

Разбором инцидентов в нашей компании занимается отдел эксплуатации (или, проще, support). Поэтому начну с описания того, как он устроен. В Туту.ру у нас есть некоторый набор продуктов, это — ЖД, авиа, туры, электрички, автобусы. В команде каждого продукта есть специалисты отдела эксплуатации. Также представители нашего отдела есть в кроссфункциональной и инфраструктурной командах.
Мы отвечаем за то, чтобы у наших пользователей не возникало проблем при использовании сервиса. Сюда входят специфичные для конкретной команды задачи по поддержке наших внешних и внутренних клиентов, а также работа, направленная на то, чтобы при всей скорости изменений, сайт переживал отказы оборудования, выдерживал нагрузки и продолжал решать задачи пользователей хорошо и быстро.
Инцидент (или сбой, ЧП) — это некая критическая (обычно массовая) проблема, которая существенно снижает доступность, корректность, эффективность или надежность бизнес-функционала или инфраструктурных систем.
В рамках процесса управления инцидентами мы ставим перед собой следующие основные цели:
1. Как можно быстрее восстановить работоспособность наших систем.
2. Не допускать возникновения одного и того же сбоя дважды.
3. Своевременно информировать заинтересованных лиц.
Как работали раньше:
У нас была самописная система мониторинга, которая подразумевала самостоятельную подписку сотрудников на сообщения о проблемах. То есть, алерты получал только тот, кто сам на них подписался. О сбоях мы узнавали от этой системы, и дальше действовали довольно разрозненно — кто-либо из эксплуатации получал смс, начинал смотреть, что происходит, приходил к нужным для решения или анализа проблемы людям (или звонил им, если речь о нерабочем времени), и сбой в итоге решался. Потом кто-нибудь писал отчет о сбое в принятом на тот момент формате (описание проблемы и причин, хронология и набор запланированных действий, направленных на «неповторение»).
При этом, существовали очевидные проблемы:
1. Не было полной уверенности в том, что на критичный алерт кто-либо подписан. То есть существовала вероятность, что сбой будет замечен уже тогда, когда затронет другие критические части системы.
2. Не было ответственного за решение проблемы, который добьется ее устранения в кратчайшие сроки. Также непонятно, у кого уточнять актуальный статус.
3. Не было возможности следить за информацией об инциденте в динамике.
4. Отсутствовало понимание того, увидел ли кто-либо сообщение от мониторинга? Среагировал ли? Какие уже выяснили подробности, и есть ли прогресс в решении?
5. Несколько специалистов дублировали действия друг друга. Смотрели те же логи/графики, шли к тем же людям, и отвлекали их повторными вопросами о том, знают ли они о проблеме, на какой стадии решение и так далее.
6. Для тех, кто непосредственно не участвовал в решении инцидента, было сложно получить информацию о его причинах, способах починки и о том, что происходило. Потому что нигде не фиксировалось, кто и чем занимается.
7. Не было одинакового понимания, что нужно писать в отчете о сбое, а что нет, насколько глубоко погружаться в разбор. Не было понятного процесса формулирования «экшенов» на улучшение. В результате отчеты о сбоях могли быть неполными, часто выглядели по-разному. По ним было сложно понять, какой был эффект, каковы причины, что делали в процессе решения, и как именно починили.
8. В разбор ЧП погружались только специалисты саппорта и те, кто непосредственно занимался устранением причин и негативного эффекта. В результате далеко не все заинтересованные получали обратную связь о проблемах.
При таком процессе обработки сбоев мы не достигали стоящих перед нами целей. Одинаковые инциденты случались, а имеющиеся отчеты не сильно помогали нам справиться с подобными сбоями в будущем. Отчеты не всегда отвечали на важные вопросы — как решилась проблема, все ли необходимое было предпринято для неповторения, и если нет, то почему. К тому же, несогласованность наших действий в момент возникновения инцидента не способствовала ускорению времени решения, особенно с увеличением численности отдела.

Что сделали:
- Разделили работу с инцидентами на две фазы — активную и ретроспективную — и начали улучшать каждую из них по отдельности.
- Разработали стандарт обработки ЧП, где зафиксировали все требования и соглашения, описали набор действий, которые обязательны для каждой фазы процесса.
- Начали писать документы-рекомендации, в которых собрали хорошие практики для разных этапов процесса разбора инцидентов.
Теперь подробнее об этих изменениях.
