
Под катом рассказ Филиппа Дельгядо (dph) на Highload++ про опыт, накопившийся за несколько лет работы над платежной системой для российского легального букмекерского бизнеса, про ошибки, но и про некоторые достижения, и про то, как грамотно смешать, но не взбалтывать, web с enterprise.

О спикере: Филипп Дельгядо за свою карьеру чем только не занимался — от двузвенок на
Visual Basic до хардкорного SQL. В последние годы в основном занимается нагруженными проектами на Java и регулярно делится своим опытом на разных конференциях.
Три года мы делаем нашу платежную систему, из них два года мы в продакшене. Два года назад я рассказывал, как сделать платежную систему за один год, но с тех пор, разумеется, в нашем решении много что изменилось.
Мы — это довольно маленькая команда: 10 программистов, в основном это бэкенд-раработчики и только два человека на фронтэнде, четверо QA и я, и плюс какой-то менеджмент. Поскольку команда маленькая, денег не очень много, особенно в начале.
Платежная система
Вообще, платежная система — это очень просто: взять денежки, перевести записи из одной таблички в ту же самую табличку со знаком «минус» — в общем-то и всё!
Реально так оно и есть, платежная система — очень простая штука. Пока не пришли юристы. Платежные системы во всем мире облагаются огромным количеством всевозможных отягощений и указаний, как именно правильно переводить деньги из одной таблички в другую, как именно взаимодействовать с пользователями, что им можно обещать, чего нельзя обещать, за что отвечаем, за что не отвечаем. Поэтому в рамках разработки платежной системы приходится все время балансировать на грани между тяжелым enterprise и вполне нормальным масштабируемым web-приложением.
От enterprise у нас следующее.
?Мы работаем с деньгами.
Поэтому, у нас сложный бухгалтерский учет, необходим высокий уровень надежности, высокий SLA (потому что простой системы не любим ни мы, ни пользователи), и высокая ответственность — мы должны точно знать, куда и какие деньги пользователя ушли и что с ними в данный момент вообще происходит.
?Мы являемся НКО (небанковской кредитной организацией).
Это практически банк, только кредиты не можем выдавать.
- У нас отчетность перед Центробанком;
- У нас отчетность перед Финмониторингом;
- У нас много коллег в банковской части компании и с банковским опытом;
- Мы вынужденно взаимодействуем с автоматизированной банковской системой.
?У нас есть юристы. Вот часть законов, которые регулируют поведение платежных систем в данный момент в Российской Федерации:

Каждый из этих законов довольно сложно реализовывать, потому что еще есть куча подзаконных актов, реальных историй использования, и со всем этим приходится работать.
При этом, кроме того, что мы такой чистый enterprise, почти банк, мы при этом еще вполне себе web-компания.
- Для нас принципиально удобство пользователя, потому что рынок высококонкурентный, и если мы не будем заботиться о нашем пользователе, он от нас уйдет и денег у нас не будет совсем.
- Мы вынуждены делать частые выкладки, потому что бизнес активно развивается. Сейчас у нас релизы 23 раза в неделю, что гораздо чаще, чем у крупных банков, где, говорят, недавно наконец начали делать релизы один раз в 3 месяца и очень этим гордятся.
- Минимальный time-to-market: как только пришла какая-то идея, нужно как можно быстрее ее запустить в реальную жизнь — желательно быстрее, чем конкуренты.
- У нас не очень много денег в отличие от многих крупных банков. Взять и залить все деньгами нам не удается, приходится как-то выкручиваться, принимать какие-то решения.

Мы используем Java, потому что найти на рынке разработчиков, хотя бы примерно понимающих про надежность работы с базами данных в мире Java несколько проще, чем на других языках.
Я знаю только три базы данных, с которыми можно делать платежную систему, но одна из них очень дорогая, для второй трудно найти поддержку и она тоже не бесплатная. В итоге PostgreSQL для нас — самый оптимальный вариант: легко найти вменяемую поддержку, и в общем-то за небольшие деньги можно вообще не думать о том, что происходит с базами данных: у вас все чистенько, красивенько и гарантированно.
В проекте используется немножко Kotlin — скорее для развлечения и для того, чтобы смотреть в будущее. Пока Kotlin в основном используется как некоторый скриптовый язык, плюс некоторые небольшие сервисы.
Разумеется, сервисная архитектура. Микросервисами это назвать категорически нельзя. Микросервис в моем понимании — это то, что проще переписать, чем разбираться и рефакторить. Поэтому у нас, разумеется, не микросервис, а нормальные полноценные большие компоненты.
Кроме того, Redis для кэширования, Angular для внутренней кухни. Основной сайт, видимый пользователю у нас сделан на чистом HTML+CSS с минимумом JS.
И понятное дело, Kafka.
Сервисы
Конечно, я предпочел бы жить без сервисов. Был бы один большой монолит, никаких проблем со связностью, никаких проблем с версионированием: взял, написал, выложил. Все просто.
Но приходят требования по безопасности. У нас есть персональные данные в системе, персональные данные должны храниться и обрабатываться отдельно, с особыми ограничениями. У нас есть информация по банковским картам, она тоже должна жить в отдельной части системы с соответствующими требованиями к аудиту каждого изменения кода и требованиями к доступу к данным. Поэтому приходится все резать на компоненты.
Есть требования надежности. Не хочется из-за того, что какой-то шлюз с одним из банков-контрагентов почему-то поломался, брать и выкладывать всю платежную логику: не дай бог, там будет неправильная выкладка, человеческий фактор — и все рухнет. Поэтому все равно приходится все делить на относительно небольшие сервисы.
Но раз уж мы начинаем делить систему на компоненты по требованиям безопасности и надежности, имеет смысл в отдельные сервисы выделять и все то, что требует собственного хранилища. Т.е. для части базы, которая вообще не зависит от всей прочей системы, проще сделать отдельный сервис.
И главный для нас принцип выделения чего-то в отдельный сервис — если можно придумать очевидное имя для этого самого сервиса.
«Процессинг» или «Отчеты» — это более-менее нормальное имя, «Фигня, которая работает с репликой базы данных» — это уже плохое имя. Явно это не один сервис — либо несколько, либо часть одного большого.
Четырех этих требований нам совершенно достаточно для выделения отдельных
сервисов.

