

Глава 8. Ветки
Концепция веток не так проста. Представьте, что вам нужно внести множество изменений в файлы вашего рабочего каталога, но эта работа экспериментальная – не факт, что всё получится хорошо. Вы бы не хотели, чтобы ваши изменения увидели другие сотрудники до тех пор, пока работа не будет закончена. Может просто ничего не коммитить до тех пор? Это плохой вариант. Мы уже знаем, что частые коммиты и пуши – залог сохранности вашей работы, а также возможность посмотреть историю изменений. К счастью, в Git есть механизм веток, который позволит нам коммитить и пушить, но не мешать другим сотрудникам.
Перед началом экспериментальных изменений вы должны создать ветку. У ветки есть имя. Пусть она будет называться my test work. Теперь все ваши коммиты будут идти именно туда. До этого они шли в основную ветку разработки – будем называть её master. Другими словами, раньше вы были в ветке master (хоть и не знали этого), а сейчас переключились на ветку my test work. Это выглядит так:
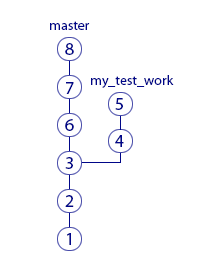
После коммита «3» создана ветка и ваши новые коммиты «4»и «5» пошли в неё. А ваши коллеги остались в ветке master, поэтому их новые коммиты «6», «7», «8» добавляются в ветку master. История перестала быть линейной.
На что это повлияло? Сотрудники теперь не видят изменений файлов, которые вы делаете. А вы не видите их изменений в своих рабочих файлах. Хотя историю изменений в ветке master вы все-таки посмотреть можете.
Итак, теперь вы сможете никому не мешая сделать свою экспериментальную работу. Если её результаты вас не устроит, вы просто переключитесь на ветку master (на её последний коммит – на рисунке это коммит «8»). В момент переключения файлы в вашей рабочей папке станут такими же, как у ваших коллег, а ваши изменения исчезнут. Теперь ваша рабочая копия стала слепком из коммита «8». По картинке видно, что в нём нет ваших изменений, сделанных в ветке my test work.
Глава 9. Слияние веток
Теперь мы знаем, что каждый может создать ветки и работать независимо. Можно по очереди работать то в одной ветке, то в другой – переключаясь между ними. Ветки переключает команда checkout.
Ветки используются не только для временной независимой работы. Часто мы одновременную готовим несколько версий игры. Например, одна версия уже почти готова к публикации и программисты вносят в неё последние исправления. В то же время гейм-дизайнеры уже занимаются следующим обновлением. Им нельзя работать в предыдущей версии потому, что:
- Их изменения не должны появиться в текущей версии;
- Любые изменения могут что-то сломать, поэтому перед публикацией версии нужно вносить в неё как можно меньше изменений.
Словом, от веток много пользы. Но вернёмся к примеру с вашей экспериментальной работой. В предыдущей главе мы решили, что она не удалась. Вы вернулись в ветку master и потеряли изменения, сделанные в ветке my test work. А если все получилось? Вы хотите перенести свои изменения в ветку master, чтобы их увидели сотрудники, которые с ней работают. Git может помочь – выполним команду merge ветки my test work в ветку master:

Здесь коммит «8» – это специальный коммит, который называется merge-commit. Когда мы выполняем команду merge, система сама создает этот коммит. В нём объединены изменения ваших коллег из коммитов «5», «6», «7», а также ваша работа из коммитов «3», «4».
Изменения из коммитов «1» и «2» объединять не нужно, ведь они были сделаны до создания ветки. А значит изначально были и в ветке master, и в ветке my test work.
Команда merge ничего не посылает в origin. Единственный ее результат – это merge-commit (на рисунке кружок с номером 8), который появится у вас на компьютере. Его нужно запушить, как и ваши обычные коммиты. Только после этого merge-commit отправится на origin – тогда коллеги увидят результат вашей работы, сделав pull.
Глава 10. Несколько мержей из ветки А в ветку В
В предыдущей главе мы узнали, как сделать новую ветку, поработать в ней и залить изменения в главную ветку. На картинке после объединения ветки слились вместе. Означает ли это, что в ветке my test work теперь работать нельзя – она ведь уже объединилась с master? Нет, вы можете продолжать коммитить в ветку my test work и периодически мержить в главную ветку. Как это выглядит:
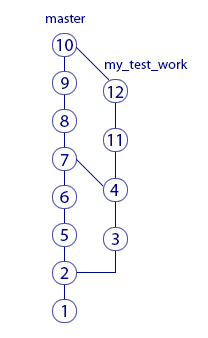
Обратите внимание, что отрезки соединяющие ветки не горизонтальные – так показано, из какой ветки в какую был мерж. В этой ситуации было два мержа и оба из правой ветки в левую. Результатом первого объединения стал merge-commit «7», а второго – merge-commit «10». Поскольку мерж происходит из правой ветки в левую, то, например, в слепке «8» есть изменения, которые были сделаны в коммите «3». А вот в слепке «11» нет изменений, которые были сделаны в коммите «5». Убедитесь, что вы понимаете причину этого. Если нет, перечитайте главы о ветках ещё раз.
