
Мы поговорим о восьми удобных изменениях, которые влияют на ваш повседневный код. Четыре изменения касаются самого языка, а ещё четыре — его стандартной библиотеки.
Вам также может быть интересна статья Десять возможностей C++11, которые должен использовать каждый C++ разработчик
Благодарности
Некоторые примеры я брал из докладов на конференциях Russian C++ User Group — за это огромное спасибо её организаторам и докладчикам! Я брал примеры из:
- Антон Полухин. C++17 (C++ SIBERIA 2016)
- Александр Фокин. C++17, который мы заслужили (C++ SIBERIA 2017)
1. Декомпозиция при объявлении (англ. structural bindings)
- используйте декомпозицию при объявлении переменных: auto [a, b, c] = std::tuple(32, "hello"s, 13.9)
- возвращайте из функции структуру или кортеж вместо присваивания out-параметров
Удобно декомпозировать std::pair, std::tuple и структуры с помощью нового синтаксиса:
#include <string>
struct BookInfo
{
std::string title; // In UTF-8
int yearPublished = 0;
};
BookInfo readBookInfo();
int main()
{
// Раскладываем поля структуры на переменные title и year, тип которых выведен автоматически
auto [title, year] = readBookInfo();
}В C++17 есть ограничения декомпозиции при объявлении:
- нельзя явно указывать типы декомпозируемых элементов
- нельзя использовать вложенную декомпозицию вида
auto [title, [header, content]] = ...
Декомпозиция при объявлении в принципе может раскладывать любой класс — достаточно один раз написать подсказку путём специализации tuple_element, tuple_size и get. Подробнее читайте в статье Adding C++17 structured bindings support to your classes (blog.tartanllama.xyz)
Декомпозиция при объявлении хорошо работает в контейнерах std::map<> и std::unordered_map<> со старым методом .insert() и двумя новыми методами :
- Метод try_emplace выполняет вставку тогда и только тогда, когда заданного ключа ещё нет в контейнере
- Если заданный ключ уже есть в контейнере, ничего не происходит: в частности, rvalue-значения не перемещаются
- Метод insert_or_assign выполняет либо вставку, либо присваивание значения существующего элемента
Пример декомпозиции с try_emplace и декомпозиции key-value при обходе map:
#include <string>
#include <map>
#include <cassert>
#include <iostream>
int main()
{
std::map<std::string, std::string> map;
auto [iterator1, succeed1] = map.try_emplace("key", "abc");
auto [iterator2, succeed2] = map.try_emplace("key", "cde");
auto [iterator3, succeed3] = map.try_emplace("another_key", "cde");
assert(succeed1);
assert(!succeed2);
assert(succeed3);
// Вы можете раскладывать key и value прямо в range-based for
for (auto&& [key, value] : map)
{
std::cout << key << ": " << value << "\n";
}
}2. Автоматический вывод параметров шаблонов
Ключевые правила:
- функции вида
std::make_pairбольше не нужны: смело пишите выраженияstd::pair{10, "hello"s}, компилятор сам выведет тип - шаблонные RAII вида
std::lock_guard<std::mutex> guard(mutex);станут короче:std::lock_guard guard(mutex); - функции
std::make_uniqueиstd::make_sharedпо-прежнему нужны
Вы можете создавать свои подсказки для автоматического вывода параметров шаблона: см. Automatic_deduction_guides
Интересная особенность: конструктор из initializer_list<> пропускается для списка из одного элемента. Для некоторых JSON библиотек (таких как json_spirit) это может оказаться фатальным. Не играйтесь с рекурсивными типами и контейнерами STL!
#include <vector>
#include <type_traits>
#include <cassert>
int main()
{
std::vector v{std::vector{1, 2}};
// Это vector<int>, а не vector<vector<int>>
static_assert(std::is_same_v<std::vector<int>, decltype(v)>);
// Размер равен двум
assert(v.size() == 2);
}3. Объявление вложенных пространств имён
Избегайте вложенности пространств имён, а если не избежать, то объявляйте их так:
namespace product::account::details
{
// ...ваши классы и функции...
