
Пару лет назад я завершил проект миграции в сети одного из наших клиентов, задача заключалась в смене платформы, которая осуществляет распределение нагрузки между серверами. Схема предоставления сервисов этого клиента эволюционировала в течении почти 10-ти лет вместе с новыми разработками в индустрии ЦОД, поэтому «придирчивый», в хорошем смысле этого слова, клиент ожидал решения, которое удовлетворяло бы не только требованиям отказоустойчивости сетевого оборудования, балансировщиков нагрузки и серверов, но и обладало бы такими свойствами как масштабируемость, гибкость, мобильность и простота. В этой статье я постараюсь последовательно, от простого к сложному, изложить основные примеры использования балансрровщиков нагрузки без привязки к производителю, их особенности и методы сопряжения с сетью придачи данных.
Балансировщики нагрузки сейчас все чаще называют контроллерами доставки приложений (Application Delivery Controller — ADC). Но если приложения работают на сервере зачем их куда-то доставлять? Из соображений отказоустойчивости или масштабирования приложение может быть запущено более чем на одном сервере, в этом случае нужен своего рода обратный прокси-сервер, который спрячет от потребителей внутреннюю сложность, выберет нужный сервер, доставит на него запрос и проследит за тем, чтобы сервер вернул корректный, с точки зрения протокола, результат, иначе — выберет другой сервер и отправит запрос туда. Для осуществления этих функций ADC должен понимать семантику протокола прикладного уровня, с которым он работает, это позволяет настраивать appication specific правила доставки трафика, анализа результата и проверки состояния сервера. Например, понимание семантики HTTP, делает возможной конфигурацию, когда HTTP запросы
отправляются на одну группу серверов с последующим сжатием результатов и кешированием, а запросы
обрабатываются по совершенно другим правилам.
Понимание семантики протокола позволяет организовывать сессионность на уровне объектов прикладного протокола, например, с помощью HTTP Headers, RDP Cookie, или осуществлять мультиплексирование запросов чтобы заполнять одну транспортную сессию многими пользовательскими запросами если прикладной уровень протокола позволяет это делать.
Сферу применения ADC иногда неоправданно представляют себе только обслуживанием HTTP трафика, на самом деле список поддерживаемых протоколов у большинства производителей гораздо шире. Даже работая без понимания семантики протокола прикладного уровня ADC может быть полезен для решения тех или иных задач, так например я принимал участие в построении самодостаточной виртуальной фермы SMTP серверов, в период спам-атак количество экземпляров увеличивается с помощью управления с обратной связью по длине очереди сообщений, чтобы обеспечить удовлетворительное время проверки сообщений ресурсоёмкими алгоритмами. Во время активации сервер регистрировался на ADC и получал свою порцию новых TCP сессий. В случае SMTP такая схема работы была вполне оправдана из-за высокой энтропии соединений на сетевом и транспортном уровнях, для равномерного распределения нагрузки во время спам-атак ADC требуется только поддержка TCP. Похожая схема может применяться для построения фермы из серверов баз данных, высоконагруженных кластеров DNS, DHCP, AAA или Remote access серверов, когда сервера можно считать равнозначными в предметном домене и когда их характеристики производительности не слишком сильно отличаются друг от друга. Углубляться в тему особенностей протоколов дальше я не буду, этот аспект слишком обширен чтобы излагать его во вступлении, если что-то покажется интересным — пишите, возможно это повод для статьи с более глубоким изложением какого-то варианта применения, а теперь перейдем к сути.
Чаще всего ADC замыкает на себя транспортный уровень, поэтому сквозная TCP сессия между потребителем и сервером становится составной, потребитель устанавливает сессию с ADC, а ADC — с одним из серверов.
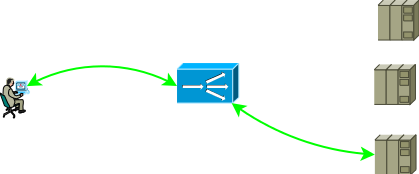
Рис.1
Конфигурация сети и настройки адресации должны обеспечивать такое продвижение трафика чтобы две части TCP сессии прошли через ADC. Самый простой вариант заставить трафик первой части прийти на ADC заключается в присвоении адресу сервиса одного из интерфейсных адресов ADC, со второй частью возможны такие варианты:
На самом деле чуть более реалистичный вид первой схемы применения выглядит уже вот так, это базис, с которого мы начнем:
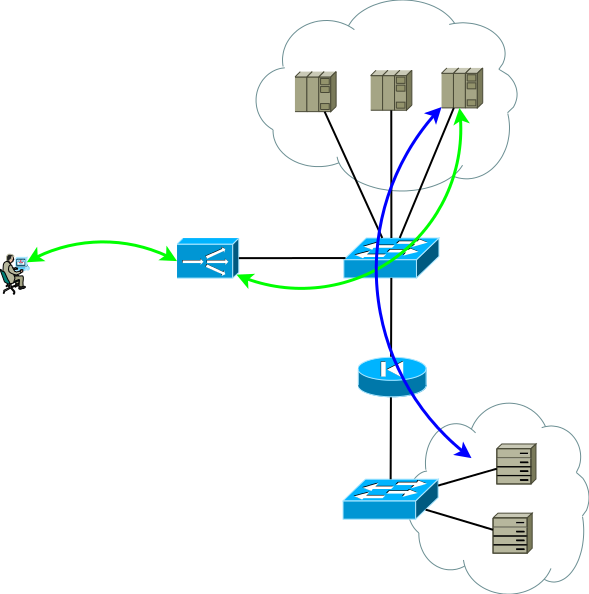
Рис.2
Вторая группа серверов может быть базами данных, бек-эндами приложений, сетевыми хранилищами или фронт-эндами для другого набора сервисов в случае декомпозиции классического приложения на микро-сервисы. Эта группа серверов может представлять собой отдельный домен маршрутизации, со своими политиками, располагаться в другом ЦОД или вовсе быть изолированной из соображений безопасности. Сервера редко находятся в одном сегменте, чаще их помещают в сегменты по функциональному назначению с четко регламентированными политиками доступа, на рисунке это изображено в виде файервола.
