

Общие принципы
Прежде чем начать, давайте узнаем/вспомним об основных фазах трансляции кода C/C++ в исполняемую программу.
Согласно п.5.1.1.2 драфта N1548 «Programming languages — C» и п.5.2 драфта N4659 «Working Draft, Standard for Programming Language C++» (опубликованные версии стандартов можно приобрести здесь и здесь) определены 8 и 9 фаз трансляции соответственно. Давайте опустим детали и рассмотрим абстрактно процесс трансляции:
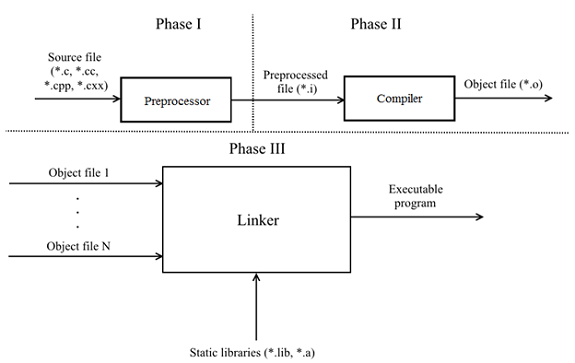
- Фаза I — исходный файл поступает на вход препроцессора. Препроцессор делает подстановку содержимого указанных в #include файлов и раскрывает макросы. Соответствует фазам 1 — 4 драфтов C11 и C++17.
- Фаза II — препроцессированный файл поступает на вход компилятора и преобразуется в объектный. Соответствует фазам 5 — 7 драфта C11 и 5 — 8 драфта C++17.
- Фаза III — компоновщик связывает объектные файлы и предоставленные статические библиотеки, формируя исполняемую программу. Соответствует фазе 8 и 9 драфтов C11 и C++17 соответственно.
Программа составляется из единиц трансляции (*.c, *.cc, *.cpp, *.cxx), каждая является самодостаточной и может препроцессироваться/компилироваться независимо от другой. Из этого также следует, что каждая единица трансляции не имеет никакой информации о других единицах. Если двум единицам трансляции надо обменяться какой-либо информацией (например, функцией), то это решается путем связывания по имени: внешняя сущность объявляется с ключевым словом extern, и на фазе III компоновщик их связывает. Простой пример.
Файл TU1.cpp:
// TU1.cpp
#include <cstdint>
int64_t abs(int64_t num)
{
return num >= 0 ? num : -num;
}Файл TU2.cpp:
// TU2.cpp
#include <cstdint>
extern int64_t abs(int64_t num);
int main()
{
return abs(0);
}Для упрощения согласования разных единиц трансляции был придуман механизм заголовочных файлов, заключающийся в объявлении четкого интерфейса. Впоследствии каждая единица трансляции в случае надобности включает заголовочный файл через директиву препроцессора #include.
Далее рассмотрим, как можно ускорить сборку на разных фазах. Кроме самого принципа также будет полезно описать, как внедрить тот или иной способ в сборочную систему. Примеры будут приводиться для следующих сборочных систем: MSBuild, Make, CMake.
Зависимости при компиляции
Зависимости при компиляции – это то, что в наибольшей степени влияет на скорость сборки C/C++ проектов. Они возникают всякий раз, когда вы включаете заголовочный файл через препроцессорную директиву #include. При этом создается впечатление, что существует лишь один источник объявления для какой-то сущности. Реальность же далека от идеала — компилятору приходится многократно обрабатывать одни и те же объявления в разных единицах трансляции. Еще сильнее картину портят макросы: стоит перед включением заголовка добавить объявление макроса, как его содержимое может в корне измениться.
Рассмотрим пару способов, как можно уменьшить число зависимостей.
Способ N1: убирайте неиспользуемые включения. Не надо платить за то, что вы не используете. Так вы сокращаете работу как препроцессору, так и компилятору. Можно как вручную «перелопатить» заголовки/исходные файлы, так и воспользоваться утилитами: include-what-you-use, ReSharper C++, CppClean, Doxygen + Graphviz (для визуализации диаграммы включений) и т.д.
Способ N2: используйте зависимость от объявления, а не от определения. Выделим 2 главных аспекта:
1) В заголовочных файлах не используйте объекты там, где можно воспользоваться ссылками или указателями. Для ссылок и указателей достаточно опережающего объявления, поскольку компилятор знает размер ссылки/указателя (4 или 8 байт в зависимости от платформы), а размер передаваемых объектов не имеет значения. Простой пример:
// Foo.h
#pragma once
class Foo
{
....
