
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
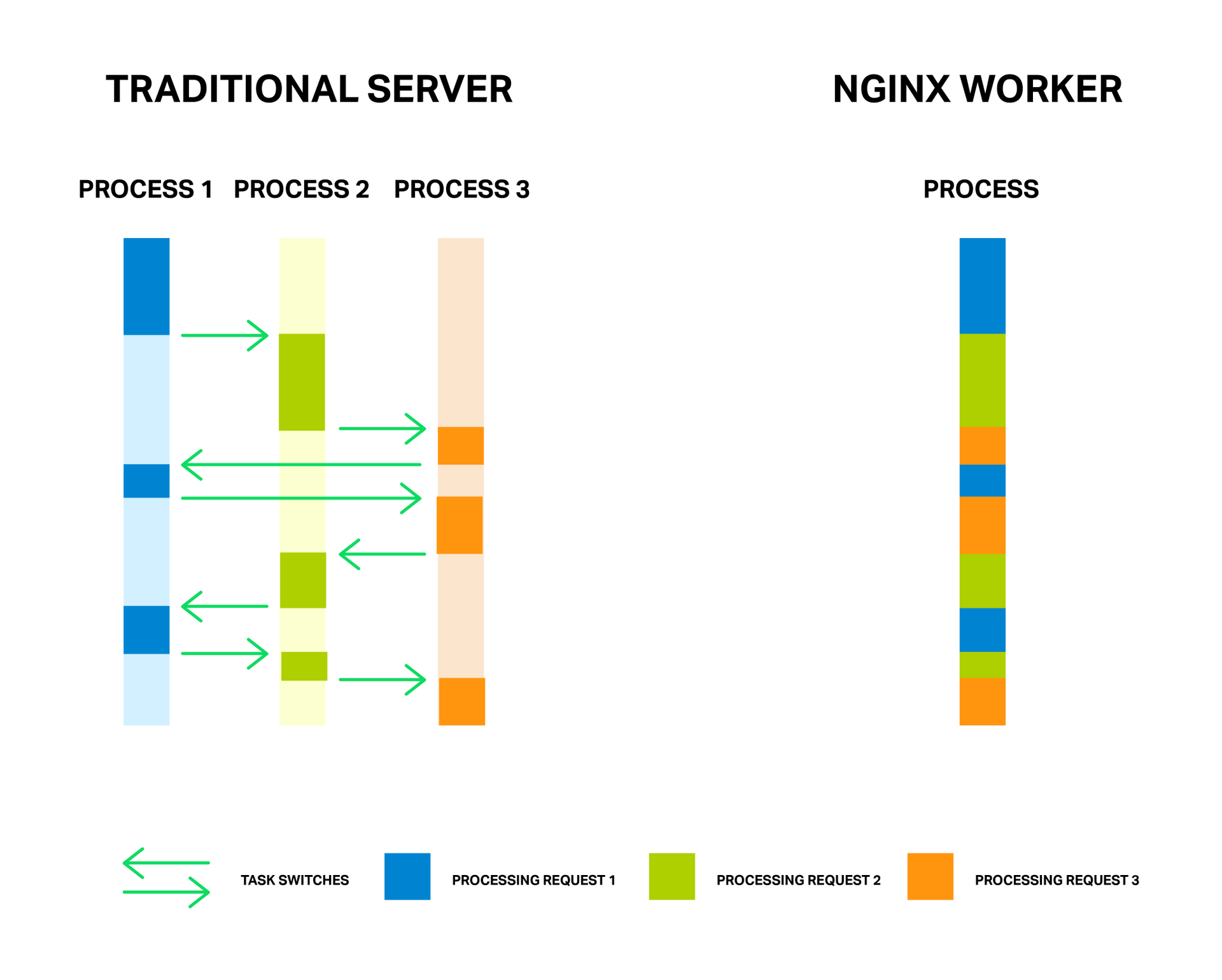
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
Проблема
Для лучшего понимания проблемы сперва разберемся подробнее в основных моментах относительно того, как работает NGINX.
По принципу работы NGINX из себя представляет такой обработчик событий, контроллер, который получает из ядра информацию обо всех событиях, произошедших в соединениях, а затем отдает команды операционной системе, что же ей делать. Фактически NGINX решает самую сложную задачу по манипулированию ресурсами системы, а операционная система занимается всей рутиной, чтением и отправкой байт информации. Так очень большое значение имеет то, насколько быстро и своевременно рабочий процесс NGINX будет реагировать на события.
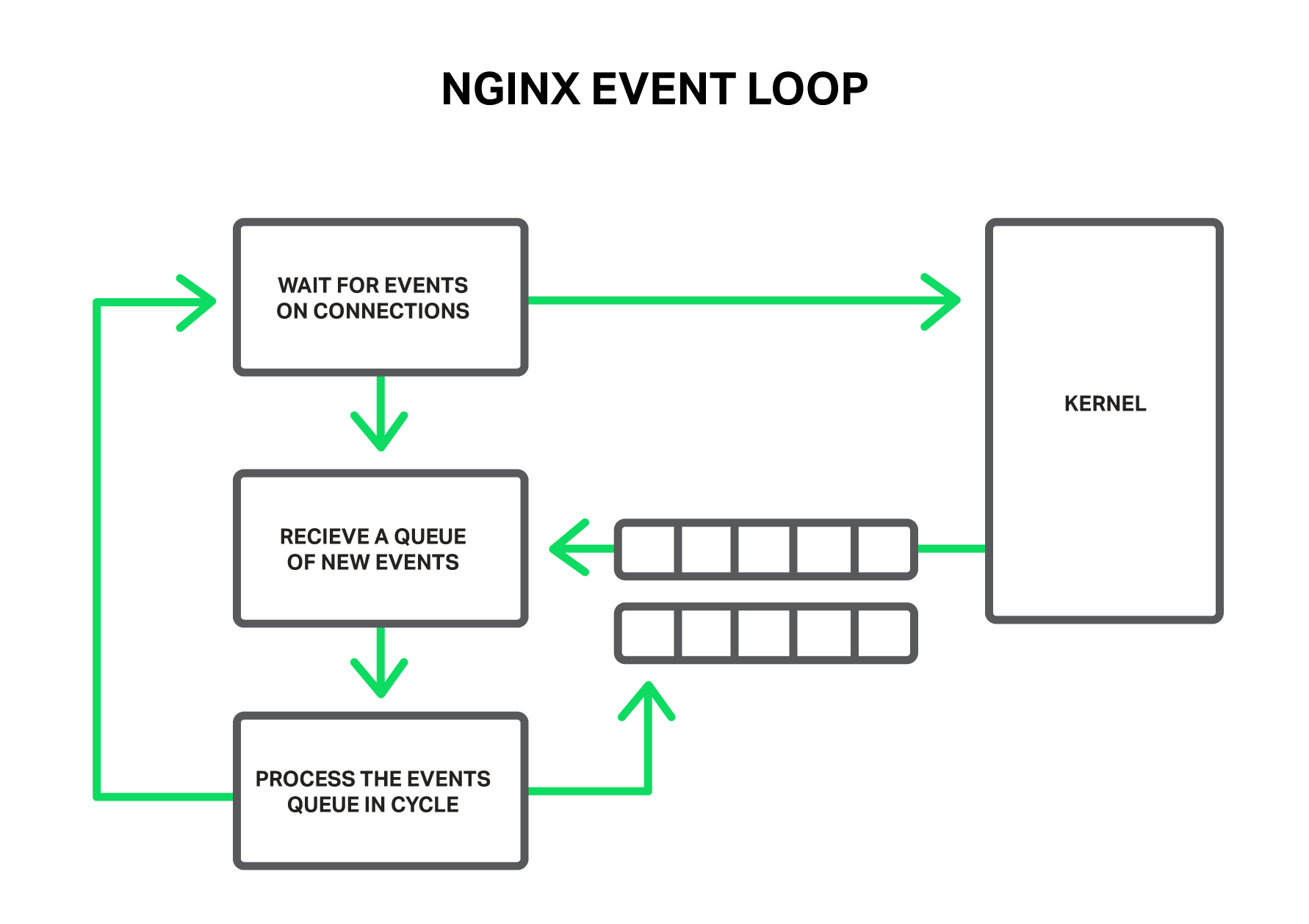
Такими событиями могут быть: события таймера, поступление новых данных или отправка ответа и освобождение места в буфере, уведомления об ошибках в соединении или его закрытие. NGINX получает пачку таких событий и начинает их по очереди обрабатывать, выполняя необходимые действия. Так вся обработка очереди событий происходит в простом цикле в одном потоке. NGINX извлекает из очереди события одно за другим и производит какие-то действия, например, пишет в сокет данные или читает. В большинстве случаев это происходит настолько быстро (чаще всего это просто копирования небольших объемов данных в памяти), что можно считать обработку всех событий мгновенной.
