
42bcfae8-2ecc-438f-9e0b-841575de7479Эти номера выступают ключами в различных таблицах, но первоначальным value является, в первую очередь, URL страниц, на которых данная кука была загружена, поисковые запросы, а также иногда некоторая дополнительная информация, которую даёт поставщик – IP-адрес, timestamp, информация о клиенте и прочее. Эти данные довольно неоднородные, поэтому наибольшую ценность для сегментации представляет именно URL. Создавая новый сегмент, аналитик указывает некоторый список адресов, и если какая-то кука засветится на одной из этих страничек, то она попадает в соответствующий сегмент. Получается, что чуть ли не 90% рабочего времени таких аналитиков уходит на то, чтобы подобрать подходящий набор урлов – в результате кропотливой работы с поисковиками, Yandex.Wordstat и другими инструментами.
Получив таким образом более тысячи сегментов, мы поняли, что этот процесс нужно максимально автоматизировать и упростить, при этом иметь возможность мониторинга качества алгоритмов и предоставить аналитикам удобный интерфейс для работы с новым инструментом. Под катом я расскажу, как мы решаем эти задачи.
Итак, как можно было понять из введения, на самом деле сегментировать нужно не пользователей, а странички интернет-сайтов, – пользователей по полученным сегментам уже автоматически распределит наш analytic engine.
Стоит рассказать несколько слов про то, как представлены сегменты в нашей DMP. Основной особенностью набора сегментов является то, что их структура иерархическая, то есть представляет из себя дерево. Никаких ограничений на глубину иерархии мы не накладываем, поскольку каждый следующий уровень позволяет более точно описывать портрет интересов пользователя. Вот примеры нескольких ветвей иерархии:
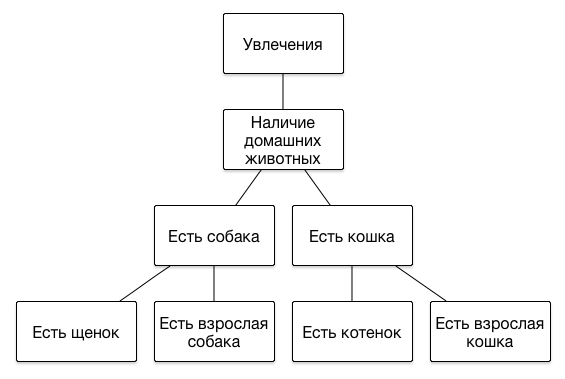
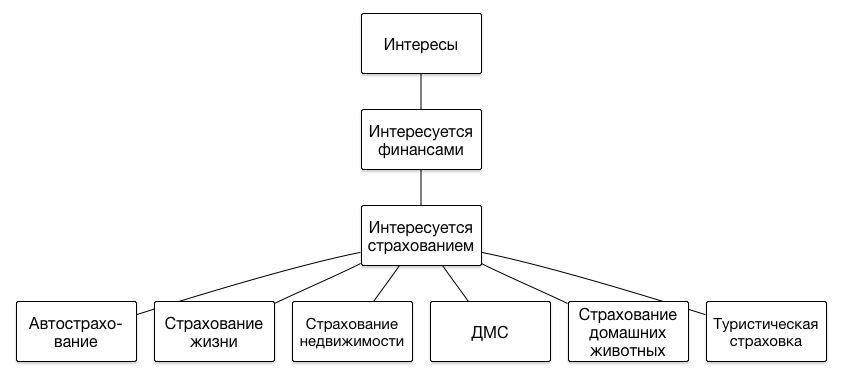
Если пользователь посетил сайт, на котором рассказывается о том, как нужно кормить щенков или приучить котика к лотку, велика вероятность того, что он является обладателем этого животного, и имеет смысл показывать ему соответствующие рекламные объявления – про ветеринарную клинику или новую линейку кормов. А если до этого в интернет-магазине он выбирал себе одежду премиальных брендов, значит у него могут быть сравнительно высокие доходы, и ему можно рекламировать более дорогие услуги – кошачьего психолога или собачьего парикмахера.
