
Как привнести «человеческое» в технологии и как технологии помогают понять и улучшить и масштабировать «человеческое»?
В этом нам поможет суровый Марвин Мински, который своим беспощадным разумом анализирует чувства, эмоции, боль, влюбленность и сознание.


Когда Джоан выбирала что ей делать – перебегать дорогу вперёд или убежать назад, ей нужно было выбрать одно из следующих правил:
Если ты на проезжей части, То убеги с неё
Если ты на проезжей части, То быстро перебеги её
Однако, для того, чтобы Джоан приняла эти решения, ей необходим какой-то механизм, который бы предсказывал и сравнивал возможные варианты разрешения этой ситуации. Что помогает Джоан делать подобные предсказания? Простейший способ – иметь при себе коллекцию трёхсоставных правил «Если –> То –> В таком случае», в котором каждое Если описывает конкретную ситуацию, каждое То описывает конкретное действие, а каждое Затем описывает возможный результат проделанной работы.

Если ты находишься на проезжей части, То убеги назад, В таком случае попробуй перейти дорогу немного позже
Если ты находишься на проезжей части, То перейди её, В таком случае ты прибудешь гораздо раньше
Если ты находишься на проезжей части, То перейди, В таком случае ты можешь получить раны
Но что если к конкретной ситуации могут быть применены несколько правил? В таком случае можно выбрать необходимое правило после сравнения результатов, которые они предсказывают:

Таким образом, эти трехсоставные правила позволяют нам строить эксперименты в нашей голове, прежде чем начать действовать в полном опасностями окружающем мире; мы можем мысленно «представить себе результат до совершения прыжка» и выбрать наиболее привлекательные альтернативы. Например, предположим, что Кэрол играет с кубиками и рассуждает о строительстве трёхблочной арки:
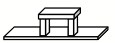
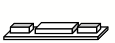
Прямо сейчас у неё есть три блока, которые лежат следующим образом:
Итак, она воображает план построения этой арки: изначально ей понадобится место для возведения основания арки, которое она может найти используя следующее правило: если блок лежит и если она поставит его на бок, тогда он будет занимать меньше места на земле.
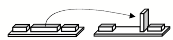
Затем она может поставить два коротких блока на рёбра, убедившись, что они находятся на правильном расстоянии друг от друга, и затем, наконец, поместить длинный блок на них плашмя. Мы можем представить последовательность действий, описывая их как последовательную смену кадров в видео.

Чтобы представить себе четырёхэтапную последовательность действий, Кэрол необходимо иметь достаточно много навыков. Сначала её зрительные системы должны описать форму и местоположение этих блоков, при этом некоторые их части могут быть вне зоны видимости, и ей понадобится способность для планирования какой блок следует передвинуть и куда его следует поставить. Затем, всякий раз когда она перемещает блок, она должна запрограммировать свои пальцы для захвата этих блоков, затем перемещать блоки в необходимое место, и, наконец, отпускать их, контролируя, при этом, чтобы её рука не столкнулась с её телом, или лицом, или другим блоком, который уже стоит на своём месте. Также ей нужно контролировать скорость, чтобы суметь положить блок на верх двух блоков, пытаясь не уронить поддерживающие блоки.
Кэрол: Ни одно из этих действий не казалось для меня проблемным. Я просто представила арку в уме и поняла как должен стоять каждый из блоков. Затем я всего лишь должна была поставить два блока перпендикулярно вверх (когда я была убеждена, что они находятся на правильном расстоянии друг от друга), а затем поместила длинный блок наверх этих двух. В конце концов, я уже делала подобные вещи. Возможно, я вспомнила свой опыт и попросту повторила его.
Но как Кэрол могла «представить» себе как фигура будет выглядеть после перемещения блока, прежде чем она непосредственно передвинет блок?
Программист: Мы знаем, как можно научить компьютер делать подобные вещи; мы называем это «физическим симулированием». К примеру, на каждом этапе дизайна нового самолёта, наши программы могут в точности предсказать силу, действующую на каждую точку самолёта, когда он двигает в воздушном пространстве. Фактически, мы можем это делать настолько хорошо, что мы построим с нуля самолёт на компьютере, а затем воссоздадим его в реальности – он будет летать.
