
Например, берутся за сложное прогнозирование, которое предложил начальник, но проект останавливается — потому что в компании нет понимания, что и как включить в продакшен, как получить прибыль, как «отбить» потраченные на новую модель ресурсы.

У HeadHunter нет больших вычислительных мощностей, как у «Яндекса» или Google. Мы понимаем, как нелегко катить в продакшен сложный ML. Поэтому многие компании останавливаются на том, что катят в прод простейшие линейные модели.
В процессе очередного внедрения ML в рекомендательную систему и в поиск по вакансиям мы столкнулись с некоторым количеством классических «граблей». Обратите на них внимание, если собираетесь внедрять ML у себя: возможно, этот список поможет по ним не ходить
Грабли № 1: дата-сайентист — свободный художник
В каждой компании, которая начинает внедрять машинное обучение, в том числе нейронные сети в свою работу, существует разрыв между тем, что хочет делать дата-сайентист, и тем, что приносит пользу в продакшене. В том числе потому, что бизнес не всегда может объяснить, что такое польза и как он может помочь.
Мы боремся с этим так: обсуждаем все возникающие идеи, но реализуем только то, что принесет пользу компании — сейчас или в будущем. Не делаем исследований в вакууме.
После каждого внедрения или эксперимента мы считаем качественный, ресурсный и экономический эффекты и обновляем наши планы.
Грабли № 2: обновление библиотек
Эта проблема возникает у многих. Появляется много новых и удобных библиотек, о которых еще пару лет назад никто не слышал, или вообще их не было. Хочется использовать самые свежие библиотеки, потому что они удобнее.
Но есть несколько препятствий:
1. Если в проде используется, например, 14-я Ubuntu, то новых библиотек в ней, скорее всего, просто нет. Выходом является перевод сервиса в docker и установка питоновских библиотек с помощью pip (вместо deb-пакетов).
2. Если для хранения данных используется формат, зависящий от кода (как, например, pickle), это «замораживает» используемые библиотеки. То есть когда модель машинного обучения получена с помощью библиотеки scikit-learn версии 15 и сохранена в формате pickle, то для корректного восстановления модели будет нужна библиотека scikit-learn именно пятнадцатой версии. Вы не можете обновиться до самой последней версии, и это гораздо более коварная ловушка, чем описанная в пункте 1.
Из нее есть два выхода:
- использовать формат хранения моделей, не зависящий от кода;
- всегда иметь возможность заново обучить любую модель. Тогда при обновлении библиотеки нужно будет обучить все модели и сохранить их с новой версией библиотеки.
Мы выбрали второй путь.
Грабли № 3: работа со старыми моделями
Делать что-то новое в старой, изученной модели — менее полезно, чем сделать что-то простое в новой. Часто в конечном итоге оказывается, что от внедрения более простых, но свежих моделей пользы больше, а количество приложенных усилий — меньше. Про это важно помнить и всегда учитывать количество общих усилий в поиске закономерностей.
Грабли № 4: только локальные эксперименты
Многие специалисты по data science любят экспериментировать локально на своих серверах для машинного обучения. Только вот проды такой гибкостью не обладают: в итоге обнаруживается куча причин, по которым нельзя эти эксперименты затащить в продакшен.
Важно настроить коммуникацию между DS-специалистом и инженерами прода для общего понимания — как та или иная модель будет работать в продакшене, имеются ли необходимые для нее мощность и физическая возможность выкатки. Кроме того, чем сложнее модели и факторы, тем сложнее сделать их надёжными и иметь возможность в любой момент обучить их заново. В отличие от соревнований Kaggle, в production зачастую лучше пожертвовать десятитысячными на локальных метриках и даже немного онлайн-KPI, зато внедрить вариант моделей намного более простой, стабильный по результатам и лёгкий по вычислительным ресурсам.
Не ходить по этим граблям нам помогают совместное владение кодом (разработчики и дата-сайентисты знают, как устроен код, написанный другими разработчиками), повторное использование признаков и метапризнаков в различных моделях как в процессе обучения, так и при работе в prod (нам помогает разработанный нами framework), unit- и автотесты, которые мы гоняем очень часто, интеграция кода с перетестированием. Итоговые модели мы кладем в git-репозитории и в продакшене тоже пользуемся ими.