}4. Атрибуты nodiscard, fallthrough, maybe_unused
Ключевые правила:
- завершайте все блоки case, кроме последнего, либо атрибутом
[[fallthrough]], либо инструкциейbreak; - используйте
[[nodiscard]]для функций, возвращающих код ошибки или владеющий указатель (неважно, умный или нет) - используйте
[[maybe_unused]]для переменных, которые нужны только для проверки в assert
Более подробно об атрибутах рассказано в статье Как пользоваться атрибутами из C++17. Здесь будут краткие выдержки.
В C++ приходится добавлять break после каждого case в конструкции switch, и об этом легко забыть даже опытному разработчику. На помощь приходит атрибут fallthrough, который можно приклеить к пустой инструкции. Фактически атрибут приклеивается к case, следующему за пустой инструкцией.
enum class option { A, B, C };
void choice(option value)
{
switch (value)
{
case option::A:
// ...
case option::B: // warning: unannotated fall-through between
// switch labels
// ...
[[fallthrough]];
case option::C: // no warning
// ...
break;
}
}Чтобы воспользоваться преимуществами атрибута, в GCC и Clang следует включит предупреждение -Wimplicit-fallthrough. После включения этой опции каждый case, не имеющий атрибута fallthrough, будет порождать предупреждение.
В проектах с высокими требованиями к производительности могут практиковать отказ от выброса исключений (по крайней мере в некоторых компонентах). В таких случаях об ошибке выполнения операции сообщает код возврата, возвращённый из функции. Однако, очень легко забыть проверить этот код.
[[nodiscard]] std::unique_ptr<Bitmap> LoadArrowBitmap() { /* ... */ }
void foo()
{
// warning: ignoring return value of function declared
// with warn_unused_result attribute
LoadArrowBitmap();
}Если вы используете, например, свой класс ошибок, то вы можете указать атрибут единожды в его объявлении.
class [[nodiscard]] error_code { /* ... */ };
error_code bar();
void foo()
{
// warning: ignoring return value of function declared
// with warn_unused_result attribute
bar();
}Иногда программисты создают переменную, используемую только в отладочной версии для хранения кода ошибки вызванной функции. Возможно, это просто ошибка дизайна кода, и возвращаемое значение следовало обрабатывать всегда. Тем не менее:
// ! старый код!
auto result = DoSystemCall();
(void)result; // гасим предупреждение об unused variable
assert(result >= 0);
// современный код
[[maybe_unused]] auto result = DoSystemCall();
assert(result >= 0);5. Класс string_view для параметров-строк
Правила:
- в параметрах всех функций и методов вместо
const string&старайтесь принимать невладеющийstring_viewпо значению
- возвращайте из функций и методов владеющий
string, как и раньше
- возвращайте из функций и методов владеющий
- будьте осторожны с возвратом string_view из функции: это может привести к проблеме висячих ссылок (англ. dangling pointers)
Подробнее о том, почему string_view лучше всего применять только для параметров, читайте в статье std::string_view конструируется из временных экземпляров строк
Класс string_view хорош тем, что он легко конструируется и из std::string и из const char* без дополнительного выделения памяти. А ещё он имеет поддержку constexpr и повторяет интерфейс std::string. Но есть минус: для string_view не гарантируется наличие нулевого символа на конце.