Исследования показывают, что современные многоуровневые приложения генерируют больше West-East трафика, и вам вряд ли захочется чтобы весь внутрицодовый/межсегментный трафик проходил через ADC. Коммутаторы на рисунке 2 не обязательно физические — домены маршрутизации можно реализовать с помощью виртуальных сущностей, которые у разных производителей называются virtual-router, vrf, vr, vpn-instance или виртуальная таблица маршрутизации.
К слову сказать, есть и вариант сопряжения с сетью, без требования к симметричности потоков трафика от потребителя к ADC и от ADC к серверам, он востребован в случаях долго живущих сессий, по которым в одну сторону передается очень большое количество трафика, например, стриминг или вещание видео контента. В этом случае ADC видит только поток от клиента к серверам, этот поток доставляется на интерфейсный адрес ADC и после простой обработки, которая заключается в замене MAC адреса на интерфейсный MAC одного из серверов, запрос отправляется на сервер где сервисный адрес присвоен одному из логических интерфейсов. Обратный трафик от сервера к потребителю идет, минуя ADC в соответствии с таблицей маршрутизации сервера. Поддержка единого широковещательного домена для всех фронт-эндов может быть очень сложна, к тому-же возможности ADC по анализу ответов и поддержки сессионности в этом случае весьма ограничены, по сути это просто свитчинг, поэтому такой вариант далее не рассматривается, хотя в решении некоторых узких задач может быть использован.
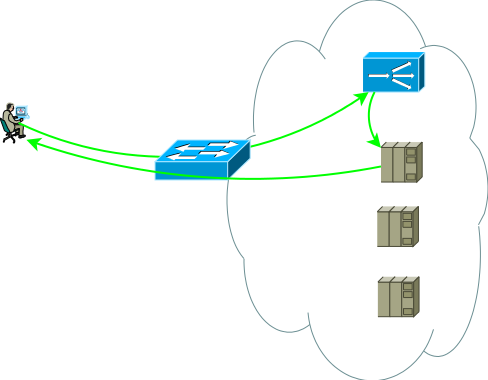
Рис.3
Итак, у нас есть один базис-ЦОД, изображенный на рисунке 2, давайте подумаем какие проблемы могут подтолкнуть базис-ЦОД к эволюции, я вижу две темы для анализа:
Эти задачи похожи тем что, в процессе их решения количество экземпляров ADC точно должно увеличится. В то же время отказоустойчивость можно организовать по схеме Active/Backup и Active/Active, а масштабирование только по схеме Active/Active. Давайте попробуем решить их по отдельности и посмотреть какими свойствами обладают разные решения.
ADC многих производителей могут быть рассмотрены как элементы сетевой инфраструктуры, RIP, OSPF, BGP – все это там есть, а значит можно построить тривиальную схему Active/Backup резервирования. Активный ADC передает сервисные префиксы вышестоящему маршрутизатору, и принимает от него default маршрут для заполнения им своей таблицы и для передачи в сторону ЦОД в соответствующую виртуальную таблицу маршрутизации. Резервный ADC выполняет все тоже самое, но, используя семантику выбранного протокола маршрутизации, формирует менее привлекательные анонсы. Сервера при таком подходе могут видеть реальный IP адрес потребителя, так как нет причин использовать трансляцию адресов. Эта схема работает также изящно в случае если вышестоящих маршрутизатор больше одного, но, чтобы избежать ситуации, когда активный ADC теряет default и связность с маршрутизатором, при этом все еще получает default от резервного ADC и продолжает анонсировать его в сторону ЦОД, постарайтесь избегать соседства между ADC и применение статических маршрутов.
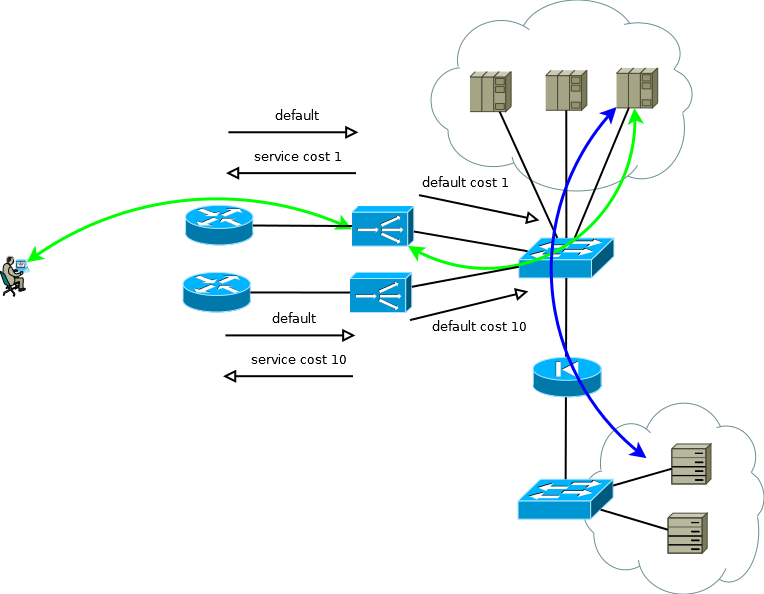
Рис.4
Если на серверах не обязательно оперировать реальными IP адресами потребителя, или протокол прикладного уровня позволяет внедрять его в заголовки, как например HTTP, схема превращается в Active/Active с почти линейной зависимостью производительности от количества ADC. В случае более чем одного вышестоящего маршрутизатора нужно позаботиться о том, чтобы входящий трафик приходил более-менее равномерными порциями. Эту задачу просто решить если в домене маршрутизации ECMP передача начинается до этих маршрутизаторов, если это затруднительно или если домен маршрутизации вами не обслуживается — можно использовать full-mesh соединения между ADX и маршрутизаторами, чтобы ECMP передача начиналась прямо на них.

