
Что можно посмотреть вечером или на этих выходных? Можно смотреть какие-нибудь фильмы, а можно — наш непрекращающийся сериал под названием «Java-конференции». Единственный сериал, после просмотра которого у вас может радикально увеличиться зарплата.
Вчерашняя статья про JPoint 2017 оказалась удивительно успешной. У неё почти не было комментариев, но на данный момент — 88 закладок. То есть статья попала в цель: люди добавляют в закладки и смотрят — ура. Буквально в первый час её пришел читать сам Сатана.
Сегодня мы будем действовать по старой схеме: я для вас отсматриваю подряд 10 докладов, делаю короткое описание содержимого, чтобы неинтересное можно было выбросить. Кроме того, с сайтов собираю ссылки на слайды и описания. Полученное сортирую и выдаю в порядке увеличения рейтинга — то есть в самом низу будет самый крутой доклад. Оценки — это не лайки на YouTube, а наша собственная оценочная система, она круче лайков.

10. Блеск и нищета распределённых стримов
Спикер: Виктор Гамов; оценка: 4.24 ± 0.11. Ссылка на презентацию.
Первый слайд:

Понятно, что раз это Виктор, то речь пойдёт о Hazelcast, хоть с первого слайда это и непонятно. Это хороший вводный доклад на тему, как сделать стримы распределёнными, чтобы они наконец-то перестали тормозить (по-настоящему, а не как всегда).
Первым примером Виктор выбирает подсчёт слов — классическую задачу мира программирования. Будет мапа <номер строки в файле-> строка>, нужно посчитать количество слов и вывести топ. Считать будут файлы с текстами песен Disturbed и Lady Gaga.
Можно сделать это на Spark, как делает Женя Борисов. Понятно, что человек-хазелкаст не может опуститься до такого простого уровня.
Первый пример — с помощью стримов из восьмёрки вычитываем строки и натравляем на результат compute — получается типичный подсчёт слов. Дается классификация операций над стримами: промежуточные, терминальные и стейтфул-блокирующие, иллюстрируется на примере картинки с бургером (которую он невозбранно спёр из книжки про лямбды).

Присутствует определенное количество кода на стримах с подробными объяснениями (алгоритмы простые, но позволяют всё хорошо продемонстрировать):
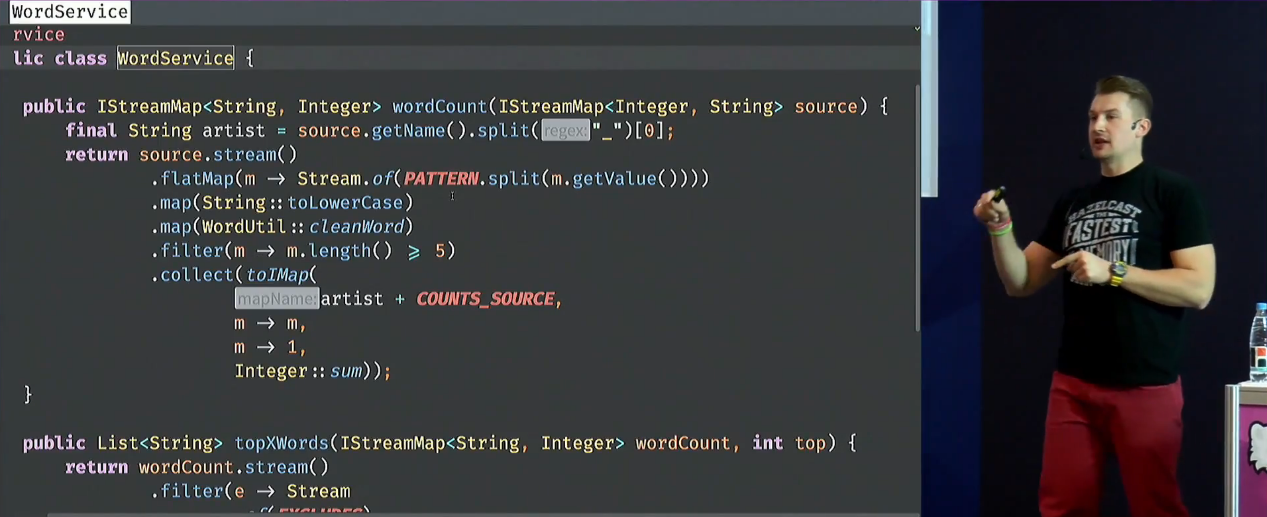
Вопрос не в том, чтобы это написать хоть как-то, а чтобы сделать распределённым. Но интерфейс стримов распределённости не предполагает, нельзя просто так взять и сконвертить готовый код (максимум можно внутри одного процесса что-то сделать с помощью parallelStream, который не факт, что вообще что-то ускорит). Лямбды тоже несериализуемы — просто так взять и переслать на другие ноды их нельзя. Результаты выполнения — тоже.
В 2014 году на JavaOne коллектив людей из Oracle (Гёц, Оливер, Сандоз, ...) рассказали, как юзать эту парадигму для распределённых данных: сделали движок для Hadoop, Coherence и т.п.
В изначальном дизайне библиотеки стримов можно было обычный Stream отнаследовать от DistributedStream, но этого сделано не было, ибо потребовало бы бороться с языком Java, притащить оверхед и так далее. Поэтому нужно DistributedStream наследовать от просто Stream. В Хазле так и сделано.
В Coherence есть, например, RemoteStreams. Там есть готовые коллекторы для стримов, для сборки данных в сериализованном виде. В Infinispan тоже есть куча интересных фишек.
Кроме, собственно, движка, у системы должно быть хорошее юзабилити: мы жабопрограммисты, нам хочется, чтобы всё просто собиралось, фигак-фигак, DevOps не про нас — сразу запихали в варник и шипнули на прод. Все эти вещи обещает решить Hazelcast. Распределённые кэши, распределённые вычисления, распределённое всё, и этим ещё и удобно пользоваться. Горизонтальное масштабирование, вертикальное масштабирование, бэкапы прямо на соседних нодах и т.п.
Но есть и всякие проблемы вроде OOM.

Для демонстрации всех этих штук у Виктора имеется приложение, запиленное на Spring Boot, и внушительная демонстрация того, как грузить данные (локально, не на кластере — но на клаудах он тоже, по его словам, всё это тестил, например, на Heroku). Виктор дальше делает лайвкодинг, и описывать это особо не имеет смысла.
Затем Виктор переходит к Hazelcast Jet и Jet Streams — что это такое и как работает. (Кстати, вам не кажется, что это какой-то ад — столько продуктов называется Jet-что-то там?) Это либа для распределённых вычислений, работает на графовой модели и основана на Hazelcast IMDG. Можно сравнить со Spark и Flink.

