
Долгое время основной базой данных в RealtimeBoard был Redis. Мы хранили в нём всю основную информацию: данные о пользователях, аккаунтах, досках и т.д. Всё работало быстро, но мы столкнулись с рядом проблем.
Проблемы с Redis
- Зависимость от сетевой задержки. Сейчас в нашем облаке она составляет порядка 20 мск, но при её увеличении приложение начнёт работать очень медленно.
- Отсутствие индексов, которые нужны нам на уровне бизнес-логики. Их самостоятельная реализация может усложнить бизнес-логику и привести к неконсистентности данных.
- Сложность кода также усложняет обеспечение консистентности данных.
- Ресурсоёмкость запросов с выборками.
Эти проблемы вместе с ростом количества данных на серверах послужили причиной для миграции БД.
Постановка задачи
Решение о миграции принято. Следующий шаг — понять, какая из БД подойдёт для нашей модели данных.
Мы провели исследование, чтобы выбрать оптимальную БД для нас, и остановились на PostgreSQL. Наша модель данных хорошо ложится на реляционную БД: у PostgreSQL есть встроенные инструменты для обеспечения консистентности данных, есть тип JSONB и возможность индексации определенных полей в JSONB. Это нам подходит.
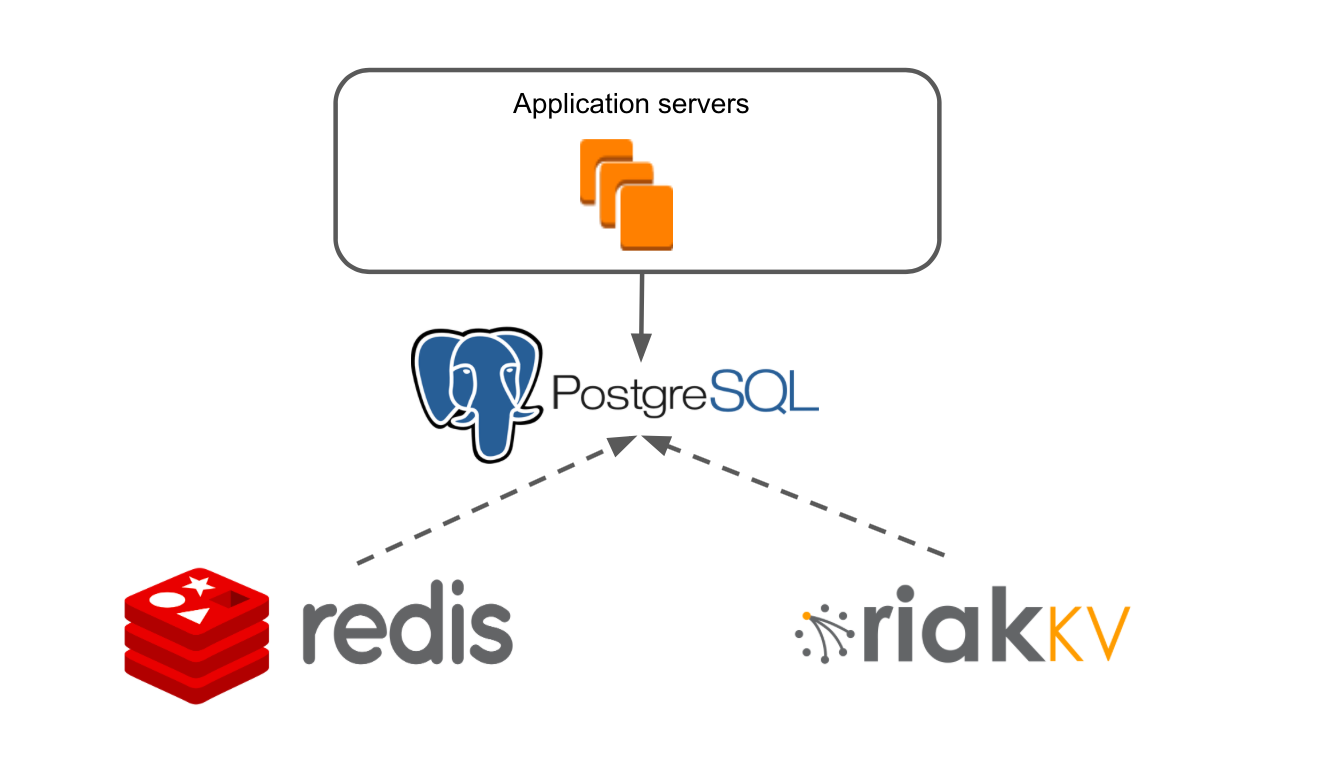
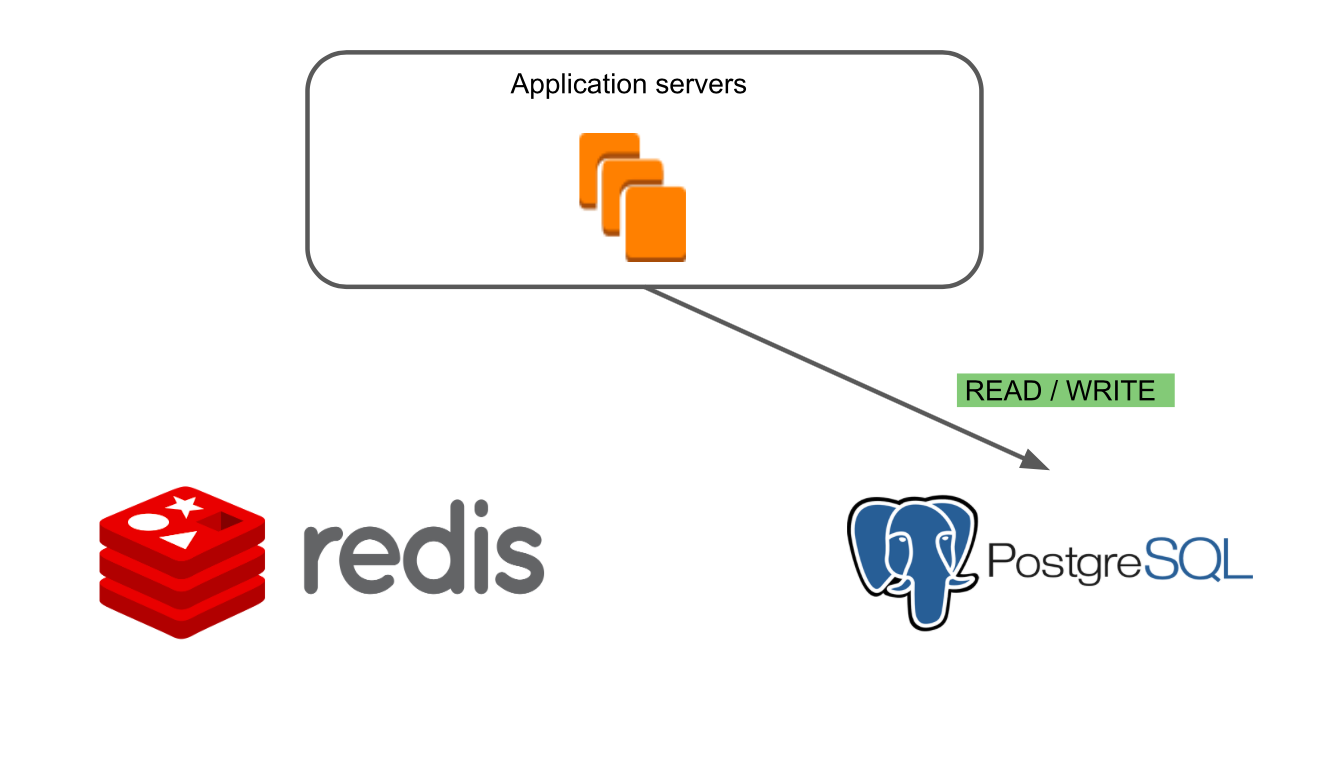
Упрощённо архитектура нашего приложения выглядела так: есть Application Servers, которые через слой работы с данными обращаются в Redis и RiakKV.
Наш Application Server — это монолитное Java-приложение. Бизнес-логика написана на фреймворке, который адаптирован под NoSQL. В приложении реализована своя транзакционная система, которая позволяет обеспечивать работу множества пользователей на любой из наших досок.
RiakKV мы использовали для хранения данных архивных досок, которые не открывались в течение 7 дней.
Добавляем в эту схему PostgreSQL. Делаем так, чтобы Application servers работали с новой базой данных. Копируем данные из Redis и RiakKV в PostgreSQL. Задача решена!