Рис.5
В начале этой части я написал, что отказоустойчивость и масштабирование — две большие разницы. Решения этих задач обладают разным уровнем утилизации ресурсов, если вы проектируете Active/Standby схему, нужно смириться с тем что половина ресурсов будет простаивать. А если так сложится что вам понадобиться сделать очередной количественный шаг, будьте готовы в будущем умножать требуемые ресурсы еще на два.
Преимущества Active/Active начинают проявляться, когда вы оперируете количеством устройств большим двух. Допустим вам необходимо обеспечить производительность 8 условных единиц (8 тыс. соединений в секунду, или 8 млн одновременных сессий) и предусмотреть сценарий отказа одного устройства, в варианте Active/Active вам достаточно трех экземпляров ADC с производительностью по 4, в случае Active/Standby — двух по 8. Если перевести эти цифры в ресурсы, которые простаивают получается треть против половины. Тот же принцип расчета можно использовать для оценки доли разорванных соединений в период частичного отказа. С увеличением количества Active/Active экземпляров математика становится еще приятнее, а система получает возможность плавного увеличения производительности вместо ступенчатого Active/Standby.
Будет корректно упомянуть об еще одном способе Active/Active или Active/Standby схем работы — кластеризации. Но будет не очень корректно уделять этому много времени, так как я старался писать о подходах, а не об особенностях производителей. При выборе такого решения нужно четко понимать следующие вещи:
Тем не менее есть и положительные вещи:
Итак, наш ЦОД с рисунка 5 продолжает расти, задача, которую вам, возможно, придется решать, заключается в увеличении количества серверов. Сделать это в существующем ЦОД не всегда возможно, поэтому предположим, что появилась новая просторная локация с дополнительными серверами.

Рис.6
Новая площадка может находится не очень далеко, тогда вы успешно решите задачу методом продления доменов маршрутизации. Более общий случай, который не исключает появление площадки в другом городе или в другой стране, поставит перед ЦОД новые проблемы:
Поддержание широкого канала между площадками может оказаться весьма затратным мероприятием, к тому же выбор места размещения перестанет быть тривиальной задачей— перегруженная площадка с маленьким временем отклика или свободная с большим. Размышление об этом подтолкнет вас к построению географически распределенной конфигурации ЦОД. Эта конфигурация, с одной сторону, дружественна по отношению к потребителям, так как позволяет получать сервис в близкой к себе точке, с другой — может существенно снизить требования к полосе канала между площадками.
Для случая, когда реальные IP адреса не обязательно должны быть доступными серверам, или, когда протокол прикладного уровня допускает их передачу в заголовках, устройство территориально распределенный ЦОД мало чем отличается от того, что я назвал базис-ЦОДом. ADC на любой площадке может направлять запросы на обработку локальным серверам или посылать их на обработку на соседнюю, трансляция адреса потребителя делает это возможным. Некоторое внимание нужно уделить мониторингу объемов входящего трафика чтобы поддерживать количество ADC в рамках площадки адекватным доле трафика, которую получает площадка. Трансляция адреса потребителя позволяет увеличивать/уменьшать количество ADC или даже перемещать экземпляры между площадками в соответствии с изменениями в матрице входящего трафика, или во время миграции/запуска. Несмотря на простоту, схема вполне гибкая, обладает приятными эксплуатационными характеристиками и легко тиражируется на количество площадок большее двух.

Рис.7
Если вы работаете с протоколом, который позволяет осуществлять пересылку запросов, как в случае HTTP Redirect, эта возможность может быть применена как дополнительный рычаг управления нагрузкой канала между площадками, как механизм проведения регламентных работ на серверах или как метод построения Active/Backup серверных ферм на разных площадках. В требуемым момент времени, автоматически или после некоторых событий-тригеров, ADC может снять трафик с локальных серверов и переместить потребителей на соседнюю площадку. Стоит уделить разработке этого алгоритма пристальное внимание так чтобы согласованная работа ADC исключала возможность взаимной пересылки запросов или резонанса.
Особый интерес представляет случай, когда серверам нужны реальные IP адреса потребителей, а протокол прикладного уровня не обладает возможностями передачи дополнительных заголовков, или, когда ADC работают без понимания семантики протокола прикладного уровня. В этом случае невозможно обеспечить согласованное соединение сегментов TCP сессии просто объявив в ADC default маршрут. Если вы это сделаете сервера первой площадки начнут использовать локальный ADC в качестве шлюза по умолчанию для сессий, которые пришли со второй площадки, само собой TCP сессия в этом случае не установится потому что ADC первой площадки будет видеть только одно плечо сессии.
