
В начале декабря в Монреале прошла 32-ая ежегодная конференция Neural Information Processing Systems, посвященная машинному обучению. По неофициальному табелю о рангах эта конференция является топ-1 событием подобного формата в мире. Все билеты на конференцию в этом году были раскуплены за рекордные 13 минут. У нас большая команда data scientist’ов МТС, но лишь одному из них – Марине Ярославцевой (magoli) – посчастливилось попасть в Монреаль. Вместе с Данилой Савенковым (danila_savenkov), который остался без визы и следил за конференцией из Москвы, мы расскажем о работах, показавшихся нам наиболее интересными. Эта выборка очень субъективна, но, надеемся, она заинтересует вас.

Relational recurrent neural networks
Abstract
Код
При работе с последовательностями часто бывает очень важно, как связаны друг с другом элементы последовательности. Стандартные архитектуры рекуррентных сетей (GRU, LSTM) с трудом могут моделировать взаимосвязь между двумя достаточно удаленными друг от друга элементами. В какой-то степени с этим помогает справиться attention (https://youtu.be/SysgYptB198, https://youtu.be/quoGRI-1l0A), но все-таки это не совсем то. Attention позволяет определить вес, с которым hidden state с каждого из шагов последовательности будет влиять на итоговый hidden state и, соответственно, на предсказание. Нас же интересует взаимосвязь элементов последовательности.
В прошлом году, опять же на NIPS’е, google предложил вообще отказаться от рекурренстности и использовать self-attention. Подход показал себя очень хорошо, правда в основном на seq2seq задачах (в статье приводятся результаты по машинному переводу).
Авторы статьи этого года используют идею self-attention в рамках LSTM. Изменений не так много:
Утверждается, что именно за счет MHDPA сетка может учитывать взаимосвязь элементов последовательности даже когда они удалены друг от друга.
В качестве игрушечной задачи модель просят в последовательности векторов найти N-ый вектор по удаленности от M-ого в терминах евклидова расстояния. Например, есть последовательность 10 векторов и мы просим найти тот, который на третьем месте по близости к пятому. Понятно, что для ответа на этот вопрос модели необходимо как-то оценить расстояния от всех векторов до пятого и отсортировать их. Здесь модель, предложенная авторами, уверенно побеждает LSTM и DNC. Помимо этого, авторы сравнивают свою модель с другими архитектурами на Learning to Execute (на вход получаем несколько строк кода, выдаем результат), Mini-Pacman, Language Modeling и везде рапортуют о лучших результатах.
Multivariate Time Series Imputation with Generative Adversarial Networks
Abstract
Код (хотя в статье они сюда не ссылаются)
В многомерных временных рядах, как правило, содержится большое количество пропусков, что мешает применению продвинутых статистических методов. Стандартные решения – заполнение средним/нулем, удаление неполных случаев, восстановление данных на основании матричных разложений в этой ситуации, зачастую не работают, поскольку не могут воспроизвести временные зависимости и сложное распределение многомерных временных рядов.
Широко известна способность генеративно-состязательных сетей (GAN’ов) имитировать любое распределение данных, в частности, в задачах «дорисовывания» лиц и генерации предложений. Но, как правило, такие модели или требуют изначального обучения на полном датасете без пропусков, либо не учитывают последовательный характер данных.
Авторы предлагают дополнить GAN новым элементом – Gated Recurrent Unit for Imputation (GRUI). Основное отличие от обычного GRU в том, что GRUI может обучаться на данных с интервалами разной длины между наблюдениями и корректировать влияние наблюдений в зависимости от их удаленности во времени от текущей точки. Рассчитывается специальный параметр затухания ?, значение которого варьируется от 0 до 1 и тем меньше, чем больше временной лаг между текущим наблюдением и предыдущим непустым.


И дискриминатор, и генератор GAN состоят из слоя GRUI и полносвязного слоя. Как обычно в GAN’ах, генератор учится имитировать исходные данные (в данном случае просто заполнять пропуски в рядах), а дискриминатор учится отличать ряды, заполненные генератором, от настоящих.
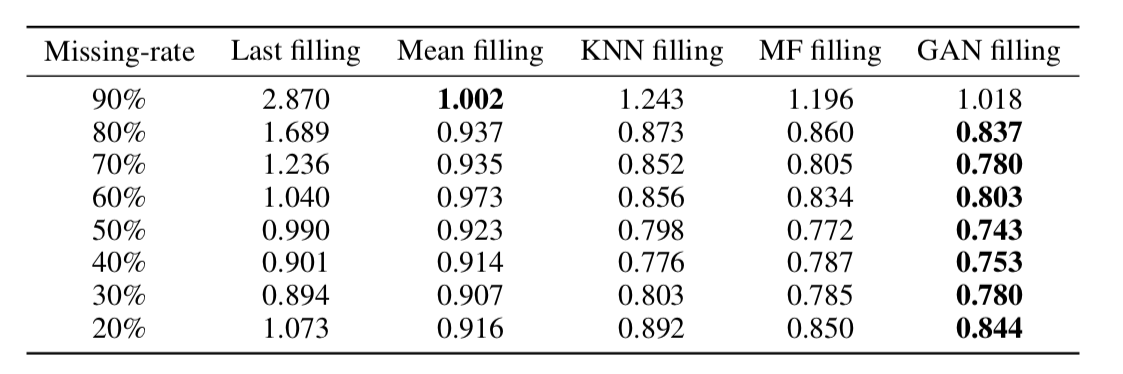
Как выяснилось, такой подход очень адекватно восстанавливает данные даже во временных рядах с очень большой долей пропусков (в таблице ниже – MSE восстановления данных в датасете KDD в зависимости от доли пропусков и метода восстановления. В большинстве случаев метод, основанный на GAN, дает наибольшую точность восстановления).
On the Dimensionality of Word Embeddings
Abstract
Код
Word embedding / векторное представление слов – подход, широко используемый для различных приложений NLP: от рекомендательных систем до анализа эмоциональной окраски текстов и машинного перевода.
При этом вопрос о том, как оптимально задать такой важный гиперпараметр, как размерность векторов, остается открытым. На практике чаще всего он подбирается эмпирическим перебором или задается по умолчанию, например, на уровне 300. При этом слишком маленькая размерность не позволяет отразить все значимые взаимосвязи между словами, а слишком большая может привести к переобучению.
Авторы исследования предлагают свое решение этой проблемы с помощью минимизации параметра PIP loss – новой меры различия между двумя вариантами эмбеддингов.
В основе расчета лежат PIP-матрицы, которые содержат в себе скалярные произведения всех пар векторных представлений слов в корпусе. PIP loss рассчитывается как норма Фробениуса между PIP-матрицами двух эмбеддингов: обученного на данных (trained embedding E_hat) и идеального, обученного на незашумленных данных (oracle embedding E).
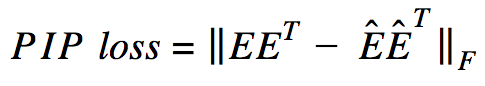
Казалось бы все просто: нужно выбрать размерность, которая минимизирует PIP loss, единственный непонятный момент — откуда взять oracle embedding. В 2015-2017 годах был опубликован ряд работ, в которых показано, что различные методы построения эмбеддингов (word2vec, GloVe, LSA) неявно факторизуют (понижают размерность) signal matrix корпуса. В случае word2vec (skip-gram) signal matrix — это PMI, в случае GloVe — матрица log-counts. Предлагается взять словарь не очень большого размера, построить signal matrix и использовать SVD для получения oracle embedding. Таким образом, размерность oracle embedding получается равной рангу signal matrix (на практике для словаря в 10k слов размерность будет порядка 2k). Однако наша эмпирическая signal matrix всегда зашумлена и приходится прибегать к хитрым схемам чтобы получить oracle embedding и оценить PIP loss по зашумленной матрице.
Авторы утверждают, что для выбора оптимальной размерности эмбеддинга достаточно использовать словарь из 10k слов, что не очень много и позволяет прогнать эту процедуру за разумное время.
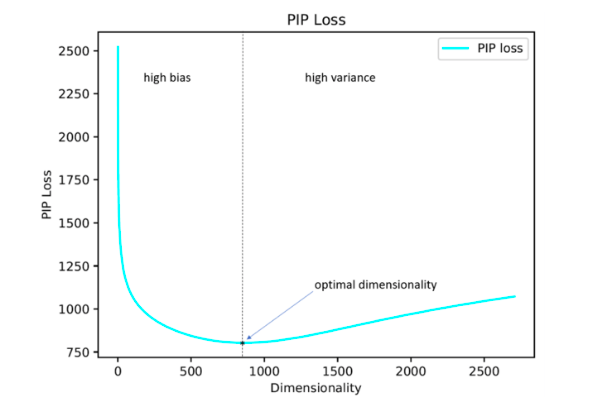
Как выяснилось, рассчитанная таким образом размерность эмбеддинга в большинстве случаев с погрешностью до 5% совпадает с оптимальной размерностью, определенной на основе экспертных оценок. Оказалось (ожидаемо), что Word2Vec и GloVe практически не переобучаются (PIP loss на очень больших размерностях не падает), а вот LSA переобучается достаточно сильно.
При помощи кода, выложенного на гитхаб авторами, можно искать оптимальную размерность Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Frequency-Agnostic Word Representation
Abstract
Код
Авторы рассуждают о том, как по-разному работают эмбеддинги для редких и для популярных слов. Под популярными я понимаю не стоп-слова (их вообще не рассматриваем), а содержательные слова, которые встречаются не очень редко.
Наблюдения следующие:
Если говорить о популярных словах, то их близость по косинусной мере очень хорошо отражает
Как бы там ни было с соотношением L2-норм эмбеддингов, разделимость популярных и редких слов — явление не очень хорошее. Мы хотим чтобы эмбеддинги отражали семантику слова, а не его частотность.
