
Принцип разделения ответственности
В каждом приложении мы имеем дело с несколькими понятиями (concerns). Как минимум три из них как правило четко определены: UI, бизнес логика и база данных. Принцип разделения ответственности тесно связан с принципом единственной обязанности (Single Responsibility Principle, SRP). Вы можете думать о SoC как о SRP примененном не к единственному классу, а к всему приложению. В большистве случаев эти два принципа могут использоваться взаимозаменяемо.
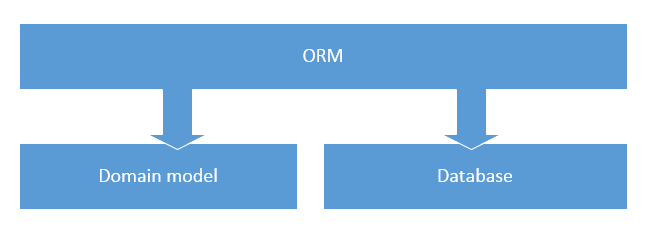
В случае с ORM принцип SoC относится к разделению логики предметной (доменной) области и логики сохранения данных в БД. Мы можем утверждать, что код приложения имеет хорошую степень разделения ответственностей если доменные классы в нем не знают о том, как они сохраняются в базе данных. Конечно, не всегда возможно достичь полного разделения этих двух областей приложения. Иногда требования производительности таковы, что приходится нарушать эти границы. Но в любом случае, всегда стоит стремиться к настолько полному разграничению ответственностей, насколько возможно.
И конечно, мы не можем просто так отделить доменную логику приложения от логики сохранения данных в БД, нам требуется что-то, что соединит их вместе. Именно в этом нам помогают ORM. ORM выступает медиатором между кодом доменной модели и базой данных. В большинстве случаев, ORM способна сделать это таким образом, что ни код предметной области, ни БД не знают о существовании друг друга.
Почему SoC важен?
Существует немало информации о том, как поддерживать хорошую степерь разделения ответственностей. Но почему это важно?
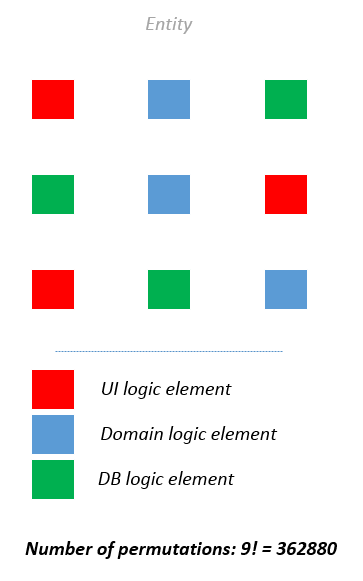
При сохранении различных ответственностей в едином классе, нам приходится коддерживать их консистентность одновременно с каждой операцией в рамках этого класса. Это очень быстро приводит к комбинаторному взрыву. Более того, сложность приложения нарастает гораздо быстрее, чем думают большинство разработчиков. Каждая дополнительная ответственность увеличивает сложность класса на порядок.
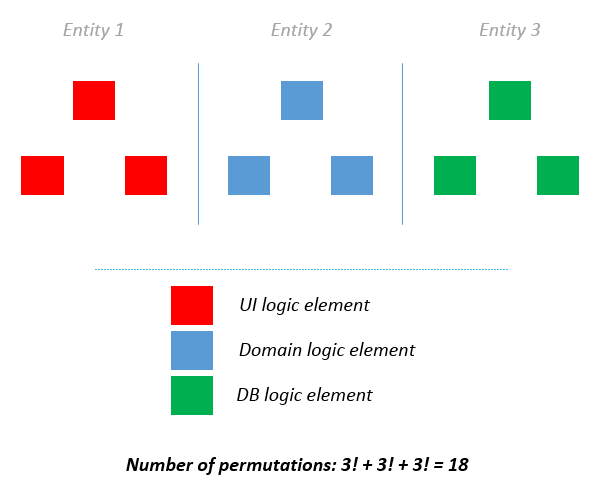
Чтобы справиться со всей этой сложностью, нам необходимо разделить эти ответственности:
SoC — это не просто вопрос хорошего или красивого кода. Принцип SoC жизненно важен для поддержания приемлемой скорости разработки. Более того, он важен для успеха вашего проекта.
Человек может удерживать в кратковременной памяти не более девяти объектов одновременно. Приложение без четкого разделения ответственностей очень быстро переполняет кратковременную память разработчика из-за огромного количества комбинаций, в которых различные неразделенные понятия могут взаимодействовать друг с другом.
Разделение этих понятий на высоко связанные части позволяет вам «разделить и властвовать» над разрабатываемым вами приложением. Гораздо проще управлять сложностью небольшого, изолированного компонента, который слабо связан с остальными компонентами приложения.
Когда логика сохранения данных в БД проникает в доменную логику
Давайте рассмотрим примеры, в которых логика сохранения данных проникает в локику предметной области.
Пример 1: Работа с персистентным статусом объекта в классе доменной модели.
public void DoWork(Customer customer, MyContext context)
{
if (context.Entry(customer).State == EntityState.Modified)
{
// Do something
}
}
Текущее персистентное состояние объекта (т.е. существует ли он уже в БД или нет) не имеет никакого отношения к логике доменной модели. В идеале, доменные объекты должны оперировать только теми данными, которые напрямую относятся к бизнес-логике приложения.
