

За последнее десятилетие глубокие нейросети (Deep Neural Networks, DNN) превратились в превосходный инструмент для ряда ИИ-задач вроде классификации изображений, распознавания речи и даже участия в играх. По мере того, как разработчики пытались показать, чем обусловлен успех DNN в сфере классификации изображений, и создавали инструменты для визуализации (например, Deep Dream, Filters), помогающие понять, «что» именно «изучает» DNN-модель, возникло новое интересное применение: извлечение «стиля» из одного изображения и применение к другому, иного содержания. Это назвали «переносом визуального стиля» (image style transfer).
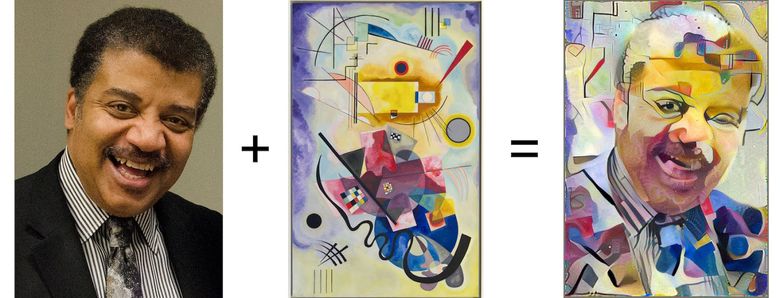
Слева: изображение с полезным содержимым, в центре: изображение со стилем, справа: содержимое + стиль (источник: Google Research Blog)
Это не только всколыхнуло интерес многих других исследователей (например, 1 и 2), но и привело к появлению нескольких успешных мобильных приложений. За последние пару лет эти методы переноса визуального стиля сильно улучшились.

Перенос стиля от Adobe (источник: Engadget)

