
Слоёная архитектура (Onion architecture)
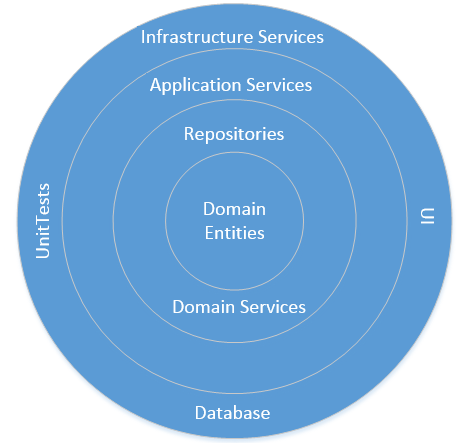
Сегодня довольно распространенной практикой является использование Onion (слоёной) архитектуры для проектирования сложных систем. Она позволяет изолировать доменную логику от остальных частей системы так, что мы можем сфокусироваться на наиболее важных частях приложения.
Изоляция доменной логики означает, что доменные классы могут взаимодействовать только с другими доменными классами. Это один из наиболее важных принципов, которому необходимо следовать для того, чтобы сделать код чистым и связанным (coherent).
На картинке ниже изображена onion архитектура с использованием классической n-уровневой схемы.
Persistence Ignorance
При использовании ORM важно поддерживать хорошую степерь изоляции между доменной логикой и логикой сохранения данных в БД (Persistence Ignorance). Это означает, что код следует структурировать таким образом, чтобы вся логика, относящаяся к сохранению данных в БД, была вынесена из доменных классов. В идеале, доменные сущности не должны содержать никакой информации о том, как они сохраняются в БД. Следование этому правилу позволяет придерживаться принципу единственной обязанности и, таким образом, сохранять код простым и поддерживаемым.
Если вы пишете код, похожий на пример ниже, вы на неверном пути:
public class MyEntity
{
// Perstisted in the DB
public int Id { get; set; }
public string Name { get; set; }
// Not persisted
public bool Flag { get; set; }
}
Если доменная логика отделена от логики сохранения данных, можно сказать что доменные классы являются persistence ignorant. Это означает, что вы можете менять то, каким образом вы сохраняете данные в БД не затрагивая доменную логику. Persistence ignorance — необходимое условие при изолировании доменной логики.
Пример 1: Удаление дочерней сущности из корня агрегата
Давайте рассмотрим примеры кода из реальных проектов.

На рисунке выше изображен агрегат, содержащий два класса. Класс Order является корнем агрегата. Это означает, что Order контролирует время жизни объектов в коллекции Lines. Если Order будет удален, то объекты из этой коллекции будут удалены вместе с ним; OrderLine не может существовать без объекта Order.
Предположим, нам нужно реализовать метод, который удаляет одну из позиций в заказе. Вот как мы можем имплементировать это в случае если наш код не связан с какой-либо ORM:
public ICollection<OrderLine> Lines { get; private set; }
public void RemoveLine(OrderLine line)
{
Lines.Remove(line);
}
Вы просто удаляете позицию из коллекции, и на этом все. До тех пор, пока заказ является корнем агрегата, клиенты этого класса могут получить доступ к его позициям только через ссылку на объект Order. Если в нем не будет этой позиции, можно считать что она удалена, т.к. другие объекты не могут сохранять ссылки на дочерние объекты агрегата.
Если вы попробуете выполнить этот код с использованием Entity Framework, вы получите исключение:
The operation failed: The relationship could not be changed because one or more of the foreign-key properties is non-nullable.
В Entity Framework не существует способа задать маппинг таким образом, чтобы удаленные из коллекции (orphaned) позиции автоматически удалялись из базы. Вам необходимо делать это самому:
public virtual ICollection<OrderLine> Lines { get; set; }
public virtual void RemoveLine(OrderLine line, OrdersContext db)
{
Lines.Remove(line);
db.OrderLines.Remove(line);
}
Передача OrdersContext в метод доменного объекта нарушает принцип разделения ответственности, т.к. класс Order в этом случае содержит информацию о том, как он сохраняется в базе.
Вот как это может быть сделано в NHibernate:
public virtual IList<OrderLine> Lines { get; protected set; }
public virtual void RemoveLine(OrderLine line)
{
Lines.Remove(line);
}
Заметьте, что этот код практически инедтичен коду, который мы бы писали, если бы нам не нужно было сохранять данные в БД. Вы можете указать NHibernate необходимость удалять позиции из БД автоматически после того как они удалены из коллекции:
public class OrderMap : ClassMap<Order>
{
public OrderMap()
{
Id(x => x.Id);
HasMany(x => x.Lines).Cascade.AllDeleteOrphan().Inverse();
}
}
Пример 2: Ссылка на связанную сущность

Предположим, что в один из классов нам необходимо добавить ссылку на связанный класс. Вот пример кода, не завязанный ни на одну ORM:
public class OrderLine
{
public Order Order { get; private set; }
// Other members
}
Вот как это делается в Entity Framework по умолчанию:
public class OrderLine
{
public virtual Order Order { get; set; }
public int OrderId { get; set; }
// Other members
}
Способ по умолчанию в NHibernate:
public class OrderLine
{
public virtual Order Order { get; set; }
// Other members
}
Как можно видеть, по умолчанию, в Entity Framework нужно добавить дополнительное свойство с идентификатором для того, чтобы связать две сущности. Этот подход нарушает принцип единственной ответственности: идентификаторы являются деталью имплементации того, как данные хранятся в БД; доменные объекты не должны содержать в себе подобную информацию. Entity Framework побуждает вас работать напрямую с терминами баз данных, в том время как в данном случае наилучшим выходом было бы создать единственное свойство Order и отдать остальную работу самой ORM.
Более того, этот код нарушает принцип Don’t repeat yourself. Объявление и OrderId, и Order позволяет классу OrderLine очень легко перейти в неконсистентное состояние:
Order = order; // An order with Id == 1
OrderId = 2;
Необходимо отметить, что EF все же позволяет объявлять ссылки на связанные сущности без указания отдельного свойства-идентификатора, но у этого подхода есть два недостатка:
— Доступ к идентификатору связанного объекта (т.е. orderLine.Order.Id) приводит к загрузке всего объекта из БД, не смотря на то, что этот идентификатор уже содержится в памяти. NHibernate, в свою очередь, достаточно умен и не загружает связанный объект из базы в случае если клиент обращается к его Id.
— Entity Framework побуждает разработчиков использовать идентификаторы. Частично из-за того, что это дефолтный способ для того, чтобы ссылаться на связанные сущности, частично из-за того, что все примеры в документации используют именно этот подход. В NHibernate, напротив, дефолтный способ объявления ссылки на связанную сущность — это ссылка на объект этой сущности.