Пример 2: Работа с идентификаторами
public void DoWork(Customer customer1, Customer customer2)
{
if (customer1.Id > 0)
{
// Do something
}
if (customer1.Id == customer2.Id)
{
// Do something
}
}
Работа с идентификаторами в классах предметной области — пожалуй, наиболее распространенный тип смешения разных видов ответственностей приложения. Идентификаторы — деталь имплементации того, как ваши объекты сохраняются в БД. Как правило они используются для сравнения объектов между собой. Если вы также используете их для этой цели, гораздо лучшим решением будет переопределить операторы сравнения (equality members) в базовом классе доменного объекта и писать ‘customer1 == customer2? вместо ‘customer1.Id == customer2.Id’.
Пример 3: Разделение свойств доменного класса по персистентному признаку
public class Customer
{
public int Number { get; set; }
public string Name { get; set; }
// Не сохраняется в БД, можем хранить здесь все что угодно
public string Message { get; set; }
}
Если вы имеете тенденцию писать такой код, то вам следует остановиться и обдумать доменную модель. Подобный подход может говорить о том, что вы включили в доменную модель элементы, которые не имеют к ней отношения.
Когда доменная логика проникает в базу данных
Пример 1: Каскадное удаление
Настройка БД для каскадного удаления — один из примеров проникновения логики предметной области в логику сохранения данных. В идеале, БД сама по себе не должна содержать информации о том, когда должно срабатывать удаление данных. Подобное знание — это забота домена. Ваш C#/Java/etc код должен быть единственным местом для хранения подобной логики.
Пример 2: Хранимые процедуры
Использование хранимых процедур, которые изменяют данные в БД — еще один пример. Не позволяйте доменной логике проникать в базу данных, храните код, изменяющий состояние данных, в вашей доменной модели.
Тут необходимо сделать два замечания. Во-первых, в большинстве случаев, нет ничего плохого в том, чтобы иметь хранимые процедуры, которые не изменяют данные в БД (read-only stored procedures). Помещение кода, приводящего к побочным эффектам (side effects), в доменную модель и кода без побочных эффектов в хранимые процедуры прекрасно соотносится с принципом CQRS.
Во-вторых, существуют случаи, когда избежать использования SQL не получится. К примеру, если вам необходимо удалить группу объектов по какому-то признаку, SQL оператор DELETE сделает эту работу намного быстрее. В таких случаях, использование SQL, изменяющего данные в БД, оправданно, но необходимо держать все подобные исключения под строгим контролем и не давать им разрастаться.
Пример 3: Значения по умолчанию
Значения по умолчанию в таблицах БД — другой пример доменной логики, проникнувшей в базу данных. Значения свойств, которые доменная сущность имеет по умолчанию, должны быть определены в коде, а не отданы на откуп БД.
Подумайте, насколько сложно собирать подобные знания по кусочкам из разных мест приложения. Намного проще хранить их в едином месте.
Заключение
Большинство подобных «протечек» возникает из-за того, что люди думают о своем приложении не в терминах предметной области, а в терминах данных. Многие разработчики рассматривают разрабатываемую ими систему именно так. Для них, классы — это всего лишь хранилище для данных, которые они переносят от БД к UI, а ORM — всего лишь утилита, помогающая не копировать вручную данные из результатов выполнения SQL запросов в эти объекты. Очень часто бывает сложно сделать сдвиг в парадигме мышления. Но после того как он сделан, люди как правило открывают целый мир выразительных доменных моделей, которые позволяют разрабатывать приложения намного быстрее, особенно на больших проектах.
Конечно, не всегда возможно достичь желаемого уровня разделения ответственностей в коде приложения. Но в большинстве случаев ничто не мешает сделать это. Большинство проектов проваливаются не из-за того, что они оказываются не способны выполнить какое-либо из технических требований. Большинство терпят неудачу из-за того, что оказываются погребены под массой беспорядочного кода, который мешает разработчикам менять что-либо в нем. Каждое изменение в подобном коде приводит к каскаду багов и неожиданных побочных эффектов по всему приложению.
SoC — принцип, который позволяет избежать подобного исхода.
Ссылка на оригинал статьи: Separation of Concerns in ORM
Комментарии (99)

FaNtAsY
20.07.2015 08:24+4Не могу согласиться с первым примером — каскадным удалением.
База данных — это не только набор таблиц, но и отношения между ними, внешние ключи. Таким образом БД гарантирует целостность данных.
Поэтому каскадное удаление также и зона ответственности БД.
Кроме того, СУБД выполнит эту операцию быстрее.

fogone
20.07.2015 09:05+6думаю, число проектов провалившихся из за плохого кода сравним с количеством проектов которые так и не стартовали из за попытки полностью отделить бизнес логику от логики работы с БД средствами орм. И уж совсем несравнимое количество тех, что загнулись из за плохого менеджмента.

FiresShadow
20.07.2015 09:49+1Настройка БД для каскадного удаления — один из примеров проникновения логики предметной области в логику сохранения данных.
Почему вы называете каскадное удаление логикой предметной области? То, удаляем ли мы каскадно данные или же продолжаем хранить потерявшие смысл подчиненные данные — это что, логика предметной области? Имхо, каскадное удаление — это оптимизация хранилища, с целью экономии места в хранилище, на основании предсказания о том, что после того, как нас перестанет интересовать автомобиль, нас точно никогда не заинтересует его дверная ручка, даже если её перевесят на интересующий нас автомобиль.