};
// Bar.h
#pragma once
#include "Foo.h"
class Bar
{
void foo(Foo obj); // <= Передача по значению
....
};Теперь, при изменении первого заголовка компилятору придется перекомпилировать единицы трансляции, зависимые как от Foo.h, так и Bar.h.
Чтобы разорвать подобную связь, достаточно отказаться от передачи объекта obj по значению в пользу передачи по указателю или ссылке в заголовке Bar.h:
// Bar.h
#pragma once
class Foo; // <= Опережающее объявление класса Foo
class Bar
{
void foo(const Foo &obj); // <= Передача по константной ссылке
....
};Что касается стандартных заголовков, то здесь можно волноваться поменьше и просто включать их в заголовочный файл при необходимости. Исключением является разве что iostream. Этот заголовочный файл настолько вырос в размерах, что к нему дополнительно поставляется заголовок iosfwd, содержащий только опережающие объявления нужных сущностей. Именно его и стоит включать в ваши заголовочные файлы.
2) Используйте идиомы Pimpl или интерфейсного класса. Pimpl убирает детали реализации, помещая их в отдельный класс, объект которого доступен через указатель. Второй подход основан на создании абстрактного базового класса, детали реализации которого переносятся в производный класс, переопределяющем чистые виртуальные функции. Оба варианта устраняют зависимости на этапе компиляции, но также вносят свои накладные расходы во время работы программы, а именно: создание и удаление динамического объекта, добавление уровня косвенной адресации (из-за указателя); и отдельно в случае интерфейсного класса — расходы на вызов виртуальных функций.
Способ N3 (опционально): дополнительно можно создавать заголовки, содержащие только опережающие объявления (аналог iosfwd). Эти «опережающие» заголовки затем можно включать в другие обычные заголовки.
Параллельная компиляция
При стандартном подходе компилятору раз за разом будет поступать новый файл для препроцессирования и компиляции. Поскольку каждая единица трансляции самодостаточна, то хороший способ ускорения — распараллелить фазы I-II трансляции, обрабатывая одновременно N файлов за раз.
В Visual Studio режим включается флагом /MP[processMax] на уровне проекта, где processMax — опциональный аргумент, отвечающий за максимальное количество процессов компиляции.
В make режим включается флагом -jN, где N — число процессов компиляции.
Если вы используете CMake (к тому же и в кросс-платформенной разработке), то им можно сгенерировать файлы для обширного списка сборочных систем через флаг -G. Например, CMake генерирует для C++ анализатора PVS-Studio решение для Visual Studio под Windows, так и Unix Makefiles под Linux. Чтобы CMake генерировал проекты в решении Visual Studio с флагом /MP, добавьте следующие строки в ваш CMakeLists.txt:
if (MSVC)
target_compile_options(target_name /MP ...)
endif()Также через CMake (с версии 2.8.0) можно позвать сборочную систему с флагами параллелизации. Для MSVC (/MP указан в CMakeLists.txt) и Ninja (параллелизм уже включен):
cmake --build /path/to/build-dirДля Makefiles:
cmake --build /path/to/build-dir -- -jNРаспределенная компиляция
Воспользовавшись предыдущим советом, можно в разы снизить время сборки. Однако, когда проект огромен, и этого может быть недостаточно. Увеличивая число процессов компиляции, вы натыкаетесь на барьер в виде максимального числа одновременно компилируемых файлов из-за процессора/оперативной памяти/дисковых операций. Здесь и приходит на помощь распределенная компиляция, использующая свободные ресурсы товарища за спиной. Идея проста:
1) препроцессируем исходные файлы на одной локальной машине или на всех доступных машинах;
2) компилируем препроцессированные файлы на локальной и на удаленных машинах;
3) ожидаем результата от других машин в виде объектных файлов;
4) компонуем объектные файлы;
5) ????
6) PROFIT!
Выделим основные особенности распределенной компиляции:
- Масштабируемость — подцепляем машину, и теперь она может помогать в сборке.
- Эффективность распределенной компиляции зависит от производительности сети и каждой машины. Крайне рекомендуется схожая производительность каждой машины.
- Необходимость в идентичности окружения на всех машинах (версии компиляторов, библиотек и т.д.). Это особенно необходимо, если препроцессирование происходит на всех машинах.
