

Предлагаю зайти к нам в гости и посмотреть как с проблемой синхронизации внутри себя борется команда “Онлайн-ипотеки” компании “Альфа-Банк”.
Статья была подготовлена членами нашей команды: Марина, Дима, Настя, Вероника, Толя.
Не так давно (чуть более полугода назад) в Альфа-Банке стартовал новый проект — «Онлайн-Ипотека». Команда под проект собиралась с нуля. Люди на проект пришли разные и с разных мест работы. Все было прямо по гайду: DevTeam (JS, Java, QA, Аналитик), скрам-мастер и Product Owner. Никто из девтим до этого никогда не работал по скрам-фреймворку.
Первая точка синхронизации: DOR
Итак, мы все собрались, познакомились и почти сразу приступили к делу. Впереди нас ждало множество неочевидных (на первый взгляд) идей. Большинство из них впоследствии стали обыденными и логичными. Но вот что мы долгое время не могли побороть — это мнимая понятность задач. Часто бывает так, что берешь задачу в спринт, а она оказывается не так проста (а иногда и сложна), как казалось на первый взгляд.
Рассинхрон для нас заключался в следующем:
- разные миры, в которых живет бизнес и девтим,
- разная степень готовности user story к тестированию,
- разное понимание завершенности задачи.
Решение пришло как-то само собой. Мы взяли стандартный инструмент и решили опробовать его в деле. DOR (Definition Of Ready) позволяет снизить степень неопределенности в задаче и согласовать действия PO (Product Owner) и девтим до начала работы над задачей. С помощью такого подхода мы всегда можем более или менее четко определить степень неизвестности, с которой столкнемся в ходе разработки, и учесть ее в оценке трудоемкости.
Опыт оказался крайне успешен. Мы стали действовать более слаженно и более продуктивно. На грумингах мы держали DOR перед глазами и использовали как чек-лист при разборе задачи. PO почти всегда узнавал заранее, чего не хватает задаче, и старался как можно скорее уточнить информацию. Иначе такая задача просто не попадала в следующий спринт.
Нам приходилось брать спайки (исследования) из верхних задач в общем бэклоге (backlog) в спринт, но это приносило колоссальный результат. Неопределенность снижалась, и мы начали корректно оценивать трудоемкость задачи.
Тут стоит отметить, что DOR у каждой команды должен быть свой. Дело в том, что он не должен представлять собой набор четких указаний от работодателя. Это скорее требования команды к минимальному описанию задачи и проработке подводных камней, которые должны быть выполнены для удобства и ускорения работы.
- Четкая постановка «Что?» — от PO (минимум за неделю до начала спринта)
- Верхнеуровневое описание логики задачи «Как?» — от DevTeam (до начала спринта)
- Готовый дизайн (если он необходим): т.е. утвержденный текст и дизайн.
- После начала спринта условия задачи не меняются.
- Описание минимальных требований в jira аналитиком происходит до начала работы разработчиков (в самом начале спринта)
- Задача прогрумлена и имеет оценку
Вторая точка синхронизации: DOD
Очень хорошо, когда вся команда понимает, какие задачи мы можем помещать в спринт, а какие лучше не стоит. После выполнения условий DOR мы столкнулись со следующим: мы берем задачу (user story) в работу, но как мы можем понять, что она точно готова?
Конечно, мы можем посмотреть на все саб-таски (sub task) и оценить готовность задач по ним. Но что, если мы не завели саб-таску по документации, тестированию или настройке доступов? Есть ли необходимость каждый раз заводить подобные саб-таски?
Ну хорошо. Допустим, мы идеально заводим саб-таски и идеально вовремя их закрываем. Тогда логично было бы закрыть задачу сразу после мерджа в мастер. Но ведь задача еще не на бою! Пользователь не увидит пользы от нашей работы, и все было зря.
Первое время мы спорили о факте закрытой задачи. После чего мы приняли какие-то не совсем формальные правила. Это сильно упростило работу, но время от времени все же конфликты возникали. Тогда мы пришли к следующему стандартному шагу синхронизации.
DOD (Definition Of Done) позволяет решить проблему приемки и общего понимания готовой задачи. DOD очень похож на DOR. Это такой же набор критериев, но на этот раз для готовой задачи. Взглянув на него, мы всегда можем сказать: готова задача или нет.

В результате мы выработали общее понимание того, что надо сделать, чтобы считать задачу закрытой. Только после выполнения всех пунктов задача переходит в DONE.
