
Здесь в основном цитируются статьи из Беркли, Google Brain, DeepMind и OpenAI за последние несколько лет, потому что их работы наиболее заметны с моей точки зрения. Почти наверняка я что-то упустил из более старой литературы и от других организаций, так что прошу прощения — я всего лишь один человек, в конце концов.

Введение
Однажды в Facebook я заявил следующее.
Когда кто-то спрашивает, может ли обучение с подкреплением (RL) решить их проблему, я сразу отвечаю, что не может. Думаю, что это верно как минимум в 70% случаев.Глубинное обучение с подкреплением сопровождается массой шумихи. И на то есть хорошие причины! Обучение с подкреплением (RL) — невероятно общая парадигма. В принципе, надёжная и высокопроизводительная система RL должна быть прекрасна во всём. Слияние этой парадигмы с эмпирической силой глубинного обучения очевидно само по себе. Глубинное RL — это то, что больше всего похоже на сильный ИИ, и это своего рода мечта, которая подпитывает миллиарды долларов финансирования.
К сожалению, в реальности эта штука пока не работает.
Но я верю, что она выстрелит. Если бы не верил, то не варился бы в этой теме. Но впереди куча проблем, многие из которых фундаментально сложны. Прекрасные демки обученных агентов скрывают всю кровь, пот и слёзы, что пролились в процессе их создания.
Несколько раз я видел, как людей соблазняли последние результаты. Они впервые пробовали глубинное RL и всегда недооценивали трудности. Без сомнения, эта «модельная задача» не так проста, как кажется. И без сомнения, эта область несколько раз их ломала, прежде чем они научились устанавливать реалистичные ожидания в своих исследованиях.
Тут нет чьей-то персональной ошибки. Здесь системная проблема. Легко нарисовать историю вокруг положительного результата. Попробуйте сделать это с отрицательным. Проблема в том, что исследователи чаще всего получают именно отрицательный результат. В некотором смысле такие результаты даже более важны, чем положительные.
В этой статье я объясню, почему глубинное RL не работает. Приведу примеры, когда он всё-таки работает и как добиться более надёжной работы в будущем, на мой взгляд. Я делаю это не для того, чтобы люди перестали работать над глубинным RL, а потому что легче добиться прогресса, если все понимают наличие проблем. Легче достичь согласия, если реально говорить о проблемах, а не снова и снова натыкаться на те же грабли отдельно друг от друга.
Хотелось бы видеть больше исследований на тему глубинного RL. Чтобы сюда приходили новые люди. И чтобы они знали, во что ввязываются.
Прежде чем продолжить, позволю несколько замечаний.
- Здесь цитируются несколько научных статей. Обычно я привожу убедительные негативные примеры и умалчиваю о положительных. Это не значит, что мне не нравится научная работа. Все они хорошие — стоит прочитать, если у вас есть время.
- Я использую термины «обучение с подкреплением» и «глубинное обучение с подкреплением» как синонимы, потому что в моей повседневной работе RL всегда подразумевает глубинное RL. Здесь подвергается критике эмпирическое поведение глубинного обучения с подкреплением, а не обучения с подкреплением в целом. В цитируемых статьях обычно описана работа агента с глубинной нейросетью. Хотя эмпирически критика может относиться также к линейным RL (linear RL) или табличным RL (tabular RL), я не уверен, что эту критику можно распространить на более мелкие задачи. Шумиха вокруг глубинного RL обусловлена тем, что RL преподносится как решение для больших, сложных, многомерных сред, где необходима хорошая аппроксимирующая функция. Именно с этой шумихой, в частности, нам нужно разобраться.
- Статья структурирована так, чтобы двигаться от пессимизма к оптимизму. Знаю, что она немного длинновата, но буду очень признателен, если вы найдёте время прочитать её целиком, прежде чем отвечать.
Без дальнейших церемоний, вот некоторые из случаев, когда глубинное RL даёт сбой.
Глубинное обучение с подкреплением может быть ужасно неэффективным
Самый известный бенчмарк для глубинного обучения с подкреплением — игры Atari. Как показано в ставшей известной статье Deep Q-Networks (DQN), если объединить Q-Learning с нейронными сетями разумного размера и некоторыми трюками оптимизации, то можно достичь человеческих показателей в нескольких играх Atari или превзойти их.
Игры Atari игры работают на 60 кадрах в секунду. Можете сходу прикинуть, сколько кадров нужно обработать самой лучшей DQN, чтобы показать результат как у человека?
Ответ зависит от игры, поэтому взглянем на недавнюю статью компании Deepmind — Rainbow DQN (Hessel et al, 2017). В ней показано, как некоторые последовательные улучшений оригинальной архитектуры DQN улучшают результат, а сочетание всех улучшений максимально эффективно. Нейросеть превосходит результат человека в более чем 40 из 57 игр Atari. Результаты показаны на этом удобном графике.
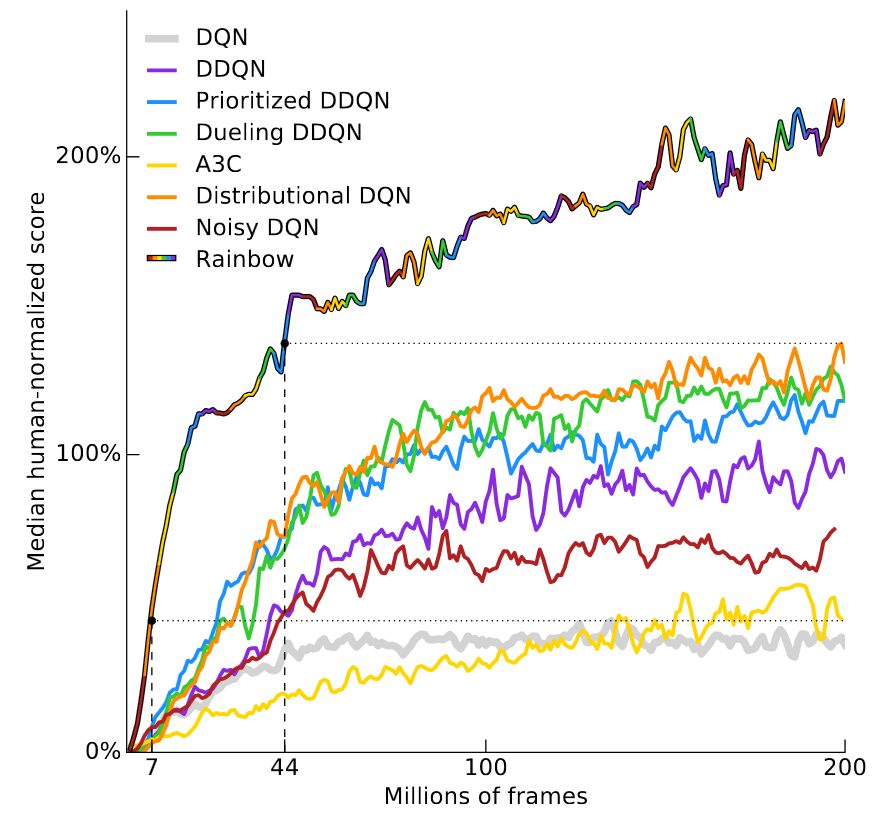
По вертикальной оси отложен «средний по медиане результат, нормализованный по человеческому». он вычисляется путём обучения 57 нейросетей DQN, по одной для каждой игры Atari, с нормализацией результата каждого агента, когда человеческий результат берётся за 100%, а затем вычислением среднего медианного результата для 57 игр. RainbowDQN превосходит рубеж 100% после обработки 18 миллионов фреймов. Это соответствует примерно 83 часам игры, плюс время на обучение, сколько бы они ни занимало. Это немало времени для простеньких игр Atari, которые большинство людей схватывает за пару минут.
Учтите, что 18 млн фреймов на самом деле очень хороший результат, ведь предыдущий рекорд принадлежал системе Distributional DQN (Bellemare et al, 2017), которой требовалось 70 млн фреймов, чтобы достичь результата 100%, то есть примерно в четыре раза больше времени. Что касается Nature DQN (Mnih et al, 2015), он вообще никогда не достигает 100% медианного результата, даже после 200 миллионов фреймов.
Когнитивное искажение «ошибка планирования» гласит, что завершение задачи обычно занимает больше времени, чем вы предполагали. В обучении с подкреплением есть собственная ошибка планирования — для обучения обычно требуется больше образцов, чем вы думали.
Проблема не ограничивается играми Atari. Второй по популярности тест — бенчмарки MuJoCo, набор задач в физическом движке MuJoCo. В этих задачах на входе обычно даются положение и скорость каждого шарнира в симуляции некоего робота. Хотя здесь не нужно решать задачу зрения, системам RL требуется для обучения от до шагов, в зависимости от задачи. Это невероятно много для контроля в таком простом окружении.
Статья DeepMind по паркуру (Heess et al, 2017), проиллюстрированная ниже, обучена с применением 64 воркеров на протяжении более 100 часов. В статье не уточняется, что такое «воркер», но я предполагаю, что это означает один процессор.
Это суперрезультат. Когда он впервые вышел, я был удивлен, что глубинное RL вообще сумело обучиться таким аллюрам на бегу.
Но это потребовало 6400 часов процессорного времени, что немного разочаровывает. Не то чтобы я рассчитывал на меньшее время… просто печально, что в простых навыках глубинное RL по-прежнему на порядок уступает уровню обучения, который мог бы быть полезен на практике.
Здесь есть очевидный контраргумент: а что если просто игнорировать эффективность обучения? Есть определённые окружения, позволяющие легко генерировать опыт. Например, игры. Но для любого окружения где такое невозможно, RL сталкивается с огромными проблемами. К сожалению, большинство окружений попадают именно в эту категорию.
Если вас волнует только итоговая производительность, то многие проблемы лучше решаются другими методами
При поиске решений любой проблемы обычно приходится искать компромисс в достижении разных целей. Вы можете сделать акцент на действительно хорошем решении именно этой конкретной проблемы, или вы можете сделать акцент на максимальном вкладе в общее исследование. Лучшие проблемы — те, где для получения хорошего решения требуется хороший вклад в исследования. Но в реальности трудно найти проблемы, которые отвечают этим критериям.
Чисто в демонстрации максимальной эффективности глубинное RL показывает не очень впечатляющие результаты, потому что его постоянно превосходят другие методы. Вот видеоролик с роботами MuJoCo, которые управляются путём интерактивной оптимизации траектории. Правильные действия вычисляются почти в реальном времени, интерактивно, без автономного обучения. Да, и всё работает на оборудовании 2012 года (Tassa et al, IROS 2012).
Думаю, эту работу вполне можно сравнить со статьёй DeepMind по паркуру. Чем они отличаются?
Разница в том, что здесь авторы применяют управление с прогнозирующими моделями, работая с реальной моделью земного мира (физический движок). В RL нет таких моделей, что сильно затрудняет работу. С другой стороны, если планирование действий на основе модели настолько улучшает результат, то зачем мучиться с навороченным обучением по правилам RL?
Аналогичным образом можно легко превзойти нейросети DQN в Atari с готовым решением поиска по дереву методом Монте-Карло (MCTS). Вот основные показатели из работы Guo et al, NIPS 2014. Авторы сравнивают результаты обученных DQN с результатами агента UCT (это стандартная версия современного MCTS).


Опять же, это нечестное сравнение, потому что DQN не осуществляет поиск, а MCTS делает именно поиск по реальной модели земной физики (эмулятор Atari). Но в некоторых ситуациях вас не волнуют, здесь честное или нечестное сравнение. Иногда просто нужно, чтобы всё работало (если вам нужно полная оценка UCT, см. приложение оригинальной научной статьи Arcade Learning Environment (Bellemare et al, JAIR 2013)).
Обучение с подкреплением теоретически подходит для всего, включая окружения с неизвестной моделью мира. Тем не менее, такая универсальность дорого обходится: трудно использовать какую-то специфическую информацию, которая могла бы помочь в обучении. Из-за этого приходится задействовать массу образцов, чтобы обучиться вещам, которые можно было просто изначально жёстко закодировать.
Опыт показывает, что за исключением редких случаев заточенные на конкретные задачи алгоритмы работают быстрее и лучше, чем обучение с подкреплением. Это не проблема, если вы разрабатываете глубинное RL ради самого глубинного RL, но лично меня расстраивает сравнение эффективности RL c… ну, с чем-нибудь ещё. Одна из причин, почему мне так понравилась AlphaGo — потому что это была однозначная победа глубинного RL, а такое происходит не очень часто.
Из-за всего этого труднее объяснять людям, почему мои задачи такие крутые, сложные и интересные, ведь часто у них нет контекста или опыта, чтобы оценить, почему же они так сложны. Существует определённая разница между тем, что люди думают о возможностях глубинного RL — и его реальными возможностями. Сейчас я работаю в области робототехники. Рассмотрим компанию, которая приходит на ум большинству людей, если вы упоминаете робототехнику: Boston Dynamics.
Эта штука не использует обучение с подкреплением. Я несколько раз встречал людей, которые думали, что здесь используется RL, но нет. Если поищите опубликованные научные работы от группы разработчиков, то найдёте статьи с упоминанием меняющихся во времени линейно-квадратичных регуляторов, решателей задач квадратичного программирования и выпуклой оптимизации. Другими словами, они применяют в основном классические методы робототехники. Выходит, что эти классические техники нормально работают, если грамотно их применить.
Для обучения с подкреплением обычно нужна функция вознаграждения
Обучение с подкреплением предполагает существование функции вознаграждения. Обычно она или есть изначально, или настраивается вручную в автономном режиме и остаётся неизменной во время обучения. Я говорю «обычно», потому что бывают исключения, такие как имитационное обучение или обратное RL (когда функция вознаграждения восстанавливается постфактум), но в большинстве вариантов RL используют вознаграждение как оракул.
Важно отметить: чтобы RL правильно работало, функция вознаграждения должна охватить в точности то, что нам нужно. И я имею в виду в точности. RL раздражающе склонен к переобучению (overfit), что ведёт к неожиданным последствиям. Вот почему Atari настолько хороший бенчмарк. Там не только легко получить множество образцов, но и в каждой игре есть ясная цель — количество очков, так что никогда не придётся беспокоиться о поиске функции вознаграждения. И вы знаете, что у всех остальных та же самая функция.
Популярность задач MuJoCo объясняется теми же причинами. Поскольку они работают в симуляции, то у вас есть полная информация о состоянии объекта, что значительно упрощает создание функции вознаграждения.
В задаче Reacher вы управляете двухсегментной рукой, которая соединена с центральной точкой, а цель состоит в том, чтобы переместить конец руки в заданную мишень. См. ниже пример успешного обучения.
Поскольку все координаты известны, вознаграждение можно определить как расстояние от конца руки до мишени, плюс небольшое время на перемещение. В принципе, в реальном мире можно провести такой же опыт, если у вас достаточно сенсоров, чтобы точно замерить координаты. Но в зависимости от того, что должна сделать система, может быть трудно определить разумное вознаграждение.
Сама по себе функция вознаграждения не являлась бы большой проблемой, если бы не…
Сложность разработки функции вознаграждения
Сделать функцию вознаграждения не так сложно. Трудности появляются, когда вы пытаетесь создать такую функцию, которая будет поощрять правильное поведение, и в то же время система сохранит обучаемость.
В среде HalfCheetah у нас двуногий робот, ограниченный вертикальной плоскостью, что означает, то есть он может двигаться только вперёд или назад.

Цель — научиться бегать рысцой. Награда — скорость HalfCheetah (видео).
Это плавное или сформированное (shaped) вознаграждение, то есть оно возрастает с приближением к конечной цели. В отличие от разреженного (sparse) вознаграждения, которое даётся только по достижении конечного состояния цели, а в других состояниях отсутствует. Плавный рост вознаграждения часто намного проще в освоении, потому что он обеспечивает положительную обратную связь, даже если обучение не дало полного решения проблемы.
К сожалению, вознаграждение с плавным ростом может быть предвзято (bias). Как уже говорилось, из-за этого проявляется неожиданное и нежелательное поведение. Хорошим примером являются гонки на лодках из статьи в блоге OpenAI. Предполагаемая цель — прийти к финишу. Можете представить вознаграждение как +1 за окончание гонки в заданное время, и вознаграждение 0 в ином случае.
Функция вознаграждения даёт очки за пересечение чекпоинтов и за сбор бонусов, которые позволяют быстрее добраться до финиша. Как выяснилось, сбор бонусов даёт больше очков, чем завершение гонки.
Если честно, эта публикация поначалу меня немного раздосадовала. Не потому что она неправильная! А потому что мне казалось, что она демонстрирует очевидные вещи. Конечно же обучение с подкреплением даст странный результат, когда вознаграждение неверно определено! Мне казалось, что публикация придаёт неоправданно большое значение данному конкретному случаю.
Но потом я начал писать эту статью и понял, что самый убедительный пример неправильно определённого вознаграждения — как раз это самое видео с гонками на лодках. С тех пор его использовали в нескольких презентациях на эту тему, что привлекло внимание к проблеме. Так что ладно, я с неохотной признаю, что это была хорошая публикация в блоге.
Алгоритмы RL попадают в чёрную дыру, если им приходится более-менее догадываться об окружающем мире. Самая универсальная категория безмодельных RL — это почти как оптимизация «чёрного ящика». Таким системам только разрешают предположить, что они находятся в MDP (марковский процесс принятия решений) — и больше ничего. Агенту просто говорят, что вот за это ты получаешь +1, а за это — не получаешь, а всё остальное должен узнать самостоятельно. Как и при оптимизации «чёрного ящика», проблема в том, что хорошим считается любое поведение, которое даёт +1, даже если вознаграждение получено неправильным путём.
Классический пример не из сферы RL — когда кто-то применил генетические алгоритмы для проектирования микросхем и получил схему, в которой для окончательного дизайна был необходим один неподключенный логический вентиль.
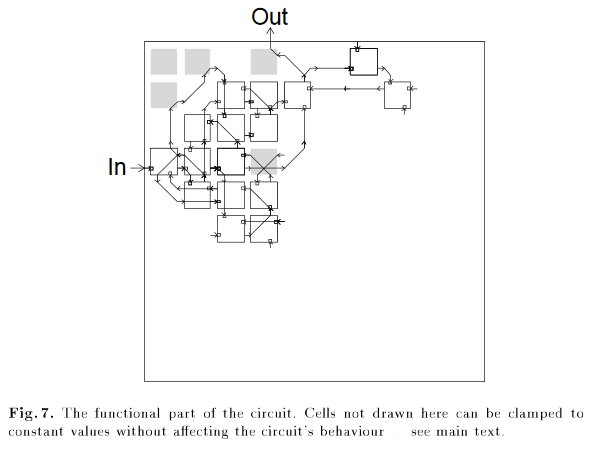
Серые элементы необходимы для корректной работы схемы, в том числе элемент в левом верхнем углу, хотя он ни к чему не подключен. Из статьи “An Evolved Circuit, Intrinsic in Silicon, Entwined with Physics”
Или более свежий пример — вот публикация в блоге Salesforce от 2017 года. Их целью было составление резюме для текста. Базовая модель обучалась с учителем, затем её оценивали автоматизированной метрикой под названием ROUGE. ROUGE — это недифференцируемое вознаграждение, но RL умеет работать с такими. Так что они попытались применить RL для оптимизации ROUGE напрямую. Это даёт высокий показатель ROUGE (ура!), но на самом деле не очень хорошие тексты. Вот пример.
Баттона лишили его 100-й гонки за McLaren после того, как ERS не пустила его на старт. Так завершились неудачные выходные для британца. Баттона опередили в квалификации. Финишировал впереди Нико Росберга в Бахрейне. У Льюиса Хэмилтона. В 11 гонках.. Гонка. Чтобы лидировать 2000 кругов.. В... И. — Paulus et al, 2017
И хотя модель RL показала максимальный результат ROUGE…
…они в итоге решили использовать другую модель для составления резюме.
Ещё один забавный пример. Это из статьи Popov et al, 2017, также известной как «статья по складыванию конструктора Лего». Авторы применяют распределённую версию DDPG для обучения правилам захвата. Цель — ухватить красный кубик и насадить его на синий.
Они заставили её работать, но столкнулись с интересным случаем сбоя. Начальное подъёмное движение вознаграждается исходя из высоты поднятия красного блока. Это определяется z-координатой нижней грани кубика. В одном из вариантов сбоя модель научилась переворачивать красный кубик нижней гранью вверх, а не поднимать его.
Ясно, что такое поведение не предполагалось. Но RL это не волнует. С точки зрения обучения с подкреплением она получила вознаграждение за переворачивание кубика — поэтому будет продолжать переворачивать кубик.
Один из способов решения этой проблемы — сделать вознаграждение разреженным, давая его только после соединения кубиков. Иногда это срабатывает, потому что редкое вознаграждение поддаётся обучению. Но часто это не так, поскольку отсутствие позитивного подкрепления всё слишком усложняет.
Ещё один вариант решения проблемы — тщательное формирование вознаграждения, добавление новых условий вознаграждения и корректировка коэффициентов для уже существующих условий до тех пор, пока алгоритм RL не начнёт демонстрировать желаемое поведение при обучении. Да, возможно побороть RL на этом фронте, но такая борьба не приносит удовлетворения. Иногда она необходима, но я никогда не чувствовал, что чему-то научился в процессе этого.
Для справки, здесь одна из функций вознаграждения из статьи по складыванию конструктора Лего.
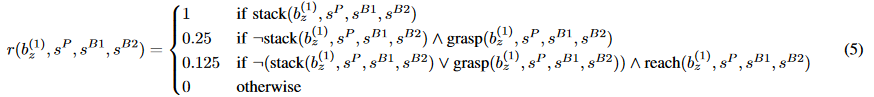
Не знаю, сколько времени ребята потратили на разработку этой функции, но по количеству членов и разных коэффициентов я бы сказал «много».
В разговорах с другими исследователями RL я слышал несколько историй об оригинальном поведении моделей с неправильно установленными вознаграждениями.
- Коллега учит агента ориентироваться в комнате. Эпизод заканчивается, если агент выходит за границы, но в этом случае не накладывается штраф. По окончании обучения агент усвоил поведение самоубийцы, потому что отрицательное вознаграждение было очень легко получить, а положительное — слишком сложно, так что быстрая смерть с результатом 0 оказалась предпочтительнее, чем долгая жизнь с высоким риском отрицательного результата.
- Друг обучал симулятор руки робота двигаться в направлении определённой точки над столом. Оказывается, точка была определена относительно стола, а стол не был ни к чему привязан. Модель научилась очень сильно стучать по столу, заставляя его упасть, что перемещало целевую точку — и та оказывалась рядом с рукой.
- Исследователь рассказывал о применении RL для обучения симулятора роботизированной руки брать молоток и забивать гвоздь. Первоначально вознаграждение определялось тем, насколько далеко гвоздь вошёл в отверстие. Вместо того, чтобы взять молоток, робот забивал гвоздь собственными конечностями. Тогда они добавили вознаграждение, чтобы поощрить робота брать молоток. В итоге усвоенной стратегией для робота стало взять молоток… и бросить инструмент в гвоздь, а не использовать его нормальным способом.
Правда, всё это — истории из чужих уст, лично я не видел видеоролики с таким поведением. Но ни одна из этих историй не кажется мне невозможной. Я погорел на RL слишком много раз, чтобы верить в обратное.
Знаю людей, которые любят рассказывать истории об оптимизаторах скрепок. Ладно, я понимаю, честно. Но по правде мне надоело слушать эти истории, потому что они всегда говорят о некоем сверхчеловеческом дезориентированном сильном ИИ как о реальной истории. Зачем выдумывать, если вокруг столько настоящих историй, которые происходят каждый день.
Даже с хорошим вознаграждением бывает трудно избежать локального оптимума
Предыдущие примеры RL часто называют «хаками вознаграждения». Как по мне, это умное, нестандартное решение, которое приносит большее вознаграждение, чем предполагаемое решение от проектировщика задачи.
Хаки вознаграждения — это исключения. Гораздо более распространены случаи некорректных локальных оптимумов, которые происходят из неправильного компромисса между разведкой и эксплуатацией (exploration?exploitation).
Вот одно из моих любимых видео. Здесь реализована нормализованная функция преимущества, которая обучается в среде HalfCheetah.
С точки зрения постороннего наблюдателя это очень, очень глупо. Но мы называем это глупым только потому что смотрим со стороны и имеем кучу знаний о том, что перемещаться на ногах лучше, чем лёжа на спине. RL не знает этого! Он видит вектор состояния, посылает векторы действий и видит, что получает некоторое положительное вознаграждение. Вот и всё.
Вот самое правдоподобное объяснение, которое я могу придумать по поводу того, что произошло во время обучения.
- В процессе случайного исследования модель обнаружила, что упасть вперёд выгоднее, чем оставаться без движения.
- Модель достаточно часто делала это, чтобы «прошить» такое поведение и начать падать непрерывно.
- После падения вперёд модель узнала, что если применить достаточное усилие, то можно сделать сальто назад, которое даёт чуть больше награды.
- Модель достаточно часто делала сальто — и убедилась, чтобы это хорошая идея, так что теперь обратное сальто «прошито» в постоянное поведение.
- С условием постоянных сальто назад, что проще для модели — обучиться исправленному поведению и пойти по «стандартному пути» или научиться двигаться вперед, лёжа на спине? Я бы поставил на второй вариант.
Это очень смешно, но явно не то, что мы хотим от робота.
Вот ещё один неудачный пример, на этот раз в окружении Reacher (видео)

В этом прогоне случайные начальные веса, как правило, выдавали сильно положительные или сильно отрицательные значения для действий. Из-за этого большинство действий выполнялись с максимально или минимально возможным ускорением. В самом деле, сильно раскрутить модель очень легко: просто выдавайте высокую величину усилия на каждый шарнир. Когда робот раскрутился, уже сложно выйти из этого состояния каким-то понятным способом: чтобы остановить безудержное вращение, следует предпринять несколько шагов разведки. Конечно, такое возможно. Но в этом прогоне такое не произошло.
В обоих случаях мы видим классическую проблему разведки?эксплуатации, которая с незапамятных времён преследует обучение с подкреплением. Ваши данные вытекают из текущих правил. Если текущие правила предусматривают широкую разведку, вы получите ненужные данные и ничему не обучитесь. Слишком сильно эксплуатируете — и «прошьёте» неоптимальное поведение.
Есть несколько интуитивно приятных идей на этот счёт — внутренние побуждения и любопытство, разведка на основе подсчёта и т.д. Многие из этих подходов впервые предложили в 80-е годы или ранее, а некоторые позже пересмотрели для моделей глубокого обучения. Но насколько я знаю, ни один подход не работает стабильно во всех средах. Иногда помогает, иногда нет. Было бы неплохо, чтобы какой-то трюк разведки срабатывал везде, но я сомневаюсь, что в обозримом будущем найдут серебряную пулю такого калибра. Не потому что никто не пытается, а потому что разведка-эксплуатация очень, очень, очень, очень сложное дело. Цитата из статьи о многоруком бандите из Википедии:
Впервые в истории эта проблема была изучена учёными стран-союзников Второй мировой войны. Она оказалась настолько трудноразрешимой, что, по словам Питера Уиттла, её предложили подбросить немцам, чтобы германские учёные тоже потратили на неё своё время.(Источник: Q-Learning for Bandit Problems, Duff 1995)
Я представляю глубинное RL как беса, который специально неправильно понимает ваше вознаграждение и активно ищет самый ленивый способ достижения локального оптимума. Немного смешно, но это оказалось действительно продуктивным мышлением.
Даже если глубинное RL работает, он может переобучиться до странного поведения
Глубинное обучение популярно, потому что это единственная область машинного обучения, где социально приемлемо обучаться на тестовом наборе.(Источник)
Положительная сторона обучения с подкреплением в том, что если хотите добиться хорошего результата в конкретной среде, то можете переобучаться как сумасшедший. Недостаток в том, что если нужно расширить модель на любую другую среду, вероятно, она будет плохо работать из-за сумасшедшей переобученности.
Сети DQN справляются со многими играми Atari, потому что всё обучение каждой модели сосредоточено на единственной цели — добиться максимального результата в одной игре. Окончательную модель невозможно расширить на другие игры, потому что её так не обучали. Вы можете настроить обученную DQN для новой игры Atari (см. работу Progressive Neural Networks (Rusu et al, 2016)), но никакой гарантии, что такой перенос состоится, и обычно никто не ожидает этого. Это не тот дикий успех, который видят люди на предобученных признаках ImageNet.
Чтобы предупредить некоторые очевидные комментарии: да, в принципе, обучение на широком диапазоне сред может решить некоторые проблемы. В отдельных случаях такое расширение действия модели происходит само собой. Примером может служить навигация, где можно пробовать случайные локации целей и использовать универсальные функции для обобщения. (см. Universal Value Function Approximators, Schaul et al, ICML 2015). Я считаю эту работу очень многообещающей, и позже приведу больше примеров из этой работы. Но думаю, что возможности обобщения глубинного RL пока не настолько велики, чтобы справиться с разнообразным набором задач. Восприятие стало намного лучше, но у глубинного RL ещё впереди тот момент, когда появится «ImageNet для управления». OpenAI Universe пыталась разжечь этот костёр, но из того, что я слышал, задача оказалась слишком сложной, так что они добились немногого.
Пока нет такого момента для обобщения моделей, мы застряли с удивительно узкими по охвату моделями. В качестве примера (и в качестве повода посмеяться над моей собственной работой) посмотрим на статью Can Deep RL Solve Erdos-Selfridge-Spencer Games? (Raghu et al, 2017). Мы изучили комбинаторную игру для двух игроков, где есть решение в аналитическом виде для оптимальной игры. В одном из первых экспериментов мы зафиксировали поведение игрока 1, а затем обучили игрока 2 с помощью RL. При этом вы можете считать действия игрока 1 частью среды. Обучая игрока 2 против оптимального игрока 1, мы показали, что RL способен показать высокий результат. Но когда мы применили те же правила против неоптимального игрока 1, то эффективность игрока 2 упала, потому что она не распространялась на неоптимальных противников.
Авторы статьи Lanctot et al, NIPS 2017 получили похожий результат. Здесь два агента играют в лазертаг. Агенты обучены с помощью мультиагентного обучения с подкреплением. Для проверки обобщения обучение запустили с пятью случайными исходными точками (сидами). Вот видеозапись агентов, которых обучили играть друг против друга.
Как видите, они обучились сближаться и стрелять друг в друга. Затем авторы взяли игрока 1 из одного эксперимента — и свели его с игроком 2 из другого эксперимента. Если усвоенные правила обобщаются, то мы должны увидеть похожее поведение.
Спойлер: мы его не увидим.
Кажется, это общая проблема многоагентных RL. Когда агенты обучаются друг против друга, то происходит своего рода совместная эволюция. Агенты обучаются реально хорошо биться друг с другом, но когда их направляют против игрока, с которым они раньше не встречались, то эффективность снижается. Хочу отметить, что единственное различие между этими видеороликами — случайный сид. Тот же алгоритм обучения, те же гиперпараметры. Разница в поведении чисто из-за случайного характера начальных условий.
Тем не менее, есть некоторые впечатляющие результаты, полученные в среде с самостоятельной игрой друг против друга — они как будто противоречат общему тезису. В блоге OpenAI есть хорошая публикация о некоторых их работах в этой области. Самостоятельная игра также является важной частью AlphaGo и AlphaZero. Моя интуитивная догадка заключается в том, что если агенты обучаются в одинаковом темпе, то могут постоянно конкурировать и ускорять обучение друг друга, но если один из них учится намного быстрее другого, то слишком использует уязвимости слабого игрока — и переобучается. Как вы переходите от симметричной самостоятельной игры к общим мультиагентным настройкам, то становится намного сложнее убедиться, что обучение идёт на одинаковой скорости.
Даже без учёта обобщения может статься, что финальные результаты нестабильны и их трудно воспроизвести
Почти у каждого алгоритма машинного обучения есть гиперпараметры, которые влияют на поведение системы обучения. Часто их выбирают вручную или случайным поиском.
Обучение с учителем стабильно. Фиксированный датасет, проверка истинными данными. Если немного изменить гиперпараметры, функционирование не слишком изменится. Не все гиперпараметры работают хорошо, но за все эти годы найдено много эмпирических трюков, так что многие гиперпараметры демонстрируют признаки жизни во время обучения. Эти признаки жизни очень важны: они говорят, что вы на правильном пути, делаете что-то разумное — и нужно уделить больше времени.
В настоящее время глубинное RL вообще не стабилен, что очень раздражает в процессе исследований.
Когда я начал работать в Google Brain, то практически сразу занялся реализацией алгоритма из вышеупомянутой статьи Normalized Advantage Function (NAF). Я думал, это займёт всего две-три недели. У меня было несколько козырей: определённое знакомство с Teano (которое хорошо переносится на TensorFlow), какой-то опыт работы с глубинным RL, а ещё ведущий автор статьи по NAF стажировался в Brain, так что я мог приставать к нему с вопросами.
В итоге мне понадобилось шесть недель, чтобы воспроизвести результаты, из-за нескольких багов в программном обеспечении. Вопрос в том, почему эти баги скрывались так долго?
Чтобы ответить на этот вопрос, рассмотрим простейшую задачу непрерывного управления в OpenAI Gym: задачу Pendulum. В этой задаче маятник закреплён в определённой точке и на него действует сила тяжести. На входе трёхмерное состояние. Пространство действий одномерное: это момент силы, который прилагается к маятнику. Цель в том, чтобы сбалансировать маятник в точно вертикальном положении.
Это маленькая проблемка, и она становится ещё проще благодаря чётко сформулированному вознаграждению. Награда зависит от угла маятника. Действия, приближающие маятник к вертикальному положению, не только дают вознаграждение, они увеличивают его.
Вот видео модели, которая почти работает. Хотя она не приводит маятник в точно вертикальное положение, но выдаёт точный момент силы для компенсации гравитации.

А вот график производительности после исправления всех ошибок. Каждая линия — это кривая вознаграждения от одного из десяти независимых прогонов. Те же гиперпараметры, разница только в случайной начальной точке.

Семь из десяти прогонов сработали хорошо. Три не прошли. Частота сбоев 30% считается рабочей. Вот ещё один график из опубликованной работы “Variational Information Maximizing Exploration” (Houthooft et al, NIPS 2016). Среда — HalfCheetah. Награду сделали разреженной, хотя подробности не слишком важны. По оси y — эпизодическое вознаграждение, по оси x — количество отрезков времени, а используемый алгоритм — TRPO.
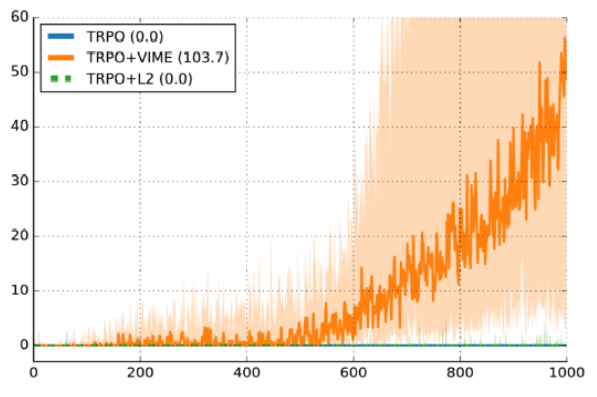
Тёмная линия — медианная производительность по десяти случайным сидам, а затенённая область — это покрытие от 25-го до 75-го процентиля. Не поймите меня неправильно, этот график представляется хорошим аргументом в пользу VIME. Но с другой стороны, линия 25-го процентиля реально близка к нулю. Это значит, что около 25% не работают просто из-за случайной начальной точки.
Смотрите, в обучении с учителем тоже есть дисперсия, но не настолько плохая. Если бы мой код обучения с учителем не справлялся в 30% прогонов со случайными сидами, то я был бы совершенно уверен, что произошла какая-то ошибка при загрузке данных или обучении. Если же мой код обучения с подкреплением справляется не лучше рандома, то я понятия не имею — то ли это баг, то ли плохие гиперпараметры, то ли мне просто не повезло.
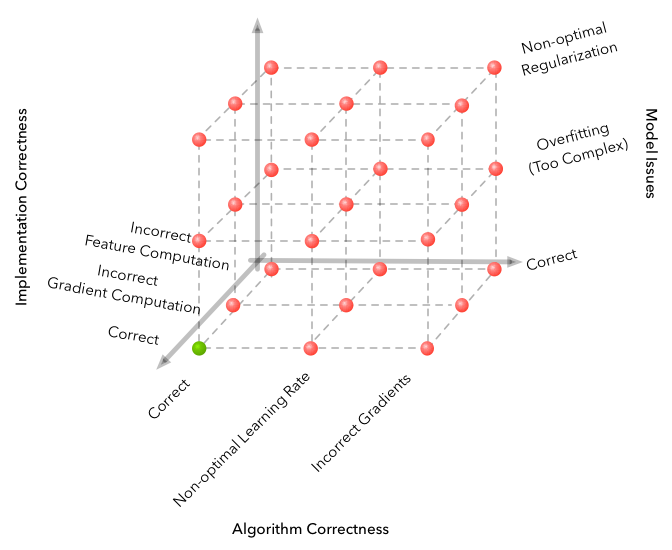
Это иллюстрация из статьи «Почему с машинным обучением так “сложно” работать?» Основной тезис в том, что машинное обучение добавляет дополнительные измерения в пространство сбоев, что экспоненциально увеличивает количество вариантов сбоя. Глубинное RL добавляет ещё одно измерение: случайность. И единственный способ решить проблему случайности — вычистить шум.
Если ваш алгоритм обучения обладает неэффективной выборкой и при этом неустойчив, то он сильно снижает продуктивность вашего исследования. Может, ему понадобится всего 1 миллион шагов. Но когда вы умножите это на пять случайных входных значений, а затем умножите на разброс гиперпараметров, то увидите экспоненциальный рост вычислений, необходимых для эффективной проверки гипотезы.
Если вам так станет легче, то я какое-то время занимаюсь этим — и потратил около 6 последних недель, чтобы вывести с нуля градиенты модели, которые работают в 50% случаев над кучей задач RL. И у меня есть кластер GPU и несколько друзей, с которыми обедаю каждый день — и они работают в данной области последние несколько лет.
К тому же, полученные из области обучения с учителем сведения о правильном проектировании свёрточных нейросетей, похоже, не распространяются на область обучения с подкреплением, потому что здесь главные ограничения — распределение кредита/контроль битрейта, а не отсутствие эффективного представления. Ваши ResNet, batchnorm и очень глубинные сети тут не действуют.
[Обучение с учителем] хочет работать. Даже если вы что-то испортите, то обычно получаете какой-то неслучайный результат. RL нужно заставлять работать. Если вы что-то испортите или не настроите что-то достаточно хорошо, то почти наверняка получите правила, которые хуже случайных. И даже если всё отлично настроено, то плохие результаты будут в 30% случаев. Почему? Да просто так.
Короче, ваши проблемы скорее объясняются сложностью работы глубинных RL, чем сложностью «проектирования нейронных сетей». — Комментарий на Hacker News от Андрея Карпати (Andrej Karpathy), когда он работал в OpenAI
Нестабильность случайных сидов похожа на канарейку в угольной шахте. Если простая случайность приводит к такой сильной разбежке между прогонами, то представьте, какая разница возникнет при реальном изменении кода.
К счастью, нам не нужно проводить этот мысленный эксперимент, потому что он уже проведён и описан в статье “Deep Reinforcement Learning That Matters” (Henderson et al, AAAI 2018). Вот некоторые выводы:
- Умножение вознаграждения на константу может привести к значительной разнице в производительности.
- Пяти случайных сидов (общая метрика в отчётах) может быть недостаточно для демонстрации значимых результатов, поскольку при тщательном отборе могут получиться неперекрывающиеся доверительные интервалы.
- У разных реализаций одного и того же алгоритма разная производительность для одной и той же задачи, даже с одинаковыми гиперпараметрами.
Моя теория в том, что RL очень чувствителен как к инициализации, так и к динамике учебного процесса, потому что данные всегда собираются в интернете и единственный контролируемый параметр — только размер вознаграждения. Модели, которые случайным образом сталкиваются с хорошими примерами для обучения, работают намного лучше. Если модель не видит хороших примеров, то она может вообще ничему не научиться, поскольку всё больше убеждается, что любые отклонения безрезультатны.
А как же все великолепные достижения глубинного RL?
Конечно, глубинное обучение с подкреплением добилось некоторых отличных результатов. DQN уже не новинка, но в своё время это было абсолютно сумасшедшее открытие. Одна и та же модель учится непосредственно по пикселям, без настройки на каждую игру в отдельности. И AlphaGo, и AlphaZero тоже остаются очень впечатляющими достижениями.
Но кроме этих успехов трудно найти случаи, когда глубинное RL имеет практическую ценность для реального мира.
Я пытался подумать, как можно использовать глубинное RL в реальном мире для практических задач — и это на удивление сложно. Думал, что найду какое-нибудь применение в системах рекомендаций, но по-моему там по-прежнему доминируют коллаборативная фильтрация и контекстуальные бандиты.
Самое лучшее, что я в итоге нашёл — это два проекта Google: снижение энергопотребления в дата-центрах и недавно анонсированный проект AutoML Vision. Джек Кларк из OpenAI обратился к читателям в твиттере с аналогичным вопросом — и пришёл к такому же выводу. (Твит прошлого года, до анонса AutoML).
Знаю, что Audi делает что-то интересное с глубинным RL, потому что они на NIPS показали маленькую модель беспилотного гоночного автомобиля и сказали, что для него разработана система глубинного RL. Знаю, что ведётся искусная работа с оптимизацией размещения устройств для больших тензорных графов (Mirhoseini et al, ICML 2017). У Salesforce есть модель резюмирования текста, которая работает, если достаточно аккуратно применять RL. Финансовые компании наверняка экспериментируют с RL в то время как вы читаете эту статью, но пока нет доказательств этому. (Конечно, у финансовых компаний есть причины скрывать свои методы игры на рынке, так что твёрдых доказательств мы можем некогда не получить). Facebook отлично работает с глубинным RL для чатботов и речи. Каждая интернет-компания в истории наверняка когда-нибудь думала о внедрении RL в свою рекламную модель, но если кто-то в реальности внедрил RL, то молчит об этом.
Так что на мой взгляд либо глубинное RL до сих пор остаётся темой академических исследований, недостаточно надёжной технологией для широкого применения, либо его реально можно заставить эффективно работать — и люди, которым это удалось, не разглашают информацию. Я думаю, что первый вариант более вероятен.
Если бы вы пришли ко мне с проблемой классификации изображений, я бы посоветовал предобученные модели ImageNet — вероятно, они отлично справятся с задачей. Мы живём в мире, где киношники из сериала «Кремниевая долина» в шутку делают реальное приложение ИИ для распознавания хот-догов. Не могу сказать о таких же успехах глубинного RL.
С учётом этих ограничений, когда применять глубинное RL?
Это априори сложный вопрос. Проблема в том, что вы пытаетесь применить один подход RL для разных окружений. Вполне естественно, что он не будет всегда работать.
С учётом вышесказанного можно сделать некоторые выводы из имеющихся достижений обучения с подкреплением. Эти проекты, где глубинное RL или обучается какому-то качественно впечатляющему поведению, или обучается лучше, чем предыдущие системы в этой области (правда, это очень субъективные критерии).
Вот мой список на данный момент.
- Проекты, упомянутые в предыдущих разделах: DQN, AlphaGo, AlphaZero, паркур-бот, снижение энергопотребления в дата-центрах и AutoML с Neural Architecture Search.
- Бот OpenAI Dota 2 1v1 Shadow Fiend, который обыграл лучших профессионалов с упрощенными настройками поединка.
- Бот Super Smash Brothers Melee, способный обыграть профессиональных игроков в 1v1 Falcon таким же образом. (Firoiu et al, 2017).
(Краткое отступление: машинное обучение недавно обыграло профессиональных игроков в безлимитный техасский холдем. Программа использует одновременно системы Libratus (Brown et al, IJCAI 2017) и DeepStack (Moravcik et al, 2017). Я говорил с несколькими людьми, которые думали, что здесь работает глубинное RL. Обе системы очень классные, но в них не применяется глубинное обучение с подкреплением. Там используется алгоритм контрфактуальной минимизации сожаления и грамотное итерационное решение подигр).
Из этого списка можно вычленить общие свойства, которые облегчают обучение. Ни одно из этих свойств, перечисленных ниже, не требуется для обучения, но чем больше их присутствует — тем определённо лучше будет результат.
- Лёгкая генерация практически неограниченного опыта. Здесь польза очевидна. Чем больше у вас данных, тем проще обучение. Это относится к Atari, го, шахматам, сёги и моделируемым средам паркур-бота. Вероятно, это относится и к проекту электропитания дата-центра, потому что в предыдущей работе (Gao, 2014) было показано, что нейросети способны с высокой точностью прогнозировать энергоэффективность. Именно такую имитационную модель вы бы взяли для обучения системы RL.
Возможно, принцип применим к работам по Dota 2 и SSBM, но это зависит от максимальной скорости игры и количества процессоров. - Задача упрощается до более простой формы. Одна из самых распространённых ошибок в глубинном RL — слишком амбициозные планы и мечты. Обучение с подкреплением способно на всё! Но это не значит, что нужно браться за всё сразу.
Бот OpenAI Dota 2 работает только в начале игры, только Shadow Fiend против Shadow Fiend, только 1х1, с определёнными настройками, с фиксированным положением и типом зданий, а также вероятно обращается к Dota 2 API, чтобы не решать задачи обработки графики. Бот SSBM показывает сверхчеловеческую производительность, но только в игре 1х1, только с Captain Falcon, только на Battlefield с бесконечным временем матча.
Это не издевательство над каким-то из ботов. В самом деле, зачем решать сложную проблему если вы даже не знаете, решается ли простая? Общий подход в этой области — сначала добиться минимального доказательства концепции, а позже обобщить его. OpenAI расширяет свою работу по Dota 2. Продолжается и работа по расширению бота SSBM на других персонажей. - Есть способ обучаться в самостоятельной игре. Так действуют AlphaGo, AlphaZero, боты Dota 2 Shadow Fiend и SSBM Falcon. Должен отметить, что под самостоятельной игрой я имею в виду именно конкурентную игру, хотя оба игрока могут управляться одним агентом. Судя по всему, такая настройка даёт наиболее стабильный результат.
- Есть ясный способ определить подходящее для обучения, неподдельное вознаграждение. В играх для двух игроков это +1 за победу и ?1 за проигрыш. В оригинальной статье по Neural Architecture Search от Zoph et al, ICLR 2017 была точность валидации обученной модели. Каждый раз, когда вы задаёте плавное вознаграждение, то вводите шанс изучения неоптимальной политики, которая оптимизирует модель для неправильной цели.
Если хотите почитать больше о том, как сделать правильное вознаграждение, попробуйте поискать по фразе [правильное правило подсчёта очков]. Эта публикация в блоге Терренса Тао приводит доступный пример.
Что касается обучаемости, у меня нет советов, кроме как попробовать и смотреть, что работает, а что нет. - Если нужно определить непрерывное вознаграждение, то по крайней мере оно должно быть богатым. В Dota 2 вознаграждение может присуждаться за последние хиты (за каждого убитого монстра любым игроком) и здоровье (срабатывает после каждой точного атаки или применения скилла). Эти сигналы поступают быстро и часто. Боту SSBM вознаграждение можно давать за нанесённый и полученный урон, с сигналом после каждой успешной атаки. Чем короче задержка между действием и следствием, тем быстрее замыкается цикл обратной связи — и тем легче системе подкрепления найти путь к максимальному вознаграждению.
Пример: Neural Architecture Search
Можно объединить несколько принципов и проанализировать успех Neural Architecture Search. Согласно первоначальной версии ICLR 2017, после 12800 образцов глубинное RL способно спроектировать лучшие в своём роде архитектуры нейросетей. По общему признанию, в каждом примере требовалось обучать нейросеть до сходимости, но это всё равно очень эффективно по количеству образцов.
Как упоминалось выше, наградой является точность валидации. Это очень богатый сигнал вознаграждения — если изменение структуры нейросети повысит точность всего с 70% до 71%, RL всё равно выиграет от этого. Кроме того, есть свидетельства того, что гиперпараметры в глубинном обучении близки к линейно независимым. (Это было эмпирически показано в работе Hyperparameter Optimization: A Spectral Approach (Hazan et al, 2017) — моё резюме здесь, если интересно). NAS не настраивает конкретно гиперпараметры, но думаю, вполне разумно, что решения проектирования нейросети принимаются таким образом. Это хорошая новость для обучения, учитывая сильные корреляции между решением и производительностью. Наконец, здесь не только богатая награда, но здесь именно то, что нам важно при обучении моделей.
Все вместе эти причины позволяют понять, почему NAS требуется «всего» около 12800 обученных сетей для определения лучшей нейросети по сравнению с миллионами примеров, необходимых в других средах. С разных сторон всё играет в пользу RL.
В целом, подобные истории успеха по-прежнему исключение, а не правило. Многие кусочки паззла должны правильно сложиться, чтобы обучение с подкреплением работало убедительно, и даже в этом случае будет непросто.
В общем, сейчас глубинное RL нельзя назвать технологией, которая работает прямо из коробки.
Взгляд в будущее
Есть старая поговорка — каждый исследователь со временем обучается, как ненавидеть свою область исследований. Прикол в том, что исследователи всё равно продолжают заниматься этим, потому что им слишком нравятся проблемы.
Это примерно то, как я отношусь к глубинному обучению с подкреплением. Несмотря на всё сказанное, я абсолютно уверен, что нам нужно пытаться применять RL на разных проблемах, в том числе на тех, где оно скорее всего окажется неэффективным. Но как ещё нам улучшить RL?
Не вижу причин, почему глубинное RL не будет работать в будущем, если дать технологии время для совершенствования. Начнут происходить некоторые очень интересные вещи, когда глубинное RL станет достаточно надёжным для широкого использования. Вопрос в том, как этого добиться.
Ниже я перечислил некоторые правдоподобные варианты развития будущего. Если для развития в этом направлении нужны дополнительные исследования, то указаны ссылки на соответствующие научные статьи в этих областях.
Локальные оптимумы достаточно хороши. Было бы высокомерием утверждать, что сами люди глобально оптимальны во всём. Я бы сказал, что мы чуть-чуть лучше других видов оптимизированы для создания цивилизации. В том же духе и решение RL необязательно должно стремиться к глобальным оптимумам, если его локальные оптимумы превышают базовый уровень человека.
Железо всё решит. Знаю людей, которые считают, что важнее всего для создания ИИ — просто увеличить быстродействие железа. Лично я скептически отношусь к тому, что железо решит все проблемы, но безусловно, оно внесёт важный вклад. Чем быстрее всё работает, тем меньше вас волнует неэффективность образцов и тем легче проломиться брутфорсом через проблемы разведки.
Добавить больше сигналов обучения. Разреженные вознаграждения сложно усвоить, потому что поступает очень мало информации о том, что именно даёт эффект. Вполне возможно, что мы или породим положительные награды в виде галлюцинаций (Hindsight Experience Replay, Andrychowicz et al, NIPS 2017), или определим вспомогательные задачи (UNREAL, Jaderberg et al, NIPS 2016), или построим хорошую модель мира, начав с самоконтролируемого обучения. Добавим вишенок на тортик, так сказать.
Обучение на моделях повысит эффективность выборки. Вот как я описываю RL на основе модели: «Все хотят её сделать, но немногие знают как». В принципе, хорошая модель исправляет кучу проблем. Как видно на примере AlphaGo, наличие модели в принципе сильно облегчает поиск хорошего решения. Хорошие модели мира неплохо переносятся на новые задачи, а внедрение модели мира позволяет вообразить новый опыт. По моему опыту, для решений на базе моделей требуется также меньше образцов.
Но обучение хорошей модели — трудное дело. У меня сложилось впечатление, что низкоразмерные модели (low-dimensional state models) иногда работают, а вот модели изображений, как правило, слишком трудны. Но если они станет проще, то могут произойти некоторые интересные вещи.
Dyna (Sutton, 1991) и Dyna-2 (Silver et al., ICML 2008) — классические работы в этой области. В качестве примеров работ, где обучение на базе модели сочетается с глубинными сетями, я бы рекомендовал несколько последних статей из лаборатории робототехники в Беркли:
- Neural Network Dynamics for Model-Based Deep RL with Model-Free Fine-Tuning (Nagabandi et al, 2017;
- Self-Supervised Visual Planning with Temporal Skip Connections (Ebert et al, CoRL 2017);
- Combining Model-Based and Model-Free Updates for Trajectory-Centric Reinforcement Learning (Chebotar et al, ICML 2017);
- Deep Spatial Autoencoders for Visuomotor Learning (Finn et al, ICRA 2016);
- Guided Policy Search (Levine et al, JMLR 2016).
Использовать обучение с подкреплением просто как этап тонкой настройки. Первая статья по AlphaGo начиналась обучением с учителем с последующей тонкой настройкой RL. Это хороший вариант, потому что он ускоряет первоначальное обучение, используя более быстрый, но менее мощный способ. Такой способ работал и в другом контексте — см. Sequence Tutor (Jaques et al, ICML 2017). Можете рассматривать его как начало процесса RL с разумным, а не случайным априорным распределением вероятностей (prior), где созданием этого «приора» занимается другая система.
Функции вознаграждения могут стать обучаемыми. Машинное обучение обещает, что на основе данных можно научиться строить вещи более качественные, чем спроектированные человеком. Если настолько сложно подобрать функцию вознаграждения, то почему бы не применить для этой задачи машинное обучение? Имитационное обучение и обратное RL — эти богатые области показали, что функции вознаграждения можно неявно определять подтверждениями или рейтингами от человека.
Самые известные научные работы по обратному RL и имитационному обучению — Algorithms for Inverse Reinforcement Learning (Ng and Russell, ICML 2000), Apprenticeship Learning via Inverse Reinforcement Learning (Abbeel and Ng, ICML 2004) и DAgger (Ross, Gordon, and Bagnell, AISTATS 2011).
Из последних работ, которые расширяют эти идеи на область глубинного обучения — Guided Cost Learning (Finn et al, ICML 2016), Time-Constrastive Networks (Sermanet et al, 2017) и Learning From Human Preferences (Christiano et al, NIPS 2017). В частности, последняя из перечисленных статей показывает, что вознаграждение, выведенное из проставленных людьми рейтингов на самом деле оказалось лучше (better-shaped) для обучения, чем оригинальное жёстко закодированное вознаграждение — и это добротный практический результат.
Из долгосрочных работ, где не используется глубинное обучение, мне понравились статьи Inverse Reward Design (Hadfield-Menell et al, NIPS 2017) и Learning Robot Objectives from Physical Human Interaction (Bajcsy et al, CoRL 2017).
Перенос обучения. Перенос обучения обещает, что вы можете использовать знания из предыдущих задач, чтобы ускорить обучение новым задачам. Совершенно уверен, что за этим будущее, когда обучение станет достаточно надёжным, чтобы решать разрозненные задачи. Трудно перенести обучение, если вы вообще не можете обучаться, а при наличии задач А и Б тяжело предсказать, произойдёт ли перенос обучения с задачи А на задачу Б. По моему опыту, здесь либо очень очевидный ответ, либо совершенно непонятный. И даже в самых очевидных случаях требуется нетривиальный подход.
Последние работы в этой области — Universal Value Function Approximators (Schaul et al, ICML 2015), Distral (Whye Teh et al, NIPS 2017) и Overcoming Catastrophic Forgetting (Kirkpatrick et al, PNAS 2017). Из более старых работ см. Horde (Sutton et al, AAMAS 2011).
Например, робототехника показывает хороший прогресс в переносе обучения из симуляторов в реальный мир (из симуляции задачи на настоящую задачу). См. Domain Randomization (Tobin et al, IROS 2017), Sim-to-Real Robot Learning with Progressive Nets (Rusu et al, CoRL 2017) и GraspGAN (Bousmalis et al, 2017). (Дисклеймер: я работал над GraspGAN).
Хорошие приоры могут сильно сократить время обучения. Это тесно связано с некоторыми из предыдущих пунктов. С одной стороны, перенос обучения заключается в использовании прошлого опыта для создания хороших априорных распределений вероятностей (priors) для других задач. Алгоритмы RL спроектированы для работы на любом марковском процессе принятия решений — и вот здесь возникает проблема с обобщением. Если мы считаем, что наши решения хорошо работают только в узком секторе окружений, то мы должны быть в состоянии использовать общую структуру для эффективного решения этих окружений.
Пьетр Эббил в своих выступлениях любит отмечать, что глубинному RL нужно задавать только такие задачи, какие мы решаем в реальном мире. Согласен, что это во многом имеет смысл. Должен существовать некий приор реального мира (real-world prior), который позволяет нам быстро обучаться новым реальным задачам за счёт более медленного обучения нереалистичным задачам, и это совершенно приемлемый компромисс.
Трудность в том, что такой приор реального мира очень сложно спроектировать. Однако думаю, есть хороший шанс, что это всё-таки возможно. Лично я в восторге от недавней работы по мета-обучению, потому что она даёт способ генерировать из данных разумные приоры. Например, если я хочу применить RL для навигации по складу, то было бы любопытно сначала использовать мета-обучение для обучения хорошей навигации в целом, а затем тонко настроить этот приор для конкретного склада, где будет двигаться робот. Это очень похоже на будущее, и вопрос в том, доберется туда мета-обучение или нет.
Сводку последних работ по обучению навыкам учиться (learning-to-learn) см. в этой публикации от BAIR (Berkeley AI Research).
Более сложные окружения парадоксально могут оказаться проще. Один из главных выводов статьи DeepMind по паркур-боту заключается в том, что если вы очень усложняете задачу, добавляя несколько вариаций задач, то в реальности упрощаете обучение, потому что правила не могут переобучиться в одной обстановке, не потеряв в производительности по всем остальным параметрам. Нечто подобное мы видели в статьях по рандомизации области (domain randomization) и даже в ImageNet: модели, обученные в ImageNet могут расширяться на другие среды намного лучше, чем те, которые обучались на CIFAR-100. Как я уже говорил, возможно, нам нужно только создать некий «ImageNet для управления», чтобы перейти к гораздо более универсальному RL.
Есть много вариантов. OpenAI Gym наиболее популярная среда, но есть ещё Arcade Learning Environment, Roboschool, DeepMind Lab, DeepMind Control Suite и ELF.
Наконец, хотя это обидно с академической точки зрения, но эмпирические проблемы глубинного RL могут не иметь значения с практической точки зрения. В качестве гипотетического примера представим, что финансовая компания использует глубинное RL. Они обучают торгового агента на прошлых данных фондового рынка США, используя три случайных сида. В реальном А/B-тестировании первый сид приносит на 2% меньше дохода, второй работает со средней прибыльностью, а третий приносит на 2% больше. В этом гипотетическом варианте воспроизводимость не имеет значения — вы просто разворачиваете модель, у которой доходность на 2% выше, и радуетесь. Аналогичным образом не имеет значения, что торговый агент может хорошо работать только в США: если он плохо расширяется на мировой рынок — просто не применяйте его там. Существует большая разница между экстраординарной системой и воспроизводимой экстраординарной системой. Возможно, стоит сосредоточиться на первой.
Где мы сейчас
Во многих отношениях меня раздражает текущее состояние глубинного RL. И всё же оно привлекает такой сильный интерес у исследователей, какого я не видел ни в какой другой области. Мои ощущения лучше всего выражаются фразой, которую Эндрю Ын упомянул в своём выступлении Nuts and Bolts of Applying Deep Learning: сильный пессимизм в краткосрочной перспективе, уравновешенный ещё более сильным долгосрочным оптимизмом. Сейчас глубинное RL немного хаотичное, но я по-прежнему верю в будущее.
Однако если меня опять кто-нибудь спросит, может ли обучение с подкреплением (RL) решить их проблему, я по-прежнему сразу отвечу, что нет — не сможет. Но я попрошу повторить этот вопрос через несколько лет. К тому времени, возможно, всё получится.
Комментарии (22)

Alex_ME
24.02.2018 01:46Я
использую RL для локомоции антропоморфного роботаизучаю RL, чтобы попытаться его использовать для локомоции антропоморфного робота IRL.
План: в отличие от паркур-бота не управлять всеми сочленениями, а получить лишь траектории ключевых точек, а дальше классическая инверсная кинематика и тому подобное. Размерность задачи проще, должно быть проще обучить. Наверное.
Почем? А почему бы и нет.
Текущее состояние: гм… изучение… Простейшие среды из gym. Как, черт возьми, они проектируют структуру самих сетей и подбирают гиперпараметры?

deksden
24.02.2018 06:01+1Интересно, а когда все наработки психологии попробуют применить — не только любопытство и набивание шишек? Страхи, подсознательная страхи (простые обученные сторонние модели с защитой от сильно неправильного поведения), лень, пресыщение, эмоции в целом — это же все важные части обучения.
Понимаю, что есть мнение о психологии как о недонауке, но вижу тут как раз поле для экспериментов. Возможно, что прививанием человеческих механизмов психики нейросетям мы сможем и механизмы психики изучить!

LorDCA
24.02.2018 07:59+2Вы, в прочем как и они, пытаетесь укрепить шаткий каркас при помощи палок и всяких липких штук. Грубо говоря, на алгоритм который оперирует множествами пикселей, вы пытаетесь прилепить философские абстракции из гораздо более высоких уровней.
Обобщение различных обученных моделей для совместного взаимодействия будет порождать хаос, и сложность будет расти в геометрической прогрессии к количеству моделей.
Попробуйте отойти от философии и изложить ваше виденье в виде конкретных алгоритмов на любом языке программирования. Не думаю что у вас выйдет что.
Нужны другие подходы к обобщению примитивных раздражителей. И изначально нужно понимать, что именно вы хотите получить в качестве результата. Причем желательно что бы это было максимально конкретизировано, а не " ну вот значит я говорю а оно такое хоба и бац".
Дальше можно развести беседу в которой рассмотреть нервную систему в виде «конечного автомата». Просто количество входящих/исходящих сигналов настолько огромно, что нам тяжело это структурировать.deksden
24.02.2018 18:04+1Про сложность системы я с вами согласен. Однако те же компьютерные науки выработали вполне работающее решение — повышение уровня абстракции.
То есть, вместо выдумывания — как заставить один уровень нейросетей работать, можно попытаться реализовать многоуровневую систему, каждый следующий уровень которой будет оперировать уже обработанными данными с предыдущего уровня.
Насчет отхода от философии — даже в компьютерных науках есть такая отчасти философская штука как архитектура приложений и систем. Да, это теоретические построения. Просто на определенном уровне понимания приходит мысль, что лучше хорошей практики может быть только хорошая теория. В статье мы ясно видим — есть ряд хороших практик. Нужна хорошая теория, и психология может подсказать — в каком направлении ее искать. Междисциплинарная синергия — довольно надежная кладезь новых идей.
SpiridonovAA
25.02.2018 00:53У людей такое тоже бывает. Максимальное подкрепление дает употребление героина. Поэтому, если агент (человек) откроет для себя героин, то сможет максимизировать награду без «лишних» телодвижений
third112
25.02.2018 04:44Спасибо за перевод. Его нужно снабдить грифом "ЧИТАТЬ ВСЕМ!" (ИМХО особая польза будет дилетантам в ИИ, а то эйфория просто зашкаливает).
(Лично мне особо приятно было увидеть фразу:
Обучение с подкреплением способно на всё! Но это не значит, что нужно браться за всё сразу.
т.к. подкрепляет мое понимание:
слишком амбициозные проекты терпят крах, а более скромные неспешно, но все же продвигают ИИ к новым рубежам.
)pdima
25.02.2018 13:24Так речь только о RL, обычное обучение с учителем вполне успешно решает реальные задачи
Alexey_mosc
25.02.2018 12:12Пара моментов по существу, которые описаны не очень.
1) НС учится на игре ATARI несколько дней, а человек, мол, сел и за 5 минут освоил. Неверное логическая основа. Человек уже к этому моменту великолепно предобучен решать такие или похожие задачи (и джойстик наверное держал не раз). А вот нейронка с нуля воссоздает все.
2) Хорошо работают 25-30% из-за якобы случайных начальных условий. Из-за них тоже, но как-то совсем опущено несколько миллионов обновлений весов, конкретно уводящих модель в ту или иную сторону.
Petrenuk
26.02.2018 03:17По поводу пункта #1, тоже удивляюсь когда начинают вот так напрямую сравнивать.
Скажем так, если новорожденного ребёнка посадить учиться играть в Atari, то он не научится ни за 5 минут, ни за несколько дней. Человеческий ребёнок сможет осознанно играть в такие игры, скажем, лет в шесть. К этому моменту он бодрствовал по меньшей мере 30000 часов, впитывая и обрабатывая всю поступающую сенсорную информацию, да и во сне, есть основания полагать, мозг тоже обучается. И это не считая миллионов лет предшествующей эволюции, которая «закодировала» многие компоненты мозга прямо в геном.
~Шести лет достаточно чтобы научиться абстрактному мышлению — выработать высокоуровневые концепции, которые легко переиспользовать для решения широкого круга задач. Так что, за последние 5 минут происходит незначительный fine tuning, не более того.Alexey_mosc
26.02.2018 11:10Ну, да! Понимание физики, восприятие объектов в пространстве вообще. Динамика тел. Это у нас с детства закладывается (плюс эволюционно — бананы ловить с пальмы, и т.д.). А тут на тебе — несколько миллионов векторов сырых пикселей — и готово!
Petrenuk
26.02.2018 15:01+1На эту тему очень хорошо высказался автор ответной заметки himanshusahni.github.io/2018/02/23/reinforcement-learning-never-worked.html
RainbowDQN takes 83 hours to learn because it does not come preloaded with notions of what a video game is, that enemies shoot bullets at you, that bullets are bad, that a bunch of pixels that seem to stay together is a bullet, that bullets exist in the world, that objects exist, that the world is organized into anything more than a maximum entropic distribution. All of these are priors that help us, humans, dramatically limit our exploration to a small set of high quality states. DQN has to learn all of these by mostly random exploration. That it learns to beat expert humans, and centuries of wisdom in the case of AlphaZero, is still very surprising.
michael_vostrikov
26.02.2018 11:351) Так там же пишут «Вы можете настроить обученную DQN для новой игры Atari, но никакой гарантии, что такой перенос состоится, и обычно никто не ожидает этого.». Сеть предобучена решать такие задачи, но с новой возникают проблемы.
Alexey_mosc
25.02.2018 14:29Поумничаю. Я сам уже около года делаю свою RL машину. Если вознаграждение разрежено и, в конкретном случае, дается агенту по окончании эпизода (пример из Pong): left-left-left-left-left-left-left-left-left-left-left-left-left-мleft-left-left-left-left-left-left-left-left-left-left-left-left-left-left-left-left-left-left-REWARD == +1, то для многих задач эта задержка создает большие проблемы в сходимости. По сути, человек дает машине огромное право выбора, что делать, но только чтобы сумма вознаграждений стремилась к своему возможному максимуму. Хоть чечетку пляши 50 итераций, но на 51 нужен +1.
Если дать машине мнгновенные вознаграждения, типа расстояние до мяча в Pong left-0,99-left-0,98-left-0,95-left-0,9-left-0,85-left-0,81-left-0,7-...left-0,01-REWARD == +1, то здесь еще одна большая проблема. От размера многвенных вознаграждений зависит та политика, которую агент усвоит. Он всегда будет стремится максимизировать сумму дисконтируемых вознаграждений, и если промежуточные значения слишком высокие — а точнее, если они пробивают какой-то заранее неизвестый порог, — то агенту проще максимизировать их, а не отложенное вознаграждение.
Для того же примера понга это может привести к тому, что (фантазирую), отбивая мяч он положит серию увеличивающся до него расстояний и будет получать меньше вознаграждения. А поэтому совсем не обязательно (не ОЧЕВИДНО), что он будет стараться мяч именно отбить.
Вот про эту сложность автор пишет много и подробно. И это очень нетривиально.Petrenuk
26.02.2018 03:37Действительно, нетривиально. В rl часто приходится заниматься вот таким инжинирингом reward-функции, что вообще говоря противоречит изначальной идее. Вместо этого хочется иметь алгоритм, который бы умел работать со sparse наградами, т.е. решать задачу которую мы действительно хотим решить. Тут пока всё грустно, хотя есть некоторые идеи.
- Составлять curriculum, т.е. сначала учить агента на самых простых версиях задачи, где награда достигается за несколько шагов, а потом постепенно отодвигать момент старта.
- Использовать какой-нибудь умный exploration, например curiosity module. Тогда агент должен методично исследовать мир, пока методом исключения не наткнется на награды.
- Можно делать какую-то иерархическую архитектуру системы, когда агент разделен на низкоуровневые модули, которые работают часто (на каждом шаге) и высокоуровневые модули, которые запускаются реже. Таким образом, вся система обучается быстрее, потому что высокоуровневым модулям нужно меньше шагов чтобы получить награду от среды, а низкоуровневые получают дополнительную плотную награду от высокоуровневых модулей. Надеюсь понятно написал :) На эту тему есть несколько статей.
Alexey_mosc
26.02.2018 15:261) Это я частично применяю, но не пробовал предобучить сеть на этом шаге, чтобы в дальнейшем использовать на более дальних примерах. Все это опять же нужно делать с промежуточными ручными проверками «а кто это у нас тут так плохо сошелся».
2) Частично это делается случайным заполнением буффера и использованием e-greedy (Boltzmann's exploration, etc.).
3) Вот это круто звучит, можно попробовать. hierarchical RL.
На простых моделях мира работает норм, на сложных — плохо.
Моя игрушка: обучение трейдингу на функции синуса )
данные:

трейды на обучении (нижние ряды — хорошо обученный агент):

А если сделать длину трейда 50-100 шагов, то сходимость будет гораздо хуже.
Petrenuk
26.02.2018 03:24Сам в последнее время разбираюсь с reinforcement learning, столкнулся со всеми этими проблемами. Оказывается, даже на простых задачах современные методы сложно чему-то обучить.
Однако надо признать, все эти dqn и a3c это очень простые алгоритмы. Например, их общая черта состоит в том, что нейронную сеть просят принять решение «моментально», за один проход. В то время как человек в трудных ситуациях произодит размышления, рефлексирует. Что-то подсказывает, что возможности софта в этой области ещё далеко не исчерпаны.
На странице репозитория есть интересные анимации: github.com/alex-petrenko/rl-experimentsAlexey_mosc
26.02.2018 12:02+1Я больше всего фрустрирую из-за огромного пространства гипер-параметров. Перечислю только некоторые, которые есть в моем скрипте RL (для Double Q Learning, e-greedy, with prioritization of learning samples):
размер буффера,
количество нейронов в (1 пока) скрытом слое,
надо ли добавить второй,
надо ли вставить drop-out,
скорость обучения,
надо ли ее делать переменнной,
gamma,
epsilon (greedy),
feature engineering (что? где? когда?),
коэффициент alpha для выравнивания приоритизации,
если это не приоритезация, надо ли выбирать образцы из буффера равномерно или ближе к последнему образцу политики?
И это еще не все. (
А самое главное, сходимость можно оценить далеко не через 5 минут. Обычно, занимает несколько часов.Petrenuk
26.02.2018 15:08Да, всё как в обычном deep learning, только ещё хуже. Кстати, для своей задачки я перебирал гиперпараметры довольно долго, и нашёл что они почти не улучшают финальный результат. Ну, т.е. легко можно ухудшить, но не улучшить) Мои изначальные параметры, видимо, были ок.
Единственный параметр который долго тюнил — как часто и как «сильно» обновлять target network в double dqn. Если редко, то обучение получается стабильным, но очень уж медленно. Если слишком часто обновлять, то может в космос улететь)
Вот этой штукой перебирал, генетическим алгоритмом github.com/alex-petrenko/udacity-deep-learning/blob/master/hyperopt.py
vladob
Спасибо за перевод.
Как в свое время в статистических моделях была выявлена проблема «переобучения» (overfitting), так здесь вырисовывается аналогичная проблема пере-подкрепление.
Впрочем, толковым педагогам, дрессировщикам, да и просто родителям эти проблемы известны.
Выход, я думаю, будет найден в разработке очередного слоя функций «кнута-и-пряника», а те, в свою очередь, будут опираться на зависимость толерантности к стимулирующим факторам (снижение восторга от «печенек» и привыкание к «кнуту») от потенциально ВСЕГО. И пока по всем локальным экстремумам пропутешествуешь…
Ну или начнут учить студентов, как обучать робота, который будет учиться обучать роботов как обучать
роботовлюдей. Денег-то вона сколько! Миллиарды!и еще… Честно сказать, про наличие собственных хорошо (или плохо) воспитанных и обученных детей у авторов глубинного и прочих обучений мне иногда интереснее, чем знать то же самое у политиков.