом логировании, но мы пока не придумали как это красиво сделать (



nsokil
Есть ли возможность настроить нотификации в случае низких показателей (лейтенси, например) и анализа исторических данных? Например, Jaeger отправляет письмо с примерным содержанием «сервис /example стал работать на 30% медленнее по сравнению с прошлой неделей/билдом, вот метрики...»
yubuylov Автор
Нотификаций и алертов в Jaeger нет. Для этих целей можно использовать Grafana или Zabbix. Например, пришел алерт из Grafana о том, что 99-й перцентиль времени ответа сервиса увеличился. Мы идем в Jaeger, ищем там запросы больше, скажем 1s, и видим что же реально там происходило.