Наиболее известными представителями являются:
В Linux можно достаточно легко интегрировать distcc и Icecream несколькими способами:
1) Универсальный, через символическую ссылку (symlink)
mkdir -p /opt/distcc/bin # или /opt/icecc/bin
ln -s /usr/bin/distcc /opt/distcc/bin/gcc
ln -s /usr/bin/distcc /opt/distcc/bin/g++
export PATH=/opt/distcc/bin:$PATH2) Для CMake, начиная с версии 3.4
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/usr/bin/distcc /path/to/CMakeDirКэш компилятора
Другим способом уменьшить время сборки является применение кэша компилятора. Немного изменим фазу II трансляции кода:
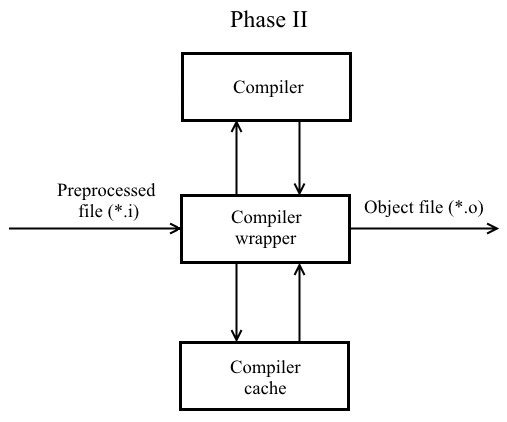
Теперь при компиляции препроцессированного файла на основе его содержимого, флагов компиляции, вывода компилятора вычисляется хэш-значение (учитывает флаги компиляции). Впоследствии хэш-значение и соответствующий ему объектный файл регистрируется в кэше компилятора. При повторной компиляции с теми же флагами неизмененного файла из кэша будет взят уже готовый объектный файл и подан на вход компоновщика.
Что можно использовать:
Регистрацию ccache для его последующего использования можно произвести несколькими способами:
1) Универсальный, через символическую ссылку
mkdir -p /opt/ccache/bin
ln -s /usr/bin/ccache /opt/ccache/bin/gcc
ln -s /usr/bin/ccache /opt/ccache/bin/g++
export PATH=/opt/ccache/bin:$PATH2) Для CMake, начиная с версии 3.4
cmake -DCMAKE_CXX_COMPILER_LAUNCHER=/usr/bin/ccache /path/to/CMakeDirКэш компилятора также можно интегрировать в распределенную компиляцию. Например, для использования ccache с distcc/Icecream, выполните следующие действия:
1) Установите переменную CCACHE_PREFIX:
export CCACHE_PREFIX=distcc # или icecc2) Воспользуйтесь одним из пунктов 1 — 2 регистрации ccache.
Предварительно откомпилированные заголовочные файлы
При компиляции большого количества исходных файлов компилятор, по факту, выполняет множество раз одну и ту же работу по разбору тяжеловесных заголовков (например, iostream). Основная идея заключается в том, чтобы вынести эти тяжеловесные заголовки в отдельный файл (обычно именуется префиксным заголовком), который компилируется единожды и затем включается во все единицы трансляции самым первым.
В MSVC для создания предкомпилированного заголовка по умолчанию генерируются 2 файла: stdafx.h и stdafx.cpp (можно использовать и другие имена). Первым шагом необходимо скомпилировать stdafx.cpp с флагом /Yc«path-to-stdafx.h». По умолчанию создается файл с расширением .pch. Чтобы использовать предкомпилированный заголовок при компиляции исходного файла используем флаг /Yu«path-to-stdafx.h». Совместно с флагами /Yc и /Yu также можно использовать /Fp«path-to-pch» для указания пути к .pch файлу. Теперь необходимо подключить в каждой единице трансляции префиксный заголовок самым первым: либо непосредственно через #include «path-to-stdafx.h», либо принудительно через флаг /FI«path-to-stdafx.h».
Подход в GCC/Clang отличается немногим: необходимо передать компилятору на вход непосредственно сам префиксный заголовок вместо обычного компилируемого файла. Компилятор автоматически выполнит генерацию предкомпилированного заголовка с расширением .gch по умолчанию. При помощи ключа -x можно дополнительно указать, рассматривать ли его как c-header или c++-header. Теперь включите префиксный заголовок вручную через #include, либо через флаг -include.
Подробно о предварительно откомпилированных заголовках вы можете прочитать здесь.
Если вы используете CMake, то рекомендуем попробовать модуль cotire: он может в автоматическом режиме проанализировать исходные файлы, сгенерировать префиксный и предкомпилированный заголовки и подключить их к единицам трансляции. Есть также возможность указать свой префиксный заголовок (например, stdafx.h).
Single Compilation Unit
Суть данного метода — создать единый компилируемый файл (блок трансляции), в который включаются другие единицы трансляции:
// SCU.cpp
#include "translation_unit1.cpp"
....