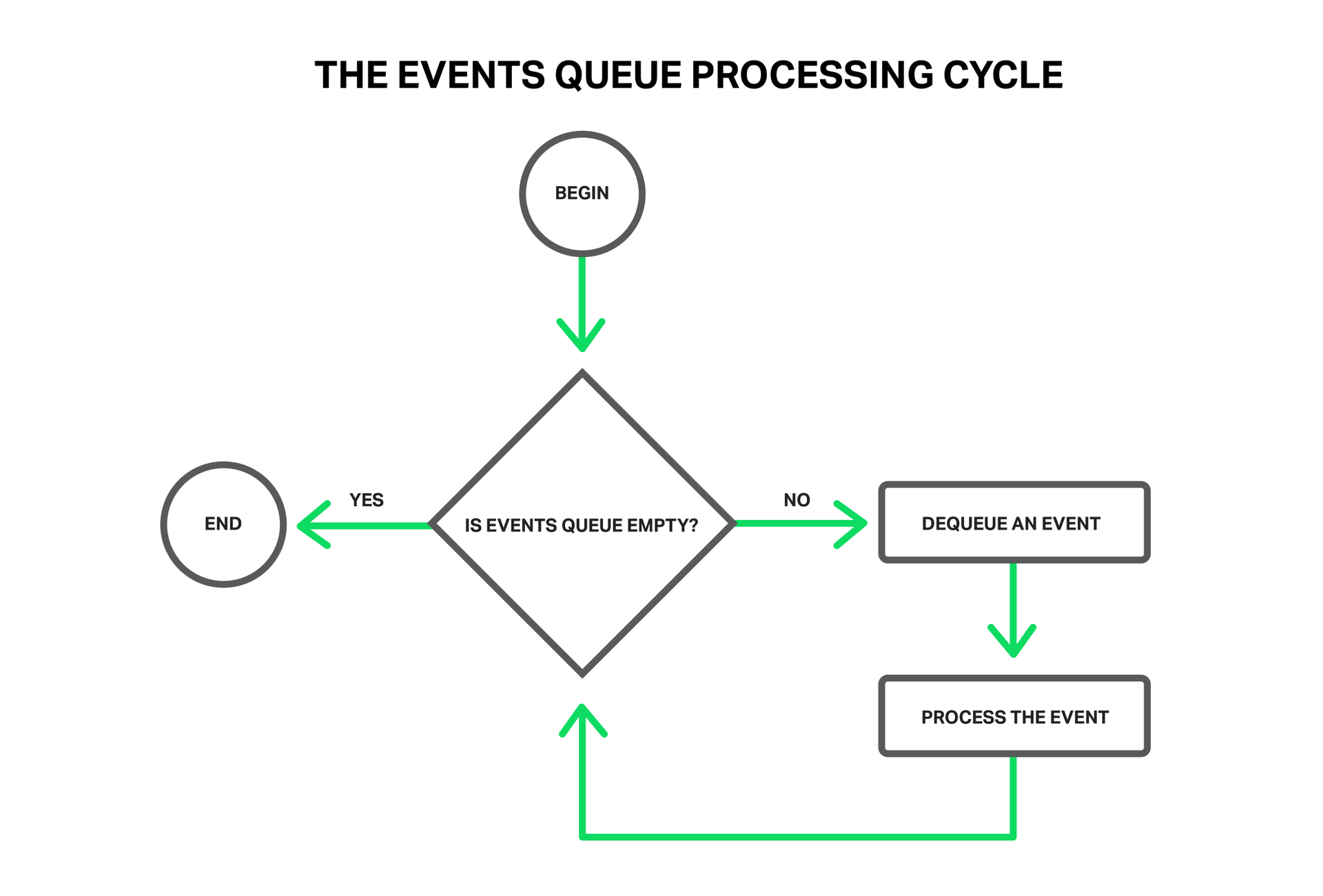
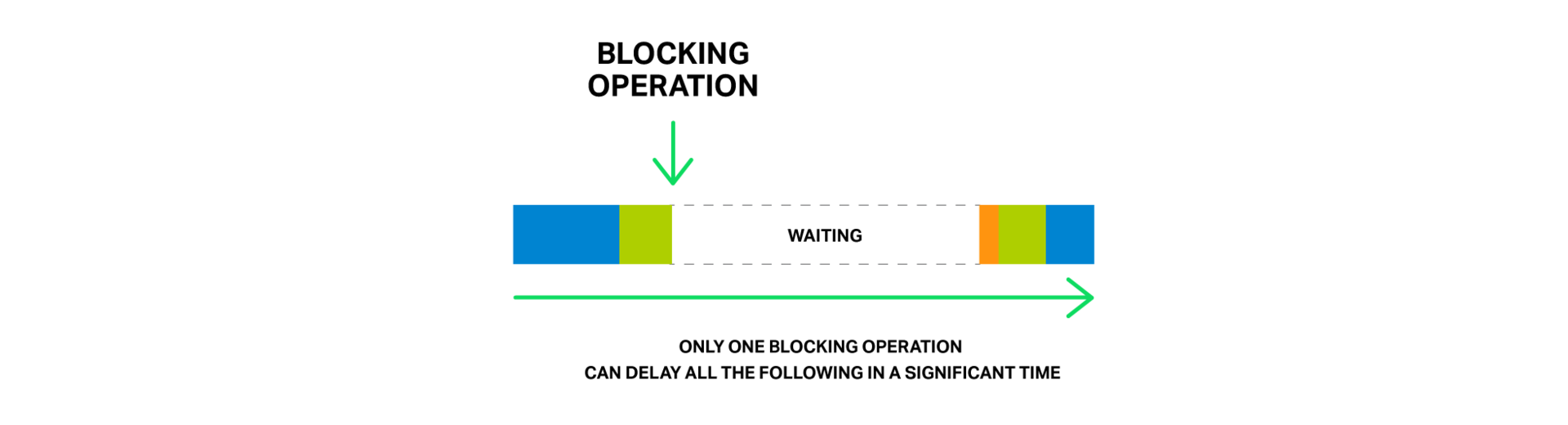
Но что произойдет, если попытаться выполнить какую-то долгую и тяжелую операцию? Весь цикл обработки событий остановится на ожидании завершения этой операции.
Так, под блокирующей операцией мы подразумеваем любую операцию, которая задерживает цикл обработки событий на существенное время. Операции можно назвать блокирующими по разным причинам. Например, NGINX может быть занят долгой ресурсоемкой вычислительной операцией, либо он может ожидать доступа к какому-то ресурсу (жесткому диску, мьютексу, библиотечному вызову, ожидающему ответа от базы данных в синхронном режиме, и т. д.). Ключевым моментом тут является то, что во время выполнения этих операций рабочий процесс не может делать более ничего полезного, не может обрабатывать другие события, хотя у нас зачастую есть еще свободные ресурсы, и события, ожидающие далее в очереди, могут их использовать.
Представьте себе продавца в магазине, к которому выстроилась огромная очередь из покупателей. И вот первый человек из очереди подходит к кассе и хочет купить товар, которого нет на витрине, но есть на дальнем складе. Продавец просит подождать пару часов и уезжает на склад за товаром. Можете себе вообразить реакцию остальных покупателей, стоящих в очереди? Теперь их время ожидания увеличилось на эти два часа, хотя для многих то, что им необходимо, лежит в нескольких метрах на прилавке.

Похожая ситуация происходит в NGINX, когда файл, который нужно отправить, находится не в памяти, а на жестком диске. Диски медленные (особенно те, что вращаются), а остальные запросы, которые ждут своей обработки в очереди, могут не требовать доступа к жестком диску, но все равно вынуждены ждать. В результате растут задержки и ресурсы системы могут не использоваться полностью.
Некоторые операционные системы предоставляют интерфейсы для асинхронного чтения файлов и NGINX умеет эффективно использовать их (см. описание директивы aio). Хорошим примером такой системы является FreeBSD. К сожалению, нельзя сказать того же о Linux. Хотя в Linux и существует некий асинхронный интерфейс для чтения файлов, но он обладает рядом существенных недостатков. Одним из таких является требования к выравниванию чтений и буферов. С этим NGINX успешно с справляется, но вторая проблема хуже. Для асинхронного чтения требуется установка флага
O_DIRECT на файловом дескрипторе. Это означает, что все данные будут читаться с диска минуя кэш страниц операционной системы (т. н. page cache), что во многих случаях не является оптимальным и существенно увеличивает нагрузку на дисковую подсистему.В частности для решения данной проблемы в NGINX 1.7.11 и был представлен новый механизм пулов потоков. Они пока не включены в NGINX Plus, но вы можете связаться с отделом продаж, если желаете испытать сборку NGINX Plus R6 с пулами потоков.
А теперь разберем подробнее, что же они из себя представляют и как функционируют.
