

Передаю слово автору.
Приветствуем вас, читатели Хабра! Мы команда WaveAccess, в этой статье поделимся с вами опытом применения службы баз данных (БД) Azure Cosmos DB в коммерческом проекте. Расскажем, для чего предназначена БД, и нюансы, с которыми нам пришлось столкнуться во время разработки.
Что такое Azure Cosmos DB
Azure Cosmos DB — это коммерческая глобально-распределенная служба база данных с мульти-модельной парадигмой, предоставляется как PaaS решение. Она является следующим поколением Azure DocumentDB.
База данных была разработана в 2017 г. в корпорации Microsoft при участии доктора компьютерных наук Лесли Лэмпорт (лауреата Премии Тьюринга 2013 г. за фундаментальный вклад в теорию распределенных систем, разработчик LaTex, создателя спецификации TLA+).
Главные характеристики Azure Cosmos DB это:
- Нереляционная база данных;
- Документы в ней хранятся в виде JSON;
- Горизонтальное масштабирование с возможностью выбора географических регионов;
- Мульти-модельная парадигма данных: ключ-значение, документное, графовое, семейство столбцов;
- Низкая задержка для 99% запросов: менее 10 мс для операций чтения и менее 15 мс для (индексированных) операций записи;
- Спроектирована для высокой пропускной способности;
- Гарантирует доступность, согласованность данных, задержку на уровне SLA 99,999%;
- Настраиваемая пропускная способность;
- Автоматическая репликация (master-slave);
- Автоматическое индексирование данных;
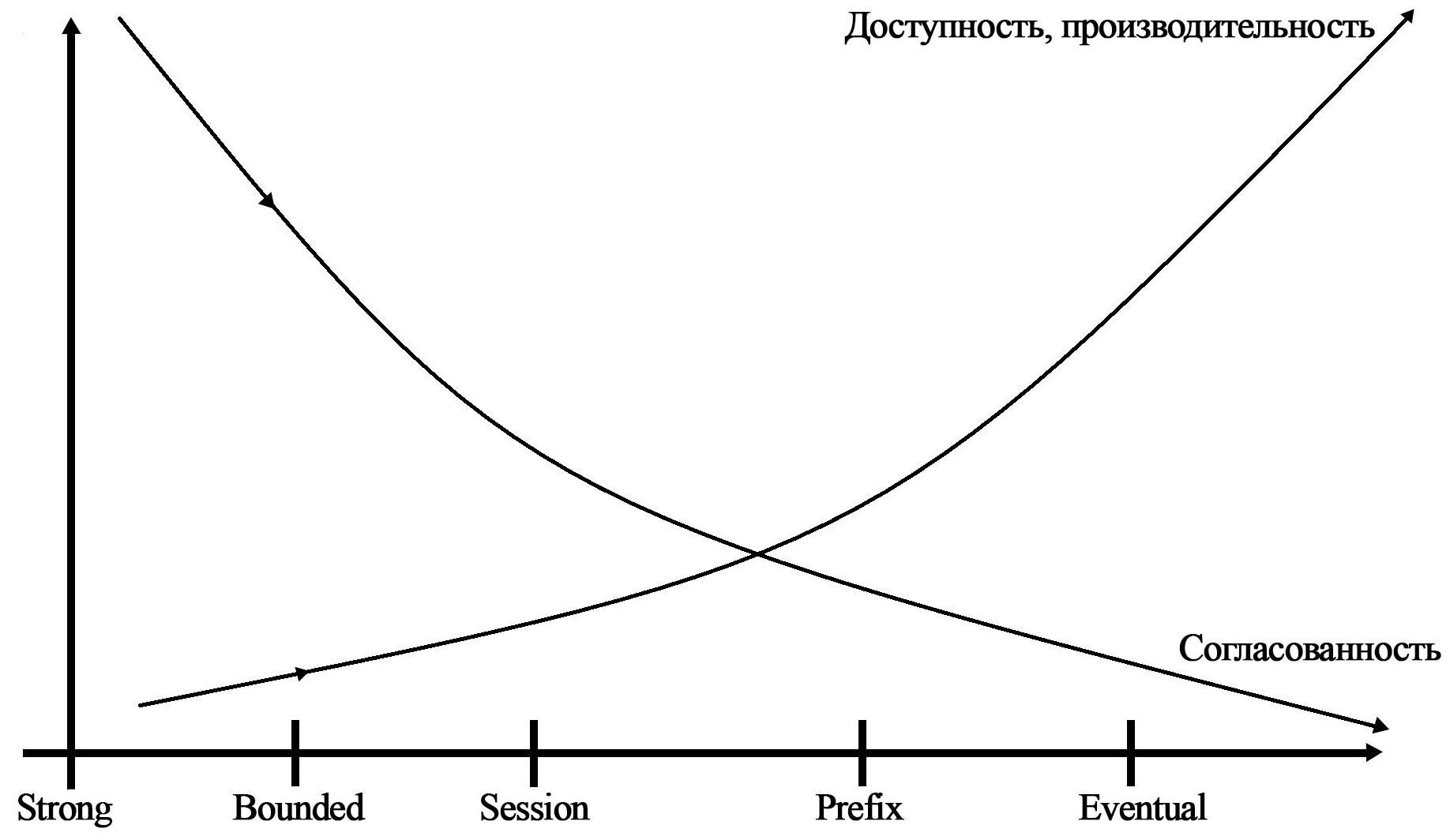
- Настраиваемые уровни согласованности данных. 5 различных уровней (Strong, Bounded Staleness, Session, Consistent Prefix, Eventual);
На графике можно видеть зависимость различных уровней согласованности от доступности, производительности и согласованности данных.
- Для удобного перехода на Cosmos DB со своей базы данных предусмотрено множество API для доступа к данным: SQL, JavaScript, Gremlin, MongoDB, Cassandra, Azure Blob;
- Настраиваемый брандмауэр;
- Настраиваемый размер БД.
Задача, которую мы решали
Тысячи датчиков, расположенные по всему миру, передают информацию (в дальнейшем нотификации) каждые несколько N-секунд. Эти нотификации должны сохраняться в БД, а в дальнейшем осуществляться поиск по ним и их отображение в UI оператора системы.
Требования от заказчика:
- Использование стек технологий Microsoft, в том числе облако Azure;
- Пропускная способность 100 запросов в секунду;
- Нотификации не имеют четкой структуры и могли в дальнейшем расширяться;
- Для критических нотификаций важна скорость обработки;
- Высокая отказоустойчивость системы.
Исходя из требований заказчика нам идеально подошла нереляционная, глобально-распределенная, надежная коммерческая БД.

