
Привет, Хабр! Меня зовут Сергей Лежнин, я старший архитектор в Сбертехе. Одно из направлений моей работы — Единая Фронтальная Система. В этой системе есть сервис управления параметрами конфигураций. Его использует множество пользователей, сервисов и приложений, что требует высокой производительности. В этом посте я расскажу, как этот сервис эволюционировал от первой, самой простой, до своей текущей версии и зачем мы в итоге развернули всю архитектуру на 180 градусов.

Вот с чего мы начали — это первая реализация сервиса управления параметрами:
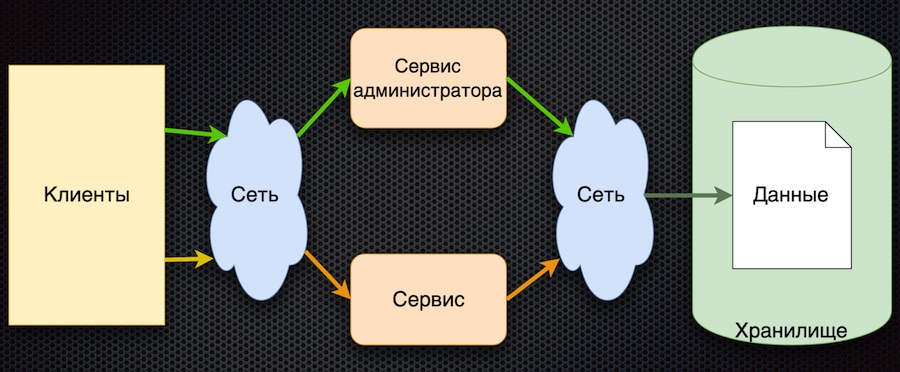
Клиент запрашивает параметры конфигурации у сервиса. Сервис транслирует запрос в базу данных, получает ответ и возвращает его клиенту. Параллельно с помощью своего отдельного сервиса параметрами могут управлять администраторы: добавлять новые значения, изменять текущие.
Преимущество у такого подхода одно — простота. Недостатков больше, хоть все они и связаны:
Чтобы пройти нагрузочное тестирование, эта архитектура должна была обеспечивать нагрузку не больше той, что идет через прямое обращение к базе данных. В итоге нагрузочное тестирование эта схема не прошла.
Второй этап: мы решили кэшировать данные на стороне сервиса.

Здесь данные при запросе изначально загружаются в общий кэш и при следующих запросах из кэша возвращаются. Сервис-администратор не только управляет данными, но и помечает их в кэше, чтобы при изменении они обновлялись.
Так мы уменьшили число обращений к хранилищу. При этом синхронизация данных получилась простой, поскольку сервис администратора имеет доступ к кэшу в памяти и управляет сбросом параметров. С другой стороны, если случится сетевой сбой, клиент не сможет получить данные. И в целом логика получения данных усложняется: если данных нет в кэше, нужно получить их из базы, положить в кэш и только потом вернуть. Нужно развивать дальше.
Третий этап развития — кэширование данных на стороне клиента:
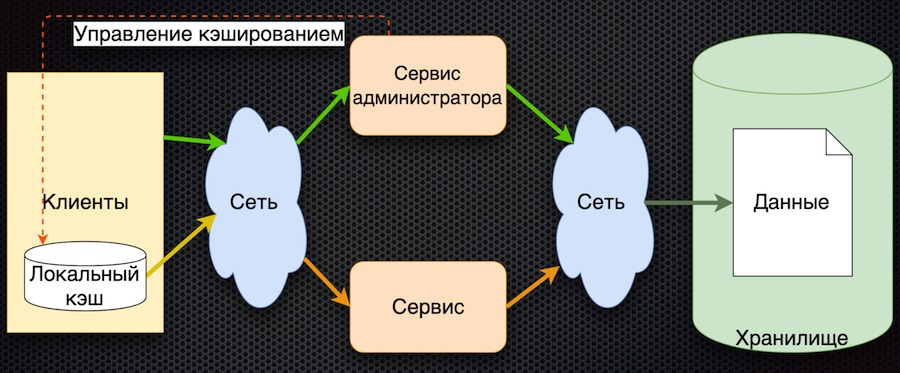
У клиента есть оболочка для доступа к сервису («клиентский модуль»), за которой скрывается локальный кэш данных. Если при запросе нужных данных в кэше не оказывается, идет обращение к сервису. Сервис запрашивает параметры из базы данных и возвращает их. По сравнению с предыдущей схемой здесь усложняется управление кэшированием. Чтобы сбросить параметры, сервис должен оповестить клиентов о том, что произошло изменение этих параметров.
