

Disclaimer
Автор хотя и имеет математическое образование, никак не связан ни с Data Mining, ни со статистическим анализом. Данный материал является результатом исследования, проведенного с целью выяснить возможность написания модуля поиска аномалий (пусть даже слабого) для разрабатываемой системы мониторинга.
Что ищем в двух картинках
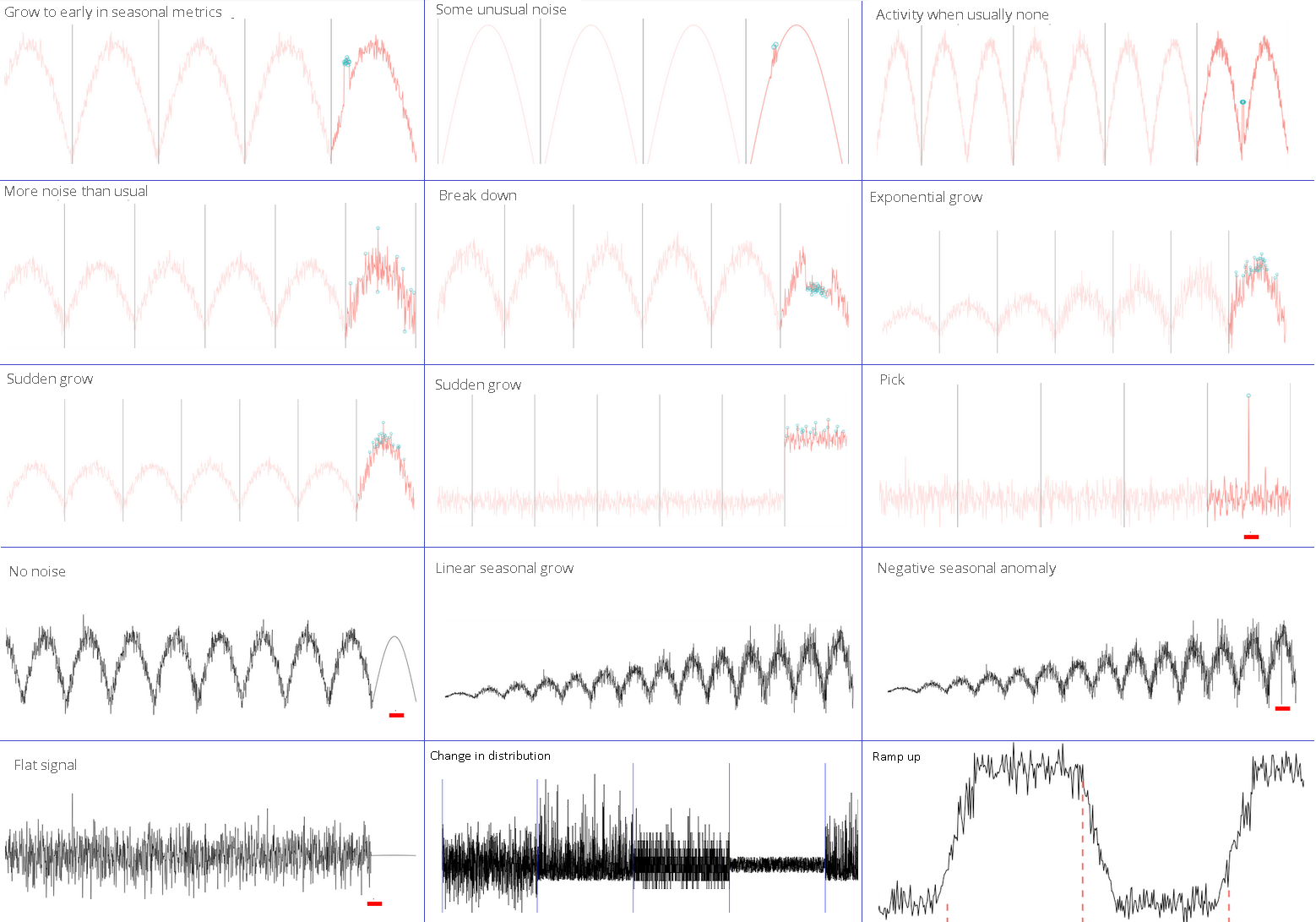
Источник Anomaly.io
Конечно в реальности, не всегда все так просто: только на б), д) и е) явная аномалия.