В общем, имея какую-то ручную таксономию тематик интернет-страниц, необходимо было создать сервис, который бы, получая на вход URL, на выходе выдавал список подходящих для него тематик. Задачу определения тематики веб-страницы мы решаем как задачу многоклассовой классификации по схеме «один против всех», то есть для каждого узла таксономии обучается свой классификатор. Классификаторы обходятся рекурсивно, начиная с корня дерева тематик и далее вниз по тем ветвям, которые на каждом текущем уровне определены как подходящие.
Устройство классификатора
Фронтенд классификатора представляет из себя Flask-приложение, которое держит в памяти некоторый объект. Он по сути занимается только подготовкой данных, десериализацией объектов обученных классификаторов класса sklearn.ensemble.RandomForestClassifier, хранящихся в mongoDB, выполнением их методов predict_proba() и обработкой результатов в соответствии с имеющейся таксономией. Таксономия вместе с запросами и тестовой выборкой, кстати, также хранится в mongoDB.
Приложение ждёт POST-запросы по URI вида:
- localhost/text/
- localhost/url/
- localhost/tokens/
classifier = RecursiveClassifier()
app = Flask(__name__)
@app.route("/text/", methods=['POST'])
def get_text_topics():
data = json.loads(request.get_data().decode())
text = data['text']
return Response(json.dumps(classifier.get_text_topics(text), indent=4), mimetype='application/json')
@app.route("/url/", methods=['POST'])
def get_url_topics():
data = json.loads(request.get_data().decode())
url = data['url']
html = html_get(url)
text = clean_html(html)
return Response(json.dumps(classifier.get_text_topics(text,url), indent=4), mimetype='application/json')
@app.route("/tokens/", methods=['POST'])
def get_tokens_topics():
data = json.loads(request.get_data().decode())
return Response(json.dumps(classifier.get_tokens_topics(data), indent=4), mimetype='application/json')
if __name__ == "__main__":
app.run(host="0.0.0.0", port=config.server_port)Получая, например, некоторый URL, приложение скачивает его тело, достает оттуда непосредственно текст страницы и инициирует рекурсивный обход таксономии от корня к детям. Рекурсия происходит только для тех узлов дерева, для которых на текущем шаге вероятность принадлежности страницы к данному узлу превышает заданный в конфиге порог.
Подготовка данных включает в себя разовую токенизацию текста, расчет частотных характеристик слов и feature conversion для каждого классификатора в соответствии с выбранными на этапе feature selection весами для токенов (об этом чуть позже). При этом используется модель «мешка слов», то есть взаимное расположение слов в тексте игнорируется.
Обучение классификатора
Процесс обучения выполняет бэкенд. При внесении изменений в таксономию или в перечень запросов к какому-то узлу, скачиваются и токенизируются тексты новых страниц, затем запускается алгоритм обучения для всех тематик на том же уровне, что и измененный. Все «братья» классификатора переобучаются вместе с изменившимся, потому что обучающая выборка для всего уровня одна и та же – тексты сайтов из ТОП-50 результатов поиска Bing, найденных по запросам из всех узлов-братьев и всех их детей. Для каждой тематики положительными примерами являются сайты, соответствующие их запросам и запросам их детей, все остальные страницы – негативные примеры. Результат сохраняется в объекте pandas.DataFrame.
Полученные наборы токенов с метками далее случайным образом распределяются на обучающую выборку (70%), выборку для feature selection (15%) и тестовую выборку (15%), – она сохраняется в mongoDB.