6. Классы optional и variant
Применение optional<> и variant<> настолько широко, что я даже не буду пытаться полностью описать их в этой статье. Ключевые правила:
- предпочитайте
optional<T>вместоunique_ptr<T>для композиции объекта T, время жизни которого короче времени жизни владельца
- для PIMPL используйте
unique_ptr<Impl>, потому что определение Impl скрыто в файле реализации класса
- для PIMPL используйте
- используйте тип variant вместо enum или полиморфных классов в ситуации, когда состояния, такие как состояние лицензии, не могут быть описаны константами enum из-за наличия дополнительных данных в каждом из состояний
- используйте тип variant вместо enum в ситуации, когда данные, такие как код ошибки в исключении, должны быть обработаны во всех вариантах, и неполная обработка вариантов должна приводить к ошибке компиляции
- используйте тип variant вместо any везде, где это возможно
- optional можно использовать для композиции объекта, время жизни которого короче времени жизни владельца
- не применяйте
optionalдля обработки ошибок: он не несёт никакой информации об ошибке
- для возврата значения либо ошибки можно написать свой класс
Expected<Value, Error>, основанный наboost::variant<...> - а можно не писать и взять готовый: github.com/martinmoene/expected-lite
- для возврата значения либо ошибки можно написать свой класс
Пример кода с optional:
// nullopt - это специальное значение типа nullopt_t, которое сбрасывает
// значение optional (аналогично nullptr для указателей)
std::optional<int> optValue = std::nullopt;
// ... инициализируем optValue ...
// забираем либо значение, либо -1
const int valueOrFallback = optValue.value_or(-1);- optional имеет
operator*иoperator->, а также удобный метод.value_or(const T &defaultValue) - optional имеет метод value, который, в отличие от
operator*, бросает исключениеstd::bad_optional_accessпри отсутствии значения - optional имеет операторы сравнения “==”, “!=”, “<”, “<=”, “>”, “>=”, при этом
std::nulloptменьше любого допустимого значения - optional имеет оператор явного преобразования в bool
Пример кода с variant: здесь мы используем variant для хранения одного из нескольких состояний в случае, когда разные состояния могут иметь разные данные
struct AnonymousUserState
{
};
struct TrialUserState
{
std::string userId;
std::string username;
};
struct SubscribedUserState
{
std::string userId;
std::string username;
Timestamp expirationDate;
LicenseType licenceType;
};
using UserState = std::variant<
AnonymousUserState,
TrialUserState,
SubscribedUserState
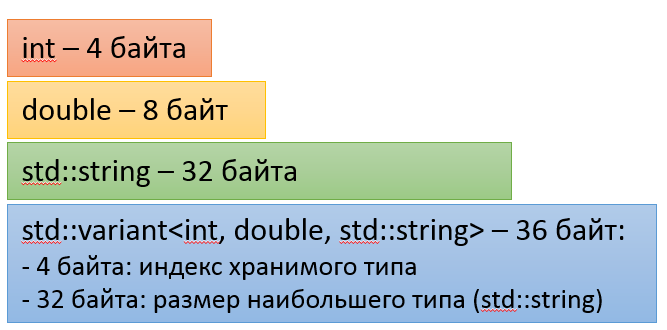
>;Преимущество variant в его подходе к управлению памяти: данные хранятся в полях значения типа variant без дополнительных выделений памяти. Это делает размер типа variant зависимым от типов, входящих в его состав. Так может выглядеть таблица размеров на 32-битных процессорах (но это неточно):
7. Используйте функции std::size, std::data, std::begin, std::end
- используйте std::size для измерения длины C-style массива
- эта функция работает с массивами и с контейнерами STL, но выдаст ошибку компиляции при попытке передать ей обычный указатель
- используйте std::data для получения изменяемого указателя начало строки, массива или
std::vector<>
- раньше для получения такого указателя использовали выражение
&text[0], но оно имеет неопределённое поведение на пустых строках
- раньше для получения такого указателя использовали выражение
Может быть, для манипуляций с байтами лучше опираться на библиотеку GSL (C++ Core Guidelines Support Library).
8. Используйте std::filesystem
Ключевые правила:
- передавайте
std::filesystem::pathвместо строк во всех параметрах, в которых подразумевается путь - будьте осторожны с функцией
canonical: возможно, вы имели ввиду метод lexically_normal
- canonical обрабатывает символические ссылки, а lexically_normal — нет
- canonical требует, чтобы путь существовал, а lexically_normal — нет
- на Windows попытка склеить почти-слишком-длинный путь и "..", а затем применить canonical может закончиться фиаско: Boost кинет исключение из-за слишком длинного пути к файлу
- будьте осторожны с функцией
relative: возможно, вы имели ввиду lexically_relative - старайтесь использовать noexcept-версии функций (с кодом ошибки), если ошибка для вас приемлема
- например, используйте noexcept версию функции exists, иначе вы получите исключения для некоторых сетевых путей!
