

Скрипты — один из самых распространенных способов сделать приложение более гибким, с возможностью поправить что-то прямо на ходу. Конечно же, у этого подхода есть и недостатки, нужно всегда помнить про баланс между гибкостью и управляемостью. Но в этой статье мы не будем рассуждать “в общем” по поводу плюсов и минусов использования скриптов, мы рассмотрим практические способы реализации этого подхода, а также представим библиотеку, которая предоставляет удобную инфраструктуру для добавления скриптов в приложения, написанные на Spring Framework.
Несколько вводных слов
Когда хочется добавить возможность менять бизнес-логику в приложении без перекомпиляции и последующего развертывания, то скрипты — один из способов, который приходит на ум в первую очередь. Зачастую, скрипты появляются не потому что так было задумано, а потому что так получилось. Например, в спецификации есть часть логики, которая вот прямо сейчас не до конца ясна, но, чтобы не тратить лишние пару дней (а иногда и дольше) на анализ, можно сделать точку расширения и вызывать скрипт — заглушку. А потом, конечно, этот скрипт будет переписан, когда требования прояснятся.
Способ не новый, и его достоинства и недостатки хорошо известны: гибкость — можно поменять логику на работающем приложении и сэкономить время на редеплое, но, с другой стороны, скрипты сложнее тестировать, отсюда — возможные проблемы с безопасностью, производительностью и т.д.
Те приемы, которые будут рассмотрены далее, могут быть полезны как разработчикам, которые уже используют скрипты в своем приложении, так и тем, кто только думает об этом.
Ничего личного, только скриптинг
С JSR-233 скриптинг в Java стал очень простым. Существует достаточное количество скриптовых движков, основанных на этом API (Nashorn, JRuby, Jython и ещё некоторые), так что добавить немного скриптовой магии в код — не проблема:
Map<String, Object> parameters = createParametersMap();
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine scriptEngine = manager.getEngineByName("groovy");
Object result = scriptEngine.eval(script.getScriptAsString("discount.groovy"),
new SimpleBindings(parameters));
Очевидно, что, если такой код будет раскидан по всему приложению, то оно превратится непонятно во что. И, безусловно, если у вас в приложении больше одного вызова скрипта, то нужно делать отдельный класс для работы с ними. Иногда можно пойти ещё дальше и сделать специальные классы, которые будут оборачивать вызовы
evaluateGroovy() в обычные типизированные Java методы. В этих методах будет довольно однотипный служебный код, как в примере:public BigDecimal applyCustomerDiscount(Customer customer, BigDecimal orderAmount) {
Map<String, Object> params = new HashMap<>();
params.put("cust", customer);
params.put("amount", orderAmount);
return (BigDecimal)scripting.evalGroovy(getScriptSrc("discount.groovy"), params);
}
Такой подход сильно увеличивает прозрачность при вызовах скриптов из кода приложения — сразу видно, какие параметры скрипт принимает, какого они типа и что возвращается. Главное — не забыть добавить в стандарты написания кода запрет на вызов скриптов не из типизированных методов!
Прокачиваем скрипты
Несмотря на то, что скрипты — это просто, если у вас их много и вы их интенсивно используете, то есть реальный шанс столкнуться с проблемами производительности. Например, если используется куча groovy шаблонов для генерации отчетов и вы их запускаете в одно и то же время, рано или поздно это станет одним из узких мест в производительности приложения.
Поэтому многие фреймворки делают разнообразные надстройки над стандартным API для улучшения скорости работы, кэширования, мониторинга выполнения, использования разных скриптовых языков в одном приложении и т.д.
Например, в CUBA был сделан довольно хитроумный движок для скриптинга, который поддерживает дополнительные возможности, такие как:
- Возможность писать скрипты на Java и Groovy
- Кэш классов для того, чтобы не компилировать скрипты повторно
- JMX бин для управления движком
Все это, конечно, улучшает производительность и удобство пользования, но все-таки низкоуровневый движок остается низкоуровневым, и все равно надо читать текст скрипта, передавать параметры и вызывать API для выполнения скрипта. Так что нужно все ещё делать какие-то обертки в каждом проекте, чтобы сделать разработку ещё эффективнее.
И было бы несправедливо не упомянуть GraalVM — экспериментальный движок, который умеет выполнять программы на разных языках (JVM и не-JVM) и позволяет вставлять в Java приложения модули на этих языках. Я надеюсь, что Nashorn рано или поздно уйдет в историю, и у нас будет возможность писать части кода на разных языках в одном исходнике. Но это пока только мечты.
Spring Framework: предложение, от которого сложно отказаться?