В такой архитектуре мы уменьшаем количество обращений к сервису и к базе данных. Теперь если параметр уже запрошен, он вернется к клиенту без обращений по сети, даже если сервис или база данных недоступны. С другой стороны, большой минус в том, что усложняется логика обмена данных с клиентом, приходится его дополнительно уведомлять через какой-то сервис — например message queue. Клиент должен подписаться на топик, ему приходят уведомления об изменении параметров, и у себя в кэше клиент должен их сбросить, чтобы получить новые значения. Довольно сложная схема.
Наконец, мы подошли к последнему на данный момент этапу. В этом нам помогли основные принципы, сформулированные в Reactive Manifesto.
Схема, соответствующая этому подходу, получилась довольно простой:
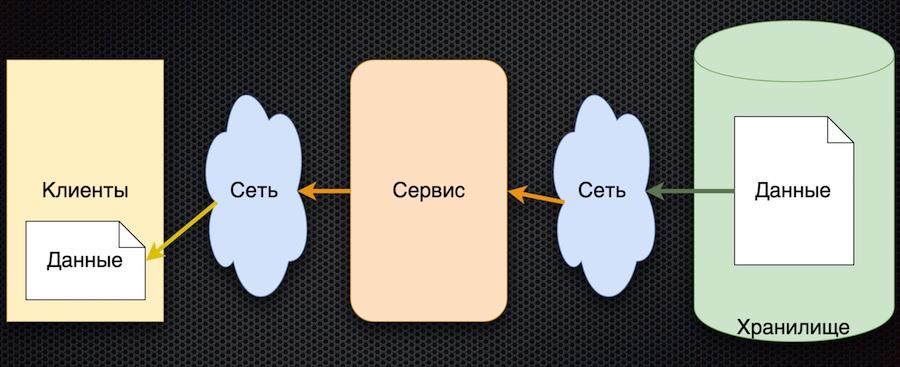
Общий принцип таков: клиент подписывается на конфигурационный параметр, и при изменении его значений сервер уведомляет клиента об этом. Схема выше немного упрощена: в ней не отражено, что когда клиент подписывается, ему нужно инициализировать и получить начальное значение. Но зато в ней есть главное: стрелки поменяли направление. Раньше клиент или кэш активно запрашивал сервис на предмет изменения данных, а теперь сервис сам передает события об изменении данных, и они обновляются у клиента.
У этой архитектуры есть несколько важных преимуществ. Количество обращений к сервису и хранилищу уменьшается, потому что клиент активно его не запрашивает. Фактически обращение для каждого нужного параметра происходит только один раз, при оформлении подписки на него. Затем клиент уже просто получает поток изменений. Доступность данных увеличивается, потому что у клиента всегда есть значение — оно кэшируется. Да и в целом эта схема обмена параметрами довольно проста.
Единственный недостаток такой архитектуры — неопределенность при инициализации данных. До тех пор, пока не было первого обновления по подписке, значение параметра остается неопределенным. Но это можно решить, установив у клиента дефолтные значения параметров, которые заменяются актуальными при первом обновлении.
Утвердив схему, мы начали поиск продуктов для ее реализации. Выбирали между Vertx.io, Akka.io и Spring Boot.

В таблице сведены интересовавшие нас характеристики. У Vertx и Akka есть акторы, а у Sping Boot есть библиотека микросервисов, которая по сути близка акторам. Аналогично и с реактивностью: Spring Boot имеет свою библиотеку WebFlux, реализующую те же возможности. Легковесность мы оценивали приблизительно, в пределах таблицы. Что касается языков, то из трех вариантов полиглотом считается Vertx: он поддерживает и Java, и Scala, и Kotlin, и JavaScript. У Akka есть Scala и Java; Kotlin, наверно, тоже можно использовать, но прямой поддержки нет. У Spring — Java, Kotlin и Groovy.
В итоге победил Vertx. Про него, кстати, много говорили на конференции JUG, да и вообще его использует много компаний. Вот скриншот с сайта разработчика:

На Vertx.io схема реализации нашего решения такова:

Параметры мы решили хранить не в базе данных, а в Git-репозитории. Мы вполне можем использовать этот сравнительно медленный источник данных за счет того, что клиент не запрашивает параметры активно и число обращений уменьшается.