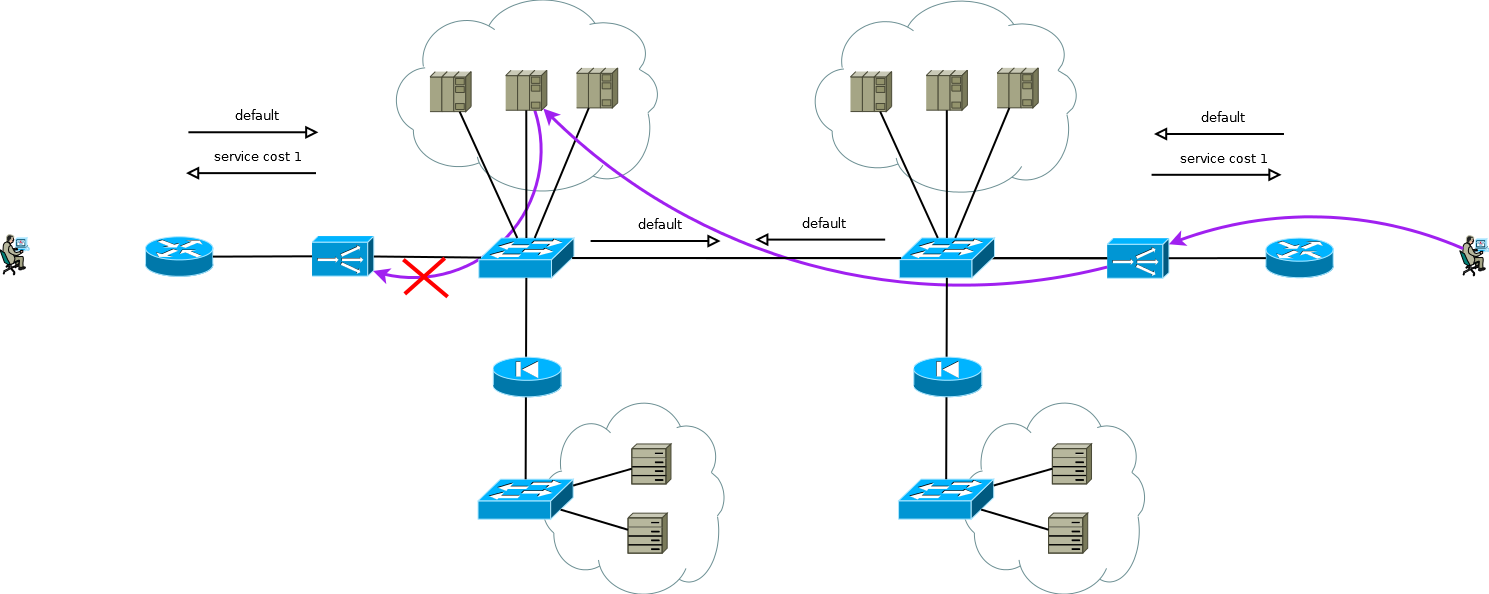
Рис.8
Есть небольшая хитрость, которая все же позволяет запустить Active/Active ADC в сочетании с Active/Active серверными фермами на разных площадках (случай Active/Backup на двух площадках я не рассматриваю, внимательное прочтение написанного выше позволит вам решить эту задачу без дополнительного изложения). Хитрость заключается в том, чтобы использовать на ADC второй площадки не интерфейсные адреса серверов, а логический адрес ADC, который соответствует серверной ферме на первой площадке. Сервера при этом принимают трафик, как если бы он пришел от локального ADC и используют локальный шлюз по умолчанию. Для поддержания такого режима работы на ADC требуется активировать функцию запоминания интерфейса, с которого пришел первый пакет на установку TCP сессии. У разных производителей эта функция называется по-разному, но суть одна и та же — запомнить интерфейс в таблице состояния сессий и использовать его для ответного трафика не обращая внимание на таблицу маршрутизации. Схема вполне работоспособная и позволяет гибко распределять нагрузку по всем доступным серверам где бы они не находились. В случае двух и более площадок выход из строя одного ADC не влияет на доступность сервиса в целом, но полностью исключает возможность обработки трафика на серверах площадки с вышедшим из строя ADC, это нужно помнить при прогнозировании поведения и нагрузки во время частичных отказов.
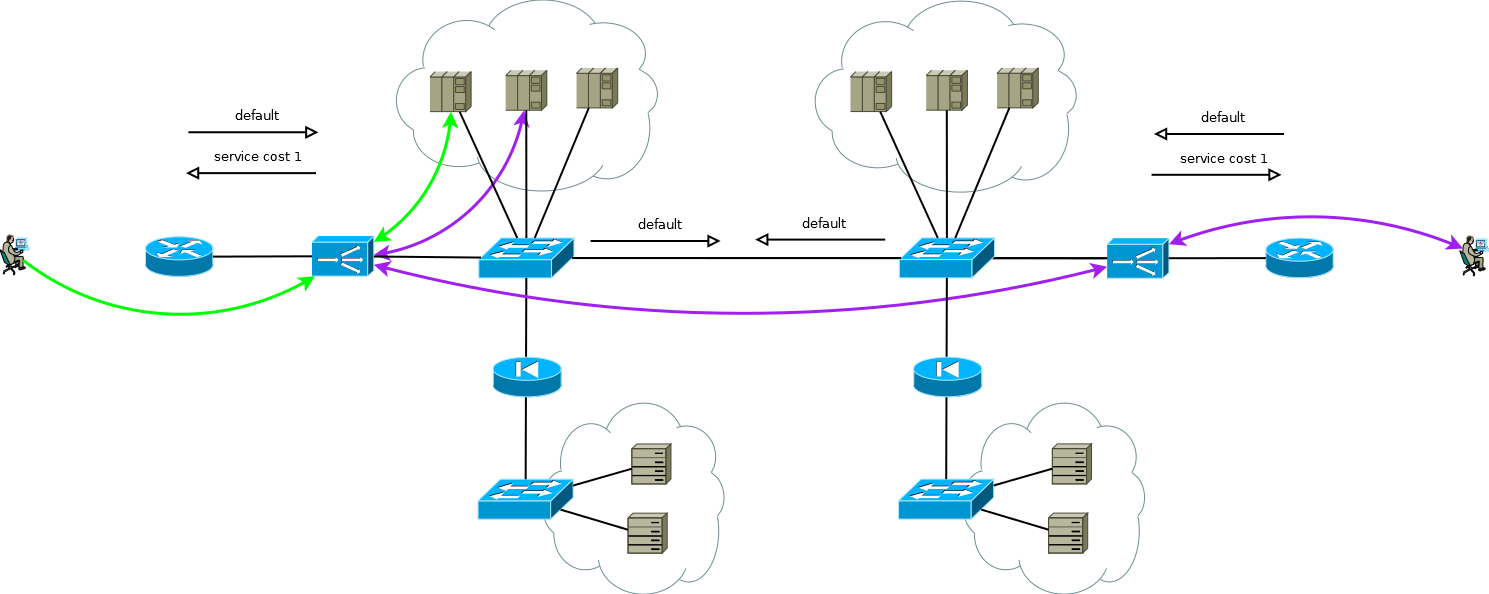
Рис.9
Примерно по такой схеме функционировали сервисы нашего клиента, когда я взялся за работу в проекте миграции на новую платформу ADC. Не было большой сложности просто воссоздать поведение устройств старой платформы на новой в рамках проверенной и устраивающей клиента схемы, именно этого от нас ждали.