Активная фаза
Направлена на достижение первой цели процесса — быстрое восстановление работоспособности наших систем.
В начале работы по улучшению этой фазы у нас сильно «болело» отсутствие эффективной коммуникации даже внутри отдела эксплуатации. В рабочее время мы могли общаться по проблемам в skype-чате отдела, но командный чат предназначен для любых рабочих вопросов. Он не предусматривает мгновенную реакцию на сообщения, и в нерабочее время не все участники команды пользуются этим инструментом.
Поэтому мы решили, что нам нужен отдельный канал для коммуникаций по ЧП, в котором не было бы другой рабочей переписки. Наш выбор пал на Telegram, так как им легко и удобно пользоваться с мобильного, а также можно расширять его возможности с использованием ботов. Мы создали чат и договорились писать в него, когда кто-то узнал, что произошел сбой, и начал им заниматься. Так как в этом чате не бывает лишних сообщений — мы обязаны быстро реагировать на него в любое время суток. Первое время в чате были только сотрудники саппорта, но достаточно быстро в нем появились также администраторы и некоторые разработчики. То есть те люди, которые могут помочь быстро устранить сбой.
Это оказалось очень удобной практикой, так как все участники процесса обработки инцидентов собраны в одном месте, и информация о происходящем есть у всех. Часто теперь даже не нужно по очереди обзванивать, допустим, администраторов, чтобы найти того, кто может заняться проблемой. Все необходимые люди есть в чате, и сами отписываются, когда заметили алерт (или их можно призвать). Здесь поясню — у нас нет как такового on-call, поэтому решением инцидентов в нерабочее время занимается тот, кто в этот момент находится возле компьютера. Пока для нас это работает.
После этого почти решилась проблема с информированием людей, причастных к работе со сбоями, о том, что происходит «на бою», и кто занимается решением. Позже мы вывели критичные сообщения от мониторинга непосредственно в этот чат. Теперь алерты гарантированно приходят всем, кому нужно, и это уже не зависит от того, подписался человек на датчики или нет.
Также мы сделали ряд улучшений, чтобы повысить управляемость процесса.
Узнать о том, что произошел инцидент мы можем двумя способами:
- по алертам от мониторинга,
- от наших сотрудников, которые заметили проблему — если мониторинг по каким-то причинам нам о ней не сообщил.
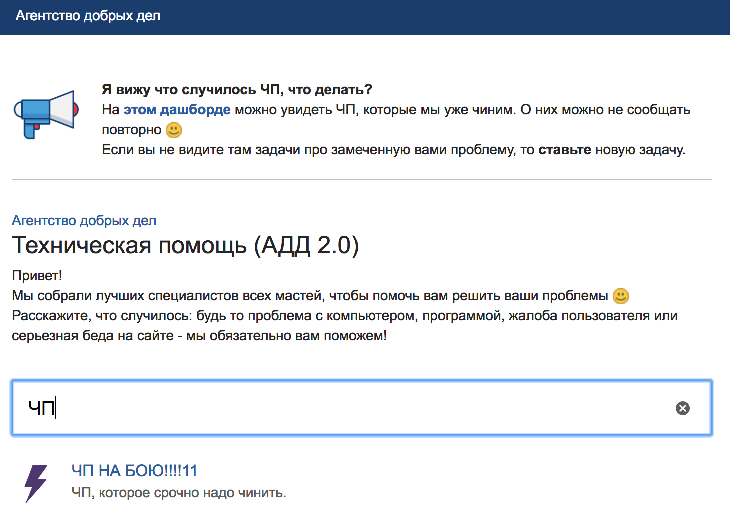
В любом случае, мы должны зафиксировать инцидент в JIRA — для контроля времени возникновения/решения проблемы, а также информирования заинтересованных лиц. Для этого у нас выделен специальный раздел в Service Desk («ЧП-бой»), куда может поставить задачу любой сотрудник компании. Также у нас есть панель, на которой выводятся все активные задачи с этим компонентом. Панель доступна непосредственно из интерфейса постановки задачи в Service Desk, и на ней можно найти ответ на вопрос, есть ли на бою проблема, и решается ли она.
На событие постановки задачи «ЧП-бой» мы настроили отправку автоматического уведомления в Telegram-чат для решения ЧП. Это позволяет быть уверенными, что проблема будет замечена даже в нерабочее время.