Всё это, конечно, подробно описывается. Исполнение графа, тасклеты и т.п. Показывает демки и бенчмарки и на основании этого всего делает выводы. И потом ещё более 10 минут вопросов и ответов.
В этом описании пропущено достаточно инфы, чтобы доклад имело смысл смотреть, а Виктор не распял меня за тотальный спойлеринг всего :-)
Лично для меня доклад ценен тем, что это та штука, которую совершенно точно стоит применять в своих приложениях мгновенно, как понадобятся распределённые стримы.
9. Жизненный цикл JIT кода
Спикер: Иван Крылов; оценка: 4.29 ± 0.07. Ссылка на презентацию.
Крылов — это товарищ из Azul, и по идее он мог бы залиться соловьём про особенности своей крутой VM-ки, но не делает этого. За что ему отдельное большое спасибо.
Говорящая картинка-эпиграф к этому докладу — Crazy House:

Это примерно то, как работает HotSpot. С моей извращённой точки зрения, иногда это даже хорошо — иначе жизнь была бы гораздо более скучной. Из проверенных источников, после смерти всех разработчиков JVM вместо ада отправляют заниматься разработкой JVM.
Доклад будет о трансформации представления кода, профилях кода, деоптимизациях, и более практическая часть — 4 API для тюнинга компиляции. Две трети доклада — про проблематику, оставшаяся часть — практическая.
Вначале рассказывается про конвейер: статическая верификация, неоптимизирующая компиляция, получающийся в результате байткод, верификация в рантайме, линковка, исполняемый код.

Но может быть иначе: байткод может прилететь из какого-нибудь ByteBuddy, виртуалка может быть без интерпретатора, как в JRockit, виртуалка может быть только с интерпретатором и всё, а может быть гибридная виртуалка с AOT, как в Excelsior JET.
Иван рассказывает о том, что профиль — это, по сути, счётчики. Неточные счётчики для вычисления соотношений (а не абсолютные величины). Иногда у этих счётчиков есть дополнительные свойства — это позволяет делать дополнительные оптимизации.
Кроме профиля нужны ещё всякие небольшие интересные штуки. Иллюстрируется на особенностях скомпилированного Enum (в скомпилированном виде он весит больше, чем его текст — как бы намекает, что внутри зашита нетривиальная логика. Эту логику можно посмотреть по байткоду).
Иван показывает, как в общих чертах работает инлайнинг, и рассказывает о том, как однажды он этот инлайнинг случайно сломал (регрессия на 24%). Есть стандартные причины поломок типа: сильно большие методы, слишком большой уровень вложенности, специальные флаги настроек виртуалки, неинициализированные классы, несбалансированные мониторы, содержит байткод jsr и т.п.
Но инлайнинг может не только помочь, но и навредить. Например, когда какие-то методы слишком часто деоптимизируются. Виртуалка может запретить инлайнинг в таких ситуациях.
Дальше речь идёт об уровнях компиляции от 1 до 4. Рассказывается схема переходов, условия, пороги (типа полторы тысячи выполнений для C1) и другие интересные штуки. Если вам вдруг кажется, что вы всё это хорошо понимаете, то… скорей всего, это не так :-)
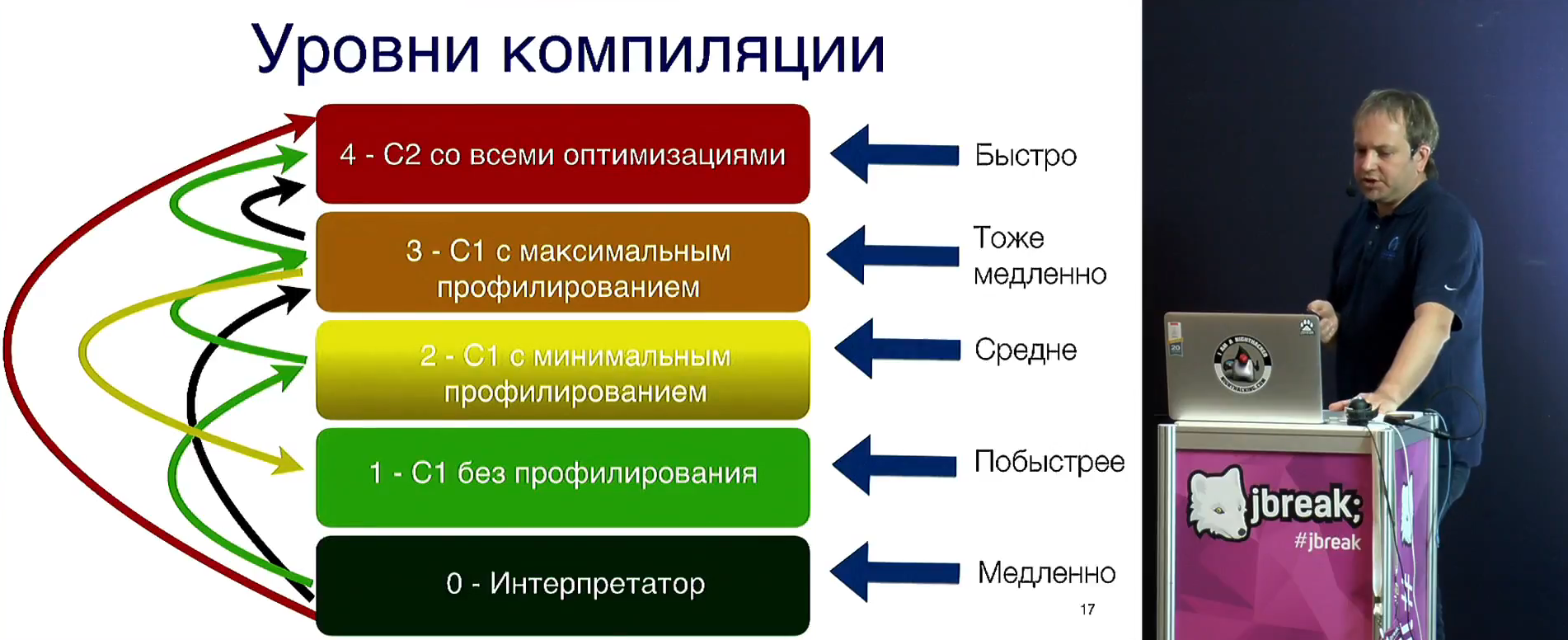
От этого делается переход к деоптимизациям, как они работают, как делятся на классы: детерминированные (constant propagation, с откатом (bias locking, tsx), спекулятивные с мгновенной остановкой (CHA invalidation).
Достаточно много кода должно выполняться по требованиям JVMS: проверки на обнуление, выход за пределы массивов, деление на ноль, проверка типов и т.п. Чтобы код от них не тормозил, JIT изо всех сил пытается доказать, что эти проверки не нужны, и выбросить их. Когда код меняется, эти оптимизации придётся выбросить. Приводится длиннющий список причин деоптимизации.
И завершается доклад подробным описанием API для настройки компилятора, которые связаны с описанной выше проблематикой. Даже если вам (как и мне) интересней копаться в кишочках JVM и экспериментировать, чем реально крутить настройки на проде кровавого ынтерпрайза — эту секцию всё равно стоит прослушать, т.к. там тоже много «мяса» по теме. Ключики просто так не объяснишь, любая попытка объяснить вскрывает дополнительные подробности. В том числе, есть пояснения про то, как это работает в Azul.

