
В рамках недавно прошедшей конференции DotNext 2018 состоялся BoF по Domain Driven Design. На нем был затронут вопрос работы с исключениями, который вызвал жаркий спор, но не получил развернутой дискуссии, поскольку не являлся основной темой.
Также, изучая множество ресурсов, начиная от вопросов на stackoverflow и заканчивая платными курсами по архитектуре, можно наблюдать, что в IT-сообществе сложилось неоднозначное отношение к исключениям и к тому, как их использовать.
Наиболее часто упоминается, что с использованием исключений легко построить поток исполнения, имеющий семантику оператора goto, что плохо сказывается на читабельности кода.
Есть разные мнения о том, стоит ли создавать собственные типы исключений или использовать стандартные, поставляемые в .NET.
Кто-то делает валидацию на исключениях, а кто-то повсеместно использует монаду Result. Справедливо, что Result позволяет по сигнатуре метода понять, возможно ли не только успешное выполнение. Но не менее справедливо, что в императивных языках (к которым относится C#) повсеместное использование Result приводит к плохо читаемому коду, засыпанному конструкциями языка настолько, что с трудом можно разглядеть исходный сценарий.
В данной статье я расскажу о практиках, принятых в нашей команде (если кратко — мы используем все подходы и ни один из них не является догмой).
Речь пойдет об enterprise-приложении, построенном на базе ASP.NET MVC+WebAPI. Приложение построено по луковой архитектуре, общается с базой данных и брокером сообщений. Используется структурированное логирование в ELK-стек и настроен мониторинг при помощи Grafana.
На работу с исключениями мы посмотрим с трех ракурсов:
- Общие правила работы с исключениями
- Исключения, ошибки и луковая архитектура
- Частные случаи для Web-приложений
Общие правила работы с исключениями
- Исключения и ошибки — не одно и то же. Для исключений используем exceptions, для ошибок — Result.
- Исключения только для исключительных ситуаций, которых по определению не может быть много. Значит и исключений чем меньше — тем лучше.
- Обработка исключений должна быть максимально гранулированной. Как писал еще Рихтер в своем монументальном труде.
- Если ошибка должна быть доставлена пользователю в исходном виде — используем Result.
- Исключение не должно покидать границы системы в исходном виде. Это не user friendly и дает злоумышленнику способ дополнительно изучить возможные слабые места системы.
- Если брошенное исключение обрабатывается нашим же приложением — используем не exception, а Result. Реализация на исключениях будет скрытым оператором goto и будет тем хуже, чем дальше код обработки от кода выброса исключения. Result же явно декларирует возможность ошибки и допускает только “линейную” ее обработку.
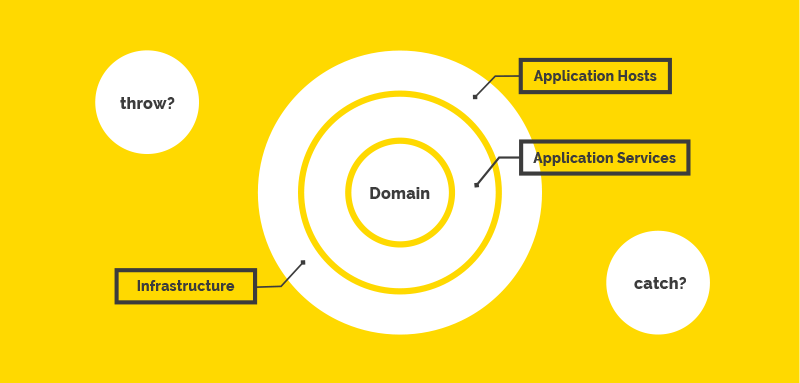
Исключения, ошибки и луковая архитектура
В последующих разделах рассмотрим ответственности и правила выброса/обработки исключений/ошибок для следующих слоев:
- Application Hosts
- Infrastructure
- Application Services
- Domain core
Application Host
За что отвечает
- Composition root, настраивающий работу всего приложения.