Если же мы узнали о проблеме от мониторинга, то задачу «ЧП-бой» мы должны поставить сами. Так как соответствующие алерты приходят в чат, нам показалось удобным автоматизировать постановку задачи в JIRA. Теперь мы можем сделать это нажатием одной кнопки в чате — задача создается от лица специального пользователя для автоматики и содержит текст сработавшего алерта. Таким образом, фиксация инцидента происходит быстро и удобно, мы не тратим на это лишнее время.
Когда приходит задача «ЧП-бой», определяем «штурмана» — человека из отдела эксплуатации, который будет отвечать за то, чтобы сбой устранили. Это не значит, что остальные перестают участвовать в разборе, вовлечены все, но штурман необходим для того, чтобы сотрудники не дублировали действия друг друга. Штурман должен координировать коммуникации и действия по решению инцидента, привлекать необходимые для этого силы. А также своевременно фиксировать информацию о ходе работ, чтобы потом при разборе можно было легко восстановить хронологию.
Штурман назначается исполнителем задачи «ЧП-бой». Когда задача назначена, наши коллеги понимают, что проблемой занимаются, и, в случае чего, знают к кому обращаться с вопросами.
Когда нам удалось устранить негативные эффекты — активная фаза завершена, задача закрывается.
В данной фазе, с точки зрения процессов, самым сложным оказалось сформировать общее понимание того, кто должен оказаться в роли штурмана. Решили, что им может быть тот, кто первым заметил ЧП, но лучше, если это будет саппортер пострадавшего продукта.

Ретроспективная фаза
Начинается непосредственно после завершения активной. Служит достижению второй цели процесса — не допускать повторения одного и того же сбоя.
Фаза включает полный всесторонний анализ случившегося. Ответственный за разбор инцидента сотрудник должен собрать всю имеющуюся информацию о том, что произошло, по каким причинам, какие действия были предприняты для восстановления работоспособности. После того, как стали ясны причины инцидента, мы проводим встречу по разбору ЧП. В ней обычно участвуют люди, которые занимались решением проблемы, а также тимлиды задействованных команд разработки. Цель встречи — выявить точки роста для наших систем или процессов и запланировать действия по их улучшению, чтобы предотвратить возникновение подобных инцидентов в будущем.
Результатом становится отчет о сбое, в котором содержится как полная информация о произошедшем, так и о том, какие мы выявили узкие места и что планируем предпринять, чтобы их устранить.
Для того, чтобы наши отчеты были написаны качественно и содержали все необходимое, мы сформулировали четкие требования к каждому разделу и зафиксировали их в стандарте. А также переработали шаблон документа и добавили в него полезные подсказки. Помимо этого, мы собрали в отдельном документе общие рекомендации по оформлению отчета, которые помогают правильно подать материал и избежать распространенных ошибок.
Отчет о сбое — это важный документ, который служит третьей цели процесса — информированию заинтересованных лиц об инцидентах и о действиях, предпринятых после. Также это инструмент сбора опыта и знаний о том, как наши системы работают и ломаются. Мы всегда можем вернуться к тому или иному инциденту, посмотреть как он протекал и как был обработан, или вспомнить по отчету, ради каких целей делалась та или иная задача по улучшению.
У нас получилась следующая структура документа:
Описание инцидента. Состоит из двух частей. Первая — краткое описание случившегося, с указанием причин и эффекта. Вторая часть — детализация. В ней мы подробно описываем причины, которые привели к инциденту, как мы о нем узнали, как он развивался, какие были записи в логах/сообщения об ошибках, и как в итоге починили. В общем, здесь собирается полная техническая информация о произошедшем.
Эффект. Описываем, как инцидент сказался на наших пользователях — какое количество пользователей с какими проблемами столкнулось. Нам нужно понимать эффект, чтобы приоритизировать задачи на улучшение.
Хронология. Для фиксации всех действий, событий, связанных с инцидентом, с указанием времени. Из этого раздела можно получить представление о ходе инцидента, видно как быстро мы среагировали, можно сделать выводы о том, вовремя ли сработал мониторинг, сколько времени заняло исправление.
По хронологии обычно достаточно хорошо заметны узкие места в процессах.
Графики и статистика. В этом разделе собираем все графики, которые показывают эффект (например сколько было 5ХХ ошибок), а также любые другие иллюстрации каких-либо аспектов инцидента.