Пулы потоков
Вернемся к нашему незадачливому продавцу. Но на этот раз он оказался находчивее (или это после того, как его побили разъяренные покупатели?) и организовал курьерскую службу. Теперь, когда покупатель запрашивает товар, которого нет на прилавке, то вместо того, чтобы покидать прилавок, отправляясь за товаром самостоятельно и вынуждая всех остальных ждать, он отправляет запрос на доставку товара в курьерскую службу и продолжает обслуживать очередь покупателей. Таким образом только те покупатели, чьих заказов не оказалось в магазине, ожидают доставки, а продавец тем временем может без проблем обслуживать остальных.

В случае NGINX роль курьерской службы выполняет пул потоков. Он состоит из очереди заданий и набора отдельных легковесных потоков, которые обрабатывают эту очередь. Когда рабочему процессу требует выполнить какую-то потенциально долгую операцию, то он вместо того, чтобы заниматься этим самостоятельно, помещает задание на обработку в очередь пула, откуда его сразу же может забрать любой свободный поток в обработку.
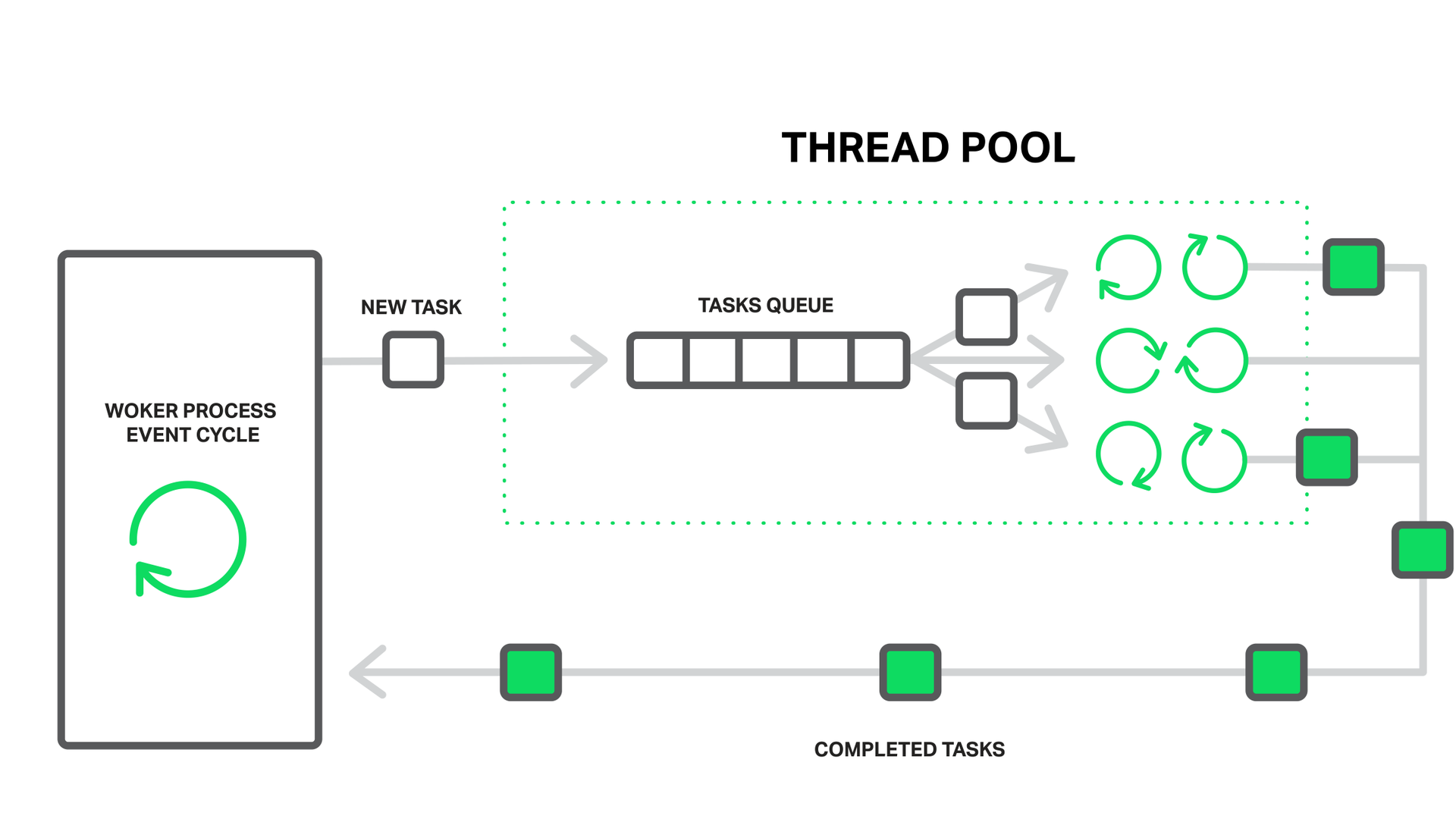
Кажется, что тут у нас еще одна очередь образовалась. Так и есть. Но в данном случае эта очередь ограничена конкретным ресурсом. Мы не можем читать с диска быстрее, чем на это способен он сам, но по крайней мере ожидание чтения теперь не задерживает обработку других событий.
Чтение с диска взято, как наиболее частый пример блокирующей операции, но на самом деле пулы потоков в NGINX могут применяться и для любых других задач, которые нерационально выполнять внутри основного рабочего цикла.
В настоящий момент выгрузка операций в пул потоков реализована только для системного вызова read() на большинстве операционных систем, а также для sendfile() на Linux. Мы продолжим исследования данного вопроса и, вероятно, в будущем реализуем выполнение и других операций пулом потоков, если это даст выигрыш в производительности.
Тестируем производительность
Пора перейти от теории к практике. Для демонстрации эффекта от использования пулов потоков проведем небольшой эксперимент. А именно воссоздадим наиболее тяжелые условия, заставив NGINX выполнять смесь блокирующих и неблокирующих чтений, когда проблема блокировок на обращениях к диску проявит себя в полной мере.
Для это требуется набор данных, который гарантированно не поместится в кэш операционной системы. На машине с объемом оперативной памяти в 48 Гб было сгенерировано 256 Гб файлов по 4 Мб каждый, содержащих рандомные данные и запущен NGINX версии 1.9.0 для их раздачи.
Конфигурация достаточно проста:
worker_processes 16;
events {
accept_mutex off;
}
http {
include mime.types;
default_type application/octet-stream;
access_log off;
sendfile on;
sendfile_max_chunk 512k;
server {
listen 8000;
location / {
root /storage;
}
}
}
Как вы можете заметить, для получения лучших показателей произведен небольшой тюнинг: отключено логирование, отключен accept_mutex, включен sendfile и настроено значение sendfile_max_chunk. Последнее позволяет сократить время блокировки на вызове
sendfile(), поскольку в этом случае NGINX не станет пытаться прочесть и отправить весь файл за раз, а будет это делать частями по 512 килобайт.Машина снабжена двумя процессорами Intel Xeon E5645 (всего 12 ядер, 24 HyperThreading потока) и сетевым интерфейсом 10 ГБит. Дисковая подсистема представляет из себя 4 жестких диска Western Digital WD1003FBYX объединенных в RAID10 массив. Все это управляется операционной системой Ubuntu Server 14.04.1 LTS.

В качестве клиентов выступают две аналогичные по характеристикам машины. На одной из них запущен wrk, создающий постоянную нагрузку Lua-скриптом. Скрипт запрашивает файлы из хранилища в случайном порядке используя 200 параллельных соединений. Назовем данную нагрузку паразитной.
