
Во время выполнения заказа по разработке telegram бота у меня возникла необходимость получения скриншота веб-страницы с его доставкой пользователю. Зачем задумываться над решением проблемы, когда его можно найти? Как оказалось, чтобы не платить! Подробнее пот катом.
Так вот, судьба натолкнула меня на сервис url2png. Вроде бы всё круто: регистрируешься, получаешь API токен и делаешь себе запросы. Но как бы не так.
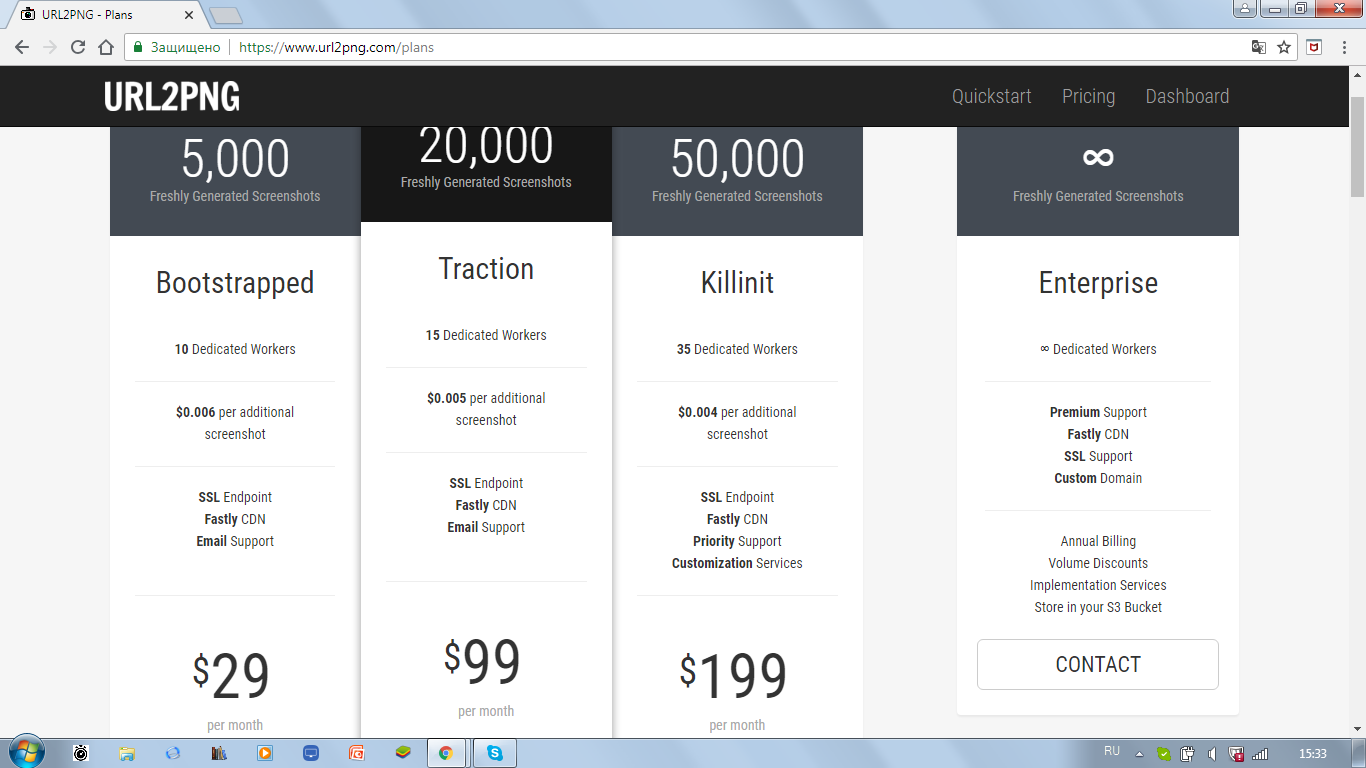
Нет, ну серьёзно, VDS под несколько телеграм ботов дешевле стоит! И тут мне стало ясно, что придётся выкручиваться всеми доступными способами. Долго ломать голову не пришлось, благо нашлась такая вещь как Selenium. Selenium требует для работы установки специального драйвера в соответствии с используемым браузером. Предупреждаю, что PhantomJS больше не поддерживается Selenium'ом, поэтому для работы в headless режиме(при запуске webdriver окно браузера не открывается) будет использоваться google chrome. Как настроить для этого VDS? Перво-наперво надо установить сам браузер. В консоли нужно ввести следующие команды.
sudo apt update
sudo apt install -y chromium-browserПосле, по этой ссылке необходимо узнать последнюю версию chromedriver(2.41 на данный момент). Установить его нужно следующими командами.
wget https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
sudo mv chromedriver /usr/bin/chromedriver
sudo chown root:root /usr/bin/chromedriver
sudo chmod +x /usr/bin/chromedriverТакже хочется отметить, что для отладки телеграм бота на своей машине придётся установить VPN, если вы находитесь в России. На мой взгляд одним из лучших решений будет сервис Windscribe, так как сразу после регистрации можно получить халявные 15 GB трафика на высокой скорости в месяц. Теперь можно приступать к разработке бота. Понадобятся библиотеки:
pytelegrambotapi
selenium
validatorsУстановить их можно спокойно с помощью pip. Начало скрипта выглядит так.
