

Многие, кто изучает машинное обучение, знакомы с проектом OpenAI, одним из основателей которого является Илон Маск, и используют в качестве среды для тренировки своих моделей нейронных сетей платформу OpenAI Gym.
Gym содержит огромный набор окружений, часть из них — различного рода физические симуляции: движения животных, человека, роботов. Данные симуляции основаны на физическом движке MuJoCo, который является бесплатным для образовательных и научных целей.
В данной статье мы создадим предельно простую физическую симуляцию подобную окружению OpenAI Gym, но основанную на свободном физическом движке Bullet(PyBullet). А так же создадим агента для работы с этим окружением.
PyBullet представляет собой python модуль для создания среды физической симуляции на основе физического движка Bullet Physics. Он, так же как MuJoCo, довольно часто используется в качестве стимуляций различных роботов, кому интересно на habr есть статья с реальными примерами.
Для PyBullet есть довольно хороший QuickStartGuide, который содержит ссылки на примеры на странице с исходниками на GitHub.
PyBullet позволяет загружать уже созданные модели в формате URDF, SDF или MJCF. В исходниках есть библиотека моделей в данных форматах, а так же полностью готовые окружения симуляторов реальных роботов.
В нашем случае мы сами создадим окружение средствами PyBullet. Интерфейс окружения будет аналогичным интерфейсу OpenAI Gym. Таким образом мы сможем тренировать наших агентов как в нашей среде, так в среде Gym.
Весь код (iPython), а так же работу программы можно увидеть в Google Colaboratory.
Окружение (Environment)
Наша среда будет состоять из шара который может передвигаться по вертикальной оси в пределах определенного диапазона высот. Шар обладает массой, и на него действует сила тяжести, а агент должен, управляя приложенной к шару вертикальной силой, привести ее к цели. Целевая высота меняется с каждым перезапуском опыта.

Симуляция очень простая, и по сути может быть рассмотрена как симуляция какого-нибудь элементарного движителя.
Для работы с окружением используются 3 метода: reset (перезапуск опыта и создание всех объектов среды), step (применение выбранного действия и получение результирующего состояния среды), render (визуальное отображение окружения).
При инициализации окружения необходимо подключить наш объект к физической симуляции. Возможны 2 варианта подключения: с графическим интерфейсом (GUI) и без (DIRECT).В нашем случае — это DIRECT.
pb.connect(pb.DIRECT)reset
При каждом новом опыте мы сбрасываем симуляцию pb.resetSimulation() и создаем все объекты окружения снова.
В PyBullet объекты имеют 2 формы: форма столкновений (Collision Shape), и форма отображения (Visual Shape). Первая используется физическим движком для вычисления столкновений объектов и, для ускорения вычисления физики, обычно имеет более простую форму чем реальный объект. Вторая не обязательна, и используется только при формировании изображения объекта.
Формы собираются в единый объект(тело) — MultiBody. Тело может быть составлено из одной формы(пары CollisionShape/Visual Shape), как в нашем случае, или же нескольких.
Кроме форм, составляющих тело, надо определить его массу, положение и ориентацию в пространстве.
Несколько слов о многообъектных телах.
Как правило, в реальных случаях, для симуляции различных механизмов, используются тела состоящие из множества форм. При создании тела, помимо базовой формы столкновений и визуализации, телу передаются цепочки форм дочерних объектов(Links), их положение и ориентация относительно предыдущего объекта, а так же типы соединений(сочленений) объектов между собой (Joint). Типы соединений могут быть фиксированными, призматичесаими(скользящими в пределах одной оси) или вращательными(вращающиеся относительно одной оси). Последние 2 вида соединений позволяют устанавливать параметры соответствующих видов моторов (JointMotor), таких как действующая сила, скорость движения или крутящий момент, симулируя таким образом двигатели “суставов” робота. Подробнее в документации.