Пример 3: Read-only коллекция связанных сущностей
Если вы хотите коллекцию позиций в заказе коллекцией только для чтения (read-only) для клиентов этого класса, вы можете написать следующий код (версия, не привязанная ни к одной ORM):
private List<OrderLine> _lines;
public IReadOnlyList<OrderLine> Lines
{
get { return _lines.ToList(); }
}
Официальных способ сделать это в EF:
public class Order
{
protected virtual ICollection<OrderLine> LinesInternal { get; set; }
public virtual IReadOnlyList<OrderLine> Lines
{
get { return LinesInternal.ToList(); }
}
public class OrderConfiguration : EntityTypeConfiguration<Order>
{
public OrderConfiguration()
{
HasMany(p => p.LinesInternal).WithRequired(x => x.Order);
}
}
}
public class OrdersContext : DbContext
{
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Configurations.Add(new Order.OrderConfiguration());
}
}
Очевидно, это не тот способ, которые вы хотите применять при проектировании доменной модели, т.к. он напрямую смешивает инфраструктурную логику с доменной. Неофициальный способ немногим лучше:
public class Order
{
public static Expression<Func<Order, ICollection<OrderLine>>> LinesExpression =
f => f.LinesInternal;
protected virtual ICollection<OrderLine> LinesInternal { get; set; }
public virtual IReadOnlyList<OrderLine> Lines
{
get { return LinesInternal.ToList(); }
}
}
public class OrdersContext : DbContext
{
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Entity<Order>()
.HasMany(Order.LinesExpression);
}
}
Опять же, класс Order содержит инфраструктурный код. В Entity Framework нет способа, который позволил бы отделить инфраструктурный код от доменного в подобных случаях.
Вот как это можно сделать с NHibernate:
public class Order
{
private IList<OrderLine> _lines;
public virtual IReadOnlyList<OrderLine> Lines
{
get { return _lines.ToList(); }
}
}
public class OrderMap : ClassMap<Order>
{
public OrderMap()
{
HasMany<OrderLine>(Reveal.Member<Order>(“Lines”))
.Access.CamelCaseField(Prefix.Underscore);
}
}
Опять же, код выше практически идентичен коду, который не завязан ни на одну ORM. Класс Order здесь чист и не содержит никакой информации о том, как он хранится в БД, что позволяет нам сфокусироваться на предметной области.
Код, использующий NHibernate, имеет один недостаток. Он подвержен ошибкам при рефакторинге, т.к. название свойства указано в виде строки. Тем не менее, это разумный компромисс, т.к. этот подход позволяет четко отделить логику предметной области от логики сохранения данных в БД. Кроме того, подобные ошибки довольно легко отлавливаются интеграционными тестами.
Пример 4: Паттерн Unit of Work
Ниже код из задачи, над которой я работал пару лет назад. Я опустил детали для кракости, но основная идея должна быть понятна:
public IList<int> MigrateCustomers(IEnumerable<CustomerDto> customerDtos,
CancellationToken token)
{
List<int> ids = new List<int>();
using (ISession session = CreateSession())
using (ITransaction transaction = session.BeginTransaction())
{
foreach (CustomerDto dto in customerDtos)
{
token.ThrowIfCancellationRequested();
Customer customer = CreateCustomer(dto);
session.Save(customer);
ids.Add(customer.Id);
}
transaction.Commit();
}
return ids;
}
Метод принимает некоторые данные, конвертирует их в доменные объекты и сохраняет после этого. Он возвращает список идентификаторов заказчиков. Внешний код может отметить процесс миграции используя CancellationToken, переданный в качестве параметра.
Если вы используете для этой задачи Entity Framework, то он будет вставлять записи в БД по мере сохранения их в сессии для того, чтобы получить Id, т.к. единственная доступная стратегия генерации целочисленных идентификаторов в EF — database identity. Этот подход работает довольно хорошо в большинстве случаев, но он имеет существенный недостаток: он нарушает принцип Unit of Work. Если вызывающий код отменит выполнение метода, EF придется удалить все записи, вставленные в БД к моменту отмены, что приводит к значительныму проседанию производительности.
С NHibernate вы можете выбрать стратегию Hi/Lo, так что записи просто не будут сохраняться в БД до момента закрытия сессии. Идентификаторы в этом случае генерируются на клиенте, так что нет необходимости сохранять записи в БД для того, чтобы получить их. NHibernate может помочь сохранить существенное количество времени в задачах подобного типа.
Пример 5: Работа с закешированными объектами
Предположим, что список ваших клиентов не меняется часто и вы решаете его закешировать, чтобы не обращаться каждый раз к базе для его получения. Допустим также, что класс заказа имеет предусловие, согласно которому каждый заказ должен принадлежать одному из клиентов. Вы можете имплементировать это предусловие используя конструктор:
public Order(Customer customer)
{
Customer = customer;
}
Таким образом, мы можем быть уверены, что ни один заказ не будет создан без указания его заказчика.
С Entity Framework вы не можете присвоить новому объекту ссылку на detached объект. Если вы напишете код как на примере выше, EF попытается вставить клиента в БД, т.к. он не был приаттачен к текущему контексту. Чтобы исправить это, вам необходимо явно указать, что заказчик уже существует в базе:
public Order(Customer customer, OrdersContext context)
{
context.Entry(customer).State = EntityState.Unchanged;
Customer = customer;
}
Опять же, такой подход нарушает принцип единственной ответственности и устанавливает зависимость между доменной и инфраструктурной логикой. В отличие от EF, NHibernate может определять, является ли объект заказчика новым по его идентификатору и не пытается вставить его в БД если он уже присутствует там. Версия кода, использующего NHibernate, аналогична версии без ORM.
Результаты
Существует простой способ измерить насколько хорошо ORM позволяет изолировать доменную логику от логики сохранения данных в БД. Чем ближе код, который использует ORM к коду, который не привязан ни к одной ORM, тем лучше эта ORM позвояет разделять ответственности в коде.
EF слишком тесно завязан на базу данных. Когда вы пишете код с Entity Framework, вам постоянно приходится думать в терминах foreign-key constraint-ов и взаимосвязей между таблицами. Без чистой и изолированной доменной модели, ваше внимание постоянно отвлекается, вы не можете сосредоточиться на логике предметной области.
Особенность тут в том, что вы можете не замечать этих отвлечений до тех пор пока ваша система не вырастет до достаточно больших размеров. И когда это случается, становится действительно сложно поддерживать прежний тепм разработки новой функциональности из-за возросших затрат на поддержку текущего кода.