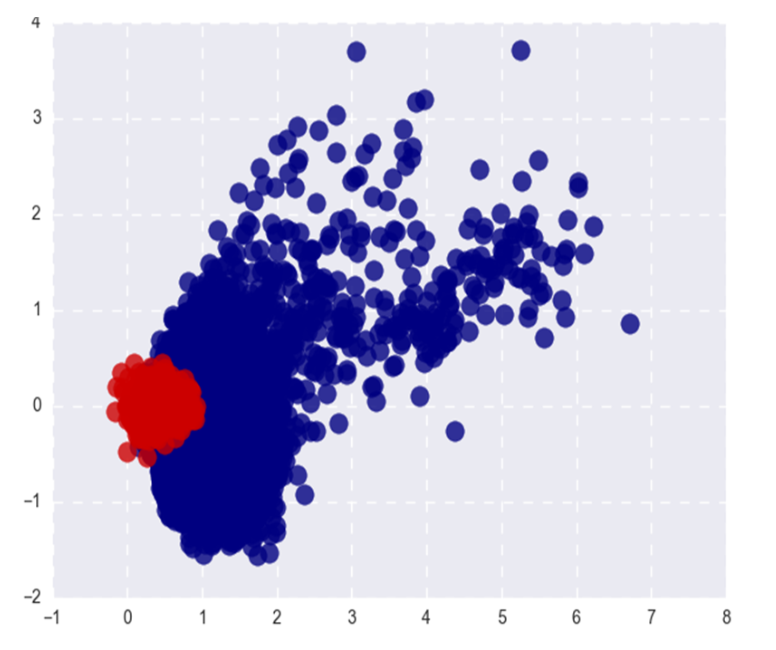
На картинке показаны Word2Vec популярных (красный) и редких (синий) слов после SVD. Под популярными здесь понимаются топ-20% слов по частоте.
Если бы проблема была лишь в L2-нормах эмбеддингов, мы могли бы нормировать их и жить счастливо, но, как я говорил в первом пункте, по косинусной близости (в полярных координатах) редкие слова тоже отделяются от популярных.
Авторы предлагают, конечно же, GAN. Давайте будем делать все то же самое, что раньше, но добавим дискриминатор, который будет пытаться отличить популярные слова от редких (опять же, популярными считаем топ-n% слов по частоте).
Выглядит это примерно так:
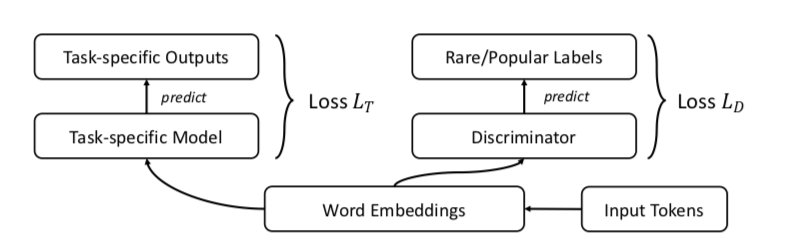
Авторы тестируют подход на задачах word similarity, machine translation, text classification и language modeling и везде перформят лучше бейзлайна. В word similarity утверждается, что качество растет особенно заметно именно на редких словах.
Один пример: citizenship. Skip-gram выдает: bliss, pakistans, dismiss, reinforces. FRAGE выдает: population, stadtischen, dignity, burger. Слова citizen и citizens у FRAGE на 79 и 7 месте соответственно (по близости к citizenship), у skip-gram — не входят в топ-10000.
Почему-то авторы выложили код только для задач machine translation и language modeling, word similarity и text classification в репозитории, к сожалению, не представлены.
Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces
Abstract
Код: кода нет, а хотелось бы
Недавние исследования показали, что два векторных пространства, обученных с помощью эмбеддинг-алгоритмов (например, word2vec) на текстовых корпусах на двух разных языках, можно сопоставить друг другу без разметки и соответствия содержания двух корпусов друг другу. В частности, этот подход используется для машинного перевода в компании Facebook. Используется одно из ключевых свойств пространств эмбеддингов: внутри них похожие слова должны быть геометрически близки, а непохожие – наоборот, находиться далеко друг от друга. Предполагается, что в целом структура векторного пространства сохраняется независимо от того, на каком языке был корпус для обучения.
Авторы статьи пошли дальше и применили подобный подход к области автоматического распознавания и перевода речи. Предлагается обучить векторное пространство отдельно для текстового корпуса на интересующем языке (например, Википедии), отдельно – для корпуса записанной речи (в аудио-формате), возможно на другом языке, предварительно разбитого на слова, а затем сопоставить эти два пространства аналогично способу с двумя текстовыми корпусами.
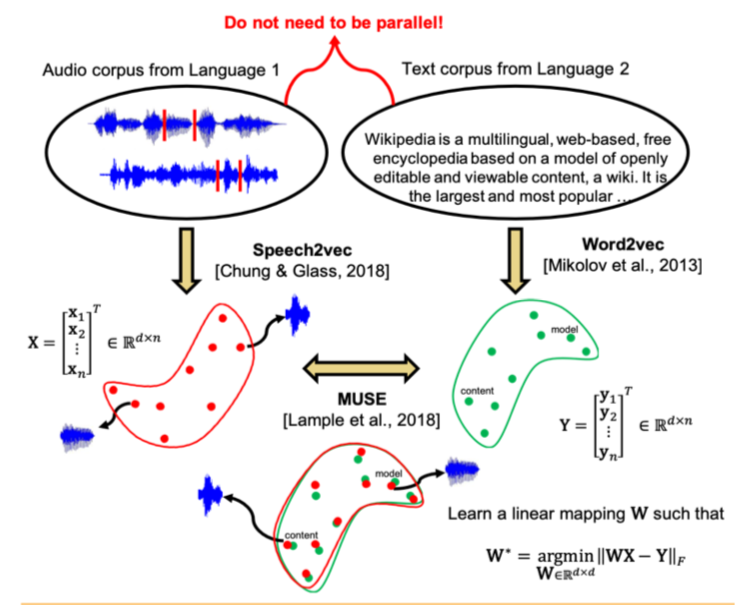
Для текстового корпуса используется word2vec, а для речи – подобный подход, названный авторами Speech2vec, основанный на LSTM и методологиях, используемых для word2vec (CBOW/skip-gram), так что предполагается, что он объединяет слова именно по контекстным и семантическим характеристикам, а не по звучанию.
После того, как оба векторных пространства обучены и есть два набора эмбеддингов – S (на корпусе речи), состоящий из n эмбеддингов размерности d1 и T (на корпусе текста), состоящий из m эмбеддингов размерности d2, нужно их сопоставить. В идеале у нас есть словарь, определяющий, какой вектор из S соответствует какому вектору из T. Тогда формируются две матрицы для сопоставления: из S выбирается k эмбеддингов, которые образуют матрицу X размера d1 x k; из T тоже выбирается k эмбеддингов, соответствующих (по словарю) ранее выбранным из S, и получается матрица Y размера d2 x k. Далее необходимо найти такое линейное отображение W, что:
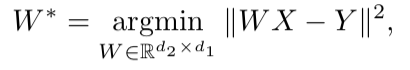
Но поскольку в статье рассматривается unsupervised подход, изначально словаря нет, поэтому предлагается процедура генерации синтетического словаря, состоящая из двух частей. Сначала получается первое приближение W с помощью domain-adversarial training (состязательная модель наподобие GAN, только вместо генератора – линейное отображение W, с помощью которого мы стараемся сделать S и T неотличимыми друг от друга, а дискриминатор старается определить настоящее происхождение эмбеддинга). Затем на основании слов, эмбеддинги которых показали наилучшее соответствие друг другу и наиболее часто встречаются в обоих корпусах, формируется словарь. После этого происходит уточнение W в соответствии с формулой выше.
Этот подход дает результаты, сравнимые с обучением на размеченных данных, что может быть очень полезно в задаче распознавания и перевода речи с редких языков, для которых слишком мало параллельных корпусов речь-текст, или они отсутствуют.
Deep Anomaly Detection Using Geometric Transformations
Abstract
Код
Достаточно необычный подход в anomaly detection, который, если верить авторам, сильно побеждает другие подходы.
Идея такая: давайте придумаем K разных геометрических трансформаций (комбинации сдвигов, поворота на 90 градусов и отражения) и применим их к каждой картинке исходного датасета. Картинка, получившаяся в результате i-ой трансформации, будет у нас теперь относится к классу i, то есть всего будет K классов, каждый из них будет представлен таким количеством картинок, которое было изначально в датасете. Теперь обучим многоклассовую классификацию на такой разметке (авторы выбрали wide resnet).
Теперь мы умеем для новой картинки получать K векторов y(Ti(x)) размерности K, где Ti — i-ая трансформация, x — картинка, y — выход модели. Базовое определение “нормальности” следующее:
Здесь мы для изображения x сложили предсказанные вероятности правильных классов для всех трансформаций. Чем больше “нормальность” тем более вероятно, что изображение взято из того же распределения, что и обучающая выборка. Авторы утверждают, что это уже работает очень здорово, но тем не менее предлагают более сложный способ, который работает еще чуть лучше. Мы будем считать, что вектор y(Ti(x)) для каждой трансформации Ti распределен по Дирихле и в качестве меры “нормальности” изображения будем считать логарифм правдоподобия. Параметры распределения Дирихле оцениваются на обучающей выборке.
Авторы рапортуют о невероятном бусте перформанса по сравнению с другими подходами.
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks
Abstract
Код
Выявление в выборке для применения модели случаев, значительно отличающихся от распределения обучающей выборки – одно из основных требований для получения надежных результатов классификации. В то же время нейронные сети известны своей особенностью с высокой степенью уверенности (и неправильно) классифицировать объекты, не встречавшиеся в обучении, или намеренно испорченные (adversarial examples).
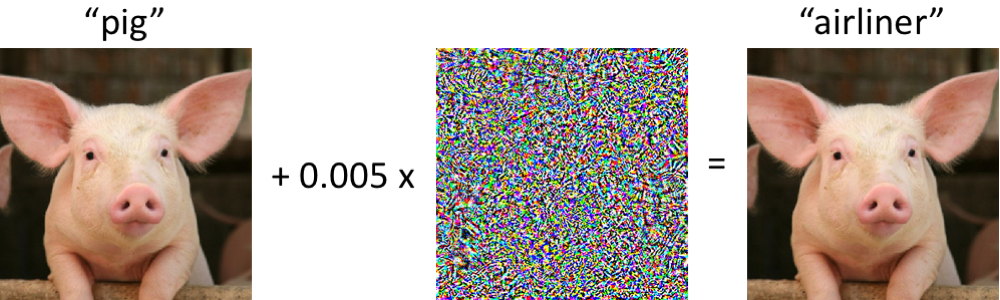
Авторы статьи предлагают новый метод выявления и тех, и других «плохих» случаев. Подход реализуется следующим образом: сначала обучается нейронная сеть с обычным softmax-выходом, затем берется выход ее предпоследнего слоя, и на нем обучается генеративный классификатор. Пусть есть x – то, что подается на вход модели для конкретного объекта классификации, y – соответствующая метка класса, тогда предположим, что у нас есть предобученный softmax-классификатор вида:
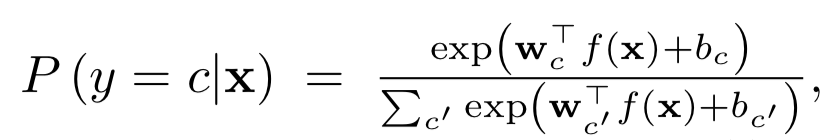
Где wc и bc – веса и константа слоя softmax для класса c, а f(.) – выход предпоследнего соя DNN.
