
От переводчика
Не так давно столкнулся с проблемой поиска набора слов в большом тексте. Разумеется главной проблемой стала производительность. Поиск готовых решений порождал больше вопросов, чем давал ответов. Часто я натыкался на примеры использования каких-то сторонних коробок или онлайн-сервисов. А мне в первую очередь нужно было простое и легкое решение, которое в дальнейшем дало бы мысли для реализации собственной утилиты.
Несколько недель назад вышла замечательная англоязычная статься об open-source python-библиотеки FlashText. Эта библиотека предоставляла быстрое работающее решение задачи поиска и замены ключевых слов в тексте.
Т.к. на русском материалов подобной тематики не так много, то я решил перевести эту статью на русский. Под катом вас ждет описание проблемы, разбор принципа работы библиотеки а так же примеры тестов производительности.
Начало
Основной задачей при работе с текстом является его очистка. Обычно этот процесс очень прост. К примеру нам нужно заменить словосочетание «Javascript» на «JavaScript». Но чаще нам нужно просто найти все упоминания словосочетания «Javascript» в тексте.
Задача очистки данных — это типичная задача для большинства проектов, работающих в области даталогии (науки о данных).
Даталогия начинается с очистки данных
Недавно я решал именно такую задачу. Я работаю исследователем в Belong.co и обработка естественного языка занимает половину моего времени.
Когда я начал использовать Word2Vec для анализа нашего текстового корпуса, то понял, что синонимы анализировались, как одно значение. К примеру термин «Javascripting» использовался вместо «Jacascript» и.т.д.
Чтобы решить эту проблему мне понадобилось очистить текст. Для этого я написал приложение, использующее регулярное выражение, которое заменяло все возможные синонимы словосочетания «Javascript» на его исходную форму. Однако это породило лишь новые проблемы.
Some people, when confronted with a problem, think
“I know, I’ll use regular expressions.” Now they have two problems.
Данную цитату первый раз я встретил тут и именно она характеризовала мой случай. Оказывается регулярное выражение выполняется относительно быстро, только в том случае, если число ключевых слов, которые необходимо найти и заменить в исходном тексте, не превышает лишь нескольких сотен. Но наш текстовый корпус состоял из более чем 3 миллионов документов и 20 тысяч ключевых слов.
Когда я оценил время, которое потребуется на замену всех ключевых слов, при помощи регулярных выражений, то оказалось что нам потребуется 5 дней для одного прогона нашего текстового корпуса.