Feature selection
Выбор наиболее информативных токенов осуществляется в процессе обучения с помощью метрики dg, вот так она реализована:
def dg(arr):
avg = scipy.average(arr)
summ = 0.0
for s in arr:
summ += (s - avg) ** 2
summ /= len(arr)
return math.sqrt(summ) / avgА вот так она вызывается для набора токенов:
token_cnt = Counter()
topic_cnt = Counter()
topic_token_cnt = defaultdict(lambda: Counter())
for row in dataset.index:
topic = dataset['topic'][row]
topic_cnt[topic] += 1
for token in set(dataset['tokens'][row]):
token_cnt[token] += 1
topic_token_cnt[topic][token] += 1
topics = list(topic_cnt.keys())
token_distr = {}
for token in token_cnt:
distr = []
for topic in topics:
distr.append(topic_token_cnt[topic][token] / topic_cnt[topic])
token_distr[token] = distr
token_dg = {}
for token in token_distr:
token_dg[token] = dg(token_distr[token]) * math.log(token_cnt[token])Таким образом оценивается значимость слов с точки зрения всех текстов обучающей выборки. Раз используются частотные характеристики встречаемости слов в коллекции, интересно посмотреть на распределение Ципфа. Вот оно (зеленым цветом изображена линейная интерполяция данных):
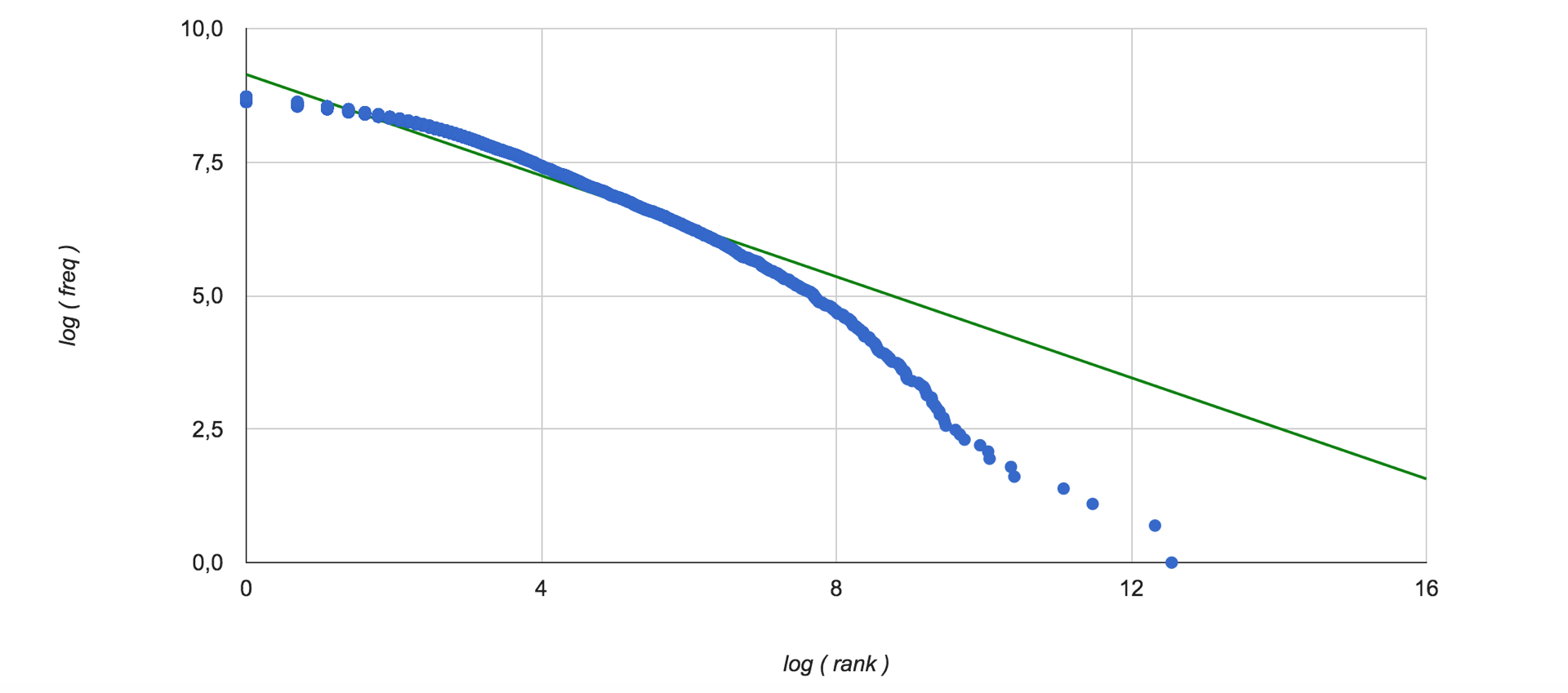
Далее для векторизации классифицируемых текстов, в том числе и в процессе обучения, полученный таким образом вес умножается на частоту слова в данном тексте, и отбираются 5 слов с наибольшим значением этой величины для каждой тематики на данном уровне таксономии. Эти вектора далее конкатенируются, в результате получается вектор длины 5*m, где m – число узлов на уровне. Теперь данные готовы к классификации.