Ни один человеческий мозг не может делать подобные сложные вычисления, но мы всё ещё можем делать полезные предсказания, используя правила «Если –> То –> В таком случае». Например, когда Кэрол планировала построить эту арку, она могла представить шаг, в котором она помещает длинный блок на верх коротких блоков:

Конечно, это действие закончится неудачей, потому что верхний блок упадёт. Однако, после того как Кэрол приобретёт больше опыта, она также научится предсказывать, что верхний блок в этой ситуации упадёт вниз.

Обратите внимание, вы также можете использовать эти правила «в обратном порядке», для того чтобы объяснить, что происходило в предыдущих шагах! Таким образом, если вы увидите упавший блок (А), вы можете догадаться, что предыдущее состояние было (В):

Студент: Интересно, будет ли использование этих правил практичным? Мне кажется, чтобы выполнить эти планы, Кэрол понадобилось бы огромное количество правил «Если –> То –> В таком случае». Ибо, если каждый из трёх блоков будет иметь тысячи разных форм, тогда Кэрол понадобилось бы использовать тысячи разных правил.
В самом деле, если мы сделаем правила «Если –> То –> В таком случае» слишком конкретными, тогда они будут применяться только к нескольким ситуациям. Это означает, что наши правила не должны учитывать слишком много деталей, но учитывать более абстрактные идеи. Таким образом, правило, применимое к физическому объекту должно описывать этот объект определённым ненаглядном виде, которое бы не изменялось если конкретный объект изменил свою визуальную форму. Наивно то, что большинство из нас склонны полагать, что мы «представляем» конкретные сцены как вполне определённые картинки. Однако в разделе §5-8 мы покажем, что все подобны модели являются иллюзиями, потому что эти изображения не ведут себя так как настоящие картинки.
Учтите, что в физическом мире, когда вы думаете о захвате или поднимании блока, вы не учитываете его вес, и предсказываете, что если вы отпустите его – то он упадёт. В экономическом мире, если вы заплатите за покупку, тогда вы будете обладать купленной вещью, иначе – вы должны будете отдать её обратно. В мире коммуникаций, когда вы говорите что-либо — то слушатели могут запомнить это, но данный факт произойдёт с гораздо большей вероятностью, если вы скажете, что данная конкретная информация является важной.
Каждый взрослый знает много таких вещей и рассматривает их как очевидные, здравомыслящие знания, но каждому ребёнку необходимо учиться этим вещам годами, до тех пор пока он не поймёт как они действуют в различных мирах. Например, если вы передвинете предмет в физическом мире – то предмет изменит своё место положения, но если вы сообщите какую-либо информацию своему другу — то она уже будет находиться сразу в двух местах. Мы более подробно рассмотрим данные вещи в главе §6.[1].
Связывая два и более правил «Если –> То –> В таком случае» в цепочку, мы можем представить, что произойдёт через несколько выполненных действий, и таким образом, предсказать что произойдёт в дальнейшем, но только в том случае, если мы в состоянии сопоставить предыдущее и последующее Если. Например, если вы находитесь в ситуации P и хотите оказаться в ситуации Q, вы можете уже знать необходимое правило: Если P –> То сделай А –> В таком случае Q. Но что если вы не знаете этого правила? В таком случае, вы можете поискать такое правило в памяти, которое связывало бы P и Q через какую-то промежуточную цепочку S.
Если P –> Сделай А –> В таком случае S и затем Если S –> Сделай В –> В таком случае Q
Затем, если вы не можете найти необходимую двухсоставную цепочку, то вы можете начать искать более длинные цепочки действий. Вполне понятно, что большая часть наших рассуждений основана на нахождении подобных «цепочек рассуждений» и как только вы научитесь использовать этот процесс, вы сможете разрешать более сложные проблемы и смотреть на несколько шагов вперёд. Например, вы довольно часто думаете:
Если я попрошу Чарльза подвезти меня до магазина, то он может ответить мне «да» или «нет». Если он ответит «да» — всё будет хорошо, но если он ответит «нет» — то я предложу ему какое-нибудь вознаграждение и это, вероятно, поможет ему поменять решение.
Однако, когда вам нужно предугадать события на большее число шагов, поиск подобных цепочек может становится слишком сложным – потому что сложность подобных вычислений растёт экспоненциально, подобно густо ветвящемуся дереву. Таким образом, если каждая ветвь приводит лишь к двум альтернативам, и вам нужно предугадать 20 последующих шагов вам придётся просмотреть порядка миллиона подобных путей, потому что именно столько ветвей будет давать последовательность из 20 выборов.
