

Введение
Эта статья — «сухой остаток» размышлений о том, как подходить к решению некоторых неизбежных проблем в системе распределенного хранения и изменения состояний, финансовых процессингов в частности. Статья не для того, чтоб «отлить в граните» какую-то одну точку зрения, а скорее для обмена мнениями и конструктивной критики.
Сразу уточню: описанные подходы работают в соответствии с теоремой CAP, не допускают движения данных быстрее скорости света и не опровергают какие-либо другие фундаментальные законы природы.
Проблема процессинга
Финансовый процессинг, «с высоты птичьего полета» – это структура данных, которая хранит в себе набор состояний (балансы счетов) и историю изменений этих состояний. К этой структуре «крепится» программа, определяющая логику, в соответствии с которой изменения состояний производятся. Вроде бы не особо сложно.
Но от процессинга требуется способность максимально быстро проводить транзакции, так как основной его пользователь не Alice которая отправила Bob 10 рублей, а онлайн магазины с тысячами и десятками тысяч клиентов, которые при падении конверсии, из-за аварий или тормозов, без раздумий уйдут к конкурентами. (Собственно это, по-видимому, основная причина, почему частные процессинги не может сожрать биткойн).
Для примерного понимания существующих потребностей, можно отталкиваться от отчетов VISA о том, как они готовятся к новогодним пикам.
Но как только мы попробуем разделить нагрузку, сделать процессинг распределенным (на каждом узле копия данных и возможность выполнять транзакции), мы столкнемся с проблемой консистентности данных.В чем собственно проблема?
Когда создается база данных со множеством реплик, то всегда возникает вопрос с тем, как разрешать возникающую неоднозначность (неконсистентность) данных, когда в на каких-то узлах системы данные уже были изменены, а до других узлов изменения еще «не доехали». При параллельном потоке изменений, система, из более чем одного узла, просто не сможет постоянно находиться в консистентном состоянии (если не использовать механизмы о которых ниже).
Существующая терминология определяет несколько видов консистентности:
- Строгая консистентность – после изменения данных, обновленная версия доступна сразу на всех узлах системы.
- Слабая консистентность – система не гарантирует, что последующие обращения к данным вернут обновленное значение. Перед тем, как будет возвращено обновленное значение, должен выполниться ряд условий. Период между обновлением и моментом, когда каждый наблюдатель всегда гарантированно увидит обновленное значение, называется окном неконсистентности (inconsistency window).
- Консистентность «в конечном счете» (Eventual consistency) – частный случай слабой консистентности. Система гарантирует, что при отсутствии новых обновлений данных, в конечном счете, все запросы будут возвращать последнее обновленное значение. При отсутствии сбоев, максимальный размер окна несогласованности может быть определен на основании таких факторов, как задержка связи, загруженность системы и количество реплик в соответствии со схемой репликации. Самая популярная система, реализующая «согласованность в конечном счете» – DNS. Обновленная запись распространяется в соответствии с параметрами конфигурации и настройками интервалов кэшированя. В конечном счете, все клиенты увидят обновление.
Это цитата хабрпоста, в котором еще много интересного про виды консистентности, но для понимания статьи этих трех достаточно.
Если на консистентность забить, мы получим уязвимость, которая называется «состояние гонки» (race condition). На практике это эксплуатируется как «двойная трата» (Double Spending это самый очевидный способ но далеко не единственный), когда на одни и те же деньги совершаются две покупки, если время между покупками меньше времени репликации. За примером далеко ходить не приходится. Как с этим бороться?
Современные распределенные системы хранения данных поддерживают разные условия, при которых изменение состояния (коммит) признается успешным, то есть одно и то же состояние доступно на всех узлах сети и признается ими как верное. При грамотной «готовке» эти условия могут сильно облегать жизнь. Например, в cassandra db поддерживаются режимы:
- общий коммит – изменения прошло без ошибок на всех узлах
- коммит по кворуму – на большинстве узлов изменения произошли без ошибок
- коммит по количеству успешных – на N узлах изменения произошли без ошибок
Общий коммит может показаться спасительным, но:
- Он плохо масштабируется, так как зависимость между временем необходимым на успешный коммит линейно (в самом лучше случае) зависит от количества узлов в кластере.
