

Часть 1. Мониторинг инженерной инфраструктуры в дата-центре. Основные моменты.
Часть 2. Как устроен мониторинг энергоснабжения в дата-центре.
Часть 3. Мониторинг холодоснабжения на примере дата-центра NORD-4.
Часть 4. Сетевая инфраструктура: физическое оборудование.
Привет, Хабр! Меня зовут Алексей Багаев, я руководитель сетевого отдела в DataLine.
Сегодня я продолжу серию статей о мониторинге инфраструктуры наших дата-центров и расскажу о том, как у нас организован мониторинг сети. Это достаточно объемная тема, поэтому, чтобы избежать сумбура, я разделил ее на две статьи. В этой речь пойдет о мониторинге на физическом уровне, а в следующий раз рассмотрим логический уровень.
Сначала я опишу наш подход к мониторингу сети, а затем подробно расскажу о всех параметрах сетевого оборудования, которые мы отслеживаем.
Содержание:
Наш подход
Сеть мониторинга и мониторинг сети
Состояние сетевых хостов
Температурные показатели
Состояние вентиляторов в коммутаторах
Состояние модулей питания
Состояние портов
Состояние процессоров
Control Plane Policy: влияние трафика на загрузку процессора
Мониторинг оперативной памяти
Небольшой бонус
Наш подход
Наша практика «мониторинга всего» длится уже более пяти лет. В каких-то областях мы не изобретаем велосипед и действуем стандартными методами, а где-то, в силу специфики, прибегаем к своим решениям. В частности, это касается мониторинга логического уровня сети, но, как я сказал ранее, это тема уже будущей статьи.
В случае с опросом физического уровня сети всё достаточно просто. Система мониторинга сетевой инфраструктуры построена на базе Open-source инструментов Nagios и Cacti. На всякий случай напомню их различия: Nagios регистрирует события в реальном времени, а Cacti агрегирует статистику, строит графики и отслеживает динамику показателей в долгосрочной перспективе.
Состояние сетевого оборудования отслеживается через запросы по стандартному протоколу SNMP:
запрос сервер–агент: GetRequest и агент–сервер: Trap.
В ОС всего управляемого сетевого оборудования есть MIB-базы. Нужный OID объекта, как правило, мы находим с помощью команды SNMPWalk или с помощью инструмента MIB Browser. Вы можете пройти по этой ссылке на англоязычную ветку Reddit, в комментариях есть несколько толковых рекомендаций на эту тему.
Разумеется, оборудование периодически меняется и модернизируется, и мы дорабатываем систему мониторинга под новые задачи. Прежде чем вводить новый хост в продуктив, параллельно с тестированием мы добавляем этот хост в систему мониторинга и определяем список объектов, которые будем отслеживать.