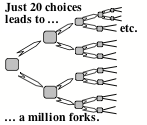
Однако есть трюк, который мог бы сделать поиск более упрощенным. Ибо если есть 20-ступенчатый путь от А до В, в таком случае должен существовать путь только из 10 ступеней, с каждого конца! Таким образом, если начинать поиск в двух концов сразу, в таком случае мы сможем встретиться в середине в точке М.
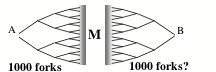
В левой части этого дерева будет находится порядка 1000 ветвей, если это также верно для части справа, в таком случае поиск будет в несколько сотен раз меньше. А затем, если вы каким-либо образом узнаете, где точка М должна находится – то вы сможете ещё сильнее ускорить поиск, разделив каждую сторону на последовательности из 5 шагов.
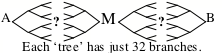
Если это сработает, то ваш поиск будет в несколько тысяч раз меньше! Однако, никакая из вышеописанных методик, кажется, не работает на практике, потому что они предполагают, что каждый «обратный» поиск будет сталкиваться только с двумя ветвями, а это далеко не всегда так. Тем не менее, если догадка М была неверной, вы всё ещё можете испробовать другие подобные догадки, и даже вам не повезёт 50 раз подряд, используя эту методику вы всё равно потратите гораздо меньше сил и времени, если бы стали перебирать все варианты!
Этот пример демонстрирует, почему иметь планы – хорошо. Если вы можете предугадать некоторые «ступеньки» на пути решения крайне сложной проблемы – то вы сможете последовательно решать гораздо менее сложные проблемы! Поэтому каждая попытка «разделения и властвования» может сделать сложную задачу простой. В первые годы искусственного интеллекта, когда большинство программ было основано на «пробах и ошибках», многие исследователи пытались найти технические методы, которые позволяли уменьшать количество попыток для достижения результата. Сейчас, однако, кажется, что более важной задачей является нахождения именно этих «ступенек», потому что именно благодаря им исходит наш здравый смысл. В главе §6 утверждается, что наши самые мощные способы разрешения проблем проистекают из придумывания хороший аналогий, с которыми мы знаем как работать, к разрешаемой проблеме.
Всякий раз, когда мы решаем проблему, мы используем множество методик мышления. Некоторые из них имеют свои имена, например планирование и логическое обоснование, но большинство не имеют своих названий. Некоторые из этих методов кажутся формально описанными и аккуратными, в то время как другие более «интуитивными».
Например, мы постоянно используем цепочки предсказаний способом, который напоминает следующий: Если А подразумевает В, а В подразумевает С, то с полной уверенностью можно сказать, что А подразумевает С. И если все из предпосылок верны, как и верно наше логическое мышление – в таком случае данное заключение будет верным, и мы никогда не совершим трагическую ошибку.
Однако, в реальной жизни, кажется, большинство предположений являются ошибочными, потому что «правила» на которых они основываются всегда имеют исключения. Это значит, что существует разница между жесткими методами логики и цепочкам различных форм ежедневно используемого здравого смысла.
Мы все знаем, что физическая цепь сильно ровно настолько, насколько сильно её самое слабое звено. Но ментальные цепи являются ещё более хрупкими, потому что каждое новое звено ослабляет последующее!
Так что использование логики – это нечто похожее ходьбе по доске. Она предполагает, что каждый отдельный шаг является правильным, тогда как здравый смысл должен обеспечиваться большей поддержкой – для него необходимо приводить новые доказательства по прошествии нескольких шагов. И слабость цепочки нарастает с наращиванием её длинны – так как каждое дополнительное звено увеличивает шанс её разрыва. Вот почему, когда люди высказывают свои аргументы они часто прерывают себя для ввода в сообщения большого количества доказательств или аналогий – они ощущают необходимость поддержки настоящего шага размышлений, прежде чем перейти к следующему шагу размышлений.
Построение длинных цепочек рассуждения является одним из путей предсказания будущей ситуации – в главе §7 будут обсуждаться большое количество других средств. Я подозреваю, что когда мы сталкиваемся с проблемами в повседневной жизни, мы склонны использовать несколько разных методов предсказаний, отчетливо понимая, что у каждого из них есть свои недостатки. Но поскольку у каждого из этих методов недостатки различны – мы можем объединить эти методы для использования их совместных сильных сторон.