- Граница взаимодействия с внешним миром — пользователи, другие сервиса, запуск по расписанию.
Поскольку это достаточно сложные ответственности, стоит ими и ограничиться. Остальные ответственности отдаем внутренним слоям.
Как обрабатывает ошибки из Result
Транслирует во внешний мир, преобразуя в соответствующий формат (например в http response).
Как генерирует Result
Никак. Данный слой не содержит логики, значит и ошибки генерировать негде.
Как обрабатывает исключения
- Скрывает детали и преобразует в формат, пригодный для отправки во внешний мир
- Логирует.
Как выбрасывает исключения
Никак, данный слой самый внешний и не содержит логики — ему некому отдать исключение.
Infrastructure
За что отвечает
- Адаптеры к портам, или попросту реализации Domain-интерфейсов, дающие доступ к инфраструктуре — сторонним сервисам, базам данных, active directory и пр. Данный слой должен быть по возможности “глупым” и содержать как можно меньше логики.
- При необходимости может выступать как Anti-corruption layer.
Как обрабатывает ошибки из Result
Мне неизвестны провайдеры к базам данных и прочим сервисам, работающие на монаде Result. Однако, некоторые сервисы работают на кодах возврата. В таком случае преобразуем их в формат Result, требуемый портом.
Как генерирует Result
В общем случае данный слой не содержит логики, значит, и ошибки не генерирует. Но в случае использования в качестве anti corruption layer возможны самые разные варианты. Например, разбор исключений от legacy-сервиса и преобразование в Result тех исключений, которые являются простыми сообщениями валидации.
Как обрабатывает исключения
В общем случае выбрасывает дальше, при необходимости залогировав детали. Если реализуемый порт допускает в контракте возврат Result, то инфраструктура преобразует в Result те типы исключений, которые могут быть обработаны.
Например, используемый в проекте брокер сообщений бросает исключения при попытке отправить сообщение, когда брокер недоступен. Слой Application Services готов к такой ситуации и в состоянии обработать ее политикой Retry, Circuit Breaker-ом или ручным откатом данных.
В таком случае слой Application Services декларирует контракт, возвращающий Result в случае ошибки. А слой Infrastructure реализует данный порт, преобразуя исключение от брокера в Result. Естественно, преобразует только конкретные типы исключений, а не все подряд.
Используя такой подход, мы получаем два преимущества:
- Явно декларируем возможность ошибки в контракте.
- Избавляемся от ситуации, когда Application Service знает, как обработать ошибку, но не знает тип исключения, поскольку абстрагирован от конкретного брокера сообщений. При этом строить блок catch на базовый System.Exception означает захватить все типы исключений, а не только те, с которыми может справиться Application Service.
Как выбрасывает исключения
Зависит от специфики системы.
Например, LINQ-операторы Single и First при запросе несуществующих данных выбрасывают исключение InvalidOperationException. Но этот тип исключения используется в .NET повсеместно, что лишает возможности выполнять его обработку гранулированно.
Мы в команде приняли практику создавать кастомный ItemNotFoundException и выбрасывать со слоя инфраструктуры его, если запрошенные данные не найдены и так не должно быть по правилам бизнеса.
Если же запрошенные данные не найдены и это допустимо — это стоит явно декларировать в контракте порта. Например, с использованием монады Maybe.
Application Services
За что отвечает
- Валидация входных данных.
- Оркестрация и координация сервисов — старт и завершение транзакций, реализация распределенных сценариев и т.д.
- Загрузка domain-объектов и внешних данных через порты к Infrastructure, последующий вызов команд в Domain Core.
Как обрабатывает ошибки из Result
Ошибки от domain core транслирует во внешний мир без изменений. Ошибки от Infrastructure может обрабатывать посредством политик Retry, Circuit Breaker или транслировать наружу.
Как генерирует Result
Может реализовать валидацию в виде Result.