- не используйте boost::filesystem
Чем плох boost::filesystem? Оказывается, у него есть несколько проблем дизайна:
- в Boost не решена проблема 2038 года; точнее, эту задачу переложили на time_t, но в Linux он до сих пор 32-битный!
- на ту тему есть отличная статья 2038: остался всего 21 год
- в STL-версии filesystem есть все средства для работы с кодировкам
Любой опытный программист знает о разнице в обработке путей между Windows и UNIX-системами:
- в Windows пути принимаются в виде UTF-16 строк (или даже UCS-2 строк, т.е. суррогатных пар в путях надо избегать!), часто используемый тип wchar_t представляет 2-байтный символ в кодировке UTF-16, а разделителем путей служит обратный слеш “\”
- в UNIX пути принимаются в виде UTF-8 строк, редко используемый wchar_t представляет 4-байтный символ в кодировке UCS32, а разделителем путей служит прямой слеш “/”
Конечно же filesystem абстрагируется от подобных различий и позволяет легко работать как с платформо-зависимыми строками, так и с универсальным UTF-8:
- для получения UTF-8 версии пути служит метод u8string
- для конструирования пути из UTF-8 строки служит свободная функция u8path
- не используйте конструктор
std::filesystem::pathизstd::string— на Windows конструктор считает входной кодировкой кодировку ОС!
Бонусное правило: прекратите переизобретать clamp, int_to_string и string_to_int
Функция std::clamp дополняет функции min и max. Она обрезает значение и сверху, и снизу. Аналогичная функция boost::clamp доступна в более ранних версиях C++.
Правило "не переизобретайте clamp" можно обобщить: в любом крупном проекте избегайте дублирования маленьких функции и выражений для округлений, обрезаний значений и т.п. — просто один раз добавьте это в свою библиотеку.
Аналогичное правило работает для задач обработки строк. У вас есть своя маленькая библиотека для строк и парсинга? В ней есть парсинг или форматирование чисел? Если есть, замените свою реализацию на вызовы to_chars и from_chars
Функции to_chars и from_chars поддерживают обработку ошибок. Они возвращают по два значения:
- первое имеет тип
char*илиconst char*соответственно и указывает на первый code unit (т.е. char или wchar_t), который не удалось обработать - второе имеет тип
std::error_codeи сообщает подробную информацию об ошибке, пригодную для выброса исключения std::system_error
Поскольку в прикладном коде способ реакции на ошибку может различаться, следует помещать вызовы to_chars и from_chars внутрь своих библиотек и утилитных классов.
#include <utility>
// конвертирует строку в число, в случае ошибки возвращает 0
// (в отличии от atoi, у которого местами есть неопределённое поведение)
template<class T>
T atoi_17(std::string_view str)
{
T res{};
std::from_chars(str.data(), str.data() + str.size(), res);
return res;
}Комментарии (43)

Kepp
01.12.2017 08:49+1шаблонные RAII вида std::lock_guard guard(mutex); станут короче: std::lock_guards guard(mutex);
точно короче?

eao197
01.12.2017 09:38Избегайте вложенности пространств имён
Это почему?
sergey_shambir Автор
02.12.2017 11:45Это почему?
Мне не хотелось бы, чтобы появление простого синтаксиса вложенных пространств имён привело к росту их числа. По моему опыту программисты часто злоупотребляют: пишут длинный многоуровневый namespace (30-40 символов) там, где конфликтов имён быть не может, и в итоге просто неудобно пользоваться.
Заголовки потом выглядят отвратительно.