Подводим итоги первых двух шагов синхронизации
Отлично! Работать стало гораздо удобнее. Мы больше не тратим время на ненужные формальности о разговорах, какая задача готова, а какую стоит еще доработать. С другой стороны, мы больше не боимся брать задачи в спринт. Но что происходит между этими событиями? Раздор, разруха и хаос.
Аналитик не всегда может изначально проверить все задачи в спринте. Один из разработчиков может сделать изменения (без возможности откатиться), которые коснутся другого разработчика. В конце концов, PO тоже люди, и задачи могут меняться в ходе спринта, даже если это сильно не приветствуется в скраме.
На самом деле есть целая масса случаев, которые могут привести к конфликтам и непродуктивной работе между этапами взятия в работу и завершения задачи (для краткости — DOR и DOD). В любой команде почти всегда можно видеть одну и ту же проблему. Кто-то что-то куда-то залил, и второй разработчик теперь страдает. Это провоцирует конфликты и негатив. И, конечно, эта проблема почти всегда возникает, когда одной задачей занимаются несколько разработчиков.
Вначале мы пытались найти что-то из уже существующего вроде DOR и DOD. К сожалению, ничего подобного и подходящего к нам мы не нашли (может быть, плохо искали). Пробовали 1 work in progress, но опыт не удался. Каждая задача состоит из разнородных частей. Наш опыт показал, что при таком подходе кто-то из разработчиков всегда скучает, а кто-то вынужден задерживаться на работе и доделывать свою “половинку”. Не так давно мы собрались и подумали над еще одним промежуточный этапом:

Третья точка синхронизации — наша собственная задумка: DOT
DOT (Definition Of Test) представляет собой набор критериев тестирования задачи и сборки ее в единое целое на тестовом стенде. Также мы устанавливаем правила о том, что девтим не может приступать к дальнейшим действиям (pull requests и тд), пока DOT не будет выполнен полностью.
Взглянем на рисунок и попробуем разобрать идею более подробно. Для начала представим, что у нас имеется только один разработчик на одну задачу:
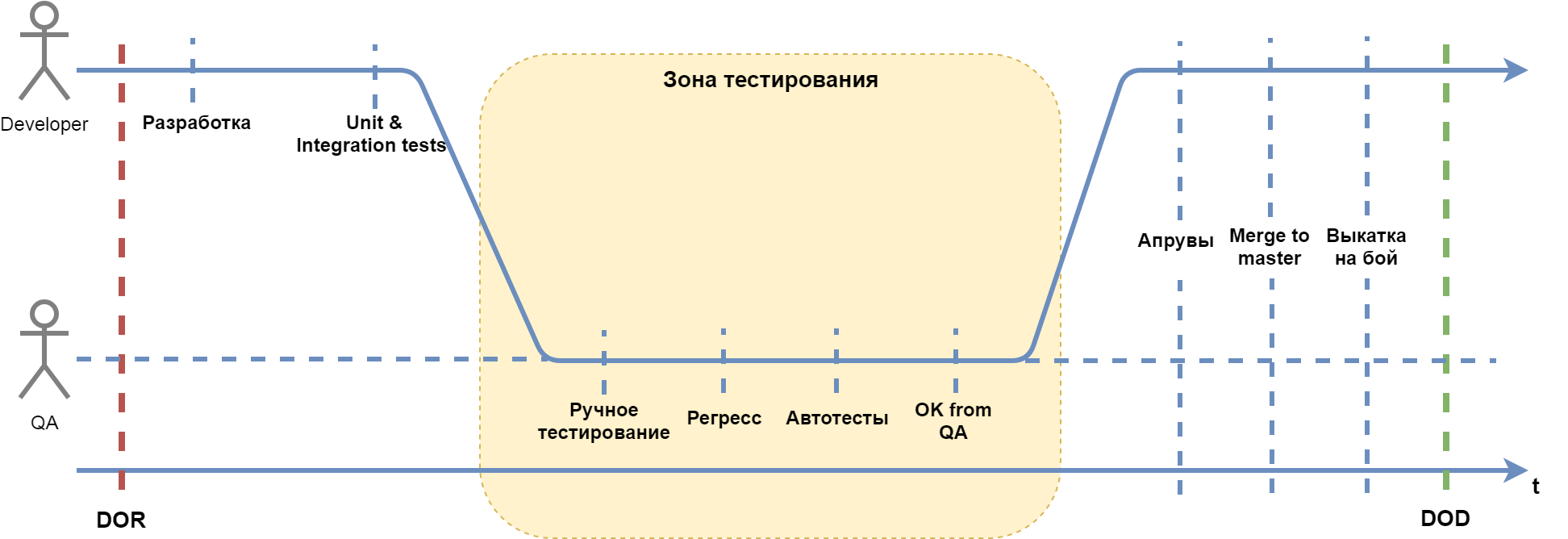
Сразу отметим здесь ключевую особенность. У нас есть то, что должно быть сделано, и то, что делать нельзя до выхода из зоны тестирования. Сюда можно отнести прохождение pull request, мердж в мастер, выкатку и прочее.