Грабли № 5: тестировать только прод
У каждого нашего разработчика и дата-сайентистов — свой тестовый стенд, иногда не один. На нём развёрнуты основные компоненты production HH. Это дорого, но качество и скорость разработки это окупает. Это необходимо, но не достаточно. Мы нагружаем не только модели, которые уже есть в продакшене, но и те, которые окажутся там в скором времени. Это помогает вовремя понять, что модели, которые прекрасно работают на локальных машинах, тестовых стендах или в production на 5% пользователей, а при включении на 100% оказываются слишком тяжелыми.
Используем несколько стадий тестирования. Очень быстро (это ключевой момент) проверяем код — при добавлении или изменениях компонентов в репозитории код собирается, на соответствующие компоненты запускаются unit- и автотесты, при необходимости мы повторно тестируем их ещё и вручную — и, если что-то не так, даём ответ «у тебя сломано, решай».
Грабли № 6: долгие расчёты и потеря фокуса
Если для обучения какой-то модели требуется, допустим, неделя, легко потерять концентрацию на задаче из-за переключения на другой проект. Мы стараемся не давать разработчикам и data scientist'ам больше чем по две задачи в одни руки. И не больше чем по одной срочной, чтобы на неё можно было переключиться, как только для неё завершатся расчёты или A/B-эксперименты. Это правило необходимо, чтобы не терять фокуса и из опасений, что часть таких задач вообще рискуют быть утраченными, а другая часть — выкатиться сильно позже нужного.
Мы наступили на грабли, но не сдались
Недавно мы закончили эксперимент по внедрению нейросетей в рекомендательную систему. Началось с того, что на внутреннем хакатоне за два дня написали модель прогнозирования откликов по резюме, которая значительно облегчала поиск подходящих вакансий.
Но позже мы узнали: чтобы выкатить ее в продакшен, надо обновить примерно всё — например, перевести систему двойного назначения, которая считает признаки и учит модели, на docker, а также обновить библиотеки машинного обучения.
Как это было
Мы использовали модель DSSM с однослойной нейросетью. В оригинальной статье Microsoft использовалась нейросеть из трех слоев, но улучшения качества при увеличении числа слоев мы не наблюдали, поэтому остановились на одном слое.

Если описывать коротко:
- Текст запроса и заголовок вакансии преобразуются в два вектора символьных триграмм. Мы используем 20000 символьных триграмм.
- Триграммный вектор подается на вход однослойной нейросети. На входе слоя нейросети — 20 000 чисел, на выходе — 64. По сути нейросеть является матрицей размера 20 000 x 64, на которую умножается входной триграммный вектор размерности 1 x 20 000. К результату перемножения добавляется постоянный вектор размерности 1 x 64. Вектор на выходе такой нейросети соответствует запросу (или заголовку вакансии).
- Вычисляется скалярное произведение dssm-вектора запроса и dssm-вектора заголовка вакансии. К произведению применяется функция сигмоида. Итоговый результат и есть метапризнак dssm.
Когда мы попробовали включить эту модель в первый раз, локальные метрики стали лучше, но при попытке выкатить ее в A/B-тест мы увидели, что улучшения не произошло.
После этого мы попробовали увеличить второй слой нейронов до 256 — выкатили на 5% пользователей: оказалось, что рекомендательная система и поиск стали лучше, но при включении модели на 100% внезапно оказалось, что она слишком тяжелая.
Проанализировали, почему модель такая тяжелая, убрали стемминг, проэкспериментировали с этой нейросетью еще раз. И только после этого, пройдя весь путь заново, выяснили, что модель даёт пользу: количество откликов в рекомендательной системе увеличилось на 700 в сутки, а в поиске, после всех пересчетов, — на 4200.
Внедрение такой не очень сложной нейросети позволяет нашим клиентам нанимать через hh.ru дополнительно несколько десятков сотрудников каждый день, и при внедрении мы победили значительную часть больших проблем. Поэтому планируем развивать у себя нейросети дальше. В планах — попробовать общий стемминг, дополнительную лемматизацию, обрабатывать полные тексты вакансии и резюме, сделать эксперименты с топологией (скрытые слои и, возможно, RNN/LSTM).
Самое важное, что мы сделали с этой моделью:
- Не бросили эксперимент посередине.