Читатель (verticle) читает данные из Git-репозитория в память приложения для ускорения доступа пользователя к данным. Это важно, например, при подписке на параметры. Кроме того, читатель обрабатывает обновления — перечитывает и помечает данные, замещает старые данные новыми.
Event Bus — это сервис Vertx, который посылает события между вертиклами, а также наружу, через мосты. В том числе и через websocket-бридж, который используется в данном случае. Когда приходят события изменений параметров, Event Bus отсылает их клиенту.
Наконец, со стороны клиента здесь реализован простенький веб-клиент, который подписывается на события (изменения параметров) и отображает эти изменения на страницах.
Покажем, как все работает, через веб-приложение.
Запускаем в браузере страницу приложения. Подписываемся на изменения данных по ключу. Затем заходим на страницу проекта в локальном GitLab, изменяем данные в формате JSON и сохраняем их в репозиторий. В приложении отображается соответствующее изменение, что нам и требовалось.
На этом все. Исходный код демонстрации вы можете найти в моем git-репозитории, а вопросы задать в комментариях.
Вот с чего мы начали — это первая реализация сервиса управления параметрами:
Клиент запрашивает параметры конфигурации у сервиса. Сервис транслирует запрос в базу данных, получает ответ и возвращает его клиенту. Параллельно с помощью своего отдельного сервиса параметрами могут управлять администраторы: добавлять новые значения, изменять текущие.
Преимущество у такого подхода одно — простота. Недостатков больше, хоть все они и связаны:
- частое обращение к хранилищу по сети,
- высокая конкуренция доступа к базе данных (она у нас расположена на одном узле),
- недостаточная производительность.
Чтобы пройти нагрузочное тестирование, эта архитектура должна была обеспечивать нагрузку не больше той, что идет через прямое обращение к базе данных. В итоге нагрузочное тестирование эта схема не прошла.
Второй этап: мы решили кэшировать данные на стороне сервиса.
Здесь данные при запросе изначально загружаются в общий кэш и при следующих запросах из кэша возвращаются. Сервис-администратор не только управляет данными, но и помечает их в кэше, чтобы при изменении они обновлялись.
Так мы уменьшили число обращений к хранилищу. При этом синхронизация данных получилась простой, поскольку сервис администратора имеет доступ к кэшу в памяти и управляет сбросом параметров. С другой стороны, если случится сетевой сбой, клиент не сможет получить данные. И в целом логика получения данных усложняется: если данных нет в кэше, нужно получить их из базы, положить в кэш и только потом вернуть. Нужно развивать дальше.
Третий этап развития — кэширование данных на стороне клиента:
У клиента есть оболочка для доступа к сервису («клиентский модуль»), за которой скрывается локальный кэш данных. Если при запросе нужных данных в кэше не оказывается, идет обращение к сервису. Сервис запрашивает параметры из базы данных и возвращает их. По сравнению с предыдущей схемой здесь усложняется управление кэшированием. Чтобы сбросить параметры, сервис должен оповестить клиентов о том, что произошло изменение этих параметров.
В такой архитектуре мы уменьшаем количество обращений к сервису и к базе данных. Теперь если параметр уже запрошен, он вернется к клиенту без обращений по сети, даже если сервис или база данных недоступны. С другой стороны, большой минус в том, что усложняется логика обмена данных с клиентом, приходится его дополнительно уведомлять через какой-то сервис — например message queue. Клиент должен подписаться на топик, ему приходят уведомления об изменении параметров, и у себя в кэше клиент должен их сбросить, чтобы получить новые значения. Довольно сложная схема.
Наконец, мы подошли к последнему на данный момент этапу. В этом нам помогли основные принципы, сформулированные в Reactive Manifesto.
- Responsive: система отвечает настолько быстро, насколько возможно.
- Resilient: система продолжает отвечать даже в случае сбоя.
- Elastic: система использует ресурсы в соответствии с нагрузкой.
- Message Driven: предусмотрена асинхронность и свободный обмен сообщениями между компонентами системы.
Схема, соответствующая этому подходу, получилась довольно простой:
Общий принцип таков: клиент подписывается на конфигурационный параметр, и при изменении его значений сервер уведомляет клиента об этом. Схема выше немного упрощена: в ней не отражено, что когда клиент подписывается, ему нужно инициализировать и получить начальное значение. Но зато в ней есть главное: стрелки поменяли направление. Раньше клиент или кэш активно запрашивал сервис на предмет изменения данных, а теперь сервис сам передает события об изменении данных, и они обновляются у клиента.