Первое решение подобной проблему напрашивалось само собой: параллельный запуск нескольких процессов поиска и замены. Однако этот подход перестал быть эффективным, после того как увеличился объем данных. Теперь текстовый корпус состоял из десятков миллионов документов и сотен тысяч ключевых слов. Но я был уверен, что должно быть лучшее решение этой проблемы! И я начал искать его…
Я поспрашивал коллег в моем офисе, задал несколько вопросов на Stack Overflow. В результате у меня была пара неплохих предложений. Vinay Pandey, Suresh Lakshmanan
в обсуждение посоветовали попробовать алгоритм Ахо-Корасик и префиксное дерево.
Мои попытки найти готовое решение не увенчались успехом. Я не нашёл ни одной стоящей библиотеки. В результате я решил реализовать предложенные алгоритмы в контексте моей задачи. Таким образом и появился на свет FlashText.
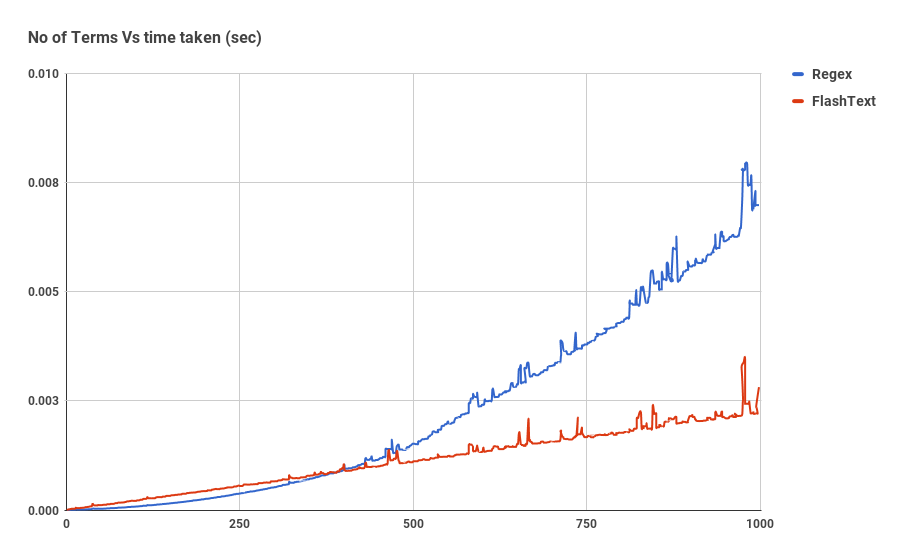
Прежде чем мы окунемся в детали реализации FlashText, давайте посмотрим как возросла скорость поиска.
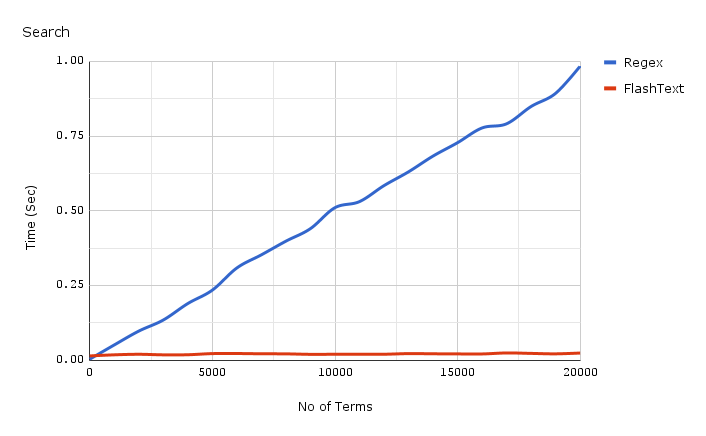
График показывает зависимость времени работы от числа ключевых слов, при выполнение операции поиска ключевых слов в одном документе. Как мы видим, время затраченное приложением использующим регулярное выражение линейно зависит от числа ключевых слов. Для FlashText такой зависимости не наблюдается.
FlashText уменьшил время одного прогона нашего текстового корпуса с 5 дней до 15 минут.