Вы хотите, чтобы у вас вся логика была в коде, в том числе каскадное удаление. При этом вы заявляете, что невозможно сделать так, чтобы в коде было указано, что удалять данные следует каскадно, но при этом каскадное удаление делалось бы средствами бд. А вот сколько времени вы потратили, пытаясь найти способ, как это сделать? Задавали ли вы вопросы на каких-нибудь форумах? Имхо, решение очевидно. Указали атрибутами предсказания, и потом эти атрибуты собираем и на их основании генерируем внешние ключи с каскадным удалением.
Какие вы видите альтернативы каскадному удалению на стороне бд? 1)Каждый раз делать каскадное удаление вручную? 2)Удалить внешние ключи? 3)Указать необходимость каскадного удаления на стороне ORM, если она поддерживает такую функциональность (если да, а в чём тогда принципиальное отличие — указать правило в маппинге ORM или в бд)? Имхо, нет ничего плохого в каскадном удалении на стороне бд, даже без генерации внешних ключей на основании атрибутов. Между прочим, вопрос о том, что следует помещать на уровень бд, уже рассматривался в комментариях к предыдущей статье автора. Автор видимо не читал. А зря…
vkhorikov Автор
20.07.2015 14:01+2В целом согласен, действительно настраивать каскад в БД или в самой ORM — разница не большая. Лично я обычно стараюсь делать так, чтобы база данных была настолько «тупой» насколько можно, поэтому если есть возможность, то все-таки выношу каскады из БД. Комментарии читал :)

konsoletyper
20.07.2015 14:10+2Кстати, есть один аргумент в пользу управления каскадами со стороны ORM. ORM может держать состояния всех сущности, с которыми она работает. Если ORM самостоятельно обрабатывает каскады, то он может правильно обновить состояния. Если же БД самостоятельно что-то удалит без ведома ORM, то для ORM потом будет полной неожиданностью, что пытаясь что-то сделать с сущностью, он не может найти её в БД.

vintage
20.07.2015 14:28Находясь в кластере нужно всегда быть к этому готовым.

lair
20.07.2015 14:33+2Да и без кластера — тоже. Это стандартный для любого кооперативного приложения сценарий.
konsoletyper
20.07.2015 15:57JPA к этому готовит следующим образом:
1. все entity имеют своё состояние в рамках текущей транзакции;
2. при выходе за границы транзакции entity переходят в состояние detached, а для них — свои правила.
Поэтому если у нас кластер, то все эффекты от соседей по кластеру будут наблюдаться в другой транзакции, которую мы в идеале не видим (а если вопрос пошёл об отключении изоляции и eventual consistency, то зачем вообще ORM?). В таком сценарии всё поломать можно только если между ORM-ными вещами фигачить мутирующий SQL. К кластеру это никакого отношения не имеет.
Aclz
20.07.2015 23:07Лично я обычно стараюсь делать так, чтобы база данных была настолько «тупой» насколько можно, поэтому если есть возможность, то все-таки выношу каскады из БД.
Сломать ссылочную целостность БД, реализованную на уровне БД, на порядок сложнее, чем сломать её, реализованную в ORM: в первом случае движок СУБД это делает за нас, во втором нам приходится следить за всем самим.

omikad
20.07.2015 12:55+1Есть гораздо более сложный пример смешения логики БД и кода — транзакции. Если вы попробуете полностью отделить код от БД, то получите что код работающий над mssql транзакционен, а на mongo — нет. Для одних БД вам удобно будет использовать паттерн Unit of Work, для других придется смириться с пониманием что каждая команда будет выполнена отдельно. Эти два слоя всегда влияют друг на друга, мы должны их разводить как можно дальше, но полностью развести — невозможно. Да и с другой стороны, очень удобно в коде вводить специфичные для БД вещи — использовать Unit of Work, отмечать в классах ORM свойства индексы, связи, ключи и т.п. Это удобный инструментарий, и отказываться от него ради академически верного абстрагирования не имеет смысла.

FractalizeR
20.07.2015 14:44+1Я думаю, транзакции вполне можно воспринимать, как часть логики приложения, а не часть БД. Если сложность проекта позволяет относиться к ним как к средству атомарного управления сущностями.

Flammar
20.07.2015 20:40Мне видится, что СУБД и ORM — это неисчерпаемый источник «еды» для желающих потроллить на тему принципа единственности обязанности и сепарации ответственностей. СУБД — потому, что СУБД развивались с упором на целостность данных и быстродействие, и к тому же производители стремились «впихнуть» в СУБД как можно больше смежных фишек типа обработки бизнес-логики (и кое-где даже отрисовывания веб-фронтенда в опциональных пакетах стандартной поставки), и никто не рассчитывал на то, что отлаженный монолит в будущем будет нужен по частям. ORM — потому, что изначально были адаптером объектно-ориентированной логики к СУБД с перемешанными ответственностями. Понятно, что часть логики, реализованной в СУБД, было бы логически правильнее перенести в ORM. Но между ORM и СУБД лежит «неблизкий путь» через сетевые соединения, и для быстродействия желательно уменьшить потребность в сетевом трафике. Вспомним распределённые транзакции: с переносом управления транзакциями на уровень ORM любые транзакции фактически стали бы распределёнными, по крайней мере по количеству участвующих в них сетевых узлов.
