
На днях мэр города Кэмпбелл, c русской фамилией Paul Resnikoff, разрезал ленточку при открытии нового офиса стартапа Wave Computing, который вместе с компанией Broadcom разрабатывает 7-нанометровый чип для ускорения вычислений нейросетей. Офис находится в здании исторической фруктово-консервной фабрики конца 19-начала 20 века, когда Кремниевая Долина представляла собой самый большой фруктовый сад в мире. Уже тогда в офисе занимались инновациями, вводили первые в абрикосово-сливовой индустрии электромоторы для конвейеров, за которыми трудились около 200 работников, в основном женщин.
На последующей за разрезанием ленточки парти засветилось много известных в индустрии людей, в частности соратник Кернигана-Ричи и автор самого популярного C компилятора конца 70-х — начала 80-х годов Стивен Джонсон, один из авторов стандарта чисел с плавающей точкой Джероми Кунен, изобретатель концепции локальной шины и разработчик чипсетов первых PC AT Диосдадо Банатао, бывшие разработчики процессоров Sun, DEC, Cyrix, Intel, AMD и Silicon Graphics, чипов Qualcomm, Xilinx и Cypress, индустриальные аналитики, девушка с красными волосами и другие обитатели калифорнийских компаний такого типа.
В конце поста мы поговорим, какие книжки нужно почитать и упражнения поделать, чтобы примкнуть к данному сообществу.
Начнем с Джероми Кунена, инноватора арифметики с плавающей точкой и менеджера Apple времен первого Макинтоша.
Не так часто встречаются кандидатские диссертации, которые затрагивают вычисления на миллиардах устройств. Именно таким стал дисер Джероми Кунена (слева) «Contributions to a Proposed Standard for Binary Floating Point Arithmetic», результаты которого вошли в IEEE Standard 754 чисел с плавающей точкой. После окончания аспирантуры Беркли в 1982 году Джероми пошел работать в Apple, где внедрил библиотеки вычислений с плавающей точкой в первый Макинтош.
После 10 лет менеджерства в Apple, Кунен консультировал Hewlett-Packard и Microsoft, а в 2000 году оптимизировал 128-битную арифметику для только появившейся 64-битной версии x86 от AMD. В последнее время Джероми обратил свое внимание на исследования по стандартам плавающей точки для нейросетей, в частности споры про Unum и Posit. Unum — это новый предлагаемый стандарт, продвижением которого занимается ученый из Калтеха John Gustafson, автор шумящей сейчас книги The End of Error, «Конец Ошибки». Posit — это версия Unum-а, которую можно более эффективно (*), чем Unum, реализовать в аппаратуре.
(*) Более эффективно по комбинации параметров: тактовой частоте, количеству циклов на операцию, пропускной способности конвейера, относительной площади на кристалле и относительному энергопотреблению.

Картинки из статей (не от Джероми) Making floating point math highly efficient for AI hardware и
Beating Floating Point at its Own Game: Posit Arithmetic by John L. Gustafson and Isaac Yonemoto:

А вот на парти Стефен/Стив Джонсон — человек, на компиляторе которого язык программирования Си стал популярным. Первый компилятор Си написал Денис Ритчи, но компилятор Ричи был жестко привязан к архитектуре PDP-11. Стив Джонсон, основываясь на работах Алана Снайдера, написал в середине 1970-х годов компилятор Portable C Compiler (PCC), который было легко переделать для генерации кода для разных архитектур. При этом компилятор Джонсона работал быстро и был оптимизирующим. Как он этого достиг?
На входе PCC Стив Джонсон использовал LALR(1) парсер, сгенерированный программой YACC (Yet Another Compiler Compiler), автором которого был тоже Стив Джонсон. После этого задача компиляции сводилась к манипуляции с деревьями в рекурсивных фукциях и генерации кода по таблице шаблонов. Часть этих рекурсивных функций была машинно-независима, другая часть переписывалась людьми, которые переносили PCC на другую машину. Таблица шаблонов состояла из записей правил типа «если свободен регистр типа A и два регистра типа B, перестроить дерево в узел типа C и сгенерировать код с строкой D». Таблица была машинно-зависимой.
Из-за комбинации элегантности, гибкости и эффективности, компилятор PCC перенесли на более чем 200 архитектур — от PDP, VAX, IBM/370, x86 до советских БЭСМ-6 и Орбита 20-700 (бортового компьютера в ранних версиях МиГ-29). Согласно Денису Ритчи, практически каждый С компилятор начала 1980-х годов базировался на PCC. Из мира BSD Unix PCC был вытеснен как стандартно поставляемый компилятор только GNU GCC в 1994 году.
Кроме PCC и Yacc, Стив Джонсон также является автором исходной программы проверки программ Lint (см. напр. статью 1978 года). Названия программ Yacc и Lint с тех пор стали нарицательными. В 2000-е Стив переписал фронт-энд MATLAB и написал MLint. Сейчас Стив Джонсон занят задачей распараллеливания алгоритмов вычислений нейросетей на устройствах типа CGRA (Coarse-Grained Reconfigurable Architecture), с десятками тысяч процессорообразных элементов, которые перекидываются между собой тензорами через сеть из тоже десятков тысяч свитчей внутри массивного чипа с миллиардами транзисторов:

А вот с бокалом вина миллиардер Диосдадо Банатао, основатель Chips & Technologies, S3 Graphics и инвестор в Marvell. Если вы программировали IBM PC в 1985-1988 годах, когда они только появились в СССР, то вы можете знать, что внутри большинства AT-шек с графикой EGA и VGA стояли чипсеты от Chips & Technologies, которые выходили одновременно с IBM-овскими. Ранние чипсеты C&T дизайнил Банатао, который выучился на электронщика в Стенфорде, а до Стенфорда работал инженером в Боинге. В 1987 году компанию Chips & Technologies купил Интел.


Слева на снимке ниже — Джон Буржуин (John Bourgoin), президент MIPS Technologies времен максимального расцвета этой компании в 2000-х, когда чипы с ядрами MIPS стояли внутри большинства DVD-плейеров, цифровых фотокамер и телевизоров, с чипсетами от Zoran, Sigma Design, Realtek, Broadcom и других компаний. До этого Джон был с 1996 года президентом отделения MIPS Silicon Graphics, когда процессоры MIPS стояли внутри рабочих станций Silicon Graphics, которые использовались в Голливуде для съемки первых реалистичных 3D фильмов «Парк Юрского Периода». До Silicon Graphics Джон был одним из вице-президентов AMD, еще с 1976 года.
Арт Свифт, справа, был вице-президентом маркетинга MIPS в 2000-е, а до этого в 1980-е работал инженером в Fairchild Semiconductor (да, том самом), потом вице-президентом по маркетингу в Sun, DEC, Cirrus Logic, и президентом компании Трансмета. В последнее время Арт был вице-председателем комитета по маркетингу RISC-V и знаком на этой позиции с российскими компаниями Syntacore и CloudBear. А сейчас стал президентом направления MIPS IP компании Wave:

Слайды из презентации по истории MIPS, относящиеся к периоду, когда MIPS-ом управлял Джон Буржуин (John Bourgoin), на снимке выше слева:

Компания Трансмета, президентом которой был некоторое время Арт Свифт, на снимке выше справа, в конце 1990-х выпустила процессор Крузо (Crusoe), который мог выполнять инструкции x86 и дошел до рынка в суб-ноутбуках Toshiba Libretto L, ноутах от NEC и Sharp, тонком клиенте от Compaq. Их конкурентным преимуществом перед Интелом и AMD ставилось контролируемо низкое энергопотребление.
Прямая реализация и верификация полного набора x86 — это очень дорогое мероприятие, поэтому Трансмета пошла другим путем, который напоминает путь российской компании МЦСТ с процессором Эльбрус (линии, которая началась с Эльбруса 2000 и сейчас представлена в виде Эльбрус 8С). Трансмета и Эльбрус в качестве основы ставили структурно простой процессор с микроархитекторой VLIW, а поверх него работал уровень эмуляции x86 с помощью технологии, которая у Трансметы называлась code morphing.
Идея VLIW (Very Long Instruction Word — Очень Длинное Слово Инструкции) довольно проста — несколько инструкций процессора в явном виде объявляются одной суперинструкцией и выполняются параллельно. В отличие от суперскалярных процессоров, в частности интелов начиная с PentiumPro (1996), в которых процессор делает выборку нескольких инструкций из памяти, и потом сам решает, что выполнять паралельно, а что последовательно, на основе автоматического анализа зависимостей между инструкциями.
Суперскалярный процессор гораздо сложнее VLIW, потому что суперскаляру приходится тратить логику на поддерживание иллюзии у программиста, что все выбранные инструкции выполняются одна за другой, хотя реально их может находится внутри процессора десятки, на разных стадиях выполнения. В случае VLIW бремя поддержания такой иллюзии ложится на компилятор с языка высокого уровня. В конечном итоге схема VLIW ломается, когда процессору приходится работать с многоуровневой кэш-памятью, у которой непредсказуемые задержки, которые приводят к тому, что компилятору становится трудно планировать инструкции по тактам. Но для математических вычислений (например поставить Эльбрус на радар и вычислять движение цели) это самое то, особенно в условиях дефицита квалифицированных инженерных кадров (для верификации суперскаляра нужно больше людей).
Иллюстрация идеи VLIW, процессор Крузо и суб-ноут Toshiba Libretto L1:

А вот в центре на фото ниже Дерек Мейер, Derek Meyer, нынешний CEO Wave Computing. До Wave Дерек был CEO компании ARC, разработчика процессорных ядер ARC, которые используются в чипах для аудио. Эти ядра в свое время лицензировала в том числе и российская компания НИИМА Прогресс, которая потом лицензировала ядра MIPS и показывала чипы на их основе на выставке в Казанском Иннополисе. Дерек Мейер неоднократно ездил в Россию, в Санкт-Петербург, где находилась группа разработчиков компании Virage Logic. В 2009 году компания ARC купила компанию Virage Logic, а в 2010 году ARC поглотила компания Synopsys, главный производитель средств проектирования микросхем в мире.
Справа на фото — Сергей Вакуленко, который на заре карьеры стоял у истоков рунета, работал в кооперативе Демос и институте Курчатова, которые принесли интернет в СССР. Сейчас Сергей пишет cycle-accurate модель процессорного элемента Wave для вычислений нейросетей, а раньше написал instruction-accurate модели ядер MIPS, которые использовались для верификации процессорных ядер MIPS I6400 Samurai, I7200 Shaolin и других.

Вот Вадим Антонов и Сергей Вакуленко в 1990 году, с первым компьютером в СССР, подключенным к интернету:

А вот справа Larry Hudepohl (по русски пишется Хьюдепол?). Ларри начинал свою карьеру в Digital Equipment Corporation (DEC) как дизайнер процессоров для MicroVAX. Потом Ларри работал в небольшой компании Cyrix, которая в конце 1980-х бросила вызов Интелу и сделала FPU сопроцессор, который был совместим Intel 80387 и при этом был его на 50% быстрее. Потом Ларри проектировал чипы MIPS в Silicon Graphics. Когда MIPS Technologies отделилась от Silicon Graphics, Ларри вдвоем с Райаном Кинтером начали первый продукт независимого MIPS — MIPS 4K, который стал основой линейки, доминирующей в домашней электронике 2000-х (DVD-плееры, фотокамеры, цифровые телевизоры). Затем MIPS 5K полетел в космос — его использовало японское космическое агентство JAXA. Потом Ларри на должности VP Hardware Engineering руководил разработкой следующих линеек, а сейчас работает над новыми архитектурами Wave акселератора.

Японский космический корабль с гордым названием Хаябуса-2 («Сапсан-2»), который в прошлом году приземлился на поверхности астероида Рюгу, управляется процессором HR5000 на основе довольно давно лицензированного у MIPS Technologies процессорного ядра MIPS 5Kf.
Вот простой последовательный конвейер 64-битного процессорного ядра MIPS 5Kf из его даташита:

Справа на фото — Даррен Джонс, Darren Jones. Он был директором хардверного инжиниринга в MIPS заведовал разработкой сложных ядер, с аппаратной многопоточностью, и суперскаляров с внеочередным выполнением инструкций. Потом Даррен ушел в Xilinx, где занимался Xilinx Zynq — чипами, на которых стоит комбинация из ПЛИС и процессоров ARM. Сейчас Даррен стал вице-президентом инжиниринга в Wave.
В MIPS Даррен был лидером группы, члены которой потом пошли работать в Apple и Samsung. Дизайнерша Моника, которая ушла в Самсунг, однажды сказала мне фразу, которую я хорошо запомнил: «RTL design: a few simple principles and the rest is cheating» (разработка аппаратуры на уровне регистровых передач: несколько простых принципов, все остальное — мухлеж"). Канонический пример мухлежа это кэш (программа записала данные и прочитала, но в памяти это окажется только когда-нибудь потом), но это только очень частный случай того, что умела делать Моника.