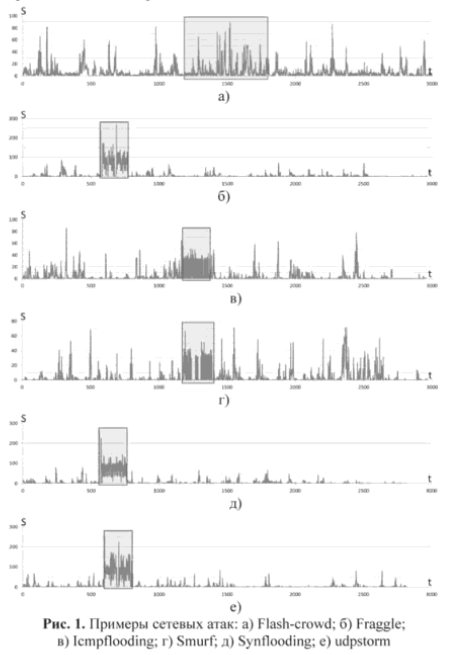
Источник cyberleninka.ru
Текущее положение дел
Коммерческие продукты почти всегда представлены в виде сервиса, использующего как статистику, так и машинное обучение. Вот некоторые из них: AIMS, Anomaly.io (прекрасный блог с примерами), CoScale (возможность интеграции, напр. с Zabbix), DataDog, Grok, Metricly.com и Azure (от Microsoft). У Elastic есть модуль X-Pack на основе машинного обучения.
Open-source продукты, которые можно развернуть у себя:
- Atlas от Netflix — in-memory база данных для анализа временных рядов. Поиск выполняется методом Хольта-Винтерса.
- Banshee от Eleme. Для обнаружения используется всего один алгоритм, основанный на правиле трех сигм.
- Стек KALE от Etsy, состоящий из двух продуктов Skyline, для обнаружения проблем в реальном времени, и Oculus для поиска взаимосвязей. Похоже заброшен.
- Morgoth — фреймворк для обнаружения аномалий в Kapacitor (модуль уведомлений InfluxDB). Из коробки имеет: правило трех сигм, тест Колмогорова-Смирнова и отклонение Дженсена-Шеннона.
- Prometheus — набирающая популярность система мониторинга, в которой можно самостоятельно реализовывать некоторые алгоритмы поиска, используя стандартный функционал.
- RRDTool — база данных, используемая, например, в Cacti и Munin. Умеет делать прогноз методом Хольт-Винтерса. О том, как это можно использовать — в статье Мониторинг прогнозированием, оповещения о потенциальном сбое
- ~2000 репозитариев на GitHub
На мой взгляд open-source по качеству поиска значительно уступает. Чтобы понять, как работает поиск аномалий и можно ли исправить ситуацию, придется немного окунуться в статистику. Математические детали упрощены и скрыты под спойлерами.
Модель и её компоненты
Для анализа временного ряда используют модель, которая отражает предполагаемые особенности (компоненты) ряда. Обычно модель состоит из трех компонент:
- Тренд — отражает общее поведение ряда в плане возрастания или убывания значений.
- Сезонность — периодичные колебания значений, связанные, например, с днем недели или месяца.
- Случайное значение — то, что останется от ряда после исключения других компонент. Здесь и будем искать аномалии.
Можно включить дополнительные компоненты, например циклическую, как множитель тренда,
аномальную (Catastrophic event) или социальную (праздники). Если тренд или сезонность в данных не просматриваются, то соответсвующие компоненты из модели можно исключить.