Предпринятые действия. Этот раздел заполняется обычно после проведения технической встречи. Здесь фиксируются все запланированные действия по улучшению, поставленные задачи, с указанием ответственного. Также сюда заносим исправления, которые были сделаны в активной фазе, если они дают долгосрочный эффект. Все экшены в этом разделе формулируются таким образом, чтобы было понятно, какую из выявленных проблем они помогают решить. После окончания работ по разбору инцидента, мы продолжаем отслеживать выполнение поставленных задач до тех пор, пока все они не будут выполнены или обоснованно отменены.
Отдельно мы выделили статус документа и сформулировали требования к его изменению. Это помогает лучше понимать, как должен выглядеть отчет на каждом этапе работ по разбору инцидента. Статусов может быть три — «в работе», «готов к технической встрече», и «работа завершена». Благодаря этому стало удобно отслеживать сбои, по которым еще ведется работа.
Подведем итоги. Мы начали внедрять новый процесс управления инцидентами полтора года назад, и с тех пор продолжаем его совершенствовать. Новая организация работы помогает нам эффективнее достигать поставленных целей и решать возникающие проблемы.
Как решились проблемы активной фазы:
- Не было полной уверенности в том, что на критичный алерт кто-либо подписан.
Сейчас все критичные сообщения от мониторинга выведены в телеграм-чат для решения ЧП, в котором есть все необходимые сотрудники. А чат обязателен для быстрого реагирования в любое время.
- Нет ответственного за решение проблемы, который добьется ее устранения в кратчайшие сроки. Также непонятно у кого уточнять актуальный статус.
- Отсутствие в каждый момент времени информации, связанной с инцидентом.
- Несколько специалистов дублировали действия друг друга.
Благодаря появлению роли штурмана и формулированию требований к этой роли, у каждого инцидента всегда есть ответственный, который в курсе происходящего. Он своевременно публикует всю нужную информацию, а также координирует процесс решения инцидента. В результате нам удалось снизить количество дублирующихся действий.
Решение проблем ретроспективной фазы:
- Для тех, кто непосредственно не участвовал в решении инцидента, было сложно получить информацию о причинах, способах починки и о том, что происходило.
Вся информация сейчас фиксируется в чате. Благодаря этому, стало возможным передать ретроспективный анализ любому сотруднику службы эксплуатации, вне зависимости от того, присутствовал ли он в момент активной фазы сбоя.
- Не было одинакового понимания, что нужно писать в отчете о сбое. По отчетам иногда было сложно полностью восстановить картину произошедшего.
После того, как мы сформулировали и описали четкие требования и рекомендации к составлению документа, у сотрудников отдела эксплуатации начало формироваться одинаковое понимание того, что должно быть отражено в отчете. Над качеством оформления отчетов мы постоянно работаем — например, проводим ревью, что также способствует обмену опытом.
- В разбор ЧП погружались только специалисты саппорта и те, кто непосредственно занимался устранением причин и негативного эффекта.Далеко не все заинтересованные получали обратную связь о проблемах.
Благодаря тому, что мы стали проводить встречи по разбору, теперь в процесс глубже вовлечены также тимлиды команд разработки и администраторы. Они участвуют во встречах, знают к каким последствиям привели те или иные узкие места в коде или инфраструктуре и лучше информированы о том, почему нужно выполнять задачи, которые мы ставим в команды после разбора инцидентов.
Комментарии (6)

Antislovoblud
23.01.2018 14:27? Про эксплуатацию и support, цитата: «Разбором инцидентов в нашей компании занимается отдел эксплуатации (или, проще, support).».
>Эксплуатация, это практическое использование (по назначению) производственных ресурсов для получения выгоды. В эксплуатацию, в том числе, входит и поддержка, но не входит разработка.
>Support – это только поддержание технического обеспечения в исправном состоянии, т.е. часть, но никак не эксплуатация в целом.
Чтобы утверждать, что занимаетесь эксплуатацией, нужно непосредственно реализовывать коммерческую выгоду. Вы ведь коммерческая организация? В целом? А сами, как работник, входите в состав ИТ подразделения, как часть организации? Смею утверждать, что речь, скорее всего, идёт об опорном процессе, поддерживающем основные (с западной т.з. основные = бизнес-процессы). Всего различают процессы: основные, опорные, качества. Кстати, поддержка (по Вашему Support) может быть бизнес процессом, а может и не быть им.
? Про инциденты, ЧП и т.д., цитата: «Инцидент (или сбой, ЧП) — это некая критическая (обычно массовая) проблема, которая существенно снижает доступность, корректность, эффективность или надежность бизнес-функционала или инфраструктурных систем.».