Разумеется, у нас все еще остаются микромонолиты, которые мы продолжаем резать, потому что у них накапливается слишком много слов и слишком много имен для одного сервиса. Это постоянный процесс перераспределения ответственности.
Сами сервисы взаимодействуют через JSON RPC по http(s), как в любом web-мире. При этом для каждого сервиса прописывается отдельная логика повторов запросов и кэширования результатов. В результате даже при падении какого-либо сервиса вся система продолжает нормально работать, а пользователь ничего не замечает.
Компоненты
Kafka
Это не очередь сообщения, Kafka у нас — это только транспортный уровень между сервисами, с гарантией доставки и понятной надежностью/кластеризацией. Т.е. если из сервиса А в сервис В надо что-то переслать, проще положить сообщение в Kafkу, из Kafkи сервис сам заберет, что надо. И тогда можно и не думать обо всей этой логике для повторов и кэширования, Kafka сильно упрощает такое взаимодействие. Сейчас мы пытаемся как можно больше всего переводить на Kafka, это тоже такой непрерывный процесс.

Ну и кроме всего прочего, это резервный источник данных о всех наших операциях. Я, конечно, параноик, поскольку специфика работы способствует. Я видел (довольно давно и не в этом проекте), как коммерческая база данных за кучу-кучу денег в некий момент начала писать ерунду не только в собственные файлы базы данных, но и во все реплики и в бэкап. И данные пришлось восстанавливать из логов, потому что это были данные о проведенных платежах, и без них компания на следующий день могла спокойно закрываться.
Я не очень люблю вытаскивать важные данные из логов, поэтому я лучше буду складывать всю необходимую информацию в ту же Kafkу. Если вдруг у меня произойдет какая-нибудь невозможная ситуация, я, по крайней мере, знаю, откуда забирать резервные данные, никак не связанные с основным хранилищем.
Вообще, для платежных систем иметь два независимых хранилища данных — это стандартная практика, без нее жить просто страшно — мне, например.
Логи разработки
Разумеется, логов у нас много и разных. Логи разработки мы сейчас сохраняем в Kafkу и дальше загружаем в Clickhouse, потому что, как выяснилось, так проще и дешевле. Тем более, заодно изучаем Clickhouse, что полезно на будущее. Впрочем, про работу с логами можно делать отдельный доклад.

Мониторинг
Мониторинг у нас на Prometheus + Grafana. Честно говоря, Prometheu’ом я недоволен.

В чем проблема?
- Prometheus прекрасен, когда вам надо собирать из готовых стандартных компонентов какие-то данные, и у вас этих компонентов очень много. У нас довольно мало машин. У нас 40 разных сервисов и это примерно 150 виртуалок, это не очень много. Если же мы хотим собирать через Prometheus, какую-то бизнес-мониторинговую информацию, например количество платежей, идущих через определенный шлюз, или количество событий в нашей внутренней очереди, то приходится писать довольно много кода на стороне клиента. Причем код, к сожалению, не очень простой, разработчикам приходится активно разбираться во внутренней логике и том, как именно Prometheus что-то считает.
- Prometheus нельзя использовать как честный event oriented time-series db. Я не могу взять и сказать, что есть событие начала платежа, событие конца платежа, а все прочие метрики он пускай сам посчитает. Я вынужден на клиенте все нужные мне метрики заранее считать, и если вдруг мне надо какую-нибудь из них поменять, — это очередная выкладка продакшн-компонента, что очень неудобно.
- Очень сложно делать интегрированные метрики. Если мне надо собрать общую метрику для некоторого количества сервисов (например, перцентили времени отклика клиентам по всем серверам фронтенда), то через Prometheus сделать это нереально даже теоретически. Я могу только делать какое-то непонятное среднее суммирование уже на уровне Grafana. Сам Prometheus это сделать не может.
Поэтому я всерьез думаю куда-нибудь уйти.
Дальше я буду рассказывать несколько отдельных кейсов о том, какие у нас были архитектурные вызовы, как мы их решали, что было хорошо и что при этом было плохо.
Использование базы данных
Вообще, платеж — это довольно сложно. Ниже примерное описание контекста платежа: множество кортежей (ассоциативных массивов), списков кортежей, кортежей списков, каких-то параметров. И все это постоянно меняется из-за изменений бизнес-логики.

Если это делать честно, будет много таблиц, много связей между ними. Как следствие, нужен ORM, нужна сложная логика миграции при добавлении колонки. Напомню, что, в PostgreSQL даже простое добавление новой nullable колонки в таблицу может привести (в некоторых специфических ситуациях) к тому, что на долгое время данная таблица будет вообще недоступна. Т.е. на самом деле добавление nullable column не атомарная бесплатная операция, как многие думают. Мы на это даже разочек наткнулись.
Все это довольно неприятно и грустно, хочется всего этого избежать, в особенности при использовании ORM. Поэтому мы убираем все эти большие и сложные сущности в JSON, просто потому что реально, кроме как на сервере приложения, нигде все эти данные и структуры целиком не нужны. Я использую такой подход уже лет 10 и, наконец, замечаю, что это становится если не мейнстримом, то, по крайней мере, общепризнанной практикой.
Практики работы с JSON
Как правило, храня сложные бизнес-данные в базе данных в виде JSON, по производительности вы ничего не проиграете, а может быть, даже временами и выиграете. Дальше я расскажу, как это сделать, чтобы нечаянно не прострелить себе ногу.