Суммируя все вышесказанное, NHibernate все еще впереди Entity Framework-а. Кроме лучшей степени изоляции доменного кода от инфраструктурной логики, NHibernate имеет довольно много полезных фич, которых нет в Entity Framework: кеш 2-го уровня, стратегии одновременного доступа к данным в БД (concurrency strategies), более гибкие способы маппинга данных и т.д. Пожалуй, единственное чем EF может похвастаться — это неброкирующий I/O при работе с БД (async database operations).
В чем же дело? Entity Framework разрабатывается уже в течение многих лет, не так ли? К сожалению, судя по всему, никто в команде EF не рассматривает ORM с точки зрения DDD. Команда Entity Framework все еще думаю об ORM в терминах данных, а не в терминах модели. Это значит, что, несмотря на то, что Entity Framework — хороший инструмент во многих простых ситуациях, если вы работаете над более сложными проектами, NHibernate будет для вас лучшим выбором.
Как по мне, эта ситуация весьма разочаровывающая. Со всей той поддержкой, которую EF получает от Microsoft и со всем доверием, которое разработчики вкладывают в него из-за того, что это рекомендованная (и дефолтная для многих) ORM, Entity Framework мог быть лучше. Судя по всему, в очередной раз в Microsoft не приняли во внимание опыт сообщества и пошли своим путем.
Апдейт
Program manager команды Entity Framework в Microsoft Rowan Miller ответил, что часть описанных выше проблем будет исправлена в EF7. Несмотря на то, что это только часть, будем надеяться что EF изменится к лучшему в будущем.
Ссылка на оригинал статьи: NHibernate vs Entity Framework
Комментарии (83)

Sioln
13.07.2015 10:37+4Если вызывающий код отменит выполнение метода, EF придется удалить все записи, вставленные в БД к моменту отмены, что приводит к значительныму проседанию производительности.
Вы можете пояснить? О каком удалении идёт речь, если у вас там транзакция и commit вызывается за циклом?
vkhorikov Автор
13.07.2015 18:22+1Имеется ввиду, что единственный способ в EF получить целочисленный идентификатор сущности — это сохранить ее в БД. Соответственно если в процессе операции вы решите отменить эту операцию, то вам придется удалить все сохраненные к этому моменту записи вручную. В NH есть различные стратегии генерации ID, что позволяет генерировать их не сохраняя саму сущность в базе.
В EF7 это кстати поправили, Rowan Miller говорит, что там уже есть Hi/Lo стратегия как в NH.
lair
13.07.2015 18:27+1Соответственно если в процессе операции вы решите отменить эту операцию, то вам придется удалить все сохраненные к этому моменту записи вручную.
Зачем же вручную, когда есть транзакция и ее откат?vkhorikov Автор
13.07.2015 18:30+1Либо через транзакцию, да. Суть в том, что в случае отмены операции эти данные придется удалять (либо вручную либо через транзакцию), что приводит к проседанию производительности. Гораздо эффективнее просто не вставлять эти данные в БД до момента завершения транзакции.
lair
13.07.2015 18:31Как этот сценарий разруливается в EF, вам показали (как раз через честный UoW).
vkhorikov Автор
13.07.2015 18:39Вы про ваш коммент? Если да, то это не совсем то, что нужно. Необходимо получение идентификаторов не в конце операции, а именно по мере создания сущностей.
В любом случае, сделать честный UoW, с database generated идентификаторами невозможно.lair
13.07.2015 18:42А зачем вам получать идентификаторы именно по мере создания сущностей?
vkhorikov Автор
13.07.2015 18:51В задаче, к кот. я ссылаюсь в посте, они были нужны для целей real-time репортинга.
lair
13.07.2015 18:54В примере, приведенном в посте, идентификаторы по мере создания сущностей никому не нужны, они получаются после сохранения. Либо вы из примера выкинули рил-таймовую часть, либо я в нем чего-то не понимаю.
Можете описать задачу поподробнее?
(впрочем, будем честными, я очень давно не использую целочисленные идентификаторы, поэтому с такими проблемами сталкиваюсь только теоретически)vkhorikov Автор
13.07.2015 18:59+1Да, я убрал эту часть из примера чтобы не делать нагромождений. У меня в целом была задача показать, что EF хуже поддерживает UoW из-за того, что у него только одна стратегия генерации идшников. Пример я думаю не выбран не слишком удачный для этого, с этим я согласен.
lair
13.07.2015 19:00EF нормально поддерживает UoW. Стратегии генерации идентификаторов тут уже особого значения не имеют (вы же можете идентификаторы и самостоятельно генерить).
vkhorikov Автор
13.07.2015 19:01Да, могу. Проблема в том, что этой функциональности нет из коробки.

FiresShadow
13.07.2015 19:06А NH как будто может отслеживать такие ситуации, что на двух компьютерах попытались почти одновременно сохранить две сущности, в результате чего им сгенерировались одинаковые идентификаторы? Исключение ведь выбросится. Такие проблемы решаются на уровне бд и решение применимо к любой ORM.
vkhorikov Автор
13.07.2015 19:24>А NH как будто может отслеживать такие ситуации
Может. Почитайте про Hi/Lo algorithm.
Например тут: stackoverflow.com/questions/282099/whats-the-hi-lo-algorithmFiresShadow
13.07.2015 19:56Насколько я понял, там говорится про sequence из базы данных, т.е. примерно тоже самое, что и я предлагал. Метод, который бы генерировал идентификаторы также, как и NH, был бы в пару строчек кода и умел бы работать с любым sequence. В крайнем случае, можно написать эту пару строчек кода и выложите в Nuget, и проблема решена.
vkhorikov Автор
13.07.2015 20:08Да, в целом вы правы. Проблема тут только в том, что этой функциональности нет «out of the box»

efremov
14.07.2015 20:00EF генерит вам временные идентификаторы, которые вы можете использовать для внешних ключей в других сущностях. После фиксации изменений во всех местах (и в первичных ключах и во внешних ключах) временные идентификаторы заменяются на сгенерированные БД. В EF 7 только добавили поддержку sequence, т.к. она появилась в MSSQL.

gandjustas
13.07.2015 18:44Если у вас database generated id, то не вставлять нельзя. А если нет, то кто мешает руками нужные ид сохранить самостоятельно?
vkhorikov Автор
13.07.2015 18:48>кто мешает руками нужные ид сохранить самостоятельно?
В EF6 есть только одна стратегия генерации целочисленных Ids — database generated ids, в этом как раз и проблема. Вставка идшников руками решила бы проблему, как это решает Hi/Lo в NH.
gandjustas
13.07.2015 18:42А кто же мешает не вставлять? Просто не вызывать save changes для контекста, а id получить после сохранения,
FiresShadow
13.07.2015 18:53А зачем вам нужны идентификаторы? Наверное чтобы сослаться на эту сущность в других сущностях, так? Для этого есть NavigationProperty.