- Одна и та же транзакция обрабатывается на всех узлах, что никак не решает проблему распределения нагрузки
Итого, общий коммит может быть неплохим для избыточности, поддержки небольшого количества «горячих» копий, но губителен для скорости и бесполезен против большого количества транзакций. Отчасти из-за этого большинство современных успешных (то есть больших и растущих) процессингов очень страдают в районе базы.
Задача
Из всего написанного можно вывести свойства, которыми должна обладать распределенная конструкция, чтоб претендовать на роль части современного процессинга:
- Невозможность race condition при проведении транзакций
- Строгая консистентность при фиксации баланса во время транзакции
- Равномерное распределение вычислительной нагрузки
- Наращивание узлов с влиянием на скорость оптимальней линейного
- Отсутствие единой точки отказа
Здесь на помощь может придти занятная особенность условия работы процессинга. Транзакции, на списание средств производятся в нем, в 95-99% случаев живыми людьми, которым моментальная готовность системы к следующей транзакции не особо нужна (10-60с). Более того, быстрый поток транзакций на списание, иногда блокируется специально, так как это признак быстрого вывода в случае кражи (когда есть лимит на размер одной транзакции). Если возвращаться к примеру интернет-магазина с тысячами клиентов, то каждый в отдельности клиент платит не часто.
Отталкиваясь от этого свойства, можно описать систему, которая позволит использовать для окна неконсистентности время после транзакции. То есть после каждой транзакции с конкретного счета мы будем иметь некоторый промежуток времени T, который будет меньше или равен скорости репликации данных в системе и в течении которого транзакции с этого и только этого счета будут невозможны, но не больше такого, который отразится на user experience 95-99% клиентов. Для начала немного терминов.
Термины и определения
Необходимы для простоты восприятия.
- Транзакция – изменение состояния счета. То же самое что перевод.
- Счет – некий ID, с которым ассоциировано некоторое состояние (баланс), которое изменяется транзакциями.
- Цепочка – цепочка транзакций на списание средств, ассоциированная с ID. Устроена так же как классическая цепочка блоков. Технически, это журнал транзакций на списание, где в каждой следующей транзакции находится хеш-сумма предыдушей, такая связь дает два важных свойства
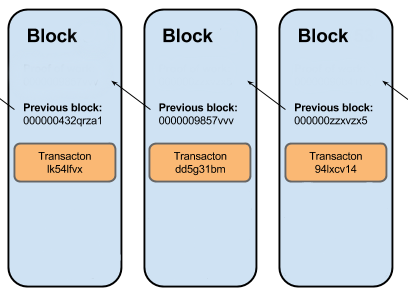
- Проверяемая последовательность транзакций
- Контроль целостности (не путать с контролем подлинности!). Если какая-то из транзакций была изменена, то через проверку по хешам это сразу станет заметно.
- Запрос на транзакцию – структура данных, в которой находится информация необходимая для проведения транзакции (кому и сколько), но в соответствии с которой транзакция еще не проведена и какое-то решение о корректности еще не принято
- Узел – программа, которая хранит реплику всех цепочек в системе, следит за тем, чтоб реплика была актуальной, процессит транзакции, создает новые блоки(транзакции и маршрутизирует запросы на транзакции. Множество узлов образует сеть, или систему.
- Система – множество узлов, которое образует сеть и которые получает на вход запросы на транзакции. Система работает в доверенном окружении: узлы доверяют друг другу, то есть никак не решают задачу византийскую задачу.
Как обеспечить защиту от race condition
Сперва рассмотрим частный случай, когда система находится в консистентном состоянии, то есть цепочка для атакующего счета одинакова на всех узлах на момент создания двух противоречивых запросов на транзакции на разных узлах системы. Для того, чтоб исключить возможность одновременно обработки запроса на транзакцию на двух разных узлах, введем в создаваемую узлами сеть маршрутизацию. Причем таким образом, чтоб 2 противоречивых запроса на транзакцию не могли быть обработаны и включены в цепочку на 2х разных узлах. Как это сделать?
Для того, чтоб система не имела единой точки отказа и горизонтально масштабировалсь (а так же имела еще кучу приятных свойств), резонно сделать маршрутизацию на основе хорошо изученного протокола DHT – Kademlia.