Глава 11. Мерж между ветками в обе стороны
В предыдущем примере мы всё время мержили из ветки my test work в ветку master. Можно ли мержить в обратную сторону и есть ли в этом смысл? Можно. Есть.
Если вы долго работаете в своей ветке, рекомендуется периодически делать мерж в неё из главной ветки. Это необходимо, чтобы вы работали с актуальными версиями файлов, которые меняют другие люди. Как это выглядит:
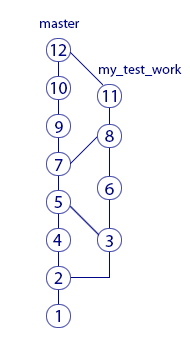
Здесь два мержа из ветки my test work в ветку master и один мерж в обратную сторону. Результатом обратного объединения стал merge-commit «8». Благодаря ему, например, слепок коммита «11» содержит изменения из коммита «7». А вот изменений из коммита «9» в слепке «11» уже нет, ведь этот коммит был сделан после мержа.
Глава 12. Коммиты и их хеши
Как Git различает коммиты? На картинках мы для простоты помечали их порядковыми номерами. На самом деле каждый коммит в Git обозначается вот такой строкой:
e09844739f6f355e169f701a5b7ae02c214d5fb0
Это «названия» коммитов, которые Git автоматически даёт им при создании. Вообще, такие строки принято называть «хеш». У каждого коммита хеш разный. Если вы хотите кому-то сообщить об определённом коммите, можно отправить человеку хеш этого коммита. Зная хеш, он сможет найти этот коммит (если это ваш коммит, то, конечно, его надо сначала запушить).
Глава 13. Ветки и указатели
Сейчас мы немного углубимся в то, как Git хранит информацию о ветках. Вроде бы внутреннее устройство Git нас не должно волновать, но это позволит намного лучше понимать, что происходит при выполнении операций в Git. А вы, в свою очередь, сможете избежать ряда ошибок.
Познакомимся с концепцией «указателя». В упрощённом виде указатель состоит из своего названия и хеша. Вот пример указателя:
master – e09844739f6f355e169f701a5b7ae02c214d5fb0
Тут вы скажете: «master – знакомое имя! У нас так называлась главная рабочая ветка». И это совпадение не случайно. Git использует указатели для обозначения веток. Идея простая: если нужна новая ветка, Git создаёт новый указатель, даёт ему имя ветки и записывает в него хеш последнего (самого свежего) коммита ветки. Ветка создана!
Благодаря хешу в указателе можно сказать, что указатель ссылается или «указывает» на последний коммит ветки. Этого достаточно Git’у, чтобы выполнять все операции над ветками. То есть, никакой другой информации о том, какие коммиты принадлежат какой ветке Git не хранит. Вот так всё минималистично.
На каждую ветку есть свой указатель. Когда в ветку добавляется очередной коммит, хеш в указателе меняется, чтобы снова «указывать» на последний коммит. Это можно представить, как сдвигание указателя ветки на последний коммит с предпоследнего.
Если вы просите Git переключиться на другую ветку (команда checkout), ему достаточно найти указатель с именем этой ветки и взять из него хеш последнего коммита. Теперь Git знает, как должны выглядеть файлы вашего рабочего каталога (как слепок этого коммита). Git приводит файлы к такому виду – и переключение на ветку произошло.
Если вы не совсем поняли идею указателей и то, как они связаны с ветками, перечитайте главу ещё раз. В Git многое завязано на указатели, поэтому важно чётко понимать механику их работы. К счастью, она совсем не сложная, просто немного необычная. Нужно лишь привыкнуть.
Глава 14. Указатель head
Итак, мы знаем, что указатели – это такие штуки, у которых есть имя, и они ссылаются на определенный коммит (хранят его хеш). Мы знаем, что при необходимости новой ветки, Git создаёт указатель на ее последний коммит и двигает его вперед при каждом новом коммите.
Указатели используются не только для веток. Есть особый указатель head. Он указывает на коммит, который выступает состоянием вашего рабочего каталога. Поняли идею? Вот пример:
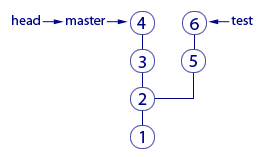
Здесь мы видим две ветки, которые представлены двумя указателями: master и test. Мы находимся в ветке master и файлы нашего рабочего каталога соответствуют слепку коммита «4». Откуда мы это знаем? Из того, что указатель head указывает на коммит «4». Точнее, он указывает на указатель master, который указывает на коммит «4». Почему бы не указывать напрямую на коммит «4»? Зачем такой финт с указанием на указатель? Так Git обозначает, что сейчас мы находимся в ветке master.