Но даже если вам всё таки нужны идентификаторы, то это вполне реализуемо для любой ORM. Храним максимальный идентификатор в каком-нибудь sequence или отдельной таблице, и в рамках одной транзакции увеличиваем его на единицу и достаём из бд. Получаем уникальный идентификатор без необходимости сохранения сущностей в базу.
lair
13.07.2015 11:47+2Пример 3: Read-only коллекция связанных сущностей
В EF можно легко добиться того же разделения, что в NH, за счет либо (а) иной области видимостиLinesInternal(тогда можно будет конфигуратор вынести за пределы класса), либо (б) построения выражения для маппинга не через лямбду, а вручную.
Пример 4: Паттерн Unit of Work
Тут неплохо бы определиться, что на самом деле надо. Если просто нужна отмена, то в EF сработает вот такой код:
public IList<int> MigrateCustomers(IEnumerable<CustomerDto> customerDtos, CancellationToken token) { List<Customer> customers = new List<Customer>(); using (var db = new CustomerDbContext()) { foreach (CustomerDto dto in customerDtos) { token.ThrowIfCancellationRequested(); Customer customer = CreateCustomer(dto); customers.Add(db.Add(customer)) } db.SaveChangesAsync(token).Wait(); //метод снаружи не асинхронный - а зря } return customers.Select(c => c.Id).ToList(); }
Если же медленнно работает само сохранение в БД, и отмену надо сделать между двумя строками, то транзакция выгоднее (пусть даже мы и тратим время на ее откат).
Пример 5: Работа с закешированными объектами
[...]
С Entity Framework вы не можете присвоить новому объекту ссылку на detached объект. Если вы напишете код как на примере выше, EF попытается вставить клиента в БД, т.к. он не был приаттачен к текущему контексту.
Это, скажем так, неточно. Действительно, эта проблема существует, но она возникает не в момент присвоения клиента в конструкторе заказа, а при сохранении заказа в БД. В EF достаточно возможностей по анализу графа сущностей перед сохранением, чтобы сделать необходимую проверку и не сохранять лишние объекты в БД.
gandjustas
13.07.2015 12:10+1Изоляция доменной логики означает, что доменные классы могут взаимодействовать только с другими доменными классами
А как вы собираетесь «изолировать логику» проверки уникальности? Например надо не продать два билета на одно место на концерт.
Или как сделать целостность на несколько сущностей? Например не создавать заказ, если на складе больше нет данной позиции.
Теория DDD красива только в теории. На практике сделать прикладную логику только на взаимодействии классов, которые не знают о базе данных — невозможно, кроме самых примитивных моделей.lair
13.07.2015 12:14+2Теория DDD красива только в теории. На практике сделать прикладную логику только на взаимодействии классов, которые не знают о базе данных — невозможно, кроме самых примитивных моделей.
Это зависит от трактовки DDD. Почему-то каждый раз, когда рассматривают «применимость ORM для DDD», забывают, что в DDD есть не только доменные сущности, но и доменные сервисы — а вот этим уже вполне можно знать про перзистентный слой.gandjustas
13.07.2015 12:45Доменные сервисы вообще-то в DDD и появились потому что изначальная идея о взаимодействии доменных классов нежизнеспособна.
lair
13.07.2015 12:51+1Ну, я не очень хочу спорить о том, почему доменные сервисы появились в DDD, мне достаточно того, что у Эванса они уже есть, и на этом фоне как-то странно, что они регулярно пропадают из дискуссий «как нам сделать на DDD вот такое-то».
gandjustas
13.07.2015 13:31Domain Service, к сожалению, разрушает целостную картину DDD.
Возникает много вопросов:
1) Как распределеть отвественность между сервисами, репозитариями и сущностями?
2) Кто вызвает сущности\репозитарии\сервисы?
У Эванса, кстати, нет ответа на эти вопросы.
Проще создать ютный мирок, в котором любая логика описывается в терминах методов классов-сущностей и не покидать его ни по каким причинам.lair
13.07.2015 13:35+1Как распределеть отвественность между сервисами, репозитариями и сущностями?
Ответственность репозитория понятна: он должен обеспечить сохранение и восстановление агрегата в/из БД.
Разделение ответственности между сущностями и сервисами, очевидно, не так уж и просто, ну так и работа архитектора — вообще не очень простая. Есть несколько правил большого пальца, одно из которых сводится к тому, что если все данные для работы есть в агрегате, то это его ответственность, если нужно координировать несколько агрегатов — ответственность сервиса.
Кто вызвает сущности\репозитарии\сервисы?
«Следующий» слой. Для приложения это будет либо презентационный слой, либо слой прикладных сервисов, для сервисов — фасад.gandjustas
13.07.2015 13:45Как раз интересует кто кого вызывает в связке app services — domain services — domain entities — repository. Я видел трехдневный холивар на эту тему, причем не в интернатах а вживую.
С репозитариями тоже не все однозначно. Вот требуется вывести список заказов с суммами заказов, рассчитаными на основе OrderLines. Вопрос: где должен быть расчет — в entity, domain service или repository?lair
13.07.2015 14:11+1Как раз интересует кто кого вызывает в связке app services — domain services — domain entities — repository. Я видел трехдневный холивар на эту тему, причем не в интернатах а вживую.
Холиварить можно на любую тему, было бы желание. Насколько я помню, формально картина выглядит так: прикладные сервисы могут вызывать всех трех, доменные сервисы могут вызывать репозиторий и сущности, сущности могут (но лучше избегать) вызывать доменные сервисы.
Вот требуется вывести список заказов с суммами заказов, рассчитаными на основе OrderLines. Вопрос: где должен быть расчет — в entity, domain service или repository?
Формально этот расчет — ответственность сущности. Сложности возникают вокруг того, как добиться, чтобы у сущности были все данные, нужные для этого расчета, и не было дикого количества запросов к БД.
efremov
14.07.2015 20:09-1А как вы собираетесь «изолировать логику» проверки уникальности? Например надо не продать два билета на одно место на концерт.
Или как сделать целостность на несколько сущностей? Например не создавать заказ, если на складе больше нет данной позиции.
Эти задачи вполне решаются передачей их на aggregation rootgandjustas
14.07.2015 21:51Да что вы?