Что такое DHT и зачем одно здесь? Если коротко, то DHT, это некоторое пространство значений (например все возможные значения хеш-функции md5), которое равномерно поделено между узлами сети.

На картинке пример пространства значений 0-1000, которое распределено между узлами A,B,C,D,E, в данном случае не равномерно.
В DHT сети узлы содержат информацию о N ближайших соседних узлах, и если необходимо найти какой-то конкретный хеш из поделенного пространства значений, то отправив запрос в такую сеть, можно относительно быстро найти узел, ответственный за ту часть пространства значений, где находится искомый хеш.
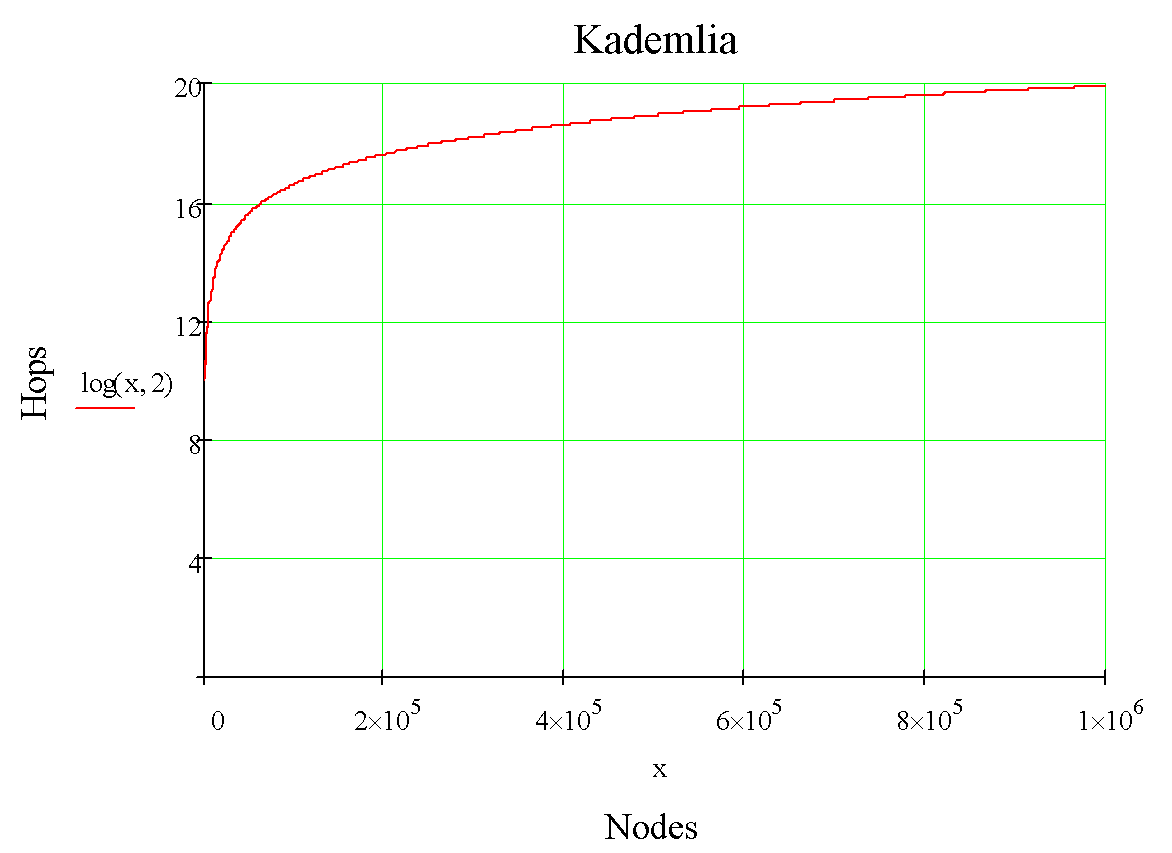
Чтоб понять насколько быстро, 2 графика с зависимостью количества хопов при поиске для классической реализации Kademlia:
И оптимизированной:
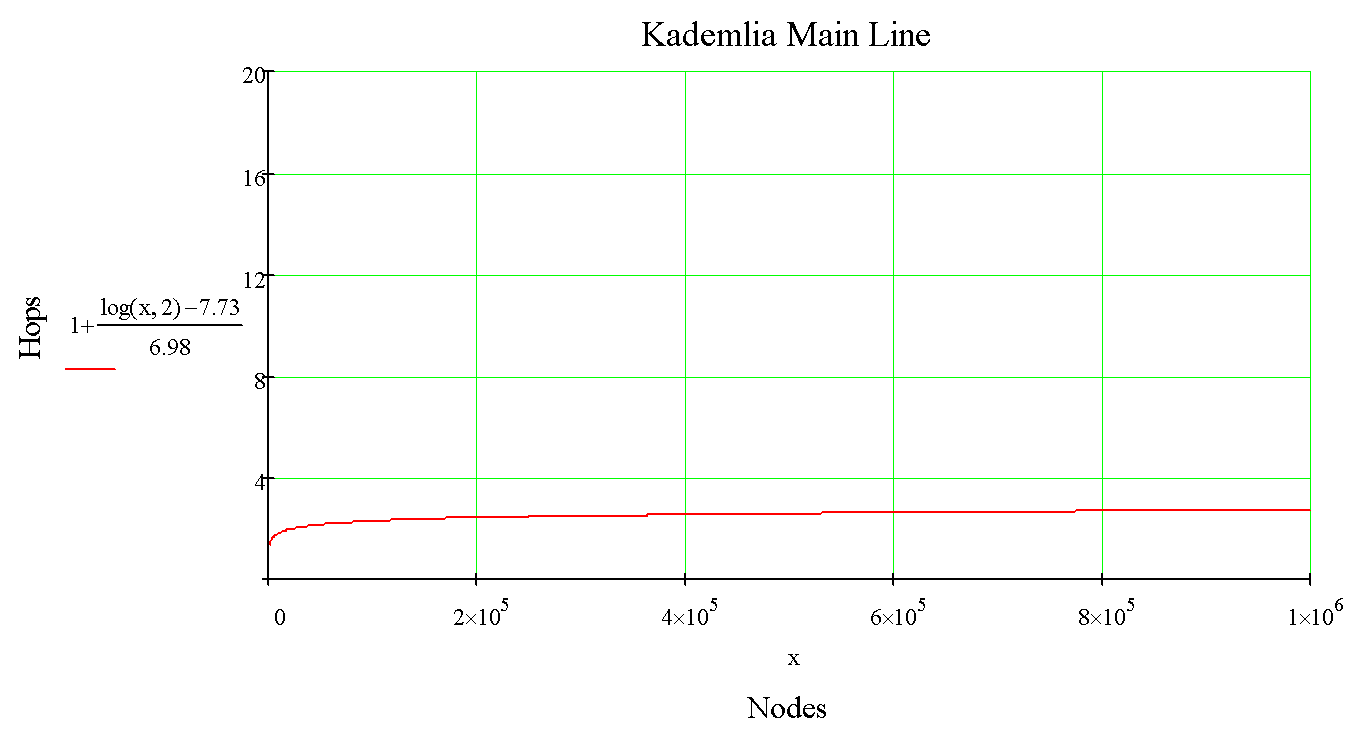
Поскольку количество хопов в маршрутизации растет логарифмически, сеть обладает выдающимся потенциалом горизонтального масштабирования.
Кстати, DHT используется в Cassandra DB и амазоновском Dynamo, но с важным отличием, там он используется только для навигации по шардированным данным, а в случае изменения реплицированных данных используются методы описанные в введении.
Как сделать так, чтоб при изменении данных в зеркальных репликах исключить параллельное изменение данных на разных репликах?
Для этого будем считать хеш от последней транзакции в цепочке и используем его, как значение из пространства имен, которое поделено между узлами сети. Таким образом, на обоих узлах где были созданы противоречивые запросы на транзакцию, полученное значение будет одинаковым (так как в соответствии цепочки на узлах в консистентном состоянии). Далее, используя это значение в функции DHTsearch, наши запросы будут «наведены» на один и только один узел, на котором запросы будут обработаны последовательно. Но это в случае исходной консистентность, которая в реальном мире существует только на бумаге :)
Теперь рассмотрим общий случай, когда система находится в неконсистентном состоянии, то есть количество транзакций в цепочке какого-то конкретного счета может отличаться от узла к узлу. Следовательно, возможно состояние, что 2 противоречивые транзакции будут получены на узлах N1 и N2, где цепочки разной степени актуальности (разные последние транзакции от которых вычисляется хеш), из-за чего запросы на транзакции вроде бы будут «наведены» на узлы N3 и N4 соответственно, где будут обработаны, что приведет к «ветвлению» цепочки, чего нельзя допускать. Если рассмотреть в эту проблему детально, то ее нет, так как у нас существует однозначная связь:
..> транзакция > узел для процессинга > следующий транзакция>..