Может генерировать уведомления о частичном успехе выполнения операции. Например, сообщения пользователю вида “Ваш заказ успешно размещен, но при верификации адреса доставки возникла ошибка. В ближайшее время с вами свяжется специалист для уточнения деталей доставки.”
Как обрабатывает исключения
Предполагая, что исключения инфраструктуры, которые приложение в состоянии обработать, уже преобразованы слоем Infrastructure в Result — никак не обрабатывает.
Как выбрасывает исключения
В общем случае — никак. Но есть пограничные варианты, описанные в финальном разделе статьи.
Domain core
За что отвечает
Реализация бизнес-логики, “ядро” системы и основной смысл ее существования.
Как обрабатывает ошибки из Result
Поскольку слой внутренний и ошибки возможны только от объектов в том же домене, обработка сводится либо к бизнес-правилам, либо к трансляции ошибки наверх в исходном виде.
Как генерирует Result
При нарушении бизнес-правил, которые инкапсулированы в Domain Core и не покрываются валидацией входных данных на уровне Application Services. Вообще в данном слое Result используется наиболее часто.
Как обрабатывает исключения
Никак. Исключения из инфраструктуры уже обработаны слоем Infrastructure, данные уже пришли структурированные, полные и проверенные благодаря слою Application Services. Соответственно, все исключения, которые могут вылететь, будут действительно исключениями.
Как выбрасывает исключения
Обычно здесь работает общее правило: чем меньше исключений — тем лучше.
Но бывали ли у вас ситуации, когда вы пишете код и понимаете, что в определенных условиях он может натворить страшных делов? Например, дважды списать деньги или настолько испортить данные, что потом костей не соберем.
Как правило, речь идет о выполнении команд, недопустимых для текущего состояния объекта.
Конечно, соответствующая кнопка на UI не должна быть видна в данном состоянии. Мы не должны получить команду из шины в данном состоянии. Все это верно при условии, что внешние слои и системы выполнили свою функцию нормально. Но в Domain Core мы не должны знать о существовании внешних слоев и верить в корректность их работы, мы должны защищать инварианты системы.
Какие-то из проверок можно разместить в Application Services на уровне валидации. Но это может превратиться в defensive programming, который в крайних проявлениях приводит к следующему:
- Ослабляется инкапсуляция, поскольку определенные инварианты должны быть проверены на внешнем слое.
- В наружный слой “протекают” знания о предметной области, проверки могут дублироваться обоими слоями.
- Проверка допустимости выполнения команды из внешнего слоя может быть более сложной и менее надежной, чем проверка доменным объектом невозможности выполнить команду в текущем состоянии.
Также, если мы размещаем подобные проверки в слое валидации, то мы должны сообщить пользователю причину ошибки. Учитывая, что речь про операцию, которую вообще нельзя выполнить в текущих условиях, мы рискуем оказаться в одной из двух ситуаций ситуации:
- Мы выдали рядовому пользователю сообщение, которое он вообще не понял и все равно пойдет в саппорт, как и при сообщении «Произошла непредвиденная ошибка».
- Мы в достаточно внятной форме сообщили злодею, почему он не может выполнить операцию, которую он выполнить хочет и он может поискать другие обходные пути.
Но вернемся к основной теме статьи. По всем признакам, обсуждаемая ситуация является исключительной. Она никогда не должна произойти, но если произойдет, то будет плохо.
Наиболее логично в данной ситуации выбросить исключение, залогировать необходимые детали, вернуть пользователю ошибку общего вида “Операция невыполнима”, настроить мониторинг на данный тип ошибок и рассчитывать, что мы никогда их не увидим.
Какой тип или типы исключений использовать в данном случае? По логике, это должен быть отдельный тип исключения, чтобы мы смогли выделить его среди других и чтобы его случайно не зацепило обработками исключений из внешнего слоя. Иерархия или множество исключений нам тоже не нужны, суть одна — произошло нечто недопустимое. Мы в своих проектах создаем для этого тип CorruptedInvariantException, и используем его в соответствующих ситуациях.