Ниже приведен график зависимости затраченного времени от числа ключевых слов при выполнении операции замены в одном документе.
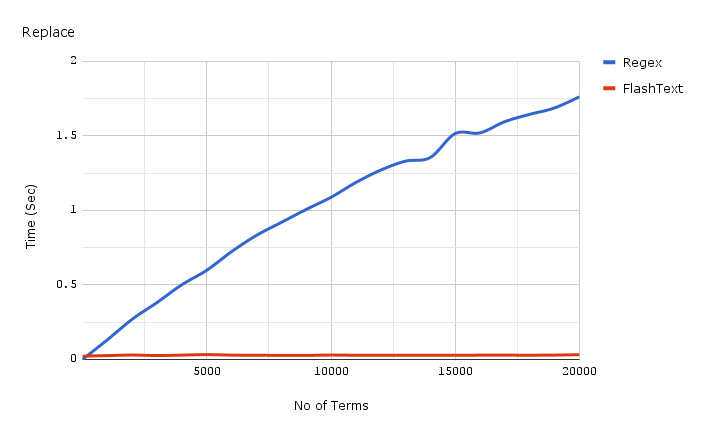
Код для получения бенчмарков, используемых для графиков, представленных выше можно найти здесь, а сами бенчмарки здесь.
Так что же такое FlashText ?
FlashText это небольшая open-source Python-библиотека, которая выложена на GitHub. Она одинаково успешно справляется как с задачей поиска, так и задачей замены ключевых слов в текстовом документе.
Первым шагом при использовании FlashText является составление корпуса ключевых слов, который будет использоваться библиотекой для построения префиксного дерева. После чего на вход библиотеки подается текст для которого будет выполнятся процедура поиска или замены.
При замене FlashText создаст новую строку с замененными ключевыми словами. При поиске библиотека вернёт список ключевых слов, найденных во входной строке. В обоих случаях результат будет получен за один проход входной строки.
В twitter уже появились первые положительные отзывы от счастливых пользователей:
Почему FlashText настолько быстрее ?
Давайте рассмотрим пример работы. Пусть у нас есть текст состоящий из трех слов:
I like Python и корпус ключевых слов, состоящий из 4 слов: { Python, Java, J2ee, Ruby }.Если мы будем проверять наличие каждого ключевого слова из корпуса в исходном тексте, то у нас будет 4 итерации поиска:
is 'Python' in sentence?
is 'Java' in sentence?
...
Из псевдокода мы видим, что если список ключевых слов будет состоять из n элементов, то нам понадобиться n итераций.
Но мы можем поступить наоборот: проверять существование каждого слова из исходного текста в корпусе ключевых слов.
is 'I' in corpus?
is 'like' in corpus?
is 'python' in corpus?
Если предложение состоит из m слов, то у нас будет m итераций. Общее время выполнения операций будет прямо пропорционально зависеть от числа слов в тексте. Стоит отметить, что поиск слова в корпусе ключевых слов будет выполняться быстрее, чем поиск ключевого слова в тексте, т.к. корпус ключевых слов представляет из себя словарь.
В основе FlashText лежит второй подход. В его реализации так же использованы алгоритм Ахо-Корасик и префиксное дерево.
Алгоритм работы следующий:
Вначале создается префиксное дерево для корпуса ключевых слов. Оно будет выглядеть так:
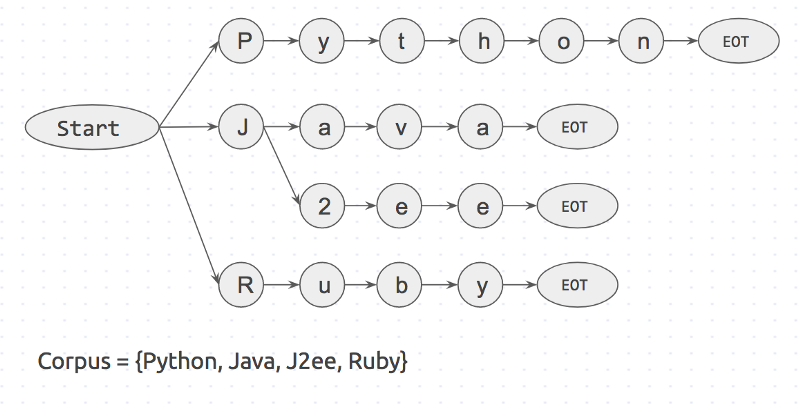
«Start» и «EOT» представляют из себя границы слов: пробел, новая строка и т.д. Ключевое слово будет совпадать с входным значением, только в том случае если слово имеет пограничные символы с обоих сторон. Такой подход исключит ошибочные совпадения, такие как «apple» и «pineapple».
Далее рассмотрим пример. Возьмем строку
I like Python и начнем поэлементный поиск в ней ключевых слов.Step 1: is <start>I<EOT> in dictionary? No
Step 2: is <start>like<EOT> in dictionary? No
Step 3: is <start>Python<EOT> in dictionary? Yes
Ниже представлено префиксное дерево для шага 3.
is <start>Python<EOT> in dictionary? Yes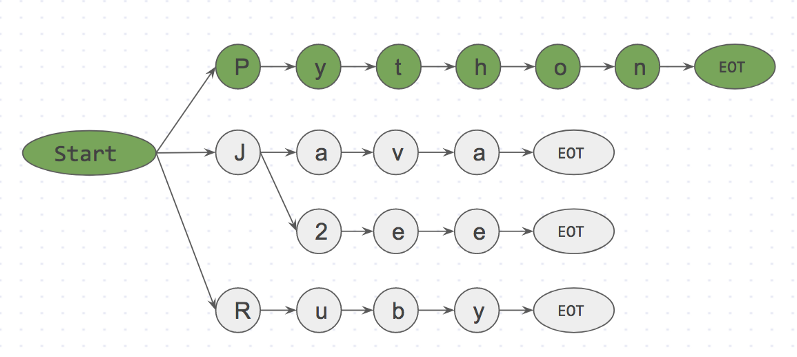
Благодаря такому подходу мы можем уже на первом символе отбросить like<EOT/>, потому что символ
i не расположен рядом с start. Таким образом мы практически мгновенно можем откинуть слова, которые не входят в корпус и не тратить на них время.Алгоритм FlashText будет анализировать символы входной строки
I like Python, в то время как корпус ключевых слов может иметь любые размеры. Размер корпуса корпус ключевых слов никак не скажется на быстродействие алгоритма. Это и есть основной секрет алгоритма FlashText.Когда вам нужно использовать FlashText ?
Всё очень просто: как только размер корпуса ключевых слов становится больше 500, то появляется этот график.
Однако стоит отметить, что Regex, в отличие от FlashText, может искать в исходной строке специальные символы такие как
^,$,*,\d,, которые не поддерживаются алгоритмом FlashText. То есть включать в корпус ключевых слов элемент word\dvec не стоит, а вот с элементом word2vec всё отработает отлично.Как запустить FlashText для поиска ключевых слов
# pip install flashtext
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
# ['New York', 'Bay Area']
Тоже самое на GitHub
Как запустить FlashText для замены ключевых слов
В общем то это была основная задача ради которой разрабатывался FlashText. У нас это используется для очистки данных перед обработкой.
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
# 'I love New York and NCR region.'
Тоже самое на GitHub
Если у вас есть коллеги которые работают с анализом тестовых данных, распознаванием упоминаний сущностей, обработкой естественного языка или Word2vec, то прошу поделиться этой статьей с ними.
Эта библиотека оказалась очень полезной для нас и я уверен, что она сможет пригодиться кому-нибудь ещё.
Получилось длинно. Спасибо, что дочитали.
Комментарии (72)