Далее, без каких-либо изменений предобученного классификатора, делается переход к генеративному классификатору, а именно дискриминантному анализу. Предполагается, что признаки, взятые из предпоследнего слоя softmax-классификатора, имеют многомерное нормальное распределение, каждая компонента которого соответствует одному классу. Тогда условное распределение можно задать через вектор средних многомерного распределения и его матрицу ковариаций:
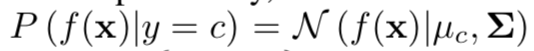
Чтобы оценить параметры генеративного классификатора, рассчитываются эмпирические средние для каждого класса, а также ковариация для случаев из обучающей выборки {(x1, y1),…, (xN, yN)}:
где N – число случаев соответствующего класса в обучающей выборке. Затем на тестовой выборке рассчитывается мера надежности – расстояние Махаланобиса между тестовым случаем и нормальным распределением класса, ближайшим к этому случаю.
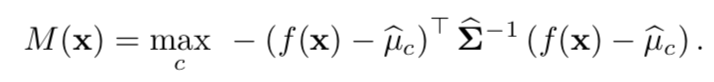
Как оказалось, такая метрика работает гораздо надежнее на нетипичных или испорченных объектах, не выдавая завышенные оценки, как у слоя softmax. В большинстве сравнений на разных данных предложенный метод показал результаты, превышающие текущий state-of-the-art в нахождении как случаев, которых не было в обучении, так и намеренно испорченных.
Далее авторы рассматривают еще одно интересное приложение своей методики: использовать генеративный классификатор для выделения на тесте новых классов, которых не было в обучении, а затем обновлять параметры самого классификатора так, чтобы в дальнейшем он смог определять и этот новый класс.
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
Abstract: https://arxiv.org/abs/1802.08195
Авторы исследуют что такое adversarial examples с точки зрения человеческого восприятия. Сегодня никого не удивляет то, что можно почти не изменив изображение заставить сеть ошибаться на нем. Однако не очень понятно насколько исходная картинка отличается от adversarial example для человека и отличается ли вообще. Понятно, что никто из людей не назовет картинку справа страусом, но все же, возможно, картинка справа для человека не совсем тождественна картинке слева, и, раз так, человек тоже может быть подвержен adversarial attacks.

Авторы пытаются оценить насколько хорошо человек сможет классифицировать adversarial examples. Для получения adversarial examples используется техника, у которой нет доступа к архитектуре исходной сети (логика авторов в том, что доступ к архитектуре человеческого мозга им все равно не дадут).
Итак, человеку показывают adversarial example, как с картинки выше и просят классифицировать его. Понятно, что в нормальных условиях результат был бы предсказуем, но здесь одно изображение показывается человеку в течение 63 миллисекунд после чего он должен выбрать один из двух классов. В таких условиях accuracy на исходных изображениях была на 10% выше, чем на adversarial. В принципе можно было бы это объяснить тем, что adversarial изображение просто зашумлено и поэтому в условиях дефицита времени люди неправильно его классифицируют, но это опровергает следующий эксперимент. Если перед тем, как добавлять к изображению perturbation мы этот perturbation отразим по вертикали, то accuracy по сравнению с исходной картинкой почти не изменится.
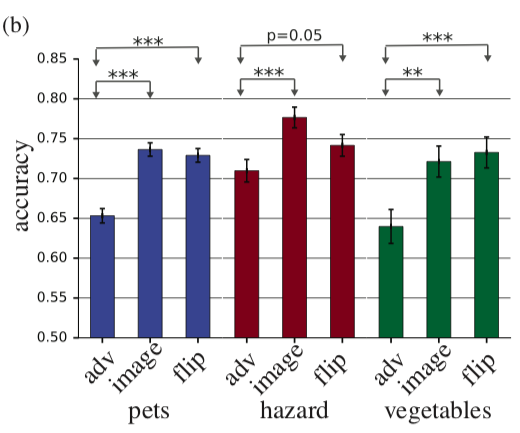
На гистограмме adv — adversarial example, image — исходное изображение, flip — исходное изображение + adversarial perturbation, отраженное по вертикали.
Sanity Checks for Saliency Maps
Abstract
Интерпретация моделей — одна из наиболее обсуждаемых тем сегодня. Если речь идет о deep learning, то обычно говорят о saliency maps. Saliency maps пытаются ответить на вопрос как меняется значение на одном из выходов сетки при изменении значений на входе. Так может выглядеть saliency map, которая показывает какие пиксели повлияли на то, что картинка была классифицирована как “собака”.

Авторы задаются очень резонным вопросом: “Как бы нам провалидировать методы построения saliency maps?” Выдвигаются два очевидных тезиса, которые предлагается проверить:
Проверять первый тезис мы будем, заменяя веса в обученной сетке рандомом: cascading randomization (рандомим слои, начиная с последнего и смотрим, как меняется saliency map) и independent randomization (рандомим конкретный слой). Второй тезис будем проверять так: перемешиваем случайно все лейблы на трейне, оверфитим трейн и смотрим saliency maps.
Если метод построения saliency map правда хороший и позволяет понять, как работает модель, такие рандомизации должны очень сильно менять saliency maps. Однако: “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — утверждают авторы. Вот, например, как выглядят saliency maps, полученные при помощи различных алгоритмов, после cascading randomization:
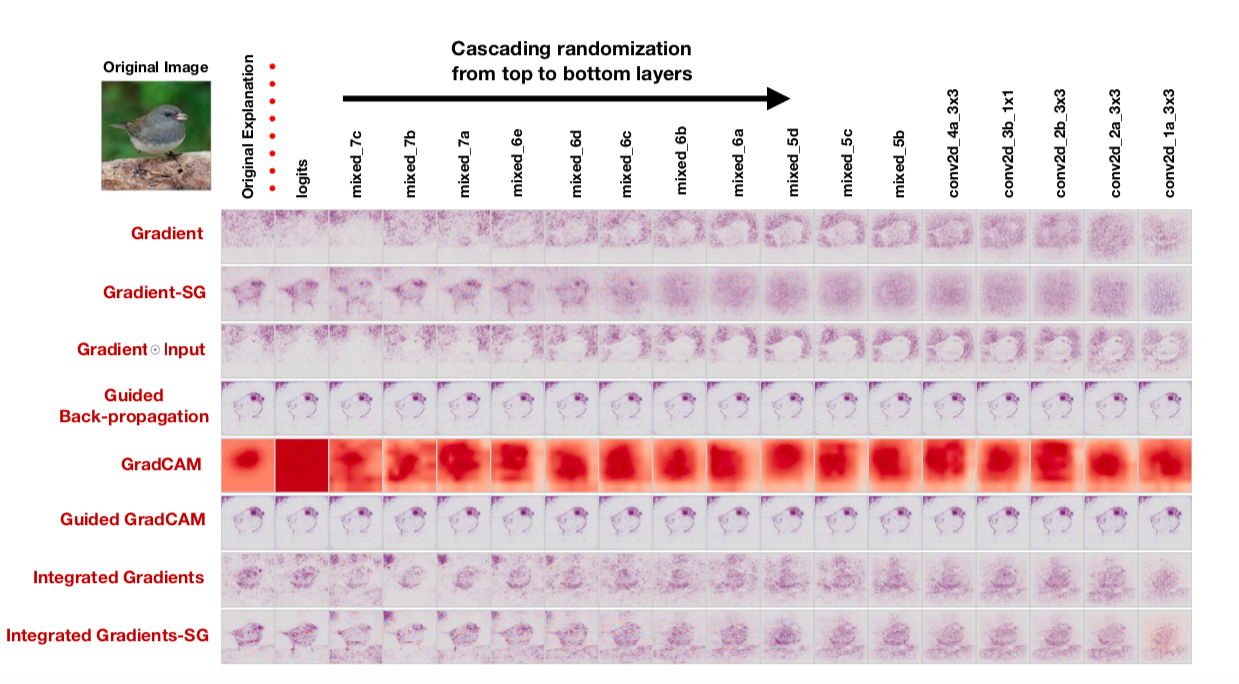
Обратите внимание на тот забавный факт, что последний столбец соответствует сетке с рандомными весами во всех слоях. То есть сетка предсказывает рандом, но некоторые saliency maps все еще рисуют птичку.
Авторы совершенно обоснованно говорят, что — оценка saliency maps по их понятности и логичности и недостаточное внимание к тому, насколько вообще результат связан с тем, как работает модель приводят к confirmation bias. Видимо в том числе и по этой причине оказывается, что распространенные подходы к интерпретации моделей вовсе их не интерпретируют.
An intriguing failing of convolutional neural networks and the CoordConv solution
Abstract: https://arxiv.org/abs/1807.03247
Код: уже много реализаций и в целом идея настолько красива и проста, что пишется буквально в 10 строчек.