- Посчитали показатели увеличения откликов и выяснили, что работа над этой моделью того стоит. Очень важно понимать, сколько пользы приносит каждое такое внедрение.
Интересно, что модель, которую мы делали и в итоге добавили в прод, очень похожа на метод главных компонент (PCA), примененный к матрице [текст запроса, заголовок документа, был ли клик]. То есть к матрице, у которой строка соответствует уникальному запросу, столбец — уникальному заголовку вакансии; значение в ячейке равно 1, если после данного запроса пользователь кликнул на вакансию с данным заголовком, и 0, если клика не было.
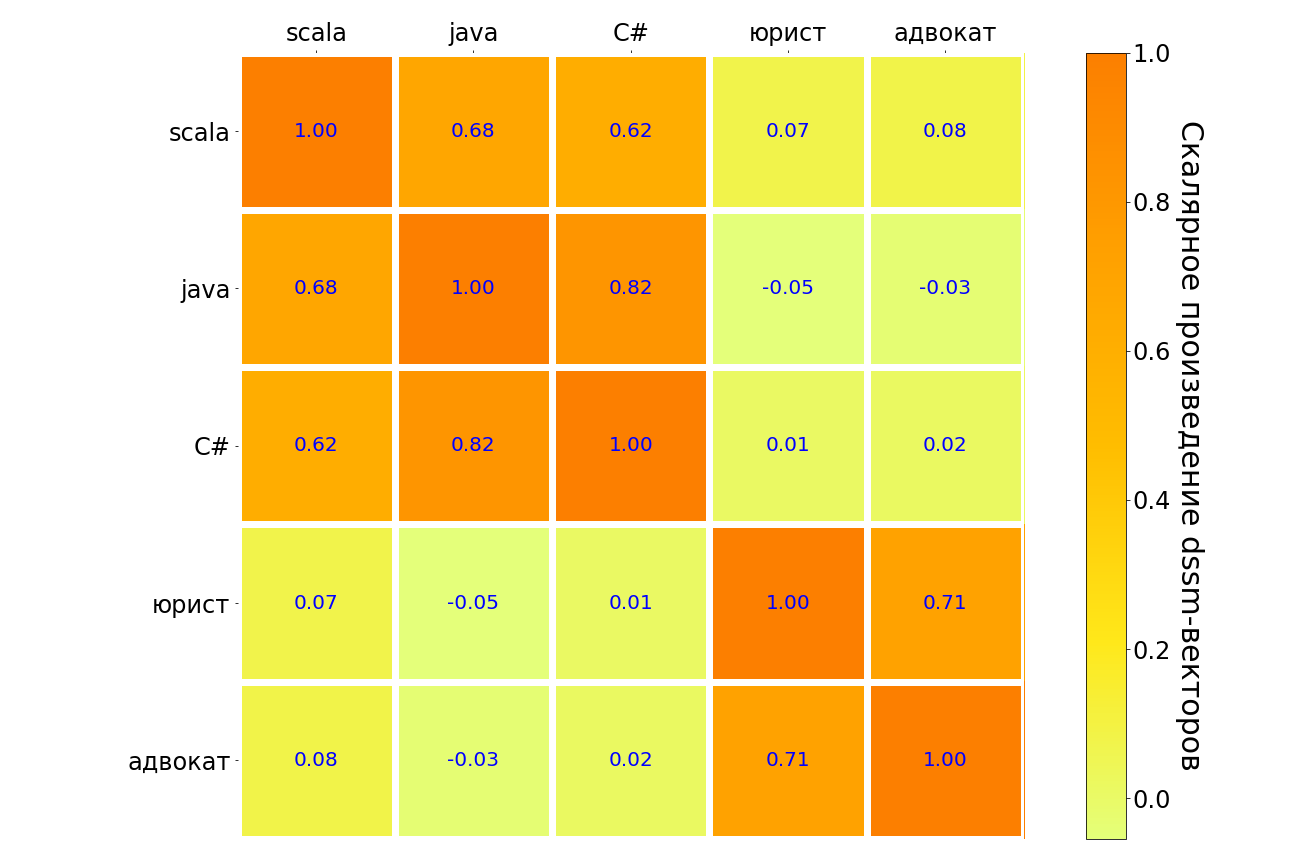
Результаты применения такой модели к запросам scala, java, C#, «юрист», «адвокат» — в табличке ниже. Сходные по смыслу пары запросов выделены темным, непохожие — светлым. Видно, что модель понимает связь между разными языками программирования, между запросом «юрист» и «адвокат» есть сильная связь. А вот между «адвокат» и любым языком программирования связь очень слабая.