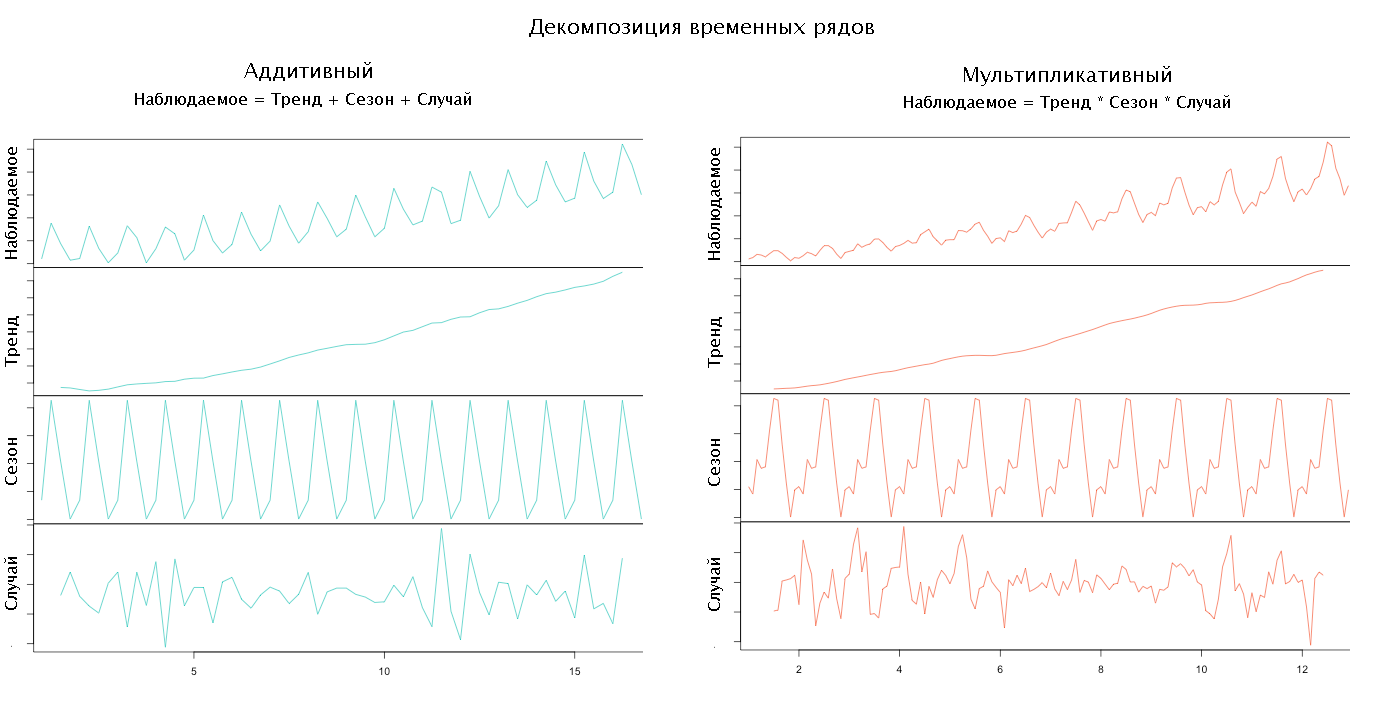
В зависимости от того, как связаны между собой компоненты модели, определяют её тип. Так, если все компоненты складываются, чтобы получить наблюдаемый ряд, то говорят, что модель аддиктивна, если умножаются, то мультипликативна, если что-то умножается, а что-то сладывается, то смешаная. Обычно тип модели выбирается исследователем на основе предварительного анализа данных.
Декомпозиция
Выбрав тип модели и набор компонент можно приступать к декомпозиции временного ряда, т.е. его разложению на компоненты.
Источник Anomaly.io
Сперва выделяем тренд, сгладив исходные данные. Метод и степень сглаживания выбираются исследователем.
Если использовать не одно, а несколько предшедствующих значений, т.е. среднее арифметическое k-соседних значений, то такое сглаживание называется простым скользящим средним с шириной окна k
Если для каждого предыдушего значения использовать какой то свой коэффициент, определяющий степень влияния на текущий, то получим взвешенное скользящее среднeе.
Несколько другой способ — эсконенциальное сглаживание. Сглаженный ряд вычисляется следующим образом: первый элемент совпадает с первым элементом исходного ряда, а вот последующие вычисляются по форумуле
Где ? — коэффициент сглаживания, от 0 до 1. Как легко видеть чем ближе ? к 1, тем больше получаемый ряд будет похож на исходный.
Для определения линейного тренда можно взять методику расчета линейной регрессии методом наименьших квадратов: , , где и — средние арифметические и .