#include "translation_unitN.cpp"Если в единый компилируемый файл включаются все единицы трансляции, то такой способ иначе называют Unity build. Выделим основные особенности Single Compilation Unit:
- Число компилируемых файлов заметно уменьшается, а значит, и число дисковых операций. Компилятор гораздо меньше обрабатывает одни и те же файлы и инстанцирует шаблоны. Это заметно отражается на времени сборки.
- Компилятор теперь может выполнять оптимизации, доступные компоновщику (Link time optimization/Whole program optimization).
- Несколько ухудшается инкрементальная сборка, поскольку изменение одного файла в составе Single Compilation Unit приводит к его перекомпиляции.
- При применении Unity Build становится невозможным использовать распределенную сборку.
Отметим возможные проблемы при применении подхода:
- Нарушение ODR (совпадение имен макросов, локальных статических функций, глобальных статических переменных, переменных в анонимных пространствах имен).
- Коллизии имен вследствие применения using namespace.
Максимальную выгоду на многоядерных системах будут давать схемы:
- параллельной компиляции нескольких Single Compilation Unit с применением предкомпилированного заголовка;
- распределенной компиляции нескольких Single Compilation Unit с применением кэша компилятора.
Если вы используете CMake, то можно автоматизировать генерацию SCU с помощью этого модуля.
Замена компонентов трансляции
Замена одного из компонентов трансляции на более быстрый аналог также может увеличить скорость сборки. Однако, делать это стоит на свой страх и риск.
В качестве более быстрого компилятора можно воспользоваться Zapcc. Авторы обещают многократное ускорение перекомпиляции проектов. Это можно проследить на примере перекомпиляции Boost.Math:

Zapcc не жертвует производительностью программ, основан на Clang и полностью с ним совместим. Здесь можно ознакомиться с принципом работы Zapcc. Если ваш проект основан на CMake, то заменить компилятор очень легко:
export CC=/path/to/zapcc
export CXX=/path/to/zapcc++
cmake /path/to/CMakeDirили так:
cmake -DCMAKE_C_COMPILER=/path/to/zapcc -DCMAKE_CXX_COMPILER=/path/to/zapcc++ /path/to/CMakeDirЕсли ваша ОС использует ELF-формат объектных файлов (Unix-подобные системы), то можно заменить компоновщик GNU ld на GNU gold. GNU gold идет в составе binutils, начиная с версии 2.19, и активируется флагом -fuse-ld=gold. В CMake его можно активировать, например, следующим кодом:
if (UNIX AND NOT APPLE)
execute_process(COMMAND ${CMAKE_CXX_COMPILER}
-fuse-ld=gold -Wl,--version
ERROR_QUIET OUTPUT_VARIABLE ld_version)
if ("${ld_version}" MATCHES "GNU gold")
message(STATUS "Found Gold linker, use faster linker")
set(CMAKE_EXE_LINKER_FLAGS
"${CMAKE_EXE_LINKER_FLAGS} -fuse-ld=gold")
set(CMAKE_SHARED_LINKER_FLAGS
"${CMAKE_SHARED_LINKER_FLAGS} -fuse-ld=gold ")
endif()
endif()Использование SSD/RAMDisk
Очевидным «бутылочным горлышком» в сборке является скорость дисковых операций (в особенности случайного доступа). Перенос временных файлов проекта или его самого на более быструю память (HDD с повышенной скоростью случайного доступа, SSD, RAID из HDD/SSD, RAMDisk) в некоторых ситуациях может сильно помочь.
Модульная система в C++
Большинство вышеперечисленных способов исторически возникли из-за выбора принципа трансляции C/C++ языков. Механизм заголовочных файлов, несмотря на кажущуюся простоту, доставляет много хлопот для C/C++ программистов.
Уже достаточно продолжительное время идет обсуждение о включении модулей в стандарт C++ (и, возможно, появится в C++20). Модулем будет считаться связанный набор единиц трансляции (модульная единица) с определенным набором внешних (экспортируемых) имен, называемых интерфейсом модуля. Модуль будет доступен для всех импортирующих его единиц трансляции только через его интерфейс. Неэкспортируемые имена помещаются в имплементацию модуля.
Другим важным достоинством модулей является то, что они не подвергаются изменениям через макросы и директивы препроцессора, в отличие от заголовочных файлов. Справедливо также и обратное: макросы и директивы препроцессора внутри модуля не влияют на единицы трансляции, импортирующие его. Семантически, модули представляют собой самостоятельные, полностью скомпилированные единицы трансляции.