arty
05.12.2017 01:13а какой результат показал сложный префиксный регексп типа такого?
/\b(?:Python|Ruby|(?:J(?:ava|2ee)))/

rznELVIS Автор
05.12.2017 01:20arty К сожалению немного не понял вопрос. Если вы имеете ввиду на сколько подобный Regex будет медленней чем простой (описанный в статье), то таких сравнений тут не проводилось.
Проблема была в том, что даже простой Regex уже выполнялся неприемлемо долго.arty
05.12.2017 01:31судя по коду на SO, вы каждый регексп прогоняли по отдельности по всему тексту. Конечно, это будет медленно. Я думаю, что если сделать сложный регексп типа приведённого мной в качестве примера, и прогнать его по тексту один раз, то это будет быстро. Заодно можно сохранить возможность находить спецсимволы и нечувствительность к регистру.
arty
05.12.2017 01:41кстати, вполне может оказаться, что реализация регекспов в языке сама будет составлять префиксное дерево, и тогда можно будет обойтись банальным:
/\b(Ruby|Python|Java|J2ee)/
rznELVIS Автор
05.12.2017 01:47хммм… такой вариант не изучался. Стоит попробовать. На мой взгляд если Regex сам создает префиксное дерево, то это уже не оптимизация а low code development какой-то)) Когда раньше разбирался с принципом работы и выполнения Regex то всё было намного проще (рекурсия и всё). Хотя по тестам производительности, которые делал раньше у меня не было ощущения что там что-то большее
arty
05.12.2017 01:48+1ну не знаю, если есть готовый и простой в использовании инструмент, то почему его не применить? зачем то же самое переписывать самостоятельно?
rznELVIS Автор
05.12.2017 01:51Если есть. Пока мы лишь предполагаем. Ваш вариант не опробовался. Тут ещё задача сгенерировать валидный Regex из 100k ключевых слов. Представляю как он будет выглядеть
arty
05.12.2017 01:53+1ну простой вариант: new RegExp(`\\b(${replacements.join('|')})`)
если же я ошибаюсь в предположении, что реализация сама строит префиксное дерево, то всё равно не сильно сложно

DenVdmj
05.12.2017 05:57На хабре когда-то публиковался готовый java-код для подобной оптимизации регулярок: habrahabr.ru/post/117177. Я его переписывал на javascript для себя codepen.io/DenVdmj/full/dmpAL