Мы создадим 3 тела: Шар, Плоскость(землю) и Указатель цели. Последний объект будет иметь только форму визуализации и нулевую массу, поэтому не будет участвовать в физическом взаимодействии между телами:
# поверхность
floorColShape = pb.createCollisionShape(pb.GEOM_PLANE)
# для плоскости (GEOM_PLANE), visualShape - не отображается при рендеринге, будем использовать GEOM_BOX
floorVisualShapeId = pb.createVisualShape(pb.GEOM_BOX,halfExtents=[100,100,0.0001], rgbaColor=[1,1,.98,1])
pb_floorId = pb.createMultiBody(0,floorColShape,floorVisualShapeId, [0,0,0], [0,0,0,1])
# шар
PB_BallRadius = 0.2
PB_BallMass = 1
ballPosition = [0,0,5]
ballOrientation=[0,0,0,1]
ballColShape = pb.createCollisionShape(pb.GEOM_SPHERE,radius=PB_BallRadius)
ballVisualShapeId = pb.createVisualShape(pb.GEOM_SPHERE,radius=PB_BallRadius, rgbaColor=[1,0.27,0,1])
pb_ballId = pb.createMultiBody(PB_BallMass, ballColShape, ballVisualShapeId, ballPosition, ballOrientation)
# указатель цели
TARGET_Z = 8
targetPosition = [0,0,TARGET_Z]
targetOrientation=[0,0,0,1]
targetVisualShapeId = pb.createVisualShape(pb.GEOM_BOX,halfExtents=[1,0.025,0.025], rgbaColor=[0,0,0,1])
pb_targetId = pb.createMultiBody(0,-1, targetVisualShapeId, targetPosition, targetOrientation)
Определим гравитацию и время шага симуляции.
pb.setGravity(0,0,-10)
pb.setTimeStep(1./60)Для того, чтобы шар не упал сразу же после запуска симуляции, уравновесим гравитацию.
pb_force = 10 * PB_BallMass
pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)step
Агент выбирает действия на основе текущего состояния окружения, после чего вызывает метод step и получает новое состояние.
Определены 2 вида действия: увеличение и уменьшение действующей на шар силы. Предельные значения силы ограничены.
После изменения действующей на шар силы, запускается новый шаг физической симуляции pb.stepSimulation(), и агенту возвращаются следующие параметры:
observation — наблюдения (состояние среды)
reward — награда за совершенное действие
done — флаг окончания опыта
info — дополнительная информация
В качестве состояний среды возвращаются 3 значения: расстояние до цели, текущая приложенная на шар сила, и скорость шара. Значения возвращаются нормализованными(0..1), так как параметры среды, определяющие эти значения, могут изменяться в зависимости от нашего желания.
# текущее положение и ориентация (берем только положение по оси Z curPos[2])
curPos, curOrient = pb.getBasePositionAndOrientation(pb_ballId)
# линейная и угловая скорость (берем только линейную скорость по оси Z lin_vel[2])
lin_vel, ang_vel= pb.getBaseVelocity(self.pb_ballId)Награда за совершенное действие равна 1, если шар находится рядом с целью(целевая высота плюс/минус приемлемая величина качения TARGET_DELTA) и 0 в остальных случаях.
Опыт завершается, если шар выходит за пределы зоны (падает на землю или высоко улетает). Если шар достигает цели, опыт так же завершается, но только после истечения определенного времени (STEPS_AFTER_TARGET шагов опыта). Таким образом наш агент обучается не только двигаться к цели, но и останавливаться и находится рядом с ней. С учетом того, что награда при нахождении рядом с целью равна 1, полностью успешный опыт должен иметь суммарную награду равную величине STEPS_AFTER_TARGET.
В качестве дополнительной информации для отображения статистики возвращается общее количество шагов выполненных в рамках опыта, а также количество шагов выполненных в секунду.
render
PyBullet имеет 2 возможности рендеринга изображений — GPU визуализация на основе OpenGL и CPU на основе TinyRenderer. В нашем случае возможна только CPU реализация.
Для получения текущего кадра симуляции необходимо определить видовую матрицу и проекционную матрицу, после чего получить rgb-изображение заданных размеров с камеры.