что для разных транзакций одной цепочки можно изобразить вот так:
R – маршрут (значение из разделяемого пространства имен)
N – узел на котором обрабатывается следующая транзакция
T – транзакция
hash(T0)=R1 – назначение, или маршрут до узла на котором будет обрабатываться T1
R1 -> Nx – наводимся на узел
Nx -> hash(T1) – создаем новый маршрут если T1 обработана успешно и включена в цепь
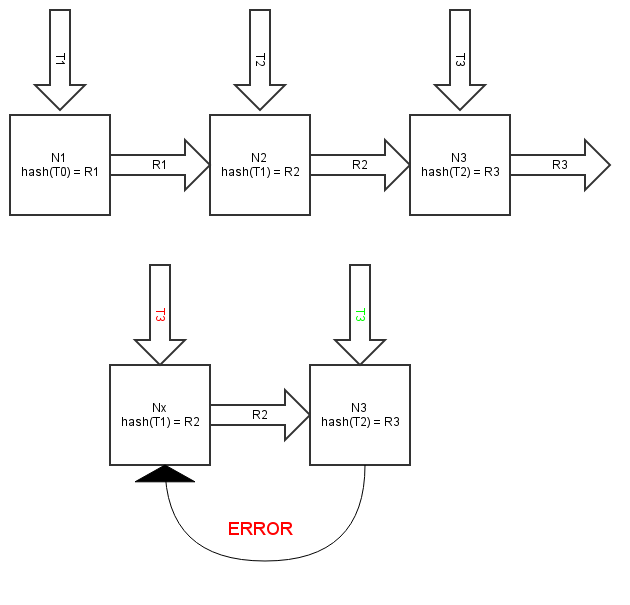
Из этого следует что если запрос на транзакцию поступит на «отстающий» узел, где будет устаревшая версия цепочки, то это запрос на транзакцию будет «наведен» на тот узел, где уже был создан и сохранена более свежая транзакция, т.е. хеши последних транзакций точно не совпадут, и запрос будет отклонен. Ветвления цепочки не произойдет.
Здесь лучше сходить за чаем.
Строгая консистентность баланса
Был описан способ безопасного изменения состояния, но для работы процессинга этого не достаточно, нужно однозначное знание о том, с какого состояние мы меняемся в какое:
- Локальная однозначность – на узле на котором обрабатывается транзакция должна быть возможность однозначно «зафиксировать баланс», и исключить возможность повторного использования средств.
- Консистентность входящих – исключение возможности двойного использования входящих средств в случае неконсистентности данных о входящих средствах на узлах, при проведении двух последовательных транзакций (которые в соответствии с маршрутизацией будут выполнены на разных узлах, а контроль через маршрутизируемость одной цепчоки никак не гарантирует консистентность других, маршрутизируемых независимо ).
Небольшое изменение терминологии – транзакции, в рамках этого раздела, для простоты восприятия, называются входящими или исходящими переводами.
Как все это достигается, когда происходит перевод со счетов IDa и IDb на IDc, а затем IDc делает перевод IDd? Исходное состояние (здесь для простоты представляется как таблица, где каждая транзакция добавленная в цепочку какого-то из счетов – ряд добавляемый снизу):
| Хеш предыдущей |
ID отправителя |
ID получателя |
Перевод | Баланс | Подтверждение | Контрольная сумма входящих |
Хеш предыдущей подтвержденной |
|---|---|---|---|---|---|---|---|
| Ba | IDa | IDc | Xa | Ya | NULL | Ha | NULL |
| Bb | IDb | IDc | Xb | Yb | NULL | Hb | NULL |
Баланс который находится на счете в момент завершения обработки исходящего перевода фиксируется в этом переводе (структуре данных включенной в цепочку). Все последующие входящие переводы в этом значении никак в «сцепленный» перевод не заносятся и существуют только как исходящие переводы на цепочках счетов отправителей.