У этой архитектуры есть несколько важных преимуществ. Количество обращений к сервису и хранилищу уменьшается, потому что клиент активно его не запрашивает. Фактически обращение для каждого нужного параметра происходит только один раз, при оформлении подписки на него. Затем клиент уже просто получает поток изменений. Доступность данных увеличивается, потому что у клиента всегда есть значение — оно кэшируется. Да и в целом эта схема обмена параметрами довольно проста.
Единственный недостаток такой архитектуры — неопределенность при инициализации данных. До тех пор, пока не было первого обновления по подписке, значение параметра остается неопределенным. Но это можно решить, установив у клиента дефолтные значения параметров, которые заменяются актуальными при первом обновлении.
Выбор технологии
Утвердив схему, мы начали поиск продуктов для ее реализации. Выбирали между Vertx.io, Akka.io и Spring Boot.
В таблице сведены интересовавшие нас характеристики. У Vertx и Akka есть акторы, а у Sping Boot есть библиотека микросервисов, которая по сути близка акторам. Аналогично и с реактивностью: Spring Boot имеет свою библиотеку WebFlux, реализующую те же возможности. Легковесность мы оценивали приблизительно, в пределах таблицы. Что касается языков, то из трех вариантов полиглотом считается Vertx: он поддерживает и Java, и Scala, и Kotlin, и JavaScript. У Akka есть Scala и Java; Kotlin, наверно, тоже можно использовать, но прямой поддержки нет. У Spring — Java, Kotlin и Groovy.
В итоге победил Vertx. Про него, кстати, много говорили на конференции JUG, да и вообще его использует много компаний. Вот скриншот с сайта разработчика:
На Vertx.io схема реализации нашего решения такова:
Параметры мы решили хранить не в базе данных, а в Git-репозитории. Мы вполне можем использовать этот сравнительно медленный источник данных за счет того, что клиент не запрашивает параметры активно и число обращений уменьшается.
Читатель (verticle) читает данные из Git-репозитория в память приложения для ускорения доступа пользователя к данным. Это важно, например, при подписке на параметры. Кроме того, читатель обрабатывает обновления — перечитывает и помечает данные, замещает старые данные новыми.
Event Bus — это сервис Vertx, который посылает события между вертиклами, а также наружу, через мосты. В том числе и через websocket-бридж, который используется в данном случае. Когда приходят события изменений параметров, Event Bus отсылает их клиенту.
Наконец, со стороны клиента здесь реализован простенький веб-клиент, который подписывается на события (изменения параметров) и отображает эти изменения на страницах.
Как все работает
Покажем, как все работает, через веб-приложение.
Запускаем в браузере страницу приложения. Подписываемся на изменения данных по ключу. Затем заходим на страницу проекта в локальном GitLab, изменяем данные в формате JSON и сохраняем их в репозиторий. В приложении отображается соответствующее изменение, что нам и требовалось.
На этом все. Исходный код демонстрации вы можете найти в моем git-репозитории, а вопросы задать в комментариях.
zam0th
Сергей, вы находитесь в четвертой итерации подсистемы управления параметрами в составе платформы ЕФС. Вы понятия не имеете, как на самом деле «этот сервис эволюционировал», а всего лишь сделали то, что в ней было еще в 2015 году, причем намного хуже (вертекс, акка, реактив, хранение в гите, вы серьезно?).
Были нагрузочные тесты, статистические исследования производительности, а у вас? Где метрики, где статистики? Что именно и как вы «разгоняли»? Взяли сравнили три совершенно не относящиеся к теме фреймворка и изобрели велосипед? Это позор и вам, и тем людям, кто пропустил эту статью.
monosoul
Илья, Вы уже больше двух лет как не работаете в СберТехе. Не думаю, что Вы имеете понятие о том, как за эти 2 года менялись требования к сервису, как и его реализация. Поверьте, нынешний СУП очень сильно отличается от того, что было 2-3 года назад.
Нагрузочное тестирование, как Вам, возможно, известно — один из обязательных этапов перед ПСИ, поэтому его не могли не проводить.
SLezhnin Автор
Учитывая, что я участвую в разработке сервиса с 2015 года, очень странно слышать от незнакомого человека то, в какой итерации мы сейчас находимся. А уж про эволюцию сервиса, тем более.
Я описал новую концепцию сервиса, которая находится в экспериментальном состоянии. Как только проведём нагрузочное тестирование, я выложу результаты и выводы.