При этом я ничего не имею противnamespace boost::detail, но дажеboost::algorithm::any_ofмне уже не нравится.
Но вы можете считать это предвзятым мнением автора =)
P.S. ещё есть отличное правило — каждая строка в коде не длиннее 80 (100, 120) строк. Вложенные пространства имён норовят его нарушить, а вводить постоянно синонимы — в cpp-файлах неудобно, в заголовках неприемлемо.
eao197
02.12.2017 11:57Но вы можете считать это предвзятым мнением автора =)
Именно таким его и остается считать. Если остальные нововведения вполне хорошо объясняются с технической точки зрения и можно наглядно показать, что это ведет к тем или иным выгодам (как в понятности кода и сокращению пространства для ошибок, так и в его эффективности), то данное утверждение является вкусовщиной, не более того.
а вводить постоянно синонимы — в cpp-файлах неудобно, в заголовках неприемлемо.
Еще одно предвзятое мнение автора.


Sklott
01.12.2017 10:08висячих ссылок (англ. dangling pointers)
Так висячии ссылки или таки висячии указатели?
dr_begemot
01.12.2017 11:27Вообще-то отсутствие break в некоторых case это такая фича — таким образом можно выполнять несколько case следующих друг за другом (как правило ограничиваются двумя).

ainoneko
01.12.2017 11:36+1В том-то и смысл: явно указать, что это фича (с помощью [[fallthrough]]), а не забытый break.
(Как дополнительные скобки при присваивании в условии.)
hdfan2
01.12.2017 13:54Это не фича, а сплошной геморрой. Пользовался я ей два-три раза (и то вставлял комментарий, что break тут не нужен), а вот сколько багов из-за неё огрёб — не сосчитать. Вообще, switch — одна из самых плохо продуманных конструкций в c\c++. Лучше было бы сделать неявный break (ну а если нужно продолжение выполнения на след. ветке, пиши goto) и новый скоуп для каждой ветки. Ну и swich по любым типам (скажем, по строке), но это уже совсем мечты.

kITerE
01.12.2017 11:28for (auto&& [key, value] : map)
Опечатка или какая-то фича, неподдерживаемая MS'ом? webcompiler.cloudapp.net, 19.12.25715.0 (x86). Last updated: Sep 25, 2017:
Compiled with /std:c++17 /EHsc /nologo /W4 main.cpp main.cpp(18): error C2440: 'initializing': cannot convert from 'std::pair<const _Kty,_Ty>' to 'std::pair<const _Kty,_Ty> &&' with [ _Kty=std::string, _Ty=std::string ] main.cpp(18): note: You cannot bind an lvalue to an rvalue reference```FoxCanFly
01.12.2017 13:51На нормальных компиляторах все нормально godbolt.org/g/PsgD4u
kITerE
01.12.2017 14:26А в чем соль использования в этом месте rvalue reference? Почему не const auto &?
stack_trace
01.12.2017 15:35Это perfect forwarding. Почитать можно, например, здесь — https://eli.thegreenplace.net/2014/perfect-forwarding-and-universal-references-in-c/
masterspline
01.12.2017 20:32Rvalue reference там, потому что это копи-паста из доклада, в котором сам докладчик толком не помнит, почему там rvalue reference. Однако, это более универсальный метод. Не уверен, что там идеальная передача, скорее просто создание именованной ссылки.
Суть в том, что rvalue reference с именем ведет себя как lvalue (или по-русски правая ссылка с именем является левым значением), но при этом правая ссылка может привязываться как к lvalue, так и rvalue. Это такая всеядная ссылка, которая дальше будет передаваться как lvalue. Если ": map" из разыменования итератора будет возвращать не ссылку, а rvalue ссылку, то простая ссылка туда не привяжется, а правая ссылка сможет. Таким образом, если где-то создается именованная ссылка, там можно более универсально использовать rvalue ссылку (однако, это не относится к передаче аргументов в функцию, т.к. там кроме того, аргумент создает ссылку для использования в теле фукнции, он еще и показывает, как этот параметр в нее передается, поэтому в нешаблонную функцию с параметром типа T&& нельзя передать lvalue).