Мы собираем основные метрики подключенного оборудования, из самого элементарного – это проверка на UP/DOWN.
В целом нас интересуют:
- внешние факторы (температура, питание и т.д);
- состояние портов (текущее состояние, доступность);
- состояние процессора;
- память;
- специфика «железа» в зависимости от типа оборудования.
Нельзя сказать, что какой-то узел важнее остальных. Продуктивная сеть – она и в Африке продуктивная. «Забитая» память или перегруженный процессор могут вызвать деградацию сети в целом и проблемы у клиента – в частности. Макрозадача в мониторинге сетевого железа – своевременная профилактика и устранение неисправностей раньше, чем они дадут о себе знать.
Сеть мониторинга и мониторинг сети
В мониторинге сети мы используем два способа доступа к оборудованию: in-band и out-of-band. Предпочтительнее для нас out-of-band: при такой схеме трафик системы мониторинга не идет по продуктивным линкам, которые используются для предоставления сервисов заказчикам.
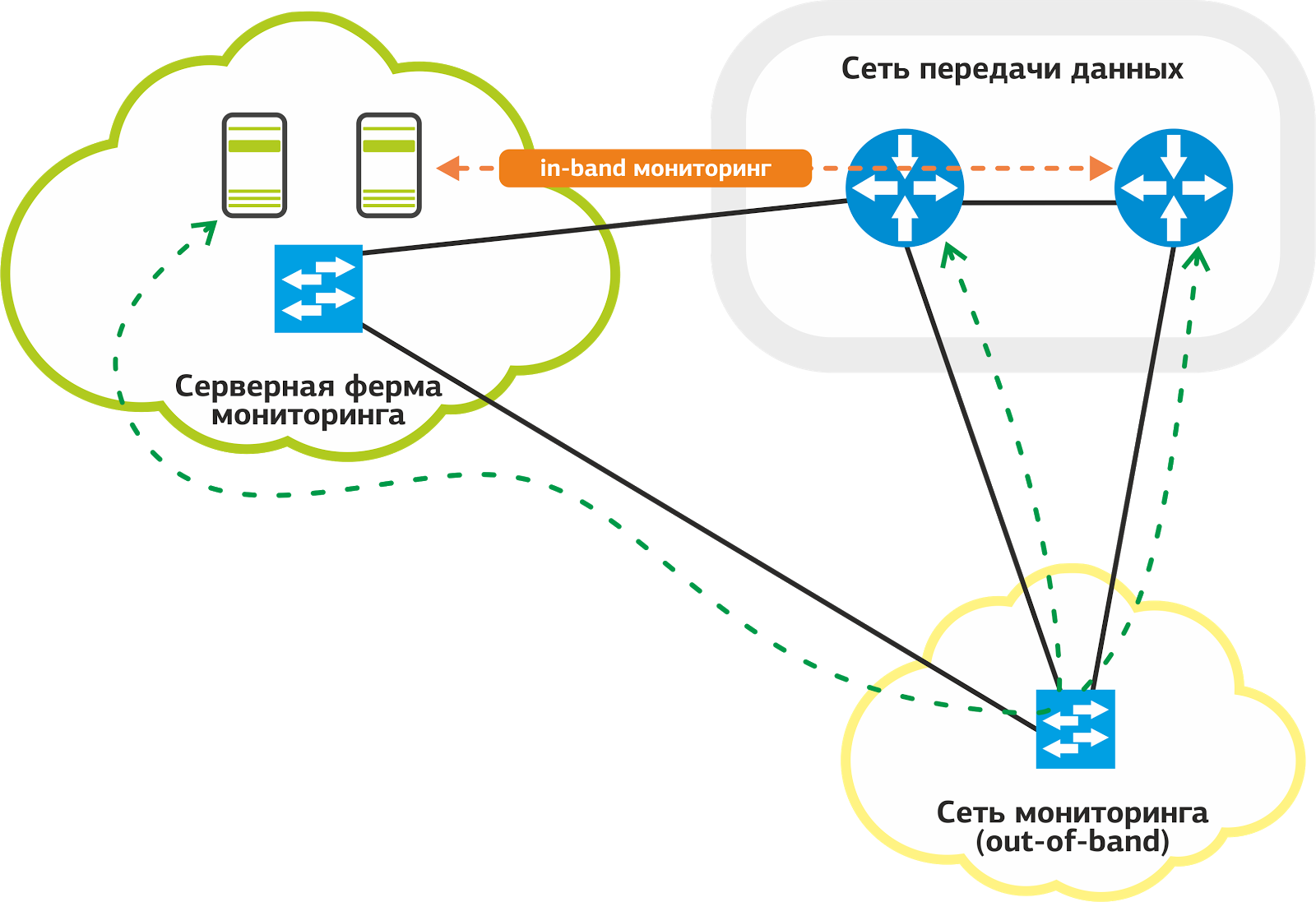
Наша сеть мониторинга.
Для мониторинга у нас есть специальная сеть: она подключена выделенными линками к портам на каждом сетевом хосте. Даже если на продуктивных линках возникнут проблемы, мониторинг будет работать без сбоев.
Часто бывает, что проблема на одном линке делает значительную часть сети недоступной для мониторинга. Это усложняет работу службы поддержки и тормозит процесс выявления неисправностей. Схема out-of-band решает эту проблему.
Не ко всем хостам удается подключить out-of-band, и в этих случаях мы используем in-band, когда трафик мониторинга идет вместе с продуктивным. Как ни странно, несмотря на явные недостатки этой схемы, у нее есть свое преимущество – надежность.
Продуктивные линки резервируются протоколами на уровне L2 и L3: при отказе основного линка трафик «переходит» на другой линк. Nagios на это может среагировать флапом сервисов, но служба поддержки останется при мониторинге.
Дальше пойду по порядку по всем узлам мониторинга физического сетевого оборудования.
Состояние сетевых хостов
Мы проверяем доступность хоста отправкой ICMP-запросов на его IP-адреса управления. Как правило, это выделенный IP в сети управления оборудованием.
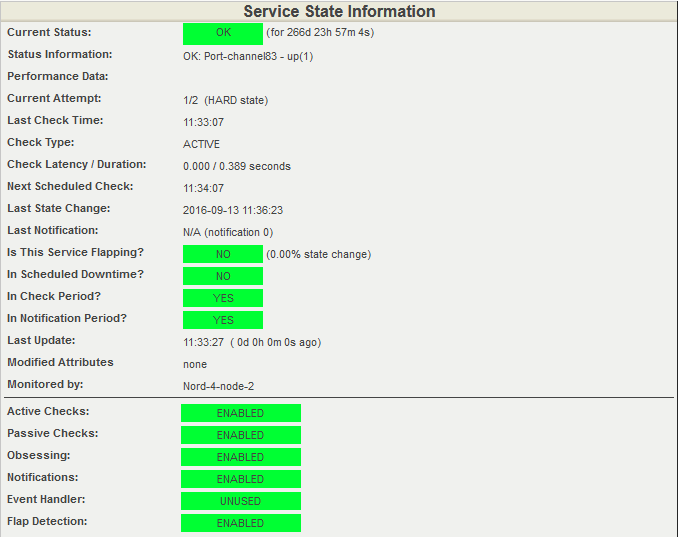
Раз в минуту хост проверяется запуском плагина check_ping для Nagios. Каждый вызов сопровождается отправкой четырех ICMP-запросов с интервалом в 1 секунду. На скриншоте ниже видно, что последняя проверка прошла с результатом в 0% потерь пакетов. Среднее время отклика RTA (round trip average) составило 2,47 миллисекунды. Это норма.
