
Привет, Хабр. Обычно я пишу программы для неговорящих людей, но решил удариться в крайности и сделать продукт для говорящих людей. Я хочу рассказать о разработке бота для VK, который переводит пересланные ему голосовые сообщения в текст. Сначала я использовал Yandex SpeechKit, но потом уперся в дневной лимит распознаваемых единиц и перешел на wit.ai, об этом и хочу рассказать, а также о фреймворке для создания ботов vk с помощью node.js, болтовне гугловского dialogflow.
Сделать бота для вк на node.js, который принимает голосовые сообщения, прямые или же пересланные, отправляет их в api распознавания речи и отвечает пользователю распознанным текстом. В ответ на текстовые сообщения бот должен поддерживать диалог с помощью сервиса google.
Для работы с api vk я взял библиотеку node-vk-bot-api, ссылку на которую нашел в официальной документации ВКонтакте, хотя у того же автора есть более крутая библиотека с поддержкой webhooks botact.
Для работы с Google Dialogflow был взят пакет apiai.
Поскольку изначально предполагалось использовать api Яндекса, готовую библиотеку, которого я не нашел, файл для работы с голосовым api написал сам, используя модуль request-promise.
Комментарии в коде русские только в статье, так то я // true programmer
В этом файле мы опишим функцию получания текста из буфера с аудиофайлом:
Вообще wit.ai — это платформа facebook'а для обработки нативной речи для создания ботов с искусственным интеллектом, которая принимает на вход текстовую или голосовую фразу на естественном языке и пробует ответить с помощью нейросетки. Я использую лишь голосовое распознавание, так сказать штырюсь от побочки.
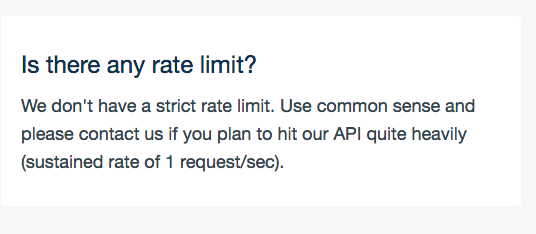
Платформа не имеет никаких лимитов, кроме ограничения в виде одного запроса в секунду, и то отслеживается самой платформой и запрос просто ставится в очередь.
В этом файле мы опишем работу с платформой dialogflow, которая будет отвечать на текстовые сообщения. Почему не wit.ai? У этого две причины. Во-первых, проект развлекательно-развивающий, соответственно целью было попробовать как можно больше технологий, во-вторых изначально использовался speechkit, только после блокировки из-за дневного лимита, было принято экстренное решение перейти на wit.
Код весьма банальный:
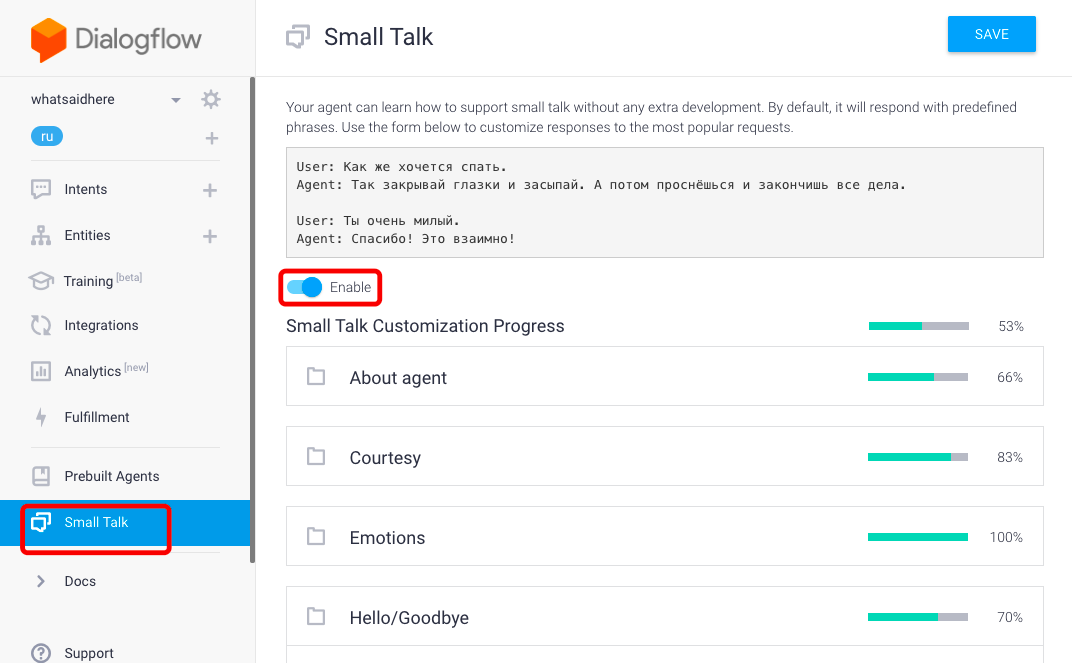
В консоле dialogflow включим и настроим готовый модуль Small Talk из агентов по умолчанию.