Ничего сложного, но есть нюансы:
- У нас 2,2 млн зарегистрированных пользователей. Ежедневно в RealtimeBoard работают 50 тысяч пользователей, пиковая нагрузка — до 14 тысяч одновременно. Пользователи не должны столкнуться с ошибками из-за наших работ, они вообще не должны заметить момент переезда на новую базу.
- 1 Тб данных в БД или 410 млн объектов.
- Непрерывный выпуск новых фич другими командами, чьей работе мы не должны мешать.
Варианты решения задачи
Перед нами стоял выбор из двух вариантов миграции данных:
- Остановить разработку сервиса > переписать код на сервере > протестировать функциональность > запустить новую версию.
- Провести плавную миграцию: постепенно переводить части продукта на новую базу данных, поддерживая одновременно PostgreSQL и Redis и не прерывая разработки новых фичей.
Остановка развития сервиса — это потеря времени, которое мы могли бы использовать для роста, а это значит — потеря пользователей и долей рынка. Для нас это критично, поэтому выбрали вариант с плавной миграцией. Несмотря на то, что по сложности этот процесс можно сравнить с заменой колёс на автомобиле во время движения.
При оценке работ мы разбили наш продукт на основные блоки: пользователи, аккаунты, доски и так далее. Отдельно вынесли работы по созданию инфраструктуры PostgreSQL. И заложили в оценку риски на случай, если что-то пойдёт не так (так оно и вышло).
Спринты и цели
Следующий шаг — построить работу команды из пяти человек так, чтобы все двигались с нужной скоростью к общей цели.
У нас есть две точки: начало работы над задачей и конечная цель. Идеально, когда мы движемся к цели прямым путем. Но часто случается, что мы хотим идти прямым путём, а получается так:
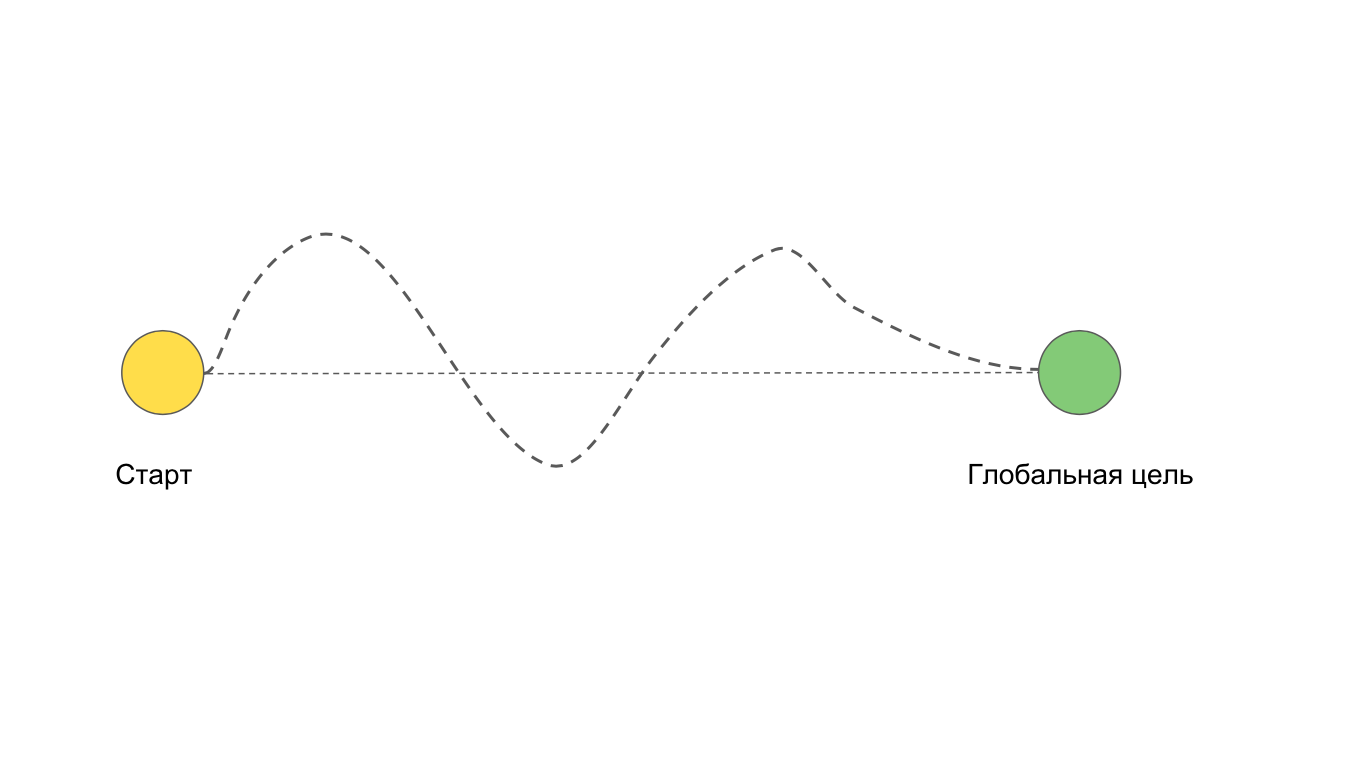
Например, из-за сложностей и проблем, которые не могли предусмотреть заранее.