В Spring есть встроенная поддержка исполнения скриптов, построенная на базе API JDK. В пакете
org.springframework.scripting.* можно найти много полезных классов — все, чтобы можно было удобно использовать низкоуровневый API для скриптинга в своем приложении.Кроме этого, есть более высокоуровневая поддержка, она подробно описана в документации. Вкратце — нужно сделать класс на скриптовом языке (например, Groovy) и опубликовать его как бин через XML описание:
<lang:groovy id="messenger" script-source="classpath:Messenger.groovy">
<lang:property name="message" value="I Can Do The Frug" />
</lang:groovy>
После того, как бин опубликован, его можно добавлять в свои классы при помощи IoC. Spring обеспечивает автоматическое обновление скрипта при изменении текста в файле, можно вешать аспекты на методы и т.д.
Выглядит неплохо, но нужно делать “настоящие” классы для того, чтобы их опубликовать, обычную функцию в скрипте не напишешь. Кроме того, скрипты можно хранить только в файловой системе, для использования БД придется лезть внутрь Spring. Да и XML конфигурацию многие считают устаревшей, особенно если в приложении уже все на аннотациях. Это, конечно, вкусовщина, но с ней зачастую приходится считаться.
Скрипты: трудности и идеи
Итак, у каждого решения есть своя цена, и, если говорить о скриптах в Java приложениях, то при внедрении этой технологии можно столкнуться с некоторыми трудностями:
- Управляемость. Зачастую вызовы скриптов раскиданы по всему приложению, и при изменениях в коде довольно сложно бывает отследить вызовы нужных скриптов.
- Возможность найти точки вызова. Если что-то идет не так в конкретном скрипте, то найти все его точки вызова будет проблемой, если только не применять поиск по названию файла или вызовам метода типа
evaluateGroovy() - Прозрачность. Написание скрипта — сама по себе непростая задача, а ещё сложнее приходится тем, кто этот скрипт вызывает. Нужно помнить, как называются входные параметры, какой у них тип данных и что является результатом выполнения. Или каждый раз смотреть в исходный код скрипта.
- Тестирование и обновление — не всегда получается протестировать скрипт в окружении кода приложения, да и после заливки его на “боевой” сервер нужно как-то уметь быстро все откатить, если что-то пойдет не так.
Похоже, что обертывание вызовов скриптов в Java методы поможет решить большинство вышеуказанных задач. Совсем хорошо, если такие классы можно будет публиковать в IoC контейнере и вызывать методы с нормальными, значащими именами в своих сервисах, вместо вызова
eval(“disc_10_cl.groovy”) из какого-нибудь утилитного класса. Ещё один плюс — код становится самодокументируемым, разработчику не надо ломать голову, какой конкретно алгоритм скрывается за названием файла. Вдобавок ко всему, если каждый скрипт будет связан только с одним методом, можно быстро найти все точки вызова в приложении при помощи меню “Find Usages” из IDE и понять место скрипта в каждом конкретном алгоритме бизнес-логики.
Упрощается тестирование — оно превращается в “обычное” тестирование классов, с использованием привычных фреймворков, mock’ами и прочим.
Все вышеописанное очень созвучно с идеей, упомянутой в начале статьи — “специальные” классы для методов, которые реализуются скриптами. А что, если сделать ещё один шаг и скрыть весь служебный однотипный код для вызовов скриптовых движков от разработчика, чтобы он про это даже не думал (ну, почти)?
Репозитории скриптов — концепт
Задумка довольно проста и должна быть знакома тем, кто хоть раз работал со Spring, особенно со Spring JPA. Что нужно — сделать Java интерфейс и при вызове его методов вызывать скрипт. В JPA, кстати, используется идентичный подход — вызов CrudRepository перехватывается, на основе имени метода и параметров создается запрос, который потом выполняется движком БД.
Что нужно, чтобы реализовать концепт?
Для начала — аннотация уровня класса, чтобы можно было найти интерфейс — репозиторий и сделать бин на его основе.
Также, наверное, пригодятся аннотации на методы этого интерфейса для того, чтобы хранить метаданные, нужные для вызова метода. Например — откуда брать текст скрипта и какой движок использовать.
Полезным дополнением будет возможность использовать методы с реализацией в интерфейсе (a.k.a. default) — этот код будет работать, пока бизнес-аналитик не выведает более полную версию алгоритма, а разработчик не сделает скрипт на основе
этой информации. Или пусть аналитик скрипт пишет, а разработчик потом просто скопирует его на сервер. Вариантов много :-)
Итак, предположим, что для интернет-магазина нужно сделать сервис для вычисления скидок на основе профиля пользователя. Прямо сейчас непонятно, как это делать, но бизнес-аналитик клянется, что всем зарегистрированным пользователям полагается скидка 10%, остальное он выяснит в течение недели у заказчика. Сервис нужен прямо завтра — сезон все-таки. Как может выглядеть код для такого случая?