Мы можем поставить указатель head на любой коммит – для этого есть команда checkout. Вспомним, что на какой коммит показывает head, в таком состоянии и будут файлы в рабочем каталоге (это свойство указателя head). Поэтому переставляя указатель head на другой коммит, мы тем самым заставим Git поменять файлы нашего рабочего каталога. Это может потребоваться, например, чтобы откатиться на старую версию рабочих файлов и посмотреть, как там всё было. А потом можно вернуться назад к последнему коммиту ветки master (checkout master). Если же сделаем checkout test (см. картинку), то head будет указывать на указатель test, который указывает на последний коммит ветки test. Файлы в рабочем каталоге поменяются на слепок «6». Так мы переключились на ветку test.
Подытожим. Перестановка особого указателя head приводит к тому, что файлы рабочего каталога меняются на слепок этого коммита. Но только тогда, когда head указывает на указатель какой-то ветки, Git считает, что мы находимся в этой ветке.
А что происходит, если head указывает на какой-то коммит напрямую (хранит его хеш)? Это состояние называется detached head. В него можно переключиться на время, чтобы посмотреть, как выглядели файлы рабочего каталога на одном из коммитов в прошлом.
Переключение (как между ветками, так и между обычными коммитами) выполняется командой checkout.
Глава 15. Указатель origin/master
Раз удалённый репозиторий (origin) такой же, как наш, значит там тоже есть свои указатели веток? Верно. Например, есть свой указатель master, который ссылается на самый свежий коммит в этой ветке.
Интересно, что когда мы забираем свежие коммиты из origin командой pull, то вместе с коммитами скачиваются и копии указателей оттуда. Чтобы не путать наш указатель master и тот, который скачался с origin, второй из них отображается у нас, как origin/master. Нужно понимать, что origin/master не показывает текущее состояние указателя master в удаленном репозитории, это лишь его копия на момент выполнения команд fetch или pull.
master и origin/master могут указывать на разные коммиты. Станет понятнее, если посмотреть на картинку:

Здесь показана ситуация, когда мы забрали свежие коммиты (командой pull), сделали два новых коммита, но ещё не сделали push. В итоге наш локальный master показывает на последний коммит. А origin/master – это последнее известное нам состояние указателя из удалённого репозитория. Поэтому он и «отстал».
После команды push два верхних коммита уйдут в origin и логично, что origin/master подвинется вверх и тоже будет указывать на наш последний коммит, как и master.
А может ли быть так, что origin/master будет наоборот выше, а master ниже? Может. Вот как это получается. Команда pull забирает свежие коммиты и сразу же помещает их в рабочий каталог. Сразу после команды pull оба указателя origin/master и master будут указывать на один и тот же последний коммит. Но есть ещё команда fetch. Она, как и pull, скачивает последние коммиты из origin, но не торопится обновлять рабочий каталог. Графически это выглядит так (если у вас нет незапушенных коммитов):
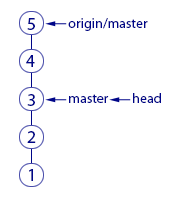
До команды fetch указатель master показывал на коммит «3» и это был последний коммит в нашем репозитории. После fetch скачались два новых коммита «4» и «5». В удалённом репозитории указатель master, очевидно, указывал на коммит «5». Этот указатель скачался нам вместе с коммитами и теперь мы его видим как origin/master, указывающий на «5». Всё логично.
Зачем может потребоваться fetch? Например, вы не готовы менять состояние рабочего каталога, а просто хотите поглядеть, чего там накоммитили ваши коллеги? Вы делаете fetch и изучаете их коммиты. Когда будете готовы, делаете команду merge. Она применит скачанные ранее коммиты к вашему рабочему каталогу.
Поскольку в этом простом примере у вас не было незапушенных коммитов, то команде merge объединять ничего не придётся. Она просто подвинет указатели master и head – теперь они будут показывать на коммит «5». Как и origin/master.
Вы можете заметить, что ничего по-настоящему сложного в описанных механиках нет. Есть лишь множество деталей, в которых приходится кропотливо разбираться. Но Git – он такой.
В финальной части статьи мы расскажем о том, откуда взялась ветка, почему push выдаёт ошибку и что такое rebase. И, конечно, подведем итоги.
Комментарии (36)

storoj
12.02.2018 15:50Очень настороженно отношусь к п.11 про взаимный merge веток. Зачем мне в моей фича-ветке свежие изменения из других веток? Мне кажется, что пока в этом нет супер острой необходимости, то ни в коем случае не надо мёржить мастер в фичу. Это сильно портит историю, тяжело потом посмотреть общий diff веток, чтобы оценить все изменения (в процессе code review, например).
Кто имеет убеждения по этому поводу, поделитесь пожалуйста своим мнением.

MooNDeaR
12.02.2018 17:04Вообще, обычно принято в свою ветку делать rebase от мастера, для того, чтобы вливание своей ветки в мастер-ветку было обычным fast-forward. Хотя и тут есть исключения, ведь rebase с конфликтами — та еще боль и иногда проще создать лишний merge-коммит, вместо того, чтобы тратить время на разрешение кучи конфликтов.
horror_x
12.02.2018 18:19Хотя и тут есть исключения, ведь rebase с конфликтами — та еще боль и иногда проще создать лишний merge-коммит, вместо того, чтобы тратить время на разрешение кучи конфликтов.
Слышал разные страшилки по поводу rebase и конфликтов, но на практике ни с чем подобным ни разу не столкнулся. Можете пояснить, в чём принципиальное отличие в разрешении конфликтов при merge и при rebase? Ведь конфликты в любом случае надо разрешать, и merge сам за вас это не сделает.
Danik-ik
12.02.2018 21:21При мерже конфликты разрешаются один раз, так как комит один. А ребэйз — считай, по черри-пику на каждый коммит исходной ветки на новый корень. И каждый чреват конфликтами. Исправил — продолжил — снова то же самое… Особенно скучно ковырять такие конфликты, когда в двух ветках постоянно идёт работа в одном и том же месте — например, дописывается в конец один и тот же файл. У меня это скрипт миграции.
А было ещё такое, что разрешил конфликт, а гит заявил, что коммитить нечего и продолжить ребейз отказался.
Так что ребейз теряет свои прелести с ростом количества коммитов и особенно — при наличии мест, которые подвержены правкам всегда и отовсюду.
horror_x
12.02.2018 21:41При мерже конфликты разрешаются один раз, так как комит один. А ребэйз — считай, по черри-пику на каждый коммит исходной ветки на новый корень.
Но общее число конфликтов от этого ведь не меняется. Да, возможно придётся править те же самые файлы, но я вижу в этом только плюс — если коммиты делать не хаотично, а отражать ими атомарные изменения, то и пошагово разрешать конфликты куда удобней, меньше вероятность запутаться и допустить ошибку.storoj
12.02.2018 22:41А зачем такие монструозные rebase? Выполнялось параллельно две, обычно не связанные между собой, работы, в конце изменения слились. Один раз исправил все конфликты, один раз проверил работоспособность, один раз с этим разобрался. В итоге есть две ветки, в каждой из которых можно пошагово проверить наличие той или иной проблемы. Или же определить, что проблема появилась именно в момент слияния.
Я часто сталкивался с мотивацией "иметь прямую историю", и в большинстве случаев только ради этого и делались rebase разной степени сложности. Однако, такой подход мне кажется лишённым смысла, он не только не даёт никакой пользы, а скорее разрушает историю, уничтожает истинный ход событий. Может, есть и другие причины так делать?

IvanPonomarev
13.02.2018 00:47+1Ничего монструозного в rebase не нахожу. Просто многие почему-то пугаются этой операции, слабо понимая её семантику. Частый rebase локальной ветки по основной ветке — это «гигиеническая процедура». Делай его часто, каждый раз, когда в основной ветке появляются новые коммиты и 1) меньше будет конфликтов, 2) возникающие конфликты будут выявляться и устраняться на ранней стадии
По-сути, выбор rebase vs merge — это аналогично тому, как с автотестами/ручными тестами: «перенести боль на начало» vs «отложить боль на потом» (в первом случае общее кол-во боли будет меньше).
Естественно, надо понимать, что rebase — это то, что ты делаешь в локальном репозитории, merge — это вливание готовой ветки в мастер по завершении фичи.Danik-ik
13.02.2018 07:53Что касается количества конфликтов — оно таки больше при ребейзе, так как один и тот же местный конфликт может повторяться много раз.
Сделайте один файл и две ветки. Допишите файл в конец, по 10 коммитов в каждой ветке. Сделайте ребейз. Откиньтесь на спинку табуретки и насладитесь процессом.
Ребейз вынуждает перестраивать промежуточные состояния, единственный смысл существования которых заключается в атомарности предыдущего коммита. И ради чего — ради потери структуры?
Отложите боль на потом, не ковыряйте болячку. Дождитесь перевязки, быстрее заживёт.
Я часто применяю ребейз для новой фичи, если в девелопе появились новые коммиты. И никогда — обратно в девелоп. Как не храню все файлы проекта в одной папке, так и не храню коммиты на одной линии. Девелоп у меня — только мержи по поводу окончания веток — и это тот разрез истории, который я никак не хочу терять.
Линейная история, по-моему, вещь в себе, красота ради красоты, которая может стоить много времени. А если что-то дороже обходится, а пользу реальную заменяет пользой умозрительной — нуивонафф, не буду...
horror_x
13.02.2018 00:53А зачем такие монструозные rebase?
А в чём монструозность? Обычный случай — есть ветка фичи с N коммитами. При ребейзе в некоторых коммитах возникли конфликты, последовательно их разрулил и всё.
Один раз исправил все конфликты, один раз проверил работоспособность, один раз с этим разобрался.
Не понимаю, в чём принципиальное различие — исправить N конфликтов в одном коммите мержа или те же N конфликтов в нескольких коммитах при ребейзе. Количество работы то же самое, но в случае ребейза решаешь конфликты только одного коммита за раз, что лично я нахожу весьма удобным, т.к. делается это в порядке хронологии, небольшими порциями и у каждой порции есть конкретный контекст. В случае большого количества изменений это порой единственный способ не запутаться при мерже.
В итоге есть две ветки, в каждой из которых можно пошагово проверить наличие той или иной проблемы. Или же определить, что проблема появилась именно в момент слияния.
В случае ребейза слияние будет распределено по коммитам, т.е. проверять нужно будет на один шаг меньше. А в случае проблем сразу понятно, при слиянии чего именно что-то пошло не так.
Однако, такой подход мне кажется лишённым смысла, он не только не даёт никакой пользы, а скорее разрушает историю, уничтожает истинный ход событий.
Истинный ход событий в общей истории никому не интересен, как и избыточные коммиты вроде «fix bug». Это только усложняет поиск нужной точки в истории при необходимости. По-хорошему бранч перед мержем надо причесать, всякие «fix bug» накатить fixup'ами на соответствующие коммиты. Т.е. да, править локальную историю, но в этом и философия — никому не надо в деталях знать как это разрабатывалось (и сколько кофе вы при этом выпили), интересует только максимально презентабельный результат в общей истории.storoj
13.02.2018 02:04Не понимаю, в чём принципиальное различие — исправить N конфликтов в одном коммите мержа или те же N конфликтов в нескольких коммитах при ребейзе.
Для меня есть разница в том, что в момент мержа видно весь масштаб всех изменений. Если где-то возник конфликт, то посмотрев на изменения в общем, можно проверить и другие потенциальные места, где конфликта нет, но влияние изменений есть. В случае же с rebase приходится работать с каждым своим комитом по отдельности, и при возникновении конфликта гораздо тяжелее оценить где что-то могло тоже испортиться. Если нет никаких автоматических тестов, то можно очень много времени тратить на эту актуализацию через rebase. Плюс ко всему, на своей практике я пока сделал вывод о том, что фича обычно не требует неотложной синхронизации с основной кодовой базой. Фичу обычно можно делать и полностью отдельно, и неважно что там в основной ветке.
Вкратце, мой поинт такой: если делать merge в конце, то в этот момент можно как следует погрузиться в процесс слияния изменений. Перед глазами есть сразу полная картина работы, и можно один раз вдумчиво всё проверить и исправить. В случае же с rebase это не просто размазывается во времени, а как будто бы даже отнимает больше времени из-за постоянных ресолвингов одного и того же. Слышал, что есть инструмент
git rerere, но не пробовал.
Истинный ход событий в общей истории никому не интересен
Не очень понял этот момент. Я очень часто прибегаю к
git blame, чтобы разобраться зачем и когда была изменена та или иная строка.
интересует только максимально презентабельный результат в общей истории
А что для вас "презентабельно"? Мы стараемся, чтобы в каждом комите был минимальный набор изменений, плюс максимально понятное описание зачем так было сделано. При просмотре истории 2 и более лет давности порой возникают вопросы "что здесь происходит? почему так было сделано?", а commit message тоже не очень хороший. В итоге получается так, что инструмент просто не работает из-за нашей неорганизованности в прошлом.
horror_x
13.02.2018 03:15Если где-то возник конфликт, то посмотрев на изменения в общем, можно проверить и другие потенциальные места, где конфликта нет, но влияние изменений есть. В случае же с rebase приходится работать с каждым своим комитом по отдельности, и при возникновении конфликта гораздо тяжелее оценить где что-то могло тоже испортиться.
Посмотреть на изменения в общем можно и в процессе ребейза. И в случае ребейза можно переписать коммиты с учётом влияния изменений, что только упростит чтение истории в будущем.
Вкратце, мой поинт такой: если делать merge в конце, то в этот момент можно как следует погрузиться в процесс слияния изменений. Перед глазами есть сразу полная картина работы, и можно один раз вдумчиво всё проверить и исправить. В случае же с rebase это не просто размазывается во времени, а как будто бы даже отнимает больше времени из-за постоянных ресолвингов одного и того же. Слышал, что есть инструмент git rerere, но не пробовал.