Модуль попросит кастомизировать себя с помощью добавления тематических фраз, это займет много времени.
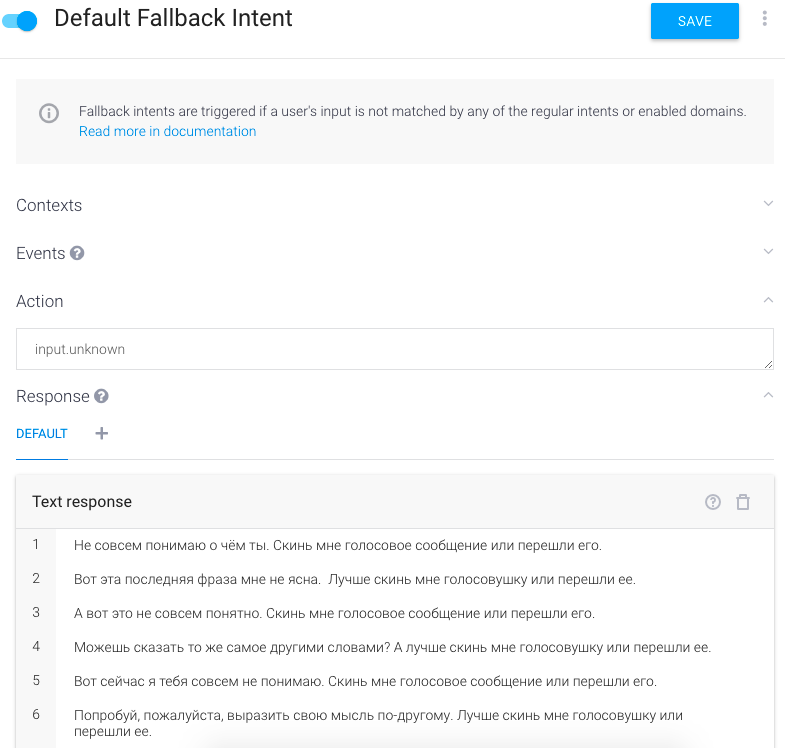
Также необходимо включить Default FallBack Intent, который будет отвечать в случае непонятных запросов.
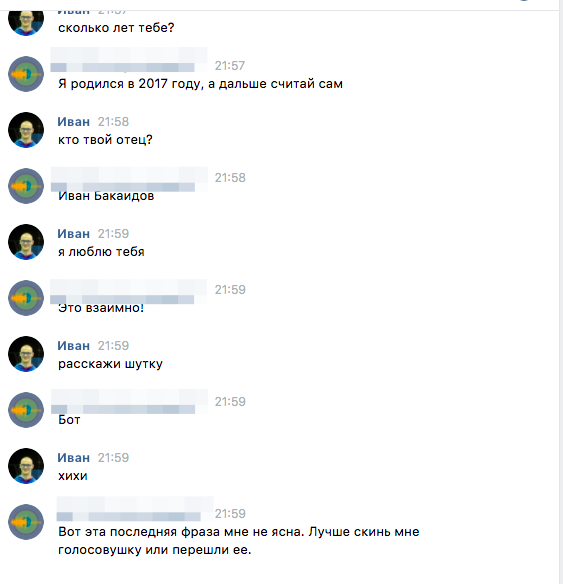
В итоге получается такая вот беседа:
Собираем всё это в главном файле.