Пример с сайта Prisma
Короткое введение в работу подобных алгоритмов:
Однако несмотря на достижения в работе с изображениями, применение этих методик в других областях, например, для обработки музыки, было весьма ограниченным (см. 3 и 4), а результаты вовсе не такие впечатляющие, как в случае с изображениями. Это наводит на мысль, что в музыке переносить стиль гораздо сложнее. В этой статье мы рассмотрим задачу подробнее и обсудим некоторые возможные подходы.
Почему так трудно переносить стиль в музыке?
Давайте сначала ответим на вопрос: что такое «перенос стиля» в музыке? Ответ вовсе не так очевиден. В изображениях концепции «содержимого» и «стиля» интуитивно понятны. «Содержимое изображения» описывает представленные объекты, например, собак, дома, лица и так далее, а под «стилем изображения» понимаются цвета, освещение, мазки кисти и текстура.
Однако музыка по своей природе семантически абстрактна и многомерна. «Содержимое музыки» может означать разные вещи в разных контекстах. Зачастую содержимое музыки ассоциируется с мелодией, а стиль — с аранжировкой или гармонизацией. Однако содержимым может быть и текст песни, а разные мелодии, использованные для пения, можно интерпретировать как разные стили. В классической музыке содержимым можно считать партитуру (включающую в себя и гармонизацию), в то время как стилем будет интерпретация нот исполнителем, который привносит свою собственную экспрессию (варьируя и добавляя от себя какие-то звуки). Чтобы лучше понять суть переноса стиля в музыке, посмотрите пару этих видео:
Во втором ролике использованы различные методики машинного обучения.
Итак, перенос стиля в музыке по определению трудно формализовать. Есть и другие ключевые факторы, усложняющие задачу:
- Машины ПЛОХО понимают музыку (пока): успех в переносе стиля в изображениях проистекает из успеха DNN в задачах, связанных с пониманием изображений, например, распознавании объектов. Поскольку DNN могут разучивать свойства, меняющиеся у разных объектов, то методики обратного распространения (back-propagation) могут использоваться для изменения целевого изображения, чтобы оно соответствовало свойствам содержимого. Хотя мы достигли значительного прогресса в создании моделей на основе DNN, способных разбираться в музыкальных задачах (например, транскрибирование мелодии, определение жанра и тому подобное), нам ещё далеко до высот, достигнутых в обработке изображений. Это серьёзное препятствие для переноса стиля в музыке. Имеющиеся модели просто не могут разучить «прекрасные» свойства, позволяющие классифицировать музыку, а значит прямое применение алгоритмов переноса стиля, используемых при работе с изображениями, не даёт такого же результата.
- Музыка скоротечна: это данные, представляющие собой динамические ряды, то есть музыкальный фрагмент изменяется со временем. Это усложняет обучение. И хотя рекуррентные нейросети и LSTM (Long Short-Term Memory, долгая краткосрочная память) позволяют эффективнее обучаться на скоротечных данных, нам ещё предстоит создать надёжные модели, способные научиться воспроизводить долгосрочную структуру музыки (примечание: это актуальное направление исследований, и учёные из команды Google Magenta добились в этом некоторого успеха).
- Музыка дискретна (как минимум на символьном уровне): символьная, или записанная на бумаге музыка по своей природе дискретна. В равномерно темперированном строе, наиболее популярной сегодня системе настройки музыкальных инструментов, звуковые тоны занимают дискретные позиции на непрерывной шкале частот. При этом длительность тонов тоже лежит в дискретном пространстве (обычно выделяют четвертные тоны, полные тоны и так далее). Поэтому очень сложно адаптировать пиксельные методы обратного распространения (используемые для работы с изображениями) в сфере символьной музыки.
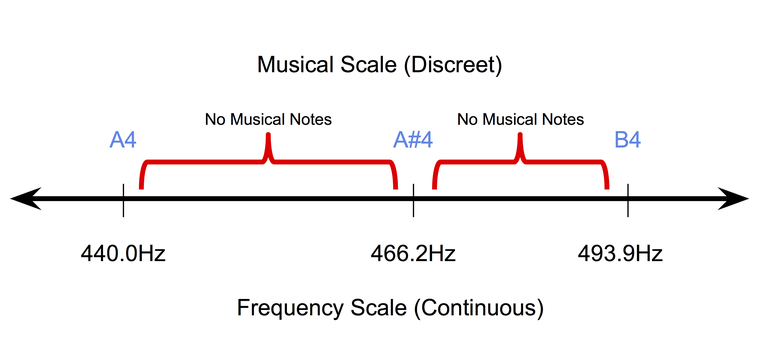
Дискретная природа музыкальных нот в равномерно темперированном строе.
Следовательно, методики, используемые для переноса стиля в изображениях, не применимы в музыке напрямую. Для этого их нужно переработать с акцентом на музыкальные концепции и идеи.
Для чего нужен перенос стиля в музыке?