# -*- coding: utf-8 -*-
import telebot
import os
import validators
from selenium import webdriverСначала я создал бота и настроил браузер для работы в headless режиме.
#создаём бота
token = 'token of this bot'
bot = telebot.TeleBot(token, threaded = False)
#настраиваем браузер для корректной работы в headless режиме
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')Потом релизовал приветствие и помощь пользователю.
#имплементация обязательных команд /start и /help
@bot.message_handler(commands=['start'])
def hello_user(message):
bot.send_message(message.chat.id, 'Hello, ' + message.from_user.username + "!")
@bot.message_handler(commands=['help'])
def show_help(message):
bot.send_message(message.chat.id, 'To get screenshot of webpage use command /getpng.\nExample: /getpng https://www.google.com')Осталось самое главное — получение скриншота. С помощью библиотеки validators осуществляется валидация(извините за тавтологию) введённой пользователем ссылки. Также с помощью модуля os скриншот удаляется с сервера после отправки, дабы не занимать место.
#получение скрина сайта с помощью selenium и headless chrome
@bot.message_handler(commands=['getpng'])
def get_screenshot(message):
uid = message.chat.id
url = ""
try:
url = message.text.split(' ')[1]
except IndexError:
bot.send_message(uid, 'You have not entered URL!')
return
if not validators.url(url):
bot.send_message(uid, 'URL is invalid!')
else:
photo_path = str(uid) + '.png'
driver = webdriver.Chrome(chrome_options = options)
driver.set_window_size(1280, 720)
driver.get(url)
driver.save_screenshot(photo_path)
bot.send_photo(uid, photo = open(photo_path, 'rb'))
driver.quit()
os.remove(photo_path)Запускаем бота и проверяем его работу!
#запуск бота
if __name__ == '__main__':
bot.infinity_polling()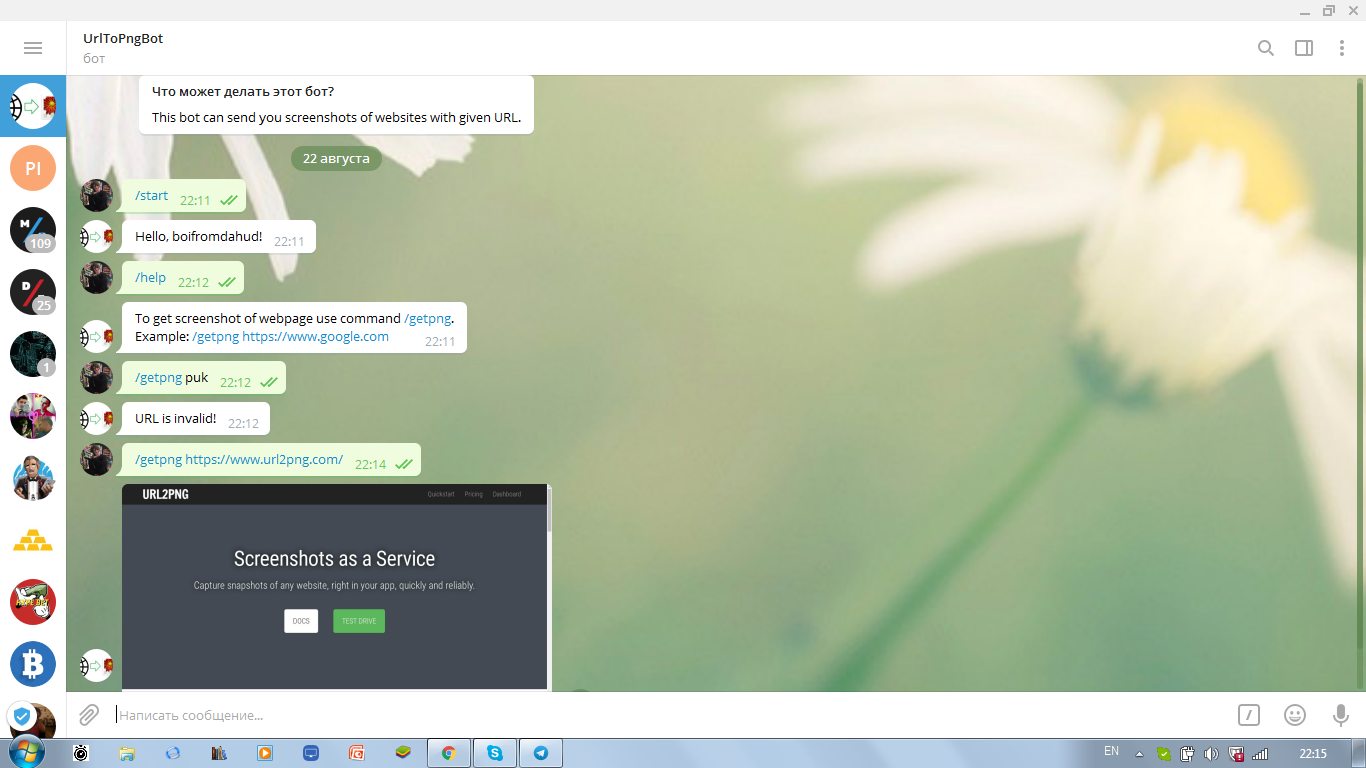
As you can see, всё работает замечательно. Конечно, всякие плюшки можно доработать, но я поставил перед собой цель построить фундамент и достиг её. Собственно, ссылка на бота для желающих и на гитхаб репозиторий для интересующихся. Ну а пока всем добра, увидимся в следующих публикациях!