Про идеальную передачу (perfect forwarding) лучше читать тут: C++ Rvalue References Explained. Только нужно учесть, что название «Универсальные ссылки» признано устаревшим, вместо него используется «Передающая ссылка» (forwarding reference), хотя даже не все главы комитетов по стандартизации C++ про это знают.
Немного про rvalue reference#include <iostream> template<typename T> class TD; // если его инстанциировать, то компилятор с сообщении об ошибке покажет переданный тип void test_ref( int& value ) // можно const int& { std::cout << "& " << value << "\n"; } void test_ref( int&& value ) { // TD<decltype(value)> t; std::cout << "&& " << value << "\n"; test_ref( value ); // Не верь глазам своим, value - это lvalue с типом int&& } int main() { int&& super_ref = 10; // Не верь глазам своим, super_ref - это lvalue типа int&& //TD<decltype(super_ref)> t; test_ref( super_ref ); // вызовется void test_ref( int& value ) int ar[] = {1,2,3}; for( auto&& el : ar ) { //TD<decltype(el)> t; test_ref( el ); // передача как lvalue, правда и тип выведется int& } // Вот если бы кто-то вернул rvalue reference без создания имени, вот тогда будет rvalue test_ref( std::move( super_ref ) ); // rvalue reference с именем всегда lvalue, даже если это последняя инструкция // в функции и дальше ссылка уничтожится, т.е. ее содержимое можно перемещать // даже в этом случае перемещения не будет return 0; }
tangro
01.12.2017 11:42Но есть минус: для string_view не гарантируется наличие нулевого символа на конце
Я так уже и вижу тысячи разных багов, которые тут могут возникнуть.stack_trace
01.12.2017 11:56Так для
std::stringтоже не гарантируется же. В чём принципиальная разница?
MooNDeaR
01.12.2017 13:32возможность вызвать c_str()?
stack_trace
01.12.2017 15:44Ну да, не будет этот класс совместим с частью сишных функций, хотя про тысячи багов это вы, конечно, преувеличили. Плюсовые функции не ожидают 0 в конце строки, проблемы могут возникнуть только с некоторыми сишными функциями, с которыми в любом случае надо быть осторожным, при работе из плюсов. Очевидно, что
string_viewпросто абстракция над парой(const char* data, size_t len), так что по другому и быть не могло.
stack_trace
01.12.2017 15:47Сама необходимость явно вызывать
c_str()означает, что пользователь должен знать об этом ограничении, чтобы его невелировать. Отсутствиеc_str()уstring_viewбудет ему намекать, что с этим классом так делать нельзя. В общем, не выглядет для меня серьезной проблемой.tangro
01.12.2017 15:50Так у него ещё и c_str() нету? Как им пользоваться вообще? В 9 случаях из 10 получается удобнее иметь const& string.
stack_trace
01.12.2017 16:25Вопрос не в удобстве а в быстродействии. Если вы на место
std::srting&передадитеconst char*произойдёт неявное копирование с выделением памяти в хипе. Здесь — не произойдёт. Если вам нужна 0-терминированная строка, вы всегда можете скопироватьstring_viewвstringявно.tangro
01.12.2017 18:38-1Получается выбор между быстродействием и удобством+безопасностью. Быстродействие в таком выборе скорее всего проиграет, тем более, что тот, кто во всех этих строках ищет быстродействия — вообще будет использовать голые С-строки без всяких обёрток.
stack_trace
01.12.2017 19:22+1Отдавать сишным функциям указатели на внутренности плюсовых классов всегда было небезопасно, так что тут ничего не поменяется. Что касается того, чтобы писать используя С-строки — это намного менее безопасно и удобно. Пример типичных компонентов, где
string_viewможет дать большой прирост производительности — различные парсеры, которым накладно выделять память, каждый раз, когда они хотят отдать пользователю токен.
masterspline
01.12.2017 20:42Есть метод data(), который возвращает то же, что и c_str(). При этом не будет возможности просто поменять тип на std::string_view уже существующей переменной или аргумента функции типа const std::string&, с которыми работают через c_str(), чтобы при этом все продолжило работать. Упадет при компиляции с сообщением, что нет метода c_str().
MooNDeaR
05.12.2017 06:15Метод data() вернет не то же самое. Он вернет строку без нуля в конце. А это уже совсем другая история.

qw1
02.12.2017 21:29Так у него ещё и c_str() нету? Как им пользоваться вообще? В 9 случаях из 10 получается удобнее иметь const& string.
У меня был один момент, когда я прямо мечтал о string_view.
XML-парсер, который на вход принимает XML вstd::stringи принимает класс-визитор, который получает оповещения о прохождении нод и атрибутов. Методы класса получали параметрconst std::string&с именем/значением ноды/атрибута. Если визитору было интересно значение, он себе его копировал в свойstd::string, или парсил вint.
Такое решение требовало создания новых строк на каждом атрибуте, а не каждый атрибут интересовал визиторы.string_viewтут был бы очень кстати (визитору всё равно, в каком виде приходят данные — string, char* или string_view).
XML-и были большие, десятки мегабайт.

bibmaster
02.12.2017 23:16На самом деле в c++ c_str практически нигде не нужен. Даже в тех местах где он нужен для передачи в C функции можно на входе принять string_view и написать небольшой checker, который, если нуля не будет, скинет всё в буферную строку и добавит его. Тогда заменив все параметры на string_view можно будет упоминание c_str в коде подозревать в преждевременной пессимизации.
bibmaster
02.12.2017 23:41Да даже литералы строковые лучше заворачивать в string_view, конструктор от указателя у них constexpr (спасибо char_traits), так что с временем инициализации то же самое, зато гарантирует что strlen более не понадобится (даже для extern литералов). Ещё прекрасный пример, кэширование каких то структур где строки имеют большую вероятность повтора, просто собрать все в какой то словарь (unordered_set) и хранить в виде string_view.
dendron
02.12.2017 01:41string_view — это просто костыль для изначально ущербного класса string.
Как же надоели чёртовы любители Boost! Варитесь в своём мирке, руки прочь от стандарта!

Error1024
02.12.2017 03:22Все сложнее и сложнее, все объемнее и объемнее.
Куча разных подходов, разных стилей, да даже в том, в каком стиле именуют стандартные классы, функции и т.д. разобраться не могут.
Зато модульность и рефлексию добавить уже двадцать лет как не могут.
Сделали бы форк — в одном месте хипстеры и Boost с прочим сахаром, а в другом настоящее расширение языка — в виде тех-же модулей.
Такое ощущение что боятся лезть под капот языку, или уже не знают как.
Error1024
02.12.2017 03:49Взглянул на новые атрибуты в C++17, и у меня возник вопрос, возможно, я слишком туп чтоб понять всю гениальность, возможно у вас есть идеи?
- maybe_unused
- nodiscard
- fallthrough
maybe_unused — через нижнее подчеркивание, чтобы разделить слова — логично.
nodiscard — одним словом, хотя слова «nodiscard» — не существует, ожидаемо наличие нижнего подчеркивания, но его нет.
Как я понимаю, эти атрибуты одновременно добавили, почему такая неконсистентность, что помешало?
DeadKnight
03.12.2017 15:31Вопрос, если я не хочу применять эти возможности, не смотря на то, что автор говорит, что я должен их применять, то я что теперь, не разработчик?

DrZlodberg
Вында очень давно понимает прямой, так что с этим пунктом можно не морочиться.
DarkEld3r
Если мне не изменяет память, то это всё-таки работает (работало?) не везде. Возможно, для "путей" реестра, хотя это, конечно, не совсем про filesystem.
mayorovp
Винда, конечно, понимает прямой — но входные данные скорее всего будут с обратным.