Лично я буду использовать этот доклад для того, чтобы быстро вводить новичков в тему. Это хороший (и главное — быстрый) обзор темы про оптимизации и деоптимизации, который не выносит мозг чрезмерным погружением.
8. CRDT. Разрешай конфликты лучше, чем Cassandra
Спикер: Андрей Ершов; оценка: 4.32 ± 0.20. Ссылка на презентацию.
Доклад про ALPS-системы (Available, Low Latency, Partition Tolerant, Scalable). К сожалению, в них неизбежны конкурентные модификации, и приходится понимать, какие изменения — правильные. Большинство систем, например, Cassandra, использует политику LWW (last write wins) — будет показано, почему она не всегда работает. В качестве альтернативы LWW придумали CRDT, которому и посвящена основная часть. В конце — много ссылок для домашней работы, самостоятельного изучения.
Всё это демонстрируется не на голой теории (которую можно и в пейперах почитать), а на примере милой сердцу любого веб-быдлокодера задачки о синхронизации данных в вебморде. Все демки не просто нарисованы на слайдах, а демонстрируются вживую (у Андрея на ноуте запущено 4 приложения).

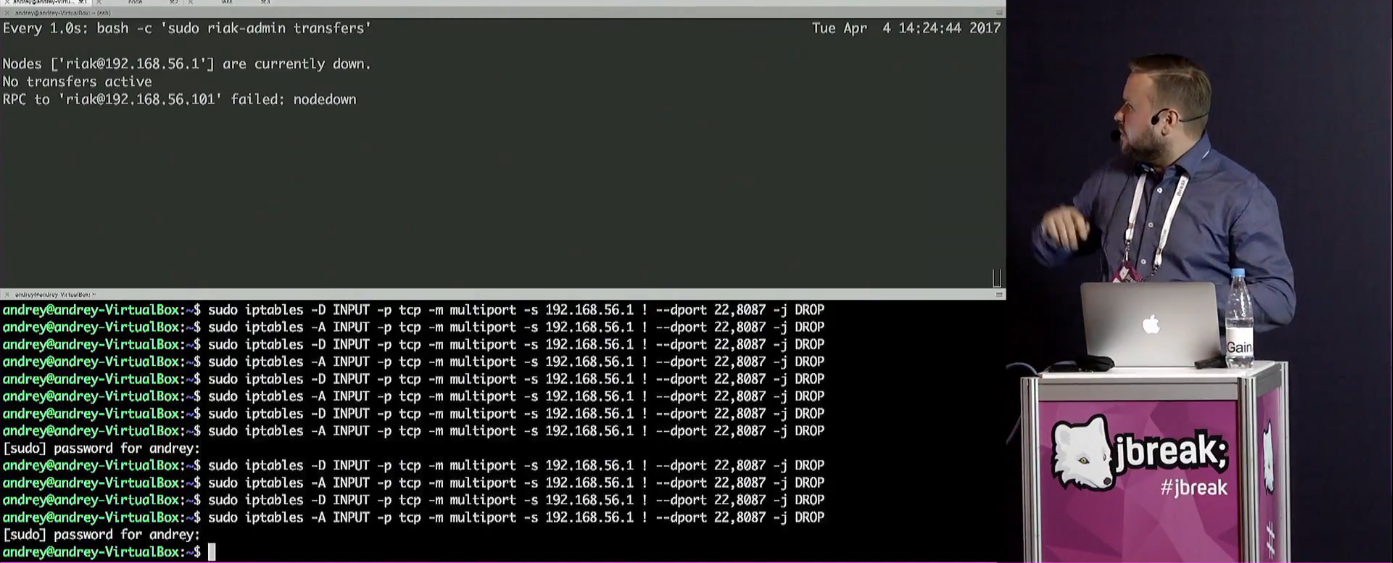
То есть эту приложуху открывают в двух вкладках браузера, но эти вкладки общаются между собой не напрямую, а через базу данных (Riak KV).
Проблемы типа сетевой сегментации тоже демонстрируются — несмотря на то, что все приложухи запущены на одном и том же компьютере. Для этого используется iptables:
Похоже, нас неотступно будут преследовать ссылки на документы, которые стоит изучить. В данном случае способ организации данных в key-value базе освещается вот этим must have документом:

Но все такие сакральные вещи мгновенно демонстрируются на реальном, понятном примере типа распределённой корзины.

Если совсем кратко, то смысл в следующем: если из двух разных вкладок редактируется одно и то же поле, то может возникнуть конфликт. В предлагаемой системе, в веб-интерфейсе отобразится не просто последнее значение, а прямо так и будет написано: «У тебя тут конфликт, что будем делать?».
Рассматриваются вопросы типа ускорения отклика (асинхронная репликация, оптимистичный UI), решение проблем сети (сетевая сегментация, offline work, чтобы работать в самолёте) и т.п. Короче, есть какие-то конкурентные изменения, и проблема с ними решается с помощью CRDT — conflict-free replicated data types.
Рассказывается, что такое Strong Eventual Consistency и, собственно, CRDT (структуры данных со свойством SEC, решающие проблемы конкурентных изменений и автоматически разрешающие конфликты). Структуры данных там почти любые — счётчики, регистры, флаги, списки, сеты, мапы, графы и так далее — всё это можно описать в виде CRDT.
Рассматривается state based CRDT (при изменении состояния объекта передается всё состояние) и их проблемы. Точнее, одну основную проблему — огромный объем данных. Конкретные реализации — Akka и Lasp.
Аналогично рассматривается operation-based CRDT, преимущества и недостатки.

Предлагается прочитать книжку «Reliable and Secure Distributed Programming», обязательно на английском языке, потому что русский перевод — фуфлыжный. После этого переходим к базовому описанию разных видов broadcast: Unreliable, Reliable, FIFO, Global Order. Обсуждается causal broadcast в разных вариантах.
В качестве примера op-based CRDT предлагаются evenuate, swiftcloud и antidotedb.
По результатам обсуждения предыдущих видов CRDT, переходим к Delta-CRDT: требования такие же, как у state-based, а размер — как у op-based. Реализуют их Akka и Riak KV.
Все эти виды CRDT иллюстрируются на реальном примере типа GCounter (grow-only counter) и PNCounter (positive-negative counter) = GCounter + GCounter. Со счётчиками возникают проблемы, и, конечно, тут нам понадобятся Riak Counters. Дальше на очереди — LWWRegister, Version Vector, MVRegister, GSet, 2PSet, OR-Set, AWMap. Всё это с подробным описанием.
Что это значит для меня? Имхо, CRDT — будущее распределённых систем. Область распределённых систем бурно развивается, и нужно поддерживать свои знания в ногу со временем, в частности, читать пейперы и ходить на такие вот доклады. Ну и конечно, раз в Akka запилили delta CRDT, этот вопрос стоит изучить в первую очередь.
7. Java-инспекции в IntelliJ IDEA: что может пойти не так?
Спикер: Тагир Валеев; оценка: 4.33 ± 0.12. Ссылка на презентацию.
Для начала надо понимать, что Тагир — это @lany, и он является живым воплощением хаба Java на Хабре.