Ну вот простая ситуация: две точки продаж билетов по городу. В обоих разные люди пытаются купить билеты. Запросы от точек приходят на разные инстнасы веб-приложения. Что нужно сделать в aggregation root, чтобы гарантированно не продать два билета на место?efremov
14.07.2015 22:10Счетчик там храните. Вторая транзакция не зафиксируется, из-за того что первая изменит счетчик в руте и изменит тем самым rowversion рута. Получите во второй транзакции ConcurrencyException и обработаете его.
efremov
14.07.2015 22:19P.S. Это более общее решение. В данном случае вам AR вообще не нужен, можно просто отловить нарушение UNIQUE KEY.
gandjustas
14.07.2015 22:29Именно.
Я об этом и писал — в DDD нет нормальной возможности выразить всю логику в терминах операций с доменными объектами. По сути для решения задачи абсолютно все равно будет у вас DDD или напрямую в базу запросы слать — все равно придется делать уникальный индекс и ловить нарушение. Поэтому DDD тут находится гораздо дальше от объективной реальности, чем подход ориентированный на запросы.
Поэтому и не стоит заморачиваться на DDD, лучше работу переложить на БД, генерируя хорошие запросы (что с EF очень легко делать), а в приложении уже разбираться с отображением данных, валидацией ввода. и обработкой ошибок.efremov
14.07.2015 23:15+1Если у вас доменная модель должна учитывать физическую модель развертывания, то вам нужно явно вводить front-end-ы в доменную модель со всеми вытекающими артефактами доменной модели для распределенной обработки. Стоит ли это делать? В случае data-centric application, каким, явно, является заказ билетов, этого не стоит, доменная модель не для него. Ваша объективная реальность лежит среди таких приложений (а их вокруг, действительно, очень много). Поэтому доменная модель вам и кажется необоснованной. Однако это не повод отрицать существование приложений, ориентированных на бизнес-логику, особенно инжектированную бизнес логику. В этом случае доменная модель вполне себе работает.
gandjustas
14.07.2015 23:49Любое многопользовательское приложение с бд по вашему будет data-centric. Ведь в сухом остатке важно что попадет в базу, а не какие классы в приложении. Получается единственная область применения DDD — простые, в основном однопользовательские, приложения без конкурентного доступа к данным. Но для таких приложений DDD — избыточные приседания.
lair
14.07.2015 23:49Заказ билетов нифига не data-centric, там очень много всего любопытного и интересного может случиться. Просто это типовой пример на concurrency.
FiresShadow
15.07.2015 09:33в DDD нет нормальной возможности выразить всю логику в терминах операций с доменными объектами.
Почитайте Эванса, помимо доменного уровня в DDD есть и другие уровни. Не нужно запихивать всю логику в доменный уровень.
1) Как распределеть отвественность между сервисами, репозитариями и сущностями?
У Эванса подробно и детально разжёвано, кто и к кому обращается и какой слой за что несёт ответственность. Процитирую отрывок: «уровни прикладных операций и предметной области обращаются к СЛУЖБАМ, предоставляемым инфраструктурным уровнем.»
2) Кто вызвает сущности\репозитарии\сервисы?
У Эванса, кстати, нет ответа на эти вопросы.
gandjustas
15.07.2015 11:00И в какой уровень по вашему нужно запихнуть проверку уникальности? И как это соотносится с DDD?
У эванса в книге вообще не расписано как распределять функционал между доменными службами и сущностями. Может вы скажете — расчет суммы заказа по позициям где должен выполняться?FiresShadow
15.07.2015 12:34+1И в какой уровень по вашему нужно запихнуть проверку уникальности?
Если мы проверяем, не продан ли билет на это место перед тем, как начать создание и сохранение билета, то это бизнес-логика приложения: «нельзя продавать два билета на одно и то же место». Проверка в процессе сохранения того, что мы не пытаемся сохранить в персистентное хранилище два билета на одно и то же место — это уже не бизнес-логика приложения, а всего лишь необходимость, возникающая из-за того, что несколько клиентов могут попытаться почти одновременно создать два билета на одно место. А так как это не бизнесс-логика и не координирование задач, то, согласно DDD, проверку уникальности в момент сохранения нужно поместить в инфраструктурный уровень. Процитирую определение Эванса, которое он даёт инфраструктурному уровню: инфраструктурный уровень обеспечивает непосредственную техническую поддержку для верхних уровней: передачу сообщений на операционном уровне, непрерывность существования объектов на уровне модели, вывод элементов управления на уровне пользовательского интерфейса и т.д. Итак, проверка должна находиться в инфраструктурном уровне.
Давайте теперь определимся в каком именно классе. Согласно ООП, данные и код, работающий с этими данными, следует поместить в одном классе. Таким образом, проверка уникальности должна находиться в коде персистентного хранилища. Если в качестве персистентного хранилища у вас используется файл на жёстком диске, то нужно написать класс, который будет производить чтение\запись в этот файл и контролировать уникальность. Если в качестве персистентного хранилища вы используете базу данных, то вам повезло — этот код уже написан за вас и вам нужно лишь декларативно указать, что два билета на одно место сохранять в хранилище нельзя.
расчет суммы заказа по позициям где должен выполняться?
Расчёт суммы заказа это бизнес-логика, она должна находиться в доменном уровне.
Прочитайте лучше книжку Эванса. Как я и говорил, он все эти моменты довольно подробно разжёвывает, в том числе объясняет когда следует использовать доменные сервисы.gandjustas
15.07.2015 12:45Таким образом, проверка уникальности должна находиться в коде персистентного хранилища
Ну собственно что и требовалось доказать, важная часть логики (на самом деле САМАЯ важная часть) выпала из структуры DDD вообще.
Расчёт суммы заказа это бизнес-логика, она должна находиться в доменном уровне.
Вы не ответили на конкретный вопрос, это будет класс сущности, domain service или репозиторий?
Прочитайте лучше книжку Эванса. Как я и говорил, он все эти моменты довольно подробно разжёвывает, в том числе объясняет когда следует использовать доменные сервисы.
Я её читал более одного раза и очень внимательно. Там нет ответа на этот вопрос. Вообще эванс в книге очень много токних моментов обходит, а потом они всплывают в разработке.FiresShadow
15.07.2015 12:55+1Ну собственно что и требовалось доказать, важная часть логики (на самом деле САМАЯ важная часть) выпала из структуры DDD вообще.
Инфраструктурный уровень, по вашему, не имеет ничего общего со структурой DDD? DDD — это концепция проектирования программ, и понятие инфраструктурного уровня — часть этой концепции.
Вы не ответили на конкретный вопрос, это будет класс сущности, domain service или репозиторий?
Алгоритм расчёта суммы заказа будет или в доменной сущности, или в доменном сервисе — в зависимости от предметной области и сложности самого расчёта.gandjustas
15.07.2015 15:22DDD не описывает инфраструктурный уровень если что. Максимум что описывает DDD — репозиторий, как компонент между инфраструктурой и доменом.