Regis
05.12.2017 02:00То, что вы предлагаете — это уж точно не «готовый и простой в использовании инструмент», так как построить регексп, соответствующий по структуре префиксному дереву — это даже чуточку сложнее, чем строить само префиксное дерево. Больше похоже на предложение забивать гвозди «простой в использовании» микроскопом :)
И это при том, что пока что нет гарантий, что такой регексп в конкретной реализации будет работать эффективно.arty
05.12.2017 02:06как я сказал выше, если реализация регулярных выражений сама строит префиксное дерево, то это готовый инструмент
предположим, она этого не делает. В таком случае у автора был выбор: написать с нуля свою библиотеку, или же взять готовую библиотеку построения префиксных деревьев и сконвертировать её выдачу в регексп. Второй вариант мне кажется правильнее.
сейчас, когда автор уже написал свою библиотеку, можно или использовать её ограниченные возможности, или же потрудиться чуть больше, но получить полные возможности регекспов.
Regis
05.12.2017 02:20В таком случае у автора был выбор: написать с нуля свою библиотеку, или же взять готовую библиотеку построения префиксных деревьев и сконвертировать её выдачу в регексп. Второй вариант мне кажется правильнее.
Чем же вам не угодил самый логичный вариант — выполнить поиск с помощью этого самого префиксного дерева? Зачем префиксное дерево конвертировать в регексп, а потом из регекспа обратно в перфиксное дерево?arty
05.12.2017 02:23тем, что встроенная реализация языка наверняка оптимизирована гораздо лучше, чем то, что напишу я. А в случае питона она наверняка будет ещё и не на байткоде, а на си, что ускорит её ещё больше.
Regis
05.12.2017 02:35встроенная реализация языка наверняка оптимизирована гораздо лучше, чем то, что напишу я
Очень распространенное заблуждение. «Если что-то есть в стандартной либе, то оно там жутко заоптимизировано под все случаи жизни». Если у вас более специализированное решение «заточенное» под конкретный сценарий, то очень часто можно получить огромную прибавку в производительности. Особенно если решение имеет лучшую оценку сложности.
А в случае питона она наверняка будет ещё и не на байткоде, а на си, что ускорит её ещё больше.
В случае с питоном — может быть. Но на самом деле не обязательно: есть же всякие PyPy и прочие.arty
05.12.2017 02:42Очень распространенное заблуждение.
Иногда эта позиция бывает ошибочна, но это не повод называть её заблуждением :) Для большинства ситуаций она всё-таки справедлива.
решение имеет лучшую оценку сложности
в данном случае оценка сложности одинакова, потому что алгоритм один и тот же: сравнение строки с префиксным деревом — на регекспе или на питоне
не обязательно: есть же всякие PyPy и прочие
есть, но не всегда используются, поэтому в среднем ускорение всё равно будет
Regis
05.12.2017 03:01в данном случае оценка сложности одинакова
Почему вы уверены, что в случае с регекспом там будет такая же сложность? Ведь регекспу нужно уметь и с другими сценариями работать. Там почти наверняка будет не просто префиксное дерево (если вообще оно), а множество дополнительных проверок, которые в данном случае будут работать вхолостую.arty
05.12.2017 10:58потому что регексп не магия, какие проверки в него напишешь, те и будут делаться. Поставил флаг i — будет проверка без учёта регистра, а не поставил — не будет её.

GrimMaple
05.12.2017 03:47как я сказал выше, если реализация регулярных выражений сама строит префиксное дерево, то это готовый инструмент
Может, но не обязана. В классическом понимании регулярки вообще должны быть детерменированными, соответственно реализации алгоритмов будут сильно плясать от языка к языку, и уж точно префиксное дерево вам никто гарантировать не может.
тем, что встроенная реализация языка наверняка оптимизирована гораздо лучше, чем то, что напишу я.
А вы попробуйте прокачать скилл и писать крутые штуки на уровне крутых прогеров, почему бы и нет ;)
в данном случае оценка сложности одинакова, потому что алгоритм один и тот же: сравнение строки с префиксным деревом — на регекспе или на питоне
Не уверен, что это верно. Насколько мне известно, Python использует рекурсивный backtracking, откуда растет экспоненциальная сложность.
Вот тут есть хороший материал по поводу регулярок.arty
05.12.2017 11:06Может, но не обязана.
ну так я и написал "если". Проверить этот вариант — дело нескольких минут, но это не было сделано.
А вы попробуйте прокачать скилл и писать крутые штуки на уровне крутых прогеров, почему бы и нет ;)
потому что малы шансы того, что я один напишу код лучше, чем группа программистов, работавшая над той же задачей в реализации языка. Кроме того, если я учусь программировать, решая какую-то задачу, я не буду предлагать учебный проект в качестве библиотеки. А отношусь я так к квалификации автора потому, что за одну минуту ускорил его регекспы в два раза банальным улучшением.
Не уверен, что это верно. Насколько мне известно, Python использует рекурсивный backtracking, откуда растет экспоненциальная сложность.
согласен, это может оказаться неверным. Но это решение было бы сделать (или взять ещё одно готовое) быстрее, чем городить самому. А вот если бы после проверки оно оказалось ещё недостаточно быстрым, то имело бы смысл делать своё.