Не вижу ничего плохого в «размазывании во времени», на вдумчивость это никак не влияет, наоборот даёт возможность сузить поле зрения. Тут я полностью согласен с IvanPonomarev — лучше делать ребейз чаще и решать конфликты сразу меньшей кровью, чем ждать до последнего и хвататься за голову от их количества.
Не очень понял этот момент. Я очень часто прибегаю к git blame, чтобы разобраться зачем и когда была изменена та или иная строка.
Я имею в виду, что истинный оригинальный порядок/время коммитов, который теряется при ребейзе, не так уж важен.
А что для вас «презентабельно»? Мы стараемся, чтобы в каждом комите был минимальный набор изменений, плюс максимально понятное описание зачем так было сделано.
Это я и понимаю под «презентабельностью». Но идеальную историю редко можно сделать, не переписывая её. Вот допустили вы ошибку пару коммитов назад, делать amend уже поздно. Большинство в таком случае просто закоммитит фикс с комментарием вроде «fix a mistake», и это нормально в процессе разработки. Но я сторонник того, чтобы перед мержем в основную ветку чистить историю от таких коммитов с помощью rebase, объединяя их с теми, где эта ошибка была допущена.storoj
13.02.2018 03:47А как тогда быть с long-lived ветками? Ведь процесс с rebase подходит только для веток типа "поработал-смержил-удалил". После merge в условный мастер потом ведь не получится на него же поребейзить.
Но раньше я тоже любил ребейзить. Приходил утром, фетчил, ребейзил, именно ради минимизации конфликтов. Но вот за последние пару лет я больше склонился к тому, что фича она почти по определению не обязана иметь сильной связи с какими бы ни было другими ветками. Спокойно работаю в ветке, пока не будет условно готово. Когда готово – наступает следующий этап объединения изменений. Потом можно ветку не удалять, а продолжать с ней работать дальше.
Стало интересно, как же работают над тем же ядром Linux? Там ведь наверное каждые полчаса происходят тонны изменений.
Надеюсь, мои ответы не выглядят как спор ради спора, я просто хочу разобраться и понять плюсы и минусы, ну и своими мыслями поделиться.

apapacy
13.02.2018 04:15merge проще понимания. rebase я не использую но насколько я понимаю это проблему если c одним remote репозитарием работают несколько разработчиков — и ветка до и после rebase была запушена, то ее может смерджить (до rebase) кто-то из разработчиков и после rebase начнутся массовые конфликты. В случае разработки например в guthub.com. Такая ситуация исключена т.к. все работают со своим персональным remote origin и потом делают merge request в публичный репозитарий. Поэтому выгода от упрощения истории есть а траблов с массовыми конфиликтами нет.
apapacy
13.02.2018 04:30Кстати мне например понравилась статья на Хабре про rebase habrahabr.ru/post/161009
Danik-ik
13.02.2018 08:21После мержа в мастер на него ребейзить можно. Нельзя ребейзить ветку, которая сама в себе имеет мерж-коммиты, т.к. ребейз подразумевает линейную структуру источника.
Это же, по сути, лишь куча последовательных (!) черри-пиков с последующим переносом указателя ветки-источника.
Черри-пик можно сделать на что угодно. Но если ветка от корня не вытягивается в линию — тут-то ребейз и невозможен
Danik-ik
13.02.2018 08:03При ребейзе (если в мастер/девелоп) теряется не столько время коммита, сколько его глобальное предназначение и группировка (принадлежность к ветке).
IvanPonomarev
13.02.2018 00:32+1А ребэйз — считай, по черри-пику на каждый коммит исходной ветки на новый корень. И каждый чреват конфликтами.
Ну так надо как можно чаще рибейзить свою ветку — тогда меньше будет проблем.
например, дописывается в конец один и тот же файл. У меня это скрипт миграции.
Мне кажется, что это общая проблема, связанная именно со скриптами миграции. Они плохо версионируются, потому что скрипт миграции — не исходный код, а лог изменений. Его или принципиально по-другому версионировать надо (но я не слышал, чтобы какие-то системы контроля версий специально поддерживали такие логи), либо идемпотентный DDL мог бы сильно выручить (но он тоже пока нигде хорошо не реализован)Danik-ik
13.02.2018 08:53Как можно чаще делать вещь в себе? Ради чего?
При работе над веткой это имеет смысл, пока обходится бесплатно или почти бесплатно, и я это делаю. Но ребейз фичи при слиянии в мастер/девелоп — это потеря структуры в части смысловой или целевой группировки коммитов, а оно мне не надо и даже вредно.