@ScriptRepository
public interface PricingRepository {
@ScriptMethod
default BigDecimal applyCustomerDiscount(Customer customer, BigDecimal orderAmount) {
return orderAmount.multiply(new BigDecimal("0.9"));
}
}
А потом подоспеет и сам алгоритм, написанный, например, на groovy, там скидки будут немного отличаться:
def age = 50
if ((Calendar.YEAR - customer.birthday.year) >= age) {
return orderAmount.multiply(0.75)
} else {
return orderAmount.multiply(0.9)
}
Цель всего этого — дать разработчику возможность написать только код интерфейса и код скрипта, а не возиться со всеми этими вызовами
getEngine, eval и прочими. Библиотека для работы со скриптами должна делать всю магию — перехватывать вызов метода интерфейса, получать текст скрипта, подставлять значения параметров, получать нужный скриптовый движок, выполнять скрипт (или вызывать default метод, если текста скрипта нет) и возвращать значение. В идеале, помимо кода, который уже написан, в программе должно быть что-то вроде этого:@Service
public class CustomerServiceBean implements CustomerService {
@Inject
private PricingRepository pricingRepository;
//Other injected beans here
@Override
public BigDecimal applyCustomerDiscount(Customer cust, BigDecimal orderAmnt) {
if (customer.isRegistered()) {
return pricingRepository.applyCustomerDiscount(cust, orderAmnt);
} else {
return orderAmnt;
}
//Other service methods here
}
Вызов читаемый, понятный, и, чтобы его сделать, не надо обладать никакими особыми навыками.
Это были идеи, на основе которых была сделана небольшая библиотека для работы со скриптами. Она предназначена для Spring приложений, этот фреймворк использовался для создания библиотеки. В ней предоставляется расширяемый API для загрузки скриптов из различных источников и их выполнения, который скрывает рутинную работу со скриптовыми движками.
Как это работает
Для всех интерфейсов, промаркированных
@ScriptRepository, во время инициализации контекста Spring при помощи метода newProxyInstance класса Proxy создаются прокси-объекты. Эти прокси публикуются в контексте Spring как singleton бины, поэтому можно объявить поле класса с типом интерфейса и поставить на него аннотацию @Autowired или @Inject. Ровно так, как и планировалось.Сканирование и обработка интерфейсов скриптов активируется при помощи аннотации
@EnableSсriptRepositories, так же, как в Spring активируется JPA или репозитории для MongoDB (@EnableJpaRepositories и @EnableMongoRepositories соответственно). В качестве параметров аннотации нужно указать массив с именами пакетов, которые нужно сканировать.@Configuration
@EnableScriptRepositories(basePackages = {"com.example", "com.sample"})
public class CoreConfig {
//More configuration here.
}
Методы нужно пометить аннотацией
@ScriptMethod (также есть @GroovyScript и @JavaScript, с соответствующей специализацией), чтобы добавить метаданные для вызова скрипта. Конечно же, поддерживаются default методы в интерфейсах. Общее устройство библиотеки показано на диаграмме. Синим выделены компоненты, которые нужно разработать, белым — которые уже есть в библиотеке. Значком Spring помечены компоненты, которые доступны в контексте Spring.
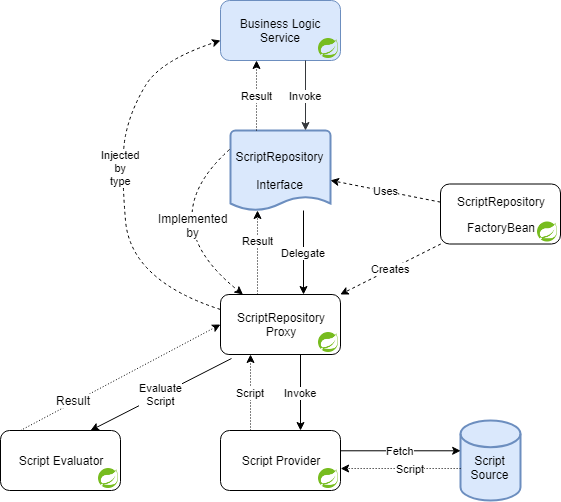
Когда вызывается метод интерфейса (по факту — прокси-объекта), запускается обработчик вызова, который в контексте приложения ищет два бина: провайдера, который будет искать текст скрипта, и исполнителя, который, собственно, найденный текст будет выполнять. Потом обработчик возвращает результат вызвавшему методу.