Подтверждения обработки – поле, в котором отмечается, были ли использованы средства этой транзакции, то есть если когда A и B переводят C, то в этих переводах это значение выставлено в NULL, а после того, когда С переведет D, то это значение для A и B будет изменено на хеш транзакции в рамках которой эти средства принимали участие( С =>D).
В поле «Хеш предыдущей подтвержденной» будет соответственно для каждой цепочки A и B занесен хеш от предыдущей подтвержденной транзакции в этих цепочках, в которой поле «подтверждение обработки» не нулевое. (зачем это описано далее)
Баланс в C=>D рассчитывается следующими шагами:
- SELECT `Перевод` FROM transactions WHERE `ID получателя` = IDc AND `подтверждение обработки` = NULL; Таким образом мы получаем сумму всех входящих средств, которые были переведены за период времени с предыдущего исходящего перевода с IDc.
- Считаем общий баланс, сложив полученное в п.1 значение со значением баланса записанном в последнем переводе IDc.
- Проверяем целостность цепочек отправителей и соответствует ли запрашиваемый перевод всем необходимым условиям, как минимум, тому что результат не отрицательный. Вычитаем перевод из полученной в п.2 суммы.
- Если все ок, то пишем в таблицу еще один перевод, а всем найденным в п.1 выставляем хеш этого перевода в поле подтверждение обработки" и «хеш предыдущей подтвержденной». Yc – баланс IDc сразу после проведения этого перевода.
Такой алгоритм позволяет однозначно фиксировать баланс при переводах выполняемых на узле локально, одновременно получая данные, которые позволяют безопасно совершить следующий перевод на распределенной системе.
Когда речь идет о распределенной системе, то возможна ситуация, когда данные о входящих переводах, на узле на котором будет выполняться следующий перевод, будут неконсистентны с данными с узла, где выполнялся предыдущий перевод: поле «подтверждение обработки» будет еще выставлено в NULL для переводов, которые использовались для расчета баланса в предыдущем переводе, в итоге эти переводы могут быть зачислены еще раз, чего допускать нельзя.
Чтоб обнаруживать такие состояния используется поле «контрольная сумма входящих», в котором сохраняется хеш от хешей всех входящих переводов, которые использовались в рамках процессинга исходящего.
Используя это значение, перед обработкой нового перевода N, можно проверить консистентность входящих переводов для перевода N-1, собрав их (по значению из поля `подтверждение обработки` ), посчитав от них хеш HASH(CONCAT(INCOME_BLOCKS)) и сравнив его с хешом в поле `Контрольная сумма входящих` в переводе N-1. В случае несовпадения, запрос на перевод отклонить.
Поскольку описанным способом проверяется консистентность последних входящих переводов, есть вероятность, что из-за ошибочного (или умышленного) обнуления поля подтверждения в какой-нибудь старом входящем переводе, который использовалась для расчета баланса когда-то в прошлом, это старый входящий перевод, при обработки нового перевода, может быть посчитан получателем еще раз, чего допускать нельзя.
Чтоб не допустить такой ситуации используется поле «хеш предыдущей подтвержденной», куда выставляется хеш предыдущего перевода с ненулевым подтверждением, рассчитанный с использованием значения из этого поля («хеш предыдущей подтвержденной»), таким образом мы создаем в цепочке отправителя двойную связность по состояниям: по факту перевода и факту получения, т.е. использования со стороны получателя. И если из-за обнуления(что разрушит одну из связей) подтверждения этот перевод «всплывет» при расчете входящих, то он будет отвергнут на этапе контроля целостности цепочки отправителя.