Если вы читали его статьи, то легко заметить, чем среднестатистический пост Тагира отличается, например, от моего среднестатистического поста. Они нифига не рекламные и очень качественные. Его доклады на конференциях — лучше, чем посты, и их нужно смотреть. На этом можно было бы поставить точку, но будучи графоманом, остановиться не смогу.
А ещё, для проведения этого доклада пришлось пожертвовать Тагиру мой ноутбук. Он лучше всех работал с проектором, или что-то такое. Если присмотритесь к крышке ноута, увидите на нём единственную круглую наклейку «Это Сбертех, детка!» — не самая очевидная наклейка для сотрудника JetBrains!

Ладно, к делу. Доклад — про написание инспекций для Идеи.
Картинка-эпиграф к докладу: такую ошибку нормальная IDE точно помогла бы предотвратить.

В Идее две тысячи инспекций, большинство из которых — поиск и замена.
Приводится пример хотелки пользователя Идеи, чтобы добавили трансформацию из:
set.stream().collect(Collectors.toList())в более разумный вид:
new ArrayList<>(set)Для тех, кто в танке, Тагир поясняет, почему регулярки — не лучший способ решать эту задачу. Нельзя представлять код в виде набора символов, нужна более абстрактная модель, например, AST. Однако его в нормальной ситуации тоже не хватает. Хватает PSI (Program Structure Interface), который реализован в Идее.
С помощью примерно такого кода можно покрыть сразу целый класс эквивалентных записей:

Дальше Тагир рассказывает про замену, что может пойти не так на этом этапе. Там есть волшебные методы, которые позволяют из строчки сделать фрагмент PSI-дерева и заменить его.

Если писать правильно, то Идея будет автоматически добавлять пропущенные импорты и прочие ништяки (см. вызов shortenClassReferences). Кроме импортов, нормализовывать код можно множеством разных способов, например — автоматически удалив ненужные квалификаторы или приведения типов.
Следующий интересный пример — обработка комментариев. В старых инспекциях, после фикса они просто терялись, в новых — за этим стараются специально следить. Где это возможно, комментарии остаются на своём месте, но не всегда так можно сделать. Например, если мы сворачиваем цикл с удалением до list.removeIf, и в середине цикла были комментарии, то все они уползут наверх и появятся непосредственно над строчкой с вызовом list.removeIf.
Похожие проблемы возникают с тем, что инспекции должны учитывать тот факт, что можно понаставить сколько угодно круглых скобочек в разных местах. Инспекции должны проваливаться внутрь скобочек. Ещё Идея может циклы сворачивать в стримы, и с этим есть дополнительный набор сложностей.
Насколько изначальный и отрефакторенный код семантически эквивалентны? Про это — отдельный большой блок доклада. Вкратце, изменением семантики иногда можно пожертвовать, и некоторые изменяющие семантику инспекции лучше по умолчанию отключить.

Следующие блоки — про дженерики и приведения типов. Как можно догадаться, проблем тут вагон.
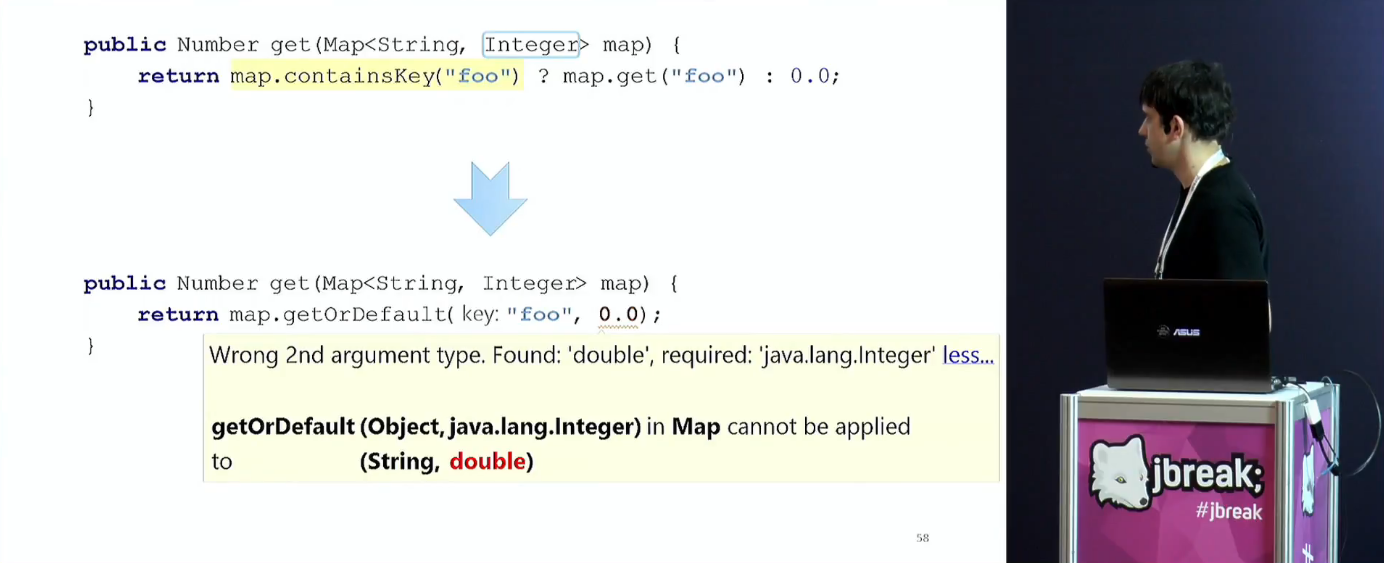
И под конец рассматривается самая жесть — некорректный код. В отличие от корректного кода, некорректным может быть любой, и тут в ход идут особо извращённые и навороченные приёмы.
Лично мне этот доклад очень полезен, потому что написание инспекций для Идеи — одна из вещей, которые я в обязательном порядке буду делать. Зачем это нужно маркетологу — сейчас объяснять не буду, про это будет отдельная статья.
6. Analyzing HotSpot Crashes
Спикер: Volker Simonis; оценка: 4.35 ± 0.14. Ссылка на презентацию.
Фолькер — это товарищ из SAP, систематически рассказывающий всякую жесть о том, как чинить Java, если её вы намерены использовать её так же жестоко, как у него на работе. Обычно там происходят кровь-кишки-расчленёнка, отладка падающих JVM, путешествия по дебрям кода на C++ и ассемблере и так далее.
Этот доклад — не исключение:

Доклад начинается с обзора структуры HotSpot VM

Фолькер как бы намекает, что при починке нам потребуется копаться в этом всём. По сути, это такая фуллстек-задача, где наш «стек» — это кишки JVM. Задача делится на две основные части: понять, в какой части стека случилась ошибка, и затем, используя наши знания об этой части, починить ошибку.
Кстати, это один из немногих докладов Фолькера, где нет настоящего лайвкодинга. Похоже, кода слишком много, чтобы набирать его вручную: он набрал его заранее и упаковал в слайды со скриншотами.
Но надо понимать, что, по сути, это всё-таки процесс отладки, цель доклада в том, чтобы понаблюдать за этим процессом, и описывать в посте всё по шагам несколько бессмысленно, поэтому скажу всего пару слов.
Если кому-то интересно, как можно быстро скрашить JVM:

Важно, что Фолькер показывает свои примеры весьма схематично. Зачастую недостаточно просто скопипастить код, нужно немного подумать. Например, настоящий код из этого краша (только что проверил) должен выглядеть как-то так:
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class Main {
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, ClassNotFoundException {
Class<?> c = Class.forName("sun.misc.Unsafe", false, Main.class.getClassLoader());
Field theUnsafe = c.getDeclaredField("theUnsafe");
theUnsafe.setAccessible(true);
Unsafe u = (Unsafe) theUnsafe.get(null);
u.putInt(0x99, 0x42);
}
}
Напоровшись на грабли, мы, вслед за Фолькером, яростно штудируем логи падения виртуалки:

Роемся в регистрах и стеке:

Обсуждаем генерирование hs_err.log и то, что с ним всё непросто:

Исследуем места падения:

И так далее.
Например, покрашиться можно в интерпретаторе, но при этом не обязательно, что это как-то связано с самим интерпретатором. Возможно, у нас просто поломался хип. Или вот, например, можно таким способом отлаживать Out of Memory (нужно копаться, начиная с флага -XX:+CrashOnOutOfMemoryError и соответствующего лога).
Для меня ценность этого доклада в том, что он даёт конкретный набор ручек, за которые можно ухватиться. Как конкретно смотреть дизассемблер, что прописывать в опции VM, как использовать Serviceability Agent, как использовать replay-файлы и так далее. Что ещё более важно, можно посмотреть за ходом мыслей Фолькера и попытаться научиться думать похожим образом.
Конечно, не каждый день у тебя падает JVM, и ещё меньше шансы того, что ты сможешь починить такой баг (элементарно, у тебя может не быть столько времени, чтобы днями напролёт ползать по логам). Обычно такие баги репортят и ждут, пока их починят профессионалы. С другой стороны, зная вещи, о которых говорит Фолькер, можно, не дожидаясь фикса, придумать какой-то хитрый воркэраунд (не на уровне починки самой JVM, а на уровне лёгкого рефакторинга своего кода на Java).
И с третьей стороны, если ты сам роешься в кишках JVM с целью проведения экспериментов, шанс, что ты что-то разломаешь в пыль, резко растёт. К тому же, если ты роешься в ещё не выпущенной джаве, можно наткнуться на такие проблемы, которые прямо сейчас, вынь да положь, решать тебе никто не будет. Как говорится, in open source no one can hear your scream. Это вряд ли можно считать самым распространённым способом использования полученных из данного доклада знаний, но, если честно, вот это для меня — основное.
5. Kafka льёт, а Spark разгребает!
Спикер: Алексей Зиновьев; оценка: 4.38 ± 0.19. Ссылка на презентацию.
Вначале дается вводная про Спарк и его место в современном мире.
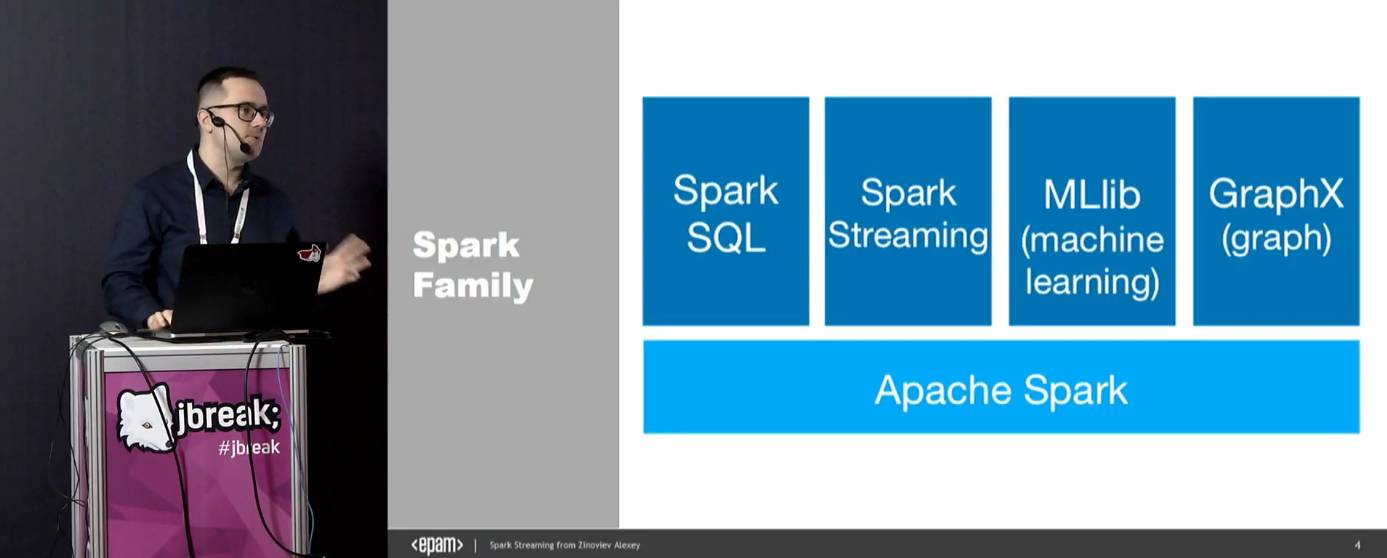
В этом докладе будет фокус на Spark Streaming и Kafka. Сейчас есть запрос не столько на батчевую обработку, сколько на риалтайм, и на это нужно реагировать.
Основные поинты доклада:

Забавно, что в докладе присутствует код как на Java, так и на Scala. Алексей честно признается, что он не суперспециалист в Scala, но иногда использовать её приходится.
Те, у кого загорелось одно место от слова «real-time» применительно к бигдате, сразу есть оговорка, что у нас под риалтаймом будет пониматься что-то, способное выдать ответ за приемлемое время.
Алексей рассказывает про состояние бигдаты в прошлом, когда люди просто лопатили большие куски батчами. О том, что во многом всё это было завязано на отчёты, и модным было строить отчёты поверх Кассандры и Монги. Типичные джобы выполнялись от 5 до 50 часов.
В 2017 году люди скорей хотят что-то вычислять на лету в режиме скользящего окна. Приложение не обязательно чересчур высоконагруженное, и приходящие миллиарды ивентов не обязательно отображать, но нужно учесть и как-то их агрегировать. А ещё сейчас лютый хайп вокруг машинного обучения (и в этом плане хочется переобучать модели, гасить эффект от прошлых моделей и т.п. — короче, нужно интегрировать машинное обучение с риалтаймом). Ещё есть идея о data lake, но она не работает :-)
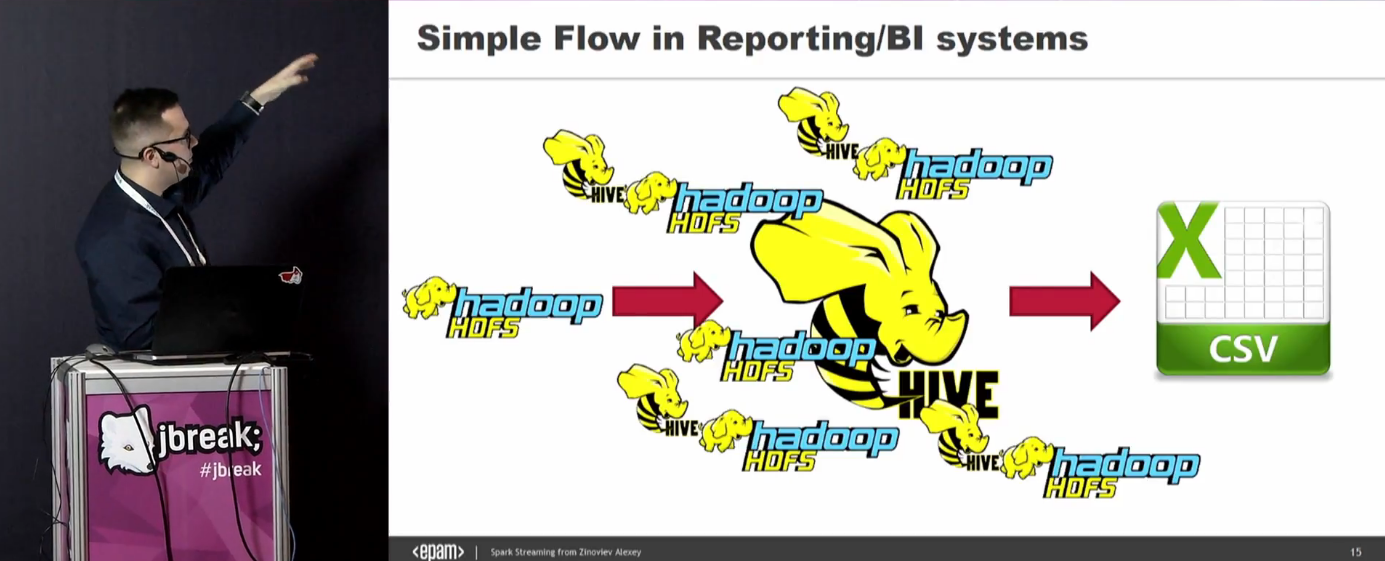
Следующий этап эволюции — Spark. Это хороший кейс, когда надо обработать логи за прошлый год. Но как только логи начинают ротироваться, важность старых логов с каждым днем падает — не лучший вариант. К тому же, всё это надо где-то хранить.
Следующий шаг — использование Кассандры. Там всё в памяти, всё круто быстро работает и т.п. И главное, сделать достаточно несложно — просто льём логи не на диск, а в Кассандру.

Более того, есть коннекторы на cassandra to spark. Но с этим решением есть некоторые проблемы, о которых рассказывается в докладе.
Поэтому мы возвращаемся к старому механизму, отправке сообщений. Publish-subscribe, топики и т.п. Но проблема в том, что JMS не очень хорошо масштабируется в ширину, да и хочется очередь, которая поддерживает всё и сразу — и point to point, и publish-subscribe, и чтобы распределённая была, и чтобы fault tolerance и т.п.
Так мы приходим к Kafka. С Кафкой к нам приезжают два важных преимущества: масштабирование без даунтайма и отсутствие потерь данных при репликации.
Далее Алексей рассказывает терминологию и основы работы Кафки, зачем нужен Zookeeper.

После чего начинается демка с лайвкодингом. Так как кода реально много, он весь был заранее записан на видео, и по ходу доклада просто откручивается на высокой скорости и с подробными комментариями. На демке делается producer, consumer, объясняются группы и в бесконечном цикле генерируются данные.
В Спарке испокон веков есть способы потребления, в том числе из Кафки, так называемые dstreams. Получается микробатчинг, эмуляция стриминга на основе батчинга. Это тут же демонструется на лайвкодерской демке.
После этого мы переходим на второй Спарк и обсуждаем его новое API.

И от этого переходим к концепции бесконечной таблицы. И ко всему этому можно посмотреть веб-интерфейс, длительность всех операций и так далее. Проводится демка «многопоточного задалбывателя Кафки» ©, на выходе печатающего в консоль. В этом месте Алексей окончательно переходит на Скалу.
Но вывод в консоль — это не интересно, а хочется кучу разных других операций: filter, sort, aggregate, join, foreach, explain и т.п. Для этого тоже есть демка.
Дальше мы уходим совсем вглубь и рассматриваем потроха Спарка, смотрим Explain, и так далее:
Глобальная картина всего:

Последняя демка заключается в том, что, в принципе, можно писать из Кафки в Кафку, и таким образом получить граф. После чего демонстрируется финальное демо с реализацией этой мега-задачи.
Уф, кажется, по большинству упомянутых тем пробежал. Конечно, демки и обсуждения я тут даже не затрагивал — а ведь это самая главная часть доклада. Короче, смотрите доклад.
Чем этот доклад полезен для меня? Понятно, что вот прямо сейчас я не рванусь писать бигдату, да и нет у меня никакой «биг» даты. С другой стороны, если такая задача всё же подвернётся — можно будет посмотреть на картину эволюции прошлых лет, описанную Алексеем, и сразу начать с современных решений, а не городить свои заранее устаревшие велосипеды. Ну и переливание из Кафки в Кафку — огонь идея.
4. Техники векторизации кода в JVM
Спикер: Владимир Иванов; оценка: 4.47 ± 0.11. Ссылка на презентацию.
Вопрос залу: «Кто знает, что такое векторизация?»