> Инцидент, не является проблемой по определению. Упрощённо, в обывательской формулировке, инцидент это «что то не работает как нужно», но можно исправить собственными ресурсами, а проблема, это «невозможность восстановить собственными ресурсами» — нет знаний, нет оборудования и т.д… И уж тем более инцидент не является ЧП. Под ЧП Вы подразумевали чрезвычайное происшествие? Тогда потрудитесь изучить определение термина ЧП – непредвиденное событие повлекшее гибель людей, порчу имущества…
Шедеврально, цитата: «надежность бизнес-функционала или инфраструктурных систем». Попробуйте изучить понятия «надёжность» (собирательный термин), «бизнес», «функция» (как полезная работа), «инфраструктура» (есть ещё 2 структуры). Вас ждёт большой сюрприз, при осознании Вашего контекста…
Простите, но, в данном случае, как нельзя кстати, подходит выражение «Всё смешалось в доме Облонских…».
?Про цели, цитата: «В рамках процесса управления инцидентами мы ставим перед собой следующие основные цели: 1.Как можно быстрее восстановить работоспособность наших систем …».
Основные? Значит есть дополнительные? Прелестно (сарказм).
> Заявленный Вами нумерованный список, не является целями по определению, поскольку ни один из пунктов нельзя ни измерить ни достичь. Изучите, хотя бы, такие модные в последние 15 лет западные принципы S.M.A.R.T.
У процесса должна быть одна цель (goal, а не target (мишень)), которую следует декомпозировать на низ лежащие уровни. Или у Вас функция в составе процесса? Это не одно и тоже.
Пример цели: модернизировать техническое обеспечение корпоративной сети между точками A и B в узлах 1,2,3,4 имеющимися ресурсами.
Дополните цель рамками и допущениями.
Декомпозируйте на функции, задачи.
? Про мониторинг, цитата: «У нас была самописная система мониторинга, которая подразумевала самостоятельную подписку сотрудников на сообщения о проблемах…»
> Мониторинг. Наблюдение и регистрация данных с неразрывно примыкающими интервалами с незначительно меняющимися данными. Различают мониторинг параметрический и состояния. Важна визуализация и оповещение… Важна интерпретация показателей.
Учитывая контекст, смею предположить, что у Вас не было и нет системы мониторинга. Скорее всего, речь идёт о недо-системе диагностики и журналировании событий, успешно выдаваемой руководству, как система мониторинга (см. определения «система», «диагностика», «журналирование», «мониторинг»).
Учитывая в целом контекст «статьи» и самостоятельную подписку, у Вас отсутствует формальная структура как часть организационного обеспечения.
Мониторинг по определению не может сообщать о проблемах (см.определение).
? Про фазы инцидентов, цитата «Разделили работу с инцидентами на две фазы — активную и ретроспективную».
Ативная-Пассивная. Ретроспективная-Перспективная. Вы хоть понимаете назначение применяемых терминов? (это риторический вопрос).
Начните, хотя бы, с русского языка – прошлое, настоящее, будущее.
Воздержитесь от применения таких терминов, как «превентивный» и т.д., если не понимаете их назначения.
- Вы не только не осознаёте используемые термины, но ещё применяете жаргонизмы и псевдо-терминологию.
Создаёте автоматизированные системы по заведомо ложным ценностям.
В общем, судя по Вашей статье, как пишите, так организуете и реализовываете – беспорядок, ошибки, подмена понятий, дезорганизация и т.д…
Прочитав, скорее всего подумаете – но ведь у нас всё работает. Да, скажу, машина на 3-х колёсах тоже работает… т.е. с т.з. она неисправна, но работоспособна… какое-то время… в какой-то мере…
Как то так.
PS: Каждый работник компании не в состоянии поставить задачу, тем более, техническому работнику, поскольку нужно обладать не только техническими знаниями, но и умением ставить задачи как таковые (см. состав задачи), что подтверждается, как правило, наличием у них только потребности.
PSS: JIRA есть СОО (BTS) – Система Отслеживания Ошибок (bug tracking system), а не система отслеживания инцидентов. BTS нужна для ЖЦ объекта во время «Разработка» (Development), а не «Сопровождение» (Maintenance). Тем более, BTS не является системой управления документооборотом, что подтверждается анализом ЖЦ и составом объектов управления. Или, по другому, применяется не по назначению. Характеризуется эта ситуация неумением или невозможностью субъекта осознать естественных явлений или объектов, что есть по определению глупость. Это с академической т.з.