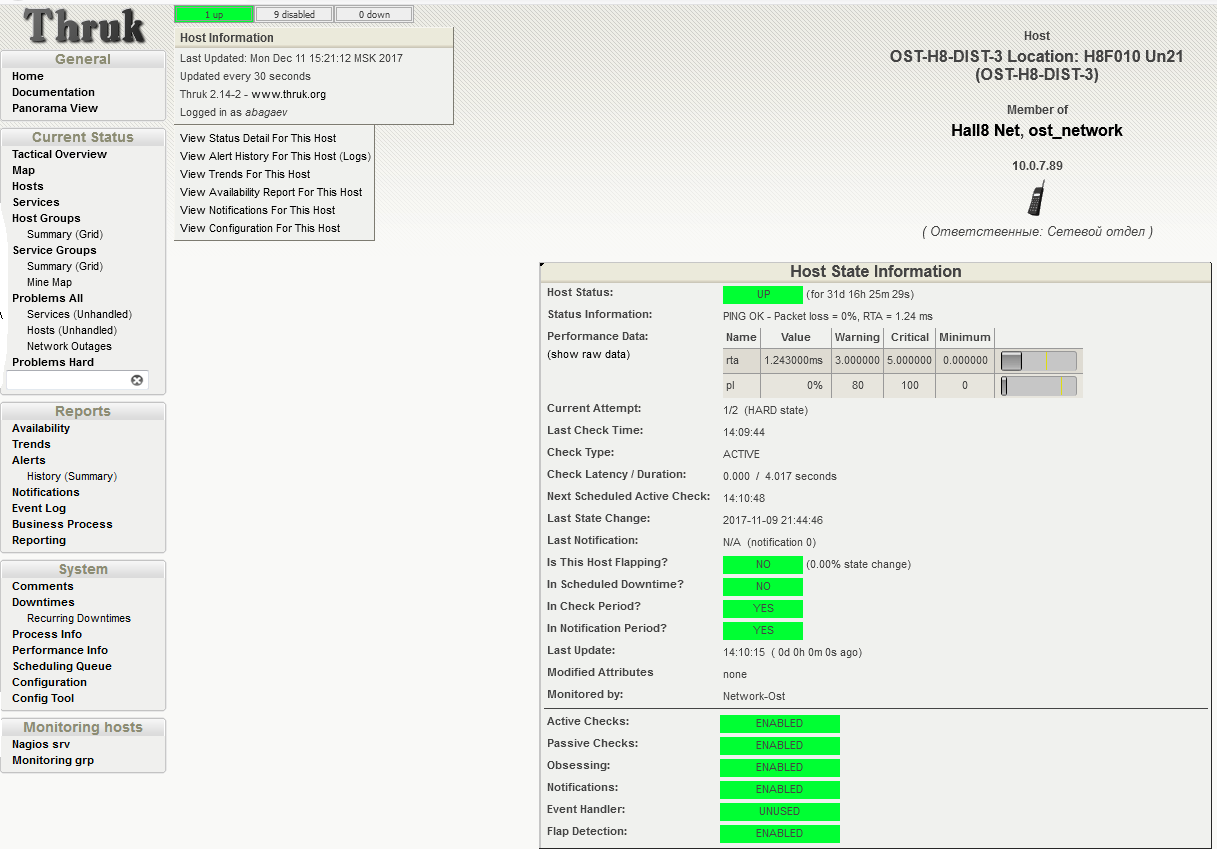
Проверка состояния хоста. Статус UP: 0% потерь пакетов, среднее время RTA 2,47 мс. UPD:
скриншот изменен, спасибо за правки Tortortor
Как мы понимаем, что возникла неисправность? Разумеется, поручить наблюдение за всеми цифрами простому человеку невозможно: инженеры отслеживают состояние оборудования в удобном интерфейсе Nagios. В нем уже заданы проверенные пороговые значения для срабатывания статусов WARNING (приближение к нежелательным показателям) и CRITICAL (критическое превышение порога, требуется вмешательство специалиста).
Внимательно посмотрим на таблицу Performance Data с предыдущего скриншота: колонка Value содержит текущее значение параметра потери пакетов (Packet loss). WARNING выдается при достижении 80% потерянных пакетов от общего количества отправленных, CRITICAL – при 100. Показатель RTA (Round Trip Average), равный 2,47 мс, означает среднее время отклика. Предупреждение будет выдано при достижении 3 мс, критическое пороговое значение установлено на 5 мс.

На этом же экране можно получить краткую сводку по следующим показателям:
- Next Scheduled Active Check – время следующей проверки;
- Last State Change – когда в последний раз менялось состояние;
- Last Notification – последнее выданное системой оповещение;
- Is Scheduled Downtime – запланировано ли время неактивности.
Температурные показатели
Недавно мои коллеги рассказывали о мониторинге холодоснабжения в машинных залах, где упомянули, что на каждый холодный коридор приходится по три температурных датчика. Эти датчики снимают общие показатели по коридору и позволяют судить о работе самой охлаждающей системы.
Для мониторинга сетевой инфраструктуры нужно знать показания температурных датчиков с каждой единицы оборудования. Это позволяет выявлять и устранять не только возможные перегревы хостов, но и определять на ранней стадии локальные перегревы стоек.
Для получения статуса устройства мы отправляем запрос вида snmpwalk <параметры> <устройство> | grep <что ищем> и получаем список всех OID по заданным фильтрам.
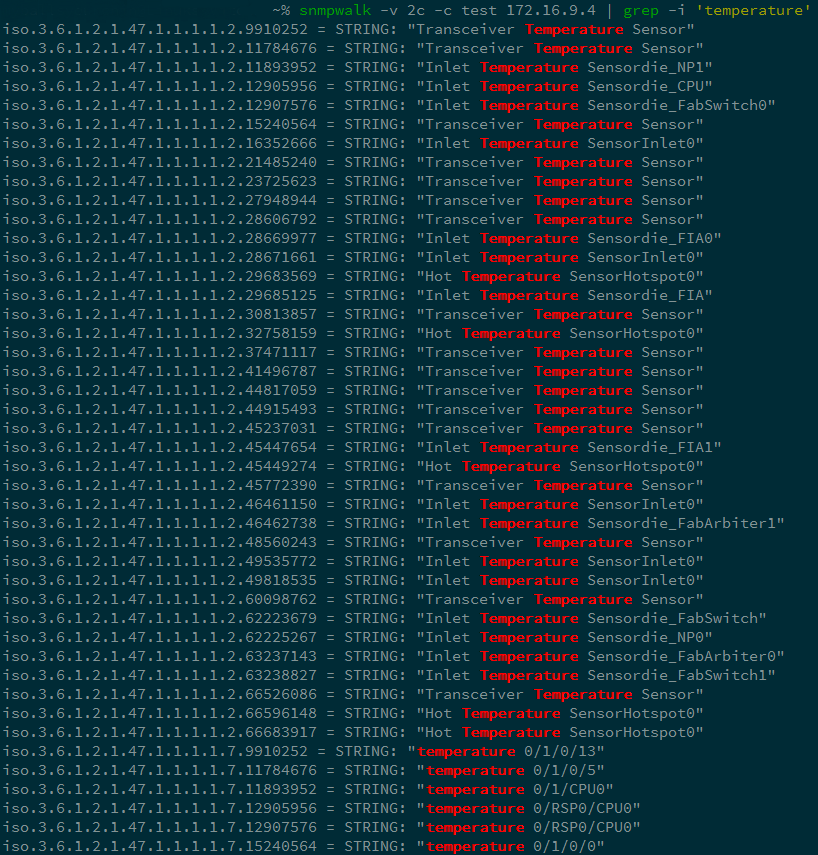
Запрос температурных показателей маршрутизатора Cisco ASR9006.