Так что, по-моему, надо осознавать, что 1) в СУБД и ORM принцип сепарации ответственностей традиционно нарушается 2) эти нарушения имеют под собой веские основания, в основном из области соображений быстродействия и лёгкости поддержания целостности данных. Хороший пример исключения из правила, о котором должен знать каждый, кто знает правило.

gandjustas
21.07.2015 00:54А при чем тут ORM?
Вопрос в том как сохранить целостность данных. Ведь в конечном счете не важно как реализована модель и на чем написан код. Важно какие данные вы сохраняете и что потом получают пользователи.
Например без контроля целостности на уровне базы сделать так, чтобы нельзя было продать два билета на одно место на концерт.
Только в самых примитивных случаях можно полностью изолировать логику от базы. В реальности появятся проекции и джоины, индексы, представления и хранимые процедуры.
Поэтому идеал не в том, чтобы изолировать логику от базы, а в том, чтобы логика в коде приложения и база данных работали согласовано, не было дублирования кода и тонн «водпроводного кода», который перекладывает данные туда-сюда.
ЗЫ. Современные ОРМы в этом помогают.
Mithgol
Чёткого отделения логики от базы не получится в том числе и потому, что примеров проникновения логики в базу (с целью ускорения работы логики) обыкновенно бывает больше, чем три приведённых выше примера. Как только число строк в таблице начинает измеряться тысячами и десятками тысяч, так сразу захочется прибавить к этим примерам ещё одну логику внутри базы, а именно индексы. А сможет ли ORM, вообще ничего не зная о той логике, которой подчинён поиск по базе, создать именно те индексы, которые ускорят такой поиск (и одновременно не насоздавать лишних индексов, которые не принесут пользы, а только замедлят пополнение и обновление базы)? Никоим образом не сможет. Это самообман.
ApeCoder
Мне кажется, что есть что-то в предметной области, что ORM может отмепить на индексы. Например, сделать какие-нибудь «хинты» типа «Типичный размер этой коллекции порядка десятков тысяч» и «нас интересуют быстрые выборки по вот этому сочетанию атрибутов». Теоретически ORM может при меппинге сгенерировать соответствующие индексы.
lair
Вам кажется. Типичный для предметной области запрос «нас интересуют быстрые выборки по любому сочетанию атрибутов». Если вы построите такой индекс, то система захлебнется при записи.
ApeCoder
Тогда невозможно построить индекс в принципе, не важно на каком уровне его декларировать — БД или приложения
lair
Возможно, просто решение об этом принимается исходя не только из знаний о предметной области, но и из постоянного наблюдения за БД и готовности чем-то жертвовать (и это не считая всяких денормализационных подходов). Только предметная область при этом не меняется.
ApeCoder
Совершенно согласен. Любая реализация объектной модели несет в себе следы ограничений ее интепретатора. Будь то JIT или SQL. Соответственно мы должны как-то сообщить интерпретатору что данном случае мы от него ожидаем. Например что запросы по определенным атрибутам нам представляются наиболее важными (а это уже требование из предметной области, как мне представляется)
lair
Это (в идеально-общем случае) нарушает принцип persistence ignorance.
ApeCoder
Я думаю, что этот принцип — недостижимый идеал, к которому, тем не менее, надо стремиться.
lair
Вот поэтому и не надо вносить в объектную модель хинты для персистентного хранилища.
ApeCoder
Это не хинт «создай индекс» это описание свойств «это сочетание атрибутов для меня важно в смысле поиска»
lair
Я уже говорил, что в домене для поиска могут быть важны все атрибуты (и более того, регулярно так и бывает). А уж для покрывающего индекса у вас тем более информации не хватит.
У вас же «поиск» происходит не только и не столько из интерфейса, есть еще сценарии изнутри самого когда, которые с одной стороны стабильны, а с другой — меняются при каждом рефакторинге, есть структура агрегатов, если у вас DDD, которая тоже влияет на порядок запросов, есть много других странных вещей, которые являются только и исключительно деталью реализации, к домену отношения не имеет, но на хранилище влияет.
ApeCoder
Вероятно надо несколько опуститься: нет никакой предметной области, есть объектная модель. Вопрос в том, может ли ORM получив некоторую дополнительную информацию об объектной модели в терминах этой модели создать индексы или мы обречены командовать ORM в терминах хранилища. А так же можно ли использовать ту же самую информацию в других местах: например при генерации UI опускать создание контролов для фильтрации если у нас мало элементов в коллекции и, наоборот, предлагать фильтрацию по умолчанию по важным признакам.
lair
Эээ, как это «нет никакой предметной области»? Вы вот так решили взять и похоронить Фаулера и Эванса? Нехорошо.
Вообще-то, это давно есть, и называется «метаданные». Только это информация не в терминах модели, потому что она всегда будет специфична для хранилища.
И получить непредсказуемое (пользователем) поведение UI? Я заодно хочу напомнить, что чем сложнее UI, тем вероятнее, что он отделен от доменной модели слоем презентационной модели.
ApeCoder
1. Я имею ввиду в рассматриваемой задаче нет. Есть объектная модель — не важно как получена, надо построить реляционную базу по ней.
2. Есть ли правила по которым проектировщик строит базу в зависимости от объектной модели и нельзя ли закодировать эти правила?