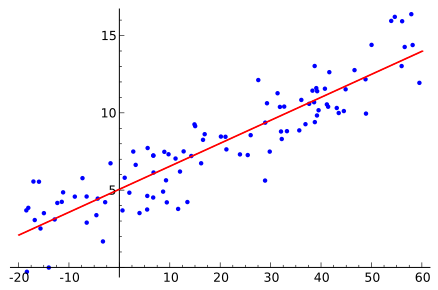
Источник Википедия
Для определения сезонной составляющей из исходного ряда вычитаем тренд или делим на него, в зависимости от типа выбранной модели, и еще раз сглаживаем. Затем делим данные по длине сезона (периоду), обычно это неделя, и находим усредненный сезон. Если длина сезона не известна, то можно попытаться найти её:
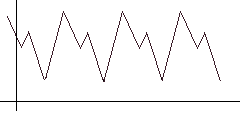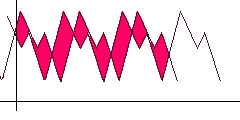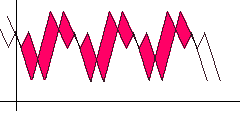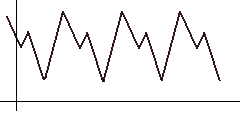
Для поиска авто-корреляцией просто сдвигаем функцию вправо и ищем такое положение, чтобы расстояние/площадь между исходной и сдвинутой функцией (выделено красным) было минимально. Очевидно для алгоритма должен быть задан шаг сдвига и максимальный предел, при достижении которого считаем, что поиск периода не удался.
Более подробно о моделях и декомпозиции можно узнать из статей «Extract Seasonal & Trend: using decomposition in R» и «How To Identify Patterns in Time Series Data».
Удалив из исходного ряда тренд и сезонный фактор, получаем случайную компоненту.
Типы аномалий
Если анализировать только случайную компоненту, то многие аномалии можно свести к одному из следующих случаев:
- Выброс
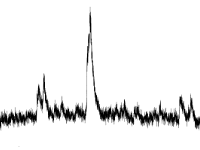 Нахождение выбросов в данных — классическая задача, для решения которой уже имеется хороший набор решений:
Нахождение выбросов в данных — классическая задача, для решения которой уже имеется хороший набор решений:
Правило трех сигм, межквартильный размах и другиеИдея подобных тестов — определить насколько далеко располагается отдельное значение от среднего. Если расстояние отличается от «обычного», то значение объявляется выбросом. Время события при этом игнорируется.
Считаем, что на входе ряд чисел — , ,… , всего штук. — -ое число.
Стандартные тесты достаточно просты в реализации и требуют лишь вычисление среднего , стандартного отклонения и иногда медианы — среднее значение, если упорядочить все числа по возрастанию и взять то, которое по середине.
Правило трех сигм
Если , то считаем выбросом.
Z-оценка и уточненный метод Iglewicz и Hoaglin
— выброс, если больше задаваемого порога, обычно равному 3. По сути переписанное правило трех сигм.
Уточненный метод заключается в следующем: для каждого числа ряда вычисляем и для получившихся значений находим медиану, обозначаемую .
— выброс, если больше порога.
Межквартильный размах
Сортируем исходные числа по возрастанию, делим на двое и для каждой части находим медианные значения и .
— выброс, если .
Тест Граббса
Находим минимальное и максимальное значения и для них вычисляем и . Затем выбираем уровень значимости ? (обычно один из 0.01, 0.05 или 0.1), заглядываем в таблицу критичных значений, выбираем значение для n и ?. Если или больше табличного значения, то считаем соответствующий элемент ряда выбросом.
Обычно тесты требуют, чтобы исследовалось нормальное распределение, но зачастую это требование игнорируется.
- Сдвиг
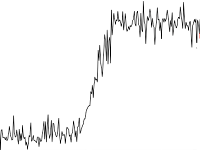 Задача обнаружения сдвига в данных неплохо исследована, поскольку встречается в обработке сигналов. Для её решения можно воспользоваться Twitter Breakout Detection. Отмечу, что это оно работает значительно хуже, если анализируется исходный ряд с компонентами сезонности и тренда.
Задача обнаружения сдвига в данных неплохо исследована, поскольку встречается в обработке сигналов. Для её решения можно воспользоваться Twitter Breakout Detection. Отмечу, что это оно работает значительно хуже, если анализируется исходный ряд с компонентами сезонности и тренда.