Изучив вывод, делаем более детальный запрос:
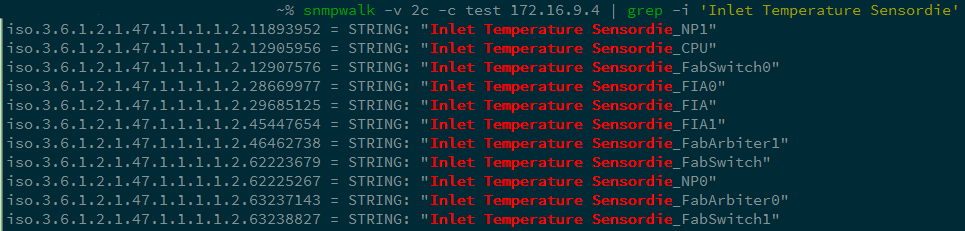
Делаем запрос параметра Inlet Temperature Sensordie для снятия значения температур.
И еще более детальный:

Выбираем параметры NP1 и NP2.
В итоге мы получаем OID 1.3.6.1.4.1.9.9.91.1.1.1.1.4.index и можем отследить показания нужного температурного датчика. На нашем примере – значение 590, т. е. 59 градусов по Цельсию.
В графическом представлении Nagios результаты опроса выглядят так:

На скриншоте мы видим следующее:
- Temperature 0/0, 0/1, 0/2 – датчики линейных карт маршрутизатора ASR9006;
- RSP – датчик карты Route Switch Processor;
- RSP/CPU – датчик температуры CPU карты Route Switch Processor.
Состояние вентиляторов в коммутаторах
Чтобы оборудование не перегревалось, с помощью системы холодоснабжения нашего дата-центра и системы холодных и горячих коридоров мы обеспечиваем постоянный приток воздуха в стойку из холодного коридора и одновременное «выдувание» нагревшегося воздуха в горячий коридор. Роль «насосов», которые качают воздух через оборудование, выполняют вентиляторы внутри коммутаторов – не путать с вентиляторами на стойках. Мы отслеживаем их статус, чтобы не допустить перегрев оборудования.
Если вентилятор остановится, у нас будет некоторое количество времени на его замену, иначе оборудование может пострадать.
Чтобы получить актуальный статус вентилятора, делаем запрос, аналогичный приведенному выше:
iso.3.6.1.4.1.9.9.117.1.1.2.1.2.24330783 = INTEGER: 2
Ответ 2 означает ON. Вентилятор работает, Nagios не паникует.

Так отображается состояние вентиляторов в Nagios.
Небольшая ремарка: при настройке систем мониторинга наши специалисты в качестве пороговых используют значения, полученные при тестовых нагрузках и «краш-тестах». Выход из «нормального» диапазона предупреждает о надвигающейся проблеме, и у нас есть время на «гладкое» устранение неисправности. При этом во многих случаях в режиме реального времени нам достаточно простой индикации «работает/не работает».
Состояние модулей питания
Этот показатель весьма очевиден и не нуждается в комментариях. Упомянем только, что система оповещений сообщит нам о неисправности и/или отсутствии питания в самих блоках питания сетевого оборудования.
Если питание пропадет, дежурная служба быстро разберется, в чем причина. Это может быть проблема с кабелем питания, отсутствие питания на этом вводе или проблема непосредственно с самим блоком. Получив оповещение, инженер предпримет меры и восстановит штатный режим работы оборудования.
OID модулей питания: 1.3.6.1.4.1.9.9.117.1.1.2.1.2.index
Отправляем запрос и получаем статус: iso.3.6.1.4.1.9.9.117.1.1.2.1.2.53196292 = INTEGER: 2
Модуль питания в порядке.

Так состояние модулей питания отслеживается в Nagios.
Состояние портов
Для отслеживания магистральных и абонентских подключений мы мониторим следующие параметры:
- доступность порта;
- уровень сигнала (для оптических портов);
- объем трафика (скорость порта);
- ошибки.
Расскажу о каждом параметре по отдельности.
Чтобы проверить операционный статус порта, производим стандартный запрос по OID.
Вводим OID нужного порта: 1.3.6.1.2.1.2.2.1.8.ifindex
Получаем ответ: iso.3.6.1.2.1.2.2.1.8.1073741829 = INTEGER: 2
Визуализация ответа в Nagios.
Если порт оптический, проверяем уровень сигнала на оптике.