В какой-то момент очень сильно хочется сдаться — эксперименты идут, но не «зажигаются». В этом месте дата-сайентисту может пригодиться поддержка команды и очередной подсчет приносимой пользы: возможно, действительно стоит «закопать стюардессу» и не пытаться «скакать на мертвой лошади», это не провал, а успешно проведенный эксперимент с отрицательным результатом. Или, взвесив все за и против, вы проведете очередной эксперимент, который «выстрелит». Так это случилось с нами.
Комментарии (8)

nikola_sa
29.06.2018 09:42Интересно, получается что у адвокаты и юристы склонны к Scala и c#, а к Java. Почему так?
alextheraven Автор
29.06.2018 15:04На самом деле, нейросеть одинаково не находит между этими терминами связи, значения прогноза на уровне сотых — в пределах случайной погрешности.
ttys
29.06.2018 17:14Может стоило начать статью с определентя, что такое ML?
Из личного опыта скажу, что люди часто произносят слова не понимая их значения. И думашь то ли лыжи не едут, то ли ...alextheraven Автор
29.06.2018 17:29Возможно, но тогда мог бы выйти бодрый спор об определениях, наподобие «как это машина автоматически подбирает функции, решающие правила, когда pipeline для этого настраивает и запускает человек? линейная регрессия в Excel это уже ML или ещё нет? а в scikit-learn? а если сначала коэффициенты подобрали ML'ем, а потом подправили, ввели бустинги и fixlist'ы вручную — было машинное обучение, а какое стало?»
ChePeter
Грабли #1. Редчайший случай, когда саентист занимался успешно управлением бизнеса. От специалиста DS требуют звезды kaggle, github и пр.пр. ( и HH это уж точно может проверить по всем вакансиям в т.ч. своим) Но в бизнесе то он никогда никаких решений не принимал и перед акционерами за прибыль не отвечал. Кажется пропущен интерфейс между двумя мирами. Одни думают что решают правильную задачу, а другие думают, что выгодную. Но получается как всегда.
Грабли #2 — 5. Код для RD и код для прода отличаются всегда и существенно. Полностью различные цели и задачи. В RD алгоритм решения не известен полностью и идет поиск именно его — а иначе зачем R&D? В проде алгоритм известен весь и решается задача его оптимальной реализации — с учетом действующей инфраструктуры и экологии данного конкретного бизнеса. Любой другой путь приводит к граблям. Путь проверен и эффективен — НИР, ОКР, Прод. Можно сокращать этапы, совмещать частично, можно как угодно приспосабливать и коверкать скрамами, матом и канбаном — но без них будут грабли, не будет ответа нужного.
Грабли #6. Фундаментальная организационная проблема. Если задача после того, как ее решали 2 недели, забылась — или задача не нужна или поставлена некорректно. И, судя по применению A/B тестов, скорее всего второе. Если задача поставлена корректно — она понятна DS, DE и бизнесу и что бы забыли все сразу! Это что то исключительное. Самая большая проблема — корректная, с точки зрения математики, задача, с приемлемым приближением реальности и при этом предлагающая решение бизнес проблемы.
Отличный пример живого проведения RD и DS в реальном бизнесе. Очень полезный и наглядный пост.
PavelMSTU
Если требуют — бегите от такого работодателя! Это такой же миф, как тот, что «олимпиадное программирование» == «хорошее программирование для бизнеса». Быть крутым «олимпиадником» не помешает, разумеется, но это РАЗНЫЕ вещи!!!
Да я тоже занимался «академической наукой»… Но опять же реальность немного другая. Фактически есть «быстрые R&D» и «долгие R&D». Бывают случаи когда нужно просто решить задачу… и так, чтобы сразу (ну почти сразу) в продакшн…
Жизнь разная бывает. Не все в Яндексах и Гуглах работают…
Femistoklov
Butt-head
DS по определению занимается обратными и некорректно поставленными задачами