Алгоритм расчёта суммы заказа будет или в доменной сущности, или в доменном сервисе — в зависимости от предметной области и сложности самого расчёта.
Предметная область — интернет-магазин. Расчет — как обычно просто сумма по позициям, но бизнес меняется, в будущем будут и скидки и, возможно, что-то еще.FiresShadow
15.07.2015 17:06+1DDD не описывает инфраструктурный уровень если что. Максимум что описывает DDD — репозиторий, как компонент между инфраструктурой и доменом.
Повторюсь, DDD — это концепция проектирования. Цитируя Эванса, DDD — это «система взглядов и подходов». Один из таких подходов — разделить приложение на уровни, в том числе на инфраструктурный уровень. И репозиторий не является компонентом между инфраструктурным и доменным уровнями.
Если честно, мне немного непонятно, зачем человек, который не знает определения DDD, не понимает какой уровень за что отвечает и пр, берётся пропагандировать, что
Теория DDD красива только в теории.
Расчет — как обычно просто сумма по позициям
Тогда в доменной сущности.FiresShadow
15.07.2015 17:26У меня есть предположение, что может не давать вам покоя в вопросе про проверку уникальности билета на стороне хранилища. Сначала нужно сделать проверку в доменном уровне на уникальность, а потом ещё и в инфраструктурном. Но этот вопрос легко решается. В одном месте задаём правило, а потом на основе этого правила и делаем проверку в доменном уровне, и генерируем правило для хранилища. Правила для хранилища можно генерировать например вот так.
gandjustas
15.07.2015 18:53Как делать индексы в codefirst я знаю. А как сделать проверку уникальности в доменном уровне? Так чтобы приложение не легло под нагрузкой от 10 таких проверок параллельно.
gandjustas
15.07.2015 18:51Повторюсь, DDD — это концепция проектирования.
Это болтология.
Для начала стоит придумать дифференцирующее определение что есть DDD, а что им не является. Причем с точки зрения кода. Иначе вообще нет смысла ни о чем говорить. Эванс такое определение дал в DDD Pattern Language, предложив конкретную архитектуру для DDD.
Вот только эта архитектура получилась дырявая со всех сторон, далеко не всю бизнес-логику можно хорошо выразить в этой архитектуре.
Еще раз повторю, что меня интересует код, а не философия.
Тогда в доменной сущности.
И вы только что сделали получение списка заказов в разы медленнее, чем стоило бы.
И если бы такой случай был единичным, то все было бы ок. Но когда такой подход распространяется на все приложение то начинает тормозить очень сильно. В приложениях довольно часто встречаются master-detail связи и каждый раз надо выводить список master c агрегированием detail.FiresShadow
16.07.2015 06:55Как уже говорил lair, холиварить можно на любую тему, было бы желание. Например, знает ли Эванс что такое DDD, или же определение, которое он дал в своей книге, неверно. Имеет ли деление кода на слои и уровни какое то отношение к коду, или это просто болтология. Можно ли реализовать приложение в духе DDD с приемлемым быстродействием. Но у меня нет желания холиварить на эти темы. Так что будем считать что каждый остался при своей точке зрения.

Bronx
16.07.2015 11:13-1> Расчет — как обычно просто сумма по позициям, но бизнес меняется, в будущем будут и скидки и, возможно, что-то еще.
Если правила расчёта меняются, то это работа для доменного сервиса, который использует политики расчёта (которые, в свою очередь, могут являться доменными объектами), загружая их из репы, компонуя и запуская расчёт.
То же самое для сложных валидаций с композитными политиками: собирать политики и дирижировать ими — это работа для сервиса.
Сам по себе доменный объект должен проверить лишь то, о чём он имеет _полную_ информацию. Полнота информации — ключевой фактор! Если объект хранит коллекцию, и у него гарантировано имеется полная информация о всех элементах коллекции — значит нужно проверять и коллекцию. Например, объект и его подчинённые сущности только что созданы, никогда не сохранялись в хранилище с конкурентным доступом и посему гарантированно существуют в единственном экземпляре. Или, скажем, если получение объекта из хранилища автоматически влечёт блокировку этого объекта в хранилище (отдельные места в зале временно блокируются в момент когда пользователь выбирает их, и разблокируются лишь при отмене заказа или по таймауту).
Если таких сильных гарантий полноты нет — значит надо делегировать эту задачу тому, у кого есть полная информация (например хранилищу), либо пересматривать инварианты в сторону ослабления (например, в распределённой системе поддерживать только локальные инварианты, а глобальными пусть занимается система разрешения конфликтов).
Если доменная область такова, что вообще трудно дать какие-то гарантии внутри сущности, и все вопросы приходится решать в сервисах — то это вырождается в anemic domain model + transaction script. Тоже бывает.
gandjustas
13.07.2015 12:43+1Пример 1: Удаление дочерней сущности из корня агрегата
Объясните мне простую вещь. Зачем грузить сущность заказа и все его позиции, чтобы удалить одну позицию?
Более того, даже сам OrderLine грузить не надо, надо лишь присоединить к контексту объект к ID в состоянии Deleted.
Описанная проблема исключительно надуманная (созданная NH). В реальности её не существует.
Пример 2: Ссылка на связанную сущность
Это просто вранье. В EF ты почему-то рассматриваешь Code First, который очевидно генерит схему по свойствам и нужно все поля выписывать в объектах, чтобы сделать мэпинг. А в database first вполне можно замапить связанную сущность без поля внешнего ключа. (также как в NH) Более того, в EF первой версии только так и работало.
НО! Когда создавался EF4 это был самый популярный запрос — сделать поля внешних ключей. Потому что все прекрасно понимают, что для добавления order line вовсе необязательно грузить Order.
Пример 3: Read-only коллекция связанных сущностей
Во-первых это настолько редкий кейс, что любой программист суммарно напишет гораздо меньше кода для реализации всех таких кейсов, чем ты написал для этого примера.
Во вторых, это просто выдавание желаемого за действительное.
Вот EF
protected virtual ICollection<OrderLine> LinesInternal { get; set; } public virtual IReadOnlyList<OrderLine> Lines { get { return LinesInternal.ToList(); } }
Вот NH
private IList<OrderLine> _lines; public virtual IReadOnlyList<OrderLine> Lines { get { return _lines.ToList(); } }
Разница только в видимости, но это прекрасно решается с помощью модификатора internal.
«Проблема» высосана из пальца. На практике вовсе не проблема.