Если рассмотреть похожие на Cosmos DB базы данных, то можно вспомнить об Amazon DynamoDB, Google Cloud Spanner. Но Amazon DynamoDB не является глобально-распределенной, а Google Cloud Spanner имеет меньше уровней согласованности и видов моделей данных (только табличное представление, реляционное).
По этим причинам мы остановились на Azure Cosmos DB. Для взаимодействия с БД использовали Azure Cosmos DB SDK для .NET, так как бэкенд был написан на .NET.
Нюансы, с которыми мы столкнулись
1. Управление базой данных
Для того, чтобы начать пользоваться базой данных, в первую очередь нужно выбрать инструмент для управления ей. Мы использовали Azure Cosmos DB Data Explorer в портале Azure и DocumentDbExplorer. Также существует утилита Azure Storage Explorer.

2. Настройка коллекций БД
В Cosmos DB каждая БД состоит из коллекций и документов.
Настраиваемые характеристики коллекции, на которые следует обратить внимание:
- Размер коллекции: фиксированная или неограниченная;
- Пропускная способность в единиц запросов в секунду RU/s (от 400 RU/s);

- Политика индексации (включение или исключение документов и путей к индексу и из него, настройка различных типов индекса, настройка режимов обновления индекса).
Пример типичного индекса
{
"id": "datas",
"indexingPolicy": {
"indexingMode": "consistent",
"automatic": true,
"includedPaths": [
{
"path": "/*",
"indexes": [
{
"kind": "Range",
"dataType": "Number",
"precision": -1
},
{
"kind": "Hash",
"dataType": "String"
},
{
"kind": "Spatial",
"dataType": "Point"
}
]
}
],
"excludedPaths": []
}
}Чтобы работал поиск по подстроке, для строковых полей нужно использовать Hash-индекс («kind»: «Hash»).
3. Транзакции БД
Транзакции реализованы в БД на уровне хранимых процедур (выполнение хранимой процедуры — это атомарная операция). Хранимые процедуры пишутся на JavaScript
var helloWorldStoredProc = {
id: "helloWorld",
body: function () {
var context = getContext();
var response = context.getResponse();
response.setBody("Hello, World");
}
} 4. Канал изменений БД
Change Feed (канал изменений) прослушивает изменения в коллекции. Когда происходят изменения документов коллекции, то БД «выкидывает» событие об изменениях всем подписчикам этого канала.
Мы использовали Change Feed для отслеживания изменений коллекции. При создании канала нужно предварительно создать вспомогательную коллекцию AUX, которая координирует обработку канала изменений для нескольких рабочих ролей.
5. Ограничения БД:
- Отсутствие bulk-операций (использовали хранимые процедуры для массового удаления, обновления документов);
- Отсутствие частичного обновления документа;
- Нет операции SKIP (сложность реализации пагинации). Чтобы реализовать пагинацию в запросах получения нотификаций мы использовали параметры RequestContinuation (ссылка на последний элемент в результате выдачи) и MaxItemCount (количество элементов возвращаемой из БД). По умолчанию результаты возвращаются в пакетах (не более 100 элементов и не более 1 МБ в каждом пакете). Количество возвращаемых элементов можно увеличить до 1000 с помощью параметра MaxItemCount.
6. Обработка 429-ой ошибки БД
Когда пропускная способность коллекции достигает максимума, то база данных начинает выдавать ошибку “429 Too Many Request”. Для ее обработки можно воспользоваться настройкой RetryOptions в SDK, где MaxRetryAttemptsOnThrottledRequests — это количество попыток выполнения запроса, а MaxRetryWaitTimeInSeconds — это суммарное время выполнения попыток подключения.
7. Прогноз стоимости использования БД