Частные случаи для Web-приложений
Существенным отличием web-приложений от других (desktop, демоны и windows сервиса и т.д.) является взаимодействие с внешним миром в форме краткосрочных операций (обработки HTTP-запросов), по выполнении которых приложение тут же “забывает” о произошедшем.
Также после завершения обработки запроса всегда формируется ответ. Если выполняемая нашим кодом операция не возвращает данные, платформа все равно вернет response, содержащий status code. Если операция была прервана исключением, то платформа все равно вернет ответ, содержащий соответствующий status code.
Чтобы реализовать подобное поведение, обработка запросов в Web-платформах построена в виде конвейеров (pipe). Сначала выполняется последовательная обработка запроса (request), а затем подготовка ответа (response).
Мы можем использовать middleware, action filter, http handler или ISAPI filter (в зависимости от платформы) и встроиться в этот конвейер на любом этапе. И на любом этапе обработки запроса мы можем прервать обработку и конвейер перейдет к формированию ответа.
Бизнес-часть приложения мы, как правило, реализуем уже не в архитектуре конвейера, а пишем код, выполняющий операции последовательно. И при таком подходе несколько сложнее реализовать сценарий, когда мы обрываем исполнение запроса и сразу переходим к формированию ответа.
Какое все это имеет отношение к работе с исключениями, спросите вы?
Дело в том, что описанные в предыдущих частях статьи правила работы с исключениями плохо вписываются в данный сценарий.
Исключения использовать плохо, потому что это семантика goto.
Повсеместное использовании Result приводит к тому, что мы таскаем его (Result) по всем слоям приложения, а при формирования ответа нужно как-то Result разобрать, чтобы понять, какой вернуть status code. Еще этот код разбора желательно обобщить и затолкать в Middleware или ActionFilter, что становится отдельным приключением. То есть Result мало чем лучше исключений.
Что делать в такой ситуации?
Не возводить абсолют. Мы устанавливаем правила себе на благо, а не во вред.
Если требуется прервать операцию, потому что ее продолжение невозможно, то выброс исключения не будет иметь семантики goto. Мы направляем исполнение на выход, а не к другому блоку бизнес-кода.
Если причина прерывания важна, чтобы определить нужный status code, то можно использовать кастомные типы исключений.
Ранее мы упомянули два кастомных типа, которые используем: ItemNotFoundException (трансформируем в 404) и CorruptedInvariant (преобразуется в 500).
Если вы проверяете права пользователей, потому что они не ложатся на модель ролей или claim-ов, то допустимо создать кастомный ForbiddenException (Status code 403).
И, наконец, валидация. Мы все равно не можем ничего сделать, пока пользователь не модифицирует свой запрос, эта семантика описана кодом 422. Значит мы прерываем операцию и отправляем запрос прямиком на выход. Это также допустимо сделать, используя exception. Например, в библиотеке FluentValidation уже есть встроенный тип исключения, который передает на клиент все детали, необходимые, чтобы внятно отобразить пользователю, что не так с запросом.
На этом все. А как вы работаете с исключениями?
Комментарии (14)

kagetoki
03.12.2018 15:54Я абсолютно согласен с вами касательно семантики исключений,
gotoи читабельности.
Раз уж вы решили использовать монадыResult&Maybe, и вас при этом беспокоит невысокая читаемость конструкций работы с ними, в силу особенностей языка C#, у меня возникает вопрос: рассматривали вы для себя возможность перехода на F#, и если да, то почему воздержались?
Работать с монадами там гораздо проще, как и определить конструкцию
Result(которая уже есть в стандартной библиотеке начиная с версии 4.1):
type Result<'Ok, 'Error> = | Ok of 'Ok | Error of 'Error
и благодаря Computation Expressions "зараженность" резалтами больше не выглядит страшно:
let createUser userDto = result { let! validatedDto = validate userDto //в случае Error возвращается ошибка, в случае Ok исполняется дальше let! userId = create validatedDto return userId }
то же самое с
Maybe.