3. В каждом сложном UI есть простые куски.
lair
А откуда взялась такая задача? Вы выдернули кусок из контекста, но вы уверены, что ваш контекст изначально верен?
Те правила, которые можно закодировать, во некоторых ORM (например, в EF) уже закодированы.
Опыт показывает, что с вероятностью 0.9 это будут не те куски, про которые вы (или я) думаете.
ApeCoder
1) Я предлагаю рассмотреть такую задачу. Так как у нас ORM а не что-то еще.
2) Что там с построением индексов?
3) Мне опыт подсказывает другое, но возможно у нас с вами разный опыт.
lair
У ORM нет задачи построить реляционную базу по объектой модели, у него есть задача преобразовать реляционные данные в объекты и обратно. И да, на основании данных, которые есть у ORM, действительно можно много чего интересного настроить, только это не доменная модель, а модель хранилища (а это важное различие).
Индексы там по умолчанию тоже строятся — по первичному и внешним ключам.
ApeCoder
Мне бы хотелось максимально абстрагироваться от хранилища. Идеально строить объектную модель предметной области (хоть и с небольшой оглядкой на модель хранения) а затем чтобы ORM брало на себя весь меппинг, как структурный так и поведенческий.
lair
Эти два предложения друг другу противоречат.
Это святой Грааль, такой же недостижимый, как и прообраз. Вы не можете избавиться от impedance mismatch.
ApeCoder
1) Почему они противоречат?
2) Дык я ж говорил что идеал недостижим — хотелось бы к нему приблизиться максимально.
lair
Потому что абстрагирование движет вас в одну сторону, а оглядка на модель хранения — в другую.
Неплохо иногда задумываться, правда ли вам нужна чашка двухтысячелетней давности, или же подойдет термос.
ApeCoder
1) Я об этом и говорю — и так всегда было — стремимся к идеалу, но учитываем ограничения
2) Пока выбираю термос, но интересно, можно ли его сделать тонким и легким как чашка
lair
Так может просто идеал не тот?
Уже сделали, вот только теперь это не та чашка, в которую в соответствующем году собрали некую кровь.
ApeCoder
1) Это просто один из вариантов использования слова «идеал» — не достижимая цель, к которой можно только приблизиться. Виртуальная точка, задающая направление.
2) Да ну, мне кажется мы весьма далеки от идеальной ORM
lair
Вот я вам и говорю: может, у вас с направлением что-то не то?
ApeCoder
Может и не то, давайте обсудим. Почему именно не то? Желание работать на как можно более высоком уровне — неправильно?
lair
Когда вы уходите на более высокий уровень, вы теряете контроль за уровнями ниже. В этом смысл абстракции.
Вас это устраивает?
ApeCoder
Да. Но я хочу уходить не сразу везде, а, допустим на 95% в тех 5% где мне надо, я хочу спускаться и ниже. Хочу GC, и я хочу одновременно GC.Collect, я хочу абстрагироваться от машинного кода, но я хочу одновременно и смотреть результат JIT там, где узкое место.
Я хочу абстрагироваться там, где это достаточно хорошо для практичного использования, но я хочу управлять там, где пока это недостаточно хорошо и я хочу чтобы первая часть была как можно больше.
lair
В этот момент вы получаете текущую абстракцию — что само по себе плохой идеал.
ApeCoder
Дык понятно, что идеал это нетекучая абстракция. Но все реальные абстракции текут. И всегда будут течь хоть чуть-чуть.
ApeCoder
А раз она течет, я хочу чтобы подстановка тазиков на уровне ниже была рассмотрена заранее и была штатной процедурой. А так же иметь карту дырок.
lair
Так вы определитесь, ваш идеал — это нетекучая абстракция, в которой вы не имеете контроля за нижним уровнем, или абстракция, в которую вы в любой момент можете воткнуть отвертку?
ApeCoder
Оба два. В условиях реальных ограничений, в каждый конкретный момент времени оно должно позволять втыкать отвертку там где абстракции текут. Но при при устремлений времени к бесконечности в условиях стремления ограничений к нулю эта область куда можно воткнуть отвертку должна сужаться.
lair
Не может быть «оба два». Только что-то одно. Либо вы признаете, что идеальный ORM не дает вам контроля за персистентностью через объектную модель, которую он мапит, либо нет.
ApeCoder
Давайте соединим в одно. Он дает контроль за перзистентностью, но не требует его нигде.
lair
Если он дает контроль, значит, он не абстрактный, потому что для каждого хранилища элементы контроля свои.
ApeCoder
Не свои, а они могут быть свои.
lair
Они совершенно точно свои. Вы не можете построить единую систему контроля для оракла и ms sql, потому что у них даже типы данных отличаются.
ApeCoder
На C# нельзя писать одновременно под Linux и Windows потому, что можно вызывать windows dll
lair
Скажем так, вы не можете использовать всю функциональность .net на linux и windows одинаково. С идеальным ORM будет та же проблема.
ApeCoder
Да и меня это устраивает. Только там где мне важно быстродействие я буду доставать отвертку.
lair
И нарушать абстракцию. О чем и речь.
ApeCoder
Да, но в идеале я буду делать это в минимуме случаев — то есть в нуле
lair
До тех пор, пока у вас есть такая возможность, абстракция протекает.
Flammar
(1) Такая возможность по крайней мере у Hibernate была ещё по крайней мере в 2009. Уже по крайней мере тогда была возможность строить объектную модель как со стороны БД, так и со стороны Java-классов.