Возможна ситуация, при которой мы вообще не придём к цели. Например, если уйдём в глубокий рефакторинг или переписывание всего приложения.
Мы разбили задачу на недельные спринты, чтобы минимизировать описанные выше сложности. Если вдруг команда уходит в сторону, она может быстро вернуться обратно с минимальными потерями для проекта, так как короткие итерации не позволяют уйти слишком далеко «не туда».
У каждой итерации есть своя цель, которая двигает команду к конечному большому результату.

Если во время спринта появляется новая задача, мы оцениваем, приближает ли нас к цели её выполнение. Да — берём в следующий спринт или меняем приоритеты в текущем, если нет — не берёмся за неё. Если появляются ошибки — ставим им высокий приоритет и быстро исправляем.
Бывает, что разработчики внутри спринта должны выполнять задачи в строго определённой последовательности. Или, например, разработчик передаёт готовую задачу QA-инженеру для срочного тестирования. На этапе планирования мы стараемся выстраивать подобные зависимости между задачами для каждого участника команды. Это позволяет всей команде видеть, кто, что и когда будет делать, не забывая про зависимость от других.
В команде есть ежедневные и еженедельные синхроны. Ежедневно по утрам мы обсуждаем, кто, что и в каком приоритете будет делать сегодня. После каждого спринта синхронизируемся друг с другом, чтобы быть уверенными, что все движутся в правильном направлении. Обязательно составляем план на крупные или сложные релизы. Назначаем дежурных разработчиков, которые, если нужно, присутствуют во время релиза и мониторят, что всё в порядке.
Планирование и синхронизация внутри команды позволяют вовлекать всех участников во все этапы работы над проектом. Планы и оценки не приходят к нам сверху, мы сами их составляем. Это увеличивает ответственность и заинтересованность команды в выполнении задач.
Так выглядит один из наших спринтов. Ведём всё на доске RealtimeBoard:

Режимы и безопасные эксперименты
Во время миграции мы должны были гарантировать стабильную работу сервиса в боевых условиях. Для этого нужно быть уверенными в том, что всё протестировано и нигде нет ошибок. Чтобы добиться этой цели, мы решили сделать нашу плавную миграцию ещё более плавной.
Идея заключалась в том, чтобы постепенно переключать блоки продукта на новую базу данных. Для этого мы придумали последовательность режимов.
В первом режиме “Redis Read/ Write” работает только старая база данных — Redis.

Во втором режиме “PostgreSQL Passive Write” мы можем убедиться, что запись в новую базу происходит корректно и базы консистентны.
