
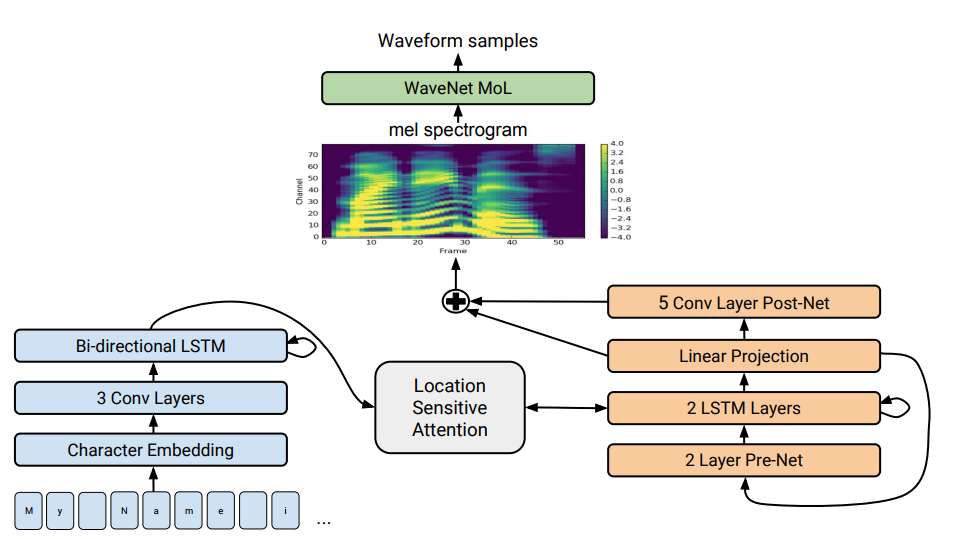
Архитектура Tacotron 2. В нижней части иллюстрации показаны модели предложение-к-предложению, которые транслируют последовательность букв в последовательность признаков в 80-мерном пространстве. Техническое описание см. в научной статье
Синтез речи — искусственное воспроизводство человеческой речи из текста — традиционно считается одной из составляющих частей искусственного интеллекта. Раньше такие системы можно было увидеть только в фантастических фильмах, а сейчас они работают буквально в каждом смартфоне: это системы Сири, Алиса и тому подобные. Вот только они не очень реалистично произносят фразы: голос неживой, слова отделены друг от друга.
Компания Google разработала продвинутый синтезатор речи нового поколения. Он называется Tacotron 2 и основан на нейросети. Для демонстрации его возможностей компания выложила примеры синтеза. Внизу странички с примерами можно пройти тест и попробовать определить, где текст произносит синтезатор речи, а где человек. Определить разницу практически невозможно.
Несмотря на десятилетия исследований, синтез речи по-прежнему остаётся актуальной задачей перед научным сообществом. За прошедшие годы в этой области преобладали разные методики: самыми продвинутыми в последнее время считались конкатенативный синтез с выбором фрагментов — процесс соединения воедино маленьких заранее записанных звуковых фрагментов, а также статистический параметрический синтез речи, в котором плавные траектории произношения синтезировал вокодер. Второй способ решал многие проблемы конкатенативного синтеза с артефактами на границах между фрагментами. Однако в обоих случаях синтезированный звук звучал невнятно и неестественно по сравнению с человеческой речью.
Затем вышел звуковой движок WaveNet (генеративная модель волновых форм во временнoй области), который впервые смог показать качество звука, сравнимое с человеческим. Он сейчас используется в системе синтеза речи Deep Voice 3.
Ранее в 2017 году компания Google представила архитектуру Tacotron типа «предложение-к-предложению». Она генерирует спектрограммы амплитуд из последовательности символов. Tacotron упрощает традиционный конвейер работы звукового движка. Здесь лингвистические и акустические признаки генерирует единственная нейросеть, обученная только на данных. Фраза «предложение-к-предложение» означает, что нейросеть устанавливает соответствие между последовательностью букв и последовательностью признаков для кодирования звука. Признаки генерируются в 80-мерной аудиоспектрограмме с кадрами по 12,5 миллисекунд.
Нейросеть обучается не только произношению слов, но и специфическим голосовым характеристикам, таким как громкость, скорость и интонация.
Затем непосредственно звуковые волны генерируются с применением алгоритма Гриффина-Лима (для фазовой оценки) и обратное кратковременное преобразование Фурье. Как отмечали авторы, это было временное решение для демонстрации возможностей нейросети. На самом деле движок WaveNet и ему подобные создают звук лучшего качества, чем алгоритм Гриффина-Лима, и без артефактов.
В доработанной системе Tacotron 2 специалисты из компании Google всё-таки подключили к нейросети вокодер WaveNet. Таким образом, нейросеть создаёт спектрограммы, а затем модифицированная версия WaveNet генерирует звук на 24 кГц.
Нейросеть самостоятельно обучается (end-to-end) на звуке человеческого голоса, который сопровождается текстом. Хорошо обученная нейросеть затем читает тексты так, что практически невозможно отличить от звучания человеческой речи, как можно убедиться на реальных примерах.
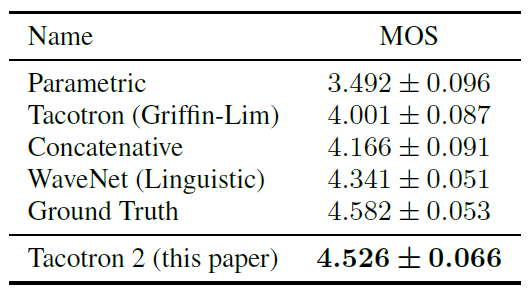
Исследователи обращают внимание, что система Deep Voice 3 использует схожий подход, но качество её синтеза всё-таки не может сравниться с человеческой речью. А вот Tacotron 2 может, см. результаты тестов Mean Opinion Score (MOS) в таблице.
Есть ещё один синтезатор речи, который тоже работает на нейросети — это Char2Wav, но у него совсем другая архитектура.
Учёные говорят, что в целом нейросеть работает отлично, но всё-таки испытывает сложности с произношением некоторых сложных слов (таких как decorum или merlot). А иногда случайным образом выдаёт странные шумы — причины этого сейчас выясняются. Кроме того, система не способна работать в реальном времени, а авторам пока не удаётся взять движок под контроль, то есть задать ему нужную интонацию, например, счастливый или грустный голос. Каждая из этих проблем интересна сама по себе, пишут они.
Научная статья опубликована 16 декабря 2017 года на сайте препринтов arXiv.org (arXiv:1712.05884v1).
Комментарии (14)
ankh1989
22.12.2017 05:25«традиционно считается одной из составляющих частей искусственного интеллекта» — кем считается? Статья на архиве таких слов не упоминает. То как сейчас лепят бирку «ИИ» к чему попало напоминает то как несколько лет назад любили добавлять приставку «нано».