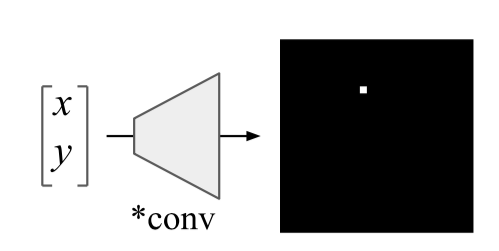
Простая в реализации и многообещающая идея от Uber. Сверточные сети изначально заточены под инвариантность к сдвигу, поэтому задачи, связанные с определением координат объекта, для таких сетей очень трудны. Обычные сверточные сети не в состоянии решить даже такие игрушечные задачи, как определить координаты точки на картинке или нарисовать точку по координатам:
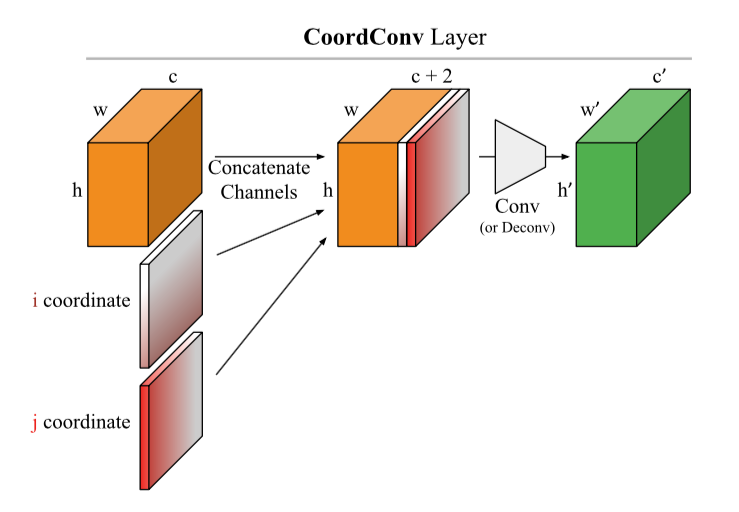
Предлагается очень элегантный хак: добавим к картинке (в общем случае к входу CoodrConv слоя) две матрицы i и j, в которых будут содержаться вертикальная и горизонтальная координаты соответствующих пикселей:
Утверждается, что:
Лично мне из этого интереснее всего второй пункт, хотелось бы увидеть результаты на реальных датасетах, но сходу ничего не гуглится. Между тем CoordConv уже достаточно активно встраивают в U-net: https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274, https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge.
Есть хорошее и более подробное видео от автора.
Regularizing by the Variance of the Activations' Sample-Variances
Abstract
Код
Авторы предлагают забавную альтернативу batch normalization. Мы будем штрафовать сетку за изменчивость дисперсии активаций на каком-то слое. На практике они реализуют это так: возьмем из батча два непересекающихся подмножества S1 и S2 и посчитаем такую штуку:
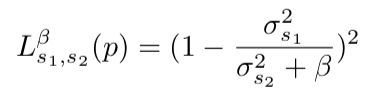
где ?2 — это выборочные дисперсии в S1 и S2 соответственно, ? — обучаемый положительный коэффициент. Эта штуку авторы называют variance constancy loss (VCL) и добавляют к общему лоссу.
В секции про эксперименты авторы жалуются на то, как не воспроизводятся результаты чужих статей и коммитятся обязательно выложить воспроизводимый код (выложили). Экспериментировали сначала с маленькой 11-слойной сеточкой на датасете маленьких картинок (CIFAR-10 и CIFAR-100). Получили, что VCL докидывает, если в качестве активаций использовать Leaky ReLU или ELU, а вот с ReLU лучше работает batch normalization. Далее увеличивают количество слоев в 2 раза и переходят на Tiny Imagenet — упрощенная версия Imagenet с 200 классами и разрешением 64x64. На валидации VCL выигрывает у batch normalization на сетке с ELU, а также у ResNet-110 и DenseNet-40, но проигрывает Wide-ResNet-32. Интересный момент состоит в том, что лучшие результаты получаются, когда подмножества S1 и S2 состоят из двух сэмплов.
Помимо этого авторы тестируют VCL в feed-forward сетях и VCL побеждает несколько чаще, чем сеть с batch normalization или без регуляризации.
DropMax: Adaptive Variational Softmax
Abstract
Код
Предлагается в задаче многоклассовой классификации на каждой итерации градиентного спуска для каждого сэмпла случайно дропать какое-то количество неверных классов. Причем вероятность, с которой мы дропнем тот или иной класс для того или иного объекта, также обучается. В итоге получается, что сеть “концентрируется” на том, чтобы различать самые трудноотделимые классы.
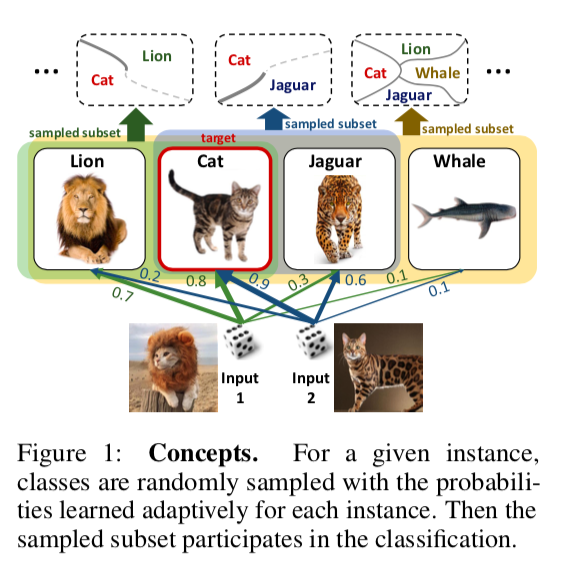
Эксперименты на MNIST, CIFAR и подмножествах Imagenet показывают, что DropMax работает лучше как стандартного SoftMax, так и ряда его модификаций.
Accurate Intelligible Models with Pairwise Interactions
(Friends Don’t Let Friends Deploy Black-Box Models: The Importance of Intelligibility in Machine Learning)
Abstract: http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdf
Код: его нет. Мне очень интересно, как в голове у авторов вяжется такое слегка императивное название с отсутствием кода. Академики, сэр =)
Можно посмотреть на этот пакет, например: https://github.com/dswah/pyGAM. В него не так давно добавили feature interactions (что собственно отличает GAM от GA2M).
Эта статья представлялась в рамках воркшопа “Interpretability and Robustness in Audio, Speech, and Language”, хотя посвящена интерпретируемости моделей в целом, а не области анализа звука и речи.Наверное, все в какой-то степени сталкивались с дилеммой выбора между интерпретируемостью модели и ее точности. Если мы используем обычную линейную регрессию, впоследствии мы по коэффициентам можем понять, как каждая независимая переменная влияет на зависимую. Если же мы используем модели «черного ящика», например, градиентный бустинг без ограничений на сложность или глубокие нейронные сети, правильно настроенная модель на подходящих данных будет очень точной, но отследить и объяснить все закономерности, которые модель обнаружила в данных, будет проблематично. Соответственно, будет сложно и объяснить модель заказчику, и самим отследить, не выучила ли она что-то такое, что нам бы не хотелось. В таблице ниже приведены оценки относительной интерпретируемости и точности различных видов моделей.

Пример ситуации, когда плохая интерпретируемость модели связана с большими рисками: на одном из медицинских датасетов решалась задача прогнозирования вероятности пациента умереть от пневмонии. В данных обнаружилась следующая интересная закономерность: если у человека есть бронхиальная астма, то вероятность умереть от пневмонии ниже, чем у людей без этого заболевания. Когда исследователи обратились к практикующим врачам, выяснилось, что такая закономерность действительно есть, поскольку люди с астмой в случае пневмонии получают наиболее оперативную помощь и сильные лекарства. Если бы мы тренировали xgboost на этом датасете, скорее всего он уловил бы эту закономерность, и наша модель относила бы пациентов с астмой к группе низкого риска, и, соответственно, рекомендовала бы для них более низкий приоритет и интенсивность лечения.
Авторы статьи предлагают альтернативу, которая и интерпретируема, и точна одновременно — это GA2M, подвид обобщенных аддитивных моделей (Generalized additive models).
Классические GAM можно рассматривать, как дальнейшее обобщение GLM: модель представляет собой сумму, каждый член которой отражает влияние только одной независимой переменной на зависимую, но влияние выражается не одним весовым коэффициентом, как в GLM, а гладкой непараметрической функцией (как правило, используются кусочно заданные функции – сплайны или деревья небольшой глубины, в том числе «пни»). За счет этой особенности GAM могут моделировать более сложные отношения, чем простая линейная модель. С другой стороны, выученные зависимости (функции) можно визуализировать и проинтерпретировать.
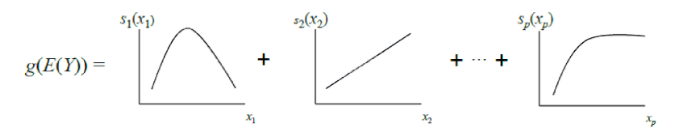
Однако стандартные GAM все же часто не дотягивают по точности до алгоритмов «черного ящика». Чтобы это исправить, авторы статьи предлагают компромисс – добавить в уравнение модели, помимо функций одной переменной, небольшое количество функций двух переменных – тщательно отобранных пар, взаимодействие которых значимо для предсказания зависимой переменной. Таким образом получается GA2M.
Сначала строится стандартная GAM (без учета взаимодействия переменных), а затем пошагово добавляются пары переменных (в качестве целевой переменной используются остатки GAM). Для случая, когда переменных много и обновление модели после каждого шага вычислительно трудоемко, предлагается алгоритм ранжирования FAST, с помощью которого можно заранее отобрать потенциально полезные пары и избежать полного перебора.
Такой подход позволяет добиться качества, близкого к моделям неограниченной сложности. В таблице приведена доля ошибок генерализованных аддитивных моделей по сравнению со случайным лесом для решения задачи классификации на различных датасетах, и в большинстве случаев качество предсказания для GA2M c FAST и для случайных лесов значимо не отличается.
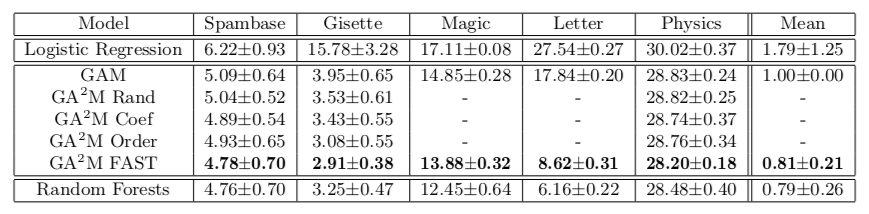
Хотел бы обратить внимание на особенности работ академиков, которые предлагают отправить в топку эти ваши бустинги и дип лернинги. Обратите внимание, что датасеты, на которых приводятся результаты содержат не более 20 тысяч объектов (все датасеты из репозитория UCI). Возникает естественный вопрос: неужели в 2018 году нет открытых датасетов нормального размера для подобных экспериментов. Можно ведь пойти дальше и сравниваться на датасете из 50 объектов — там есть шанс, что и константная модель не будет значимо отличаться от случайного леса.