- Изменение характера (распределения) значений
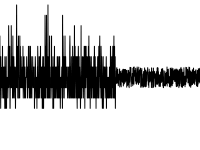 Как и для сдвига, можно использовать тот же пакет BreakoutDetection от Twitter, но с ним не все гладко.
Как и для сдвига, можно использовать тот же пакет BreakoutDetection от Twitter, но с ним не все гладко.
- Отклонение от «повседневного» (для данных с сезонностью)
Для обнаружения данной аномалии необходимо сравнить текущий период и несколько предыдущих. Обычно используют
Метод Хольта-ВинтерсаМетод относится к прогнозированию, поэтому его применение сводится к тому, чтобы сравнить прогнозируемое значение с действительным.
Основная идея метода в том, что каждая из трех компонент экспоненциально сглаживается, используя отдельный коэффициент сглаживания, поэтому метод зачастую называется тройным экспоненциальным сглаживанием. Формулы рассчета для мультипликативного и аддиктивного сезонов есть в Википедии, а подробности о методе в статье на Хабре.
Три параметра сглаживания должны выбираться так, чтобы получаемый ряд был «близок» к исходному. На практике такая задача решается перебором, хотя RRDTool требует явного задания этих значений.
Недостаток метода: требует минимум три сезона данных.
Другой способ, примененный в Одноклассниках, — выбрать значения из других сезонов, соответсвующие анализируемому моменту, и проверить их совокупность на наличие выброса, например тестом Граббса.
Также Twitter предлагает AnomalyDetection, который на тестовых данных показывает хорошие результаты. К сожалению, как и BreakoutDetection, он уже два года без обновлений.
- Поведенческие
Иногда аномалии могут иметь специфичный характер, который в большинстве случаев должен быть проигнорирован, например, одно значение у двух соседних элементов. В таких случаях требуются отдельные алгоритмы.
- Совместные аномалии
Отдельно стоит упомянуть о аномалиях, когда значения двух наблюдаемых метрик поотдельности в пределах нормы, но их совместное появление признак проблемы. В общем случае, нахождение таких аномалий может быть решено кластерным анализом, когда пары значений представляют координаты точек на плоскости и все множество событий делится на две/три группы (кластера) — «норма»/«шум» и «аномалия».
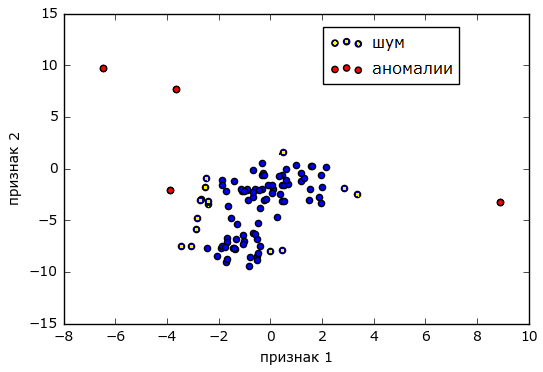
Источник alexanderdyakonov.wordpress.com
Более слабый метод состоит в том, чтобы отслеживать насколько метрики зависят друг от друга во времени и в случае, когда зависимость теряется, выдавать сообщение об аномалии. Для этого, вероятно, можно использовать один из методов.
Линейный коэффициент корреляции ПирсонаПусть и два набора чисел и требуется выяснить имеется ли между ними линейная зависимость. Вычисляем для среднее и стандартное отклонение . Аналогично для .
Коэффициент корреляции Пирсона
Чем коэффициент по модулю ближе к 1, тем большая зависимость. Если коэффициент ближе к -1, то зависимость обратная, т.е. рост связан с убыванием .
Расстояние Дамерау — ЛевенштейнаПусть есть две строки ABC и ADEC. Чтобы получить из первой вторую, необходимо убрать B и добавить D и E. Если каждой операции удаления/добавления символа и перестановке XY в YX задать стоимость, то суммарная стоимость и будет расстояниеи Дамерау — Левенштейна.