Een_Stemming
22.12.2017 08:27Меня до сих пор подташнивает от слов «нанотехнологии» и «инновации».

sergku1213
22.12.2017 09:19А я когда встречаю " машинное обучение" — читаю его как «мышиное обучение» и очень радуюсь. Попробуйте что-нибудь в этом духе и может быть Ваша жизнь станет чуть лучше

ReakTiVe-007
22.12.2017 09:45Нейросеть произносит мерло как мерлАТ. Опять нейроны что то напутали… а жаль, голос приятный.

pasetchnik
22.12.2017 13:07Здорово, что робот понимает где глагол, а где существительное (отличает desert от desert и present oт present.)

imm
22.12.2017 14:16не торты, а торты!
pasetchnik
22.12.2017 15:08Я скорее имел в виду пОрты и портЫ. А не ошибочное ударение.
ОмографыКстати, в русском языке, оказывается, тоже целая куча омографов.
Бедные роботы…
pasetchnik
22.12.2017 13:15Интересно есть что-нибудь близкое по качеству, чтобы можно было туда книжки загружать?

sainomori
22.12.2017 15:55Забавно, но довольно легко отличить в приведенных примерах человека от синтезатора.
У Человека явно слышно придыхание при произношении. Машина — не дышит =)
Особенно заметно на согласных типа p и t

redpax
23.12.2017 12:08“Алиса“ не синтезирует голос, там предзаписаны все предложения актрисой озвучки Татьяной Игоревной Шитовой.

Quiensabe
EndUser
«Испытания умной бомбы сорвались, когда её не смогли выпихнуть из самолёта»