1. Проверяем исходящий сигнал:
OID: 1.3.6.1.4.1.9.9.91.1.1.1.1.4.txindex
Ответ: iso.3.6.1.4.1.9.9.91.1.1.1.1.4.6869781 = INTEGER: 8580
2. Затем проверяем входящий сигнал:
OID: 1.3.6.1.4.1.9.9.91.1.1.1.1.4.rxindex
Ответ: iso.3.6.1.4.1.9.9.91.1.1.1.1.4.63630989 = INTEGER: 2499
Расшифрую цифры в примерах выше. Запрос возвращает нам значение в миллиВаттах и показывает четыре знака после запятой. То есть показатели выше означают 0,8 мВт и 0,2 мВт. Далее встроенная функция шаблона Cacti преобразует значение в дБм (Децибел-миллиВатт).
Статистика по уровням затухания на оптических линках полезна при анализе проблем в сети. Cacti позволяет увидеть динамику ухудшения характеристик и найти причину проблем на линке.
У нас был необычный случай с сигналом на одной из оптических трасс. На графике ниже виден провал в уровне приема оптического сигнала. Этот провал длился целую неделю, но потом уровень резко «отскочил» в нормальное состояние. Что это могло быть, нам остается только догадываться. Возможно, какой-то подрядчик проводил работы в телефонной канализации, а потом по-тихому все вернул на место.
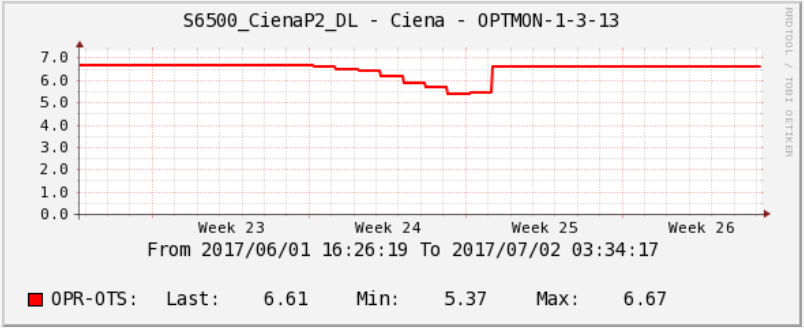
Статистика сигнала на оптической трассе в Cacti.
Еще один очень важный параметр – пропускная способность (скорость) портов. Нам необходимо в режиме реального времени получать информацию о степени загруженности сетевых линков.
Эта метрика позволяет нам планировать трафик и управлять мощностями сети. Кроме того, имея статистику о пропускной способности линков, мы можем проанализировать последствия DDoS-атаки и принять меры по уменьшению влияния DDoS-атак в будущем.
Чтобы получить сводку о количестве принятых и отправленных пакетов информации, снова используем запросы:
1. Принятые пакеты
OID: 1.3.6.1.2.1.31.1.1.1.6.ifindex
Ответ: iso.3.6.1.2.1.31.1.1.1.6.1073741831 = Counter64: 109048713968
2. Отправленные пакеты
OID: 1.3.6.1.2.1.31.1.1.1.10.ifindex
Ответ: iso.3.6.1.2.1.31.1.1.1.10.1073741831 = Counter64: 67229991783
Цифры, полученные в запросах выше, – это количество байт. Разница в этих значениях за N секунд/N и есть пропускная способность в байтах. Если умножить на восемь, получим бит/с. Т.е. мониторинг запрашивает раз в минуту значение, сравнивает его с предыдущим, вычисляет разницу между двумя значениями, переводим байт в бит и получаем скорость бит/с.
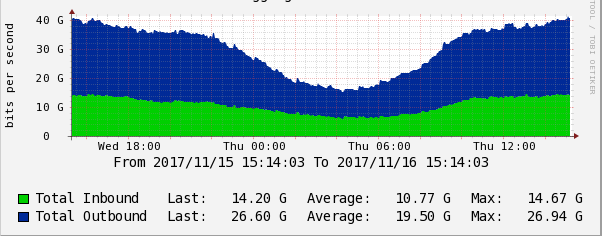
График скорости передачи данных в Cacti.
Нередко у наших абонентов возникает деградация каналов Интернет из-за переполнения выделенной для них полосы пропускания. Трудно сходу определить причину деградации: симптом на стороне абонента – частичная потеря пакетов. Для быстрого распознавания этой проблемы в Nagios мы выставляем пороги срабатывания на полосу пропускания каждого абонентского канала.
В дашборде Nagios это выглядит так:

Детальный вывод:
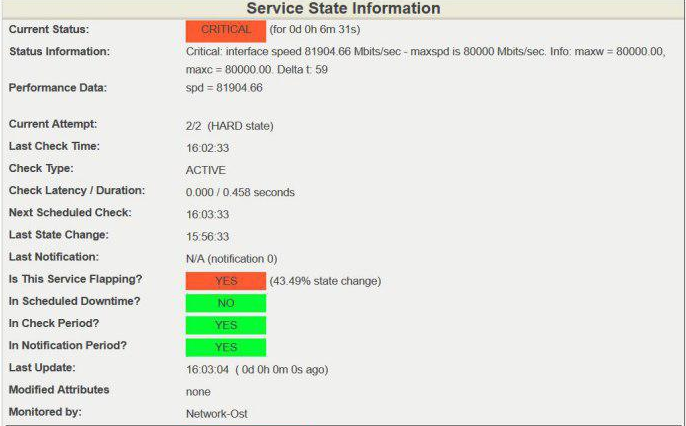
Превышение порога скорости 80 Гбит/с на 100-гигабитном канале считается опасным, в таких случаях мы принимаем меры по разгрузке канала либо расширяем его. Помните, всегда нужно оставлять «пространство для маневра», т.е. свободную полосу пропускания на случай быстрого роста трафика. Это может быть пик посещаемости ресурса, бэкап или, в худшем случае, DDoS.
Наконец, для каждого порта мы мониторим ошибки. Используя статистику по ошибкам, мы локализуем и устраняем проблему.