Чтобы спрогнозировать стоимость использования базы данных, мы использовали онлайн-калькулятор RU/s. В базовом плане одна единица запроса для элемента размером 1 КБ соответствует простой команде GET по ссылке на себя или идентификатору этого элемента.
Выводы
Azure Cosmos DB удобна в использовании, легко и гибко настраивается через портал Azure. Множество API для доступа к данным позволяют быстро осуществить переход на Сosmos DB. Не нужно привлекать администратора баз данных для обслуживания базы данных. Финансовые гарантии SLA, глобальное горизонтальное масштабирование делают эту базу данных очень привлекательной на рынке. Она подходит для использования в корпоративных и глобальных приложениях, которые предъявляют высокие требования к отказоустойчивости и пропускной способности. Мы в WaveAccess продолжаем использовать Cosmos DB в наших проектах.
Об авторе
Команда WaveAccess создаёт технически сложное высоконагруженное отказоустойчивое ПО для компаний всего мира. Александр Азаров, старший вице-президент по разработке ПО в WaveAccess, комментирует:
Сложные на первый взгляд задачи можно решить сравнительно простыми методами. Важно не только изучать новые инструменты, но и доводить до совершенства знание привычных технологий.
Блог компании
Комментарии (7)

Marwin
13.06.2018 14:33Простите за очередной глупый вопрос, но… скажите уже в конце концов… можно ли в азуре хранить БД с данными регистрации пользователей на сайте или нет?? (Подразумеваем, что данные (почта, фио, мобила, адрес проживания) заведомо реальны, ибо у нас участники должны бы настоящими людьми для участия в конкурсах, а так же могут проводить платежи через яндекс.кассу, а мы храним логи транзакций)
constb
13.06.2018 18:47Технически вам никто не запрещает это делать, и это будет нормально работать. Практически – если вы задаёте такие вопросы, возможно вам стоит ограничиться тем стеком, который вам хорошо знаком – быстрее выйдете в продакшен, меньше будет багов и непредсказуемых сюрпризов в неожиданных местах. У AWS/Azure/GCP есть и вполне надёжно работают все привычные вещи вроде mysql, pg, redis, elasticsearch. Хорошо обслуживаются самой компанией, бэкапы, кластеризация – всё делается в несколько кликов, стоят разумных денег. А свяжетесь с незнакомой штукенцией – потратите время и силы, которые не факт что окупятся…
Marwin
13.06.2018 18:52я, честно говоря, спрашивал в целом применительно к любой БД в азуре, а не только этого космоса. Так-то мы уже давно сидим на виртуалке селектела, который предоставляет нам какие-то документы соответствия ФЗ о персональных данных. А вот даёт ли что-то бумажное азур в этом плане — вопрос. Просто я думаю, зачем арендовать целую виндовую виртуалку, чтобы юзать простенький asp.net стэк и mssql express
constb
13.06.2018 18:09Но Amazon DynamoDB не является глобально-распределенной
Global Tables вышли в GA ещё прошлой осенью. Но собственно с DynamoDB Streams этот функционал и раньше вполне можно было самому реализовать, просто велосипеды не всем охота строить, я это понимаю…
Yo1
в эпоху реалтайм аналитики с kafka + hadoop подсаживаться на пропретарные технологии, с которых никуда не переехать и которые будут вытягивать бабло по экспоненте глупо. во сколько раз вырастет цена, когда нагрузка вырастит хотя бы до 40к запросов? такие базы имеют смысл лишь под прототип с крошечной нагрузкой.
Stas911
Переедут на Cassandra, в чем проблема? Не скажу за Azure, а в Амазоне к тому же можно гибко менять производительность DynamoDB (как я понимаю, ближайший аналог вышеприведенного) — если нагрузки нет, открутил на минимум и никто денег не ест почти.
Yo1
что-то я сомневаюсь что с таким подходом реально переключиться