Для определения похожести графиков можно оттолкнуться от алгоритма, использованного в KALE
Вначале исходный ряд значений, например, ряд вида [960, 350, 350, 432, 390, 76, 105, 715, 715], нормализуется: ищется максимум — ему будет соответствовать 25, и минимум — ему будет соответствовать 0; таким образом, данные пропорционально распределяются в пределе целых чисел от 0 до 25. В итоге мы получаем ряд вида [25, 8, 8, 10, 9, 0, 1, 18, 18]. Затем нормализованный ряд кодируется с помощью 5 слов: sdec (резко вниз), dec (вниз), s (ровно), inc (вверх), sinc (резко вверх). В итоге получается ряд вида [sdec, flat, inc, dec, sdec, inc, sinc, flat].
Закодировав два временных ряда таким образом, можно узнать расстояние между ними. И если оно меньше какого то порога, то считать, что графики похожи и связь имеется.
Заключение
Разумеется, многие алгоритмы нахождения аномалий уже реализованы на языке R, предназначенном для статистической обработки данных, в виде пакетов: tsoutliers, strucchange, Twitter Anomaly Detection и других. Подробнее о R в статьях А вы уже применяете R в бизнесе? и Мой опыт введения в R. Казалось бы, подключай пакеты и используй. Однако есть проблема — задание параметров статистических проверок, которые в отличии от критических значений далеко не очевидны для большинства и не имеют универсальных значений. Выходом из данной ситуации может быть их подбор перебором (ресурсоёмко), с редким периодичным уточнением, независимо для каждой метрики. С другой стороны, большая часть аномалий, не связанных с сезонностью, хорошо определяется визуально, что наталкивает на мысль использовать нейронную сеть на отрендеренные графики.
Приложение
Ниже привожу собственные алгоритмы, которые работают сопоставимо с Twitter Breakout по результатам, и несколько быстрее по скорости при реализации на Java Script.
- Если ряд сильно зашумленный, то усредняем, напр. по 5 элементам.
- В результат включаем первую и последние точки ряда.
- Находим максимально удаленную точку ряда от текущей ломаной и добавляем ее в набор.
- Повторяем пока среднее отклонение от ломаной до исходного ряда не будет меньше среднего отклонения в исходном ряде или пока не достигнуто предельное число вершин ломаной (в этом случае, вероятно, апроксимация не удалась).
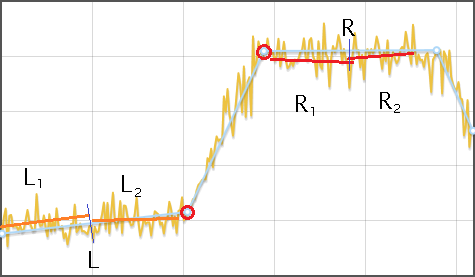
- Апроксимируем исходный ряд ломаной
- Для каждого отрезка ломаной, кроме первого и последнего:
- Находим его высоту , как разность y-координат начала и конца. Если высота меньше игнорируемого интервала, то такой отрезок игнорируется
- Оба соседних отрезка и делим на двое, каждый участок , , , аппроксимируем своей прямой и находим среднее расстояние от прямой до ряда — , , , .