camTargetPos = [0,0,5] # расположение цели (фокуса) камеры
camDistance = 10 # дистанция камеры от цели
yaw = 0 # угол рыскания относительно цели
pitch = 0 # наклон камеры относительно цели
roll=0 # угол крена камеры относительно цели
upAxisIndex = 2 # ось вертикали камеры (z)
fov = 60 # угол зрения камеры
nearPlane = 0.01 # расстояние до ближней плоскости отсечения
farPlane = 20 # расстояние до дальной плоскости отсечения
pixelWidth = 320 # ширина изображения
pixelHeight = 200 # высота изображения
aspect = pixelWidth/pixelHeight; # соотношение сторон изображения
# видовая матрица
viewMatrix = pb.computeViewMatrixFromYawPitchRoll(camTargetPos, camDistance, yaw, pitch, roll, upAxisIndex)
# проекционная матрица
projectionMatrix = pb.computeProjectionMatrixFOV(fov, aspect, nearPlane, farPlane);
# рендеринг изображения с камеры
img_arr = pb.getCameraImage(pixelWidth, pixelHeight, viewMatrix, projectionMatrix, shadow=0, lightDirection=[0,1,1],renderer=pb.ER_TINY_RENDERER)
w=img_arr[0] #width of the image, in pixels
h=img_arr[1] #height of the image, in pixels
rgb=img_arr[2] #color data RGB
dep=img_arr[3] #depth dataВ конце каждого опыта на основе собранных изображений генерируется видео.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000)
display(HTML(ani.to_html5_video()))
Агент
В качестве основы для Агента брался код пользователя GitHub jaara, как простой и понятный пример реализации обучения с подкреплением для среды Gym.
Агент содержит 2 объекта: Memory — хранилище для формирования обучающих примеров и Brain собственно нейросеть, которую он тренирует.
Тренируемая нейросеть создана на TensorFlow с помощью библиотеки Keras, которая с недавних пор полностью включена в TensorFlow.
Нейросеть имеет простую структуру — 3 слоя, т.е. всего 1 скрытый слой.
Первый слой содержит 512 нейронов и имеет количество входов равное количеству параметров состояния среды (3 параметра: расстояние до цели, сила и скорость шара). Скрытый слой имеет размерность равную первому слою — 512 нейронов, на выходе соединен с выходным слоем. Количество нейронов выходного слоя соответствует количеству выполняемых Агентом действий (2 действия: уменьшение и увеличение действующей силы).
Таким образом на вход сети подается состояние системы, а на выходе имеем выгоду для каждого из действий.
Для двух первых слоев в качестве функций активаций используется ReLU(rectified linear unit), для последнего — линейная функция (проста сумма входных значений).
В качестве функции ошибки MSE(среднеквадратичная ошибка), в качестве алгоритма оптимизации — RMSprop (Root Mean Square Propagation).
model = Sequential()
model.add(Dense(units=512, activation='relu', input_dim=3))
model.add(Dense(units=512, activation='relu'))
model.add(Dense(units=2, activation='linear'))
opt = RMSprop(lr=0.00025)
model.compile(loss='mse', optimizer=opt)
После каждого шага симуляции Агент сохраняет результаты данного шага в виде списка (s, a, r, s_):
s — предыдущее наблюдение(состояние окружения)
a — выполненное действие
r — награда, полученная за выполненное действие
s_ — конечное наблюдение после выполнения действия
После этого Агент получает из памяти случайный набор примеров за предыдущие периоды и формирует обучающий пакет(batch).
В качестве входных значений (X) пакета берутся первоначальные состояние s из выбранных из памяти случайных шагов.
Реальные значения выходных для обучения (Y’) вычисляются следующим образом: На выходе (Y) нейросети для s будет значения Q-функции для каждого из действий Q(s). Из этого набора агент выбрал действие с наибольшим значением Q(s,a)=MAX(Q(s)), совершил его и получил награду r. Новое значение Q для выбранного действия a будет Q(s,a) = Q(s,a) + DF*r, где DF — фактор дисконтирования. Остальные значения выходов останутся прежними.