Во-первых, надо сразу думать о возможных конфликтах.
Когда-то у вас была версия объекта с одним набором полей данных, вы выпустили другую версию, где уже другой набор полей данных, вам надо каким-то образом читать старый JSON и преобразовывать его в удобный для вас объект.
Для решения этой задачи обычно достаточно найти хороший сериализатор / десериализатор, которому вы можете в явном виде сказать, что вот это поле из JSON надо преобразовать в такой-то набор полей, эти вещи сериализовывать так-то, а если чего-то нет, то заменить на значение по умолчанию и т.д. В Java, к счастью, с такими сериализаторами проблем нет. Мой любимый — Jackson.
Обязательно в базе данных надо хранить версию структуры, которую вы пишете.
Т.е. рядом с каждым полем, где у вас хранится JSON, должно быть еще одно поле, где хранится версия. В первую очередь, это нужно, чтобы не бесконечно поддерживать код понимания старой версии новой.
Когда вы выпустили новую версию, и у вас появилась новая структура данных, вы просто делаете скрипт миграции, который пробегает по всей базе, находит все старые версии структуры, читает их, записывает в новом формате, и у вас через какое-то довольно ограниченное время, в базе остается максимум 2-3 различные версии данных, и вы не мучаетесь с поддержкой всего разнообразия того, что у вас накопилось за многие годы. Это избавление себя от легаси, избавление себя от технического долга.
Для PostgreSQL — надо выбрать между json и jsonb.
Когда-то в этом выборе еще был смысл. У нас, например, использовался JSON, потому что мы начинали довольно давно. Напоминаю, что тип данных JSON — это просто текстовое поле, и чтобы залезть куда-нибудь внутрь, его каждый раз будет парсить PostgreSQL. Поэтому в продакшене лучше лишний раз внутрь json-объектов в базе данных не залезать, только в случае какой-то поддержки или исправления неисправностей. По-хорошему, в вашем SQL-коде вообще не должно быть команд работы с json-полями.
Если же использовать JSONB, то PostgreSQL все аккуратненько разбирает в бинарный формат, но не сохраняет оригинальный вид JSON-объекта. Когда мы, например, храним оригинальные входящие к нам данные, мы всегда используем только JSON.
Нам пока JSONB не нужен, но в данный момент, действительно имеет смысл всегда использовать JSONB и об этом уже не думать. Разница в производительности стала практически нулевой, даже на простое чтение и запись.
PCI DSS. Из простого сделать сложное, и как web становится enterprisе
Еще на этапе разработки, задолго до выхода в продакшен, был у нас маленький простой сервис с данными банковских карт, включая и собственно номер карты, который мы, разумеется, шифровали средствами PostgreSQL. При этом теоретически руководитель эксплуатации мог, наверно, найти где-нибудь ключик этого шифрования и что-нибудь узнать, но мы ему вполне доверяли.
Надежность сервиса реализовывали через active-standby — потому что сервис маленький, перезапускается быстро, 3-5 секунд прочие компоненты его точно подождут, поэтому нет смысла громоздить какую-то сложную кластерную систему.
Перед запуском мы начали проходить аудит PCI DSS, и выяснилось, что есть довольно жесткие требования контроля доступа к данным, которые, в случае нашего аудитора, сводились к тому, что:
- Не должно быть одного человека, который может прочесть всю информацию из базы данных. Это должны быть минимум несколько человек, которые совместно должны получать доступ.
- Требуется регулярная смена ключей доступа.
- PCI DSS требует при любой обнаруженной уязвимости обновлять инфраструктуру, а поскольку уязвимости в операционной системе и инфраструктурном ПО находятся довольно часто, значит, систему надо тоже обновлять довольно часто.
Для начала мы перестаем доверять руководителю эксплуатации и пытаемся придумать схему, когда у нас нет одного человека, который знает ключи.

Логичным образом приходим к схеме Шамира. Это способ генерации ключа, когда на основании готового ключа генерируется несколько ключей, любое подмножество из которых может породить исходный ключ.
Например, вы формируете длинный ключ, сразу разбиваете его на 5 кусочков так, чтобы любые три из них могли породить исходный. После чего раздаете эти три эксплуатации, два храните в сейфе на всякий случай, если кто-то заболеет, попадет под автобус и т.д., и спокойно живете. Оригинальный длинный ключ вам уже не нужен, только эти кусочки.
Понятно, что после перехода на схему Шамира в сервисе появляется логика генерации и смены ключей. Для генерации ключа использутся отдельная виртуалочка, на которой:
- генерируется ключ,
- раздается админам,
- виртуалочка убивается.
В результате исходный ключ никто не может узнать, потому что он создается в присутствии СБ-шников, на быстроумирающей системе, а дальше раздаются уже только «порожденные» ключи
При смене ключей оказывается, что у нас одновременно может быть два актуальных ключа в системе: один старый, один новый, часть данных зашифрована старым, и нужна процедура перешифровки на новый ключ.
Поскольку для того, чтобы запустить компоненту, теперь требуется два или три человека, это занимает уже не 30 секунд, а несколько минут. Поэтому простой компонента при перезапуске будет занимать уже несколько минут, и приходится переходить на схему Active-Active, с несколькими одновременно работающими экземплярами.
Таким образом, простой очевидный сервис в несколько десятков строчек становится довольно сложной конструкцией: со сложной логикой старта, с кластеризацией, с довольно сложными инструкциями по сопровождению. Из нормального простого веба мы радостно перешли в entreprise. И, к сожалению, такое происходит довольно часто — гораздо чаще, чем хотелось бы. Тем более, что топ-менеджмент и бизнес, посмотрев на все это дело, сказал, что теперь надо все данные на всякий случай шифровать примерно таким же образом, и Active-Active ему тоже всюду нравится. И эти желания бизнеса, прямо скажем, реализовать не всегда просто.
Логика платежа. Из сложного сделать простое
Как я уже говорил, платеж — это довольно сложно. Ниже нарисована примерная схема процесса перевода денег от пользователя к конечному контрагенту, но на схеме далеко не все. В процессе платежа много зависимостей от каких-то внешних сущностей: есть банки, есть контрагенты, есть банковская информационая система, есть транзакции, проводки, и все это должно работать надежно.
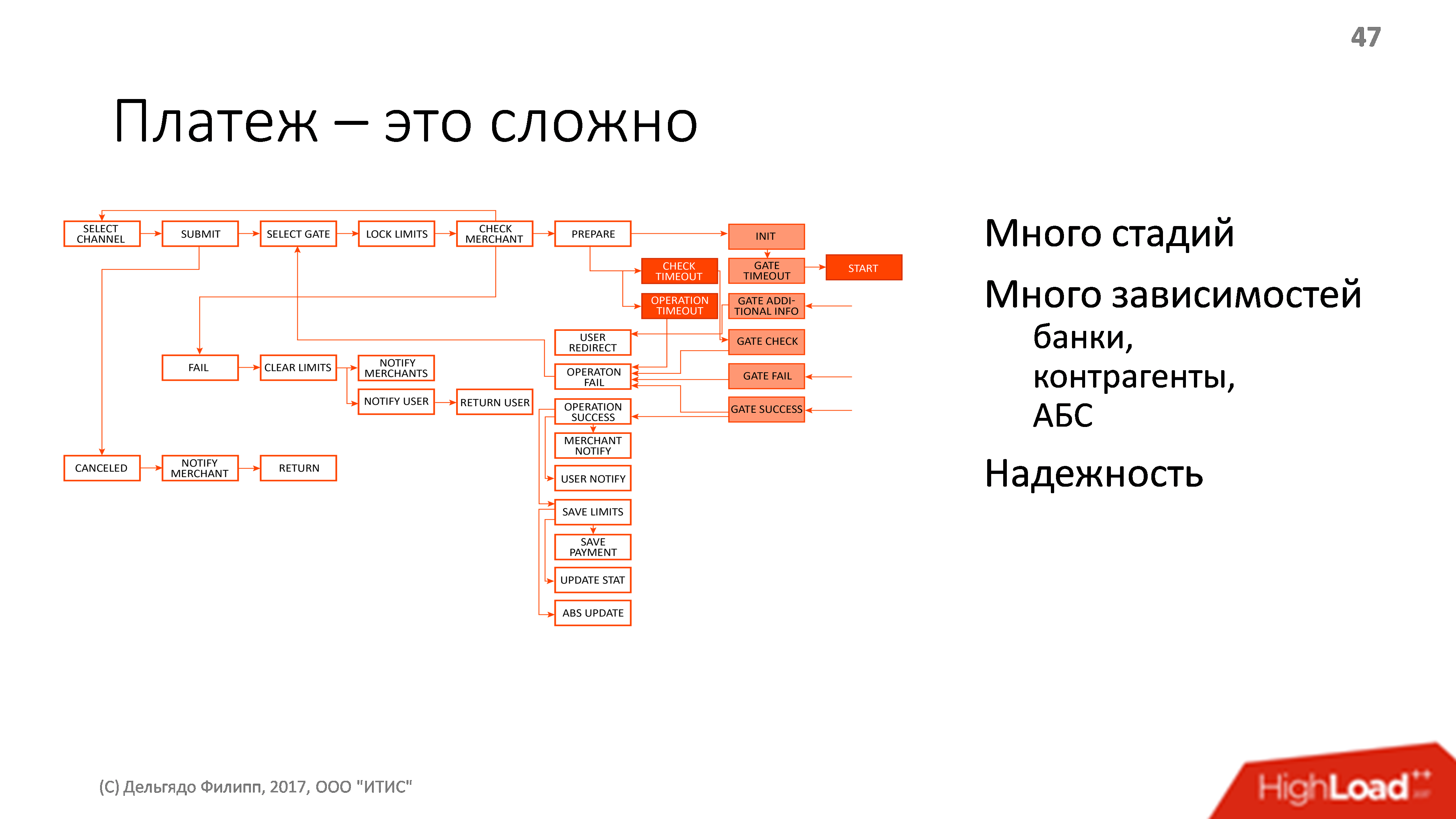
Надежно — это значит, что мы всегда знаем, на чьей стороне деньги, а если у нас сейчас все упало, с кого эти деньги требовать. Они могут зависнуть у любого из контрагентов, главное, чтобы не у нас. И мы должны точно знать, у кого они зависли так, чтобы все это можно было подтвердить и сообщить пользователю И, конечно, желательно, что бы всевозможных проблем было как можно меньше.
Finite State Machine