В данной статье не будет детально рассматриваться устройство будущих модулей. Если вы хотите узнать о них больше, то рекомендуем к просмотру выступление Бориса Колпакова на CppCon 2017 о модулях C++ (там также показана разница по времени сборок):
На сегодняшний момент компиляторы MSVC, GCC, Clang предлагают экспериментальную поддержку модулей.
А что-нибудь про сборку PVS-Studio будет?
В этом разделе давайте рассмотрим, насколько бывают эффективными и полезными описанные подходы.
За основу возьмем ядро анализатора PVS-Studio для анализа C и C++ кода. Оно, конечно же, написано на C++ и представляет собой консольное приложение. Ядро является небольшим проектом по сравнению с такими гигантами, как LLVM/Clang, GCC, Chromium и т.д. Вот, например, что выдает CLOC на нашей кодовой базе:
----------------------------------------------------------------
Language files blank comment code
----------------------------------------------------------------
C++ 380 28556 17574 150222
C/C++ Header 221 9049 9847 46360
Assembly 1 13 22 298
----------------------------------------------------------------
SUM: 602 37618 27443 196880
----------------------------------------------------------------Отметим, что до проведения всяких работ наш проект собирался за 1.5 минуты (использовались параллельная компиляция и один предкомпилированный заголовок) на следующей конфигурации рабочей машины:
- Процессор Intel Core i7-4770 3.4 GHz (8 CPU).
- ОЗУ 16 Gb RAM DDR3-1333 MHz.
- Samsung SSD 840 EVO 250 Gb в качестве системного диска.
- WDC WD20EZRX-00D8PB0 2 Tb под рабочие нужды.
Примем в качестве стартового показателя сборку проекта на HDD, выключив все оптимизации времени сборки. Далее обозначим первый этап замеров:
- сборка на HDD, компиляция в 1 поток, без оптимизаций;
- сборка на SSD, компиляция в 1 поток, без оптимизаций;
- сборка на RAMDisk, компиляция в 1 поток, без оптимизаций.
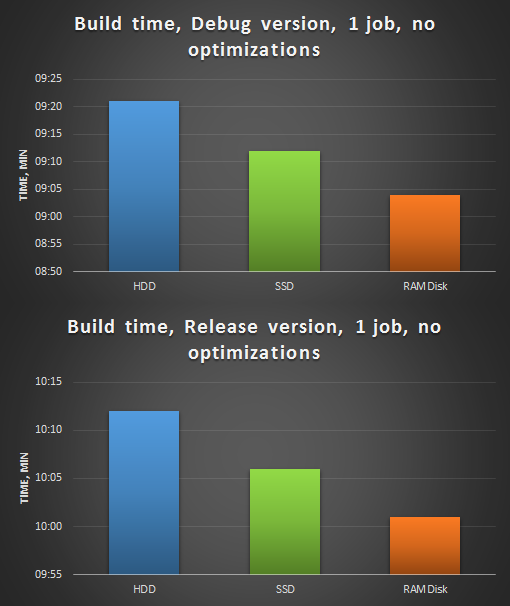
Рисунок 1. Сборка анализатора PVS-Studio, 1 поток, без оптимизаций. Сверху — сборка Debug версии, снизу — Release.
Как видно из диаграммы, за счет большей скорости произвольного доступа проект на RAMDisk без оптимизаций в 1 поток собирается быстрей.
Второй этап замеров — дорабатываем напильником исходный код: удаляем ненужные включения заголовков, устраняем зависимости от определения, улучшаем предкомпилированный заголовок (убираем из него часто изменяемые заголовки) — и постепенно прикручиваем оптимизации:
- компиляция в 1 поток, проект на HDD, SSD и RAMDisk:
- single compilation units (SCU);
- предкомпилированный заголовок (PCH);
- single compilation units + предкомпилированный заголовок (SCU + PCH).
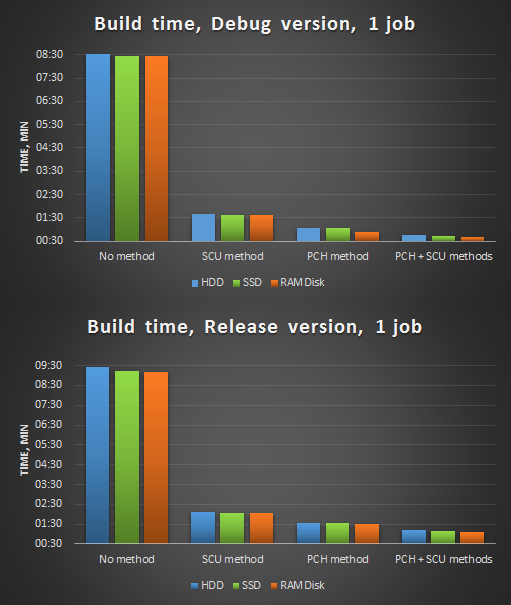
Рисунок 2. Компиляция в 1 поток после оптимизаций.