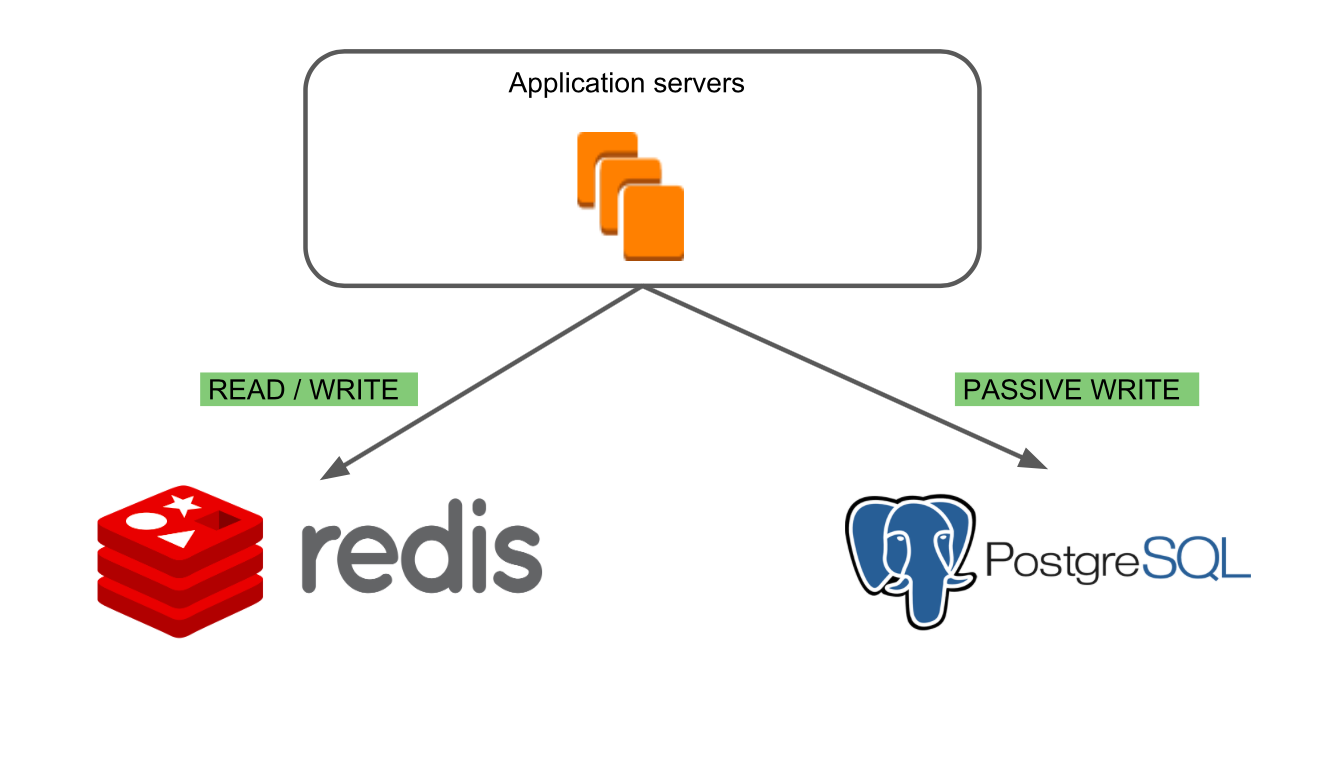
Третий режим “PostgreSQL Read/Write, Redis Passive Write” позволяет убедиться в корректности чтения данных из PostgreSQL и посмотреть, как ведёт себя новая БД в боевых условиях. Основной базой при этом остаётся Redis, что давало нам возможность находить специфичные случаи работы с досками, которые могли приводить к ошибкам.

В последнем режиме “PostgreSQL Read/ Write” работает только новая база данных.
Работы по миграции могли затронуть основные функции продукта, поэтому мы должны были быть на 100% уверены, что ничего не сломаем и новая база данных работает как минимум не медленнее, чем старая. Поэтому мы начали проводить безопасные эксперименты с переключением режимов.
Переключать режимы начали на нашем корпоративном аккаунте, который используем ежедневно в работе. После того, как мы убедились, что в нём ошибок нет, начали переключать режимы на небольшой выборке внешних пользователей.
Timeline запуска экспериментов с режимами получился такой:
- Январь-февраль: Redis read/write
- Март-апрель: PostgreSQL passive write
- Май-июнь: PostgreSQL read/write, основная база — Redis
- Июль-август: PostgreSQL read/write
- Сентябрь-декабрь: полная миграция.
При возникновении ошибок у нас была возможность быстро их исправлять, потому что мы сами могли делать релизы на серверы, где работали пользователи, участвующие в эксперименте. Мы никак не зависели от основного релиза, поэтому исправляли ошибки быстро и в любое время.
Кросс-командное взаимодействие
Во время миграции мы часто пересекались с командами, которые выпускали новые фичи. У нас единая code base, и в рамках своих работ команды могли изменять в новой БД существующие структуры или создавать новые. При этом могли происходить пересечения команд по разработке и выводу новых фич. Например, одна из продуктовых команд пообещала команде маркетинга выпустить новую фичу к конкретной дате; команда маркетинга запланировала рекламную кампанию на этот срок; команда продаж ждёт фичу и кампанию, чтобы начать общаться с новыми клиентами. Получается, все зависят друг от друга, и затягивание сроков одной командой срывает планы другой.