Следующий момент — регуляризация. На большом количестве признаков очень легко переобучиться даже без интеракций. Авторы, возможно, считают, что этой проблемы не существует, а единственная проблема — это black-box модели. По крайней мере в статье о регуляризации не говорят нигде, хотя она, очевидно, необходима.
И последнее, про интерпретируемость. Даже линейные модели не интерпретируемы если у нас достаточно много признаков. Когда у вас 10 тысяч нормально распределенных весов (в случае использования L2-регуляризации это примерно так и будет), невозможно сказать, какие именно признаки ответственны за то, что predict_proba выдает 0.86. Для интерпретируемости мы хотим не просто линейную модель, а линейную модель со sparse весами. Казалось бы, этого можно добиться L1-регуляризацией, но здесь тоже не все так просто. Из набора сильно коррелированных фичей L1-регуляризация выберет одну практически случайно. Остальные получат вес 0, хотя, если одна из этих фичей обладает предсказательной способностью, другие явно не являются просто шумом. В плане интерпретации модели это может быть и ОК, в плане понимания взаимосвязи признаков и целевой переменной это очень плохо. То есть даже с линейными моделями не все так однозначно, подробнее об interpretable and credible models можно глянуть здесь.
Visualization for Machine Learning: UMAP
Absract
Код
В день тьюториалов одним из первых шло выступление “Visualization for Machine Learning” от Google Brain. В рамках тьюториала нам рассказали про историю визуализаций, начиная от создателя первых графиков, а также про разные особенности человеческого мозга и восприятия и техники, которые можно использовать, чтобы привлечь внимание к самому важному на картинке, пусть даже содержащей много мелких деталей – например, выделение формой, цветом, рамочкой и т.д., как на рисунке ниже. Я эту часть пропущу, но тут есть хороший обзор.

Лично мне больше всего была интересна тема визуализации многомерных датасетов, в частности подход Uniform Manifold Approximation and Projection (UMAP) – новый нелинейный метод снижения размерности. Предложен он был в феврале этого года, поэтому мало кто пока его использует, но выглядит многообещающе как в плане времени работы, так и в плане качества разделения классов в двухмерных визуализациях. Так, на разных датасетах по скорости работы UMAP опережает t-SNE и другие методы в 2-10 раз, причем чем больше размерность данных, тем больше отрыв в производительности:
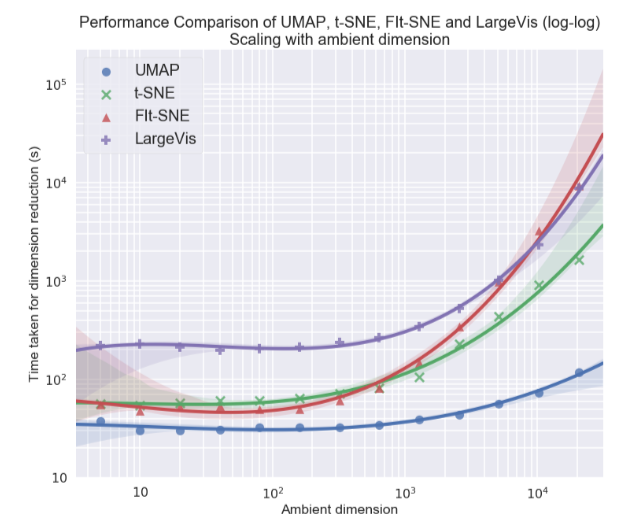
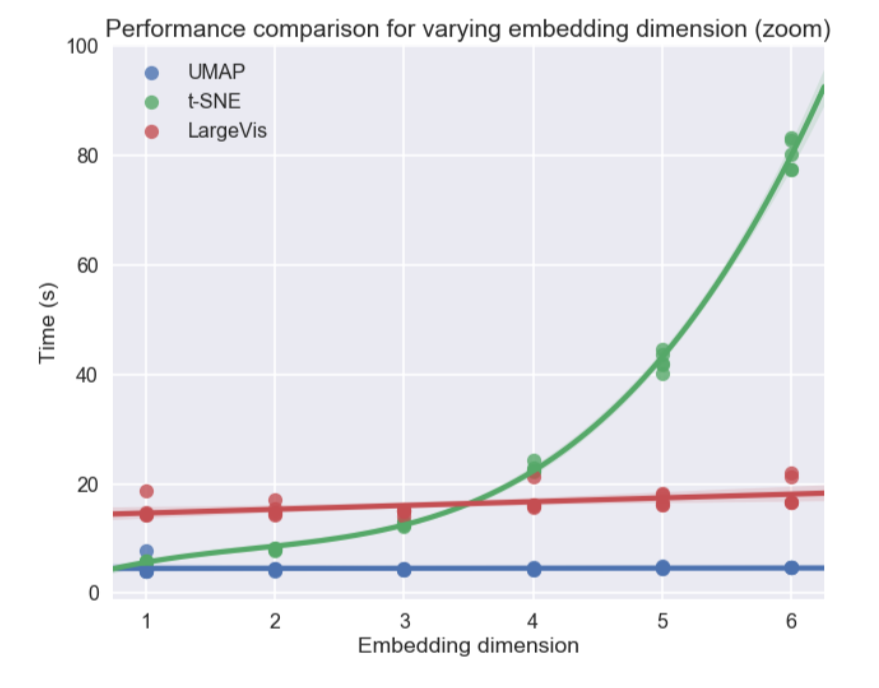
Кроме этого, в отличие от t-SNE время работы UMAP почти не зависит от размерности нового пространства, в которое мы эмбеддим наш датасет (см. рис. ниже), что делает его подходящим инструментом для других задач (помимо визуализации) — в частности, для снижения размерности перед обучением модели.
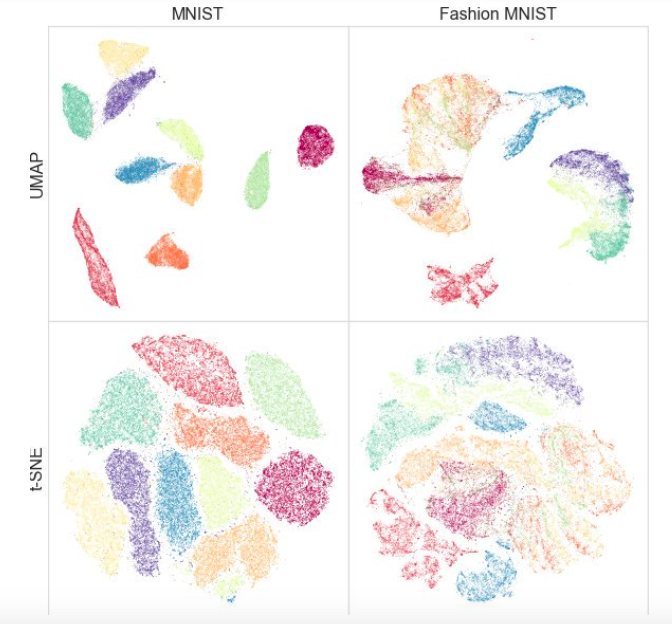
При этом тестирование на различных датасетах показало, что для визуализации UMAP работает не хуже, а местами лучше t-SNE: например, на датасетах MNIST и Fashion MNIST классы лучше разделяются именно в варианте с UMAP:
Дополнительный плюс — удобная реализация: класс UMAP наследуется от классов sklearn, так что можно использовать его как обычный трансформер в sklearn pipeline. Кроме того, утверждается, что UMAP более интерпретируем, чем t-SNE, т.к. лучше сохраняет глобальную структуру данных.?
В будущем авторы планируют добавить поддержку semi-supervised обучения — то есть если у нас будут метки хотя бы для части объектов, мы можем построить UMAP с учетом этой информации.
А какие статьи понравились вам? Пишите комментарии, задавайте вопросы, мы обязательно на них ответим.
Relational recurrent neural networks
Abstract
Код
При работе с последовательностями часто бывает очень важно, как связаны друг с другом элементы последовательности. Стандартные архитектуры рекуррентных сетей (GRU, LSTM) с трудом могут моделировать взаимосвязь между двумя достаточно удаленными друг от друга элементами. В какой-то степени с этим помогает справиться attention (https://youtu.be/SysgYptB198, https://youtu.be/quoGRI-1l0A), но все-таки это не совсем то. Attention позволяет определить вес, с которым hidden state с каждого из шагов последовательности будет влиять на итоговый hidden state и, соответственно, на предсказание. Нас же интересует взаимосвязь элементов последовательности.
В прошлом году, опять же на NIPS’е, google предложил вообще отказаться от рекурренстности и использовать self-attention. Подход показал себя очень хорошо, правда в основном на seq2seq задачах (в статье приводятся результаты по машинному переводу).
Авторы статьи этого года используют идею self-attention в рамках LSTM. Изменений не так много:
- Меняем вектор cell state на матрицу “памяти” M. Матрица памяти в какой-то степени — это много векторов cell state (много ячеек памяти). Получая новый элемент последовательности мы определяем, насколько этот элемент должен обновить каждую из ячеек памяти
- Для каждого элемента последовательности будем обновлять эту матрицу используя multi-head dot product attention (MHDPA, почитать об этом методе можно в упомянутой статье от google). Результат MHPDA для текущего элемента последовательности и матрицы M прогоняется через полносвязную сетку, сигмоиду и далее матрица M обновляется так же, как и cell state в LSTM
Утверждается, что именно за счет MHDPA сетка может учитывать взаимосвязь элементов последовательности даже когда они удалены друг от друга.
В качестве игрушечной задачи модель просят в последовательности векторов найти N-ый вектор по удаленности от M-ого в терминах евклидова расстояния. Например, есть последовательность 10 векторов и мы просим найти тот, который на третьем месте по близости к пятому. Понятно, что для ответа на этот вопрос модели необходимо как-то оценить расстояния от всех векторов до пятого и отсортировать их. Здесь модель, предложенная авторами, уверенно побеждает LSTM и DNC. Помимо этого, авторы сравнивают свою модель с другими архитектурами на Learning to Execute (на вход получаем несколько строк кода, выдаем результат), Mini-Pacman, Language Modeling и везде рапортуют о лучших результатах.