Оценка качества классификатора
Нам хотелось иметь возможность получать одно число для оценки работы всего классификатора в целом. Понятно, что легко рассчитать точность, полноту и F-меру для каждого отдельного узла таксономии, но когда в нее входит не одна сотня классов, толку от этого становится мало. Поскольку классификатор иерархический, качество работы отдельных классификаторов в нижних узлах зависит от качества предшествующих – это ключевая особенность нашего алгоритма. Precision и Recall рассчитываются по следующим формулам:

(где TP – число true positive результатов, FN – число false negative и т.д.)
F-мера это среднее гармоническое между полнотой и точностью, при этом можно устанавливать соотношение, с которым эти величины входят в результат с помощью параметра ?:
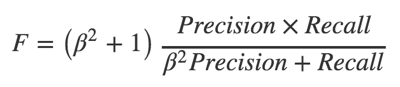
При ?>1 метрика получает перекос в сторону полноты, при 0<?<1 – в сторону точности. Этот параметр мы выбираем в соответствии с долей положительных примеров тестовой выборки для каждой тематики на текущем уровне, ведь чем больше векторов классификатор пропустит дальше, тем больше шансов ошибиться у следующего, и так далее.
Следующий шаг – расчет усредненной F-меры для каждой независимой ветви дерева, то есть для всех дочерних узлов родителя с первого уровня. Поскольку для каждого узла F-мера вычислена уже с учетом состава обучающей выборки, достаточно просто вычислить среднее F-мер всех классификаторов в ветви без дополнительного взвешивания.
Единая метрика для всего классификатора рассчитывается как взвешенное среднее метрик ветвей, вес – доля положительных примеров ветви в выборке. Здесь простым средним уже не обойтись, т.к. количество узлов и поисковых запросов в разных ветвях может сильно отличаться. Можем похвастаться значением ~0,8 для F-меры классификатора целиком, вычисленной таким образом.
Важно отметить, что при тестировании классификатора мы удаляем слова соответствующих поисковых запросов из списка лексем, чтобы избежать обратной связи.