abusalimov
05.12.2017 03:37Интересно, я бы тоже ожидал аналогичную оптимизацию внутри самого движка regex'ов стандартной библиотеки, но тем не менее regex вида
\b(Ruby|Python|Java|J2ee)\bвсе равно сильно проигрывает FlashText (я использовал бенчмарк по ссылке из комментариев к оригинальной статье).
С другой стороны, если задача ограничивается поиском ключевых слов, не содержащих пробелов внутри себя, то простой regex
\b\w+\bс заменойcompiled_re.sub(lambda m: rep.get(m.group(0), m.group(0)), story)(заменять вообще все слова; те, что неинтересны, заменять на самих себя) ожидаемо уделывает эту библиотеку раза в 2-3:
python ./flashtext_regex_timing_keyword_replace.py$ python ./flashtext_regex_timing_keyword_replace.py Count | FlashText | Regex ------------------------------- 1 | 0.00968 | 0.00412 | 1001 | 0.01066 | 0.00425 | 2001 | 0.01156 | 0.00418 | 3001 | 0.01201 | 0.00436 | 4001 | 0.01136 | 0.00436 | 5001 | 0.01133 | 0.00439 | 6001 | 0.01215 | 0.00444 | 7001 | 0.01196 | 0.00442 | 8001 | 0.01209 | 0.00445 | 9001 | 0.01218 | 0.00446 | 10001 | 0.01218 | 0.00451 | 11001 | 0.01230 | 0.00446 | 12001 | 0.01239 | 0.00452 | 13001 | 0.01263 | 0.00457 | 14001 | 0.01265 | 0.00458 | 15001 | 0.01308 | 0.00457 | 16001 | 0.01283 | 0.00451 | 17001 | 0.01301 | 0.00455 | 18001 | 0.01296 | 0.00457 | 19001 | 0.01303 | 0.00458 | 20001 | 0.01318 | 0.00462 |
aamonster
05.12.2017 09:41Вот! Тоже охренел, увидев это безобразие: у человека простая задача замены по словарю, а он деревья строит.

brickerino
05.12.2017 13:33В смысле деревья строит? Для поиска множества подстрок в строке стандартный алгоритм — Ахо-Корасик. Можно еще юзать алгоритм Укконена, если вам скорость построения дерева важна.
mayorovp
05.12.2017 13:38Алгоритм Укконена нужно юзать когда набор паттернов не известен заранее. И наоборот, алгоритм Ахо-Корасик подходит когда весь текст не известен заранее.
Что же до скорости построения дерева — обычно в задачах текст намного длиннее набора паттернов. В таких условиях алгоритм Укконена проигрывает как по времени так и по памяти.
aamonster
05.12.2017 14:36У него замена целых слов. Ему не надо искать вхождения с произвольной точки текста — только от границы слова до границы слова, тут никакие Ахо-Корасики и т.п. не нужны: выделил очередное слово, нашёл в словаре (хэш-таблица), заменил (точнее, отправил в выходной буфер или исходное слово, или подстановку), пошёл дальше.
mayorovp
05.12.2017 16:21У него замены цепочек слов. Тут простой поиск слова в словаре не подойдет.
Хотя трюк с предварительным разбиением на слова все еще можно использовать. Я думаю, алгоритм значительно ускорится если рассматривать каждое слово как символ.
arty
05.12.2017 11:08у него там в комментариях писали, что будто бы у Rust реализация регекспов крутая
впрочем, это неважно, всё равно я вначале предложил оптимизированный регексп на префиксном дереве
rznELVIS Автор
05.12.2017 01:43Теперь понял ваш вопрос! Вариант интересный, но не забывайте, что у нас 20k-100k ключевых слов. Подобный Regex будет весьма сложным. Насколько я помню принцип работы регулярных выражений из примеров в томике Страуструпа, то в их работе лежит рекурсивный принцип (могу ошибаться). А любая рекурсия это увеличенный расход памяти. При сложном Regex да и на большом объеме документа (а он большой) могла банально закончиться память.
P.S. Прогонял всё-таки не я, а автор. Обращаю внимание что это перевод. Я не могу присваивать себе заслуги автора :) Кстати автор оригинала (Vikash) очень коммуникабельный человек, если у вас будут интересовать более глубокие детали, то можете и его смело спрашивать. Мне он отвечал в течении нескольких часов.arty
05.12.2017 01:46100k слов даже по 100 символов это 10 мегабайт памяти, без учёта более коротких слов и «повторного использования» префиксов
посмотрю, что автору в исходной записи накомментировали