Разумеется, вначале у нас была FSM — нормальная стейт-машина, каждое событие обрабатывается в транзакции. Текущее состояние тоже сохраняем в СУБД. Реализовали все сами.
Первая проблема — у нас есть одновременные события.
Мы обрабатываем событие, связанное, например, с подтверждением пользователем начала платежа. В это время приходит событие от контрагента, отменяющее возможность проведения операции и это событие тоже нужно обработать. Поэтому в логике работы у нас появляются какие-то блокировки по ресурсам, ожидания снятия блокировок и т.д. К счастью, вначале вся обработка платежей проходила на одной машине и блокировки можно было реализовывать на уровне JVM.
Кроме того многие шаги имеют четкое максимальное время выполнения (тайм-аут), и эти времена тоже нужно где-то хранить, обрабатывать, смотреть, когда события наступления таймаутов происходят (и они тоже иногда бывают одновременными).
Все это реализовывалось через логику блокировок внутри Java-машины, потому что в базе данных это было делать не очень легко. Как следствие, получилась система с организацией высокой доступности только через Active-Standby и с кучей специальной логики восстановления контекстов и тайм-аутов.
У нас довольно маленькая нагрузка, всего десятки платежей в секунду, даже меньше сотни в случае максимального потенциального пика. При этом, правда, даже десять платежей в секунду приводит к сотне запросов (отдельных шагов) в секунду. Это небольшие нагрузки, поэтому одной машины нам почти всегда хватает.
Все было замечательно, но потребовался Active-Active.
Active-Active
Во-первых, мы захотели использовать схему Шамира, ну а также появились и другие хотелки: давайте мы будем выкладывать новую версию только на 3% пользователей; давайте часто менять логику платежа; хочется ее выкладывать с нулевым простоем и т.д.
Делать распределенные блокировки — это грустно, делать тайм-ауты распределенные тоже грустно. И мы начали в очередной раз разбираться — что такое платеж? Платеж — это множество событий, которые надо строго последовательно обрабатывать, это сложное изменяемое состояние, и обработка платежей должна идти параллельно.
Кто узнал определение? Правильно, платеж — это актор.
В Java много разных моделей акторов. Есть прекрасная Akka, есть временами странный, но прикольный Vert.x, есть гораздо менее используемый Quasar. Они все замечательные, но у них есть один фундаментальный недостаток (и не тот, о котором вы подумали) — у них недостаточные гарантии.
Ни один из них не гарантирует доставку сообщений между акторами, у всех из них есть проблема с работой внутри транзакции в базе данных.
Мы долго на это смотрели, думали, не допилить ли нам что-нибудь до вменяемого состояния, но потом сделали свой велосипед: очередь в PostgreSQL через select for update skip locked.

Все решение влезло в тысячу строчек кода и заняло примерно две человеко-недели на разработку и две человеко-недели на тестирование-доводки. При этом многие наши внутренние потребности, которые в той же Akka нормально не сделать, оказались выполнены.
Skip locked
Это такая прекрасная штука для реализации очередей в PostgreSQL. На самом деле данный механизм есть во всех базах данных, кроме, по-моему, MySQL.
Предположим, у нас есть две таблички: табличка с нашими акторами — flow, и табличка событий для этих акторов, она связана по колонке flow. События отсортированы по автоинкрементному ключу ID, все обычно. Пишем SQL-запрос.

Выбираем самое первое событие в самом первом из flow, указав магическое for update skip locked. Если никаких блокировок в табличке нету, запрос работает ровно как нормальный for update — берет и ставит блокировку на первую строчку, которую мы выбрали, т.е. на строку с первым актором и на строку с первым событием для этого актора.
Запускаем тот же запрос второй раз и он делает ровно то же самое, но пропуская уже заблокированные строчки. Поэтому он выберет первое событие во втором акторе (третья строка в таблице) и повесит на него блокировку.
Предположим, за это время мы закончили обработку первого из событий, удалили его и закрыли транзакцию. Блокировка снялась, поэтому в следующий раз выполнив запрос мы получим первое, на данный момент, событие, в первом акторе.

Это все работает достаточно быстро и надежно. На дешевом железе мы получали порядка 1000 подобных операций в секунду, при условии, что каждая из них тормозит где-то по 10 миллисекунд. Я использовал подобный подход несколько раз, весь код пишется буквально в три строчки и очень легко приделывать к такой очереди всякие удобные вещи.
Что мы получаем с такой очередью?