- компиляция в 4 потока, проект на HDD, SSD, RAMDisk:
- single compilation units;
- предкомпилированный заголовок;
- single compilation units + предкомпилированный заголовок
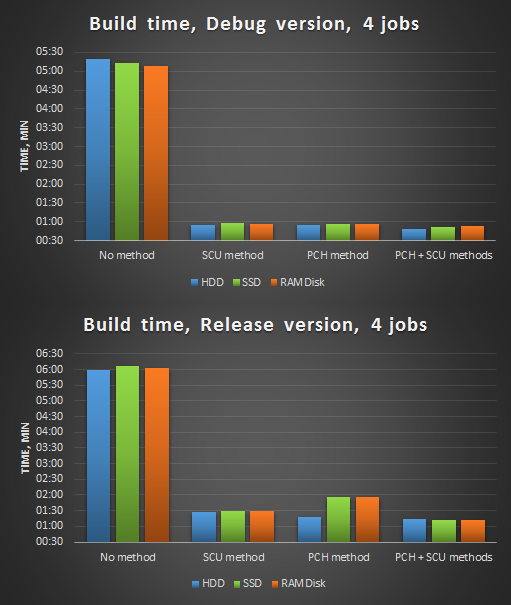
Рисунок 3. Компиляция в 4 потока после оптимизаций.
- компиляция в 8 потоков, проект на HDD, SSD, RAMDisk:
- single compilation units;
- предкомпилированный заголовок;
- single compilation units + предкомпилированный заголовок
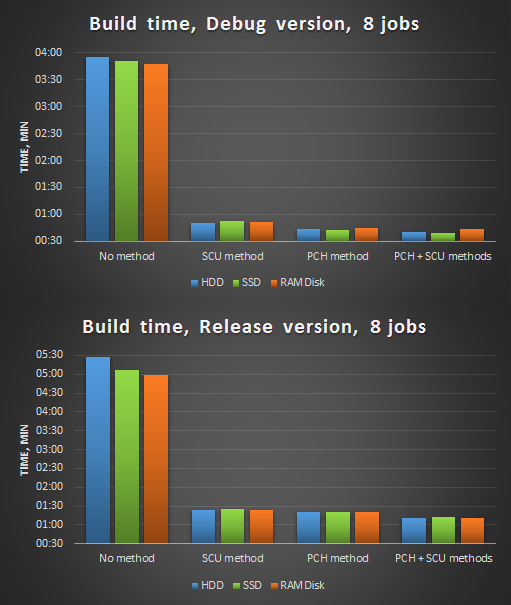
Рисунок 4. Компиляция в 8 потоков после оптимизаций.
Сделаем краткие выводы:
- Польза от применения SSD/RAMDisk может колебаться в зависимости от их модели, скорости произвольного доступа, условий запуска, фаз луны и т.д. Хоть они и являются более быстрыми аналогами HDD, конкретно в нашем случае они не дают значительный выигрыш.
- Предкомпилированные заголовки — очень эффективное средство. Этот способ и ранее использовался в нашем анализаторе, и его использование даже при компиляции в 1 поток давало 7-8 кратное ускорение.
- При малом числе единых блоков трансляции (SCU) целесообразно не создавать предкомпилированные заголовки. Используйте предкомпилированные заголовки, когда число единых блоков трансляции достаточно велико (> 10).
Заключение
Для многих программистов языки C/C++ ассоциируются как нечто «долго компилирующееся». И на это есть свои причины: выбранный в свое время способ трансляции, метапрограммирование (для C++), тысячи их. Благодаря описанным методам оптимизации можно лишить себя подобных предрассудков о чрезмерно долгой компиляции. В частности, время сборки нашего ядра анализатора PVS-Studio для анализа C и C++ кода удалось снизить с 1 минуты 30 секунд до 40 секунд путем интеграции Single Compilation Units и переработки заголовочных и исходных файлов. Более того, если бы до начала оптимизаций не были использованы параллельная компиляция и предкомпилированные заголовки, нами было бы получено семикратное уменьшение времени сборки!