1. Узнаем количество полученных пакетов с ошибками:
OID: 1.3.6.1.2.1.2.2.1.14.ifindex
Ответ: iso.3.6.1.2.1.2.2.1.14.1073741831 = Counter32: 0
2. Проверяем количество пакетов, которые не были отправлены, т.к. содержали ошибки:
OID: 1.3.6.1.2.1.2.2.1.20.ifindex
Ответ: iso.3.6.1.2.1.2.2.1.20.1073741831 = Counter32: 0
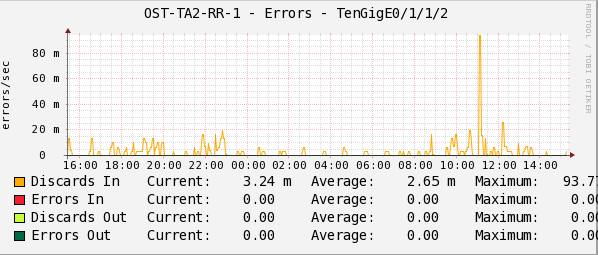
Статистика в Cacti фиксирует количество ошибок при передаче пакетов в секунду.
Показатели Discards In/Out и Errors In/Out на графике – это консолидированные счетчики всех возможных причин, по которым пакет данных мог не передаться протоколам вышестоящего уровня.
Чтобы отслеживать ошибки и узнавать о проблемах с линками, в Nagios предусмотрена система оповещений по каждому OID. Однако ошибки не всегда можно оперативно отследить, поэтому для своевременного оповещения дежурных инженеров в Nagios дополнительно настроен сервис мониторинга ошибок на портах.
Так выглядит проверка на наличие ошибок на портах в Nagios.
Пожалуй, это все ключевые метрики портов, которые мы мониторим.
Упомяну только об одном важном моменте: при перезагрузке коммутатора с операционной системой Cisco IOS, например Cisco Catalyst 6500, меняется соответствие «порт-ifindex». Это неизбежно приводит к необходимости перенастройки SNMP-запросов в системе мониторинга. Для закрепления значений индекса интерфейса (ifindex) нужно ввести команду snmp ifmib ifindex persist в глобальном режиме IOS, тогда после перезагрузки ifindex в MIB останутся неизменёнными.
Состояние процессоров
Загрузка процессора, приближенная к 100%, может негативно повлиять на здоровье сетевого хоста или сети в целом. Это тот случай, когда мы должны мгновенно узнавать о превышении допустимых порогов. Для этого, как вы уже поняли, мы используем Nagios. Изучая графики из Cacti и наблюдая за системой в реальном времени, мы понимаем тренды и цикличность работы процессоров. Все это помогает инженерам находить и обезвреживать проблемы до того, как они скажутся на работе сети.
Производим запрос состояния процессора сетевых устройств:
OID: 1.3.6.1.4.1.9.9.109.1.1.1.1.7.index
Ответ: iso.3.6.1.4.1.9.9.109.1.1.1.1.7.2098 = Gauge32: 2
Получаем значение загрузки CPU в минуту.

Состояние загрузки процессора в Nagios.
Открываем подробную информацию о состоянии процессора. Снова обратим внимание на пункт Performance Data на скриншоте ниже. Он содержит информацию о текущей загрузке процессора и пороговые значения. Текущая загрузка составляет 3%. Предупреждение система выдаст при загрузке 50% и даст сигнал CRITICAL при 70% загруженности.
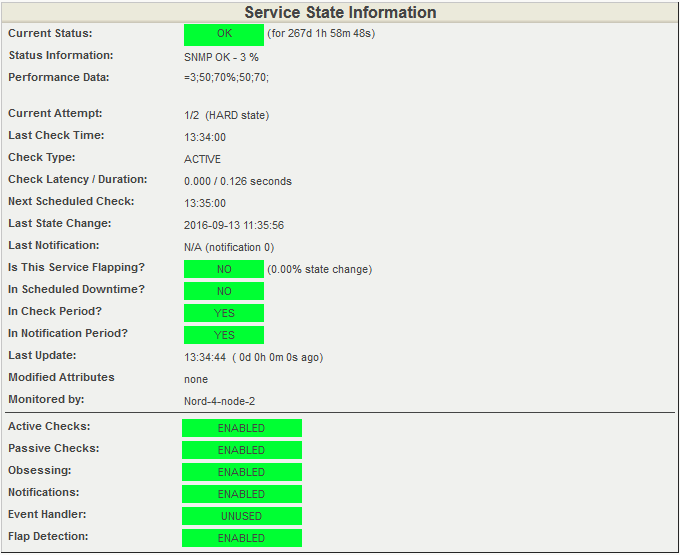
Подробная информация о состоянии процессора. Все показатели в норме.
Control Plane Policy: влияние трафика на загрузку процессора
Этот показатель дополняет рассмотренную выше базовую информацию о загрузке процессора. Часть входящего трафика проходит обработку процессором, и мы отслеживаем его тип и количество отдельно. Повышенную загрузку CPU может вызвать как DDoS-атака, так и вполне валидный трафик (ICMP-, ARP-запросы и т.д.), которого просто слишком много.
Обрабатывая чрезмерное количество данных, любой процессор может загрузиться «под завязку» и не сможет обрабатывать служебный трафик, например протоколы маршрутизации — routing updates или hello/keepalive-пакеты. Соответственно, взаимодействие с соседним сетевым оборудованием прекратится, и сервис деградирует или упадёт.
Вот реальный пример:
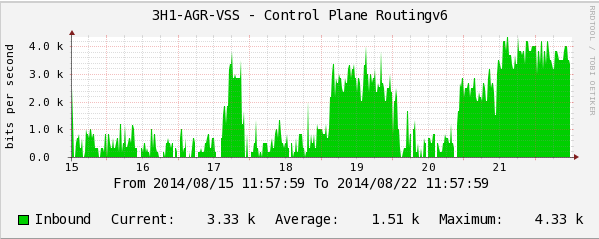
Скорость потока пакетов протокола маршрутизации IPv6.