С другой машины-клиента мы будем запускать
wrk, который будет запрашивать один и тот же файл в 50 потоков. Поскольку к данному файлу идет постоянное обращение, то, в отличие от файлов, запрашиваемых в случайном порядке, он не будет успевать вымываться из кэша операционной системы и его чтение всегда будет происходить из памяти. Назовем такую нагрузку тестовой.Производительность мы будем измерять по показателям
ifstat на сервере и статистике wrk со второй машины-клиента.Итак, первый запуск без использования пулов потоков показывает очень скромные результаты:
% ifstat -bi eth2
eth2
Kbps in Kbps out
5531.24 1.03e+06
4855.23 812922.7
5994.66 1.07e+06
5476.27 981529.3
6353.62 1.12e+06
5166.17 892770.3
5522.81 978540.8
6208.10 985466.7
6370.79 1.12e+06
6123.33 1.07e+06
Как видно с данной конфигурацией и под такой нагрузкой сервер способен выдавать порядка одного гигабита в секунду. При этом в top-е можно наблюдать, что все рабочие процессы NGINX находятся большую часть времени в состоянии блокировки на I/O (помечены буквой
D):top - 10:40:47 up 11 days, 1:32, 1 user, load average: 49.61, 45.77 62.89
Tasks: 375 total, 2 running, 373 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 67.7 id, 31.9 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 49453440 total, 49149308 used, 304132 free, 98780 buffers
KiB Swap: 10474236 total, 20124 used, 10454112 free, 46903412 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4639 vbart 20 0 47180 28152 496 D 0.7 0.1 0:00.17 nginx
4632 vbart 20 0 47180 28196 536 D 0.3 0.1 0:00.11 nginx
4633 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.11 nginx
4635 vbart 20 0 47180 28136 480 D 0.3 0.1 0:00.12 nginx
4636 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.14 nginx
4637 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.10 nginx
4638 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4640 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4641 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx
4642 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.11 nginx
4643 vbart 20 0 47180 28276 536 D 0.3 0.1 0:00.29 nginx
4644 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.11 nginx
4645 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.17 nginx
4646 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx
4647 vbart 20 0 47180 28208 532 D 0.3 0.1 0:00.17 nginx
4631 vbart 20 0 47180 756 252 S 0.0 0.1 0:00.00 nginx
4634 vbart 20 0 47180 28208 536 D 0.0 0.1 0:00.11 nginx
4648 vbart 20 0 25232 1956 1160 R 0.0 0.0 0:00.08 top
25921 vbart 20 0 121956 2232 1056 S 0.0 0.0 0:01.97 sshd
25923 vbart 20 0 40304 4160 2208 S 0.0 0.0 0:00.53 zsh
В данном случае все упирается в производительность дисковой подсистемы, при этом процессор большую часть времени простаивает. Результаты
wrk также не утешительны: Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 7.42s 5.31s 24.41s 74.73%
Req/Sec 0.15 0.36 1.00 84.62%
488 requests in 1.01m, 2.01GB read
Requests/sec: 8.08
Transfer/sec: 34.07MB
Достаточно существенные задержки даже на раздаче всего одного файла из памяти. Все рабочие процессы заняты чтением с диска для обслуживания 200 соединений с первой машины, создающей паразитную нагрузку, и не могут своевременно обработать данные тестовые запросы.
А теперь подключим пул потоков, для чего добавим директиву
aio threads в блок location с хранилищем:location / {
root /storage;
aio threads;
}
и попросим наш NGINX перезагрузить конфигурацию.
Повторим тест:
% ifstat -bi eth2
eth2
Kbps in Kbps out
60915.19 9.51e+06
59978.89 9.51e+06
60122.38 9.51e+06
61179.06 9.51e+06
61798.40 9.51e+06
57072.97 9.50e+06
56072.61 9.51e+06
61279.63 9.51e+06
61243.54 9.51e+06
59632.50 9.50e+06
Теперь наш сервер выдает 9,5 ГБит/сек (против ~1 ГБит/сек без пулов потоков)!
Вероятно он мог бы отдавать и больше, но это является практическим пределом для данного сетевого интерфейса и NGINX упирается в пропускную способность сети. Рабочие процессы большую часть времени спят в ожидании событий (находятся в состоянии
S):top - 10:43:17 up 11 days, 1:35, 1 user, load average: 172.71, 93.84, 77.90
Tasks: 376 total, 1 running, 375 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 1.2 sy, 0.0 ni, 34.8 id, 61.5 wa, 0.0 hi, 2.3 si, 0.0 st
KiB Mem: 49453440 total, 49096836 used, 356604 free, 97236 buffers
KiB Swap: 10474236 total, 22860 used, 10451376 free, 46836580 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4654 vbart 20 0 309708 28844 596 S 9.0 0.1 0:08.65 nginx
4660 vbart 20 0 309748 28920 596 S 6.6 0.1 0:14.82 nginx
4658 vbart 20 0 309452 28424 520 S 4.3 0.1 0:01.40 nginx
4663 vbart 20 0 309452 28476 572 S 4.3 0.1 0:01.32 nginx
4667 vbart 20 0 309584 28712 588 S 3.7 0.1 0:05.19 nginx
4656 vbart 20 0 309452 28476 572 S 3.3 0.1 0:01.84 nginx
4664 vbart 20 0 309452 28428 524 S 3.3 0.1 0:01.29 nginx
4652 vbart 20 0 309452 28476 572 S 3.0 0.1 0:01.46 nginx
4662 vbart 20 0 309552 28700 596 S 2.7 0.1 0:05.92 nginx
4661 vbart 20 0 309464 28636 596 S 2.3 0.1 0:01.59 nginx
4653 vbart 20 0 309452 28476 572 S 1.7 0.1 0:01.70 nginx
4666 vbart 20 0 309452 28428 524 S 1.3 0.1 0:01.63 nginx
4657 vbart 20 0 309584 28696 592 S 1.0 0.1 0:00.64 nginx
4655 vbart 20 0 30958 28476 572 S 0.7 0.1 0:02.81 nginx
4659 vbart 20 0 309452 28468 564 S 0.3 0.1 0:01.20 nginx
4665 vbart 20 0 309452 28476 572 S 0.3 0.1 0:00.71 nginx
5180 vbart 20 0 25232 1952 1156 R 0.0 0.0 0:00.45 top
4651 vbart 20 0 20032 752 252 S 0.0 0.0 0:00.00 nginx
25921 vbart 20 0 121956 2176 1000 S 0.0 0.0 0:01.98 sshd
25923 vbart 20 0 40304 3840 2208 S 0.0 0.0 0:00.54 zsh
И у нас еще есть солидный запас по ресурсам процессора.
Результаты
wrk со второй машины:Running 1m test @ http://192.0.2.1:8000/1/1/1
12 threads and 50 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 226.32ms 392.76ms 1.72s 93.48%
Req/Sec 20.02 10.84 59.00 65.91%
15045 requests in 1.00m, 58.86GB read
Requests/sec: 250.57
Transfer/sec: 0.98GB
Среднее время отдачи 4 Мб файла сократилось с 7.42 секунд до 226.32 миллисекунд, т.е. в ~33 раза, а количество обрабатываемых запросов в секунду возросло в 31 раз (250 против 8)!
Объясняется все это тем, что теперь запросы более не ждут в очереди на обработку, пока рабочие процессы заблокированы на чтении с диска, а обслуживаются свободными потоками. И пока дисковая подсистема делает свою работу как может, обслуживая наш “паразитный” трафик с первой машины, NGINX использует оставшиеся ресурсы процессора и пропускную способность сети, чтобы обслужить второго клиента из памяти.
Серебряной пули не существует
После всех страшилок про блокирующие операции и таких потрясающих результатов, многие из вас захотят скорее включит пулы потоков на своих серверах. Не спешите.
Правда в том, что, к счастью, в большинстве случаев операции с файлами не приводят к чтению с медленного жесткого диска. Если у вас хватает оперативной памяти, то современные операционные системы достаточно умны, чтобы закэшировать файлы, к которым часто происходит обращение в так называемом кэше страниц (page cache).
Кэш страниц справляется достаточно хорошо и это всегда позволяло NGINX демонстрировать высокую производительность в наиболее распространенных ситуациях. Чтения из кэша страниц происходят очень быстро и такую операцию нельзя назвать блокирующей. В то же время, взаимодействие с пулом потоков несет дополнительные издержки на синхронизацию.
Так что если у вас достаточно оперативной памяти и небольшой объем горячих данных, то у вас уже все хорошо и NGINX работает наиболее оптимальным образом без использования пулов потоков.
В действительности выгрузка операций чтения в отдельный пул потоков решает довольно узкий спектр задач. Он ограничен ситуациями, когда объем регулярно запрашиваемых данных не помещается в оперативной памяти, что делает кэш страниц операционной системы неэффективным. Таким примером может являться высоконагруженный сервис раздачи медиаданных. Данную ситуацию мы и симулировали в нашем тесте.
Выгрузку операций чтения в пулы потоков можно было бы сделать более универсальной для операций чтения и снизить задержки, если бы существовал эффективный способ узнать заранее, находятся ли необходимые данные в памяти или нет, и только в последнем случае выгружать операцию в отдельный поток.
Возвращаясь к аналогии с магазином и дальним складом, сейчас у продавца нет возможности узнать, что товар находится на витрине и он вынужден всегда работать посредством курьерской службы.
Дело в том, что отсутствует соответствующая поддержка со стороны ядра операционной системы. Первые попытки добавить такую возможность в Linux в виде системного вызова fincore() относятся к 2010 году, но «воз и ныне там». Позже были попытки в виде системного вызова
preadv2() и флага RWF_NONBLOCK (подробности можно узнать из статей Non-blocking buffered file read operations и Asynchronous buffered read operations на LWN.net) — но судьба и этих патчей по прежнему под вопросом. Печально, что виной всему этому похоже является пресловутый байкшединг (споры о том, какого цвета фломастеры лучше пахнут).В то время, как пользователям FreeBSD не о чем беспокоиться, у них есть неплохо работающий механизм асинхронного чтения, реализованный в ядре. Именно его и рекомендуется использовать вместо пулов потоков.