Все сообщения транзакционные: мы начали транзакцию, в ней что-то делаем с базой данных, в ней посылаем куда-то сообщения в другие акторы, если транзакция откатывается, сообщения тоже будут не посланы, что безумно удобно.
Можно не думать об отправке сообщений, отменяющих предыдущие, не думать о том, что все сообщения надо посылать пачкой только в конце обработки и после коммита. Вообще о многих вещах перестаешь думать. Например, не нужно думать о блокировках, потому что у вас все события обрабатываются последовательно, для чего, собственно, и придуманы акторы.
В своей реализации мы еще и добавили сложную политику обработки ошибок, потому что 80% логики платежа — это на самом деле обработка возможных ошибок: пользователь куда-то ушел, контрагент ответил какой-то ерундой, у пользователя вообще нет денег или контрагент не работает и надо выбрать другого контрагента, другой шлюз, и так далее. Там безумное количество разной сложной логики по обработке всевозможных ошибок.
Для нас это решение эффективно — 100 платежей в секунду нас устраивает.
Но это решение очень ограниченной применимости — свой велосипед, который можно применять довольно мало где. И у него очень жесткие ограничения по производительности. То есть коллегам из Яндекс.Денег такое не посоветую, потому что у них бывают черные пятницы, и 100 платежей в секунду им явно мало. У нас, к счастью, черной пятницы не бывает, у нас очень конкретный рынок, и поэтому мы можем спокойненько обойтись подобным решением. При этом это честный свой велосипед, честный enterprise-подход — OpenSource библиотеки в данном случае нам не очень подходит.
Сеть и транзакции
На бумаге все было гладко. Мы это внедрили, запустили — работает. И вдруг приходит проблема — упал один из шлюзов.
Шлюз — это реализация протокола взаимодействия с кем-то из поставщиков денег. Ну, упал и упал, пользователи ничего не заметили, мы переключились на резервный с другим контрагентом и начали разбираться, почему. Оказалось, что кончились соединения в пуле. Причина непонятна, вроде бы на шлюзе была не такая уж и большая нагрузка, чтобы исчерпать все соединения.
Начинаем разбираться и выясняем: у нас контрагент стал отвечать на сетевые запросы не за полсекунды, как было раньше, а за одну минуту. Поскольку у нас обработк азапроса к контрагенту является шагом платежа, то она выполняется в транзакции. Когда много транзакций начинают выполняться долго то соединений с БД на все поступающие запросы уже не хватает. Такое нормальное поведение: когда у вас очень много длинных транзакций, у вас соединения почему-то начинают заканчиваться.
Мы начали думать, что я этим делать. Самое первое — можно увеличить число соединений. К сожалению, в PostgreSQL есть вполне понятные лимиты на максимальное количество соединений на ядро, и оно не очень большое — порядка сотни. Потому что у PostgreSQL, напоминаю, каждое соединение — это один процесс. А процессов все-таки совсем много, десятки тысяч или сотни тысяч дешево сделать не получится. А если у нас контрагенты начинают отвечать раз в минуту, то одновременных транзакций может потребоваться и больше.
Можно попытаться сетевой вызов сделать асинхронным, то есть каждый шаг разбить на два. Каждый раз, когда нам нужно кого-то дернуть из контрагентов, нужно сделать вызов, сохранить состояние в контекстную базу данных, получить от него ответ. Обработка ответа попадет на этот же актор, мы поднимем состояние из базы данных, сделаем еще что-нибудь нужное. Но при этом у нас многократно увеличивается количество шагов в платеже, и в наше требование — 100 платежей в секунду — мы уже не укладываемся. Да и логика работы становится сложной.
Остается только управлять гарантиями сохранения. Нам не всегда нужна жесткая транзакционность, нам не всегда нужно жесткое восстановление при сетевом вызове, мы почти всегда можем его повторить. Поэтому нам нужно не все уметь делать через базу данных, какие-то вещи надо уметь делать в обход базы данных, в обход транзакций.
К сожалению, стандартного решения, которое бы позволяло тонко управлять гарантиями сохранения для конкретного события, нет. Сейчас я его пытаюсь писать, но, честно, реализовать skip locked на каком-нибудь Redis на Lua оказывается, довольно нетривиальная задача. Если я все это сделаю, я обязательно про это расскажу.
В качестве временного решения мы разбили процесс платежа на несколько отдельных акторов, исполняемых на разных СУБД (и на разных серверах). Это позволило внести асинхронные запросы там, где это было необходимо и решить текущие проблемы.
Главный вывод — если у вас в системе где-то появились акторы, они рано или поздно поползут всюду. Если вы думаете: «у нас будет актор в отдельном кусочке и производительности нам хватает», это не так. У вас в конечном итоге через год разработки выяснится, что все хотят их использовать там, где надо, и там, где не очень надо, и они всюду. Просто попробовать не удастся!
Учет и контроль. Бюджетный Business Intelligence
У нас платежная система, то есть деньги, а деньги любят, когда их считают. Поэтому очень быстро к нам пришел бизнес с просьбой сделать Business Intelligence систему. Данных у нас не очень много, какие-то сотни гигабайт, нужно это только топ-менеджменту, сотен аналитиков у нас не наличествует. И главное — надо делать «быстро и дешево».
Power BI — быстро и дешево?

Берем PowerBI — это решение от Microsoft: система генерирует нужные данные в виде csv, csv загружаются в облако, из облака они загружаются в PowerBI. Дешево, быстро, просто, сделано буквально на коленке, почти совсем без привлечения программистов. Отчеты написать в csv — это несложно.
Но оказалось, что дешево — это если у вас мало данных, и быстро — если мало данных. Как только у нас объем данных превысил 1 Гб, выяснилось, что и обрабатывается это довольно долго, и главное, в некий момент Microsoft изменил условия использования сервиса и он стал очень платным как раз примерно начиная с размера в 1 Гб. И выяснилось, что это нам уже несколько не по карману.
Пошли смотреть, что можно сделать.
ClickHouse
Первая мысль — ура, есть же ClickHouse! Кидаем все наши события в Kafkу, оттуда пачками выгружаем в ClickHouse, получается круто, модно, хайпово, аналитика должна работать быстро, все должно быть бесплатно, вообще прекрасно и замечательно. Но результат из ClickHouse надо где-то показывать. На данный момент с Clickhouse лучше всех работает Redash. Сделали тестовую версию Redash, показали бизнесу — те сказали, что с этим они работать не будут, потому что выглядит оно, мягко говоря, уродливо и некоторых милых бизнесу вещей типа drill-down там просто нет.
Начали выяснять, а о чем вообще мечтает бизнес. Бизнес мечтает о чем-нибудь типа Tableau, где все красиво. Tableau лучше всего интегрируется с Vertica, и получается прекрасная, по-идее, система: все события кидаем в Kafka, с Kafka перекидываем в Vertica.
Vertica работает быстро, качественно, надежно, просто, а Tableau Server все это показывает. Одно но — стоимость лицензии Vertica официально не сообщается, но, мягко говоря, немалая,. Tableau тоже не очень дешевый. К счастью, выяснилось, что на наших объемах все это на самом деле не так и дорого, потому что до одного терабайта данных Vertica — халявная, Community Edition нас абсолютно устраивает, до терабайта нам еще далеко. А поскольку лицензия на Tableau нам нужна только на небольшое количество разработчиков и топ-менеджеров, то это стоит какие-то полне нормальные деньги. Вплоть до того, что нам нужно было меньше лицензий, чем минимальный пакет, который продает Tableau.
Оказалось, что такое нормальное, совершенно классическое тяжелое enterprise-решение, является еще и нормальным web-решением. Оно недорого и ставится с нуля, не задумываясь. Vertica меня пока радует: в ней многие именно аналитические вещи решаются очень красиво. Пока у вас не очень много данных — советую. Впрочем, в эксплуатации она требовательна к пониманию принципов ее работы, нужно в них разобраться перед использованием.