Комментарии (19)

Kirtis
23.08.2018 00:06+6А у GitHub'а поменялся адрес?

А по боту, вызывает сомнения кусок кода:
photo_path = str(uid) + '.png'
Хоть у меня и не получилось воспроизвести баг, при котором при быстрой отправке двух запросов отправится скриншот последней страницы (или вообще битый), но это только из-за того, что сейчас запросов, видимо, слишком много (харабэффект?). Если же у вас программа работает в один поток (что тоже может помочь избежать этого бага), то производительность должно быть очень низкая. ИМХО, лучше генерировать уникальный id каждый раз.
ZXZs
23.08.2018 00:22+6Да, поменялся. На сокращалку ссылок с рекламой.

ZloyKishechnik
23.08.2018 07:28+3а разве такое не запрещено правилами хабра? что-то мне не особо хочется переходить по ссылке и смотреть рекламу; я хочу провалиться сразу на гит, а не на corneey…
kITerE
23.08.2018 08:43Ага, как и линки с советами от чистого сердца:

ZloyKishechnik
23.08.2018 10:08+2может, не стоит так говорить, но понятно, почему у автора карма в «минусе», а его посты находятся в рекавери…
selivanov_pavel
23.08.2018 02:54+3А вот готовая скриншотилка сразу для запуска в докере, сделал мой бывший коллега: https://github.com/agentsib/siteshot-php Использует wkhtmltopdf.
dmitriylyalyuev
23.08.2018 08:40Ох и огород. Хром из консоли сам скрины умеет. https://developers.google.com/web/updates/2017/04/headless-chrome
kAIST
23.08.2018 08:53Кстати, при таком подходе, селениум каждый раз запускает хром для одного скриншота, а потом его закрывает? Я правильно понимаю?
ogost
23.08.2018 09:45строчка
driver.quit()
как раз закрывает хром.
И выше уже заметили, хром из коробки в headless режиме умеет делать скриншоты, selenium тут немного оверкилл.
dmxrand
23.08.2018 10:01>photo_path = str(uid) + '.png'
Ааааааааааааа docs.python.org/3/library/tempfile.html
napa3um
А теперь попробуйте продать аналогичный сервис широкому кругу клиентов, и оцените, какое количество запросов в единицу времени потянет ваш сервис на вашем железе. Очень может оказаться, что цены платного сервиса соответствуют не 39-ти строчкам кода, а совершенно другим ресурсам. (Не знаю, может и не окажется дорого, но навскидку представляется, что больше страниц ста одновременно вы на своих мощностях открыть не сможете, а учитывая время их загрузки/выгрузки окажется, что уже при достижении 20-50 пользователей в час пик они начнут испытывать дискомфорт от таймаутов.)
Так-то и «убийцу фейсбука» для своего локалхоста можно уложить в пару тыщ строчек, наверное. И зарегистрировать там пару тестовых пользователей даже.
format1981
Автор хотел сказать, что не нужен ему такой сервис, потому что для себя сделает аналогичный который справится с его нагрузкой на дешевом VPS.
ZXZs
Автор же указал, что это лишь фундамент. Для хайлоад-среды можно попробовать прикрутить asyncio, aiohttp, tornado и им подобные. После асинхронщины прикручиваем Centrifuge, она для этого и создана — разгружать большие очереди.
А ещё лучше будет переписать всё на NodeJS или какой-нибудь Erlang\Elixir с Go. Python это конечно классно, сам его люблю, но он медленный, собака. Медленнее Java раз в пять.
Sabubu
Основной пожиратель ресурсов тут скорее всего Хром (а также затраты времени на его инициализацию), так что «асинхронная среда» или переход на Го мало чем поможет. Вы слона не видите.
Stefanio Автор
format1981 прав, а фундамент как раз в контексте своей маленькой пиратской копии, которую я буду дорабатывать по мере надобности.
kITerE
А что в ней пиратского-то?