Пример 4: Паттерн Unit of Work
Прости, но это просто бред. Это в NH надо вызывать сохранение объекта в сессии, чтобы id генерировались. А в EF этого делать не надо. Поэтому в EF надо только оставить SaveChanges в конце цикла и все. Даже транзакция не нужна.
Кстати создание ID на клиенте — ахтунг при конкурентном доступе. Так что в этой ситуации EF сработает даже лучше NH.
Пример 5: Работа с закешированными объектами
Снова выдаешь желаемое за действительное.
Во-первых что в EF, что в NH у Order будет parameterless конструктор, так что смысла в создании конструктора с параметром Customer нету.
Во-вторых в EF можно просто id кастомера присвоить свойству-внешнему ключу, для этого даже список кастомеров в памяти держать не надо.
То есть для NH такая проблема есть и она как-то решается. Для EF этой проблемы просто нет.
Короче ты показал как EF не умеет решать проблемы, которые создает NH. Можно ли в этом обвинять EF — сомневаюсь.efremov
14.07.2015 20:15+1Причем в обоих случаях это вообще не решение для encapsulates collections т.к. во-первых .ToList() при каждом обращении, а во вторых если эту коллекцию использовать в запросе, то на SQL это, очевидно, не провалится.

kayan
13.07.2015 13:12+1Как можно видеть, по умолчанию, в Entity Framework нужно добавить дополнительное свойство с идентификатором
Насколько я помню — это не обязательно (для CodeFirst, по крайней мере).
Ключи можно указать в маппинге просто строкой (именем столбца-внешнего ключа).gandjustas
13.07.2015 13:22А такое разве сработает если база генерируется по коду?
lair
13.07.2015 13:29+1Есть возможность сконфигурировать такое поведение (точно через fluent configuration, возможно через атрибуты тоже).
kayan
13.07.2015 17:47Да. Даже промежуточная таблица для связи многие-ко-многим автоматически создастся.
FiresShadow
1)
Если бы вместо OrdersContext был интерефейс IOrdersContext, то Order не знал бы КАК он сохраняется в бд, а просто знал бы, ЧТО он сохраняется в неком хранилище. И это было бы гораздо лучше, чем гибернейтовская автомагия.
2)
В гибернейте есть специальных флаг отложенной загрузки связанных сущностей LazyLoad. Беда в том, что необходимость отложенности загрузки зависит от места использования. В итоге для сущностей, которые используются в нескольких местах, или куча ненужной информации из бд тянется (если не установлен LazyLoad), или из-за отложенной загрузки для каждого бизнес объекта из выборки (коих может быть миллион) по несколько запросов в бд идёт (т.е. несколько миллионов запросов) (это если установлен LazyLoad), или в коде несколько одинаковых маппингов, отличающихся лишь флагами LazyLoad. То есть или получается нарушение DRY, или всё жутко тормозит. Подход с идентификаторами мне кажется более приемлемым. Невелика беда, что данные хранятся не в хранилище List
FiresShadow
(Часть комментария не сохранилась, видимо из-за наличия в нём <ob_ject> без подчёркивания)
<ob_ject>, а в Dictionary<int, ob_ject> (под хранилищем-словарём имеется ввиду бд).
3)
А вот и неправда. Пока не будет вызвано session.SaveChanges(), ничего в базу данных сохраняться не будет, а будут подставлены фиктивные идентификаторы. Поэтому собирать идентификаторы смысла нет, вместо этого нужно использовать ссылки на связанные сущности (NavigationProperty).
4)
А что мешает, вынести context.Entry(customer).State = EntityState.Unchanged в класс, который занимается кэшированием?
FiresShadow
Подумал по поводу флага LazyLoad — в принципе можно динамически генерировать маппинг на основе декларативных указаний где нужен LazyLoad, а где нет, но тогда маппинг станет сложнее и велик риск неправильно указать необходимость LazyLoad, и если ошибиться, то потом будет сложно разобраться, почему программа тормозит.
Если же для извлечения данных использовать джойны только по нужным таблицам, то не ошибёшься, но писанины станет чуть больше. Я предпочитаю решения, в которых сложнее ошибиться. Подход с идентификаторами можно совместить с ссылками на связанные сущности (NavigationProperty). Тогда можно обеспечить хорошее быстродействие там, где это нужно, и удобство использования в остальных местах.
В любом случае, не вижу серьёзного нарушения дизайна в добавлении поля с идентификатором. В конце концов, можно просто этим полем не пользоваться, и добавить юнит-тест, проверяющий что нигде в вашем коде это поле не используется.
gandjustas
Lazy load не нужен нигде, от слова вообще.
FiresShadow
Почему не нужен? В некоторых случаях Lazy load позволяет уменьшить время запроса в несколько раз.
lair
Именно Lazy, т.е. отложенная загрузка, или Partial — когда грузится только то, что нужно для работы?
Если первое, то вы не могли бы привести пример?
FiresShadow
Например в маппинге fluent nhibernate заказа есть следующий код:
References(x => x.Customer).Column(«CUSTOMER_ID»).LazyLoad();
Тогда при загрузке из бд заказа поле Customer не заполнится, но оно считается из бд при первом обращении к этому полю.
Если грузится сразу много заказов и по факту нужна только треть таких полей (связанных сущностей из других таблиц), то запрос может занимать несколько минут, и его оптимизация оправдана.
lair
Проблема этого подхода в том, что если у вас из запроса на n сущностей нужно m деталей, то при очень малых m вы в выигрыше, а вот при больших можете оказаться, наоборот, в проигрыше. И вот эта недетерминированность очень опасна — вы никогда не знаете, сколько именно запросов в БД порождает ваш код.
FiresShadow
Не совсем понимаю. По-моему, всегда в выигрыше. Если без использования LazyLoad NH сгенерирует примерно следующий код
select * from Table
join Table2 on…
join Table3 on…
Если указать что Table2 и Table3 LazyLoad, то NH сгенерирует «select * from Table».
Если потом в коде не обращаться к Table.Table2 и Table.Table3, то всегда в выигрыше.
Если в коде для каждого объекта Table обратиться к Table.Table2 и Table.Table3, то всегда в проигрыше.
lair
Если всегда не обращаться, то в выигрыше тот код, который не грузит — это как раз partial loading.
Если всегда обращаться, то в выигрыше код, который грузит сразу (eager loading).
А вот если обращаться не всегда, то, в зависимости от соотношения сколько раз надо обратиться, и сколько — нет, может быть быстрее eager или lazy.
FiresShadow
Так я как раз и писал о том,
lair
Что значит «зависит от места использования»? Код, который гуляет по списку ордеров, сам определяет, надо ли грузить кастомеров? В этом случае проблема вашего кода — недетерминированная производительность.