Конфигурация
Итак, если вы твердо уверены, что сможете извлечь выгоду из пула потоков для ваших задач, то непременно встает вопрос, как его включить и настроить.
Конфигурация достаточно простая и вместе с тем очень гибкая. Для начала вам потребуется NGINX версии 1.7.11 или выше, собранный с флагом
--with-threads. В простейшим случае настройка выглядит элементарно. Все, что необходимо для включения выгрузки операций чтения и отправки файлов в пул потоков, это директива aio на уровне http, server или location, установленная в значение threads:aio threads;
Это минимально возможный вариант настройки пулов потоков. На самом деле он является сокращенной версией такой конфигурации:
thread_pool default threads=32 max_queue=65536;
aio threads=default;
Она задает пул потоков
default, в котором будут работать 32 потока и максимально допустимый размер очереди заданий составляет 65536. Если очередь заданий переполняется, то NGINX отклоняет запрос и логирует ошибку:thread pool "NAME" queue overflow: N tasks waiting
Такое возможно, если ваши потоки не справляются с объемом работы и очередь заполняется быстрее, чем обрабатывается. В этом случае вы можете попробовать увеличить максимальной размер очереди и если это не помогает, то значит ваша система просто не в состоянии обработать такое большое количество запросов.
Как можно заметить, с помощью директивы thread_pool у вас есть возможность задавать количество потоков, максимальный размер очереди, а также имя данного пула потоков. Последнее предполагает возможность сконфигурировать несколько независимых пулов и использовать их в разных частях конфигурации для разных задач:
thread_pool one threads=128 max_queue=0;
thread_pool two threads=32;
http {
server {
location /one {
aio threads=one;
}
location /two {
aio threads=two;
}
}
…
}
Если параметр
max_queue не указан явно, как в пуле two, то используется значение по умолчанию, равное 65536. Как видно из примера, можно задать нулевой размер очереди. Тогда пул сможет одновременно принимать в обработку только такое количество заданий, сколько у него имеется свободных потоков и не будет ожидающих в очереди заданий.А теперь представьте, что у вас есть сервер с тремя жесткими дисками, который должен выполнять роль кеширующего прокси для ваших бэкендов. При этом предполагаемый размер кэша многократно превосходит объем доступной оперативной памяти. По сути это что-то вроде кэш-ноды в вашей личной сети раздачи контента (CDN). В этом случае основная нагрузка по отдачи кэшированных данных будет ложиться на дисковую подсистему. Разумеется вы хотите извлечь максимум производительности из тех трех дисков, что имеются в наличии.
Одним из решений тут может стать организация RAID массива. У такого подхода конечно же есть свои плюсы и минусы. Но сегодня NGINX готов предложить вам другой подход:
# В нашей системе каждый из жестких дисков примонтирован в одну из следующих директорий:
# /mnt/disk1, /mnt/disk2 или /mnt/disk3 соответственно
thread_pool pool_1 threads=16;
thread_pool pool_2 threads=16;
thread_pool pool_3 threads=16;
http {
proxy_cache_path /mnt/disk1 levels=1:2 keys_zone=cache_1:256m max_size=1024G use_temp_path=off;
proxy_cache_path /mnt/disk2 levels=1:2 keys_zone=cache_2:256m max_size=1024G use_temp_path=off;
proxy_cache_path /mnt/disk3 levels=1:2 keys_zone=cache_3:256m max_size=1024G use_temp_path=off;
split_clients $request_uri $disk {
33.3% 1;
33.3% 2;
* 3;
}
server {
…
location / {
proxy_pass http://backend;
proxy_cache_key $request_uri;
proxy_cache cache_$disk;
aio threads=pool_$disk;
sendfile on;
}
}
}В данной конфигурации используется три независимых кэша — по одному на каждый жесткий диск, и три независимых пула потоков, также по одному на диск.
Для равномерного распределения нагрузки между кэшами (а соответственно и жесткими дисками) используется модуль split_clients, который прекрасно для этого подходит.
Параметр
use_temp_path=off у директивы proxy_cache_path инструктирует NGINX сохранять временные файлы в той же директории, где находятся данные кэша. Это необходимо во избежание копирования данных с одного диска на другой при сохранении ответа в кэш.Все это вместе позволяет выжать максимум производительности из данной дисковой подсистемы, поскольку NGINX посредством отдельных пулов потоков взаимодействует с каждым диском параллельно и независимо. Каждый диск обслуживают 16 независимых потоков и для него формируется отдельная очередь заданий на чтение и отправку файлов.
Ведь ваши клиенты любят индивидуальных подход? Будьте уверены ваши жесткие диски тоже. ;)
Данный пример является демонстрацией огромной гибкости NGINX в конфигурировании непосредственно под ваше железо. Вы как бы инструктируете NGINX, каким образом лучше всего взаимодействовать с дисковой подсистемой на данном сервере и вашими данными. И такая тонкая настройка, когда программное обеспечение вплоть до пользовательского уровня работает с оборудованием самым оптимальным образом, обеспечивает наиболее эффективное использование всех ресурсов конкретной системы.
Выводы
Пулы потоков — это замечательный механизм, который борется с основным и хорошо известным врагом асинхронного подхода — блокирующими операциями, и тем самым позволяет вывести NGINX на новый уровень производительности, особенно если мы говорим об очень больших объемах данных.
Как уже упоминалось ранее, пулы потоков могут быть использованы и для любых других операций и работы с библиотеками, не имеющими асинхронного интерфейса. Потенциально это открывает новые возможности для реализации модулей и функциональности, реализация которой без ущерба для производительности ранее была неосуществимой в разумные сроки. Можно потратить много усилий и времени на написание асинхронного варианта имеющийся библиотеки или в попытках добавить такой интерфейс, но возникал вопрос: «стоит ли игра свеч»? С пулами потоков данную задачу можно решить гораздо проще, создавая модули, работающие с блокирующими вызовами, и при этом не мешая NGINX выполнять свою основную задачу обрабатывая остальные запросы.
Так что много нового и интересного ждет NGINX в будущем. Оставайтесь с нами!
Комментарии (47)

sebres
19.06.2015 15:03+21Офигительный перевод Бартенева, сделаный Бартеневым )) Неделя nginx продолжается… Ура!
crea7or
19.06.2015 15:21Я так понял, что теперь будет проще на IOCP переписать под Windows?

VBart Автор
19.06.2015 15:29+2Нет. IOCP тут ортогонально. Прелесть данного механизма пулов потоков заключается в том, что он абсолютно независим от основного процесса обработки событий, не использует с ним разделяемых ресурсов, кроме двух очередей, что позволяет практически избежать локов и вмешательств в основные структуры.
Кроме того он реализован только под *nix.crea7or
19.06.2015 16:40Так через асинхронные функции с OVERLAPPED (под Windows) не будет достигнут такой же эффект?
VBart Автор
19.06.2015 17:38Почитал про overlapped. Кажется это скорее про реализацию нормального ядерного AIO и отдельные потоки там не нужны. Но я могу ошибаться, поскольку плохо знаком с windows даже на уровне пользователя.
Возможно sebres сможет ответить.
Важно понимать, что текущая реализация пулов не делает nginx многопоточным в плане обработки событий, он по-прежнему обрабатывает события на дескрипторах асинхронно и в одном потоке на рабочий процесс. А отдельные потоки из пулов используются исключительно для выгрузки долгих блокирующих операций, при этом они изолированы от основного потока через две сериализованные очереди (очередь ожидающих обработки заданий и очередь выполненных заданий).sebres
19.06.2015 18:15+2Так то оно так. И это правда реактор на AIO. Просто тонкости реализации и «тонкие» настройки там играют очень заметную роль. Много и много фрагильнее линуксовых. Например в свое время была такая библиотека как ACE, так там до какой-то версии реактор acceptor-ов «конфликтовал» с реактором worker-ов. Ужасно бажная была реализация.
Проблема еще в том, что под win GetOverlappedResult (или WSAGetOverlappedResult) многопоточно, это не тоже самое что GetOverlappedResult многопроцессно. Вся разница в том, что оно изначально заточено под пул потоков и там более менее оптимально «ядерно» работает. В случае же много процессов есть небольшой конфликт в ядре в генераторе события и обертка над наследуемыми сокетами там в одном месте как-бы настолько синхронна (и насколько помню даже не атомарно), что не просто context switch, а процессы тупо «распараллеливаются» — это не то, чтобы узкое горлышко — по моему такое называют порогами (как на реке), т.е. потоки разных процессов их проходят друг за другом.
Кто погоняет такой реактор SoftICE-ом с дебажным win-kernel, откроет для себя много нового по поводу thread != process под windows.