Для визуализации результатов тестирования, используется Google OrgChart – он в первую очередь наглядно изображает древовидную структуру таксономии, а также позволяет указывать значения метрик в каждом узле и даже вешать цветовые индикаторы прямо внутрь листов. Вот как выглядит одна из ветвей:
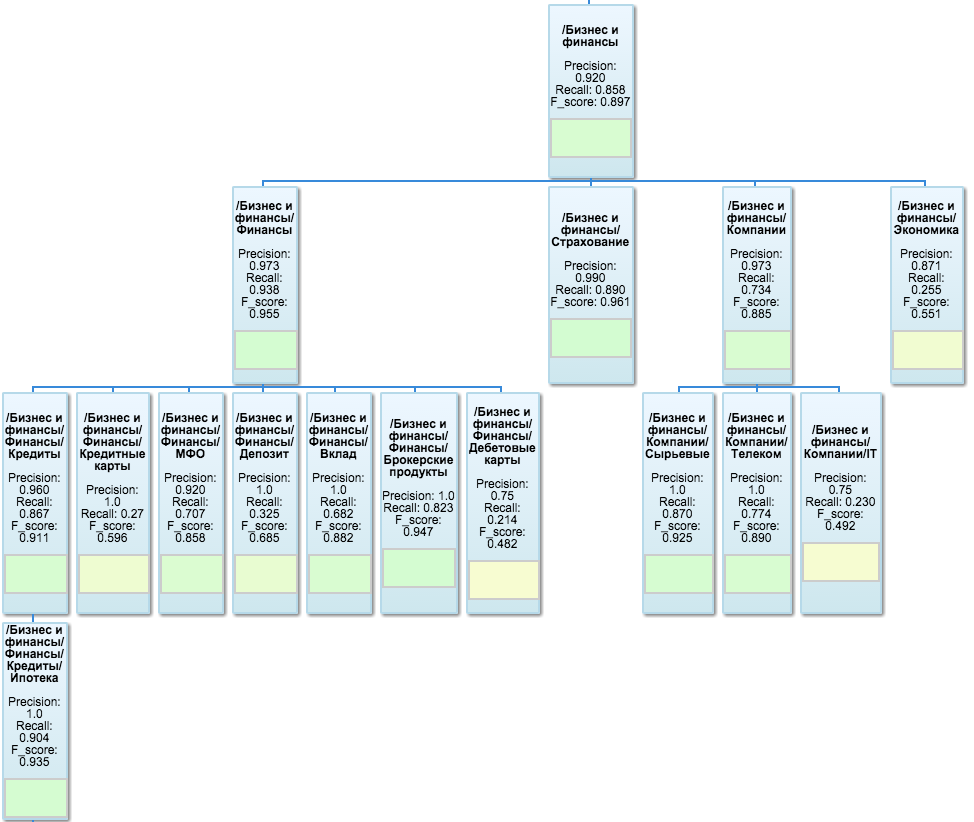
Тестер реализован в виде отдельного Flask приложения, которое по запросу загружает из mongoDB предраcсчитанные значения метрик, дорассчитывает, то, чего не хватает из-за возможных изменений в классификаторе с момента последнего расчета, и рисует orgchart. Как приятное дополнение – оттуда же доступен простенький интерфейс, позволяющий вставить список урлов или plain text в текстовое поле и посмотреть на результат классификации.
Интеграция в DMP
Теперь, когда есть подобный сервис, нужно его активно использовать. Каждый день из нашей DMP выбирается миллион самых посещаемых за прошлый день сайтов и прогоняется через классификатор. Эти сайты помечаются id сегментов, в которые они попали, а пользователи, которые посещали эти страницы в последнем месяце, попадают в эти сегменты. Сейчас классификация одной страницы занимает порядка 0,2 – 0,3 секунды (за вычетом latency хостингов).
Такой подход позволяет автоматически присваивать сегментам тысячи урлов в день, тогда как вручную аналитик обычно добавлял не более сотни страниц. Теперь работа аналитика будет сводится только к выбору подходящих тематике поисковых запросов, все остальное за него сделает DMP и даже сориентирует, насколько качественно это произошло.
Планы на будущее
В первую очередь перед нами стояла задача реализовать работающий прототип классификатора, и на данном этапе мы не особенно заморачивались выбором оптимальных параметров для эстиматоров и прочими настройками. Однако мы не ожидали, что такая довольно простая математическая модель покажет вполне приличное качество работы. Конечно, все прозвучавшие константы алгоритмов можно гибко настраивать, подбору оптимальных настроек возможно будет посвящена отдельная статья. Сейчас в планах следующие работы:
- Мы переведем классификатор на неблокирующий сервер Tornado, чтобы можно было обращаться к нему асинхронно;
- Кроме метрики dg мы рассмотрим различные вариации tf-idf;
- Постараемся особняком учитывать слова, которые содержатся в названии страниц и мета-тегах;
- Покрутим многочисленные настройки эстиматоров, попробуем заменить random forest на ансамбли SVM и увеличим число отбираемых для классификации слов.