gdt
05.12.2017 07:40Рекурсивные алгоритмы разбора используются в качестве обучающих и для небольших объёмов данных, насколько мне известно, нормальные реализации всё-таки используют конечные автоматы.
mayorovp
05.12.2017 09:09Поправлю. Есть два разных разновидности языка регулярок: с возвратными ссылками и без них. По регулярке второго типа можно построить конечный автомат. По регулярке первого типа в общем случае автомат построить нельзя — а потому библиотеки которые поддерживают обратные ссылки обычно КА строить не умеют.
gdt
05.12.2017 09:13Поправлю. Есть такой тип конечных автоматов — ДКА с магазинной памятью (ДМПА), которые позволяют разбирать даже контекстно-свободные грамматики. Думаю, с регулярками с обратными ссылками такие автоматы тоже могут справиться.
mayorovp
05.12.2017 09:20Что-то мне кажется, что регулярка с обратными ссылками контекстно-зависима. По крайней мере, я не вижу способа представить
(a*)(b*)c\1+\2+в виде КС-грамматики.
PS ДМПА — это расширение КА а не их тип
gdt
05.12.2017 09:25Не хочу спорить о терминологии, как и разводить лишнюю полемику. См. Реализации
регулярных выражений.
Цитата:
NFA (англ. nondeterministic finite-state automata — недетерминированные конечные автоматы) используют жадный алгоритм отката, проверяя все возможные расширения регулярного выражения в определённом порядке и выбирая первое подходящее значение. NFA может обрабатывать подвыражения и обратные ссылки. Но из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы. Поскольку традиционный NFA принимает первое найденное соответствие, он может и не найти самое длинное из вхождений (этого требует стандарт POSIX, и существуют модификации NFA выполняющие это требование — GNU sed). Именно такой механизм регулярных выражений используется, например, в Perl, Tcl и .NET.
mayorovp
05.12.2017 09:47(комментарий был удален)
gdt
05.12.2017 09:53Как скажете.
Хочу, правда, отметить, чтоНо из-за алгоритма отката традиционный NFA может проверять одно и то же место несколько раз, что отрицательно сказывается на скорости работы.
, так что одного суждения по времени работы будет недостаточно. А ещё рекурсивный поиск обычно не используется не столько из-за времени работы, сколько из-за потребляемой памяти, так что замерьте ещё потребление памяти, раз уж берётесь за такое. Если оно тоже быстро растёт — тогда я с вами соглашусь.
Рекомендую ещё посмотреть, что пишет Microsoft про реализацию регулярных выражений.
А именно:
The .NET Framework regular expression engine is a backtracking regular expression matcher that incorporates a traditional Nondeterministic Finite Automaton (NFA) engine such as that used by Perl, Python, Emacs, and Tcl. This distinguishes it from faster, but more limited, pure regular expression Deterministic Finite Automaton (DFA) engines such as those found in awk, egrep, or lex. This also distinguishes it from standardized, but slower, POSIX NFAs.

slonopotamus
05.12.2017 14:26Ну тривиально же решается. Если в процессе компиляции регекса нашли в нём backreference — стройте backtracking автомат. Не нашли — стройте быстрый DFA.

middle
05.12.2017 15:48У DFA количество состояний может расти экспоненциально. Т.е. скомпилированное выражение может в итоге занять очень много памяти.
Впрочем, в случае NFA это же выражение займёт много памяти при выполнении разбора.

bibmaster
05.12.2017 08:52+1Если слова заменяются целиком, возможно hash словарь замен будет быстрее.
slonopotamus
05.12.2017 10:10is 'Python' in sentence?
is 'Java' in sentence?
...
Но регексы работают не так.
Вообще, без результатов профилировки решения на регексах статья бесполезна чуть менее чем полностью. Может он там на каждую операцию поиска компилирует регекс, вот и получил O(n) от количества термов.mayorovp
05.12.2017 10:28Регексы, может, работают и не так — но автор, видимо, их использовал именно так.
slonopotamus
05.12.2017 13:17Я теряюсь в догадках, как использовать регексы так чтобы был O(n)? Сделать по регексу на каждый из термов и ручками их перебирать? Тогда начерта вообще регексы, цикл из strstr по каждому из термов и даст O(n) от количества термов. Но регекс вида (term1|term2|term3|...term4) работает не так.
mayorovp
05.12.2017 13:22Сделать по регексу на каждый из термов и ручками их перебирать?
Если посмотреть вопрос автора на SO — будет видно что именно так он и сделал.
slonopotamus
05.12.2017 13:29Короче, автор просто не умеет пользоваться регексами. На фигню в его вопросе на SO вы уже указали, а в Код для получения бенчмарков, используемых для графиков, представленных выше можно найти здесь он таки действительно компилирует регекс на каждый из документов.
Статью закопать, автора отправить читать документацию.EviGL
05.12.2017 22:49Может я что-то путаю, но в коде по ссылке компилируется один регексп на каждый "запуск" теста (для разного количества кейвордов). Как раз через |.
compiled_re = re.compile("|".join(rep.keys()))
В вопросе на SO да, фигня, но в бенчмарке исправлено.