В итоге, окончательный перевод IDc => IDd будет выглядеть так:
| Хеш предыдущей |
ID отправителя |
ID получателя |
Перевод | Баланс | Подтверждение | Контрольная сумма входящих |
Хеш предыдущей подтвержденной |
|---|---|---|---|---|---|---|---|
| Ba | IDa | IDc | Xa | Ya | HASH(LAST_C_BLOCK) | Ha | HASH(LAST_CONFIRMD_A_BLOCK) |
| Bb | IDb | IDc | Xb | Yb | HASH(LAST_C_BLOCK) | Hb | HASH(LAST_CONFIRMD_A_BLOCK) |
| Bc | IDc | IDd | Xc | Yc | NULL | HASH(CONCAT(INCOME_BLOCKS)) | NULL |
Про распределение нагрузки
Если для маршрутизации в качестве хеш-функции будет использоваться криптографическая, то есть та которая обладает свойством равномерного распределения значений, то все запросы на транзакцию с разных счетов будут распределяться равномерно по всем узлам, где будут обрабатываться независимо друг от друга, т.е. нагрузка будет распределяться равномерно.
Отказоустойчивость
Потеря одного узла в сети приведет к тому, что система не сможет обрабатывать только транзакции наведенные на этот узел. Эта проблема может быть решена созданием standby копии для каждого узла в простом случае или динамическим перераспределением пространства имен между оставшимися узлами (что нужно делать ОЧЕНЬ осторожно).
Заключение
Не смотря на всю сложность изложения, надеюсь я смог донести принципиальные различия с традиционными системами. Если Вы нашли в себе силы дочитать до этих строк то, наверное, в ожидании ссылки на гитхаб, где уже будет собранный концепт? К сожалению, какого-либо практического PoC пока нет, однако, публикация этой статьи, это попытка незамыленным взглядом собрать подводные камни, которые я мог упустить. И стать еще на шаг ближе к практической реализации, так что все замечания, конструктивная критика, возможные косяки are very welcome!
Использованная литература
Комментарии (18)

shai_xylyd
01.07.2015 11:26+1Как ведет себя система при split brain и падениях отдельных узлов?

sandman Автор
01.07.2015 11:39Транзакции, которые маршрутизируются на упавшие узлы дропаются. (хотя возможны варианты)
Сплитбрейн в привычном смысле здесь не особо возможен, но если имеется ввиду форк цепочки, то чтоб это произошло нужно начать переназначать DHT диапазоны, но «само» это случиться не может. Но если даже и случится, то по цепочкам можно проследить когда это случилось и какие транзакции в таком состоянии были проведены. Транзакций таких вряд ли будет много, так как из-за неконсистентности цепочек проводка встанет и все.

dinikin
01.07.2015 12:44Здесь на помощь может придти занятная особенность условия работы процессинга. Транзакции, на списание средств производятся в нем, в 95-99% случаев живыми людьми, которым моментальная готовность системы к следующей транзакции не особо нужна (10-60с).
А как насчет транзакций на зачисление средств, по ним отдельную систему делать?sandman Автор
01.07.2015 14:36Не уверен, что правильно понял суть вопроса, можно пожалуйста чуть подробней?
dinikin
01.07.2015 16:39Например, возьмем случай интернет-эквайринга, когда подключенный к банку интернет-магазин имеет в нем один счет, на который поступает довольно большое количество платежей, для которых задержка 10-60 сек критична? Например счёт какого нибудь мобильного оператора или популярной онлайн-игры.
sandman Автор
01.07.2015 19:0310-60 секунд это время репликации всей процессинговой сети, т.е. зависит от сети между узлами.
по поводу входящих средств, они «болтаются» как отправленные, и время их попадания на все узлы(когда они могут быть задействованы в транзакциях) зависит от времени репликации в сети.
то есть практически, если мы хотим со счета с большим количеством входящих(на этот счет) транзакций перевести средства, то мы имеем достаточно информации, чтоб определить на каком узле будет такая транзакация проведена. Соответственно, можем отправить туда запрос о том, сколько в конкретный момент средств доступно (сколько входящих транзакций среплицировалось на этот узел), и оценивать текущий баланс счета-источника (на который входящие средства перечисляются).

bigwizard
01.07.2015 18:05А как насчет транзакций на зачисление средств, по ним отдельную систему делать?
Нет, не надо. Начисления делаются в бэке, там нет таких требований на ответ.
bigwizard
01.07.2015 18:48Но от процессинга требуется способность максимально быстро проводить транзакции, так как основной его пользователь не Alice которая отправила Bob 10 рублей, а онлайн магазины с тысячами и десятками тысяч клиентов, которые при падении конверсии, из-за аварий или тормозов, без раздумий уйдут к конкурентами. (Собственно это, по-видимому, основная причина, почему частные процессинги не может сожрать биткойн).