STATE_CNT = 3
ACTION_CNT = 2
batchLen = 32
# начальные состояния из пакета
states = numpy.array([ o[0] for o in batch ])
# начальные состояния из пакета
states_ = numpy.array([ o[3] for o in batch ])
# выгоды для начальных состояний
p = agent.brain.predict(states)
# выгоды для конечных состояний
p_ = agent.brain.predict(states_)
# сформируем пустой обучающий пакет
x = numpy.zeros((batchLen, STATE_CNT))
y = numpy.zeros((batchLen, ACTION_CNT))
# заполним пакет
for i in range(batchLen):
o = batch[i]
s = o[0]; a = o[1]; r = o[2]; s_ = o[3]
t = p[i] # выгоды действий для начального состояния
# обновим выгоду только для совершенного действия, для неиспользованных действий выгоды останутся прежними
t[a] = r + GAMMA * numpy.amax(p_[i]) # вычислим новую выгоду действия используя награду и максимальную выгоду конечного состояния
# сохраним значения в batch
x[i] = s
y[i] = t
# обучим сеть по данному пакету
self.brain.train(x, y)По сформированной пачке происходит обучение сети
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)После завершения опыта генерируется видео
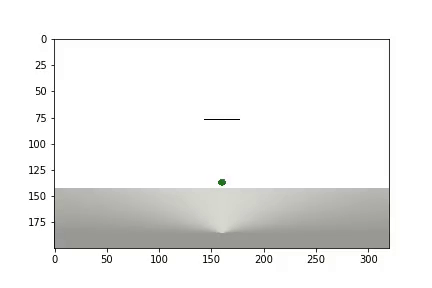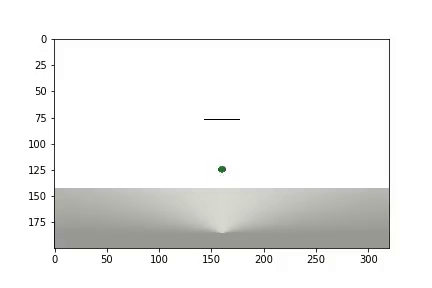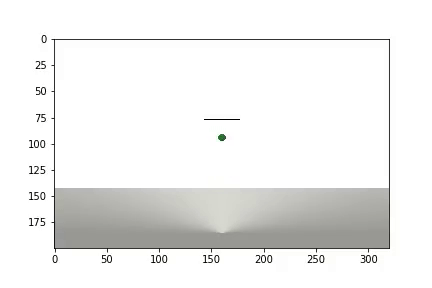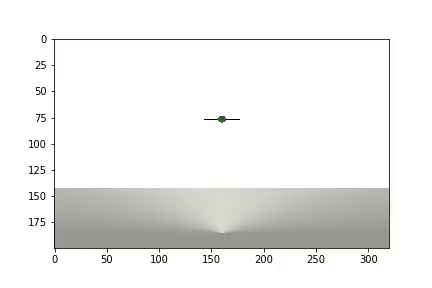
и отображается статистика
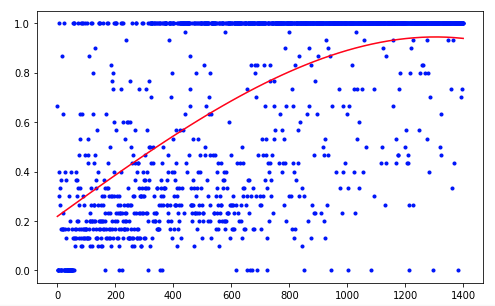
Агенту потребовалось 1200 опытов чтобы достичь примерно 95 процентного результата (количество успешных шагов). А уже к 50-му опыту Агент научился двигать шар к цели(исчезают неудачные опыты).
Для улучшения полученных результатов, можно попробовать изменить размеры слоев сети (LAYER_SIZE), параметр фактора дисконтирования (GAMMA) или скорости уменьшения вероятности выбора случайного действия(LAMBDA).
Наш Агент имеет самую простую архитектуру — DQN (Deep Q-Network). На такой простой задаче ее достаточно, чтобы получить приемлемый результат.
Использование, например, архитектуры DDQN (Double DQN) должна дать более плавное и точное обучение. А сеть RDQN (Recurrent DQN) сможет прослеживать закономерности изменения среды во времени, что даст возможность избавиться от параметра скорости шара, уменьшив количество входных параметров сети.
Также можно расширить нашу симуляцию, добавив изменяемую массу шара или угол наклона его движения.
Но это уже в следующий раз.
ser-mk
а не многовато нейронов для 3 параметров?
А для первого периода откуда они берутся?
zishnik Автор
При данных параметрах обучения сеть меньших размеров обучается хуже и менее стабильно. Но думаю можно уменьшить размеры сети, подобрав оптимальные значения параметров фактора дисконтирования, диапазона и скорости уменьшения выбора случайных действий.
Первые шаги симуляции проходят без обучения, пока не появится достаточно примеров для формирования первого batch-а для обучения.