PsyHaSTe
Насколько я могу судить, человек просто говорит о линейной свертке по индексам. То есть у нас есть переменные-индексы и константы-статистики производительности запросов по этим индексам. Мы задаем целевую функцию как обычный скаляр. Используя эти данные и обычную динамическую оптимизацию мы можем перестраивать индексы под нужные требования, стремясь к оптимуму. Фактически то же делаем и мы, просто руками, а не математикой. Это как отладка против трассировки. Можно и последним заниматься, но зачем, когда есть такой удобный quick watch?..
lair
Вопрос в том, (а) что считать целевым значением и (б) как тестировать эффективность примененных изменений.
PsyHaSTe
Ну как обычно, этим занимается системный аналитик, достаточного уровня, чтобы понимать слова «свертка», «оптимум», «Паретто-оптимальность» и т.п. плюс набор экспертов для анкетирования. Эксперты берутся из предметной области, кому собственно софт пишем, а аналитик-математик должен быть в штате.
lair
Я это, сварщик ненастоящий, консерваториев не заканчивал, все умные слова знаю из википедии, так что можно мне на примерах?
Вот есть маленькая такая системка документооборота, с одним видом документов, документ приходит, регистрируется, назначается исполнителю, переназначается дальше, обрабатывается последним. Что мы возьмем за параметры для оптимизации и как мы будем расчитывать эффект от оптимизации, принесенный индексами в БД?
PsyHaSTe
Ну простейшим вариантом является нейросеть, то есть изначально мы индексы ставим у случайных полей и смотрим, быстро ли выполнился запрос. Если быстро, то вес соответствующих индексов увеличиваем, если нет — уменьшаем. Через несколько миллионов итераций (например, поставили на один день оптимизацию) у нас будет достаточно хорошее распределение индексов, которое можно будет использовать для построения индексов. Так как у нас все индексы и выходная величина — время выполнения — это числовые характеристики, то это можно без человека автоматически делать.
Это что касается вероятностных подходов. Для аналитики нужны спецы предметной области (бухгалтеры всякие, хз, уж Я-то точно не спец в документообороте) для определения, что у нас критично, а что нет, и аналитик, который это формализует в итоговую формулу: бд тут вообще не причем, О-нотация наше всё.
lair
Что значит «быстро ли выполнился запрос»? Какой запрос? В каких условиях?
Я вполне готов сыграть вам роль такого специалиста предметной области.
PsyHaSTe
Время выполнения в миллисекундах. Быстро или нет — вам решать. Можно шкалирование ввести, это задача уже определения нечетких множеств на лексические переменные. В конечном счете всё сводится к цифрам и автоматическому пересчету. Что касается условий, то они не важны, т.к. с увеличением количества экспериментов у нас сходится по вероятности весовой коэффициент индекса на конкретном поле конкретной таблицы.
lair
Самый важный вопрос — это какой запрос вы будете замерять. Ну и отдельно хочется заметить, что условия очень важны, потому что оптимизация ста записей и ста миллионов записей — это разные вещи, равно как и оптимизация под десять пользователей и под десять тысяч пользователей.
PsyHaSTe
Ну очевидно, что выборка должна быть репрезентативной. Запросы тоже сами выбираете, какие оптимизировать и в каком количестве.
Короче, весьма реально даже на текущем уровне вычислительной техники.
lair
Понимаете ли, в чем проблема… самое сложное — это выбрать, какие запросы оптимизировать (т.е., какие, собственно, показатели мы измеряем), и как их балансировать друг между другом (особенно в конкурентных сценариях), т.е. чем ради чего мы готовы жертвовать (например, запаздыванием актуальности (stale data) против времени ответа (latency)). После того, как это выбрано, человек сделает быстрее, чем нейронная сеть, просто потому, что стоимость эксперимента все-таки высока.
FractalizeR
Разве индексы БД являются частью предметной области / логики приложения?
Mithgol
Во всяком случае, без знания логики приложения трудно создавать нужные индексы (которые ускоряют исполнение важных запросов) и воздерживаться от создания ненужных индексов (которые не ускоряют исполнение никаких достаточно важных запросов, а только замедляют собою пополнение и обновлениебазы) — следовательно, трудно возложить создание индексов на ORM, если мы понимаем ORM как прокладку между базою и приложением, ничего не знающую о логике приложения.
Если ORM — это нечто существенно более сложное, чем простая прокладка… например, если ORM собирает статистику о частоте поступления запросов к базе из приложения и о времени исполнения запросов базою, а затем использует эту статистику для самостоятельного принятия решений о создании индексов в базе… тогда другое дело. Но и тогда знание логики приложения подменяется внешним анализом поведения, эмпирически-концептуальным по своей сути. Мне это не представляется изящным.
FractalizeR
Вы не могли бы привести пример хотя бы одного ORM на любом языке, который автоматически управляет индексами? Я пока не представляю себе, как это возможно реализовать.
Mithgol
Я также не представляю; я рассуждал теоретически.
serbod
1С-Предприятие. Оно не только индексы, но и хранимые процедуры создает для некоторых операций. Включается галочкой «отбор и сортировка» для каждого поля.