ИМХО, обоснование для статьи слабовато.
Что понимается под термином «процессинг» в контексте интернет-магазина?
И как это связано с балансом клиента?
sandman Автор
01.07.2015 19:05например, есть некий qiwipaypalwebmoney, в котором есть счета у магазина и у клиента, и клиент делает перевод магазину.
bigwizard
02.07.2015 20:13Как писал выше, не делается перевод со счета на счет в одной БД транзакции.
Заблокировали сумму на счету клиента. Добавили сообщение о начислении магазину. — одна системная транзакция
Выбрали сообщение. Сделали фин. обработку. Зачислили деньги магазину — вторая системная транзакция.
Фин. обработки могут быть достаточно сложными, например, комиссия для магазина может уменьшаться после некоторого объема переводов.
sandman Автор
03.07.2015 03:59Если относительно логики транзакции, то можно разные вещи реализовать на шаге зачисления.
В описываемой системе, входящие средства на счет магазина существуют только как исходящие транзакции со счетов клиентов, (т.е информация он них есть, их всегда можно посчитать и по ним какую-то аналитику провести).
А технически они прописываются в баланс магазина ( в последнюю транзакцию цепочки магазина), когда магазин создает исходящую транзакцию на вывод, и вот тогда все финконтроли и комиссии и могут быть проведены, что замечательно, отдельно от процесса покупки.
Или может я не понимаю деталей и нужна синхронная финобработка в момент оплаты?
touzoku
Вопросы:
Чем принципиально такой вид load balancing-а отличается от обычного применения affinity (sticky sessions) на load balancer-ах?
При условии, что все транзакции одного и того же клиента попадают на один и тот же хост, то блокчейны по сути тут излишни — один нод сам отлично умеет контролировать целостность redo log. Непонятна польза блокчейнов при репликации — что мешает делать two-way acknowledgement между нодами?..
Не особо понятно откуда нод понимает, что у него устарела версия цепочки. Из чего «из этого» следует?
sandman Автор
>все транзакции одного и того же клиента попадают на один и тот же хост,
>При условии, что все транзакции одного и того же клиента попадают на один и тот же хост,
Нет. Узел, который будет обрабатывать транзакцию индивидуален для каждой отдельной транзакции, так как рассчитывается от хеша каждой предыдущей обработанной транзакции. (если узлов не много, то возможны частные случаи когда это будет один и тот же узел, то только из-за того, что хеши предыдущей транзакции и предпредыдущей будут находиться в DHT диапазоне этого узла)
>Чем принципиально такой вид load balancing-а отличается от обычного применения affinity (sticky sessions) на load balancer-ах
мне трудно ответить на этот вопрос, так как я общего не вижу. Можете по пунктам перечислить, если не сложно?
>Не особо понятно откуда нод понимает, что у него устарела версия цепочки. Из чего «из этого» следует
из того, что хеш последней обработанной транзакции на узле, который отправил в сеть запрос не транзакцию (этот хеш в запросе) отсутствует на узле-получателе, который должен транзакцию обработать.
bigwizard
Почему просто не балансировать нагрузку через шардирование (платежная система, БИНы карты и т.п.)?
sandman Автор
а как шардирование поможет балансировать нагрузку?
поток транзакций не равномерно между счетами же делится, какие-то более активные, какие-то менее, соответственно какие-то шарды будут больше нагружены, а какие-то меньше. это, конечно, лучше чем ничего, но на балансировку не тянет, как минимум из-за отсутствия возможности управлять распределением нагрузки.
bigwizard
нет потока со счета на счет во фронтальной системе финансового процессинга.
ИМХО, вы слабо представляете как устроен финансовый процессинг. Ну нельзя переводить деньги со счета на счет в одной БД транзакции, т.к. счет становиться узким местом.
Выделили атрибуты для шардирования и распределили нагрузку на узлы.
sandman Автор
>ИМХО, вы слабо представляете как устроен финансовый процессинг. Ну нельзя переводить деньги со счета на счет в одной БД транзакции, т.к. счет становиться узким местом.
пожалуйста расскажите почему и как с этим бороться?
Что в данном случае «атрибут шардирования», не могу нагуглить вменяемого определения?