Сразу стоит отметить отличие от DOR и DOD. Когда мы говорим про DOR, мы говорим о том, что нужно для решения задачи. При разговоре о DOD, мы говорим какую задачу можно считать сделанной. В DOT на нас влияют сразу несколько видов обстоятельств. С одной стороны, разработка задачи должна быть завершена. С другой, многие действия для доведения задачи в полностью готовый вид делать не стоит.
По-настоящему раскрывает себя идея в случае нескольких разработчиков с одной задачей. Посмотрим на такой случай. В нашем примере у нас будут фронт и бэк:
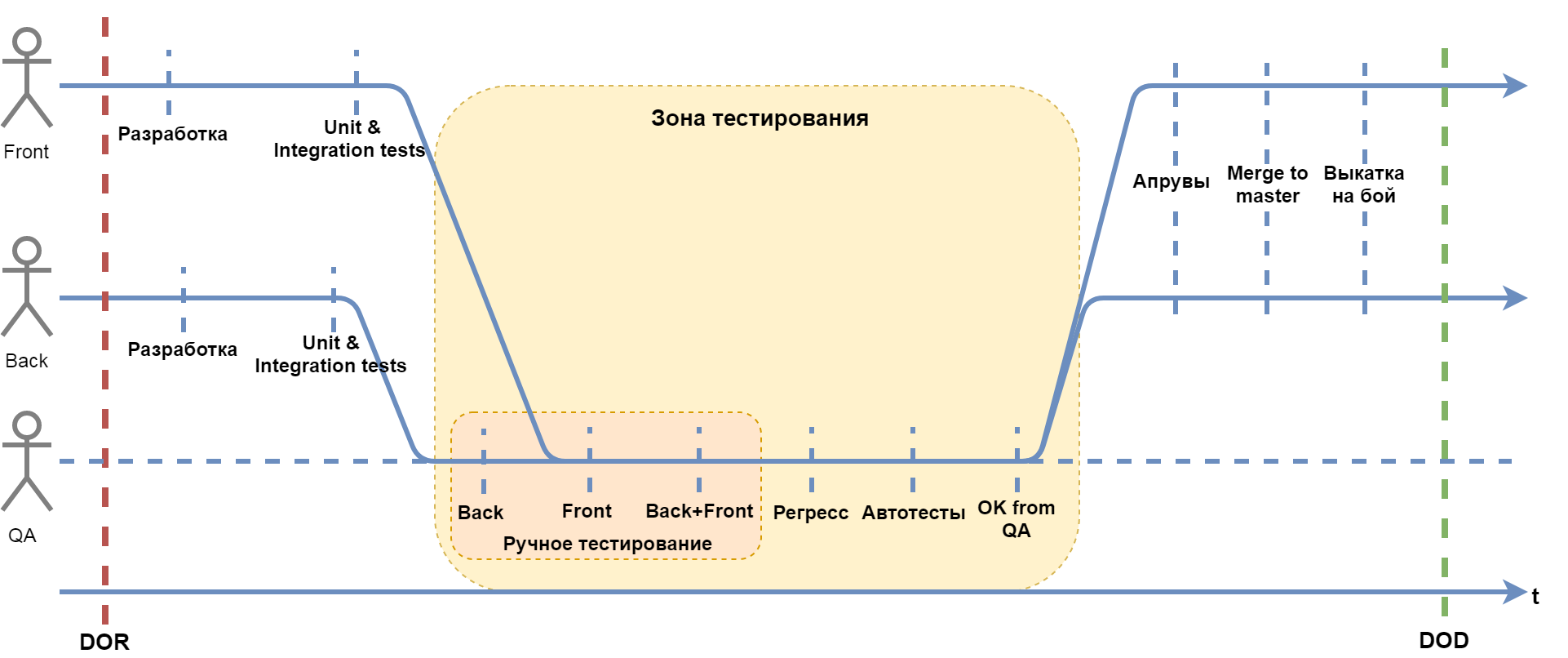
Схема очень примерная. Понятно, что у нас один специалист может помогать (или мешать) другому. Необходимость доработать задачу может всплыть раньше. А выкаткой на бой может заниматься другой человек. Главное тут другое. У нас есть некая область с четко оговоренными ДО и ПОСЛЕ. Более того, ПОСЛЕ не может наступить, пока не будут выполнены все условия DOT. И только после этого можно получить ОК от тестирования.
Что еще тут важно? Как видно из картинки, разработка может начинаться в разное время. Самое главное тут то, что в область тестирования входят несколько разработчиков в разное время, но выйти из нее они могут только вместе. Чем они будут заняты в это время — можно договориться.
После того как задача полностью протестирована, все разработчики получают волшебный ОК от тестирования, и теперь уже стартуют из одной точки. Интересно, что здесь крайне мала вероятность каких-то недочетов в синхронизации. Оставшиеся действия занимают примерно одинаковое время.
Потребностью DOT является необходимость жесткой синхронизации разработчиков между собой. В одну область входят несколько разработчиков в разное время, но выходят всегда в единой точке.
Минусом такого подхода является дополнительное время на продумывание организации задач на этапе формирования. Но на самом деле такие затраты легко окупаются. При этом, задачи становятся более структурированными и прогнозируемыми.

Заключение
Конечно, DOT — это не новый мир. Это просто то, как мы видим синхронизацию в нашей команде. Насколько данная практика хороша и к чему приведет — пока рано говорить. Мы понимаем, что у каждой компании и даже команды в компании, разный рабочий процесс и не всем это подойдет. Мы верим в итеративный подход и улучшение на основе опыта. Попробуем; получим результат; решим, что делать дальше. Тем не менее, мне кажется, что это интересный опыт. В ближайшем будущем мы обязательно поделимся с вами результатами нашего эксперимента. Спасибо за внимание!
Комментарии (12)

voicetranslator
22.05.2018 17:51девтим не может приступать к дальнейшим действиям (pull requests и тд), пока DOT не будет выполнен полностью
Чем они будут заняты в это время — можно договориться
А можно и не договориться? Ваш srum напоминает мне чем-то странную смесь srum-а и сломанного waterfall-а.
А проблемы с синхронизацией у вас, похоже, из-за неверного планирования спринтов.faoxy Автор
22.05.2018 17:54+1Waterfall не вытекает за одну сторю. А идеального планирования, к сожалению, не бывает. Иначе не было бы так много различных подходов к работе.
belchona
22.05.2018 18:37+2У нас появились правила по шагам тестирования и докатке задачи до боя. И это правда похоже на вотерфол, никто не спорит!) Но только в рамках одной маленькой стори.
А вот с неверным планированием готова подискутировать. Не получится так, что все идеально одинаково заняты над одной задачей, и дружно ровно переключаются на другую.
Если получится — приглашай в гости, я так точно готова поучиться у вас)voicetranslator
23.05.2018 00:27Что значит «идеально заняты над одной задачей»? Зачем у вас все занимаются одной задачей-то? Продукт может быть один (а может и не один), проектов множество, и у каждого проекта свое множество задач (aka user stories). На этапе планирования спринта, архитектор (которого, по старинке, можно было-бы, в нашем конкретном случае, назвать еще и тим лидом) планирует и разбрасывает по команде истории так, чтобы обеспечить:
— наиболее полную загрузку народа (чтобы увеличить velocity)
— с другой стороны, выбираются истории — если, конечно, есть выбор — так, чтобы не тормозить друг друга. Например, реализуется новая фича, зависящая и от backend, и от контроллеров, и от frontend. Для текущего спринта можно реализовать либо сначала backend часть, а потом пилить контроллеры и front (да, фронтенд тоже может быть не один и очень разный), либо сначала контроллеры, за ними фронт, а бэкенд можно запилить и в следующем спринте — если фича не горящая. На каждом retrospective обсуждаем, где и в чем были задержки, смотрим статистику, улучшаем планирование.
При этом никто никогда никого не ждет.
Кстати, для этого в dev team полезно иметь full stack-ов, чем больше, тем лучше (если бабки позволяют). Всегда можно перебросить на «провисающую» story.
Если получится — приглашай в гости, я так точно готова поучиться у вас
Я бы с удовольствием пригласил, но, во-первых, немного далековато (у нас — это в Бостоне), во-вторых, я, к сожалению, эти вопросы не решаю.
P.S. Еще немного не понял сентенцию про pull request-ы — они ведь специально для того и были выдуманы (и спецом предназначены), чтобы не ждать, когда кто-то запилит свою часть. Вы там как, с git-ом — на короткой ноге, или в процессе освоения? ;)belchona
23.05.2018 00:47+1Уловила ваш подход)
Мы с вами с разными целями заполняем спринт. Цель нашего спринта — доставить ценность до прода. То есть фича должна быть готова полностью. И ни фронт, ни бэк, ни что-то ещё на другие спринты не съезжают.