Каждый человек имеет множество способов делать краткосрочные планы, сравнивать доступные варианты развития событий и применять обыденные методы рассуждения – и мы способны это делать настолько легко, что едва ли можем задумываться об этих процессах. Однако, когда эти процессы не выполняют свои функции, и нам нужно изменить наши методы краткосрочных предсказаний – тогда мы начинаем думать над тем, что мы делам – и это называется рефлексивным мышлением.
За перевод спасибо Станиславу Суханицкому. Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru

Марвин Ли Минский (англ. Marvin Lee Minsky; 9 августа 1927 — 24 января 2016) — американский учёный в области искусственного интеллекта, сооснователь Лаборатории искусственного интеллекта в Массачусетском технологическом институте. [Википедия]
Интересные факты:
В этом нам поможет суровый Марвин Мински, который своим беспощадным разумом анализирует чувства, эмоции, боль, влюбленность и сознание.
§5-3. Обдумывание
Когда Джоан выбирала что ей делать – перебегать дорогу вперёд или убежать назад, ей нужно было выбрать одно из следующих правил:
Если ты на проезжей части, То убеги с неё
Если ты на проезжей части, То быстро перебеги её
Однако, для того, чтобы Джоан приняла эти решения, ей необходим какой-то механизм, который бы предсказывал и сравнивал возможные варианты разрешения этой ситуации. Что помогает Джоан делать подобные предсказания? Простейший способ – иметь при себе коллекцию трёхсоставных правил «Если –> То –> В таком случае», в котором каждое Если описывает конкретную ситуацию, каждое То описывает конкретное действие, а каждое Затем описывает возможный результат проделанной работы.
Если ты находишься на проезжей части, То убеги назад, В таком случае попробуй перейти дорогу немного позже
Если ты находишься на проезжей части, То перейди её, В таком случае ты прибудешь гораздо раньше
Если ты находишься на проезжей части, То перейди, В таком случае ты можешь получить раны
Но что если к конкретной ситуации могут быть применены несколько правил? В таком случае можно выбрать необходимое правило после сравнения результатов, которые они предсказывают:
Таким образом, эти трехсоставные правила позволяют нам строить эксперименты в нашей голове, прежде чем начать действовать в полном опасностями окружающем мире; мы можем мысленно «представить себе результат до совершения прыжка» и выбрать наиболее привлекательные альтернативы. Например, предположим, что Кэрол играет с кубиками и рассуждает о строительстве трёхблочной арки:
Прямо сейчас у неё есть три блока, которые лежат следующим образом:
Итак, она воображает план построения этой арки: изначально ей понадобится место для возведения основания арки, которое она может найти используя следующее правило: если блок лежит и если она поставит его на бок, тогда он будет занимать меньше места на земле.
Затем она может поставить два коротких блока на рёбра, убедившись, что они находятся на правильном расстоянии друг от друга, и затем, наконец, поместить длинный блок на них плашмя. Мы можем представить последовательность действий, описывая их как последовательную смену кадров в видео.
Чтобы представить себе четырёхэтапную последовательность действий, Кэрол необходимо иметь достаточно много навыков. Сначала её зрительные системы должны описать форму и местоположение этих блоков, при этом некоторые их части могут быть вне зоны видимости, и ей понадобится способность для планирования какой блок следует передвинуть и куда его следует поставить. Затем, всякий раз когда она перемещает блок, она должна запрограммировать свои пальцы для захвата этих блоков, затем перемещать блоки в необходимое место, и, наконец, отпускать их, контролируя, при этом, чтобы её рука не столкнулась с её телом, или лицом, или другим блоком, который уже стоит на своём месте. Также ей нужно контролировать скорость, чтобы суметь положить блок на верх двух блоков, пытаясь не уронить поддерживающие блоки.
Кэрол: Ни одно из этих действий не казалось для меня проблемным. Я просто представила арку в уме и поняла как должен стоять каждый из блоков. Затем я всего лишь должна была поставить два блока перпендикулярно вверх (когда я была убеждена, что они находятся на правильном расстоянии друг от друга), а затем поместила длинный блок наверх этих двух. В конце концов, я уже делала подобные вещи. Возможно, я вспомнила свой опыт и попросту повторила его.