С обывательской, это как забивать гвозди микроскопом, потому что он тяжёлый и, таки, забивает. Однако есть плюс – продуцирование квази-деятельности в которой все заняты…
Удачи.Merlyel
23.01.2018 15:06PSS: JIRA есть СОО (BTS) – Система Отслеживания Ошибок (bug tracking system), а не система отслеживания инцидентов. BTS нужна для ЖЦ объекта во время «Разработка» (Development), а не «Сопровождение» (Maintenance).…
Мёсье потрудился посмотреть JIRA и выяснить, что в ней довольно-таки много различных доп.модулей, которые делают из JIRA почти всё, что угодно?
С обывательской, это как забивать гвозди микроскопом, потому что он тяжёлый и, таки, забиваетAntislovoblud
23.01.2018 15:46Ваше предложение состоит исключительно из сущностных квантификаторов и относительных ссылок, но без указания точки отсчёта, т.е. не представляет информационной ценности — не информативно.
Пример: те или иные, всякие разные, довольно много, различные.
Обращение «месье» неуместно.
Желаете дискуссии, извольте обосновать (см.определение) позицию в явной форме. Я готов. Риторика и демагогия меня не интересует.
Vkuvaev
23.01.2018 18:43Вижу, коллега, вашу позицию, как абсолютно противоположную, подходу описанному в статье.
Т.е. В статье описано как можно пару колес скрутить и превратить, с помощью пары палок, в велосипед и поехать. Вы же, судя по всему, сторонник академического подхода.
Мне тоже больно, что не хотят, понимаешь ли, купить отличный, готовый продукт из класса ITSM решений с нормальным консалтингом. И ведь знаю, что в Tutu работают товарищи, съевшие на теме ITSM собаку. ( или уже работали).
Глоссарий не используют из ITIL, да, велосипед переизобретают, да. Но свою потребность закрыли.
Сможете в статье описать так, чтоб все бросились выкидывать JIRA в окно? Боюсь сейчас время когда большинство решений — наколенная поделка JIT( без презрения, сам такой же)
Antislovoblud
24.01.2018 22:11По поводу колёс и палок. Контекст Вашего комментария соответствует принципу аналогии и ассоциативной связи, что снижает точность и достоверность оценки. Контекст моего комментария предельно ясен – ошибочность технических и организационных решений. Применение продуктов не в соответствие с их назначением. Если оценивать с позиции велосипеда, то последний предназначен для увеличения скорости перемещения человека. Используемая в ТУТУ.РУ АС управляет объектом типа электронный документ. Потребность состояла в увеличении скорости перемещения инцидентов? Это риторический вопрос. Переход от объективных оценок к субъективным приводит к искажению информации. Каждая последующая субъективная оценка вносит дополнительное искажение.
Про потребность. Предполагаю, что находясь на этапе неосознанного незнания, вполне себе можно мыслить, что потребность закрыта, но от мнения человека объективная реальность не зависит… Вспоминается рассказ про обезьян, банан и холодную воду…
Про покупку. Покупать? А обоснование есть? У работников есть аналитическая записка по выбору ПО для автоматизации? На основании моего опыта, сомневаюсь. Предполагаю, что выбор был по ощущениям «как уже те ребята сделали». Впрочем, проверить ведь не сложно. А нужно? Например, руководителю ИТ? И снова – каждое ошибочное решение вносить дополнительно искажение, усугубляя состояние…
Про статью. Что бы создать предметную статью, содержащую знания, нужна предметная постановка цели. Интересы (политические, экономические…). Далее, естественно, с декомпозицией на задачи и т.д. Входящие данные, типа «Сделать хорошо, чтобы все выбросили в окно» (утрирую), для анализа не подходят.
PS: Собаку есть не надо =), надо демонстрировать компетентность. Желательно на бумаге, поскольку на ней видна вся глупость человеческая. К тому же, человеку нельзя помочь, пока он этого сам не захочет, т.е. не перейдёт в состояние осознанного незнания и готовности к действиям.
Vkuvaev
Не хочу быть занудой :) но это, по-сути описано в ITIL, он, конечно, не новое изобретение, и выглядит пыльно, но обидно наблюдать как в индустрии все наработки по-сути теряются.
По статье, молодцы, все сделали правильно.