В окончание хочется добавить, что об этой проблеме прекрасно помнят в комитете стандартизации и полный ходом идет решение данной проблемы: все мы ждем нового стандарта C++20, который, возможно, одним из нововведений «завезёт» модули в любимый многими язык и сделает жизнь C++ программистов гораздо проще.
Комментарии (33)

Noospheratu
12.12.2017 22:12Стоит ли ожидать появления соответствующих диагностик в PVS-Studio (например, для уменьшения зависимостей использованием указателя вместо объекта (способ 2, вариант №1))?

Andrey2008
12.12.2017 23:27Мы про это не думали. Сейчас основное наше направление, это поиск ошибок и контроль качества кода.

KF-121
13.12.2017 08:42у вас уже есть такое правило, выдает предупреждение о снижении производительности и предлагает использовать константные ссылки. номер сейчас не вспомню.
Noospheratu
13.12.2017 11:38Семейство диагностик V.800: www.viva64.com/ru/w
«V801. Decreased performance. It is better to redefine the N function argument as a reference. Consider replacing 'const T' with 'const… &T' / 'const… *T'.»Andrey2008
13.12.2017 11:42«Для уменьшения зависимостей» (оптимизация скорости сборки) и микрооптимизации кода, это всё-таки разные направления.


Videoman
12.12.2017 22:20+1В заголовочных файлах не используйте объекты там, где можно воспользоваться ссылками или указателями. Для ссылок и указателей достаточно опережающего объявления, поскольку компилятор знает размер ссылки/указателя (4 или 8 байт в зависимости от платформы), а размер передаваемых объектов не имеет значения.
Тут, хотелось бы уточнить, что в случае объявления можно возвращать объект по значению. Об этом мало кто помнит, но это также помогает избежать ненужных include-ов. Т.е. такой код скомпилируется:/ Bar.h #pragma once class Foo; // <= Опережающее объявление класса Foo class Bar { Foo get_foo() const; // Размер возвращаемого значения не важен .... };khandeliants Автор
12.12.2017 23:24Дополнительно уточню, что в случае опережающего объявления вы можете не только возвращать объект по значению, но даже и принимать объект по значению в качестве параметра! Единственное, что от вас требует компилятор — предоставить определение класса на момент вызова функции. Этот пример тоже скомпилируется:
// Foo.h class Foo { .... }; // Bar.h class Foo; // <= Все также опережающее объявление class Bar { Foo get_foo(Foo obj) const; // <= И принимаем параметр по значению, // и также возвращаем .... };
evnuh
13.12.2017 17:24А как компилятор узнает где разместить параметр, переданный по значению, не зная его размер?
Videoman
13.12.2017 18:38Согласитесь, данная информация никак не влияет на размер класса Bar и его интерфейс может быть объявлен без неё. В .c/.cpp файле определение естественно понадобится. Как только вы попытаетесь вызвать данный метод или вернуть класс по значению, вот тут, вам и понадобится определение Foo и компилятор вам подскажет об этом.
VioletGiraffe
13.12.2017 00:52Вот это новость. 10 лет программирую на С++ (из них 6 — профессионально), и был уверен, что так нельзя. Спасибо.
al_sh
13.12.2017 10:57А разве не будет создан лишний экземпляр и лишний копирующий конструктор не будет вызван на c<11?
Videoman
13.12.2017 12:32При возврате по значению, если из функции один return, то, почти всегда, будет RVO или RNVO — зависит от компилятора. А это даже быстрее чем std::move.
При передаче по значению, конечно будет. Но это не всегда будет медленнее. Зависит от размера класса и его структуры.

Xu4
12.12.2017 22:28+1Вам нужно было просто продать Macbook Pro и купить Macbook Mini 2012-го года для сборки (памяти на него накатить ещё, и SSD поставить)… Опыт хабрапользователей показывает, что скорость сборки вырастает.
anonrab
13.12.2017 14:41Еще есть сейчас поверья, что замена батареи Macbook Pro ускорит время компиляции и скорость работы системы в целом… И устаревший Mac mini покупать не придется.

slonopotamus
12.12.2017 23:17убирайте неиспользуемые включения
включается во все единицы трансляции самым первым
У вас тут взаимоисключающие параграфы. Нельзя одновременно сделать PCH и IWYU.
gasizdat
13.12.2017 08:52Частично, да. Но и в stdafx можно напихать много ненужного. Иногда так происходит из-за всякого рода рефакторингов, когда нужные раньше заголовки становятся ненужными.
khandeliants Автор
13.12.2017 11:45Судя по этой задаче, IWYU поддерживает предкомпилированные заголовки. Предлагают использовать следующие флаги:
- --pch_in_code сообщает IWYU рассматривать первое включение как предкомпилированный заголовок. Используйте --pch_in_code, чтобы предотвратить ситуации, в которых IWYU удалит необходимые PCH включения.