Тем более, слияние в мастер и даже в девелоп регламентируется отнюдь не соображениями красоты и линейности, но своевременностью и состоянием готовности.
Теперь представим, что у тебя ветка в 20-30 коммитов. Пять минут назад ты делал ребейз своей ветки на главную. Тем временем главная обновилась. Сейчас делаешь ребейз ещё раз, мы же делаем это почаще, да?.. Тыдыщ, пересоздаются 30 коммитов, и каждый — потенциальный скандалист.
Ребейз — очень тяжело масштабируемое явление.
storoj
12.02.2018 19:32+1Мы в своей команде пока пришли к мнению, что превращать ветку в fast-forward не очень-то и выигрышно. Если это была реальная ветка с несколькими коммитами, связанными между собой по смыслу, пусть лучше это будет именно merge, чтобы было явно видно: была какая-то работа, вот так-то её решали, такие N изменений применены. Иногда даже делаем
git merge --no-ff.
Rebase применяем только когда это было N коммитов, не связанных между собой, или же "ветка" состоит из одного коммита.
Как показала практика, хорошая история изменений довольно важна, т.к. регулярно приходится возвращаться к коду, написанному год и более назад. Внимание к оформлению истории порой сильно выручает.
Busla
12.02.2018 17:34А зачем продолжать разработку в старом неактуальном окружении?
Где-то баги поправили, тесты дописали, документацию, функционал расширили. Лучше быть в курсе изменений касающихся вашего фронта работы, чем в последний момент разгребать конфликты слияния и пытаться понять почему оно не работает.storoj
12.02.2018 19:26Идея как раз в том, что обычно твоя ветка на то и ветка, чтобы там были изолированные изменения. Это как атомарные коммиты, никто ведь не спорит в логичности такого подхода. Я придерживаюсь мнения, что ветки тоже должны бы быть атомарными. Разгребать конфликты что так, что так придётся – или постепенно, или один раз в конце. По-моему, уж лучше сделать это именно один раз и в конце, чтобы охватить все эти проблемные места, находясь в этом контексте.
Если подтягивать другие изменения в свою ветку, то не всегда можно быть уверенным, что они не порушат какое-то состояние. Потом вместо поиска проблем только в своей истории изменений, ты будешь вынужден учитывать ещё и какие-то левые изменения из других веток.
Если у кого-то есть богатый практический опыт по этой теме, давайте обсудим.
tailan
13.02.2018 14:54А представим ситуацию. У нас есть мастер и релиз. После мердж мастера в релиз его начали тестировать. И обнаружили несколько багов которые критичны. Их там же поправили и отправили релиз пользователям. А что дальше делать? Думаю не стоит копи пастить код. Лучше сделать мердж в мастер в котором идёт дальнейшая работа всех разработчиков.

domix32
12.02.2018 15:58Было бы неплохо для каждого из терминов на всяки случай писать значения на английском (для новичков же). То бишь мерж = merge, ветка — branch и т.д. Да и если уж писать на русском, так по-русски — мерж = слияние.

dovg
12.02.2018 17:57+1Раз удалённый репозиторий (origin) такой же
Origin — это не удаленный репозиторий. Это имя по-умолчанию для удаленного репозитория, которых кстати часто бывает больше одного.
git-scm.com/book/ru/v1/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B-Git-%D0%A0%D0%B0%D0%B1%D0%BE%D1%82%D0%B0-%D1%81-%D1%83%D0%B4%D0%B0%D0%BB%D1%91%D0%BD%D0%BD%D1%8B%D0%BC%D0%B8-%D1%80%D0%B5%D0%BF%D0%BE%D0%B7%D0%B8%D1%82%D0%BE%D1%80%D0%B8%D1%8F%D0%BC%D0%B8
IvanPonomarev
13.02.2018 01:02В этой статье даются вредные советы новичкам, я считаю.
В гите можно делать сотнями разных способов, а новичкам надо рассказывать, как делать правильно. А то ведь и вправду начнут мёржить изменения во все стороны.
На мой взгляд, до новичков очень важно доносить следующее:
- Говорить о Git нужно всегда в контексте принятого у вас процесса разработки и CI/CD. Git работает в синергии с CI/CD. Если в компании есть Git и нет CI/CD, то это неэффективность в квадрате, т. к. тогда уж лучше применять более простой SVN.
- Процесс должен быть построен так, что главная ветка должна быть защищённой от пуша. В неё можно только мёржить, и только такой код из других веток, который прошёл quality gates вашей CI/CD системы. Таким образом, в вашем мастере должен быть гарантированно стабильный код, и фичи, разработка которых гарантированно завершена.
- Ни в коем случае не надо мёржить во все стороны (впрочем, если у вас правильный процесс с защищённым мастером, то не очень-то вы и хаотично помёржите в мастер). Не надо бояться rebase. Отведя локальную ветку с выполняемой вами задачей, работайте с ней и выполняйте rebase часто, пере-отводясь от верхушки мастера по мере поступления новых стабильных коммитов в мастер.