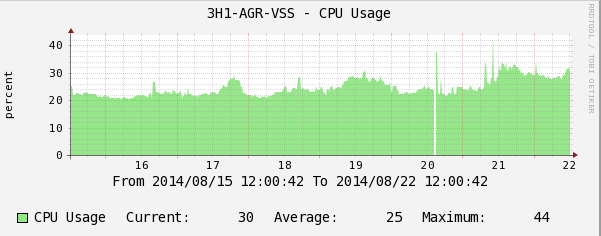
График загрузки CPU.
На графиках видно, как пакеты протокола маршрутизации IPv6 начинают «подгружать» CPU коммутатора. Этот факт можно не заметить своевременно и при увеличении потока IPv6-пакетов получить весьма болезненный инцидент на сети.
С помощью стресс-тестов на сетевом оборудовании мы определили, какой трафик по типу и количеству приводит к проблемам на сетевых устройствах, и установили на control plane policing оптимальные пороговые значения для каждого из них. Графики ниже показывают скачки значений выше пороговых.
Пример мониторинга CoPP (control plane policing) на одном из коммутаторов в продуктиве:

Количество бит в секунду пакетов трафика. ICMP, идущие в обработку на CPU.

Пакеты UDP.
Наблюдая за этими показателями, мы можем предупреждать повышенную нагрузку на процессор и сохранять стабильность сети. Как и в случае с остальными данными мониторинга, мы собираем историю с помощью Cacti и отображаем текущую ситуацию на мониторах с помощью Nagios.
Мониторинг оперативной памяти
Одна из самых опасных ситуаций в случае с оперативной памятью – утечка (memory leak). Предупреждать и устранять ее важно своевременно, так как в небольших интервалах (день, неделя) медленное, но неотвратимое уменьшение свободной памяти можно просто не заметить.
Частично решить эту проблему позволяет сбор долгосрочной статистики в Cacti. Мы можем отследить тенденцию к переполнению памяти и запланировать технологическое окно для перезагрузки оборудования. К сожалению, в большинстве случаев это единственный абсолютный метод «лечения» утечки.
Вот еще один пример из жизни нашей сети:
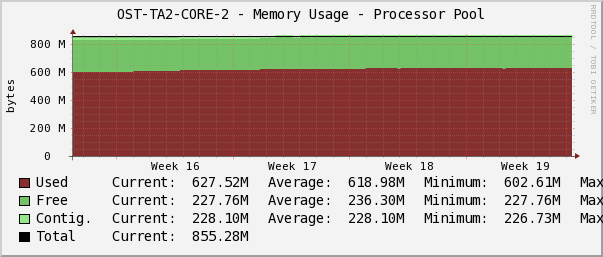
При очередном анализе показателей мониторинга инженеры обнаружили динамику уменьшения объема свободной памяти на одном из коммутаторов. Изменения были почти незаметны на коротких интервалах времени, но, если увеличить масштаб времени, скажем до месяца, появлялся тренд на плавное уменьшение свободной памяти. При заполнении памяти последствия для коммутатора могут быть непредсказуемы, вплоть до странностей в поведении протоколов маршрутизации. Например, часть маршрутов может перестать анонсироваться своему соседу. Или случайным образом начнет отказывать peer-link на системе VSS.
Ситуация, описанная выше, закончилась вполне благополучно. Мы согласовали с клиентами техокно и перегрузили коммутатор.
Итак, продолжим. Графики Cacti помогают определить точное время начала утечки, и, сопоставив логи, мы находим и «лечим» причину.
Делаем запрос загрузки оперативной памяти:
OID: 1.3.6.1.4.1.9.9.221.1.1.1.1.18.index
Ответ: iso.3.6.1.4.1.9.9.221.1.1.1.1.18.52690955.1 = Counter64: 2734644292
Значение указывает количество байтов из пула памяти, используемое операционной системой.
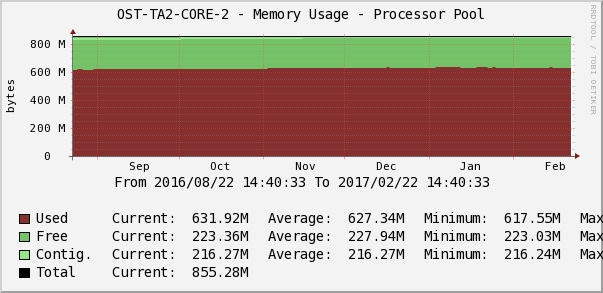
Статистика загрузки оперативной памяти в Cacti.
Дежурный инженер следит за тем, чтобы не было аномальных перепадов или тренда на постоянное заполнение свободной памяти по параметру Memory Usage. График в Cacti показывает память под процессы, ввод/вывод, общую память, количество свободной/занятой памяти.
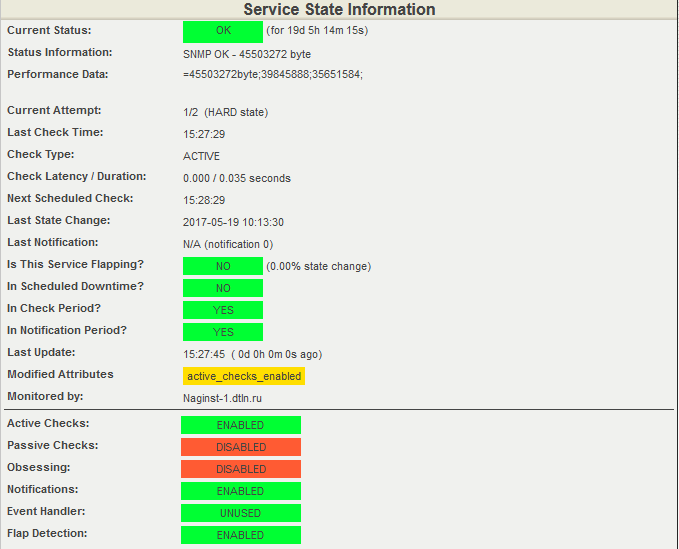
Текущее значение свободной оперативной памяти коммутатора – выгрузка из Nagios.