Aclz
Разве что индексы оно создаёт не автоматически, как рассуждалось выше, а путём параметрической настройки, производимой пользователем.
serbod
Галочка — это очевидный пользователю способ включения индекса для ускорения отбора и сортировки по конкретному полю. А есть еще неявно создаваемые индексы и процедуры, которые зависят от совокупности настроек. Например, в настройках свойств регистров нет ничего про индексы и процедуры, они создаются автоматически, в зависимости от состава измерений, взаимосвязей, периодичности, итд…
Aclz
Речь немного не об этом. Этот алгоритм создания дефолтных индексов для каждого типа метаданных детерминирован, прост как три рубля, жестко зафиксирован и не всегда оптимален. Он никак не учитывает характер данных и будущие потребности по их выборке.
serbod
Но он есть, он работает и он эффективен в 99.9% случаев. А в оставшихся 0.1% случаев не всякий DBA сделает лучше, ибо проблема скорее всего на уровне дизайна метаданных.
konsoletyper
Вот не согласен. Видел я, какие порнографические запросы этот ваш 1С генерит. Да что там генерит, разбирал я, например, такие вещи в ЗУП, как генерация табеля. 1200 строк запроса с несколькими временными таблицами и 4-мя уровнями вложенности подзапросов. Разобраться в этом нереально. Разобраться в развесистом плане запроса — тем более. Вручную написанный код, с вручную созданными индексами и схемой БД, и несколькими запросами, разнесёнными в методы, и денормализацией где надо, справляется с этой задачей за 2 секунды.
В общем, 1С — это рельсы. Пока надо ехать прямо, справляется отлично. Как только надо чуть-чуть сменить направление — всё рушится. Отличная штука для решения узкого круга задач хозяйственного учёта, но как general purpose — увольте.
FractalizeR
Он есть, но он на 100% зависит от действий пользователя, а не от типа и формата ваших данных. Какова разница между выполнением CREATE INDEX в Postgres и установкой галочки в 1С?
konsoletyper
А по совокупности полей?
А на реквизиты индексов? Проблема в том, что и тут пользователь должен явно сказать, что является измерением, а что — реквизитом. Т.е. неявно описать индекс. А что если в некоторых запросах такой индекс оказывается недостаточно селективным?
Так ведь автоматическое создание индексов для всех foreign key — это совсем тривиальная задача, некоторые СУБД даже настройку такую имеют. Или некоторые ORM, такие как Hibernate. Проблема в том, что в подавляющем числе случаев такие индексы просто не нужны, поэтому я никогда не включаю создание схемы в Hibernate и пишу DDL руками.
Вот что я видел реально крутое на эту тему, так это в MSSQL профайлер, который может по логу запросов предлагать строить индексы. Очень хорошо предлагает, надо сказать. Опять же, прошу обратить внимание на уровень, на котором работает данная штуковина, т.е. уровень хранения данных, а не ORM.
Кстати, то, что в 1С, я бы даже ORM не назвал. Формально это реализация паттерна Active Record, см. Фаулера.
konsoletyper
Задача ORM — не освободить разрабочика от любой работы с хранилищем данных (в частности, СУБД), а разделить логику хранения и бизнес-логику. Я обычно пишу просто entity в виде POJO, пишу для них юнит-тесты, которые вообще ничего не знают о БД. Когда логика написана и протестирована, можно создавать хранилище для неё. При этом используется несколько различных инструментов: для миграций (куда, в частности, включается создание индексов в случае реляционных СУБД), для маппинга на объекты и т.д. В случае корректного написания маппинга и миграционных скриптов такая модель будет себя прекрасно чувствовать в БД, и все бизнес-операции будут так же работать на persistent entities. ORM не может быть слишком умной, ибо тогда она будет нарушать принцип SRP, да и потому, что пока машины не научились писать код и самостоятельно принимать решения по части архитектуры.
Кстати, если в проекте используется ORM, это вовсе не значит, что ORM должен быть единственным способом для доступа к БД. ORM хороши, когда у нас для обработки внешних воздействий (согласование заказа, приёмка поступления) используется какая-то сложная логика, которую хорошо выражать в терминах сущностей, меняющих своё состояние. Наоборот, отчёты ничего не модифицируют, зато для них нужны сложные критерии выборки и хардкорно оптимизированные запросы, поэтому для них я использую raw SQL.
lair
Здравствуй, CQRS.
FractalizeR
Вы не могли бы пояснить? При использовании CQRS мы имеем две различные модели данных. Одна для чтения, другая для записи. Это вовсе не то же самое, что просто иметь персистентные сущности + SQL код для построения отчетов.
lair
При использовании CQRS мы имеем два потока данных — один на запись, другой на чтение. Когда у вас какая-то часть системы, отделенная по принципу «здесь мы только читаем», идет по альтернативному потоку — вы уже используете CQRS.
ApeCoder
А как в рамках CQRS обеспечивается непротиворечивость представления двух потоков о хранимых данных? И недублирование кода?
lair
А откуда возьмется противоречие? Один поток соответствует бизнес-требованиям на запись, другой поток соответствует бизнес-требованиям на чтение. Если они реализованы верно, то единственный источник противоречия — бизнес-треования.
Если вкратце, то никак. Эта проблема особо никого не волнует — если в чтении/записи единая структура, то (а) можно использовать одни и те же сущности и (б) не факт, что CQRS вообще нужен. Если же структура разная, то откуда дублирование?