При этом я думаю, что если мы через несколько лет вырастем за пределы терабайта, то к этому времени у нас как раз уже будет хорошая экспертиза по ClickHouse, Tableau к этому времени явно сделает к нему адаптор, и мы аккуратненько переползем на бесплатный ClickHouse за какое-то вполне разумное время.
Контент
У нас довольно много текстов:
- Юридическая информация, которую мы обязаны предоставлять, оферты и т.д.;
- Информация о контрагентах, включая комиссии, которые мы берем с пользователей;
- Инструкции для пользователей;
- Собственный маленький блог;
- Информация об ошибках и прочее.
Ошибка в этой информации довольно болезненна. Например, если мы выложили не те комиссии, которые мы реально взимаем, пользователи потом могут очень сильно на нас обидеться, а, главное, на нас могут обидеться контролирующие органы, что гораздо хуже. Поэтому тексты для нас — это тоже код: нужно проверять его перед публикацией, в его подготовке задействовано много людей, ошибки дорого стоят.

Вначале у нас текст был просто частью фронтенда: все тексты верстались верстальщиками-фронтендерами, потом шли в тестирование, вычитывалось, показывалось на демо-стенде, потом уже шли в продакшн. Но текст меняется слишком часто, и так делать было просто дорого.
И мы начали думать, как бы все это автоматизировать и сделать CМS. Простые CМS не подходят, потому что:
- сложно с разделением тестовой среды и продакшена;
- непонятно, как тестировать текст;
- сложно работать большому количеству пользователей;
- сложно интегрировать с большой Java-системой.
Не простые CМS — слишком дорогие во всех смыслах, они и стоят обычно больших денег, и их интеграция весьма неочевидна, потому что там напридумано много всего.
Идеальным решением было бы поставить у всех, кто работает с текстами, банальный Git: пусть они все написанные тексты отправляют прямо в репозитарий. Но от мысли поставить Git топ-менеджерам и копирайтером и научить их им пользоваться, мы подумали-подумали и в ужасе отказались, потому что все-таки git не для нормальных людей.
Самое идеальное решение было бы, наверное, редактор текстов, встроенный прямо в IntelliJ IDEA, где можно сложность использования Git аккуратненько скрыть. Но, к сожалению, JetBrains такого редактора до сих пор не сделали, хотя я давно их просил.
Пришлось опять делать велосипед:
- Простой редактор текста.
- Простой редактор html, потому что вместо сложного редактора текста проще попросить нашего же фронтендера сверстать все в html, но при этом выкладывать через систему CMS и систему контроля качества.
- Простая концепция версий — есть пакеты изменений, публикация идет целиком пакетами, восстановление при необходимости всего контента тоже по одной кнопочке. И очень простой порядок работы с текстами.
- Категорический запрет (просто нет такой кнопочки) что-нибудь изменить прямо на продакшне. Все можно изменить только через задачу в Jira, дальше она попадает в тестовую версию, с тестовой версии на продакшен уже переносят отдельно обученные люди — все, что они могут, это переносить готовые пакеты с тестовой версии на продакшн, после того как получены все подтверждения, без возможности вносить правки.

То есть пришлось написать, по сути дела, микро-портальчик в стиле enterprise.
Честно говоря, если бы я мог такое решение купить — я предпочел бы это купить. Но ни одной embedded CMS для больших систем я на рынке просто не нашел, и, по-моему, их до сих пор нет. Я, честно говоря, уже который раз пишу ее с нуля, и очень жалко, что до сих пор никто это не сделал за меня.
Выводы

Что из всего этого можно сказать? Что жизнь на грани довольно интересна.
Когда у вас задачи одновременно и из web, и из enterprise, можно заимствовать разные идеи из мира корпораций, у них довольно много вещей продумано. Иногда можно заимствовать не только идеи, но и конкретные решения типа как Vertica, если они дешевые.
Честно, если бы я нашел дешевую поддержку для IBM DB2 — я бы реализовывал бы проект на ней, я ее очень люблю, она дешевая и очень надежная, но найти поддержку этой базы за разумные деньги в России сложно. Конечно, можно кого-нибудь переманить из Почты России, но они привыкли к настолько большим серверам, что мы явно для них слишком мелкие.
Ну и большие проблемы из мира enterprise можно решать в web-стиле довольно просто, чем мы постоянно занимаемся.
Архитектура — понятие динамическое.

Не бывает хорошей архитектуры вообще. Бывает архитектура, которая более-менее вас удовлетворяет в конкретный момент времени. Время меняется — архитектура меняется, и надо постоянно быть в этому готовым, и всегда вкладывать ресурсы в развитие архитектуры. Архитектура проекта — это процесс, а не результат.
Java и SQL — это реально круто, если вы умеете это готовить. Мы умеем, поэтому у нас все получается просто, быстро, ненапряжно, и очень небольшой командой мы делаем довольно сложны
Новости
Даты проведения HighLoad++ 2018 переносятся на 8 и 9 ноября, чтобы разминуться с Percona Live.
Прием заявок на Highload++ Siberia, которая пройдет 25 и 26 июня в Новосибирске, уже закончился, поданные доклады опубликованы на сайте, цена билетов уже не минимальная, но еще и не слишком выросла — идеальный момент для бронирования.
До РИТ++ осталось совсем немного времени, программа активно формируется. В тему сегодняшней статьи можно отметить такие заявки:
- «Возможности ClickHouse для продвинутых» от собственно разработчика ClickHouse Алексея Миловидова.
- Юрий Лилеков с докладом о том, зачем разработчику статистика, или как улучшить качество продукта?
- Александр Сербул расскажет об особенностях lambda-архитектур, платформе микросервисов Amazon Lambda, а также подводных камнях и победах с Node.JS и многопоточной Java.
Комментарии (26)