Помимо этого, система типов более описательная, и она позволяет сделать некорректные состояния невыразимыми — может быть, это решит вашу проблему "исключительных" исключений для ситуаций, когда остальные сервисы с валидацией не справились.
На эту тему есть отличная книга Скотта Влашина
fshchudlo Автор
03.12.2018 16:17+1Вопрос не в бровь, а в глаз.
Для F#, скажем так, зреем и для этого есть куда более весомый довод — упомянутый в статье проект это лишь front-часть, высунутая наружу. А дальше куча микросервисов, представляющих из себя машины состояний на Mass Transit.
И на императивном языке описывать машины состояний то еще удовольствие. Отлично ощущаешь почему в мире C# и Java так прижился XML :)
В обозримом будущем (2-3 месяца) планируем аккуратно попробовать F# и начать как раз с машин состояний. Если заведется — тоже будет статья на Хабр.vkhorikov
03.12.2018 19:52+2State machine-ы делать на F# — одно удовольствие. Рекомендую этот курс Марка Симана если еще не смотрели: app.pluralsight.com/library/courses/fsharp-type-driven-development/table-of-contents
vkhorikov
03.12.2018 20:39+2Хорошая статья. Пара комментариев/дополнений с моей стороны:
1. Очень хороший поинт насчет того, что с конвейерами подход с резалтами не работает — слишком много нагромождений (at least in C#), и это явно не то как авторы asp.net видели для себя обработку ошибок из middleware. Поэтому сценарий с декораторами — исключение из общего правила. При этом единственное, я не встречал других сценариев где такая работа с exceptions была бы оправдана.
2. По поводу типов исключений. Я не думаю что стоит создавать более 1 кастомного исключения (если только это не special case scenario as in #1 above). В статье говорится о преоразовании ItemNotFoundException в 404. Это как раз классический случай, где надо преобразовывать отсутствие объекта (Single/First) в return value и работать дальше уже с ним.
К примеру, может быть use case когда запись по данному Id обязана находиться в базе и если ее нет — это является исключительной ситуацией. В других кейсах это может не быть исключительной ситуацией. И если всегда бросать ItemNotFound, то нельзя будет отличить исключительную ситуацию (500) от не-исключительной (404). Здесь немного более подробно на эту тему: enterprisecraftsmanship.com/2017/01/31/rest-api-response-codes-400-vs-500
Рекомендую всегда возвращать Maybe из репозиториев/гейтвеев и потом уже решать кидать исключение или возвращать 404.
3.Но не менее справедливо, что в императивных языках (к которым относится C#) повсеместное использование Result приводит к плохо читаемому коду, засыпанному конструкциями языка настолько, что с трудом можно разглядеть исходный сценарий.
Код получается более verbose, да, но он при этом становится наоборот, более читаемым благодаря явной логике ветвений. Опять же, по аналогии с goto: можно переписать метод с кучей if-ов на использование goto и тогда код будет плоский, без indentations. Только читать его станет намного сложнее.
4. И еще один отличный поинт про Application Service, валидацию, и инкапсуляцию в доменный слой. Я обычно делегирую все (возможнные) проверки слою домена через паттерн Do/CanDo. Получается примерно так:
class DomainClass { public Result CanTransfer() { return Result.Ok(); } public void Transfer() { Guard.Require(CanTransfer().IsSuccess); // кидает исключение в случае false /* ... */ } }fshchudlo Автор
04.12.2018 06:30Спасибо за развернутый ответ.
Это как раз классический случай, где надо преобразовывать отсутствие объекта (Single/First) в return value и работать дальше уже с ним.
Полагаю, данный сценарий можно однозначно разделить на два, и ваша статья про response codes помогла мне это понять, за что дополнительное спасибо.