ApeCoder
1) Если например есть общие сущности какие-нибудь. Например что у сотрудника есть такие то поля + соблюдается соотношение, что возраст на дату X = X — Дата рождения
2) А они всегда структурно 100% различные например при записи у нас есть Имя подразделения, в при чтении Цвет мячика?
lair
А зачем вам это соотношение в потоке записи? Оно, скорее всего, нужно только при чтении.
Именно структурно — очень часто. Например, при записи у вас есть идентификатор подразделения, в котором работает сотрудник, а при чтении — его наименование (или наименование + идентификатор).
ApeCoder
1) Я наверное, как-то неправильно понимаю CQRS — вот, допустим, у нас есть приложение которое показывает формочку для ввода даты рождения и показывает возраст в процессе ввода. Отдельно у нас есть некая штука которая показывает статистику по работникам в разрезе возраста. Я так понимаю что в рамках CQRS эти две штуки должны быть разделены, но в то же время хочется контроля целостности концепций между потоками.
2) А при записи наименование подразделения есть?
lair
Да тут, по большому счету, и без CQRS интересно. «статистика по работникам в разрезе возраста», скорее всего, должна считаться на SQL-сервере (потому что иначе это будет очень медленно). Вы, естественно, не можете использовать тот же механизм при вводе (мы не рассматриваем вариант «сделать sql-функцию и дергать ее с формы для расчета), поэтому так или иначе вам придется либо отказаться от показа возраста в процессе ввода (а точно надо?), либо сдублировать код. Если вы очень изобретательны, вы можете объявить расчет возраста бизнес-правилом и написать для него трансляторы в UI-код и SQL-код. Добавление CQRS в этом конкретном случае ни на что не влияет.
Нет, зачем? Представьте себе типовой интерфейс — подразделение выбирается из списка, название показывает контрол, но в модели оно отсутствует.
FractalizeR
Фаулер описывает CQRS иначе.
Термин «поток данных» в рамках объектно-ориентированного проектирования вообще представляется мне туманным. Может быть, я вас неправильно понял?
lair
When in doubt, go to the source.
Но если серьезно, то Фаулер пишет в настолько общих словах, что они применимы к чему угодно. Обратите внимание на «most commonly» во фразе «By separate models we most commonly mean different object models» — это означает, что отличие может быть не только в объектных моделях. Янг в статье по ссылке выше показывает, что отличие может быть в сервисных интерфейсах, я от себя добавлю, что можно иметь
UpdateCommand<Customer>()иGetObjectQuery<Customer>, и это все еще ничему не будет противоречить.Да, в большом и красивом CQRS у вас две явно различные модели, блаблабла. Но всегда ли у вас настолько большое приложение?
Представьте себе «типовое сложное» веб-приложение. Пользователь ввел данные на форме — они преобразовались в какую-то модель (input model) — обработаны контроллером/прикладным сервисом — преобразованы в доменную модель — обработаны агрегатом/доменным сервисом — преобразованы в модель хранения — засунуты в БД. Вот он, ваш поток данных на запись. Все то же самое, но в обратную сторону (и с view model в конце) — поток данных на чтение.
FractalizeR
Я не думаю, что стоит называть CQRS любую архитектуру, в которой есть чтение и запись данных в разных объектах. Фундаментальное отличие CQRS в том, что для чтения и для записи используются различные модели вплоть до уровня базы данных (разные таблицы).
Если у вас есть таблица БД Users, модель данных Users и два репозитария ReadUsers и WriteUsers (тупой пример, согласен, но для иллюстрации, думаю, пойдет), то это не CQRS несмотря на то, что чтение и запись данных производятся разными объектами потому, что нет серьезного разделения между чтением и записью данных. Разнесение методов чтения и записи в разные классы на архитектуру в данном случае существенно не влияет.
А вот если в архитектуре есть денормализованная таблица UserData, содержащая все денормализованные данные пользователей (Query table), и серия таблиц, содержащих все данные, требуемые для построения этой таблицы на любой момент времени (Command Tables) — такого рода архитектуру (вместе с объектами, которые ее поддерживают, конечно) я бы назвал CQRS.
Насколько я понимаю, Янг говорит о том же:
lair
Ну написано же:
И я прекрасно понимаю, почему Янг так пишет — потому если ваша система потребляет это API, то сегодня оно может быть построено вокруг единого хранилища, завтра — вокруг системы с раздельной оптимизацией, и вы этого никак не заметите. А если вы еще и изначально заложитесь на асинхронность внесения изменений (т.е., что возврат управления из метода записи не означает, что вы уже видите эти данные в методе чтения), то вы можете делать дальше что угодно, включая очереди, шины сообщений и любые красивые слова.
Во-первых, нет такой вещи, как Command table, команды — они в прикладном слое, в хранилище команд нет. А во-вторых, то, что вы описываете, называется Event Sourcing, и тоже не является обязательным пререквизитом для CQRS (хотя и часто используется вместе с ним).
FractalizeR
Да, похоже, что вы правы. Спасибо!
Flammar
Вспоминаю в Java 1.6 новые быстрые методы межпоточного взаимодействия из серии compare-and-set и compare-and-swap…
yul
Если уж подходить в автоматизации индексов, то я бы делал это с другой стороны — собирал статистику использования и на основании этих данных создавал бы индексы. И не надо пихать это в приложение.
Но есть и другие моменты, N+1 запрос, сложные поисковые условия и т.п., которые уже не разрулишь, не влезая в код.