FiresShadow
Не совсем понимаю, почему если точно знать будут ли в этом месте использоваться заказчики и перед загрузкой заказов указать нужно ли сразу загрузить и заказчиков, то возникает недетерминированная производительность? Очень даже определенная производительность — можно даже план запроса посмотреть. А будут использоваться заказчики или же нет, можно и по коду посмотреть. Но вот если до того, как мы достали заказы точно неизвестно, нужны заказчики или нет, да ещё для некоторых заказов нужны, а для некоторых нет, то лучше их сразу всех загрузить одним запросом. По крайней мере мы точно можем определить по коду (или по постановке задачи): или заказчики точно не нужны, или возможно понадобятся.
FiresShadow
Если точнее, не программист запрос к бд на всех заказчиков указанных заказов напишет, а NH автоматически джойн заказов с заказчиками сделает в момент доставания заказов из бд и соответствующие свойства Заказ.Заказчик заранее заполнит, если флаг LazyLoad не выставлен.
gandjustas
Это все равно медленнее, чем затянуть сразу все заказы с кастомерами + применить проекцию.
lair
Похоже, проще на примерах.
1. Частичная загрузка:
2. Жадная (eager) загрузка:
Это вариант медленнее, чем (1), зато работает.
3. Проекция
Этот вариант быстрее, чем (2) (и чем (1) — тоже), и при этом все еще работает.
4. Ленивая (lazy) загрузка:
Это самый медленный вариант (даже медленнее чем (2)).
5. Ленивая (lazy) загрузка с условием:
А производительность этого варианта недетерминирована, потому что напрямую зависит от количества подозрительных заказов. Если их ни одного — производительность будет как у (1), то есть разумной, а если их больше некоего количества — то производительность станет хуже, чем у (2), и в худшем случае будет как у (4).
Вот и возникает вопрос — а зачем, все-таки, нужна ленивая загрузка (т.е. варианты 4 и 5)?
efremov
В таких сценариях она не нужна. Но полезна в следующих примерах:
Lazy load must have в rich-модели, поскольку пользователь такой модели не имеет никакого представления о проекции данных, которая на самом деле требуется entity для выполнения запрошенной им функции. Конечно, при применении такой функции к листу объектов, автоматически получаем какой-то из вариантов «SELECT N+1»-проблемы. Поскольку EF в настоящий момент не дружит с rich подходом, то и без lazy load вполне можно обойтись.
lair
Прямо скажем, в EF lazy load есть, так что EF этот сценарий обработает из коробки без проблем.
Другое дело, что меня «SELECT N+1» пугает весьма сильно в таких сценариях.
gandjustas
Это проблема NH. EF не генерирует джоины если явно не попросишь об этом — через include или связанные сущности в linq-запросе. Так что утверждение про LL верно только в контексте NH.
А вообще неявные джоины это жопа для быстродействия. Только из за них nh категорически не стоит использовать.
qw1
Пример: в сущности Order есть ссылки на справочники (OrderType, OrderState, City)
Запрос выбирает 10 млн. Order, если LazyLoad включен, основной запрос будет без join, что сильно его ускорит, а отдельно загрузятся всего лишь десятки элементов. Если бизнес-операция сложная (несколько запросов к Orders), большая вероятность, что эти lazy-сущности и так уже в кеше сессии.
lair
(я не буду спрашивать, зачем грузить десять миллионов заказов с подключенными справочниками)
Вы делали реальное сравнение, в котором было бы видно, что оверхед от дублей в результирующем наборе записей больше, чем потери от отдельных запросов в БД за каждым элементом справочника (которых тоже может набежать достаточно много в сумме)?
qw1
Вопрос не только в производительности, но и в удобстве.
Я хочу писать ф-ции, принимающие entity, при вызове которых не надо думать, к каким полям они теоретически могут обратиться, чтобы заранее их прогрузить. Если из-за lazy будет много догрузок, я это замечу и добавлю в запрос join (обычно до этого не доходит: если понятно, что поле будет использоваться и это не справочник, join сразу пишется в запрос).
Самый оптимальный вариант, с проекциями, вообще предлагает каждый сценарий обрабатывать уникально и ни о каких общих ф-циях, принимающих entity, речи нет. Понятно, что для каких-то узких случаев проекции это самое лучшее, но я бы не стал категорично утверждать, что у LazyLoad вообще нет применений.
lair
А я этого и не утверждал. Я просто считаю, что в среднем lazy load — это жертва скоростью в пользу удобства, и каждый для себя выбирает, где ему комфортно остановиться.
gandjustas
Это я утверждал.
В любой системе есть разделение запросов и операций изменений данных. В вебе это просто два разных HTTP запроса на сервер.
Далее:
1) Если у вас запрос, который тянет много строк, то без покрывающих индексов не обойтись уже на десятке тысяч записей в базе. А использовать покрывающие индексы без проекций невозможно. Так что как ни крутись, но для любых серьезных объемов надо делать проекции.
2) Операции изменения в 90% и более случаев затрагивают одну запись или небольшое множество записей, так как пользователь физически не сможет на одном экране обработать одной корневой и нескольких связанных записей. В этом случае вполне можно тянуть и полные объекты (сущности).
Это все создает сложности? Совершенно не создает. Запрос\команда пользователя всегда приходит в разные контроллеры\application services. Соотвественно в них и можно решать что загружать, а что — нет.
Вы и так это уже делаете
Остается сделать маленький шаг в сторону правильной архитектуры — отказаться в запросах от методов, работающих с полными сущностями и работать только с IQueryable, навешивая проекцию только в контроллере (ибо только в контроллере мы точно знаем как данные будут отображаться). При обработке команд изменения можно оставить как есть, ибо большого влияния на быстродействие это не окажет.
Если у вас, не дай бог, двузвенная архитектура и вы ходите в базу напрямую из клиентского кода, то вам тоже надо делать проекции, так как сеть часто становится узким местом. В отличие от трехзвенки, где сервер и база находятся в одной сети с толстым каналом, клиент двухзвеки обычно «далеко» (относительно небольшая пропускная способность, высокая латентность) от базы и тянуть полные объекты, тем более с джоинами — очень сильно забивает канал и снижает отзывчивость. Это прекрасно видно на примере толстого клиента 1С.
Единственный вариант когда можно (и даже нужно) не делать проекции, а работать с lazy load — локальная (embedded) база для небольшого клиентского приложения. В этом случае вы можете спокойно держать ссылку на целый объект сколько угодно долго и не беспокоиться, что получение данных забьет канал, так как чтение данные, считанные с диска уже попадают в память приложения и вы не выиграете ничего от проекций.
qw1
В Hibernate достаточно добавить пустую критерию на lazy-сущность, чтобы она загрузилась