A_J
19.06.2015 15:31Пулы потоков это хорошо, но проблема еще и в том, что нет возможности узнать чем занимается конкретный поток. Быть может он ждет на блокирующей операции, а процессор в результате простаивает. К сожалению, системного вызова который бы сообщил состояние thread в Linux нет.
VBart Автор
19.06.2015 15:33+4Так задача потока в пуле и заключается в том, чтобы ждать на блокирующей операции.
A_J
19.06.2015 15:50Если использовать их только для этого то все ок (как у вас указано — для обслуживания read()) но если добавить что-то еще то возможны варианты.
Я сталкивался со сценариями типа: часть запросов требует интенсивного счета, другая часть — ввода/вывода (т.е. может блокироваться). Если все потоки из пула уже заблокировались, то вроде как имеет смысл добавить новых, для выполнения счетных операций. Но поскольку знать состояние потока мы не можем, то непонятно когда это делать.
Разумеется, пока вы используете пулы потоков только для ожидания — все более-менее ок.VBart Автор
19.06.2015 15:58+2Для интенсивного счета можно будет настроить отдельный пул потоков. NGINX позволяет создать их сколько угодно. Зачем смешивать все операции в одну кучу? У него будет своя очередь и необходимое количество тредов.
A_J
19.06.2015 16:03Возможно вы и правы, и я хочу странного.
Просто хочется меньше задумываться над спецификой.

grossws
19.06.2015 15:54+1Спасибо за статью. А какие блоги можете посоветовать nginx internals с точки зрения разработки/доработки модулей? Из того, что находил хорошего — Evan Miller, agentzh и что-то у Joshua Zhu.
VBart Автор
19.06.2015 16:03+4Пожалуй к этому списку нечего больше добавить. Самый лучший nginx internals постигается чтением исходников.
Есть ещё выступление Валерия Холодкова на HL++ 2008 и статья по мотивам: www.grid.net.ru/nginx/nginx-modules.html и его же блог, посвященный исследованиям внутренностей nginx: www.nginxguts.com

stalkerg
19.06.2015 17:41+1lkml.org/lkml/2015/3/16/891 — Уже 7 версию пытаются… Andrew Morton конечно бухтит но и смысл в его словах есть.
Нам для Postgres это то же нужно, что бы адекватнее косты подсчитывать (fincore в смысле). Надо как то их всех пнуть.VBart Автор
20.06.2015 00:10Да, я пару месяцев назад общался с Милошем. С его патчами нам будет не хватать
sendfile(). В этом отношении подход Мортона чуть более универсален, хотя менее эффективен и порождает маловероятный на практике, но всё же существующий race-condition между вызовомfincore()и соответвующимread()илиsendfile(). С другой стороныfincore()нам не поможет при записи. При определенных условияхwrite()блокируется и хорошо бы об этом узнать заранее, чтобы отправить соответвующий таск в пул.
Милош настроен твердо: twitter.com/mtanski/status/611932316865298433

apangin
20.06.2015 03:33+2Чудо! Не могу поверить, что в самом популярном сервере поддержка пула потоков для длительных операций появилась только в 2015 году. При том, что паттерн Proactor известен науке по меньшей мере с 90-х.
Забавно, что автор винит ОС в том, что нет возможности узнать, какие данные закешированы, а какие нет.
Кешируйте сами — делов-то!
Именно так работает, например, video download сервер известной социальной сети. То, что закешировано в памяти, он отдаёт сразу из потока-селектора. А за тем, чего в кеше нет, обращается асинхронно из отдельного пула. В результате один сервер отдаёт наружу до 40 Гбит/с, причём сам сервер написан даже не на C, а на «тормозной» Java.VBart Автор
20.06.2015 12:42+5Не могу поверить, что в самом популярном сервере поддержка пула потоков для длительных операций появилась только в 2015 году. При том, что паттерн Proactor известен науке по меньшей мере с 90-х.
Не очень понял, какая логическая связь между двумя процитированными предложениями. Мне кажется её нет, но отвечу. Не было необходимости, да и сейчас в большинстве случаев включать пул потоков нет необходимости. Для большинства типичных задач он не нужен. И даже в тех случаях, когда он нужен, есть и другие варианты решения проблемы.
Забавно, что автор винит ОС в том, что нет возможности узнать, какие данные закешированы, а какие нет.
И файловую систему пишите сами, и tcp-стек, и т.д. по списку. Как только вы начинаете кэшировать данные сами, то натыкаетесь на необходимость копировать огромные объемы данных из ядра в пользовательское пространство и обратно. Такой системный вызов, как
Кешируйте сами — делов-то!sendfile()был создан специально для того, чтобы этим не заниматься. Вы наверное не сталкивались, когда производительность начинает упираться в память и приходится делать всё возможное, чтобы уменьшать количество копирований.
Именно так работает, например, video download сервер известной социальной сети. То, что закешировано в памяти, он отдаёт сразу из потока-селектора. А за тем, чего в кеше нет, обращается асинхронно из отдельного пула. В результате один сервер отдаёт наружу до 40 Гбит/с, причём сам сервер написан даже не на C, а на «тормозной» Java.
Безусловно есть разные подходы к решению задачи. Каждый подход имеет свои плюсы и минусы. Инженеры из известной социальной сети выбрали такой подход и мы не знаем всех факторов, которые повлияли на их решение, поэтому я не возьмусь, например, давать оценки.
Информация про 40 Гбит/с особо не говорит ни о чем, ибо число сильно далеко от того, чтобы производить впечатление в 2015 году. И если уж мериться, то нужно делить этот показатель на стоимость сервера. Одно дело раздавать 40 Гбит/c с одного сервера, а другое дело раздавать треть всего интернет трафика в США и значительную долю всего мирового трафика с серверов, собранных из недорогих комплектующих. Когда количество серверов исчесляется десятками и сотнями тысяч, то их стоимость начинает иметь существенное значение. Ну и т. д. ;)apangin
20.06.2015 14:15Прошу прощения, писал ночью — грубовато получилось. Просто искренне удивился, что лежащая на поверхности идея, которую я и сам не раз упоминал в докладах про архитектуру ОК, оказывается, до недавнего времени, в NGINX не была реализована. Думал, может, какие-то подводные камни были. Ну, раз просто было не нужно — то ладно.
Ручное кеширование не отменяетsendfile. Я ж не зря ссылку на презентацию дал — там всё наглядно рассказано и показано. Создаёте один большой файл в/dev/shm, мапите в адресное пространство процесса. Работаете как с обычной памятью, разбиваете на блоки, вытесняемые по принципу LRU. А в сеть отдаёте блоки черезsendfile, минуя user space.
40 Гбит/с, поверьте, у нас тоже не суперкомпьютеры раздают. Понятно, что это ближе к верхушке нашей линейки, но я про то, что это не экспериментальный стенд, а commodity оборудование, стоящее на эксплуатации.VBart Автор
20.06.2015 14:35+1На 2002 год, когда Игорь начал разработку nginx, он пробовал разные подходы и смотрел на треды. На тот момент с поддержкой потоков в интересующих операционных системах всё было очень и очень плохо. Поэтому да, подводные камни были.
VBart Автор
20.06.2015 15:38+1С предложенным подходом возникает несколько вопросов. Как минимум оно не будет нормально работать на FreeBSD, поскольку там с tmpfs всё плохо в этом месте или было плохо до недавнего времени (могу уточнить этот момент у наших FreeBSD разработчиков, поскольку сам я на Linux специализируюсь).
Второй момент в том, что всё это сильно напоминает попытку реализации кэша страниц, но в пользовательском простанстве. Я вот не уверен, что это будет сильно лучше работать. Зато точно уверен, что потребует трудозатрат на более-менее универсальную реализацию и последующую поддержку. Тем более, что большинство проблем связаны как раз с тем случаем, когда горячие данные никак в память не помещаются и любое кэширование малоэффективно. Докладчик упоминает, что данные в LRU кэше в среднем живут 40 секунд. Возникает вопрос, что будете делать, когда данные там будут жить 40 микросекунд?
Решая отдельную специфическую задачу можно не наступить на ряд граблей, которые всплывут при попытке реализовать универсальное решение. Например, очень скоро обнаружится, что сильно не хватает умного readahead'а, и его тоже потребуется реализоваывать в юзерспейсе.apangin
20.06.2015 17:18Решение, конечно же, должно быть опциональным и конфигурируемым. Я ведь не говорю, что нужно по умолчанию его использовать везде, включая FreeBSD, с которым, как вы утверждаете, и так всё хорошо. Или на системах, где кеш вообще бесполезен (у нас есть и такие — мы в это случае просто ставим в сервер дюжину SSD накопителей, и с кешами даже не заморачиваемся). Но в ряде случаев, как раз для раздачи тяжёлого медиаконтента с характерным профилем популярности, это и будет той серебряной пулей для Linux, о которой вы писали.