Имена бинов провайдера и исполнителя указываются в аннотации
@ScriptMethod, там же можно поставить ограничение на время выполнения метода. Ниже — пример кода использования библиотеки:@ScriptRepository
public interface PricingRepository {
@ScriptMethod (providerBeanName = "resourceProvider",
evaluatorBeanName = "groovyEvaluator",
timeout = 100)
default BigDecimal applyCustomerDiscount(
@ScriptParam("cust") Customer customer,
@ScriptParam("amount") BigDecimal orderAmount) {
return orderAmount.multiply(new BigDecimal("0.9"));
}
}
Можно заметить аннотации
@ScriptParam — они нужны для того, чтобы указывать имена параметров при передаче их в скрипт, поскольку Java компилятор стирает исходные имена из исходников (есть способы заставить его это не делать, но лучше на это не полагаться). Можно имена параметров и не указывать, но, в таком случае, в скрипте нужно будет использовать “arg0”, “arg1”, что не сильно улучшает читаемость.По умолчанию, в библиотеке есть провайдеры для чтения .groovy и .js файлов с диска и соответствующие исполнители, которые представляют из себя обертки над стандартным JSR-233 API. Можно создавать собственные бины для разных источников скриптов и для разных движков, для этого нужно имплементировать соответствующие интерфейсы:
ScriptProvider и SpringEvaluator. Первый интерфейс использует org.springframework.scripting.ScriptSource а второй — это org.springframework.scripting.ScriptEvaluator. API Spring использовалось для того, чтобы можно было использовать готовые классы, если они уже есть в приложении. Поиск провайдера и исполнителя производится по имени для большей гибкости — можно заменить в своем приложении стандартные бины из библиотеки, назвав свои компоненты такими же именами.
Тестирование и версионирование
Поскольку скрипты меняются часто и легко, нужно иметь способ как-то убедиться, что изменения ничего не ломают. Библиотека совместима с JUnit, репозиторий просто можно протестировать как обычный класс в составе юнит или интеграционного теста. Mock библиотеки тоже поддерживаются, в тестах к библиотеке можно найти пример того, как сделать mock на метод репозитория скриптов.
Если нужно версионирование, то можно создать провайдера, который будет читать разные версии скриптов из файловой системы, из базы данных или из Git, например. Так можно будет легко организовать откат на предыдущую версию скрипта в случае неполадок на основном сервере.
Итого
Представленная библиотека поможет организовать скрипты в Spring приложении:
- Разработчик всегда будет иметь информацию о том, какие параметры нужны скриптам и что возвращается. А если методы интерфейса названы осмысленно, то и что скрипт делает.
- Провайдеры и исполнители помогут держать код для получения скриптов и взаимодействия со скриптовым движком в одном месте и эти вызовы не будут раскиданы по всему коду приложения.
- Все вызовы скриптов можно легко найти, используя Find Usages.
Поддерживается Spring Boot автоконфигурация, юнит тестирование, mock’и. Можно получить данные о “скриптовых” методах и их параметрах через API. А ещё можно результат исполнения обернуть с специальный объект ScriptResult, в котором будет результат или экземпляр исключения, если не хочется возиться с try...catch при вызовах скриптов. Поддерживается XML конфигурация, если она требуется по тем или иным причинам. И напоследок — можно указывать таймаут для выполнения скриптового метода, если возникнет такая необходимость.
Исходники библиотеки — тут.
elegorod
Главная проблема со скриптами — хакеры могут выполнять произвольный код на сервере, если в приложении пользователи могут редактировать скрипты через UI. Или сами напишут вирус, или, если UI доступен только админам, то могут поменять скрипты через XSS, если не предусмотреть защиты. Или, если скрипты в БД, то могут через SQL-инъекции их подменить.
Так что, если можно обойтись без скриптов — лучше обойтись.
aleksey-stukalov
Безусловно согласен со всеми пунктами. По возможности скриптам нужно выделять отдельный контекст исполнения, например, пользователь с ограниченными правами на базе, отдельное runtime окружение с ограничениями отжираемой памяти и п.р. В данном варианте исполнения репозитория за это отвечает evaluator, соответсвенно, все это приется учесть там.
Однозначно, сколько не решай проблемы с безопасностью — скрипт это дыра в кишки приложения.ggo
Скрипты обычно нужны для кастомизации нетривиальных правил у конечного пользователя. Обычно это суровый enterprise. С трудом представляю себе какой-нибудь ERP/ECM/etc, выставленный наружу.