Multivariate Time Series Imputation with Generative Adversarial Networks
Abstract
Код (хотя в статье они сюда не ссылаются)
В многомерных временных рядах, как правило, содержится большое количество пропусков, что мешает применению продвинутых статистических методов. Стандартные решения – заполнение средним/нулем, удаление неполных случаев, восстановление данных на основании матричных разложений в этой ситуации, зачастую не работают, поскольку не могут воспроизвести временные зависимости и сложное распределение многомерных временных рядов.
Широко известна способность генеративно-состязательных сетей (GAN’ов) имитировать любое распределение данных, в частности, в задачах «дорисовывания» лиц и генерации предложений. Но, как правило, такие модели или требуют изначального обучения на полном датасете без пропусков, либо не учитывают последовательный характер данных.
Авторы предлагают дополнить GAN новым элементом – Gated Recurrent Unit for Imputation (GRUI). Основное отличие от обычного GRU в том, что GRUI может обучаться на данных с интервалами разной длины между наблюдениями и корректировать влияние наблюдений в зависимости от их удаленности во времени от текущей точки. Рассчитывается специальный параметр затухания ?, значение которого варьируется от 0 до 1 и тем меньше, чем больше временной лаг между текущим наблюдением и предыдущим непустым.
И дискриминатор, и генератор GAN состоят из слоя GRUI и полносвязного слоя. Как обычно в GAN’ах, генератор учится имитировать исходные данные (в данном случае просто заполнять пропуски в рядах), а дискриминатор учится отличать ряды, заполненные генератором, от настоящих.
Как выяснилось, такой подход очень адекватно восстанавливает данные даже во временных рядах с очень большой долей пропусков (в таблице ниже – MSE восстановления данных в датасете KDD в зависимости от доли пропусков и метода восстановления. В большинстве случаев метод, основанный на GAN, дает наибольшую точность восстановления).
On the Dimensionality of Word Embeddings
Abstract
Код
Word embedding / векторное представление слов – подход, широко используемый для различных приложений NLP: от рекомендательных систем до анализа эмоциональной окраски текстов и машинного перевода.
При этом вопрос о том, как оптимально задать такой важный гиперпараметр, как размерность векторов, остается открытым. На практике чаще всего он подбирается эмпирическим перебором или задается по умолчанию, например, на уровне 300. При этом слишком маленькая размерность не позволяет отразить все значимые взаимосвязи между словами, а слишком большая может привести к переобучению.
Авторы исследования предлагают свое решение этой проблемы с помощью минимизации параметра PIP loss – новой меры различия между двумя вариантами эмбеддингов.
В основе расчета лежат PIP-матрицы, которые содержат в себе скалярные произведения всех пар векторных представлений слов в корпусе. PIP loss рассчитывается как норма Фробениуса между PIP-матрицами двух эмбеддингов: обученного на данных (trained embedding E_hat) и идеального, обученного на незашумленных данных (oracle embedding E).
Казалось бы все просто: нужно выбрать размерность, которая минимизирует PIP loss, единственный непонятный момент — откуда взять oracle embedding. В 2015-2017 годах был опубликован ряд работ, в которых показано, что различные методы построения эмбеддингов (word2vec, GloVe, LSA) неявно факторизуют (понижают размерность) signal matrix корпуса. В случае word2vec (skip-gram) signal matrix — это PMI, в случае GloVe — матрица log-counts. Предлагается взять словарь не очень большого размера, построить signal matrix и использовать SVD для получения oracle embedding. Таким образом, размерность oracle embedding получается равной рангу signal matrix (на практике для словаря в 10k слов размерность будет порядка 2k). Однако наша эмпирическая signal matrix всегда зашумлена и приходится прибегать к хитрым схемам чтобы получить oracle embedding и оценить PIP loss по зашумленной матрице.
Авторы утверждают, что для выбора оптимальной размерности эмбеддинга достаточно использовать словарь из 10k слов, что не очень много и позволяет прогнать эту процедуру за разумное время.
Как выяснилось, рассчитанная таким образом размерность эмбеддинга в большинстве случаев с погрешностью до 5% совпадает с оптимальной размерностью, определенной на основе экспертных оценок. Оказалось (ожидаемо), что Word2Vec и GloVe практически не переобучаются (PIP loss на очень больших размерностях не падает), а вот LSA переобучается достаточно сильно.
При помощи кода, выложенного на гитхаб авторами, можно искать оптимальную размерность Word2Vec (skip-gram), GloVe, LSA.
FRAGE: Frequency-Agnostic Word Representation
Abstract
Код
Авторы рассуждают о том, как по-разному работают эмбеддинги для редких и для популярных слов. Под популярными я понимаю не стоп-слова (их вообще не рассматриваем), а содержательные слова, которые встречаются не очень редко.
Наблюдения следующие:
Если говорить о популярных словах, то их близость по косинусной мере очень хорошо отражает
- их смысловую близость. Для редких слов это не так (что ожидаемо), и (что менее ожидаемо) top-n самых близких по косинусной мере слов к редкому слову тоже редкие и при этом семантически не связанные. То есть редкие и частые слова в пространстве эмбеддингов живут в разных местах (в разных конусах, если уж мы говорим о косинусе)
- Во время обучения вектора популярных слов обновляются значительно чаще и в среднем оказываются в два раза дальше от инициализации, чем вектора для редких слов. Это приводит к тому, что эмбеддинги редких слов в среднем ближе к началу координат. Я, честно говоря, всегда считал, что наоборот эмбеддинги редких слов имеют в среднем большую длину, и пока не знаю как относиться к заявлению авторов =)
Как бы там ни было с соотношением L2-норм эмбеддингов, разделимость популярных и редких слов — явление не очень хорошее. Мы хотим чтобы эмбеддинги отражали семантику слова, а не его частотность.
На картинке показаны Word2Vec популярных (красный) и редких (синий) слов после SVD. Под популярными здесь понимаются топ-20% слов по частоте.
Если бы проблема была лишь в L2-нормах эмбеддингов, мы могли бы нормировать их и жить счастливо, но, как я говорил в первом пункте, по косинусной близости (в полярных координатах) редкие слова тоже отделяются от популярных.
Авторы предлагают, конечно же, GAN. Давайте будем делать все то же самое, что раньше, но добавим дискриминатор, который будет пытаться отличить популярные слова от редких (опять же, популярными считаем топ-n% слов по частоте).
Выглядит это примерно так:
Авторы тестируют подход на задачах word similarity, machine translation, text classification и language modeling и везде перформят лучше бейзлайна. В word similarity утверждается, что качество растет особенно заметно именно на редких словах.
Один пример: citizenship. Skip-gram выдает: bliss, pakistans, dismiss, reinforces. FRAGE выдает: population, stadtischen, dignity, burger. Слова citizen и citizens у FRAGE на 79 и 7 месте соответственно (по близости к citizenship), у skip-gram — не входят в топ-10000.
Почему-то авторы выложили код только для задач machine translation и language modeling, word similarity и text classification в репозитории, к сожалению, не представлены.
Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces
Abstract
Код: кода нет, а хотелось бы
Недавние исследования показали, что два векторных пространства, обученных с помощью эмбеддинг-алгоритмов (например, word2vec) на текстовых корпусах на двух разных языках, можно сопоставить друг другу без разметки и соответствия содержания двух корпусов друг другу. В частности, этот подход используется для машинного перевода в компании Facebook. Используется одно из ключевых свойств пространств эмбеддингов: внутри них похожие слова должны быть геометрически близки, а непохожие – наоборот, находиться далеко друг от друга. Предполагается, что в целом структура векторного пространства сохраняется независимо от того, на каком языке был корпус для обучения.
Авторы статьи пошли дальше и применили подобный подход к области автоматического распознавания и перевода речи. Предлагается обучить векторное пространство отдельно для текстового корпуса на интересующем языке (например, Википедии), отдельно – для корпуса записанной речи (в аудио-формате), возможно на другом языке, предварительно разбитого на слова, а затем сопоставить эти два пространства аналогично способу с двумя текстовыми корпусами.
Для текстового корпуса используется word2vec, а для речи – подобный подход, названный авторами Speech2vec, основанный на LSTM и методологиях, используемых для word2vec (CBOW/skip-gram), так что предполагается, что он объединяет слова именно по контекстным и семантическим характеристикам, а не по звучанию.
После того, как оба векторных пространства обучены и есть два набора эмбеддингов – S (на корпусе речи), состоящий из n эмбеддингов размерности d1 и T (на корпусе текста), состоящий из m эмбеддингов размерности d2, нужно их сопоставить. В идеале у нас есть словарь, определяющий, какой вектор из S соответствует какому вектору из T. Тогда формируются две матрицы для сопоставления: из S выбирается k эмбеддингов, которые образуют матрицу X размера d1 x k; из T тоже выбирается k эмбеддингов, соответствующих (по словарю) ранее выбранным из S, и получается матрица Y размера d2 x k. Далее необходимо найти такое линейное отображение W, что:
Но поскольку в статье рассматривается unsupervised подход, изначально словаря нет, поэтому предлагается процедура генерации синтетического словаря, состоящая из двух частей. Сначала получается первое приближение W с помощью domain-adversarial training (состязательная модель наподобие GAN, только вместо генератора – линейное отображение W, с помощью которого мы стараемся сделать S и T неотличимыми друг от друга, а дискриминатор старается определить настоящее происхождение эмбеддинга). Затем на основании слов, эмбеддинги которых показали наилучшее соответствие друг другу и наиболее часто встречаются в обоих корпусах, формируется словарь. После этого происходит уточнение W в соответствии с формулой выше.
Этот подход дает результаты, сравнимые с обучением на размеченных данных, что может быть очень полезно в задаче распознавания и перевода речи с редких языков, для которых слишком мало параллельных корпусов речь-текст, или они отсутствуют.
Deep Anomaly Detection Using Geometric Transformations
Abstract
Код
Достаточно необычный подход в anomaly detection, который, если верить авторам, сильно побеждает другие подходы.
Идея такая: давайте придумаем K разных геометрических трансформаций (комбинации сдвигов, поворота на 90 градусов и отражения) и применим их к каждой картинке исходного датасета. Картинка, получившаяся в результате i-ой трансформации, будет у нас теперь относится к классу i, то есть всего будет K классов, каждый из них будет представлен таким количеством картинок, которое было изначально в датасете. Теперь обучим многоклассовую классификацию на такой разметке (авторы выбрали wide resnet).