Но как Кэрол могла «представить» себе как фигура будет выглядеть после перемещения блока, прежде чем она непосредственно передвинет блок?
Программист: Мы знаем, как можно научить компьютер делать подобные вещи; мы называем это «физическим симулированием». К примеру, на каждом этапе дизайна нового самолёта, наши программы могут в точности предсказать силу, действующую на каждую точку самолёта, когда он двигает в воздушном пространстве. Фактически, мы можем это делать настолько хорошо, что мы построим с нуля самолёт на компьютере, а затем воссоздадим его в реальности – он будет летать.
Ни один человеческий мозг не может делать подобные сложные вычисления, но мы всё ещё можем делать полезные предсказания, используя правила «Если –> То –> В таком случае». Например, когда Кэрол планировала построить эту арку, она могла представить шаг, в котором она помещает длинный блок на верх коротких блоков:
Конечно, это действие закончится неудачей, потому что верхний блок упадёт. Однако, после того как Кэрол приобретёт больше опыта, она также научится предсказывать, что верхний блок в этой ситуации упадёт вниз.
Обратите внимание, вы также можете использовать эти правила «в обратном порядке», для того чтобы объяснить, что происходило в предыдущих шагах! Таким образом, если вы увидите упавший блок (А), вы можете догадаться, что предыдущее состояние было (В):
Студент: Интересно, будет ли использование этих правил практичным? Мне кажется, чтобы выполнить эти планы, Кэрол понадобилось бы огромное количество правил «Если –> То –> В таком случае». Ибо, если каждый из трёх блоков будет иметь тысячи разных форм, тогда Кэрол понадобилось бы использовать тысячи разных правил.
В самом деле, если мы сделаем правила «Если –> То –> В таком случае» слишком конкретными, тогда они будут применяться только к нескольким ситуациям. Это означает, что наши правила не должны учитывать слишком много деталей, но учитывать более абстрактные идеи. Таким образом, правило, применимое к физическому объекту должно описывать этот объект определённым ненаглядном виде, которое бы не изменялось если конкретный объект изменил свою визуальную форму. Наивно то, что большинство из нас склонны полагать, что мы «представляем» конкретные сцены как вполне определённые картинки. Однако в разделе §5-8 мы покажем, что все подобны модели являются иллюзиями, потому что эти изображения не ведут себя так как настоящие картинки.
Учтите, что в физическом мире, когда вы думаете о захвате или поднимании блока, вы не учитываете его вес, и предсказываете, что если вы отпустите его – то он упадёт. В экономическом мире, если вы заплатите за покупку, тогда вы будете обладать купленной вещью, иначе – вы должны будете отдать её обратно. В мире коммуникаций, когда вы говорите что-либо — то слушатели могут запомнить это, но данный факт произойдёт с гораздо большей вероятностью, если вы скажете, что данная конкретная информация является важной.
Каждый взрослый знает много таких вещей и рассматривает их как очевидные, здравомыслящие знания, но каждому ребёнку необходимо учиться этим вещам годами, до тех пор пока он не поймёт как они действуют в различных мирах. Например, если вы передвинете предмет в физическом мире – то предмет изменит своё место положения, но если вы сообщите какую-либо информацию своему другу — то она уже будет находиться сразу в двух местах. Мы более подробно рассмотрим данные вещи в главе §6.[1].
Планирование и Поиск
Связывая два и более правил «Если –> То –> В таком случае» в цепочку, мы можем представить, что произойдёт через несколько выполненных действий, и таким образом, предсказать что произойдёт в дальнейшем, но только в том случае, если мы в состоянии сопоставить предыдущее и последующее Если. Например, если вы находитесь в ситуации P и хотите оказаться в ситуации Q, вы можете уже знать необходимое правило: Если P –> То сделай А –> В таком случае Q. Но что если вы не знаете этого правила? В таком случае, вы можете поискать такое правило в памяти, которое связывало бы P и Q через какую-то промежуточную цепочку S.