Но посмотрите еще раз на рисунок 9, видите ли вы там то что можно оптимизировать?
Основной минус схемы работы с цепочкой ADC заключается в том, что на обработку некоторой части сессий расходуются ресурсы двух ADC. В случае этого клиента выбор был абсолютно осознанным, он обусловлен спецификой работы приложений и необходимостью иметь возможность очень быстро (от 20-ти до 50-ти секунд) перераспределять нагрузку между серверами разных площадок. В разные периоды времени двойная обработка забирала в среднем от 15-ти до 30-ти процентов ресурсов ADC, это достаточное количество чтобы подумать над оптимизацией. Обговорив этот момент с инженерами клиента, мы предложили заменить поддержку таблицы сессий ADC с привязкой к интерфейсу на маршрутизацию по источнику на серверах с помощью PBR на IP стеке Linux. В качестве ключа мы рассматривали такие варианты как:
Первый и второй варианты так или иначе оказали бы влияние на сеть в целом. Среди побочных эффектов варианта номер один нам показалось неприемлемым увеличение, кратное количеству ADC, ARP таблицы на коммутаторах, а второй вариант потребовал бы увеличения количества сквозных широковещательных доменов между площадками или отдельных экземпляров виртуальных таблиц маршрутизации. Локальный характер третьего варианта показался нам очень привлекательным, и мы взялись за работу, по итогу которой получился простой контроллер, который автоматизирует конфигурацию туннелей на серверах и ADC, а также конфигурацию PBR на IP стеке серверов Linux.

Рис.10
Как я уже написал миграция завершилась, клиент получил то что хотел — новую платформу, простоту гибкость, масштабируемость, и, как следствие перехода на оверлей, упрощение конфигурации сетевого оборудования в рамках обслуживания этих сервисов — вместо нескольких экземпляров виртуальных таблиц и больших широковещательных доменов получилось что-то наподобие простой IP фабрики.
Коллеги, которые работают у производителей ADC, этот абзац посвящен в большей степени вам. Некоторые ваши продукты хороши, но попробуйте обратить внимание на более тесную интеграцию с приложениями на серверах, автоматизацию их настроек и оркестрацию всего процесса разработки и эксплуатации. Мне это представляется в виде классического взаимодействия контроллер-агента, внося изменения на ADC пользователь инициирует обращение контроллера к зарегистрированным агентам, это то что сделали мы с клиентом, но «из коробки».
Помимо этого, некоторым клиентам покажется удобной переход с PULL модели взаимодействия с серверами на PUSH модель. Возможности приложений на серверах очень широки, поэтому иногда проще организовать серьезную application specific проверку работы сервиса на самом агенте. Если проверка дает положительный результат агент передает информацию, например, в виде похожем на BGP Cost Community, для использования в алгоритмах взвешенного расчета весов.
Зачастую обслуживание серверов и ADC выполняют разные подразделения организации, переход на PUSH модель взаимодействия мог бы быть интересен тем что эта модель избавляет от необходимости координации между подразделениями по интерфейсу человек-человек. Сервисы, в которых участвует сервер, можно передавать напрямую от агента к ADC в виде чем-то похожем на расширенный BGP Flow-Spec.
Много чего еще можно написать. К чему я все это… Находясь в свободном выборе мы принимаем решении в пользу более удобного, более подходящего или в пользу варианта, который расширяет окно возможностей чтобы минимизировать свои риски. Крупные игроки интернет индустрии для решения своих задач изобретают что-то совсем инновационное, то что диктует завтрашний день, игроки поменьше и компании с опытом разработки программного обеспечения все чаще применяют такие технологии и продукты, которые допускают глубокую кастомизацию под себя. Многие производители балансировщиков нагрузки отмечают снижение востребованности своих продуктов. Иными словами, сервера и приложения, которые на них работают, коммутаторы и маршрутизаторы некоторое время назад уже качественно изменились и вошли в SDN эру. Балансировщики пока стоят на пороге, сделайте этот шаг пока дверь открыта, в противном случае вы рискуете потерять конкурентные преимущества и переместиться на периферию.
Балансировщики нагрузки сейчас все чаще называют контроллерами доставки приложений (Application Delivery Controller — ADC). Но если приложения работают на сервере зачем их куда-то доставлять? Из соображений отказоустойчивости или масштабирования приложение может быть запущено более чем на одном сервере, в этом случае нужен своего рода обратный прокси-сервер, который спрячет от потребителей внутреннюю сложность, выберет нужный сервер, доставит на него запрос и проследит за тем, чтобы сервер вернул корректный, с точки зрения протокола, результат, иначе — выберет другой сервер и отправит запрос туда. Для осуществления этих функций ADC должен понимать семантику протокола прикладного уровня, с которым он работает, это позволяет настраивать appication specific правила доставки трафика, анализа результата и проверки состояния сервера. Например, понимание семантики HTTP, делает возможной конфигурацию, когда HTTP запросы
GET /docs/index.html HTTP/1.1
Host: www.company.com
Accept-Language: en-us
Accept-Encoding: gzip, deflate
отправляются на одну группу серверов с последующим сжатием результатов и кешированием, а запросы
POST /api/object-put HTTP/1.1
HOST: b2b.company.com
X-Auth: 76GDjgtgdfsugs893Hhdjfpsj
Content-Type: application/json
обрабатываются по совершенно другим правилам.
Понимание семантики протокола позволяет организовывать сессионность на уровне объектов прикладного протокола, например, с помощью HTTP Headers, RDP Cookie, или осуществлять мультиплексирование запросов чтобы заполнять одну транспортную сессию многими пользовательскими запросами если прикладной уровень протокола позволяет это делать.