JediPhilosopher
10.05.2018 14:12+3Я занимаюсь платежными системами в Нигерии, где на ИБ кладут здоровый болт, в итоге забавно сравнивать свой опыт с чужим. Например те же ключи шифрования для сетевых запросов по протоколу iso 8583. По правилам их положено разбивать на две части, которые должны знать два разных человека, которые должны вводить их в терминалы каждый свой фрагмент, чтобы никто не знал целый ключ. На практике же нам эти ключи все сразу (обе части + комбинированный итоговый) присылали по простому емейлу.
Вообще очень грустно что все эти нюансы толком нигде не описаны. Нету гайдов «платежные системы для чайников», есть только какие-то совершенно огромные нечитаемые многотомники отдельных стандартов, тех же EMV или PCI DSS в которых без опыта фиг разберешься. И область это довольно узкая и готовых спецов в ней сложно найти. В итоге каждая команда вынуждена снова и снова ходить по тем же граблям.
dph
11.05.2018 07:03Насколько я могу видеть, с ИБ вообще все довольно плохо. К нам на собеседования регулярно приходили разработчики из банков или платежных систем — и судя по ответам, далеко не всюду всерьез заботятся о безопасности.
У меня после нескольких сделанных платежных систем развилась легкая личная паранойя на теме доступа к данным и уязвимостям, но в большинстве проектов не готовы увеличивать стоимость разработки и поддержки ради безопасности. Хорошо, если аудитор грамотный и может показать какие-то реальные уязвимые точки, но обычно при PCI DSS аудите проверяются только система, связанная с карточными данными, а это далеко не полный список уязвимостей.
А вместо руководства «платежная система для чайников» — проще найти специалистов для отдельной консультации, все будет дешевле, чем самому грабли собирать. Так, в общем-то, почти в любых сложных проектах.JediPhilosopher
11.05.2018 13:02Так в том и дело что тратить дополнительные деньги (на консультации или аудит) никто не хочет. Типа «у нас пять лет все норм работало значит все в порядке». А то что у них POS-терминалы шлют карточные данные по незашифрованному протоколу (даже банальный TLS они три года настроить не могут), при этом вполне вероятно что часть из них сидит в плохо защищенных wifi сетях — это фигня. Спасает только то, что уровень нигерийских хакеров видимо соответствует уровню их разработчиков.
Были бы какие-то общедоступные гайды — можно было бы хотя бы на них ссылаться.dph
11.05.2018 17:37Ну, в документах по PCI DSS есть выжимки по организации безопасности, их можно использовать для убеждения. И есть же список общих практик по информационной безопаности (вечно забываю, как именно документ называется, но все безопасники на него всегда ссылаются), можно его использовать. Он тоже вполне конкретен.
SbWereWolf
10.05.2018 23:59«Самое идеальное решение было бы, наверное, редактор текстов, встроенный прямо в IntelliJ IDEA, где можно сложность использования Git аккуратненько скрыть. Но, к сожалению, JetBrains такого редактора до сих пор не сделали, хотя я давно их просил.» — не правда, *.md можно успешно редактировать и видеть итог, можно просто текст править и просто складывать его в репозиторий, можно *.html править и в браузере смотреть, вариантов много.
dph
11.05.2018 10:05Редактирование html не подходит по условиям задачи (с текстами должны работать люди, не разбирающиеся в верстке). Про плагин работы с Markdown я, конечно, знаю, но это именно плагин, не очень удобный в использовании для «не программиста» и не убирающий всю прочую сложность Idea. Я имел в виду отдельное решение типа WebStorm, но не для языка программирования, а для текстов (сложных текстов). С связями между файлами, возможностью добавить собственные CSS, возможностью добавить метаинформацию и т.п.
Так, что бы этот инструмент можно было дать редактору или маркетологу.
Теоретически, такое можно сделать из Eclipse, но это была бы уже более сложная разработка, нежели мы могли себе позволить.
vyatsek
11.05.2018 03:13А что за платежная система? Можно поподробнее про характеристики? Сколько платежей в секунду можете процессить? Какие операторы, типы операторов.
Как я уже говорил, платеж — это довольно сложно.
такие высказывания не придают значимости.
Вы очень еще любите говорить про enterprise. Enterprise — это когда не только вы зависите от систем, но и сторонние системы зависят от вас. А платежная система это не более, чем продукт для небольшой IT компании.dph
11.05.2018 10:14Ну, вообще-то в начале сказано, что это система платежей для легального российского букмекерского бизнеса. Таковых на рынке ровно две и я рассказывал не про Qiwi.
В качестве требований — до 100 платежей в секунду, сквозные платежи, прямые платежи, интеграция с другими агрегаторами, карточными процессингами и другими платежными системами.
Почему платеж — это гораздо сложее, чем кажется, я довольно много рассказывал. Статусы, надежность переходов, юридические ограничения и так далее.
Ну и от этой системы зависит где-то половина российского онлайного букмекерского бизнеса, это не мало. Собственно, потому и на грани энтерпрайза.
sshmakov
11.05.2018 14:37-1Подумайте о переходе с обработки единичных платежей на обработку пачек платежей, естественно, асинхронно. Так вы решите вопрос производительности радикально.
dph
11.05.2018 17:29+2Увы, это имело бы смысл, если бы контрагенты поддерживали бы пакетную обработку и если бы у всех платежей был бы одинаковый процесс прохождения.
Но это не так, контрагенты не поддерживают пакетной обработки и каждый платеж достаточно индивидуален.
А все, что можно сделать пачкой мы, конечно, сделали, но таких операций очень и очень мало. Да и логика обработки сильно усложняется.sshmakov
12.05.2018 18:34А вам нужно проще или быстрее?
Да, контрагенты есть разные, и да, процессы прохождения платежей различаются. Но процентов на 90 платежи имеют одинаковую обработку и их можно автоматически, на стороне АБС организовать в пакеты, и обрабатывать пакет за раз.
Просто как пример способа объединения — одной из "тяжёлых" операций является изменение остатка/ликвидности на счетах при исполнении платежа. Типично в АБС остаток меняется каждой проводкой отдельно. Если вы сгруппируете проводки по задействованным счетам и отложите апдейт остатка на обработку пакета проводок, вы сразу получите прирост производительности.dph
12.05.2018 22:35+2А откуда взялась такая статистика «90 процентов имеют одинаковую обработку»? У нас категорически не так.
Впрочем, подозреваю, вы путаете процессинг (проведение онлайн платежа) и банковский учет (оформление проводок в АБСке). Я рассказываю в основном про процессинг, где задержки пользователя недопустимы, а проводок вообще нет (платеж, представляет собой первичный документ в терминах бухучета и в АБСку поступает только при удачном завершении).