Чтобы избежать таких ситуаций, мы вместе с другими командами составили единый продуктовый roadmap, по которому синхронизировались несколько раз в квартал, а с некоторыми командами еженедельно.
Выводы
Чему мы научились за время этого проекта:
- Не бояться браться за сложные проекты. После декомпозиции, оценки и выработки подходов к работе сложные проекты перестают казаться невыполнимыми.
- Не жалеть времени и сил на предварительные оценки, декомпозицию и планирование. Это помогает глубже разобраться в задаче до того, как вы начнёте работу над ней, и понять объём и трудоёмкость работ.
- Закладывать риски в тяжелые технические и организационные проекты. В процессе работ вы обязательно встретитесь с проблемой, которая не была учтена при планировании.
- Не делать миграцию, если в этом нет необходимости.
В следующих статьях я подробнее расскажу о технических проблемах, которые мы решали во время миграции.
Комментарии (27)

gecube
28.01.2019 23:03+1Мы провели исследование, чтобы выбрать оптимальную БД для нас, и остановились на PostgreSQL. Наша модель данных хорошо ложиться на реляционную БД: у PostgreSQL есть встроенные инструменты для обеспечения консистентности данных, есть тип JSONB и возможность индексации определенных полей в JSONB. Это нам подходит.
во-первых — «ложиться». Режет глаз.
во-вторых, вы сами себе придумываете приключения. По сути — планируете использовать PostgreSQL как KV, но с дополнительными вторичными индексами. Очень интересно — чем же все-таки Riak не подошел. Или что-то посвежее. Вроде Couchbase, Cockroach etc.
Второе измерение — почему не RDS или managed инстансы? Сами все готовили?
И что там с шардированием-репликацией? Это же в Постгрес настраивать прямо боль, хотя вот коллеги из Zalando как-то справляются. И все-таки как обеспечивается целостность данных (понимаем, что транзакционность на уровне инстанса БД != транзакционность на уровне распределенной системы + особенности хранения/передачи/синхронизации данных).
batyrmastyr
29.01.2019 09:07И что там с шардированием-репликацией? Это же в Постгрес настраивать прямо боль
Намного больнее блокировки кластера «обычно, не более чем на 12 секунд» при падении мастера у Монги?

stvlasov Автор
30.01.2019 09:09+1Мы выбирали между RDS и своими инстансами EC2 в AWS, посчитали, что для нас выгоднее свои инстансы. Готовили сами.
Для шардирования рассматривали несколько вариантов (citus, pg_shardman, etc) — везде были проблемы. В итоге остановились на шардировании на стороне серверного приложения. Т.е. приложение знает с какой базой работать. Об этом напишу подробней в следующих частях.
slonpts
29.01.2019 01:4810 лет назад все переезжали с Sql на NoSql.
Это уже третья статья на хабре про миграцию с NoSQL на SQL. Предыдущие две:
Mongo => Postgres, 14 марта 2015 года — habr.com/ru/post/253075
Mongo => Postgres, 17 января 2019 — habr.com/ru/company/itsumma/blog/436416
Кажется, это новый тренд — переезд с NoSql на Sql.
Ждать ли через 10 лет тренд «все срочно переезжаем с SQL на NnnSql»?KamAdm
29.01.2019 07:52Не, наверное на что-то гибридное или какие не будь нейробазы с менеджером в виде нейросети, которая будет вспоминать данные.
batyrmastyr
29.01.2019 08:49Мы тоже так делали. Сначала перевели часть проектов с MySQL 5.5 на Монгу, выяснили, что у неё тоже проблем хватает. Тут подоспел Postgres 9.4 с нормальной поддержкой JSON и обнаружилось, что из десятка наших проектов только в двух Монга работала лучше, во всех остальных она с треском проигрывала Постгресу.
gecube
29.01.2019 09:10Т.е. Вы умеете уже готовить Постгрес и Вас не пугают особенности его работы?
Вот, например, парни из TimeScaleDB сделали из Постгресса что-то типа TSDB (а-ля Influx, VictoriaMetrics, Prometheus LevelDB etc.). Результат — к эксплуатации практически не пригодно (это вообще нормально, когда индексы по объему == кол-ву данных?). Я уж не говорю про всякие «радости» типа вакуума (и пускай весь мир подождет).