Сферу применения ADC иногда неоправданно представляют себе только обслуживанием HTTP трафика, на самом деле список поддерживаемых протоколов у большинства производителей гораздо шире. Даже работая без понимания семантики протокола прикладного уровня ADC может быть полезен для решения тех или иных задач, так например я принимал участие в построении самодостаточной виртуальной фермы SMTP серверов, в период спам-атак количество экземпляров увеличивается с помощью управления с обратной связью по длине очереди сообщений, чтобы обеспечить удовлетворительное время проверки сообщений ресурсоёмкими алгоритмами. Во время активации сервер регистрировался на ADC и получал свою порцию новых TCP сессий. В случае SMTP такая схема работы была вполне оправдана из-за высокой энтропии соединений на сетевом и транспортном уровнях, для равномерного распределения нагрузки во время спам-атак ADC требуется только поддержка TCP. Похожая схема может применяться для построения фермы из серверов баз данных, высоконагруженных кластеров DNS, DHCP, AAA или Remote access серверов, когда сервера можно считать равнозначными в предметном домене и когда их характеристики производительности не слишком сильно отличаются друг от друга. Углубляться в тему особенностей протоколов дальше я не буду, этот аспект слишком обширен чтобы излагать его во вступлении, если что-то покажется интересным — пишите, возможно это повод для статьи с более глубоким изложением какого-то варианта применения, а теперь перейдем к сути.
Чаще всего ADC замыкает на себя транспортный уровень, поэтому сквозная TCP сессия между потребителем и сервером становится составной, потребитель устанавливает сессию с ADC, а ADC — с одним из серверов.
Рис.1
Конфигурация сети и настройки адресации должны обеспечивать такое продвижение трафика чтобы две части TCP сессии прошли через ADC. Самый простой вариант заставить трафик первой части прийти на ADC заключается в присвоении адресу сервиса одного из интерфейсных адресов ADC, со второй частью возможны такие варианты:
- ADC как default gateway для серверной сети;
- трансляция на ADC адреса потребителя в один из своих интерфейсных адресов.
На самом деле чуть более реалистичный вид первой схемы применения выглядит уже вот так, это базис, с которого мы начнем:
Рис.2
Вторая группа серверов может быть базами данных, бек-эндами приложений, сетевыми хранилищами или фронт-эндами для другого набора сервисов в случае декомпозиции классического приложения на микро-сервисы. Эта группа серверов может представлять собой отдельный домен маршрутизации, со своими политиками, располагаться в другом ЦОД или вовсе быть изолированной из соображений безопасности. Сервера редко находятся в одном сегменте, чаще их помещают в сегменты по функциональному назначению с четко регламентированными политиками доступа, на рисунке это изображено в виде файервола.
Исследования показывают, что современные многоуровневые приложения генерируют больше West-East трафика, и вам вряд ли захочется чтобы весь внутрицодовый/межсегментный трафик проходил через ADC. Коммутаторы на рисунке 2 не обязательно физические — домены маршрутизации можно реализовать с помощью виртуальных сущностей, которые у разных производителей называются virtual-router, vrf, vr, vpn-instance или виртуальная таблица маршрутизации.
К слову сказать, есть и вариант сопряжения с сетью, без требования к симметричности потоков трафика от потребителя к ADC и от ADC к серверам, он востребован в случаях долго живущих сессий, по которым в одну сторону передается очень большое количество трафика, например, стриминг или вещание видео контента. В этом случае ADC видит только поток от клиента к серверам, этот поток доставляется на интерфейсный адрес ADC и после простой обработки, которая заключается в замене MAC адреса на интерфейсный MAC одного из серверов, запрос отправляется на сервер где сервисный адрес присвоен одному из логических интерфейсов. Обратный трафик от сервера к потребителю идет, минуя ADC в соответствии с таблицей маршрутизации сервера. Поддержка единого широковещательного домена для всех фронт-эндов может быть очень сложна, к тому-же возможности ADC по анализу ответов и поддержки сессионности в этом случае весьма ограничены, по сути это просто свитчинг, поэтому такой вариант далее не рассматривается, хотя в решении некоторых узких задач может быть использован.
Рис.3
Итак, у нас есть один базис-ЦОД, изображенный на рисунке 2, давайте подумаем какие проблемы могут подтолкнуть базис-ЦОД к эволюции, я вижу две темы для анализа:
- Предположим, что коммутационная подсистема полностью зарезервирована, давайте не задумываться, как и чем, тема слишком обширная. Приложения работают на нескольких серверах и резервируются с помощью ADC, но как зарезервировать сам ADC?
- Если анализ показывает, что следующий сезонный пик нагрузки может превзойти возможности ADC, вы, само собой, задумаетесь о масштабируемости.
Эти задачи похожи тем что, в процессе их решения количество экземпляров ADC точно должно увеличится. В то же время отказоустойчивость можно организовать по схеме Active/Backup и Active/Active, а масштабирование только по схеме Active/Active. Давайте попробуем решить их по отдельности и посмотреть какими свойствами обладают разные решения.
ADC многих производителей могут быть рассмотрены как элементы сетевой инфраструктуры, RIP, OSPF, BGP – все это там есть, а значит можно построить тривиальную схему Active/Backup резервирования. Активный ADC передает сервисные префиксы вышестоящему маршрутизатору, и принимает от него default маршрут для заполнения им своей таблицы и для передачи в сторону ЦОД в соответствующую виртуальную таблицу маршрутизации. Резервный ADC выполняет все тоже самое, но, используя семантику выбранного протокола маршрутизации, формирует менее привлекательные анонсы. Сервера при таком подходе могут видеть реальный IP адрес потребителя, так как нет причин использовать трансляцию адресов. Эта схема работает также изящно в случае если вышестоящих маршрутизатор больше одного, но, чтобы избежать ситуации, когда активный ADC теряет default и связность с маршрутизатором, при этом все еще получает default от резервного ADC и продолжает анонсировать его в сторону ЦОД, постарайтесь избегать соседства между ADC и применение статических маршрутов.