kogemrka
05.12.2017 10:12В основе FlashText лежит второй подход. В его реализации так же использованы алгоритм Ахо-Корасик и префиксное дерево.
Впервые вижу, чтобы классический алгоритм «из учебника» рекламировали с таким пиететом, мемасиками, графиками и приведениями цитат из твитера.
firk
05.12.2017 12:03php(python/ruby/perl/js)-кодеры открывают для себя мир почти нормального (нормальное будет кода этот код перепишут на си и он станет ещё в разы быстрее) программирования, всё норм
brickerino
05.12.2017 13:38Еще бы автор для себя мир гугла открыл. Готовую реализацию он найти не смог, написал велосипед.
Myotahapea.
bjornd
05.12.2017 12:58«Как я начал использовать индексы и сократил алгоритмическую сложность задачи с O(N) до O(1)». Нам это на первом курсе преподавали.

KvanTTT
05.12.2017 13:21+1А лексер на основе ANTLR не пробовали использовать? По идее он тоже должен быстро отрабатывать, правда придется вводить кучу ключевых слов в него и генерировать.
to_climb
05.12.2017 14:48pyahocorasick — и не нужно изобретать велосипед.
Кстати, в статье описано простое префиксное дерево, которое построит движок регулярных выражений, если добавить в него все альтернативы через ИЛИ. А Ахо-Корасик работает несколько сложнее: у него есть переходы между ветками, благодаря чему не нужно перезапускать поиск на каждом символе (или делать возвраты в переборе).EviGL
05.12.2017 23:11В комментариях автор пишет что пробовал, но не смог настроить поиск по целым словам. Если это таки возможно, автору бы точно пригодилось. Специализированная библиотека большей частью написанная на C явно будет быстрее.
mayorovp
06.12.2017 12:34Есть даже два варианта:
1. поставить спец. символ на границах каждого слова как в тексте, так и в ключевых словах;
2. предварительно разбить текст на слова, которые потом использовать вместо символов.
Laney1
05.12.2017 15:29какой-то "исследователь естественного языка" пишет статью о том, как он не знал про элементарные строковые алгоритмы, побежал со своей проблемой на stackoverflow и накодил велосипед. Офигеть исследователь, желаю удачи его стартапу.
… а, он индус. У них да, принято рассказывать миру о своем невежестве.

Zoolander
06.12.2017 10:28высокая коммуникабельность является стимулирующим фактором роста коммюнити
или, как говорили в древней Японии «для сегуна ценнее тысяча простых солдат, чем один искусный самурай»

zabr
06.12.2017 19:43возможно будет интересен этот проект: github.com/noprompt/frak, как раз про ваши тысячи слов.

AnterKan
08.12.2017 11:47Я сделяль тест на регулярах (правда в жаве, как жава кодер) с одинаковым кол-вом параметров (7 ключевых слов на входной док в 300 мегабайт)
flashtext 22 секунды
java регулярка: 5.2 секунды
Ну хоть результат один и тот же. По крайней мере работает правильно…rznELVIS Автор
08.12.2017 11:47а как ваша реализация отработает на 1000-10000 ключевых слов. В статье был график, который показывал, что до 500 ключевых слов Regex работает лучше
basilbasilbasil
Также можно разделить текст на (количество потоков cpu) кусков и гнать параллельно. Интересно, сколько это займёт времени?
rznELVIS Автор
что конкретно? Если вы про время, которое потребуется на обновление кода для поддержки многопоточности, то немного. Т.к. проще всего в каждый отдельный поток загонять поиск/замену по отдельному документу. Каждый поток будет работать только с одним документом. Остальные ему не нужны. Корпус ключевых слов можно шарить между потоками, так как он в процессе работы приложения не меняется.
А результаты работы поиска агрегировать,
А результат работы замены просто выгружать и сохранять в новый документ.
Сама задача довольно проста для распараллеливания.
basilbasilbasil
я просто из спортивного интереса посмотреть на тайминги.
Defersa
Скорее всего что то сравнимое с линейным увеличением производительности, как замечено выше эта задача очень хорошо распараллеливается.
Antervis
если узкое место — быстродействие диска, то распараллеливание может уменьшить производительность. Надо тестировать на конкретном железе