- Если и значительно меньше чем , то считаем, что сдвиг обнаружен
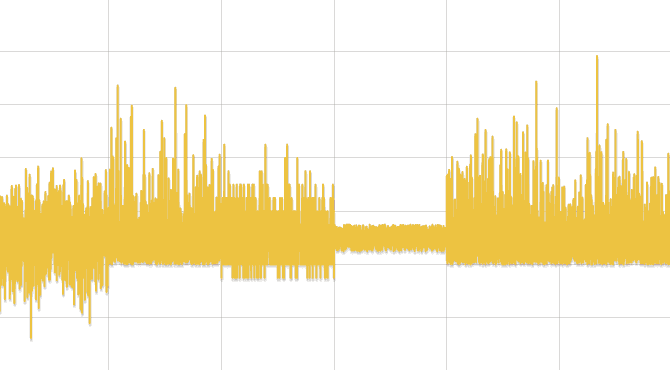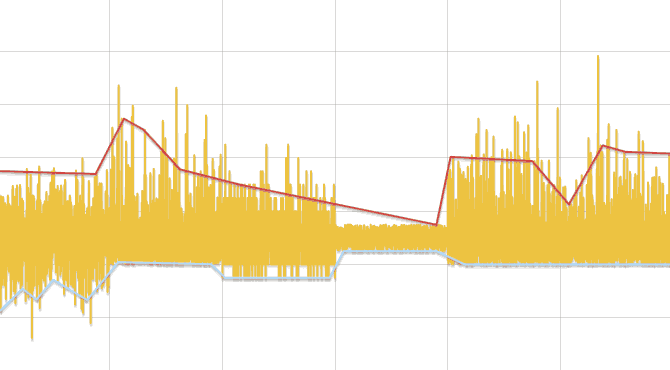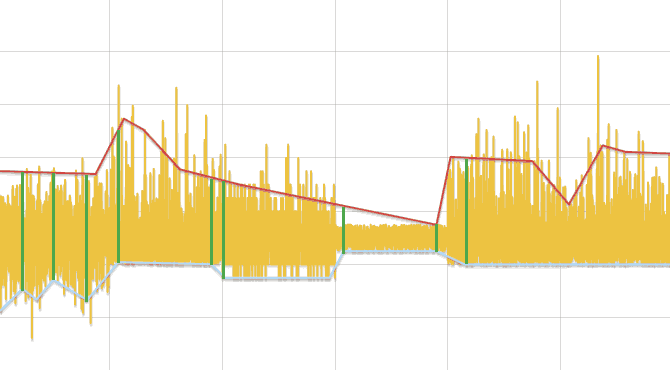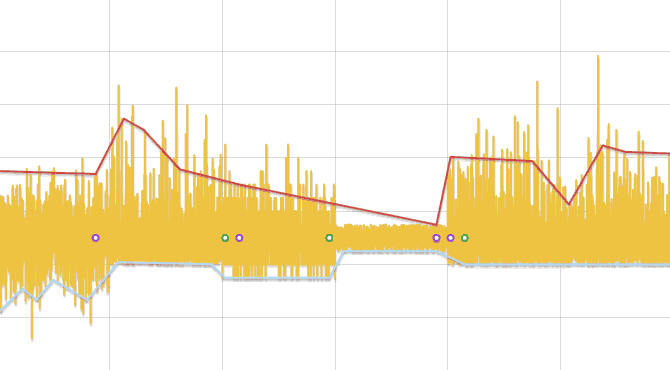
- Исходный ряд разбивается на отрезки, длинной, зависящей от числа данных, но не менее трех.
- В каждом отрезке ищется минимум и максимум. Заменяя каждый отрезок его центром, образуется два ряда — минимумы и максимумы. Далее ряды обрабатываются отдельно.
- Ряд линейно аппроксимируется и для каждой его вершины, кроме первой и последней, выполняется сравнение данных исходного ряда, лежащих слева и справа до соседних вершин ломаной, тестом Колмогорова-Смирнова. Если разница обнаружена, то точка добавляется в результат.
Вначале значения обоих рядов разбиваются на несколько (около десятка) категорий. Далее для каждой категории вычисляется число , вошедших в него значений из ряда , и делится на длину ряда . Аналогично для ряда . Для каждой категории находим и затем общий максимум по всем категориям. Проверяемое значение критерия вычисляется по формуле .
Выбирается уровень значимости (один из 0.01, 0.05, 0.1) и по нему определяется критичное значение по таблице. Если больше критичного значения, то считается, что группы различаются существенно.
Комментарии (10)

IvanKhozyainov
16.12.2017 04:40Большая, интересная тема. Спасибо за статью. Да, в блоге anomaly.io неплохо написано про статистические методы. Кстати, если кому будет интересно посмотреть видео по похожей теме (хотя там больше про machine learning) — есть канал на ютуб www.youtube.com/user/numenta/videos, grokstream.com использует эти разработки в своем решении.
У меня пару вопросов на понимание.
1. Про совместные аномалии
Хороший термин, раньше не встречал русского обозначения, но все-таки надо как-то обзывать эти многомерные аномалии, почему бы и не так. Он где-то использовался в русскоязычной литературе?
Из возможных интуитивных подходов — использование сворачивания этой 2d-функции в одномерную и искать уже аномалии в значениях f(x,y). Например, как это делается в регрессионном анализе при поиске зависимостей.