Судя по лесу рук, сидящим в зале этот час покажется вечностью :-) Вкратце, вот о чём будет доклад:
Основная тема доклада — OpenJDK, автовекторизация в нём, интринсики, которые выигрывают от векторизации, и под конец — немного о будущем.
12 лет назад началась новая эра: мир стал всерьёз задумываться о параллелизации. Throughput однопоточных приложений почти не растёт. Можно добавить серверов, ядер, использовать специальные инструкции. Все современные процы умеют SIMD. Рассматривается, как это выглядит на x86: широкие регистры, инструкции над пакованными векторами и т.п.
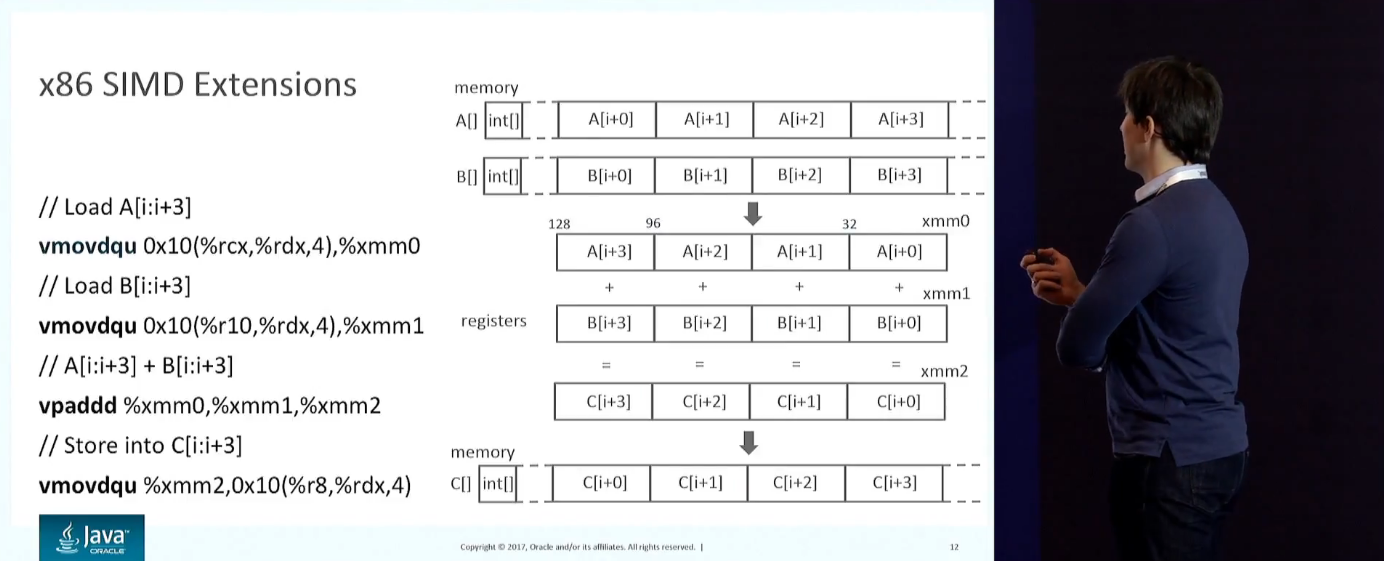
Обсуждаются техники векторизации: автоматическая, полуавтоматическая или напрямую работать с инструкциями (low-level представлениями).
По набору инструкций есть проблема обратной совместимости. Можно код написать сразу на нескольких разных наборах инструкций (надо автоматически определять, что доступно). Anger Fog на эту тему доказывал, что расходы на это невероятно большие, плюс есть огромный список проблем. JVM в этом смысле в привилегированном положении, так как байткод переносимый, и JVM всё знает о машине, на которой запускается.
В хотспоте есть куча уже готовых SIMD-инструкций, можно делать автоматическую векторизацию, и есть соответствующие интринсики типа копирования массивов. Обсуждается алгоритм -XX:+UseSuperWord и что такие оптимизации работают только над счётными циклами.

Показываются опции для проверки этого (-XX:+PrintCompilation, -XX:+TraceLoopOpts), или можно просто сделать -XX:+PrintAssembly и вычитать всё это глазами. Приводится большое количество примеров циклов, и аудитории предлагается сказать — являются ли они оптимизируемыми. Показывается в ассемблере, как выглядят развёрнутые циклы и как их можно случайно поломать. Обсуждается, почему именно такой код генерится и как это связано с выравниванием.
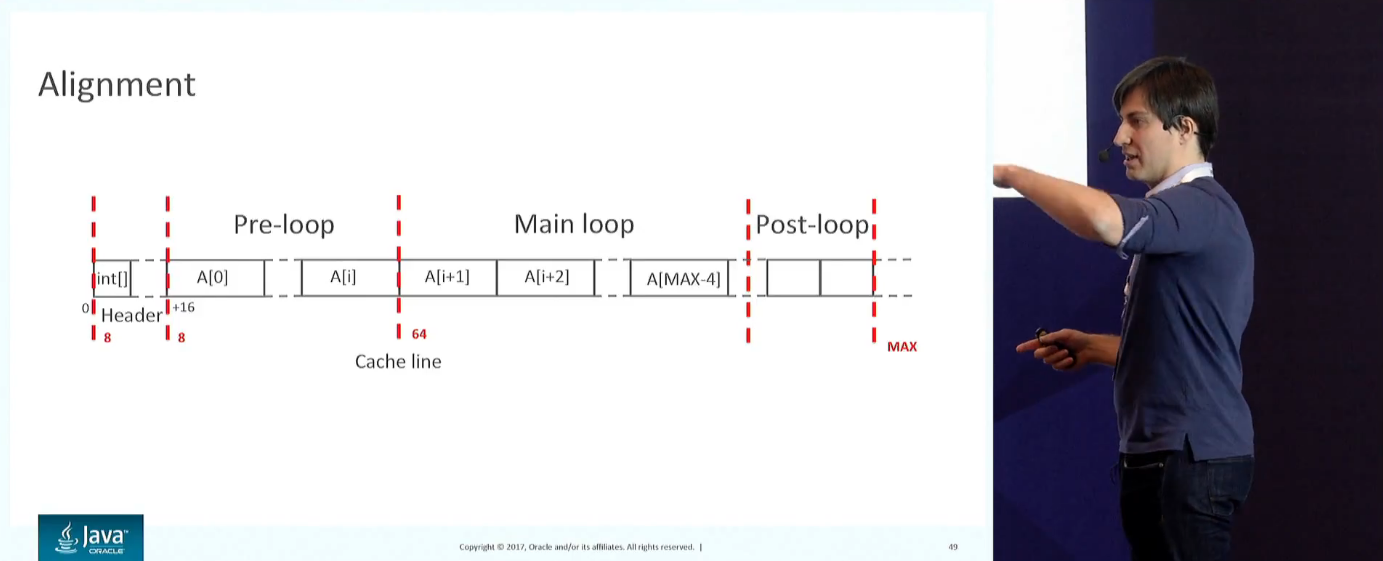
По ходу дела рассматриваются разные способы ускорения типа Fused Operations, всё это в контексте разного нижележащего железа и версии JDK. Ну и AVX-512, увеличивший в 10 раз количество инструкций на x86.

Под конец упоминаются интринсики: System.arraycopy, Arrays.copyOf и, начиная с Девятки: Arrays.mismatch, ArraysSupport.vectorizedMismatch.
Подводятся итоги того, в каком состоянии находится экосистема Java относительно использования SIMD в 2017 году. И из этого напрямую делается вывод о необходимости проекта Panama, в котором происходит разработка векторных API. Подробно рассказывается о проекте: о текущем статусе, проблемах, перспективах и связи с другими проектами в OpenJDK.