Разумеется, интеграция с АБСкой делается пакетно, уже после завершения платежа. Проблемы возникают, скорее, из-за неторопливости нашей АБСки (впрочем, насколько я знаю, это проблема не столько нашей конкретной системы, сколько всех АБСок — они в основном сделаны по технологиям прошлого века), ну для этого мы и переводим потихоньку бухучет в процессинг (где он занимает, впрочем, совершенно незначительное время по сравнению с прочими этапами платежа).
Ну а изменение остатка и ликвидности в процессинге — совершенно не значимая операция, что там может быть сложного и тяжелого…
ITMatika
11.05.2018 16:37Например, если мы выложили не те комиссии, которые мы реально взимаем, пользователи потом могут очень сильно на нас обидеться, а, главное, на нас могут обидеться контролирующие органы, что гораздо хуже. Поэтому тексты для нас — это тоже код: нужно проверять его перед публикацией, в его подготовке задействовано много людей, ошибки дорого стоят.
Только что пришла смс от МТС о грядущем изменении тарифа. Перехожу в подробности и что вижу — если сейчас я плачу 8 руб. в сутки, то буду платить 820, или около того, в чём я нисколько не сомневаюсь :)
Новые тарифы
olegnyr
12.05.2018 10:31+1Такие проблемы которые вы описали прошли многие процессинги платежей
- Стейт машин для платежа не подходит на практике лучше себя показало использование шагов, каждый платеж набирает пройденные шаги и в зависимости от набранного множества принимается решение.
- Долгая транзакция это действительно проблема, и ваше решение выглядит, как пришли через боль, написание шлюзов становится не тривиальной задачей.
- То что для анализа финансовой системы выгружаете данные о платежах в клауд это просто капец. Говорит о вашей не состоятельности, Вы не понимаете что у вас творится в системе с деньгами? С НКО у вас наверно беда.
- Для очередей в бд, ребята из яндекс денег выложили отличный проект db-queue
- Очень понравилось что вы сделали с безопасностью, это действительно последняя тема которой уделяют внимание(но примеры с qiwi, Rapida и д.р. дали талчек, но пока гром...)
- Еще порадовало архитектура динамическая ;-(
Спасибо отличная статья, я бы хотел добавить что мир платежных систем держится на идемпотентности, так что платим не боимся. :-)
dph
12.05.2018 13:37О, содержательный комментарий, ура. По пунктам:
1) Если посмотришь на статью, то именно это мы и сделали. Только шаги набираются не заранее, а в процессе прохождения платежа. От чистого STM мы отказались вообще сразу, а дальше был длинный путь до осознания, что наша модель работы с платежами — это просто персистентные акторы.
2) Как раз с шлюзами у нас проблем нет, они на акторной модели пишутся просто и там легко можно вместо длинных транзакций внутри одного шага сделать несколько шагов, базы данных у шлюзов независимые, в производительность не упремся. Тут главное — в продуманном внутреннем API для шлюзов, если оно асинхронное, то все пишется достаточно просто.
3) Э, не надо путать учет в НКО и бизнес-аналитику. Учет в НКО — это управленческий и бухгалтерский, ведется в АБСке, и там все достаточно хорошо (по крайней мере и бизнес и аудит ЦБ довольны). А бизнес-аналитика нужна для ответов на вопросы вида «после обновления API у такого-то контрагента как изменилось распределение ошибок по соответствующему шлюзу» или «мы изменили дизайн формы оплаты через мобильных операторов, что стало с конверсией» или «один из клиентов начал рекламную акцию на Дальнем Востоке, как это изменило поток платежей по региону сравнительно с предыдущими подобными акциями». Это очень разные инструменты. Одним из требований к бизнес-аналитике, кстати, является интеграция с Google Analitics.
4) Как ты думаешь, кто проектировал самую первую очередь (еще на Oracle) на БД в Яндекс.Деньгах? И переписывал ее потом на skip locked? Да и появилась db-queue уже после того, как мы сделали свое собственное решение. И в нашем решении некоторые вещи сделаны заметно гибче и (для нас) удобнее. Например, возможность задавать свои стратегии повтора (произвольные) или добавлять действия на коммит транзакции обработки (для инвалидации или заполнения кэшей, например).
Собственно, то, что я делал в текущем проекте — это как раз попытка не наступить на те грабли, что были в Яндекс.Деньгах.
5) Сейчас у меня есть понимание, как это можно сделать еще проще, но пока не реализовано, так что доклада пока не будет )
6) Спасибо. Но идемпотемптность идет по одной операции, а не по цепочке. И не все контрагенты (почти никто, если честно) вообще не поддерживают идемпотемптность в платежах, так что все не так хорошо. Ну и пособеседовав кучу разработчиков и архитекторов из маленьких платежных систем — я понял, что спокойно готов пользоваться только теми, что сам писал (так что Яндекс.Деньгами я спокойно пользуюсь).olegnyr
12.05.2018 14:21С аналитикой мы пошли другим путем :)
Долгое время внедрял системы интеграции, АБС банков с процесингами платежей и везде были одни и те же проблемы не сходится день, откаты в закрытом дне, расчеты на счетчиках, нет стабильности в отчетах, нет понимания у каких поставщиков какие деньги.
На рынке мы так и не нашли, что смогло бы удовлетворить нас.
Написали свой ;-) но пошли от схемы проводок, запихали часть абс в процесинг и получили банковский учет внутри. Получили учет по банковским правилам, получили аналитику в обортно сальдовой ведомости.dph
12.05.2018 15:21Ну, у нас, вроде бы, проблем с АБСкой нет. Там есть ограничения по производительности (слишком дорого получается масштабировать), так что мы тоже переносим банковский учет внутрь процессинга. И, конечно, внутри процессинга приходится делать проводки, счета и т.п, но это как раз относительно просто, хотя и муторно. Сложности там скорее в прекрасных отчетах из 255 полей для Финмониторинга и прочих вещах, связанных с персональными данными.
Кстати, а ты (или лучше на Вы) где работаешь?
Arbane
13.05.2018 02:40На будущее заметка — у нас Firebird3 держит сотни соединений в варианте суперсервера без проблем. Может много больше. Не постгресом единым.
dph
13.05.2018 17:13Сотни (и тысячи) и PostgreSQL держит. Но в Firebird нет skip locked (и вообще, насколько я помню, там очень ограничено управление блокировками и транзакциями).
С трудом себе представляю сценарий, в котором мне мог бы понадобиться Firebird.
Cobolorum
Радостно слышать что люди открывают для себя транзакционный бизнес в платёжных системах. Но печально что изобретают велосипеды.
dph
Хм, а что можно было бы использовать вместо велосипедов? Мы же их изобретали не просто так (
Ну и уже давно не открывают, это не первая платежка в моей жизни )