- Выполняя частый rebase, вы «переносите боль на начало». Откладывая всё до финального merge, вы «откладываете боль на потом». Как и в других аналогичных инженерных практиках (например, связанных с автотестированием), общее количество боли будет меньше в первом случае.
- Завершив работу, открывайте Pull Request, успешное закрытие которого сопровождается слиянием с мастером. Условием возможности слияния обязательно должно быть прохождение quality gates вашей CI/CD системы и желательно code review / approval от других разработчиков
hexploy
14.02.2018 15:49Конкретные шаги, такие как, например, pull request в мастер, зависят от workflow.
У нас, например, каждый мерж в мастер означает новый релиз после этого мержа. А feature-бранчи мержатся пулл-реквестом в отдельный бранч будущего релиза
(http://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow)
Собственно, новичку бы посоветовал понять что делают основные команды сами по себе и то как работает его команда. Стратегий использования больше чем одна и правильно следовать той, которая используется.
LeonidY
13.02.2018 08:27Автор, если уж затрагиваем продвинутые темы, то пожалуйста (! пожалуйста !) опишите следующие операции:
1. Скопировать (но не rebase) изменения с ветки А на ветку Б. При нормальной работе в команде разработчиков rebase просто делать нельзя, он уничтожает по умолчанию исходную ветку.
2. Как найти общий коммит для двух веток.
3. Как найти какой коммит УДАЛИЛ конкретную строку из старой версии. Ну и заодно — рассказать про git blame.LeonidY
13.02.2018 08:41И совсем уж забыл — 4. Как из удаленного репозитория R скопировать обновления в не очень удаленный репозиторий L без того, чтобы убить в L все то, что вы там наработали на настоящий момент. Очень полезно, когда например вы работаете автономно.
ashumkin
15.02.2018 17:061. Скопировать (но не rebase) изменения с ветки А на ветку Б. При нормальной работе в команде разработчиков rebase просто делать нельзя, он уничтожает по умолчанию исходную ветку.
создаёте ещё одну ветку С на том же коммите, что и А, и уже её рибейсите (что по сути, набор cherry-pick'ов) на Б — вот у вас и копия (только если делатьgit cherry-pickесть ключ-x, чтобы сообщение коммита содержало ID-коммита, откуда было скопировано изменения)
2. Как найти общий коммит для двух веток.
git merge-base
3. Как найти какой коммит УДАЛИЛ конкретную строку из старой версии...
git log -Sстрока(подробнее в git log --help)
igorbalash
13.02.2018 14:53Только начинаю изучать Git и в поисках информации наткнулся на первую и вторую часть данной статьи. Статья оказалась полезной так как весь текст изложен простым и понятным языком, что для начинающего пользователя является немаловажным. Еще бы хотелось, чтобы автор выпустил статью в которой описываются наиболее популярные версии программ с GUI для Windows и способы работы с ними.
AleksSMR
13.02.2018 14:53Неплохой цикл статей, но данный материал скорее нужен для тех, кто уже работает с GIT для систематизации знаний. Новичку по этой статье сложно будет разобраться — уж больно «гуманитарная» она, без технических деталей. ИМХО конечно же.
Новичкам (и не только) крайне советую курс от Google «How to Use Git and GitHub» на Udacity.
Он бесплатный, небольшой (рельно за 2 дня не напрягаясь пройти), но «технический» на примерах и отлично будет дополнять данный цикл статей, при этом последняя лекция там про взаимодействие с GitHub.apapacy
13.02.2018 18:17В основы git я въезжал довольно долго (правда тогда не работал в ИТ сфере). Разработчики git не побоюсь этого слова гении или где-то близко и писали программу для своего использования. Поэтому получилось очень необычно для обычного пользователя. Для простой работы с git достаточно уверенно знать и применять несколько команд (я насчитал 7 самых ходовых). Тем не менее они порой выглядят немного многословно с применением ключей. И поскольку у каждой команды большое количество ключей то сложно понять что один из них самый ходовой а все остальные это для специальных случаев.

ganqqwerty
14.02.2018 11:37Про rebase крайне интересно было бы послушать таким же человеческим языком. Иногда делаю rebase, чтобы слить слишком мелкие коммиты в более осмысленные покрупнее, но что именно при этом происходит, не задумывался.
ashumkin
>
origin\masterпростите, но всё же
origin/master(не обратный, а прямой слэш; и все опробованные мной на Windows Git-клиенты так показывают)Вы пишете для новичков, на своём опыте осмелюсь утверждать, что их обычно путает (а то и пугает) любое несоответствие «учебника» с реальном выводом..
Ivanye
Спасибо, поправили!