Рис.4
Если на серверах не обязательно оперировать реальными IP адресами потребителя, или протокол прикладного уровня позволяет внедрять его в заголовки, как например HTTP, схема превращается в Active/Active с почти линейной зависимостью производительности от количества ADC. В случае более чем одного вышестоящего маршрутизатора нужно позаботиться о том, чтобы входящий трафик приходил более-менее равномерными порциями. Эту задачу просто решить если в домене маршрутизации ECMP передача начинается до этих маршрутизаторов, если это затруднительно или если домен маршрутизации вами не обслуживается — можно использовать full-mesh соединения между ADX и маршрутизаторами, чтобы ECMP передача начиналась прямо на них.
Рис.5
В начале этой части я написал, что отказоустойчивость и масштабирование — две большие разницы. Решения этих задач обладают разным уровнем утилизации ресурсов, если вы проектируете Active/Standby схему, нужно смириться с тем что половина ресурсов будет простаивать. А если так сложится что вам понадобиться сделать очередной количественный шаг, будьте готовы в будущем умножать требуемые ресурсы еще на два.
Преимущества Active/Active начинают проявляться, когда вы оперируете количеством устройств большим двух. Допустим вам необходимо обеспечить производительность 8 условных единиц (8 тыс. соединений в секунду, или 8 млн одновременных сессий) и предусмотреть сценарий отказа одного устройства, в варианте Active/Active вам достаточно трех экземпляров ADC с производительностью по 4, в случае Active/Standby — двух по 8. Если перевести эти цифры в ресурсы, которые простаивают получается треть против половины. Тот же принцип расчета можно использовать для оценки доли разорванных соединений в период частичного отказа. С увеличением количества Active/Active экземпляров математика становится еще приятнее, а система получает возможность плавного увеличения производительности вместо ступенчатого Active/Standby.
Будет корректно упомянуть об еще одном способе Active/Active или Active/Standby схем работы — кластеризации. Но будет не очень корректно уделять этому много времени, так как я старался писать о подходах, а не об особенностях производителей. При выборе такого решения нужно четко понимать следующие вещи:
- Кластерная архитектура иногда накладывает ограничения на ту или иную функциональность, в каких-то проектах это принципиально, в каких-то может стать принципиально в будущем, тут все сильно зависит от производителя и каждое решение нужно прорабатывать индивидуально;
- Кластер зачастую представляет из себя один fault domain, ошибки в программном обеспечении есть у будут.
- Кластер легко собрать, но очень сложно разобрать. Технология обладает меньшей мобильностью — вы не можете управлять частями системы.
- Вы попадаете в цепкие объятия своего производителя.
Тем не менее есть и положительные вещи:
- Кластер просто инсталлируется и просто эксплуатируется
- Иногда вы можете ожидать близкую к оптимальной утилизацию ресурсов.
Итак, наш ЦОД с рисунка 5 продолжает расти, задача, которую вам, возможно, придется решать, заключается в увеличении количества серверов. Сделать это в существующем ЦОД не всегда возможно, поэтому предположим, что появилась новая просторная локация с дополнительными серверами.
Рис.6
Новая площадка может находится не очень далеко, тогда вы успешно решите задачу методом продления доменов маршрутизации. Более общий случай, который не исключает появление площадки в другом городе или в другой стране, поставит перед ЦОД новые проблемы:
- Утилизация каналов между площадками;
- Разница времени обработки запросов, которые ADC отправил на обработку близким и далеким серверам.
Поддержание широкого канала между площадками может оказаться весьма затратным мероприятием, к тому же выбор места размещения перестанет быть тривиальной задачей— перегруженная площадка с маленьким временем отклика или свободная с большим. Размышление об этом подтолкнет вас к построению географически распределенной конфигурации ЦОД. Эта конфигурация, с одной сторону, дружественна по отношению к потребителям, так как позволяет получать сервис в близкой к себе точке, с другой — может существенно снизить требования к полосе канала между площадками.
Для случая, когда реальные IP адреса не обязательно должны быть доступными серверам, или, когда протокол прикладного уровня допускает их передачу в заголовках, устройство территориально распределенный ЦОД мало чем отличается от того, что я назвал базис-ЦОДом. ADC на любой площадке может направлять запросы на обработку локальным серверам или посылать их на обработку на соседнюю, трансляция адреса потребителя делает это возможным. Некоторое внимание нужно уделить мониторингу объемов входящего трафика чтобы поддерживать количество ADC в рамках площадки адекватным доле трафика, которую получает площадка. Трансляция адреса потребителя позволяет увеличивать/уменьшать количество ADC или даже перемещать экземпляры между площадками в соответствии с изменениями в матрице входящего трафика, или во время миграции/запуска. Несмотря на простоту, схема вполне гибкая, обладает приятными эксплуатационными характеристиками и легко тиражируется на количество площадок большее двух.
Рис.7
Если вы работаете с протоколом, который позволяет осуществлять пересылку запросов, как в случае HTTP Redirect, эта возможность может быть применена как дополнительный рычаг управления нагрузкой канала между площадками, как механизм проведения регламентных работ на серверах или как метод построения Active/Backup серверных ферм на разных площадках. В требуемым момент времени, автоматически или после некоторых событий-тригеров, ADC может снять трафик с локальных серверов и переместить потребителей на соседнюю площадку. Стоит уделить разработке этого алгоритма пристальное внимание так чтобы согласованная работа ADC исключала возможность взаимной пересылки запросов или резонанса.
Особый интерес представляет случай, когда серверам нужны реальные IP адреса потребителей, а протокол прикладного уровня не обладает возможностями передачи дополнительных заголовков, или, когда ADC работают без понимания семантики протокола прикладного уровня. В этом случае невозможно обеспечить согласованное соединение сегментов TCP сессии просто объявив в ADC default маршрут. Если вы это сделаете сервера первой площадки начнут использовать локальный ADC в качестве шлюза по умолчанию для сессий, которые пришли со второй площадки, само собой TCP сессия в этом случае не установится потому что ADC первой площадки будет видеть только одно плечо сессии.