Про затраты на разработку никто не спорит. Я лишь делюсь опытом, что этот подход: а) востребован, б) относительно просто реализуем, в) приносит пользу.
Помимо прочего, кеширование в user space открывает широкое поле для различного рода улучшений. Например, вы можете явно управлять тем, какой контент как долго живёт и как вытесняется. Например, контент средней степени популярности мы при вытеснении складываем в кеш второго уровня на SSD, а непопулярный выкидываем совсем.
Дисковый же кеш очень непредсказуем. Скажем, Linux может вдруг решить, что в данный момент кеш важнее хипа приложения, и выгрузить хип в своп, несмотря на любые настройки/proc/sys/vm.
А что насчёт HTTPS? Как вам тут поможет дисковый кеш иsendfile? В нашем же случае мы без лишних копирований отправляем данные из того же кеша, заменив толькоsendfileнаSSL_write. Конечно, 40 Гбит/с тут уже не будет, но 25 Гбит шифрованного трафика тоже немало.VBart Автор
21.06.2015 00:30+4Я знаю другой опыт, который подсказывает, что серебряной пулей это не будет, если вообще будет лучше. Кстати, так работает Varnish Cache например, он полностью управляет своим кэшом, но особого выигрыша там не видно.
Есть две крайности — одна запихивать всё в ядро (аля TUX), а другая реализовывать всё в юзерспейсе. Последний подход чреват тем, что в итоге всё равно прослойка в виде ядра остается и проблемы ядра никуда не уходят, а только множаться. Ядро работает с сетью, ядро работает с диском, и от этого никуда не деться, если только не выкинуть ядро совсем, но это уже другая история. Я согласен с тем, что у приложения есть больше информации о том, как лучше кэшировать данные, но это не является причиной приложению брать на себя функции ядра. Это является поводом улучшить интерфейс ядра в этом месте.
Пример одной социальной сети очень неубедительный. Его не с чем сравнить. В докладе я не услышал о том, что пытались сделать так-то, столкнулись с такими-то проблемами, их можно было преодолеть только таким вот решением. Скорее звучит, как мы решили, что так будет эффективнее, реализовали и вроде как работает, наши задачи выполняет. Но из этого нельзя сделать вывод, что решение получилось эффективным. Где сравнение с другими подходами?
При этом столкнулись с проблемой вытеснения данных из кэша, до того, как отработает sendfile() и никак эту проблему не решили. Возможно это приемлемо для конкретного случая, но во всех остальных это будет неприемлемо и серьезной проблемой.
Улучшение, о котором вы говорите — скорее не улучшение, а наоборот ещё один механизм, который уже реализован ядром и его потребуется реализовывать заново. Сейчас всё это можно настроить с помощью dm-cache или bcache достаточно гибко и эффективно.
И ещё ни разу не видел, чтобы при наличии свободных страниц ядро начинало бы свопить если не преодолен рубеж swappiness. Если есть какая-то проблема в ядре, которая приводит к странностям и дергадации в определенных ситуациях, то её нужно исправлять.
В свою очередь с за'map'ленными в память файлами есть серьезная проблема. Сейчас если у нас происходит ошибка чтения с диска, то read() или sendfile() возвращает ошибку, приложение может эту ошибку обработать и продолжить работать дальше. С map() приложение упадет, что для асинхронного сервера, обрабатывающего тысячи запросов в одном процессе очень больно.
Если мы будем копировать с диска в /dev/shm, то будет дополнительная работа, во-первых. Во-вторых, возникает проблема со свопингом, если наш кэш начнет свопиться, то всё «превратиться в тыкву».
Из памяти можно отдавать столько, сколько позволяет шина памяти и сетевая подсистема, 40 Гбит/сек тут не предел. Сложности наступают тогда, когда нужно раздавать 150 терабайт с одного сервера и упираешься во все подряд так, что приходится пробовать различные подходы, работать с вендорами жестких дисков, оптимизировать прошивку, драйвера, различные подсистемы ядра и сетевой стек, изобретать новый алгоритм для congestion control в TCP. Всего этого в докладе одной социальной сети не наблюдается.
В свою очередь советую послушать:
events.yandex.ru/lib/talks/2682 — там же есть ответ на ваш вопрос о HTTPS ;-)
events.yandex.ru/lib/talks/2396apangin
21.06.2015 01:33По-моему, вы сейчас пытаетесь на ходу придумать оправдания, почему кеширование в
/dev/shmплохо. Не хотите так делать — не надо, кто-нибудь другой сделает. Я ж не принуждаю, а просто делюсь положительным опытом.
При этом столкнулись с проблемой вытеснения данных из кэша, до того, как отработает sendfile() и никак эту проблему не решили.
Решили тривиальным reference counter'ом.
И ещё ни разу не видел, чтобы при наличии свободных страниц ядро начинало бы свопить если не преодолен рубеж swappiness.
А я, вот, видел, как приswappiness=0Linux вместо освобождения page cache иногда начинает свопить полезную память. В тоже время со свопом кеша из/dev/shmпроблем нет. Тем более, что кеш этот — одна непрерывная область, которая легко лочится черезmlock. Так что метафора про «тыкву» неуместна.
В свою очередь с за'map'ленными в память файлами есть серьезная проблема. Сейчас если у нас происходит ошибка чтения с диска
С какого диска? Мы мапим файл из tmpfs, он целиком в памяти.
Если мы будем копировать с диска в /dev/shm, то будет дополнительная работа
Серьёзно? Если данные востребованы, и мы хотим их закешировать в памяти, как это можно сделать проще, не делаяread?
приходится пробовать различные подходы, работать с вендорами жестких дисков, оптимизировать прошивку, драйвера, различные подсистемы ядра и сетевой стек, изобретать новый алгоритм для congestion control в TCP
Вот, как раз про всё это вас было бы очень интересно послушать :)VBart Автор
21.06.2015 02:42+1По-моему, вы сейчас пытаетесь на ходу придумать оправдания, почему кеширование в /dev/shm плохо. Не хотите так делать — не надо, кто-нибудь другой сделает. Я ж не принуждаю, а просто делюсь положительным опытом.
У меня свое мнение на этот счет и свой опыт, поэтому я привожу аргументы в пользу того, что не стоит один положительный опыт обощать в качестве универсального решения.
Решение с fincore() или RWF_NONBLOCK оно универсально. Поскольку его можно включить и оно у всех будет работать, не важно сколько у человека памяти и как она используется, не важно, что у человека на том же сервере ещё и база данных крутится, php-процессы и log rotate периодически запускается сжимая большие логи. А главное, ничего отдельно настраивать не придется, не придется подбирать размер кэша.
Вы почему-то назвали это забавным, что я этого хочу, мол вы лучше перенесите всю логику кэша страниц в юзерспейс и будет вам счастье.
Тем более, что кеш этот — одна непрерывная область, которая легко лочится через mlock. Так что метафора про «тыкву» неуместна.
Если взять и залочить огромный объем памяти, то мы автоматически лишаем этой памяти систему. В итоге в своп улетит что-нибудь другое, не менее важное. У системного кэша страниц в этом случае приемущество, что он динамический.
В вашей системе — кэш есть центр вселенной и всё вращается вокруг него, у множества пользователей nginx это не так. И завтра человек залочит 3 Гб памяти из имеющихся у него 4 на его VPS-ке, а в пик нагрузки у него php-fpm демоны улетят в своп.
Я не пытаюсь утверждать, что ваше решение плохое, я все пытаюсь донести мысль, что у него есть свои минусы и с решением одной проблемы, мы принесем множество других.
Я не исключаю, что подобный кэш будет когда-нибудь реализован в nginx для отдельных случаев, но сегодня нужны fincore() или RWF_NONBLOCK.
С какого диска? Мы мапим файл из tmpfs, он целиком в памяти.
И при этом файл пустой.
Можно не мапить из tmpfs, а делать непосредственно mmap() на сам файл на диске и таким образом пытаться управлять тем, что у нас есть в памяти, работать с ним, как с памятью, а не с файлом. Об этом случае я писал в параграфе, это просто еще один вариант управляемого кэша, который приходит в голову.
Я понимаю, что вы делаете иначе. Следующий абзац и был про ваш случай, на что вы вполне резонно заметили:
Серьёзно? Если данные востребованы, и мы хотим их закешировать в памяти, как это можно сделать проще, не делая read?
Всё верно, изобретая промежуточный слой в виде tmpfs, вы вынуждены делать сперва read() и копировать в него данные.
Сделать проще, это позвать sendfile() на самом файле без промежуточного слоя в виде tmpfs и позволить оперционной системе сделать свою работу по кэшированию данных, как nginx уже делает и вполне успешно. Если данные востребованы, то они будут в кэше страниц и без лишних приседаний.