Зачем вообще нужно решать эту задачу? Как и в случае с изображениями, потенциальные применения переноса стиля в музыке довольно интересны. Например, разработка инструмента в помощь композиторам. Скажем, автоматический инструмент, способный трансформировать мелодию с использованием аранжировок из разных жанров, будет крайне полезен для композиторов, которым нужно быстро попробовать разные идеи. Заинтересуются такими инструментами и диджеи.
Косвенным результатом подобных изысканий будет значительное улучшение систем музыкальной информатики. Как пояснялось выше, чтобы в музыке работал перенос стиля, создаваемые нами модели должны научиться лучше «понимать» разные аспекты.
Упрощение задачи переноса стиля в музыке
Начнём с очень простой задачи по анализу монофонических мелодий в разных жанрах. Монофонические мелодии — это последовательности нот, каждая из которых определяется тоном и длительностью. Тоновая прогрессия по большей части зависит от звукоряда мелодии, а прогрессия длительности зависит от ритма. Так что сначала чётко разделим «тоновое содержимое» (pitch content) и «ритмовый стиль» (rhythmic style) в качестве двух сущностей, с помощью которых можно перефразировать задачу переноса стиля. Также при работе с монофоническими мелодиями мы сейчас будем избегать задач, связанных с аранжировкой и текстом.
В отсутствие заранее обученных моделей, способных успешно различать тоновые прогрессии и ритмы монофонических мелодий, мы сначала прибегнем к очень простому подходу к переносу стиля. Вместо того, чтобы пытаться изменить тоновое содержимое, выученное на целевой мелодии, ритмовым стилем, выученным на целевом ритме, мы попытаемся по отдельности обучить паттернам тонов и длительностей из разных жанров, а затем попробуем объединить их. Примерная схема подхода:
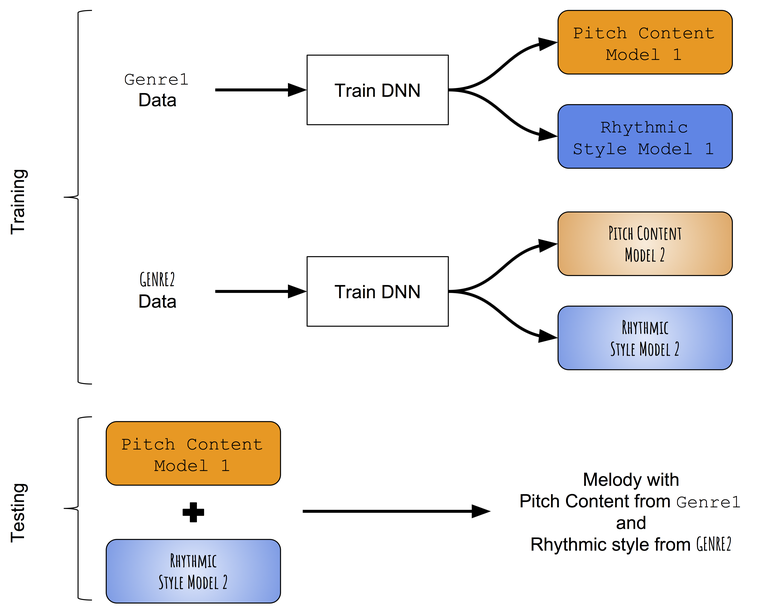
Схема метода межжанрового переноса стиля.
Обучаем отдельно тоновым и ритмовым прогрессиям
Представление данных
Мы представим монофонические мелодии как последовательность музыкальных нот, каждая из которых имеет индекс тона и последовательности. Чтобы наш ключ представления был независимым, воспользуемся представлением на основе интервалов: тон следующей ноты будет представлен как отклонение (± полутоны) от тона предыдущей ноты. Создадим два словаря для тонов и длительностей, в которых каждому дискретному состоянию (для тона: +1, -1, +2, -2 и так далее; для длительностей: четверть ноты, полная нота, четверть с точкой и так далее) присвоен индекс словаря.
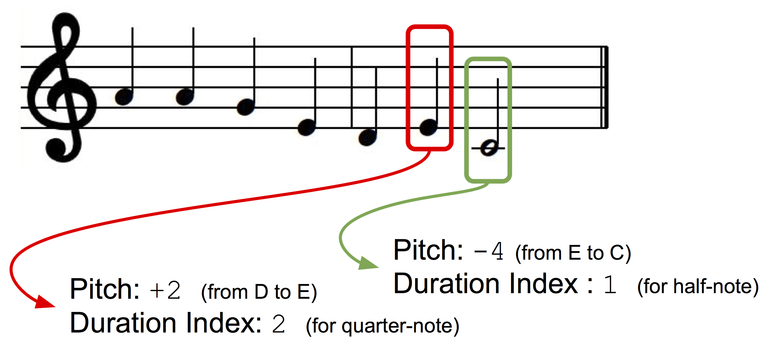
Представление данных.
Архитектура модели
Воспользуемся такой же архитектурой, которую использовали Коломбо с коллегами — они одновременно обучали две LSTM-нейросети одному музыкальному жанру: а) тоновая сеть училась предсказывать следующий тон на основе предыдущей ноты и предыдущей длительности, б) сеть длительностей училась предсказывать следующую длительность на основе следующей ноты и предыдущей длительности. Также перед LSTM-сетями мы добавим уровни встраивания (embedding layer) для сопоставления индексов входных тона и длительности в заучиваемых пространствах встраивания. Архитектура нейросети показана на картинке:
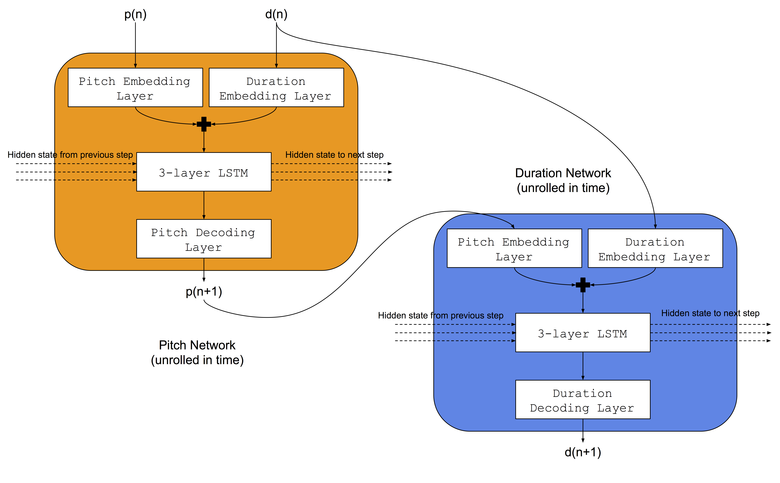
Процедура обучения
По каждому жанру сети, отвечающие за тоны и длительности, обучаются одновременно. Мы воспользуемся двумя датасетами: a) Norbeck Folk Dataset, охватывающий около 2000 ирландских и шведских народных мелодий, б) джазовый датасет (публично не доступен), охватывающий около 500 джазовых мелодий.
Слияние обученных моделей
При тестировании мелодия сначала генерируется с помощью тоновой сети и сети длительностей, обученных на первом жанре (допустим, фолк). Затем последовательность тонов из сгенерированной мелодии используется на входе для сети последовательностей, обученной на другом жанре (скажем, джазе), и в результате получается новая последовательность длительностей. Следовательно, мелодия, созданная с помощью комбинации двух нейросетей, имеет последовательность тонов, соответствующей первому жанру (фолк), и последовательность длительностей, соответствующих второму жанру (джаз).
Предварительные результаты
Короткие отрывки из некоторых получившихся мелодий:
Фолк-тоны и фолк-длительности

