

История
Рекуррентные слои были изобретены еще в 80х Джоном Хопфилдом. Они легли в основу разработанных им искусственных ассоциативных нейронных сетей (сетей Хопфилда). Сегодня рекуррентные сети получили большое распространение в задачах обработки последовательностей: естественных языков, речи, музыки, видеоряда и тд.
Задача
В рамках задачи по Hierarchy reinforcement learning я решил прогнозировать не одно действие агента, а несколько, используя для этого уже пред обученную сеть способную предсказать последовательность действий. В данной статье я покажу как реализовать “sequence to sequence” алгоритм для обучения этой самой сети а в последующей, постараюсь рассказать, как использовать ее в Q-learning обучении.
Окружение
Представим себе небольшой 2D игровой мир, 5x5 клеток. Каждую клетку будет занимать либо некий объект, либо пустое место.

Перед нашей сетью мы ставим задачу: выдать последовательность действий из заданного множества действий [“left”, “right”, “up”, “down”, “take”, “attack”].
На вход надо подать состояние нашего мира, состоящее из 25 отдельных клеток, каждая из которых может принимать одно значение из множества: [“space”, “enemy”, “life”, “source point”, “destination point”].

Можно отобразить такой мир в виде вектора размерностью 6*25, а после сжать embedded алгоритмом. Такая модель будет очень чувствительна к изменению количества клеток и объектов этого мира.
Чтобы избавиться от такой ограниченности, мы можем формировать входной слой как последовательность, где каждый элемент этой последовательности и есть один объект нашего мира. Таким образом, мы будем подавать на вход последовательности различной длины (для различных размеров моделируемого мира) и в процессе до-обучения мы сможем расширять количество объектов нашего мира.
Sequence to sequence
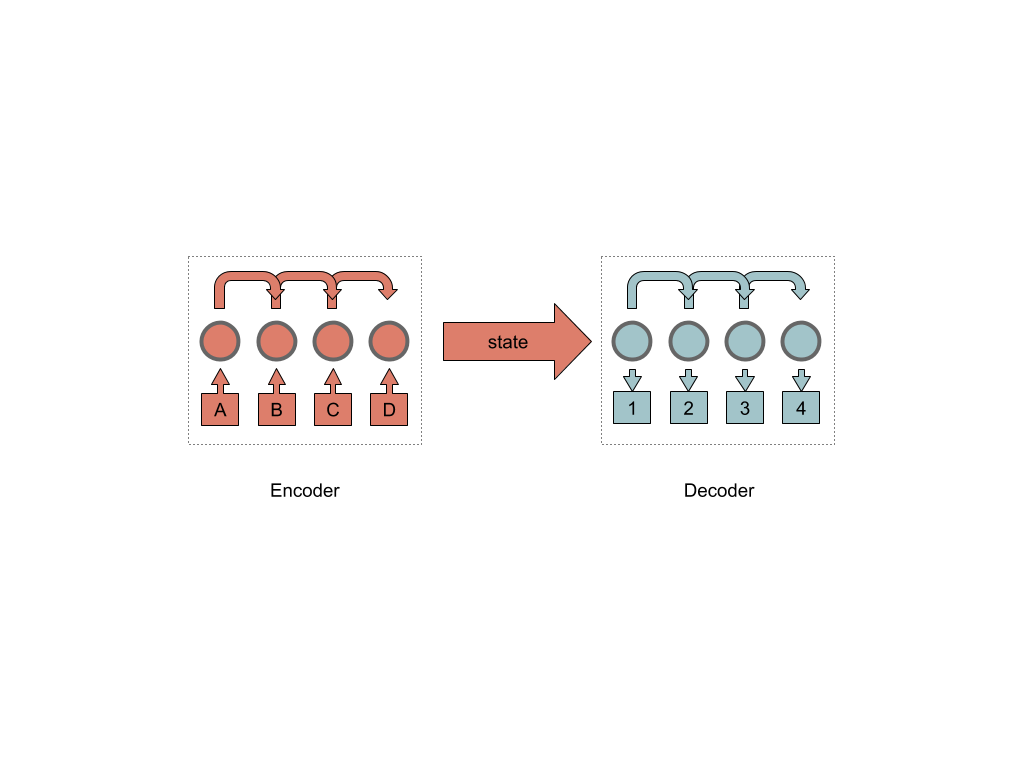
Sequence to sequence нейронные сети представляют из себя два блока encoder и decoder, и некий соединяющий их скрытый слой внутреннего состояния.
В свою очередь encoder состоит из цепочки рекуррентных ячеек (в реализации это может быть как одна, так и несколько).
Самой распространенной на сегодня рекуррентной ячейкой (на мой субъективный взгляд) можно назвать LSTM (Long short term memory) ячейку.
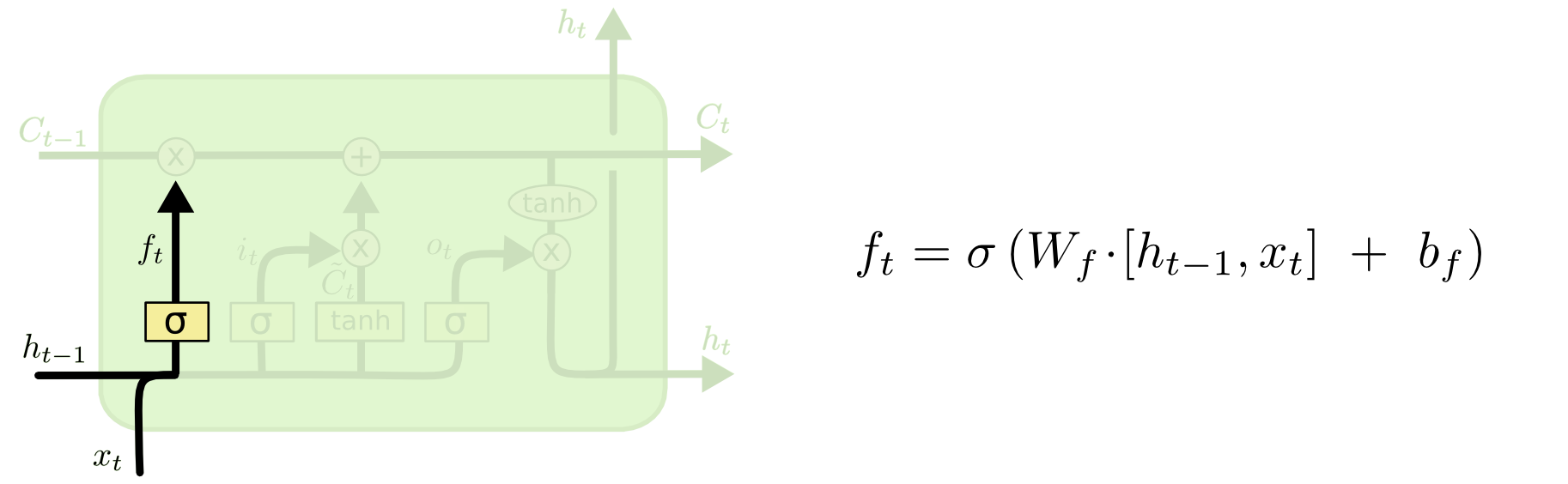
Не углубляясь в реализацию LSTM, (детальнее советую почитать тут), кратко опишу принцип ее работы.
На вход LSTM ячейки приходит 3 входа C, H, X. Вход “конвейера” C с возможными линейными модификациями сигнала внутри ячейки. Первая модификация это “ворота”.
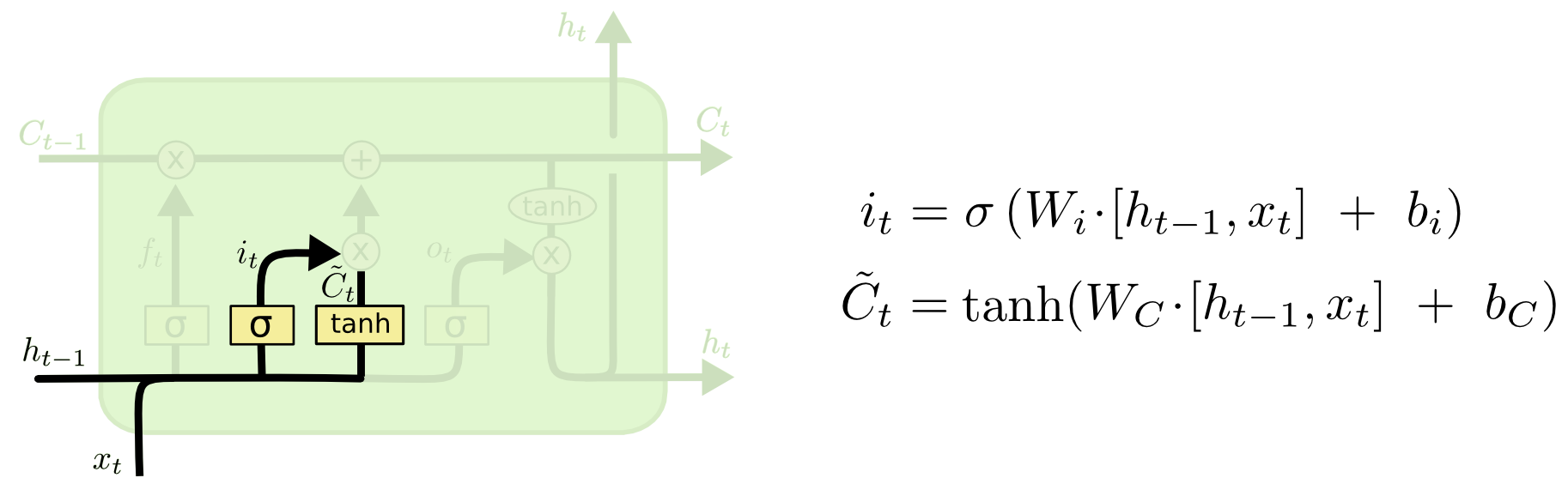
Обрабатывая сигнал с входов H и X “ворота” решают пропускать ли сигнал пришедший сейчас по конвейеру C. Происходит это путем умножения сигнала C на значение сигмоид функции с параметрами H, X, W, b.
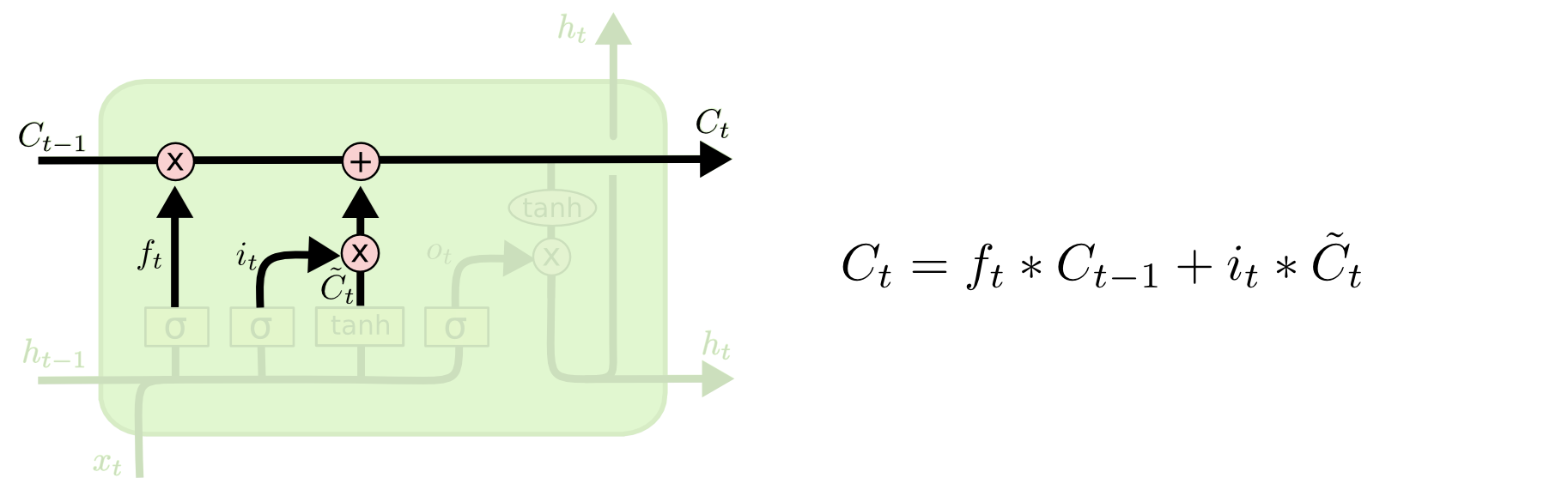
Следующий шаг — решить, какую новую информацию мы собираемся хранить в состоянии ячейки. Это решение принимается в два этапа.
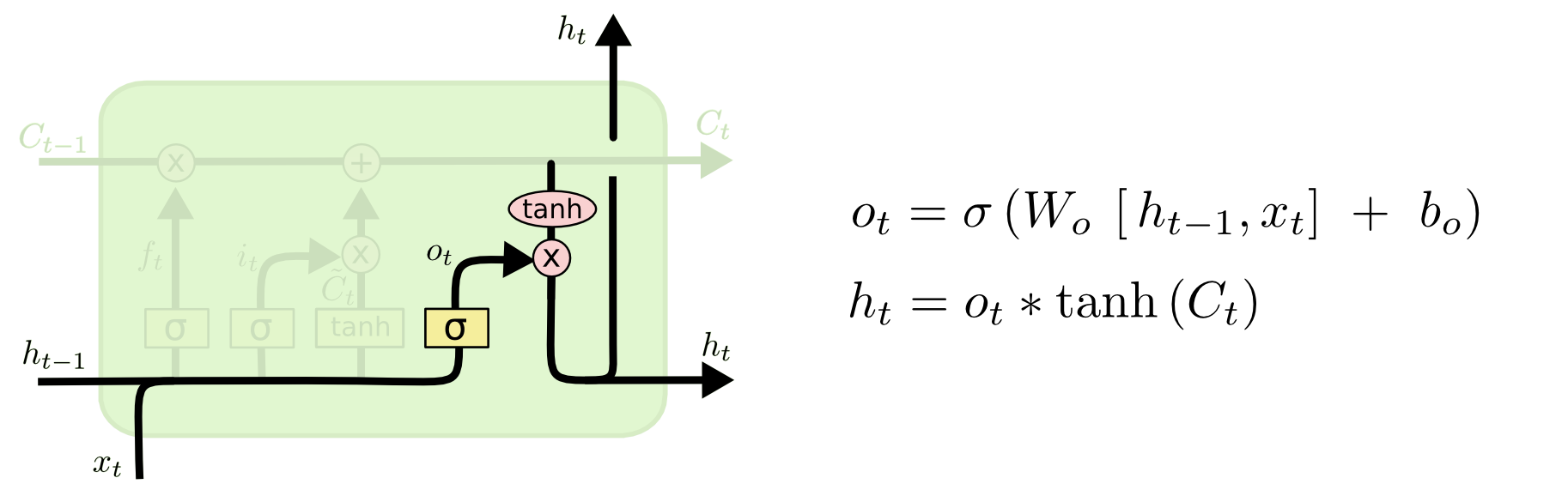
Для начала, второй сигмоидный слой, называемый “input gate layer”, решает, какие значения мы будем обновлять. Затем слой tanh создает вектор новых значений кандидата выходного слоя C, которые могут быть добавлены в состояние. На следующем шаге ячейка объединяет сигнал идущий по “конвейеру” C, с полученным, чтобы создать обновленное состояние. Наконец, нам нужно решить, что будет на H выходе нашей ячейки. Этот вывод будет основан на состоянии нашей ячейки, но при этой пройдет некий фильтр. Сначала ячейка пропустит сигнал через сигмоидный слой, который решает, какие части состояния ячейки мы собираемся выводить. Затем умножим его на значение “конвейера” C, проходящего через функцию tanh.
Так же про LSTM вы можете почитать и на Хабре.
Таким образом, собирая несколько LSTM ячеек в “цепь”, мы можем прогнозировать некое состояние, опираясь на предыдущие предсказания в цепочке.
Существует множество техник, которые помогают улучшить сходимость таких сетей, например, методика двунаправленных ячеек. Располагая ячейки в два ряда таким образом, чтобы один ряд следил за состоянием предыдущей ячейки, а другой за состоянием ячейки идущей после него, можно учитывать не только то слово, которое было до прогнозируемого, но и идущее следом. Также используют “акценты” или внимание (attention) для определения ключевых слов в предложении.
Реализация
Нейронную сеть я буду “собирать” средствами TensorFlow и языка python. Так же для этой статьи я написал небольшой класс для симуляции мира.
Первое, что необходимо сделать, — определить входные слои:
self.input_data_input = tf.placeholder(tf.int32, [None, None], name='input')
self.targets = tf.placeholder(tf.int32, [None, None], name='targets')
self.learning_rate_input = tf.placeholder(tf.float32, name='learning_rate')
self.target_sequences_length_input = tf.placeholder(tf.int32, (None,), name='target_sequences_length')
self.max_target_sequences_length = tf.reduce_max(self.target_sequences_length_input, name='max_target_len')
self.source_sequences_length_input = tf.placeholder(tf.int32, (None,), name='source_sequences_length')
Далее создаем encoder слой.
Тут стоит сказать, что для уменьшения размерности используется механизм эмбединга, механика его реализации уже присутствует в TensorFlow.
# 1. Encoder embedding
encoder_embed_input = tf.contrib.layers.embed_sequence(input_data_input, vocabulary_size, TF_FLAGS.FLAGS.encoding_embedding_size)
# 2. Construct the encoder layer
encoder_cell = tf.contrib.rnn.MultiRNNCell([self.make_cell() for _ in range(TF_FLAGS.FLAGS.num_layers)])
enc_output, enc_state = tf.nn.dynamic_rnn(encoder_cell, encoder_embed_input, sequence_length=source_sequences_length_input, dtype=tf.float32)
Создаем rnn cell и добавляем их в нашу сеть.
dec_cell = tf.contrib.rnn.LSTMCell(TF_FLAGS.FLAGS.rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
Детальнее можно посмотреть видео с TFSummit 2017.
Выход нашей подсети будет состоять из выхода (конвейерного) последней RNN ячейки и ее скрытого состояния. Нам понадобится только состояние.
Переходим к декодеру.
Так же как и в декодере, необходимо подготовить слой эмбединга.
# 1. Decoder Embedding
target_vocab_size = self.vocabulary_size
decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, TF_FLAGS.FLAGS.decoding_embedding_size]))
decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input)
Далее создаем первый слой с рекуррентными ячейками и проецируем их выходы на полносвязный перцептрон для дальнейшей классификации результатов.
# 2. Construct the decoder layer
dec_cell = tf.contrib.rnn.MultiRNNCell([self.make_cell() for _ in range(TF_FLAGS.FLAGS.num_layers)])
# 3. Dense layer to translate the decoder's output at each time
# step into a choice from the target vocabulary
output_layer = Dense(target_vocab_size, kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
Выходы ячеек подаем на полносвязный слой классификатора.
В декодере у нас будет две ветки граффа:
Первая ветка для обучения, другая для обработки конечных заданий.
Для обучения нам понадобится удалить последний символ из целевых (тех, что мы хотим получить на выходе декодера) последовательностей и добавить «GO» в начало каждой целевой последовательности. Это необходимо, так как мы будем обучать каждую ячейку в отдельности и на каждую из них надо подать правильный входной сигнал, а не сигнал с соседней обучающейся ячейки.
Для реализации слоя декодера TensorFlow необходим помощник. По сути это некий итератор, который предпроцессит входные данные.
Создаем помощник и динамический декодер для обучения.
# Helper for the training process. Used by BasicDecoder to read inputs.
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=decoder_embed_input, sequence_length=target_sequences_length, time_major=False)
# Basic decoder
training_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, training_helper, encoder_state, output_layer)
# Perform dynamic decoding using the decoder
training_decoder_output = tf.contrib.seq2seq.dynamic_decode(training_decoder, impute_finished=True, maximum_iterations=max_target_sequences_length)[0]
Создаем помощник и динамический декодер для обработки конечных задач.
start_tokens = tf.tile(tf.constant([ua.UrbanArea.vacab_go_key], dtype=tf.int32), [TF_FLAGS.FLAGS.batch_size], name='start_tokens')
# Helper for the inference process.
inference_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(decoder_embeddings, start_tokens, ua.UrbanArea.vacab_eos_key)
# Basic decoder
inference_decoder = tf.contrib.seq2seq.BasicDecoder(dec_cell, inference_helper, encoder_state, output_layer)
inference_decoder_output = tf.contrib.seq2seq.dynamic_decode(inference_decoder, impute_finished=True, maximum_iterations=max_target_sequences_length)[0]
Далее добавляем нашу функцию потерь.
Для последовательностей в TensorFlow есть функция перекрестной энтропии, которой на вход мы будем подавать выход rnn сети и примеры обучения.
training_logits = tf.identity(training_decoder_output.rnn_output, 'logits')
_ = tf.identity(inference_decoder_output.sample_id, name='predictions')
# Create the weights for sequence_loss
masks = tf.sequence_mask(self.target_sequences_length_input, self.max_target_sequences_length, dtype=tf.float32, name='masks')
with tf.name_scope("optimization"):
# Loss function
self.cost = tf.contrib.seq2seq.sequence_loss(training_logits, self.targets, masks)
tf.summary.scalar("loss", self.cost)
Градиентный спуск и Adam оптимизатор будет обновлять значения весов.
# Optimizer
optimizer = tf.train.AdamOptimizer(self.learning_rate_input)
# Gradient Clipping
gradients = optimizer.compute_gradients(self.cost)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
self.train_op = optimizer.apply_gradients(capped_gradients)
Все, достаточно получить несколько сотен обучающих данных из нашего симулятора и запустить сессию обучения.
Epoch 1/100 Batch 20/65 Loss: 1.170 Validation loss: 1.082 Time: 0.0039s
Epoch 1/100 Batch 40/65 Loss: 0.868 Validation loss: 0.950 Time: 0.0029s
Epoch 1/100 Batch 60/65 Loss: 0.939 Validation loss: 0.794 Time: 0.0031s
...
Epoch 99/100 Batch 60/65 Loss: 0.136 Validation loss: 0.403 Time: 0.0030s
Epoch 100/100 Batch 20/65 Loss: 0.149 Validation loss: 0.430 Time: 0.0037s
Epoch 100/100 Batch 40/65 Loss: 0.110 Validation loss: 0.423 Time: 0.0031s
Epoch 100/100 Batch 60/65 Loss: 0.153 Validation loss: 0.397 Time: 0.0031s
В результате можно получить последовательность шагов для прохода через наш виртуальный лабиринт.
Желтым выделена последовательность посчитанная алгоритмом, зеленым — последовательность предложенная искусственной нейронной сетью.

Также я добавил немного визуализации в обучение.
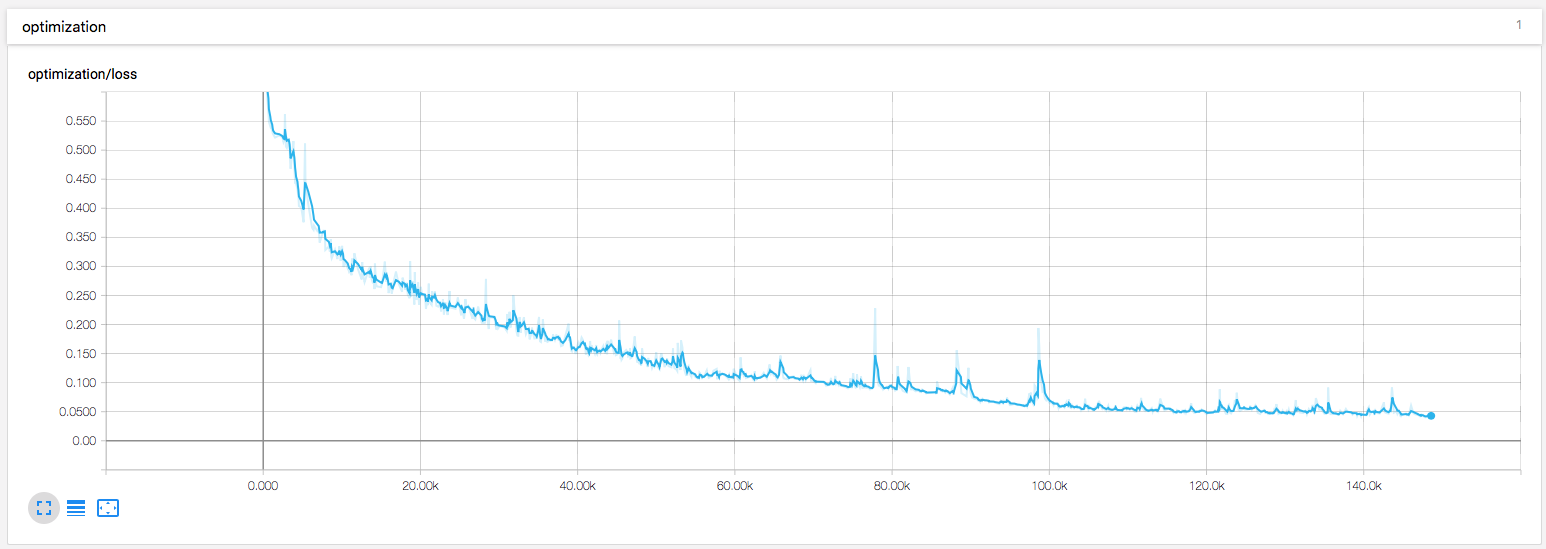
Готовое решение можно посмотреть в моем github репозитории.
fireSparrow
Из какой игры первая картинка?
Sirion
Есть подозрение, что не из какой. Гугление привело меня сюда. Если я правильно интерпретирую написанное на этой странице, то гифка — просто фантазия художника.
QuAzI
Очень жаль. А я уж обрадовался, что нормальных игр завезли
fireSparrow
Вот и я обрадовался… Видимо, придётся и дальше ждать Stoneshard.