Теперь мы умеем для новой картинки получать K векторов y(Ti(x)) размерности K, где Ti — i-ая трансформация, x — картинка, y — выход модели. Базовое определение “нормальности” следующее:
Здесь мы для изображения x сложили предсказанные вероятности правильных классов для всех трансформаций. Чем больше “нормальность” тем более вероятно, что изображение взято из того же распределения, что и обучающая выборка. Авторы утверждают, что это уже работает очень здорово, но тем не менее предлагают более сложный способ, который работает еще чуть лучше. Мы будем считать, что вектор y(Ti(x)) для каждой трансформации Ti распределен по Дирихле и в качестве меры “нормальности” изображения будем считать логарифм правдоподобия. Параметры распределения Дирихле оцениваются на обучающей выборке.
Авторы рапортуют о невероятном бусте перформанса по сравнению с другими подходами.
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks
Abstract
Код
Выявление в выборке для применения модели случаев, значительно отличающихся от распределения обучающей выборки – одно из основных требований для получения надежных результатов классификации. В то же время нейронные сети известны своей особенностью с высокой степенью уверенности (и неправильно) классифицировать объекты, не встречавшиеся в обучении, или намеренно испорченные (adversarial examples).
Авторы статьи предлагают новый метод выявления и тех, и других «плохих» случаев. Подход реализуется следующим образом: сначала обучается нейронная сеть с обычным softmax-выходом, затем берется выход ее предпоследнего слоя, и на нем обучается генеративный классификатор. Пусть есть x – то, что подается на вход модели для конкретного объекта классификации, y – соответствующая метка класса, тогда предположим, что у нас есть предобученный softmax-классификатор вида:
Где wc и bc – веса и константа слоя softmax для класса c, а f(.) – выход предпоследнего соя DNN.
Далее, без каких-либо изменений предобученного классификатора, делается переход к генеративному классификатору, а именно дискриминантному анализу. Предполагается, что признаки, взятые из предпоследнего слоя softmax-классификатора, имеют многомерное нормальное распределение, каждая компонента которого соответствует одному классу. Тогда условное распределение можно задать через вектор средних многомерного распределения и его матрицу ковариаций:
Чтобы оценить параметры генеративного классификатора, рассчитываются эмпирические средние для каждого класса, а также ковариация для случаев из обучающей выборки {(x1, y1),…, (xN, yN)}:
где N – число случаев соответствующего класса в обучающей выборке. Затем на тестовой выборке рассчитывается мера надежности – расстояние Махаланобиса между тестовым случаем и нормальным распределением класса, ближайшим к этому случаю.
Как оказалось, такая метрика работает гораздо надежнее на нетипичных или испорченных объектах, не выдавая завышенные оценки, как у слоя softmax. В большинстве сравнений на разных данных предложенный метод показал результаты, превышающие текущий state-of-the-art в нахождении как случаев, которых не было в обучении, так и намеренно испорченных.
Далее авторы рассматривают еще одно интересное приложение своей методики: использовать генеративный классификатор для выделения на тесте новых классов, которых не было в обучении, а затем обновлять параметры самого классификатора так, чтобы в дальнейшем он смог определять и этот новый класс.
Adversarial Examples that Fool both Computer Vision and Time-Limited Humans
Abstract: https://arxiv.org/abs/1802.08195
Авторы исследуют что такое adversarial examples с точки зрения человеческого восприятия. Сегодня никого не удивляет то, что можно почти не изменив изображение заставить сеть ошибаться на нем. Однако не очень понятно насколько исходная картинка отличается от adversarial example для человека и отличается ли вообще. Понятно, что никто из людей не назовет картинку справа страусом, но все же, возможно, картинка справа для человека не совсем тождественна картинке слева, и, раз так, человек тоже может быть подвержен adversarial attacks.
Авторы пытаются оценить насколько хорошо человек сможет классифицировать adversarial examples. Для получения adversarial examples используется техника, у которой нет доступа к архитектуре исходной сети (логика авторов в том, что доступ к архитектуре человеческого мозга им все равно не дадут).
Итак, человеку показывают adversarial example, как с картинки выше и просят классифицировать его. Понятно, что в нормальных условиях результат был бы предсказуем, но здесь одно изображение показывается человеку в течение 63 миллисекунд после чего он должен выбрать один из двух классов. В таких условиях accuracy на исходных изображениях была на 10% выше, чем на adversarial. В принципе можно было бы это объяснить тем, что adversarial изображение просто зашумлено и поэтому в условиях дефицита времени люди неправильно его классифицируют, но это опровергает следующий эксперимент. Если перед тем, как добавлять к изображению perturbation мы этот perturbation отразим по вертикали, то accuracy по сравнению с исходной картинкой почти не изменится.
На гистограмме adv — adversarial example, image — исходное изображение, flip — исходное изображение + adversarial perturbation, отраженное по вертикали.
Sanity Checks for Saliency Maps
Abstract
Интерпретация моделей — одна из наиболее обсуждаемых тем сегодня. Если речь идет о deep learning, то обычно говорят о saliency maps. Saliency maps пытаются ответить на вопрос как меняется значение на одном из выходов сетки при изменении значений на входе. Так может выглядеть saliency map, которая показывает какие пиксели повлияли на то, что картинка была классифицирована как “собака”.
Авторы задаются очень резонным вопросом: “Как бы нам провалидировать методы построения saliency maps?” Выдвигаются два очевидных тезиса, которые предлагается проверить:
- Saliency map должна зависеть от весов сетки
- Saliency map должна зависеть от закономерностей, которые есть в данных
Проверять первый тезис мы будем, заменяя веса в обученной сетке рандомом: cascading randomization (рандомим слои, начиная с последнего и смотрим, как меняется saliency map) и independent randomization (рандомим конкретный слой). Второй тезис будем проверять так: перемешиваем случайно все лейблы на трейне, оверфитим трейн и смотрим saliency maps.
Если метод построения saliency map правда хороший и позволяет понять, как работает модель, такие рандомизации должны очень сильно менять saliency maps. Однако: “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — утверждают авторы. Вот, например, как выглядят saliency maps, полученные при помощи различных алгоритмов, после cascading randomization:
Обратите внимание на тот забавный факт, что последний столбец соответствует сетке с рандомными весами во всех слоях. То есть сетка предсказывает рандом, но некоторые saliency maps все еще рисуют птичку.
Авторы совершенно обоснованно говорят, что — оценка saliency maps по их понятности и логичности и недостаточное внимание к тому, насколько вообще результат связан с тем, как работает модель приводят к confirmation bias. Видимо в том числе и по этой причине оказывается, что распространенные подходы к интерпретации моделей вовсе их не интерпретируют.
An intriguing failing of convolutional neural networks and the CoordConv solution
Abstract: https://arxiv.org/abs/1807.03247
Код: уже много реализаций и в целом идея настолько красива и проста, что пишется буквально в 10 строчек.
Простая в реализации и многообещающая идея от Uber. Сверточные сети изначально заточены под инвариантность к сдвигу, поэтому задачи, связанные с определением координат объекта, для таких сетей очень трудны. Обычные сверточные сети не в состоянии решить даже такие игрушечные задачи, как определить координаты точки на картинке или нарисовать точку по координатам:
Предлагается очень элегантный хак: добавим к картинке (в общем случае к входу CoodrConv слоя) две матрицы i и j, в которых будут содержаться вертикальная и горизонтальная координаты соответствующих пикселей:
Утверждается, что:
- Такие свертки не портят перформанс на ImageNet’е. Задача классификации картинок как раз требует инвариантности к сдвигу, и, судя по результатам, сетка легко учится тому, что в задаче классификации координаты использовать не нужно
- CoordConv сильно улучшает object detection. По результатам экспериментов по детектированию цифр из MNIST, разбросанных по картинке при помощи Faster R-CNN, заявляют об увеличении IoU на 21%
- При использовании CoordConv в GAN разнообразие сгенерированных картинок увеличивается.
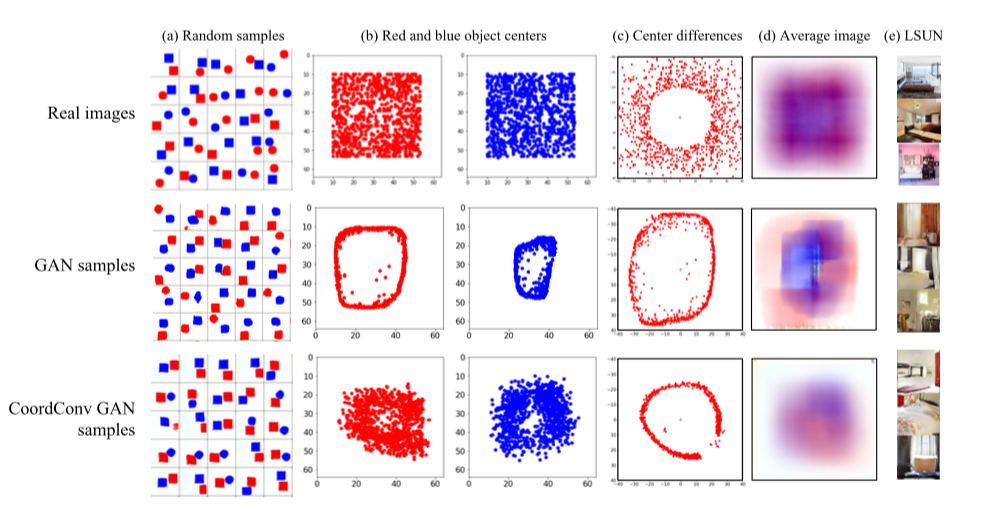
Обучали GAN’ы на двух датасетах: игрушечный датасет с фигурами красного и синего цвета в случайных местах и датасет с интерьерами спален LSUN. В первом датасете центры фигур распределены равномерно, распределение разности между центрами — верхний график в столбце c. При том, что сгенерированные GAN’ом сэмплы похожи на исходные, видно, что распределение центров и расстояний между центрами сильно отличается. При использовании CoordConv распределение расстояний между центрами значительно более похоже на исходное, хотя проблемы с разностью расстояний остаются. В случае с LSUN по столбцу d видно, что в целом распределение сэмплов, сгенерированных CoordConv GAN, ближе к исходному
- 4. Использование CoordConv в A2C дает прирост в некоторых (не во всех) играх.