Выдержка из нотной записи.

Выдержка из нотной записи.
Джаз-тоны и джаз-последовательности

Выдержка из нотной записи.
Джаз-тоны и фолк-последовательности

Выдержка из нотной записи.
Заключение
Хотя текущий алгоритм неплох для начала, у него есть ряд критических недостатков:
- Невозможно «перенести стиль» на основе конкретной целевой мелодии. Модели обучаются паттернам тонов и длительностей на жанре, а значит все трансформации определяются жанром. Было бы идеально изменять музыкальный фрагмент в стиле конкретной целевой песни или фрагмента.
- Невозможно управлять степенью изменения стиля. Был бы очень интересно получить «ручку», управляющую этим аспектом.
- При слиянии жанров невозможно сохранить музыкальную структуру в трансформированной мелодии. Долгосрочная структура важна для музыкальной оценки в целом, а чтобы сгенерированные мелодии были музыкально эстетичны, структура должна сохраняться.
В следующих статьях мы рассмотрим способы обхода этих недостатков.
Комментарии (5)

{kind=link}

SADKO
18.01.2018 16:45Скажем, автоматический инструмент, способный трансформировать мелодию с использованием аранжировок из разных жанров, будет крайне полезен для композиторов, которым нужно быстро попробовать разные идеи.
А вы пробовали Band in Box или Korg Karma?
ИМХО есть некоторая подмена понятий, как в случае со «стилизацией» изображений, так и с музыкой. Вот тётенька играет хэппи бёздэй, «стилизуя его», а по сути подаёт его в контексте музыкальных отрывков семантически ассоциирующихся их авторами (по простому, тупо узнаваемыми), и подгоняя экспрессию.
Ок, а если мы возьмём менее известные произведения тех-же авторов, и\или слушателей для которых эти-же произведения не известны, и предъявив им примеры неизвестных авторских произведений, попросим определить этот хэппибёздэй, он чей?
То-же и графикой, это для лохов такая стилизация чудо, но тем кто в теме понятно что происходит, из предъявленного примера «стиля» делают мозаику сэмплов, а потом из них пытаются сложить наиболее близкое подобие исходного изображения, усё…
Фигня в том, что экспрессия красок и деструкцией форм, которую обыватель принимает за стиль художника, не статичны, а несут смысловую нагрузку в конкретном произведении и тупо переносить этот стиль, ну это как последние конвульсии пост-советской эстрады под стили YAMAHA PSS…
PS.Я в начале не с проста помянул Карму, ИМХО один из первых инструментов пытающихся понять, а что-же ты на нём играешь, и соответственно подстроить свою шарманку.

arTk_ev
18.01.2018 17:36Очень странное решение было выбрано. Музыка не является дискретной. В чем проблема разложить звук на спект частот, с помощью Фурье. Затем обучать гармоникам, чтобы классифициоровать мелодию и тональность. А все остальное — это и есть стиль.
И уже у гугла есть решение по обучению акценту синтетичексокой речи, очень похожие области.
Хотя для непрырвного и волного сигнала лучше подходит голограммные сети, если не ошибаюсь
daiver19
Вы музыку, обычно, по бумаге читаете? Музыка — это непрерывный поток колебаний. Делать модель на простенькой одномерной последовательности — это уж слишком примитивный подход.
Ayahuaska
Колебания сами по себе дискретны (: