

Для начала попробуем определить, что означает написание кода в функциональном стиле. Во-первых, мы должны оперировать не переменными и манипуляциями с ними, а цепочками некоторых вычислений. По сути, последовательностью функций. Кроме того, у нас должны быть специальные структуры данных. Например, стандартные java коллекции не подходят. Скоро станет понятно почему.
Рассмотрим функциональные структуры более подробно. Любая такая структура должна удовлетворять как минимум двум условиям:
- immutable — структура должна быть неизменяемой. Это означает, что мы фиксируем состояние объекта на этапе создания и оставляем его таковым до конца его существования. Явный пример нарушения условия: стандартный ArrayList.
- persistent — структура должна храниться в памяти максимально долго. Если мы создали какой-то объект, то вместо создания нового с таким же состоянием, мы должны использовать готовый. Говоря более формально, такие структуры при модификации сохраняют все свои предыдущие состояния. Ссылки на эти состояния должны оставаться полностью работоспособными.
Очевидно, что нам нужно какое-то стороннее решение. И такое решение есть: библиотека Vavr. На сегодняшний день это самая популярная библиотека на Java для работы в функциональном стиле. Далее я опишу основные фишки библиотеки. Многие, но далеко не все, примеры и описания были взяты из официальной документации.
Основные структуры данных библиотеки vavr
Кортеж
Одной из самых базовых и простых функциональных структур данных являются кортежи. Кортеж — упорядоченный набор фиксированной длины. В отличие от списков, кортеж может содержать данные произвольного типа.
Tuple tuple = Tuple.of(1, "blablabla", .0, 42L); // (1, blablabla, 0.0, 42)Получение нужного элемента происходит из вызова поля с номером элемента в кортеже.
((Tuple4) tuple)._1 // 1Обратите внимание: индексация кортежей начинается с 1! Кроме того, для получения нужного элемента мы должны преобразовать наш объект к нужному типу с соответствующим набором методов. В примере выше мы использовали кортеж из 4 элементов, а значит преобразование должно быть в тип Tuple4. На самом деле, никто не мешает нам изначально сделать нужный тип.
Tuple4 tuple = Tuple.of(1, "blablabla", .0, 42L); // (1, blablabla, 0.0, 42)
System.out.println(tuple._1); // 1Топ 3 коллекций vavr
Список
Создать список с vavr очень просто. Даже проще, чем без vavr.
List.of(1, 2, 3)Что мы можем сделать с таким списком? Ну во-первых, мы можем превратить его в стандартный java список.
final boolean containThree = List.of(1, 2, 3)
.asJava()
.stream()
.anyMatch(x -> x == 3);
Но на самом деле в этом нет большой необходимости, т.к. мы можем сделать, например, так:
final boolean containThree = List.of(1, 2, 3)
.find(x -> x == 1)
.isDefined();Вообще, у стандартного списка библиотеки vavr имеется множество полезных методов. Например, есть довольно мощная функция свертки, которая позволяет объединять список значений по некоторому правилу и нейтральному элементу.
// рассчет суммы
final int zero = 0; // нейтральный элемент
final BiFunction<Integer, Integer, Integer> combine
= (x, y) -> x + y; // функция объединения
final int sum = List.of(1, 2, 3)
.fold(zero, combine); // вызываем сверткуЗдесь следует отметить один важный момент. У нас имеются функциональные структуры данных, а это значит, что мы не можем менять их состояние. Как реализован наш список? Массивы нам точно не подходят.
Linked List в качестве списка по умолчанию
Сделаем односвязный список с неизмеяемыми объектами. Получится примерно так:

List list = List.of(1, 2, 3);У каждого элемента списка есть два основных метода: получение головного элемента (head) и всех остальных (tail).
list.head(); // 1
list.tail(); // List(2, 3)Теперь, если мы хотим поменять первый элемент в списке (с 1 на 0), то нам надо создать новый список с переиспользованием уже готовых частей.
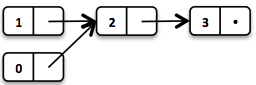
final List tailList = list.tail(); // получаем хвост списка
tailList.prepend(0); // добавляем элемент в начало спискаИ все! Так как наши объекты в листе неизменны, мы получаем потокобезопасную и переиспользуемую коллекцию. Элементы нашего списка могут быть применены в любом месте приложения и это совершенно безопасно!
Очередь
Еще одной крайне полезной структурой данных является очередь. Как сделать очередь для построения эффективных и надежных программ в функциональном стиле? Например, мы можем взять уже известные нам структуры данных: два списка и кортеж.
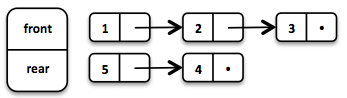
Queue<Integer> queue = Queue.of(1, 2, 3)
.enqueue(4)
.enqueue(5);Когда первый заканчивается, мы разворачиваем второй и используем его для чтения.
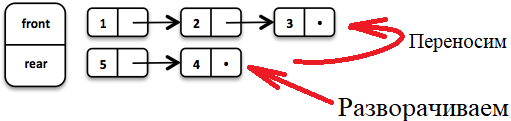
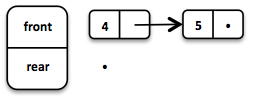
Важно помнить, что очередь должна быть неизменной, как и все остальные структуры. Но какая польза от очереди, которая не меняется? На самом деле, есть хитрость. В качестве принимаемого значения очереди мы получаем кортеж из двух элементов. Первый: нужный элемент очереди, второй: то, что что стало с очередью без этого элемента.
System.out.println(queue); // Queue(1, 2, 3, 4, 5)
Tuple2<Integer, Queue<Integer>> tuple2 = queue.dequeue();
System.out.println(tuple2._1); // 1
System.out.println(tuple2._2); // Queue(2, 3, 4, 5)Стримы
Следующая важная структура данных — это стрим. Стрим представляет собой поток выполнения некоторых действий над некоторым, часто абстрактным, набором значений.
Кто-то может сказать, что в Java 8 уже есть полноценные стримы и новые нам совсем не нужны. Так ли это?
Для начала, давайте убедимся, что java stream — не функциональная структура данных. Проверим структуру на изменяемость. Для этого создадим такой небольшой стрим:
IntStream standardStream = IntStream.range(1, 10);Сделаем перебор всех элементов в стриме:
standardStream.forEach(System.out::print);В ответ получаем вывод в консоль: 123456789. Давайте повторим операцию перебора:
standardStream.forEach(System.out::print);Упс, произошла такая ошибка:
java.lang.IllegalStateException: stream has already been operated upon or closed
Дело в том, что стандартные стримы — это просто некоторая абстракция над итератором. Хоть стримы внешне и кажутся крайне независимыми и мощными, но минусы итераторов никуда не делись.
Например, в определении стрима ничего не сказано про ограничение количества элементов. К сожалению, в итераторе оно есть, а значит есть и в стандартных стримах. Мы не можем создавать бесконечные структуры.
К счастью, библиотека vavr решает эти проблемы. Убедимся в этом:
Stream stream = Stream.range(1, 10);
stream.forEach(System.out::print);
stream.forEach(System.out::print);В ответ получаем 123456789123456789. Что означает первая операция не “испортила” наш стрим.
Попробуем теперь создать бесконечный стрим:
Stream infiniteStream = Stream.from(1);
System.out.println(infiniteStream); // Stream(1, ?)
Обратите внимание: при печати объекта мы получаем не бесконечную структуру, а первый элемент и знак вопроса. Дело в том, что каждый последующий элемент в стриме генерируется налету. Такой подход называется ленивой инициализацией. Именно он и позволяет безопасно работать с таким структурами.
Если вы никогда не работали с бесконечными структурами данных, то скорее всего вы думаете: зачем вообще это надо? Но они могут быть крайне удобны. Напишем стрим, который возвращает произвольное количество нечетных чисел, преобразовывает их в строку и добавляет пробел:
Stream oddNumbers = Stream
.from(1, 2) // от 1 с шагом 2
.map(x -> x + " "); // форматирование
// пример использования
oddNumbers.take(5)
.forEach(System.out::print); // 1 3 5 7 9
oddNumbers.take(10)
.forEach(System.out::print); // 1 3 5 7 9 11 13 15 17 19Вот так просто.
Общая структура коллекций
После того как мы обсудили основные структуры, пришло время посмотреть на общую архитектуру функциональных коллекций vavr:
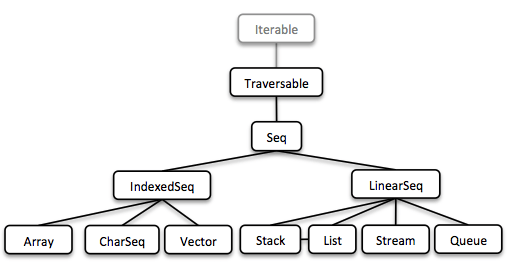
Каждый элемент структуры может быть использован как итерируемый:
StringBuilder builder = new StringBuilder();
for (String word : List.of("one", "two", "tree")) {
if (builder.length() > 0) {
builder.append(", ");
}
builder.append(word);
}
System.out.println(builder.toString()); // one, two, treeНо стоит дважды подумать и посмотреть доку перед использованием for. Библиотека позволяет делать привычные вещи проще.
System.out.println(List.of("one", "two", "tree").mkString(", ")); // one, two, treeРабота с функциями
Библиотека имеет ряд функций (8 штук) и полезные методы работы с ними. Они представляют собой обычные функциональные интерфейсы с множеством интересных методов. Название функций зависит от количества принимаемых аргументов (от 0 до 8). Например, Function0 не принимает аргументов, Function1 принимает один аргумент, Function2 принимает два и т.д.
Function2<String, String, String> combineName =
(lastName, firstName) -> firstName + " " + lastName;
System.out.println(combineName.apply("Griffin", "Peter")); // Peter GriffinВ функциях библиотеки vavr мы можем делать очень много крутых вещей. По функционалу они уходят далеко вперед от стандартных нам Function, BiFunction и т.д. Например, каррирование. Каррирование — это построение функций по частям. Посмотрим на примере:
// Создаем базовую функцию
Function2<String, String, String> combineName =
(lastName, firstName) -> firstName + " " + lastName;
// На основе базовой строим новую функцию с одним переданным элементом
Function1<String, String> makeGriffinName = combineName
.curried()
.apply("Griffin");
// Работаем как с полноценной функцией
System.out.println(makeGriffinName.apply("Peter")); // Peter Griffin
System.out.println(makeGriffinName.apply("Lois")); // Lois GriffinКак вы видите, достаточно лаконично. Метод curried устроен крайне просто, но может принести огромную пользу.
@Override
default Function1<T1, Function1<T2, R>> curried() {
return t1 -> t2 -> apply(t1, t2);
}
В наборе Function есть еще множество полезных методов. Например, можно кэшировать возвращаемый результат функции:
Function0<Double> hashCache =
Function0.of(Math::random).memoized();
double randomValue1 = hashCache.apply();
double randomValue2 = hashCache.apply();
System.out.println(randomValue1 == randomValue2); // trueБорьба с исключениями
Как мы говорили ранее, процесс программирования должен быть безопасным. Для этого необходимо избегать различных посторонних эффектов. Исключения (exceptions) являются явными их генераторами.
Для безопасной обработки исключений в функциональном стиле можно использовать класс Try. На самом деле, это типичная монада. Углубляться в теорию для использования вовсе не обязательно. Достаточно посмотреть простой пример:
Try.of(() -> 4 / 0)
.onFailure(System.out::println)
.onSuccess(System.out::println);Как видно из примера все достаточно просто. Мы просто вешаем событие на потенциальную ошибку и не выносим ее за пределы вычислений.
Pattern matching
Часто возникает ситуация, в которой нам необходимо проверять значение переменной и моделировать поведение программы в зависимости от результата. Как раз в таких ситуациях на помощь приходит замечательный механизм поиска по шаблону. Больше не надо писать кучу if else, достаточно настроить всю логику в одном месте.
import static io.vavr.API.*;
import static io.vavr.Predicates.*;
public class PatternMatchingDemo {
public static void main(String[] args) {
String s = Match(1993).of(
Case($(42), () -> "one"),
Case($(anyOf(isIn(1990, 1991, 1992), is(1993))), "two"),
Case($(), "?")
);
System.out.println(s); // two
}
}Обратите внимание, Case написано с большой буквы, т.к. case является ключевым словом и уже занято.
Вывод
На мой взгляд библиотека очень крутая, но стоит применять ее крайне аккуратно. Она может отлично проявить себя в event-driven разработке. Однако, чрезмерное и бездумное ее использование в стандартном императивном программировании, основанном на пуле потоков, может принести много головной боли. Кроме того, часто в наших проектах используются Spring и Hibernate, которые не всегда готовы к подобному применению. Перед импортом библиотеки в свой проект необходимо четкое понимание, как и зачем она будет использована. О чем я и расскажу в одной из своих следующих статей.
Комментарии (12)

zakgof
02.10.2018 10:29Это большой шаг для языка, но этого все еще мало
можно ли обосновать, для чего конкретно мало, и как vavr это решает?
persistent — структура должна храниться в памяти максимально долго
это весьма странное утверждение, совсем далекое от правильного определения persistent структуры («структуры, которые при модификации сохраняют все свои предыдущие состояния и ссылки на них эти состояния будут оставаться полностью работоспособными» или как-то так)faoxy Автор
02.10.2018 10:35Спасибо!
можно ли обосновать, для чего конкретно мало, и как vavr это решает?
Действительно стоило пояснить. Мало для написания программ в функциональном стиле. Далее разбирается почему (например, базовые структуры для этого непригодны).
это весьма странное утверждение, совсем далекое от правильного определения persistent структуры («структуры, которые при модификации сохраняют все свои предыдущие состояния и ссылки на них эти состояния будут оставаться полностью работоспособными» или как-то так)
Здесь я попытался по-простому написать то, что вы описываете. Но я согласен, что ваше опеределение более формально и, скорее всего, подходит лучше. Поменяю. :)
vba
02.10.2018 11:24На мой взгляд библиотека очень крутая, но стоит применять ее крайне аккуратно. Она может отлично проявить себя в event-driven разработке. Однако, чрезмерное и бездумное ее использование в стандартном императивном программировании, основанном на пуле потоков, может принести много головной боли.
Тут как бы не очень ясно что автор имел ввиду. Нет задач из императивного программирования с которыми ФП не справилось бы. Сказать можно больше, ФП справляется с такими задачи намного лучше императивного подхода. ФП идеально подходит для любой задачи, итеративный подход почти везде это грабли.
Что действительно может выстрелить в ногу так это смесь
дикобраза с китомдвух под подходов. Например hibernate и vavr, выкиньте первый и используйте второй для написания более функциональной обертки over JDBC без сайд эффектов и будет вам счастье.rkfg
02.10.2018 12:25Сказать можно больше, ФП справляется с такими задачи намного лучше императивного подхода. ФП идеально подходит для любой задачи, итеративный подход почти везде это грабли.
Я бы не стал так идеализировать. ФП такой же подход к решению задач, как и любой другой, со своими плюсами и минусами. Из описанных свойств персистентности следует повышенная нагрузка на GC, например, при итерации по очереди будут создаваться и практически сразу удаляться временные объекты Tuple/Queue, тогда как при обычном for будет меняться лишь одна переменная-указатель (или индекс). Я не вижу, почему первый вариант будет производительнее второго и уж тем более читабельнее.
Безусловно, для параллельных вычислений функциональная чистота полезна, такой код писать и поддерживать будет скорее всего проще, чем императивный, и это будет важнее потерь производительности. Но это опять же доказывает, что все случаи индивидуальны, и стричь все задачи под одну функциональную гребёнку неразумно. Также, не будем забывать, что сами процессоры работают очень императивно и мутабельно, поэтому абстракции поверх этой логики всегда будут нести накладные расходы (дополнительные аллокации памяти как минимум). Но изначально функциональные языки типа Haskell, насколько я знаю, оптимизируются под такую логику работы, поэтому там оверхед должен быть меньше, чем в изначально императивной Java.
Ещё есть фундаментально грязные функции — работа с любым I/O, т.к. при этом меняется внешнее состояние, тут ничего не поделать. Без очень сильного колдунства не получится представить файлы, например, в виде иммутабельной структуры. Придётся хранить отдельную копию файла на каждое изменение или применять снапшоты/CoW, причём, всё это в большинстве случаев без особой практической необходимости, чисто ради поддержания идеологии.
При всём при этом, мне нравится ФП, и я его иногда применяю именно в сочетании с императивным подходом. В Java с помощью Optional и Stream можно достаточно элегантно и надёжно описывать логику, которая иначе вырождается в кучу проверок на null и обработку различных исключений. Просто не думаю, что стоит ударяться в крайности, от этого чаще всего страдает качество конечного продукта.
vba
02.10.2018 12:54Я бы не стал так идеализировать. ФП такой же подход к решению задач, как и любой другой, со своими плюсами и минусами.
Тут готов поспорит, математическое описание какой либо задачи гораздо ближе к функциональному стилю чем к императивному.
Не могу найти ссылку, но читал об одном embedded софте для пейсмекеров который изначально был написан на Сях и который был подвержен сбоям в связи со сложностью кода, которая способствовала трудно выявляемым багам. Как не сложно догадаться из за таких сбоев просто гибли пациенты. Так вот софт переписали на Haskell и вы не поверите сбоев связанных с софтом почти не осталось.
В Java с помощью Optional и Stream можно достаточно элегантно ...
Недомоноид Optional(в версии Java) и непереиспользуемый Stream. ФП в Java это все таки не самый оптимальный вариант и скорее костыль из за безысходности.
rkfg
02.10.2018 13:01Пример с софтом — это частный случай, который не подтверждает намного более сильное утверждение, что ФП прямо всегда и везде лучше ИП. Был плохой код на одном языке, стал хороший код на другом языке, таких примеров можно найти массу, и необязательно они связаны со сменой парадигмы программирования. Иначе игры бы тоже писали на хаскеле или лиспе, но что-то пока даже близко не видно такого тренда.
vba
02.10.2018 15:23Пример с софтом — это частный случай, который не подтверждает намного более сильное утверждение, что ФП прямо всегда и везде лучше ИП
Согласен, все задачи выполнимы, на Assembler, проверенно временем. Согласен с вами что это всего лишь мое частное мнение. Но все же повторюсь, ФП гораздо ближе к мат аппарату чем ИП, следовательно выразительнее. Горькая правда в том что ЦП-ру наплевать на это так как он питается только машинным кодом.
rkfg
02.10.2018 15:32Так я как раз к тому, что передёргивать не надо. Да, всё можно решить на ассемблере, всё так же можно решить с помощью ФП. Но эффективность (по различным критериям, замечу) обоих подходов в каждом конкретном случае может различаться на порядки. Где-то важнее производительность, где-то читабельность, где-то близость к матаппарату. И далеко не в каждой задаче этот матаппарат необходим повсеместно.
Представьте, что вы пишете игру. У вас есть граф сцены в виде дерева, у каждого элемента есть список дочерних узлов. На сцене появляется монстр, его нужно добавить в этот граф. Но так как у вас функциональный подход, дерево не мутабельно, т.е. вам нужно сделать копию с добавленным в граф новым объектом. Конечно, тут могут быть всякие оптимизации со стороны компилятора, который заметит, что вы не используете и не сохраняете нигде предыдущее состояние дерева, поэтому можно схитрить и мутировать структуру, но полагаться на это, пожалуй, наивно. Потому что если вы вдруг где-то всё же сохраните старое состояние, оптимизация сломается, и производительность просядет дичайше. Поправьте, если я что-то не так понимаю, но в таких ситуациях, упрощённо, математически некорректное
x = x + 1работает проще, быстрее и очевиднее, чемreturn x + 1в некой рекурсивной функции.
sshikov
Люблю Vavr, еще с тех пор когда его звали javaslang. Пишите еще!
faoxy Автор
Хорошо, спасибо! :)