2. «Алгоритм нахождения сдвига в данных»
Нахождение среднего тут неявно заложено в алгоритме аппроксимации. А как аппроксимировали? Своим методом, который «Алгоритм кусочно-линейной аппроксимации временного ряда»? Или метод наименьших квадратов?
В этом смысле очень похоже на алгоритм, который используется в R-пакете твиттера, но подход с другой стороны. В математическом смысле суть похожа: «находим локальное среднее значение, сравниваем с соседними»
А часто бывает когда результат апроксимации совпадает с «сырой» исходной ломаной?
Мне правда это интересно с той точки зрения, насколько могут быть похожи или различаться решения одной и той же задачи. Может быть решение вообще только единственное верное в идеальном случае. Но это вопрос больше философский.
P.S. Вашу статью, кстати, вполне можно как шпаргалку использовать для первичной навигации по теме :)
С наступающим!
little-brother Автор
16.12.2017 13:131. В русскоязычных материалах термин «совместные» вроде не встречал (да и в целом не так её и много просмотрел). Да, наверно можно и свертку сделать, у меня просто проблема в нехватке знаний :(
2. Аппроксимировал своим методом. Аппроксимация мои методом близка к исходному ряду, если будет аппроксимироваться не достаточно сглаженный ряд. Возможно можно использовать какой то параметр гладкости внутри метода, чтобы так не промахиваться.
Метод наверняка так себе, поскольку мне оказалось проще придумать своё, нежели использовать готовое. Через язык статей, тому кто в этой теме не постоянно, прорываться очень сложно.IvanKhozyainov
17.12.2017 01:561. Честно говоря, русскоязычной литературы по этой теме не так много находил — в основном все-таки англоязычная. Поэтому подумалось «а вдруг».
2. Интересно, что в математике в этом смысле есть сходство с программированием. Готовые исследованные решения типа методов Эйлера как фреймворки, а самостоятельно придуманные методы — это что-то вроде своих самописных решений в программировании. Преимущества и недостатки очень похожи.

A1essandro
16.12.2017 12:20… что наталкивает на мысль использовать нейронную сеть на отрендеренные графики.
По идее можно не рендерить, а просто использовать тот же персептрон. Входные данные просто нужно будет преобразовать: привести количество точек по x к количеству нейронов входного слоя, а значения y нормировать от [0, 1] либо [-1, 1].little-brother Автор
16.12.2017 12:41Я пока только присматриваюсь к нейронным сетям, которые показывают впечатляющие результаты, так что не очень представляю как и что там работает. Сейчас книгу начал читать по азам, вдохновившись вот этой статьей.
A1essandro
17.12.2017 12:56Еще про совместные аномалии и нейронные сети — обратите внимание на Нейронную Сеть Кохонена. Очень простая по структуре (два слоя). Легко реализуема. Обучение без учителя для этой сети тоже легче реализовать чем тот же самый алгоритм обратного распространения ошибки. Дает неплохие результаты по классификации. Правда иногда нужно поиграться с начальными весами.
openbsod
16.12.2017 12:20Благодарю вас, очень увлекательная статья. Если позволите, пара вопросов: на каком объеме данных (примерно) вы проводите вычисления, с какой частотой поступают метрики на анализ, к-примеру, «150k значений/sec, 300GB данных в час»? Спасибо.
little-brother Автор
16.12.2017 13:27Объема данных у меня никакого нет — несколько простых железок, опрашиваемых раз в две минуты и всё. Разрабатываемая система мониторинга уровня Cacti, а не Zabbix/Prometheus/Influx.
Задачу выделения аномалий хорошо можно распараллелить, если использовать численные/статистические методы, но чтобы анализировать скажем 150К/с это уже надо делать балансировщики и сопутствующую архитектуру. Но даже в этом случае придется переписать все расчеты на низкоуровневые языки. R, Python и, используемый мной, Java Script — слишком медленные для такого.
JekaMas
Вариант от facebook, prophet не пробовали?
little-brother Автор
Prophet я видел, но не стал в обзор, поскольку как я понял, у них больше прогнозирование. В целом, если хочется учитывать праздничную составляющую из коробки, то да, можно им воспользоваться. Тут вопрос насколько это будет быстро.