- --prefix_header_includes=<value> позволяет выбрать, что делать с включениями и опережающими объявлениями, которые встречаются как в префиксном/предкомпилированном заголовке, так и единице трансляции. Возможные значения: add (по умолчанию), keep, remove.
Также соглашусь с gasizdat, после рефакторинга у вас могут остаться куча неиспользуемых include'ов даже в предкомпилированном заголовке, а в него не стоит запихивать все и побольше.slonopotamus
13.12.2017 13:22Вы не поняли. Тут противоречие на концептуальном уровне. PCH инклюдится во все файлы. Даже в те которым он не нужен. Это нарушает принцип IWYU.
FlameDancer
12.12.2017 23:32+1Как любят писать «я просто оставлю это здесь» www.youtube.com/watch?v=OhaEINErq6w
Вообщем electric cloud рулит и у меня лично сложилось впечатление что оно соберет не только быстро, но и правильно, правда за деньги :)
mezastel
13.12.2017 15:36IncrediBuild лучше потому что соберет на вашем локальном простаивающем железе. Zero-config в VS, просто устанавливаешь и оно работает.

dmbreaker
13.12.2017 04:43Интересно, к C++33 таки поправят эти косяки архитектуры языка, или так и будут продолжать катить этот ворох компромиссов?
mviorno
13.12.2017 11:45Очень сомневаюсь, обратная совместимость постоянно будет тянуть обратно в трясину. Тут тот самый случай, когда сделать новое будет проще, чем починить старое. А у чего-то нового будут большие проблемы с тем чтобы взлететь.

acmnu
13.12.2017 17:55На самом деле было бы неплохо в компиляторы включать strict режим, который бы не компилировал устаревшие конструкции. Это разумеется не сработало бы для легаси, но для написания нового кода с нуля дало бы выигрыш.

Kitmouse
15.12.2017 11:54Планируют добавить модули, которые, как предполагается, должны будут со временем полностью вытеснить #includ-ы.

bibmaster
13.12.2017 07:44Unity build можно делать вручную, без автогенерации. У нас например сделано так — Cmake функции передается список исходников, в которых она ищет файлы вида unity_build.*.cpp. Из этих файлов извлекается список include и в зависимости от опции в сборке либо отключается сам unity build модуль либо все его включения.
bibmaster
13.12.2017 07:53Причем все файлы можно оставить в проекте, отключая компиляцию через свойство HEADER_FILE_ONLY.

Antervis
13.12.2017 08:02SCU мб и хорошо использовать для сборки всего проекта, но по идее этот процесс должен быть автоматизирован. А вот скорость инкрементальных сборок, куда больше влияющую на скорость разработки, он попросту уничтожает

sashkin
13.12.2017 13:13Искусство составления графиков: как 2-3% показать значительной разницей. )))) А 15 секунд из 9-10 минут это именно 2-3%. Низя же так манипулировать. :)
DrLivesey
13.12.2017 15:40+1Статья познавательная, но есть пара замечаний:
- Пропущен вопрос того, как инстанциируются шаблоны в С++ (а по умолчанию они инстанциируются для каждой единицы компиляции и это вопрос можно частично решить с помощью
extern templateиз С++11) - Оптимизация процесса линковки тоже не описана, ведь как минимум в MSVS существуют разные варианты оптимизации на этом уровне, например
Whole Program Optimizationне позволяет делать инкрементальную линковку, что очень неприятно когда при изменении одной строки кода приходится ждать несколько минут на линковке. По моему опыту, полученному из ряда эксперименов, при включеномWPOфайлы компилируются быстрее, но время с лихвой съедается за счет линковки в случае большого проекта. При выключеном — компиляция удлинняется, зато линковка почти мгновенная.
- Пропущен вопрос того, как инстанциируются шаблоны в С++ (а по умолчанию они инстанциируются для каждой единицы компиляции и это вопрос можно частично решить с помощью
ivan2kh
В проекте Chromium недавно пошли по пути Single Compilation Unit с использованием jumbo, так как из параллельной компиляции все соки уже выжали.
Разумеется сразу возникли проблемы с коллизиями имен, но их постепенно решают. Оказалось, что подход хорошо работает для сборки в 4-8 потока (ускорение в 2 раза), и дает меньший эффект на многоядерных системах. Настоятельно рекомендуется всем использовать
use_jumbo_build = true