Предполагая, что мы остаемся в контексте DDD и Web:
1. Требуется загрузить aggregate root по идентификатору, пришедшему в web-запросе. Если aggregate root не найден, то бизнес-логика вряд ли сможет делать какие-либо предположения кроме того, что пользователь прислал неверный идентификатор, что превращается в код 404. Если мы используем специфичный репозиторий, а не формируем запросы через IQueryable прямо из бизнес-логики, то данный сценарий можно обработать единожды на уровне Data Access вместо повторяющейся обработки во всех местах вызова из бизнес-логики.
2. После загрузки aggregate root «Заказ» мы обнаруживаем, что он находится в статусе «Оплачен», но данные об оплате при этом отсутствуют. Для работы с такими случаями идеально подходит Maybe и проверки результата уже на уровне бизнес-логики и дальнейшую трансформацию в код 500, если проверка не пройдена.
Код получается более verbose, да, но он при этом становится наоборот, более читаемым благодаря явной логике ветвений.
Абсолютно согласен, что логика становится более явной и Result является верным выбором при написании Domain-логики. Но verbosity может перевесить когда мы работаем над «глупыми» слоями, например при построении Anti Corruption Layer.
Данную ситуацию трудно пояснить на каком-то специфичном сценарии, поэтому приведу пример общеизвестный, но несколько утрированный — Entity Framework.
В определенных условиях DbContext выбрасывает исключение ObjectDisposedException. И выброс исключения это оптимальный вариант в данном случае.
Было бы хорошо, если бы методы First и Single возвращали Maybe вместо выброса InvalidOperationException.
Было бы хорошо, если бы SaveChanges возвращал Result вместо выброса EntityValidationException.
Но было бы плохо, если бы Result возвращался вместо выброса ObjectDisposedException, поскольку это бы засорило все контракты IQueryable и даже не могу представить, как бы в таком случае выглядел Lazy Loading. Такая загрузка контракта не стоит того, чтобы обрабатывать ошибку, которая при правильном использовании вообще никогда не произойдет.
Повторюсь, пример утрированный. Но попытки выстроить Anti Corruption Layer вокруг legacy систем могут ставить в ситуации, которые и в кошмарном сне не приснятся.
Я обычно делегирую все (возможнные) проверки слою домена через паттерн Do/CanDo.
Так просто и элегантно, но почему-то никогда не приходило в голову. Спасибо за совет :)
yurybykov
05.12.2018 11:59Правильно ли я понял, вы делаете валидацию в нескольких местах (при получении запроса и при работе сервиса)? То, что может проверить доменный слой проверяет он, всё остальное на уровне Application.
vkhorikov
05.12.2018 12:50Валидация в одном месте — application services layer. Но она либо делегируется доменным объектам (через вызов их CanDo методов), либо нет (к примеру проверка имейла юзера на уникальность идет напрямую к базе или к репозиторию).
qw1
Что делать, если Domain Core используется и в веб-приложении, и в прочих?
Согласно первой части статьи, для ошибок бизнес-логики («нет средств для списания, например») нужно использовать Result, но если код подключается в web-сервер, то лучше бы он бросал исключения?
fshchudlo Автор
В случае бизнес-ошибок web-серверу тоже лучше работать с Result.
CorruptedInvariant и код 500, описанные в статье, это кейс для ситуаций, которые мы надеемся не увидеть вообще никогда. То есть как раз таки исключительные ситуации.
Для ошибки «нет средств для списания» больше походит Result, который в Web будет превращен в код 400 или 409, в зависимости от того, какой выглядит осмысленнее для клиента приложения.
Вообще, если мы принимаем правила статьи и 403, 404, 422 и 500 обрабатываем исключениями, то мы можем быть уверены на стороне Web, что Result это сугубо бизнесовая ошибка (и к этому и стоит стремиться, на мой взгляд) и его можно преобразовывать в 200 на случай Success и в 400 или 409 на случай Failure.