Если P –> Сделай А –> В таком случае S и затем Если S –> Сделай В –> В таком случае Q
Затем, если вы не можете найти необходимую двухсоставную цепочку, то вы можете начать искать более длинные цепочки действий. Вполне понятно, что большая часть наших рассуждений основана на нахождении подобных «цепочек рассуждений» и как только вы научитесь использовать этот процесс, вы сможете разрешать более сложные проблемы и смотреть на несколько шагов вперёд. Например, вы довольно часто думаете:
Если я попрошу Чарльза подвезти меня до магазина, то он может ответить мне «да» или «нет». Если он ответит «да» — всё будет хорошо, но если он ответит «нет» — то я предложу ему какое-нибудь вознаграждение и это, вероятно, поможет ему поменять решение.
Однако, когда вам нужно предугадать события на большее число шагов, поиск подобных цепочек может становится слишком сложным – потому что сложность подобных вычислений растёт экспоненциально, подобно густо ветвящемуся дереву. Таким образом, если каждая ветвь приводит лишь к двум альтернативам, и вам нужно предугадать 20 последующих шагов вам придётся просмотреть порядка миллиона подобных путей, потому что именно столько ветвей будет давать последовательность из 20 выборов.
Однако есть трюк, который мог бы сделать поиск более упрощенным. Ибо если есть 20-ступенчатый путь от А до В, в таком случае должен существовать путь только из 10 ступеней, с каждого конца! Таким образом, если начинать поиск в двух концов сразу, в таком случае мы сможем встретиться в середине в точке М.
В левой части этого дерева будет находится порядка 1000 ветвей, если это также верно для части справа, в таком случае поиск будет в несколько сотен раз меньше. А затем, если вы каким-либо образом узнаете, где точка М должна находится – то вы сможете ещё сильнее ускорить поиск, разделив каждую сторону на последовательности из 5 шагов.
Если это сработает, то ваш поиск будет в несколько тысяч раз меньше! Однако, никакая из вышеописанных методик, кажется, не работает на практике, потому что они предполагают, что каждый «обратный» поиск будет сталкиваться только с двумя ветвями, а это далеко не всегда так. Тем не менее, если догадка М была неверной, вы всё ещё можете испробовать другие подобные догадки, и даже вам не повезёт 50 раз подряд, используя эту методику вы всё равно потратите гораздо меньше сил и времени, если бы стали перебирать все варианты!
Этот пример демонстрирует, почему иметь планы – хорошо. Если вы можете предугадать некоторые «ступеньки» на пути решения крайне сложной проблемы – то вы сможете последовательно решать гораздо менее сложные проблемы! Поэтому каждая попытка «разделения и властвования» может сделать сложную задачу простой. В первые годы искусственного интеллекта, когда большинство программ было основано на «пробах и ошибках», многие исследователи пытались найти технические методы, которые позволяли уменьшать количество попыток для достижения результата. Сейчас, однако, кажется, что более важной задачей является нахождения именно этих «ступенек», потому что именно благодаря им исходит наш здравый смысл. В главе §6 утверждается, что наши самые мощные способы разрешения проблем проистекают из придумывания хороший аналогий, с которыми мы знаем как работать, к разрешаемой проблеме.
Причина и Надёжность
Всякий раз, когда мы решаем проблему, мы используем множество методик мышления. Некоторые из них имеют свои имена, например планирование и логическое обоснование, но большинство не имеют своих названий. Некоторые из этих методов кажутся формально описанными и аккуратными, в то время как другие более «интуитивными».
Например, мы постоянно используем цепочки предсказаний способом, который напоминает следующий: Если А подразумевает В, а В подразумевает С, то с полной уверенностью можно сказать, что А подразумевает С. И если все из предпосылок верны, как и верно наше логическое мышление – в таком случае данное заключение будет верным, и мы никогда не совершим трагическую ошибку.
Однако, в реальной жизни, кажется, большинство предположений являются ошибочными, потому что «правила» на которых они основываются всегда имеют исключения. Это значит, что существует разница между жесткими методами логики и цепочкам различных форм ежедневно используемого здравого смысла.
Мы все знаем, что физическая цепь сильно ровно настолько, насколько сильно её самое слабое звено. Но ментальные цепи являются ещё более хрупкими, потому что каждое новое звено ослабляет последующее!
Так что использование логики – это нечто похожее ходьбе по доске. Она предполагает, что каждый отдельный шаг является правильным, тогда как здравый смысл должен обеспечиваться большей поддержкой – для него необходимо приводить новые доказательства по прошествии нескольких шагов. И слабость цепочки нарастает с наращиванием её длинны – так как каждое дополнительное звено увеличивает шанс её разрыва. Вот почему, когда люди высказывают свои аргументы они часто прерывают себя для ввода в сообщения большого количества доказательств или аналогий – они ощущают необходимость поддержки настоящего шага размышлений, прежде чем перейти к следующему шагу размышлений.