Лично мне из этого интереснее всего второй пункт, хотелось бы увидеть результаты на реальных датасетах, но сходу ничего не гуглится. Между тем CoordConv уже достаточно активно встраивают в U-net: https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274, https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge.
Есть хорошее и более подробное видео от автора.
Regularizing by the Variance of the Activations' Sample-Variances
Abstract
Код
Авторы предлагают забавную альтернативу batch normalization. Мы будем штрафовать сетку за изменчивость дисперсии активаций на каком-то слое. На практике они реализуют это так: возьмем из батча два непересекающихся подмножества S1 и S2 и посчитаем такую штуку:
где ?2 — это выборочные дисперсии в S1 и S2 соответственно, ? — обучаемый положительный коэффициент. Эта штуку авторы называют variance constancy loss (VCL) и добавляют к общему лоссу.
В секции про эксперименты авторы жалуются на то, как не воспроизводятся результаты чужих статей и коммитятся обязательно выложить воспроизводимый код (выложили). Экспериментировали сначала с маленькой 11-слойной сеточкой на датасете маленьких картинок (CIFAR-10 и CIFAR-100). Получили, что VCL докидывает, если в качестве активаций использовать Leaky ReLU или ELU, а вот с ReLU лучше работает batch normalization. Далее увеличивают количество слоев в 2 раза и переходят на Tiny Imagenet — упрощенная версия Imagenet с 200 классами и разрешением 64x64. На валидации VCL выигрывает у batch normalization на сетке с ELU, а также у ResNet-110 и DenseNet-40, но проигрывает Wide-ResNet-32. Интересный момент состоит в том, что лучшие результаты получаются, когда подмножества S1 и S2 состоят из двух сэмплов.
Помимо этого авторы тестируют VCL в feed-forward сетях и VCL побеждает несколько чаще, чем сеть с batch normalization или без регуляризации.
DropMax: Adaptive Variational Softmax
Abstract
Код
Предлагается в задаче многоклассовой классификации на каждой итерации градиентного спуска для каждого сэмпла случайно дропать какое-то количество неверных классов. Причем вероятность, с которой мы дропнем тот или иной класс для того или иного объекта, также обучается. В итоге получается, что сеть “концентрируется” на том, чтобы различать самые трудноотделимые классы.
Эксперименты на MNIST, CIFAR и подмножествах Imagenet показывают, что DropMax работает лучше как стандартного SoftMax, так и ряда его модификаций.
Accurate Intelligible Models with Pairwise Interactions
(Friends Don’t Let Friends Deploy Black-Box Models: The Importance of Intelligibility in Machine Learning)
Abstract: http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdf
Код: его нет. Мне очень интересно, как в голове у авторов вяжется такое слегка императивное название с отсутствием кода. Академики, сэр =)
Можно посмотреть на этот пакет, например: https://github.com/dswah/pyGAM. В него не так давно добавили feature interactions (что собственно отличает GAM от GA2M).
Эта статья представлялась в рамках воркшопа “Interpretability and Robustness in Audio, Speech, and Language”, хотя посвящена интерпретируемости моделей в целом, а не области анализа звука и речи.Наверное, все в какой-то степени сталкивались с дилеммой выбора между интерпретируемостью модели и ее точности. Если мы используем обычную линейную регрессию, впоследствии мы по коэффициентам можем понять, как каждая независимая переменная влияет на зависимую. Если же мы используем модели «черного ящика», например, градиентный бустинг без ограничений на сложность или глубокие нейронные сети, правильно настроенная модель на подходящих данных будет очень точной, но отследить и объяснить все закономерности, которые модель обнаружила в данных, будет проблематично. Соответственно, будет сложно и объяснить модель заказчику, и самим отследить, не выучила ли она что-то такое, что нам бы не хотелось. В таблице ниже приведены оценки относительной интерпретируемости и точности различных видов моделей.
Пример ситуации, когда плохая интерпретируемость модели связана с большими рисками: на одном из медицинских датасетов решалась задача прогнозирования вероятности пациента умереть от пневмонии. В данных обнаружилась следующая интересная закономерность: если у человека есть бронхиальная астма, то вероятность умереть от пневмонии ниже, чем у людей без этого заболевания. Когда исследователи обратились к практикующим врачам, выяснилось, что такая закономерность действительно есть, поскольку люди с астмой в случае пневмонии получают наиболее оперативную помощь и сильные лекарства. Если бы мы тренировали xgboost на этом датасете, скорее всего он уловил бы эту закономерность, и наша модель относила бы пациентов с астмой к группе низкого риска, и, соответственно, рекомендовала бы для них более низкий приоритет и интенсивность лечения.
Авторы статьи предлагают альтернативу, которая и интерпретируема, и точна одновременно — это GA2M, подвид обобщенных аддитивных моделей (Generalized additive models).
Классические GAM можно рассматривать, как дальнейшее обобщение GLM: модель представляет собой сумму, каждый член которой отражает влияние только одной независимой переменной на зависимую, но влияние выражается не одним весовым коэффициентом, как в GLM, а гладкой непараметрической функцией (как правило, используются кусочно заданные функции – сплайны или деревья небольшой глубины, в том числе «пни»). За счет этой особенности GAM могут моделировать более сложные отношения, чем простая линейная модель. С другой стороны, выученные зависимости (функции) можно визуализировать и проинтерпретировать.
Однако стандартные GAM все же часто не дотягивают по точности до алгоритмов «черного ящика». Чтобы это исправить, авторы статьи предлагают компромисс – добавить в уравнение модели, помимо функций одной переменной, небольшое количество функций двух переменных – тщательно отобранных пар, взаимодействие которых значимо для предсказания зависимой переменной. Таким образом получается GA2M.
Сначала строится стандартная GAM (без учета взаимодействия переменных), а затем пошагово добавляются пары переменных (в качестве целевой переменной используются остатки GAM). Для случая, когда переменных много и обновление модели после каждого шага вычислительно трудоемко, предлагается алгоритм ранжирования FAST, с помощью которого можно заранее отобрать потенциально полезные пары и избежать полного перебора.
Такой подход позволяет добиться качества, близкого к моделям неограниченной сложности. В таблице приведена доля ошибок генерализованных аддитивных моделей по сравнению со случайным лесом для решения задачи классификации на различных датасетах, и в большинстве случаев качество предсказания для GA2M c FAST и для случайных лесов значимо не отличается.
Хотел бы обратить внимание на особенности работ академиков, которые предлагают отправить в топку эти ваши бустинги и дип лернинги. Обратите внимание, что датасеты, на которых приводятся результаты содержат не более 20 тысяч объектов (все датасеты из репозитория UCI). Возникает естественный вопрос: неужели в 2018 году нет открытых датасетов нормального размера для подобных экспериментов. Можно ведь пойти дальше и сравниваться на датасете из 50 объектов — там есть шанс, что и константная модель не будет значимо отличаться от случайного леса.
Следующий момент — регуляризация. На большом количестве признаков очень легко переобучиться даже без интеракций. Авторы, возможно, считают, что этой проблемы не существует, а единственная проблема — это black-box модели. По крайней мере в статье о регуляризации не говорят нигде, хотя она, очевидно, необходима.
И последнее, про интерпретируемость. Даже линейные модели не интерпретируемы если у нас достаточно много признаков. Когда у вас 10 тысяч нормально распределенных весов (в случае использования L2-регуляризации это примерно так и будет), невозможно сказать, какие именно признаки ответственны за то, что predict_proba выдает 0.86. Для интерпретируемости мы хотим не просто линейную модель, а линейную модель со sparse весами. Казалось бы, этого можно добиться L1-регуляризацией, но здесь тоже не все так просто. Из набора сильно коррелированных фичей L1-регуляризация выберет одну практически случайно. Остальные получат вес 0, хотя, если одна из этих фичей обладает предсказательной способностью, другие явно не являются просто шумом. В плане интерпретации модели это может быть и ОК, в плане понимания взаимосвязи признаков и целевой переменной это очень плохо. То есть даже с линейными моделями не все так однозначно, подробнее об interpretable and credible models можно глянуть здесь.
Visualization for Machine Learning: UMAP
Absract
Код
В день тьюториалов одним из первых шло выступление “Visualization for Machine Learning” от Google Brain. В рамках тьюториала нам рассказали про историю визуализаций, начиная от создателя первых графиков, а также про разные особенности человеческого мозга и восприятия и техники, которые можно использовать, чтобы привлечь внимание к самому важному на картинке, пусть даже содержащей много мелких деталей – например, выделение формой, цветом, рамочкой и т.д., как на рисунке ниже. Я эту часть пропущу, но тут есть хороший обзор.
Лично мне больше всего была интересна тема визуализации многомерных датасетов, в частности подход Uniform Manifold Approximation and Projection (UMAP) – новый нелинейный метод снижения размерности. Предложен он был в феврале этого года, поэтому мало кто пока его использует, но выглядит многообещающе как в плане времени работы, так и в плане качества разделения классов в двухмерных визуализациях. Так, на разных датасетах по скорости работы UMAP опережает t-SNE и другие методы в 2-10 раз, причем чем больше размерность данных, тем больше отрыв в производительности:
Кроме этого, в отличие от t-SNE время работы UMAP почти не зависит от размерности нового пространства, в которое мы эмбеддим наш датасет (см. рис. ниже), что делает его подходящим инструментом для других задач (помимо визуализации) — в частности, для снижения размерности перед обучением модели.
При этом тестирование на различных датасетах показало, что для визуализации UMAP работает не хуже, а местами лучше t-SNE: например, на датасетах MNIST и Fashion MNIST классы лучше разделяются именно в варианте с UMAP:
Дополнительный плюс — удобная реализация: класс UMAP наследуется от классов sklearn, так что можно использовать его как обычный трансформер в sklearn pipeline. Кроме того, утверждается, что UMAP более интерпретируем, чем t-SNE, т.к. лучше сохраняет глобальную структуру данных.?
В будущем авторы планируют добавить поддержку semi-supervised обучения — то есть если у нас будут метки хотя бы для части объектов, мы можем построить UMAP с учетом этой информации.
А какие статьи понравились вам? Пишите комментарии, задавайте вопросы, мы обязательно на них ответим.