DISCLAIMER: я не спец по постгресу, просто мимо проходил.batyrmastyr
30.01.2019 11:50+2не пугают особенности его работы
Пугать — не пугают, но у нас с ним проблем, чем с Мускулем и Монгой. В одном проекте он даже Сфинкса наполовину «выдавил».
Пока из особенностей словили только ненависть к длинным транзакциям и неожиданное (после мускуля и монги) целочисленное деление, что-то с UPSERT. Но многие вещи даже не опробованы — то же секционированием с «шардированием» через postgres_fdw.
С вакуумом проблем пока не было, даже со стандартными настройками, но каждое второе руководство по настройке советует делать задачи вакуума менее объёмными, чтобы мир не ждал.
к эксплуатации практически не пригодно
Только сейчас узнал, что TimeScaleDB — расширение Постгреса )
Всякое возможно: DNSFilter перешли с InfluxDB на TimeScaleDB и довольны.
Впрочем, кое-кто из разрабов ClickHouse с вами согласен и утверждает, что и TimeScaleDB, и InfluxDB «просто недоработаны, и ими стыдно пользоваться».
Возможно вы что-то не то сделали (мы вот не нашли нужны нужной «ручки» у монги, чтобы count(*) по скромным 14 гигам журналов не минуту тупил, а админам у моего друга это удалось, жаль не знаю как), может TimeScaleDB уже исправил те проблемы, а ребятам из DNSFilter ещё только предстоит получить граблями по лбу.
индексы по объему == кол-ву данных
В первой версии SphinxSearch только индексы и хранил. Задача у него такая была.gecube
30.01.2019 14:07Всякое возможно: DNSFilter перешли с InfluxDB на TimeScaleDB и довольны.
а ребятам из DNSFilter ещё только предстоит получить граблями по лбу.
Выбор технологии — это же бизнесовая история. Может они все посчитали, всю экономику. И может оказалось, что недостатки несущественны, стоимость владения не столь велика, а преимущества (например, полноценный SQL и возможность обогащать данными JOIN'ами) перевешивают…
gecube
29.01.2019 09:16Самая кора, конечно — метания Uber между MySQL vs PostgreSQL
habr.com/ru/company/southbridge/blog/322624
habr.com/ru/company/devconf/blog/353682AlexeyVi
31.01.2019 15:35Собственно, вся суть метания была в архитектурном недостатке, о котором все успешно забыли или подумали что, ну блин все переходят на PostgreSQL. А недостатком оказался всем любимый автовакуум, ребята решили быстро и шустро читать с реплик, а не вышло)))
Либо обрыв запросов на реплике, так как на мастере автовакуум побежал уже по этим данным, либо если включен фидбэк на реплике, распухание мастера и возможное чтение устаревших данных.
И второе из-за «особенностей» работы автовакуума следует ждать большего кол-ва IOPS
MySQL этого лишен за счет UNDO log
ggo
29.01.2019 09:44я думаю, есть кейсы, в которых лучше sql.
есть кейсы в которых лучше nosql.
и соответственно есть варианты удачного использования нужной технологии, и неудачной.
мигрируют те, кому не повезло с выбором. и потому делятся своим опытом.gecube
29.01.2019 10:19Я думаю, что нужны какие-то гибридные варианты. Зачем сидеть на одной технологии, если можно взять лучшее сразу у нескольких?
stvlasov Автор
30.01.2019 09:18+1Согласен. Мы тоже совсем не отказываемся от Redis, в будущем будем его использовать, но не для всех данных.
jehy
Кажется, у вас в статье потерялся план про риак — о нём только в самом начале. Про миграцию с него было бы очень интересно прочитать.
stvlasov Автор
Данные из Riak мигрировали через уже существующий механизм на серверной стороне, который извлекал порцию «холодных» данных и помещал в Redis.
jehy
И с этим проблем не возникло? Один в один смигрировалось?
stvlasov Автор
Этот механизм «разархивации» из Riak уже был обкатан, он использовался на prod не один год, наша команда лишь оптимизировала его для большей производительности. Поэтому особых проблем не возникло. Также добавили дополнительные сервера «разархиваторы», которые вытаскивали данные из Riak параллельно.
Да, данные один в один. Но нам также приходилось фиксить неконсистентные данные, если мы такие находили.
jehy
А в паблике есть? Или может планирует выложить? Наверное, вы уже поняли, что у меня интерес не теоретический…
stvlasov Автор
В паблике сейчас нет, но уточню в ближайшее время сможем ли что-то выложить.