Построение длинных цепочек рассуждения является одним из путей предсказания будущей ситуации – в главе §7 будут обсуждаться большое количество других средств. Я подозреваю, что когда мы сталкиваемся с проблемами в повседневной жизни, мы склонны использовать несколько разных методов предсказаний, отчетливо понимая, что у каждого из них есть свои недостатки. Но поскольку у каждого из этих методов недостатки различны – мы можем объединить эти методы для использования их совместных сильных сторон.
Каждый человек имеет множество способов делать краткосрочные планы, сравнивать доступные варианты развития событий и применять обыденные методы рассуждения – и мы способны это делать настолько легко, что едва ли можем задумываться об этих процессах. Однако, когда эти процессы не выполняют свои функции, и нам нужно изменить наши методы краткосрочных предсказаний – тогда мы начинаем думать над тем, что мы делам – и это называется рефлексивным мышлением.
За перевод спасибо Станиславу Суханицкому. Кто хочет помочь с переводом — пишите в личку или на почту magisterludi2016@yandex.ru
Оглавление книги The Emotion Machine
Введение
Chapter 5. LEVELS OF MENTAL ACTIVITIES
Chapter 6. COMMON SENSE
Chapter 7. Thinking.
Chapter 8. Resourcefulness.
Chapter 9. The Self.
Chapter 1. Falling in Love
Chapter 2. ATTACHMENTS AND GOALS
Chapter 3. FROM PAIN TO SUFFERING
Chapter 4. CONSCIOUSNESSChapter 5. LEVELS OF MENTAL ACTIVITIES
Chapter 6. COMMON SENSE
Chapter 7. Thinking.
Chapter 8. Resourcefulness.
Chapter 9. The Self.
Об авторе
Марвин Ли Минский (англ. Marvin Lee Minsky; 9 августа 1927 — 24 января 2016) — американский учёный в области искусственного интеллекта, сооснователь Лаборатории искусственного интеллекта в Массачусетском технологическом институте. [Википедия]
Интересные факты:
- Минский дружил с критиком Харольдом Блумом из Йельского университета (Yale University), который отзывался о нём не иначе как «зловещий Марвин Минский».
- Айзек Азимов описывал Минского как одного из двух людей, которые умнее, чем он сам; вторым, по его мнению, был Карл Саган.
- Марвин — робот с искусственным интеллектом из цикла романов Дугласа Адамса Автостопом по галактике и фильма Автостопом по галактике (фильм).
- Минский имеет контракт на заморозку своего мозга после смерти для того, чтобы его «воскресили» в будущем.
- В честь Минского назван пес главного героя в фильме Трон: Наследие. [Википедия]
Про #philtech
#philtech (технологии + филантропия) — это открытые публично описанные технологии, выравнивающие уровень жизни максимально возможного количества людей за счёт создания прозрачных платформ для взаимодействия и доступа к данным и знаниям. И удовлетворяющие принципам филтеха:
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку
#philtech (технологии + филантропия) — это открытые публично описанные технологии, выравнивающие уровень жизни максимально возможного количества людей за счёт создания прозрачных платформ для взаимодействия и доступа к данным и знаниям. И удовлетворяющие принципам филтеха:
1. Открытые и копируемые, а не конкурентно-проприетарные.
2. Построенные на принципах самоорганизации и горизонтального взаимодействия.
3. Устойчивые и перспективо-ориентированные, а не преследующие локальную выгоду.
4. Построенные на [открытых] данных, а не традициях и убеждениях
5. Ненасильственные и неманипуляционные.
6. Инклюзивные, и не работающие на одну группу людей за счёт других.
Акселератор социальных технологических стартапов PhilTech — программа интенсивного развития проектов ранних стадий, направленных на выравнивание доступа к информации, ресурсам и возможностям. Второй поток: март–июнь 2018.
Чат в Telegram
Сообщество людей, развивающих филтех-проекты или просто заинтересованных в теме технологий для социального сектора.
#philtech news
Телеграм-канал с новостями о проектах в идеологии #philtech и ссылками на полезные материалы.
Подписаться на еженедельную рассылку