Для меня этот доклад важен тем, что даёт понимание текущего статуса одного из самых перспективных направлений разработки JVM. Если бы я мог взять и вбухать всё своё свободное и рабочее время в какой-то из проектов OpenJDK, эта тема была бы, пожалуй, на самой вершине (но сразу после Graal & Truffle, которых вышибить с первого места невозможно).
3. Перформанс: Что В Имени Тебе Моём?
Спикер: Алексей Шипилёв; оценка: 4.47 ± 0.06. Ссылка на презентацию.
Так получилось, что в топе у нас есть всего два доклада, которые были одновременно и на JPoint, и на JBreak. И оба эти доклада сделаны Лёшей.
Этот доклад рассматривался вчера, в предыдущей статье о лучших докладах JPoint 2017. По второму разу его описывать не буду, переходите по ссылке.
2. Java 9 Модули. Почему не OSGi?
Спикер: Никита Липский; оценка: 4.60 ± 0.06. Ссылка на презентацию.
Как следует из названия, разговор будет целиком о модулях и об OSGi. Для тех, кто ещё не в курсе (т.е. посмотрел недостаточно докладов JUG.ru Group), Никита Липский — это разработчик совершенно самостоятельной реализации Java Excelsior JET, пилит её более 17 лет (то есть стоял у истоков Java вообще), является идейным вдохновителем проекта и практикующим компиляторщиком. То есть входит в очень небольшой круг людей, которые не просто смотрят и имплементят результаты чьей-то архитектурной работы, а активно в ней участвует. Это, конечно, не Mark Reinhold (большинство из нас всё-таки используют OpenJDK, а не JET, поэтому его мнение было бы более в кассу), но уже близко к тому.
В Java 9 появились модули, и, очевидно, к нам приехали проблемы. В тот момент, когда Никита делал этот доклад, Девятка всё ещё не была выпущена, поэтому он говорит в будущем времени. Тем не менее, как и с любыми более-менее фундаментальными докладами, прошедший год на актуальности информации почти не сказался.
Вначале даётся вводная о стандартном вопросе обычного разработчика: зачем мне модули, если уже есть Maven и OSGi. Если с Maven всё более-менее понятно (например, клеш версий зависимостей, который мы чиним из года в год), то с OSGi всё мутней.
Нацлидер скажет в этом месте что-то вроде такого:

Тут некоторые люди сразу оказались по обе стороны баррикады: как исследователям OpenJDK, этот аргумент, безусловно, катит. Но как конечным пользователям нам, в общем-то, всё равно — главное, чтобы OpenJDK работало, а как будут мучиться его корные разрабы и исследователи — ССЗБ (сами себе злобные бараны).
Дальше идёт вводная про то, что такое OSGi, как он работает, какие у него есть реализации и почему это могло бы быть хорошо.

Дальше подробно разбираются проблемы OSGi. Всё это иллюстрируется диаграммами, вроде вот этой схемы версионирования:

Мы проходимся по модульности, обновлениям на лету (помним, что нельзя так просто взять и выгрузить класс, classloader memory leaks, вот это всё). Проблемы с версионированием и то, что OSGi никак не помогает избежать нарушения loading constraints (погуглите по слову «LinkageError», чтобы оценить масштаб проблемы). Иначе говоря, чтобы избежать этой проблемы, существует единственное решение — не использовать внутри программы библиотеку двух разных версий. Это развенчивает миф о том, что OSGi эту проблему, якобы, решает.
Но самое ужасное в другом. У JVM по стандарту не определён порядок загрузки. Разные JVM (или одна, но с разными настройками), могут загружать их либо лениво (ссылки разрешаются при первом доступе), либо энергично (сразу разрешаются все доступные ссылки). OSGi не работает с энергичной загрузкой! Он работает только по тому чудесному стечению обстоятельств, что в HotSpot по умолчанию сделана ленивая подгрузка. Но по сути, это мина замедленного действия — однажды в OpenJDK порядок загрузки классов изменится, и всё сломается. Это ужас-ужас, особенно учитывая, что такие работы уже ведутся (привет, Graal & Truffle!).
Я тут описываю упрощённо, и если интересны детали (а также если вам кажется, что в этой аргументации есть изъяны) — обязательно читайте доклад. Кстати, Никита присутствует на Хабре @pjbooms и может быть, если система оповещения Хабра опять не заглючит, увидит ваши комментарии и что-нибудь ответит.
С другой стороны, в Jigsaw изначально думали над разными способами использования, и в этом плане там всё очень хорошо. Обсуждается «мантра Jigsaw»: «reliable configruation + strong encapsulation» и её реализация в текущих реалиях и делается некое заключение:

И потом десять минут вопросов, конечно.
Чем этот доклад оказался полезен лично для меня? Да всем. Это один из тех редких докладов, который как бы и про advanced топик на тему работы JVM, и must have при проектировании и реализации почти любого приложения чуть больше хэлловорлда. Если взять самый-самый глобальный вывод для себя: на OSGi смотреть с опаской и самостоятельно не использовать (чем более low level проект, чем больше там хаков — тем сильней становится желание даже не прикасаться), а вот новые модули — наоборот внедрять везде и наработать хорошие практики их использования (даже если сейчас кажется, что «нафиг они нужны» — это иллюзия). На какие темы нарабатывать практики — этот доклад является отличным руководством.
1. Shenandoah: сборщик мусора, который смог
Спикер: Алексей Шипилёв; оценка: 4.62 ± 0.06. Ссылка на презентацию.
Так получилось, что в топе у нас есть всего два доклада, которые были одновременно и на JPoint, и на JBreak. Оба эти доклада сделаны Лёшей. «Сборщик мусора, который смог» на обеих конференциях оказался #1 в топе зрительских оценок.
Этот доклад рассматривался вчера, в предыдущей статье о лучших докладах JPoint 2017. По второму разу его описывать не буду, переходите по ссылке.
Заключение
В этой статье мы кратко рассмотрели все самые популярные доклады на JBreak 2017. Вполне возможно, по большинству из них будут выпущены отдельные статьи на Хабре с подробными расшифровками.
Крайне рекомендую самостоятельно пробежаться по всем этим докладам и сделать собственные выводы. Каждый из докладов занимает всего около часа.
История JBreak на этом, конечно, не заканчивается. В этом году, 4 марта 2018, на площадке Новосибирского Экспоцентра пройдёт следующий JBreak 2018, на котором будет много новых, интересных и полезных докладов. Приобрести билеты можно уже сейчас.
lany
Сейчас мы, кстати, вышли на новый уровень фанатизма с комментариями. У нас гоняются рандомные проперти-тесты, где в различные джава-файлы вставляются комментарии в самые сумасшедшие места, потом применяются любые интеншны и квик-фиксы и проверяется, что все комментарии остались в коде. Многие старые инспекции уже починили на этот счёт. Сегодня мне свалилось, например, такое:
Может никому и не придёт в голову вставлять сюда комментарий, но мы это починим :-)
olegchir Автор
Такой Chaos Monkey, но не для микросервисов? :)
А где лежит этот тест, чтобы найти в исходниках Community Edition и заценить?
lany
JavaCodeInsightSanityTest#testPreserveComments и далее, там довольно развесистая система.
В некотором смысле да, даже названия классов намекают.