Вот, как раз про всё это вас было бы очень интересно послушать :)
Я ссылку и дал ниже на пару докладов Глеба Смирнова, который непосредственно работает с Netflix-ом и может гораздо больше и лучше меня об этом рассказывать.VBart Автор
21.06.2015 03:35Спутанно получилось. Третий час ночи, пора спать.
Если коротко, то:
1. Есть различные подходы.
2. Один из них — это оставить управление кэшом операционной системе, как nginx и делает. И его пример показывает, что для большинства он неплохо работает. Поэтому я склонен считать его всё же более универсальным.
3. Второй подход — это собственный кэш в памяти, которым управляет приложением. Его можно также реализовывать разными способами.
4. У каждого из этих подходов есть приемущества и недостатки. И рассматривать их нужно в зависимости от решаемой задачи.
5. Как бы то ни было, fincore() или RWF_NONBLOCK нам с текущим подходом поможет.
apangin
21.06.2015 02:02Кстати, к вопросу о других решениях. NGINX мы тоже тестировали, хотели использовать в качестве прокси. Не вышло: уже при трафике в 3 Гбит/с CPU usage улетал в 100%. Деталей, к сожалению, не знаю, могу потом у коллег уточнить. Просто о неудачах редко когда рассказывают на конференциях :) Хотя, согласен, отрицательный опыт тоже порой очень интересен.

datacompboy
21.06.2015 11:25+5Польза большинства отрицательных опытов гораздо выше большинства положительных.

Zelgadis
24.06.2015 10:01+1В православной ОС идут работы по переносу части SSL в ядро как раз, чтобы не копировать лишниый раз.
apangin
20.06.2015 14:23Мда, я так выразился, что вы, наверное, подумали, будто у нас всего один download сервер :) Не, их много. И они генерируют львиную долю трафика, пусть и не Штатов, но хотя бы Рунета.

iDoka
20.06.2015 17:01CentOS 7 x64
$ uname -a Linux 3.10.0-229.1.2.el7.x86_64 #1 SMP x86_64 GNU/Linux $ nginx -V nginx version: nginx/1.8.0 built by gcc 4.8.2 20140120 (Red Hat 4.8.2-16) (GCC) ... --with-file-aio
При вставке в /etc/nginx/nginx.conf строчки aio threads; получаю ошибку:
[emerg] «aio threads» is unsupported on this platform
PS: nginx из репозитория nginx.org/packages/centos/7
Что я делаю не так?VBart Автор
20.06.2015 22:59Опция
--with-file-aioне имеет отношения к тредам, она про файловое AIO в ядре. NGINX должен быть собран с опцией--with-threads. В нашем репозитории на данный момент с ней собирается только mainline версия пакетов и для тех дистрибутивов, где glibc не слишком старый и в нём есть поддержка eventfd(). Попробуйте поставить 1.9.2.

DjOnline
23.06.2015 20:55>>если бы существовал эффективный способ узнать заранее, находятся ли необходимые данные в памяти или нет, и только в последнем случае выгружать операцию в отдельный поток.
То есть второй поток awk из примера всегда заново читает данные с диска, именно поэтому всего 250rps?sebres
23.06.2015 23:34-1Всего 250?! Вы хоть раз такую нагрузку симулировали?
А именно воссоздадим наиболее тяжелые условия, заставив NGINX выполнять смесь блокирующих и неблокирующих чтений, когда проблема блокировок на обращениях к диску проявит себя в полной мере.
Вы через строчку читаете?
И пока дисковая подсистема делает свою работу как может, обслуживая наш “паразитный” трафик с первой машины, NGINX использует оставшиеся ресурсы процессора и пропускную способность сети, чтобы обслужить второго клиента из памяти.
Грубо говоря, есть огромный disk load (паразитный ли нет, есть не суть важно). Кэш вымывается, скорость чтения падает и т.д. Но из за того что имеем теперь пул потоков, а не один воркер, этот пул может отдать в 31 раз больше (т.е. целых 250 вместо всего 8 rps) например то, что еще или уже лежит в памяти.DjOnline
24.06.2015 02:04Я так и не понял, кто следит за тем, чтобы эти вот эти небольшие данные всегда лежали в памяти и не вымавались оттуда, несмотря на огромный фоновый disk load?
Можно ли например на location с сотнями тысяч картинок включить aio threads, а для location со статическими файлами дизайна сайта, которые всегда должны быть в памяти и отдаваться максимально быстро, не включать aio threads, не теряя в этом случае скорость на помещение задания в очередь?
Nginx с aio threads теперь так же быстр например для тех же фотографий, как решение elliptics от yandex или backpack от habrahabr.ru/post/184652?VBart Автор
24.06.2015 12:35Я так и не понял, кто следит за тем, чтобы эти вот эти небольшие данные всегда лежали в памяти и не вымавались оттуда, несмотря на огромный фоновый disk load?
Этим занимается операционная система. Если к данным регулярно обращаются, то они всегда всплывают наверх очереди в кэше страниц и не успевают из него вымываться. Пулы потоков тут не причем.
Можно ли например на location с сотнями тысяч картинок включить aio threads, а для location со статическими файлами дизайна сайта, которые всегда должны быть в памяти и отдаваться максимально быстро, не включать aio threads, не теряя в этом случае скорость на помещение задания в очередь?
Можно.
VBart Автор
24.06.2015 00:27+1250rps по 4 мегабайта каждый — это чуть менее 1 гигабайта в секунду или ~8.4 гигабит в секунду. Поскольку данные запрашивались по 10 гигабитной сети с двух клиентов, то это просто та эффективная полоса, которая осталась свободной для запросов со второй машины, создающей тестовую нагрузку к одному файлу. Как я и написал в статье, в данном случае nginx уперся в максимальную пропускную способность сети на тестовом стенде.
Именно поэтому 250rps.
Как явно было указано, wrk со второй машины всегда получает данные из памяти. Благодаря этому он разогнался до ~8.4 гигабит и загрузил сеть по полной.
Читается ли данные в потоке или в основном процессе — никак не влият на то, будут данные отданы из кэша страниц или прочитанны с диска. Просто если бы мы знали заранее, что данные находятся в памяти, то мы бы могли прочитать их в основном процессе, что было бы немного более эффективно.
Эффективнее потому, что отправка задания в пул потоков требует дополнительных циклов процессора, взятия лока, помещения задания в очередь. Затем пул должен опять взять лок, забрать задание из очереди, прочитать или отправить наконец данные, после чего взять лок очереди завершенных заданий, поместить туда результат операции и уведомить основной процесс.
В случае, когда данные находятся в памяти, отправляя задание в поток nginx тратит больше ресурсов, чем если бы он выполнил чтение и отправку в рамках основного процесса. В данном тесте эти траты ничтожны по сравнению с выигрышем от избавления от блокировок на чтении с диска.
datacompboy
Погодите, а что, nginx не использует aio_* при общении с диском?!
VBart Автор
Я об этом писал в статье. На линукс все плохо. См. lse.sourceforge.net/io/aio.html — с тех пор не продвинулись.
aio_*() просто обертка над всем этим.
datacompboy
… вот вроде ж читал статью, а этот абзац как-то проглядел.
Спасибо! Шок, это по-нашему. Я использовал асинхронный ввод-вывод в ТойЧтоНельзяУпоминать — там, конечно, кода вагон, но работало весьма стабильно…
VBart Автор
Наверное я тут перепутал с libaio. То POSIX AIO, что сейчас в glibc — это тоже обертка, но уже над тредами и довольно примитивная, чтобы её использовать для серьезных задач.
isden
А вы не в курсе, под OSX тут как дело обстоит? Я сходу попробовал погуглить, но, видимо, т.к. я не совсем в теме, ничего полезного не нашлось :(
VBart Автор
OSX не серверная система. Не стоит пытаться использовать её в этом качестве, можно наступить на огромное количество различных граблей.
isden
Есть хостеры, которые продают серверы с OSX server.
VBart Автор
Что не отменяет написанного мной выше. =)
Мы поддерживаем OSX как платформу для разработки, поскольку многие программисты пользуются макбуками. Но граблей там порядочно. Вот из последнего, не так давно натыкались на ту же проблему, что и разработчик Rust: erickt.github.io/blog/2014/11/19/adventures-in-debugging-a-potential-osx-kernel-bug — банально баг в ядре, связанный с race-condition, который приводит к тому, что попытка записи в сокет может вызывать ошибку EPROTOTYPE, которую никто в этом месте не ожидает увидеть.
И подобного там достаточно, и подозреваю достаточно того, о чем еще неизвестно, но сразу повылезает при попытке использовать OSX под более-менее серьезной нагрузкой.
isden
Ну так то да, но сервера с OSX таки попадаются у клиентов.
Теперь есть еще один повод советовать сменить, спасибо :)