Рис.8
Есть небольшая хитрость, которая все же позволяет запустить Active/Active ADC в сочетании с Active/Active серверными фермами на разных площадках (случай Active/Backup на двух площадках я не рассматриваю, внимательное прочтение написанного выше позволит вам решить эту задачу без дополнительного изложения). Хитрость заключается в том, чтобы использовать на ADC второй площадки не интерфейсные адреса серверов, а логический адрес ADC, который соответствует серверной ферме на первой площадке. Сервера при этом принимают трафик, как если бы он пришел от локального ADC и используют локальный шлюз по умолчанию. Для поддержания такого режима работы на ADC требуется активировать функцию запоминания интерфейса, с которого пришел первый пакет на установку TCP сессии. У разных производителей эта функция называется по-разному, но суть одна и та же — запомнить интерфейс в таблице состояния сессий и использовать его для ответного трафика не обращая внимание на таблицу маршрутизации. Схема вполне работоспособная и позволяет гибко распределять нагрузку по всем доступным серверам где бы они не находились. В случае двух и более площадок выход из строя одного ADC не влияет на доступность сервиса в целом, но полностью исключает возможность обработки трафика на серверах площадки с вышедшим из строя ADC, это нужно помнить при прогнозировании поведения и нагрузки во время частичных отказов.
Рис.9
Примерно по такой схеме функционировали сервисы нашего клиента, когда я взялся за работу в проекте миграции на новую платформу ADC. Не было большой сложности просто воссоздать поведение устройств старой платформы на новой в рамках проверенной и устраивающей клиента схемы, именно этого от нас ждали.
Но посмотрите еще раз на рисунок 9, видите ли вы там то что можно оптимизировать?
Основной минус схемы работы с цепочкой ADC заключается в том, что на обработку некоторой части сессий расходуются ресурсы двух ADC. В случае этого клиента выбор был абсолютно осознанным, он обусловлен спецификой работы приложений и необходимостью иметь возможность очень быстро (от 20-ти до 50-ти секунд) перераспределять нагрузку между серверами разных площадок. В разные периоды времени двойная обработка забирала в среднем от 15-ти до 30-ти процентов ресурсов ADC, это достаточное количество чтобы подумать над оптимизацией. Обговорив этот момент с инженерами клиента, мы предложили заменить поддержку таблицы сессий ADC с привязкой к интерфейсу на маршрутизацию по источнику на серверах с помощью PBR на IP стеке Linux. В качестве ключа мы рассматривали такие варианты как:
- дополнительный IP адрес на серверах на общем интерфейсе для каждого ADC;
- интерфейсный IP адрес на серверах на отдельном 802.1q для каждого ADC;
- отдельная оверлей туннель сеть на серверах для каждого ADC.
Первый и второй варианты так или иначе оказали бы влияние на сеть в целом. Среди побочных эффектов варианта номер один нам показалось неприемлемым увеличение, кратное количеству ADC, ARP таблицы на коммутаторах, а второй вариант потребовал бы увеличения количества сквозных широковещательных доменов между площадками или отдельных экземпляров виртуальных таблиц маршрутизации. Локальный характер третьего варианта показался нам очень привлекательным, и мы взялись за работу, по итогу которой получился простой контроллер, который автоматизирует конфигурацию туннелей на серверах и ADC, а также конфигурацию PBR на IP стеке серверов Linux.
Рис.10
Как я уже написал миграция завершилась, клиент получил то что хотел — новую платформу, простоту гибкость, масштабируемость, и, как следствие перехода на оверлей, упрощение конфигурации сетевого оборудования в рамках обслуживания этих сервисов — вместо нескольких экземпляров виртуальных таблиц и больших широковещательных доменов получилось что-то наподобие простой IP фабрики.
Коллеги, которые работают у производителей ADC, этот абзац посвящен в большей степени вам. Некоторые ваши продукты хороши, но попробуйте обратить внимание на более тесную интеграцию с приложениями на серверах, автоматизацию их настроек и оркестрацию всего процесса разработки и эксплуатации. Мне это представляется в виде классического взаимодействия контроллер-агента, внося изменения на ADC пользователь инициирует обращение контроллера к зарегистрированным агентам, это то что сделали мы с клиентом, но «из коробки».
Помимо этого, некоторым клиентам покажется удобной переход с PULL модели взаимодействия с серверами на PUSH модель. Возможности приложений на серверах очень широки, поэтому иногда проще организовать серьезную application specific проверку работы сервиса на самом агенте. Если проверка дает положительный результат агент передает информацию, например, в виде похожем на BGP Cost Community, для использования в алгоритмах взвешенного расчета весов.
Зачастую обслуживание серверов и ADC выполняют разные подразделения организации, переход на PUSH модель взаимодействия мог бы быть интересен тем что эта модель избавляет от необходимости координации между подразделениями по интерфейсу человек-человек. Сервисы, в которых участвует сервер, можно передавать напрямую от агента к ADC в виде чем-то похожем на расширенный BGP Flow-Spec.
Много чего еще можно написать. К чему я все это… Находясь в свободном выборе мы принимаем решении в пользу более удобного, более подходящего или в пользу варианта, который расширяет окно возможностей чтобы минимизировать свои риски. Крупные игроки интернет индустрии для решения своих задач изобретают что-то совсем инновационное, то что диктует завтрашний день, игроки поменьше и компании с опытом разработки программного обеспечения все чаще применяют такие технологии и продукты, которые допускают глубокую кастомизацию под себя. Многие производители балансировщиков нагрузки отмечают снижение востребованности своих продуктов. Иными словами, сервера и приложения, которые на них работают, коммутаторы и маршрутизаторы некоторое время назад уже качественно изменились и вошли в SDN эру. Балансировщики пока стоят на пороге, сделайте этот шаг пока дверь открыта, в противном случае вы рискуете потерять конкурентные преимущества и переместиться на периферию.
Комментарии (3)

xcore78
25.09.2018 01:10попробуйте обратить внимание на более тесную интеграцию с приложениями на серверах, автоматизацию их настроек и оркестрацию всего процесса разработки и эксплуатации
У F5 есть достаточно приличное API довольно давно. У KEMP есть API.
Karroplan
Для такой ориентации схем как у вас — east-west превратились в north-south… e обычно слева, а n — сверху )