Не самый чистый код, есть много косяков и глупостей, но всё же я надеюсь, что рассказал о полезных вам технологиях и вдохновил, что либо сделать с их помощью.
Поскольку тестить бота сам не мог, не говорю, использовал другого бота, который переводил текст в речь.

0. ТЗ
Сделать бота для вк на node.js, который принимает голосовые сообщения, прямые или же пересланные, отправляет их в api распознавания речи и отвечает пользователю распознанным текстом. В ответ на текстовые сообщения бот должен поддерживать диалог с помощью сервиса google.
1. Стэк
Для работы с api vk я взял библиотеку node-vk-bot-api, ссылку на которую нашел в официальной документации ВКонтакте, хотя у того же автора есть более крутая библиотека с поддержкой webhooks botact.
Для работы с Google Dialogflow был взят пакет apiai.
Поскольку изначально предполагалось использовать api Яндекса, готовую библиотеку, которого я не нашел, файл для работы с голосовым api написал сам, используя модуль request-promise.
2. Разделение проекта
Комментарии в коде русские только в статье, так то я // true programmer
2.0 asr.js
В этом файле мы опишим функцию получания текста из буфера с аудиофайлом:
const fs = require('fs')
const request = require('request-promise')
const uri = `https://api.wit.ai/speech`
const apikey = '<...>' // получаем ключ доступа на wit.ai
module.exports = async (body) => {
// отправляем post запрос с буфером аудио
const response = await request.post({
uri,
headers: {
'Accept': 'audio/x-mpeg-3',
'Authorization': `Bearer ` + apikey,
'Content-Type': 'audio/mpeg3',
'Transfer-Encoding': 'chunked'
},
body
})
// парсим ответ и отдаем результат расшифровки
return JSON.parse(response)._text
}Вообще wit.ai — это платформа facebook'а для обработки нативной речи для создания ботов с искусственным интеллектом, которая принимает на вход текстовую или голосовую фразу на естественном языке и пробует ответить с помощью нейросетки. Я использую лишь голосовое распознавание, так сказать штырюсь от побочки.
Платформа не имеет никаких лимитов, кроме ограничения в виде одного запроса в секунду, и то отслеживается самой платформой и запрос просто ставится в очередь.
1. assistent.js
В этом файле мы опишем работу с платформой dialogflow, которая будет отвечать на текстовые сообщения. Почему не wit.ai? У этого две причины. Во-первых, проект развлекательно-развивающий, соответственно целью было попробовать как можно больше технологий, во-вторых изначально использовался speechkit, только после блокировки из-за дневного лимита, было принято экстренное решение перейти на wit.
Код весьма банальный:
const apiai = require('apiai');
// для каждого пользователя будем использовать уникальный идентификатор сессии, но из-за того, что нам лень поднимать дб, мы будем его генерировать из 36 битного ключа, заменяя последние символы на id пользователя
// не делайте так
const uniqid = 'e4278f61-9437-4dff-a24b-aaaaaaaaaaaa';
const app = apiai(‘<...>’);
module.exports = (q, uid) => {
// городим свой промис, так как библиотека стремная
return new Promise((resolve, reject) => {
uid = uid + ''
// don’t touch, magic
const cuniqid = uniqid.slice(0, uniqid.length - uid.length) + uid
// запрос
const request = app.textRequest(q, {
sessionId: uniqid
})
// удача!
request.on('response', (response) => {
resolve(response)
})
// нееееееет!
request.on('error', (error) => {
reject(error);
})
// не знаю зачем, но надо
request.end();
})
}
В консоле dialogflow включим и настроим готовый модуль Small Talk из агентов по умолчанию.
Модуль попросит кастомизировать себя с помощью добавления тематических фраз, это займет много времени.
Также необходимо включить Default FallBack Intent, который будет отвечать в случае непонятных запросов.