Надеемся, что рассказ был интересным. В комментариях ответим на ваши вопросы и с удовольствием обсудим предложения по совершенствованию нашего классификатора.
Комментарии (15)

Spoilt333
02.07.2015 19:20+1Полученные наборы токенов с метками далее случайным образом распределяются на обучающую выборку (60%), выборку для feature selection (15%) и тестовую выборку (15%), – она сохраняется в mongoDB.
А оставшиеся 10% списываете на хоз.нужды?)
ser0t0nin Автор
02.07.2015 19:21нет, обучающая выборка, конечно, 70%

anokhinn
16.07.2015 17:49Все «братья» классификатора переобучаются вместе с изменившимся, потому что обучающая выборка для всего уровня одна и та же – тексты сайтов из ТОП-50 результатов поиска Bing, найденных по запросам из всех узлов-братьев и всех их детей.
Правильно ли я понимаю, что в случае с классификацией двух тематик (пример: есть кошка/есть собака), размер обучающей выборки составляет 70 веб страниц, а тестовой — 15?ser0t0nin Автор
16.07.2015 20:20Нет, каждой тематике можно сопоставить сколько угодно поисковых запросов и по каждому из них будет 50 сайтов (правда странички, найденные по разным запросам, могут совпадать), сейчас число запросов не может быть менее 5, но часто их больше. Кроме того есть так называемые «белый и черный списки» — вручную добавленные странички, которые также участвуют в обучении.
anokhinn
17.07.2015 10:25Собственно, какой в итоге типичный размер обучающей выборки?
ser0t0nin Автор
17.07.2015 11:24Для разных уровней таксономии порядки отличаются. Для верхнего уровня обучающая выборка сейчас в районе 15 000 документов, с 1000 — 3000 положительных примеров на тематику, для нижних уровней — порядка 200 — 300 положительных примеров на 500 — 700 сайтов вообще.
anokhinn
17.07.2015 11:40А какие параметры леса? Тюните как-то?
И кстати, почему ova, у RF с мультиклассом же все в порядке?ser0t0nin Автор
17.07.2015 12:44Пока что я экспериментирую с различными настройками и видами деревьев. Единственного выбранного подхода на данный момент нет. Как появится — напишу.

Swarg
03.07.2015 08:10+1А можете пояснить суть метрики dg? Что подается в аргумент arr и вообще какая была логика выбора этой метрики?
ser0t0nin Автор
03.07.2015 12:31Мы сделали процедуру Feature Selection на основе этой статьи: Demographic Prediction Based on User’s Browsing Behavior. Там приведена формула для случая 2 классов (пункт 4.1.2.2), но мы расширили её на произвольное число классов.
Swarg
03.07.2015 08:14Все «братья» классификатора переобучаются вместе с изменившимся, потому что обучающая выборка для всего уровня одна и та же – тексты сайтов из ТОП-50 результатов поиска Bing, найденных по запросам из всех узлов-братьев и всех их детей.
А почему для подготовки выборки выбран поисковик Bing, а не Яндекс, которые выдает более релевантные сайты на поисковые запросы?ser0t0nin Автор
03.07.2015 11:21У нас есть подписка на Azure, который предоставляет удобный API к Bing, а Яндекс, на сколько я знаю, возвращает результаты только в XML, что нам не очень удобно. Плюс к этому у Яндекса довольно сложная система ограничений на количество запросов и IP-адреса.
А вообще для данной задачи в большей степени важен тематический поиск — нужно находить сайты, на которых много текста заданной тематики. По этому параметру Bing в целом не уступает Яндексу, который скорее ориентирован на навигацию и пользовательские интенты.

Rondo
Чем-то напоминает Яндекс.Атом а если вы зашли в комментарии узнать, что за чертёж на КДПВ — это так называемая myasorubka