И спринт планируется при этом таким образом, чтобы выполнить бизнес-цель. Равномерная загрузка разработчиков при этом достигается редко, и такое распределение, которое у вас делает архитектор/тимлид, у нас не практикуется.
Мы можем предлагать Продакту выбрать определенный набор фич, чтобы все компетенции успели выполнить задачи за спринт. То есть если фронт перегружен и точно не успеет сделать третью стори, то Продакту самому это не очень интересно.
Девтим может предложить взять третью строи поменьше, или добавить техтасок, если есть техдолг или задачи по девопсу.
Главная цель — полностью готовые фичи на проде.
А в Бостон было бы классно скататься, да...voicetranslator
23.05.2018 04:34Ну, цели-то у нас одинаковые — гибкая адаптивная разработка с целью наиболее быстрого и эффективного удовлетворения пользовательских запросов. И, естественно, целью каждого спринта является релиз. Но достоинство спринта именно в его гибкости; догм и ритуалов быть не должно — это свидетельствует о неправильном понимании методологии scrum. Описанных вами простоев «до готовности всех» в scrum быть просто не должно: ведь всегда есть бэклоги, которые нужно вырабатывать, добавляя velocity, и открывая дополнительные резервы времени на будущее.
Видимо, ваши проблемы происходят еще и от того, что у вас нет хорошего архитектора, и full stack devs.
А статистику скрама вы ведете? Что у вас с velocity и health? Правильная статистика в scrum — это must have, запросто вскрывает проблемы.
P.S. Да, забыл написать по поводу «фича должна быть готова полностью». Есть такой термин, MVP, вы с ним знакомы? Специально для таких случаев и придуман :Dbelchona
23.05.2018 06:28+1Простоев собственно и нет) Люди переключаются на другие задачи, пока фича полностью тестируется и готовится к релизу. Таким образом с velocity все в порядке.
MVP, разумеется, есть. Наши Продакты достаточно в теме) Разработка тоже знает что это, и помогает Продакту найти этот минимальный жизнеспособный продукт.
В целом, не вижу жестких противоречий скраму в нашем подходе. Сказать, что Фича не мерджится в мастер, пока не прошла функциональное тестирование — это скорее здравый смысл, нежели догма, по моему скромному мнению.
Однако спасибо за ваши мысли, очень интересно!voicetranslator
23.05.2018 07:01Простоев собственно и нет
Ну и чудесно! Значит, я вас неправильно понял, либо вы не совсем верно выразились в тексте статьиНаш опыт показал, что при таком подходе кто-то из разработчиков всегда скучает, а кто-то вынужден задерживаться на работе и доделывать свою “половинку”.
У нас таких проблем и обид не возникает, и никто не задерживается на работе больше, чем он хочет сам. Вот приведу «пример на пальцах»: делаем user story, в которую вовлечены почти все софтверные компоненты (а у нас scrum применяется еще не только для софта), я запилил, например, фронт по быстрому, а человек, у которого карта (мы пользуемся Trello) с беком/мидлом, не успевает (ну, мало ли что — заболел, куча интервью, форс-мажор). Ничего страшного — я перекинул на себя его карту (с частью user story — кстати, разбитие больших задач на мелкие подзадачи — очень важная часть правильного скрама) и запилил контроллер. Не успеваю сделать бэк (или там есть тонкости, которые я не знаю, а время тратить не охота) — воткнул стаб в контроллер и обозвал MVP. Счастливому кастомеру ушел новый релиз «на обкатку», в бэклог пошла новая story — все happy, включая скрам-мастера и PO :)
Притом, помимо user stories, у нас есть и house stories — над развитием продукта нужно думать (для чего важен хороший архитект). Вот сейчас, в бэкграунде, переезжаем потихоньку на serverless (рекомендую покопать, любопытная штука), попиливая потихоньку house stories в спринтах. И, глядишь, незаметно так и мигрируем себе ;)
В общем, скрам прикольная, забавная и полезная штука, главное — применять его гибко, с умом и без догматики.
annabella0131
23.05.2018 07:16Интересно, как на ваших схемах проседает QA. То есть в рамках одной задачи всё ок, но если задач несколько, то тогда упущены «входящие» для девов — реоупены. Прокомментируйте)
ladutsko
Наши наброски по DOD:
2. Протестировано на проде
4. Выложено на прод
как так то?
belchona
Это список всех критериев. Он не отсортирован по очередности выполнения. Набрасывали его в формате брейншторма, так и записали.