В итоге получается такая вот беседа:
2. index.js
Собираем всё это в главном файле.
const vk = require('api.vk.com')
const request = require('request-promise')
const Bot = require('node-vk-bot-api')
const asr = require('./asr')
const assistent = require('./assistent')
const token = require('./token');
// оборачиваем в промис старенький модуль для работы с api
const api = (method, options) => {
return new Promise((resolve, reject) => {
vk(method, options, (err, result) => {
if (err) return reject(err)
resolve(result)
})
})
}
// создаем экземпляр бота
const bot = new Bot({ token })
// вешаем событие на входящие сообщение
bot.on(async (object) => {
// для простоты создадим один catcher ошибок, и при появлении онных будем отвечать пользователю о неудаче
try {
//асинхронно помечаем прочитанность и устанавливаем статус печатанья
api('messages.setActivity', { access_token: token, type: 'typing', user_id: object.user_id })
api('messages.markAsRead', { access_token: token, message_ids: object.message_id })
//переменная, в которую попадет uri аудиосообщения
let uri
// проверяем наличие прикрепленных сущностей
if (object.attachments.length != 0) {
// получаем подробную информацию о сообщении
const [msg] = (await api('messages.getById', { access_token: token, message_ids: object.message_id, v: 5.67 })).items
// проверяем, прикреплена ли вообще аудио запись
if (msg.attachments[0].type != 'audio' || msg.attachments[0].type != 'doc' || msg.attachments[0].doc.type != 5) {
uri = null
}
// выковырываем uri
try {
if (msg.attachments[0].type === 'doc') uri = msg.attachments[0].doc.preview.audio_msg.link_mp3
else if (msg.attachments[0].type === 'audio') uri = msg.attachments[0].audio.url
} catch (e) {
uri = null
}
// обрабатываем пересланное голосовое сообщение
} else if (object.forward != null) {
try {
uri = object.forward.attachments[0].doc.preview.audio_msg.link_mp3
}
catch (e) {
uri = null
}
} else {
uri = null
}
// ошибка авторских прав на аудиозапись
if (uri === '') {
throw ('Не могу послушать это аудио')
}
if (uri == null) {
// если есть текстовое cообщение, отправляем в dialogflow
if (object.body != '') {
const { speech } = (await assistent(object.body, object.user_id)).result.fulfillment
object.reply(speech)
return
}
else {
throw ('Мы не нашли голосовых сообщений. Отправь нам свой голос или перешли его')
}
}
// получаем буфер с аудио
const audio = await request.get({ uri, encoding: null })
let phrase
try {
phrase = await asr(audio)
}
catch (e) {
console.error('asr error', e)
throw ('сбой в распознавании речи')
}
// отправляем результат
if (phrase != null) {
object.reply(phrase, (err, mesid) => { });
} else {
throw ('Не удалось распознать')
}
} catch (error) {
// логируем ошибку и отвечаем пользователю
console.error(error)
object.reply('string' == typeof error ? error : 'Произошла непонятная ошибка. Я не знаю, что делать!')
}
})
// не забываем про главное, включаем long pong.
bot.listen()
Не самый чистый код, есть много косяков и глупостей, но всё же я надеюсь, что рассказал о полезных вам технологиях и вдохновил, что либо сделать с их помощью.
Результат:
Поскольку тестить бота сам не мог, не говорю, использовал другого бота, который переводил текст в речь.
Комментарии (7)


alatushkin
10.01.2018 17:07В своем боте-турагенте с горящими турами/билетами тоже использовал распознавание речи (жизнь слишком коротка чтобы заставлять человека руками набивать «тур на море в конце февраля на 7-10 дней до 25 тысяч»), но в итоге остановился на сервисе от гугла, хотя и с ним были сложности: голосовые сообщения из телеграмма обрабатывались как надо, а вот из ВК — пришлось менять sampling rate.

Assargin
10.01.2018 17:44А можно ссылку на бота?
alatushkin
10.01.2018 17:45Сейчас попробуем)
t.me/departureBot
vk.me/departureBot
На подходе следующая версия. Менее многослованя
VitaliiDel
Спасибо, полезная статья