В момент создания скриншота было свободно 45503272 байт ОП, установлены пороги срабатывания: для WARNING — в интервале от 35651584 до 39845888 байт, для CRITICAL — от 0 до 35651584 байт.
Небольшой бонус
Напишу пару слов о том, как система мониторинга оповещает нас о нештатных ситуациях.
В нашей собственной «кухне» мы не используем дополнительные email- или SMS-оповещения, так как дежурные инженеры отлично справляются с мониторингом показателей на экранах. Исключение составляют отдельные критичные показатели, об изменениях которых нам нужно узнавать незамедлительно и вне зависимости от человеческого фактора. Для этих показателей мы настраиваем e-mail- или SMS-рассылку. По желанию клиента мы можем настроить отдельные оповещения на каждое срабатывание. Здесь всё индивидуально. Когда какой-либо параметр в Nagios достигает состояния hard, система оповещает заказчика через тот канал, который мы для этого настроим.
И еще одна мелочь, но приятная. Система мониторинга не только позволяет быстро реагировать на события, но и помогает дежурным оперативно устранить проблему. Делаем мы это, размещая ссылку на инструкцию на хост или сервис Nagios:

Ссылка на ресурс с инструкцией находится под значком «красная книжка» (View Extra Host Notes), в качестве базы знаний с инструкциями мы используем Redmine. Дежурный может перейти по ссылке и уточнить последовательность действий для устранения неисправности. Слева на скриншоте есть картинка в виде телефона, по ней можно узнать ответственное за этот сервис подразделение, и, в случае затруднений, эскалация инцидента происходит именно на это подразделение производственной дирекции.
В заключение хочу обратить ваше внимание на довольно-таки критическую уязвимость SNMP-протокола (версий 1, 2c и 3) в операционных системах Cisco IOS и XE. Уязвимость позволяет злоумышленнику получить полный контроль над системой или инициировать перезагрузку операционной системы атакуемого хоста. Компания Cisco анонсировала уязвимость 29 июня 2017 г., а закрыта она была в новых релизах ПО, вышедших после середины июля. Если не получается по каким-либо причинам обновить софт, как временное решение Cisco рекомендует отключить следующие MIB-базы:
- ADSL-LINE-MIB
- ALPS-MIB
- CISCO-ADSL-DMT-LINE-MIB
- CISCO-BSTUN-MIB
- CISCO-MAC-AUTH-BYPASS-MIB
- CISCO-SLB-EXT-MIB
- CISCO-VOICE-DNIS-MIB
- CISCO-VOICE-NUMBER-EXPANSION-MIB
- TN3270E-RT-MIB
На этом мониторинг аппаратной части сетевой инфраструктуры заканчивается. Задавайте вопросы в комментариях, а о мониторинге сетевой инфраструктуры на логическом уровне я расскажу в следующий раз.
Комментарии (8)

abagaev Автор
08.12.2017 18:04alex005 У нас развернуто несколько инстансов Nagios — по одному на каждый дата-центр. Также используем HA Cluster: Pacemaker + Corosync + DRDB. Для автоматизированного добавления объектов в мониторинг мы используем связку наших скриптов, с помощью которых можно сгенерировать конфигурации для Nagios. Да, Вы правы, лучше иметь функцию автоматизации, уже встроенную в решение. Сейчас как раз смотрим и тестируем Check_MK. Спасибо за совет CEE с Micro Core. Попробуем и его.
alex005
08.12.2017 18:13Пожалуйста. Там такой же подход, генерируется конфигурация для Nagios. Check_MK суперское решение, разворачивал его как в бесплатной версии, так и в Enterprise Virtual на много сайтовых системах, немцы которые это написали просто очень сильные программисты, когда смотришь код модулей на Python видно с какой любовью и дотошностью они это делали. Самая крутая фича в системе Event Console, можно перенаправить все уведомления в нее и регулярными выражениями вылавливать критические события.
Tortortor
09.12.2017 10:51«Предупреждение будет выдано на 3 мс, критическое пороговое значение установлено на 5 мс.»
продолжайте так думатьabagaev Автор
11.12.2017 12:27Закралась небольшая неточность, предупреждение выдается при достижении RTA 3 мс.
Tortortor
11.12.2017 12:58и опять неправильно. не ждите быстрых ответов, могу комментировать раз в час.
abagaev Автор
11.12.2017 16:35Спасибо за внимательность. Действительно, на скриншоте был показатель WARNING 3000 мс вместо 3 мс — по ошибке сделал скриншот из тестовой среды. В продуктиве у нас всё так, как и должно быть — WARNING настроен на 3 мс. Аналогично и с CRITICAL. Скриншот обновил.
alex005
Для инфраструктуры таких масштабов не кажется, что мониторинг на Nagios не надежен и требуется много рутинной работы по правке конфигов и шаблонов устройств?
Напрашивается решение с HA Clustered Services и несколько сайтов для мониторинга разных частей инфраструктуры, например Check_MK поддерживает это в бесплатной версии, про CEE с Micro Core вообще говорить можно долго, там есть буквально все.
abagaev Автор
Спасибо за комментарий, ответил развернуто ниже.