Аппаратная многопоточность и внеочередной суперскаляр — это два разных подхода к повышению производительности процессора. Аппаратная многопоточность позволяет повысить пропускную способность без особого повышения энергопотребления, но с нетривиальным программированием. Суперскаляр позволяет выполнять однопоточные программы грубо говоря вдвое быстрее, но и тратит вдвое больше ватт. Но без ухищрений в программировании.
Аппаратную многопоточность наконец-то хорошо разъяснили в русской википедии, вот ее временная многопоточность (она реализована в MIPS interAptiv и MIPS I7200 Shaolin), а вот одновременная многопоточность (ее в 1990-е сделали в процессорах DEC Alpha, потом в SPARC, а потом в MIPS I6400 Samurai / I6500 Daimyo).
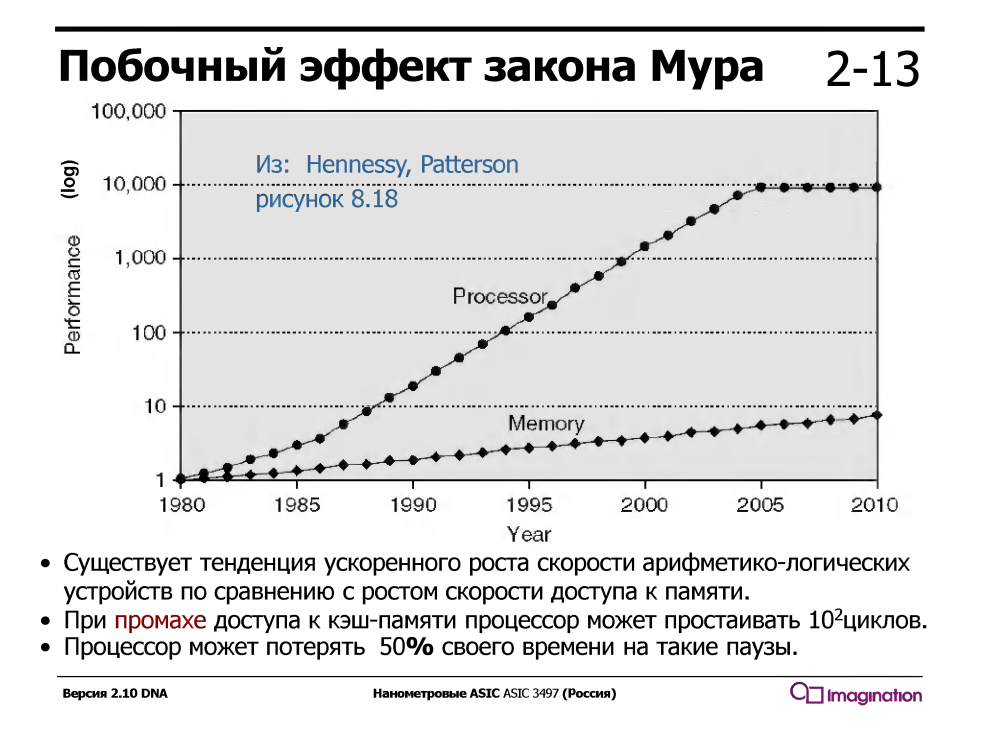
Временная многопоточность эксплуатирует тот факт, что процессор с обычным последовательным конвейером половину времени выполнения простаивает / ждет. Чего он ждет? Данные, которые через кэши идут из памяти. Причем ждет долго — за время ожидания одного промаха кэша процессор мог бы выполнить десятки или даже сотню-другую простых арифметических инструкций типа сложения.
Так было не всегда — в 1960-е годы арифметические устройства были гораздо медленнее, чем память. А вот с примерно 1980-го года скорость процессорных ядер росла гораздо быстрее, чем скорость памяти, и даже появление у процессоров многоуровневых кэшей решило проблему только частично.
Процессоры с временной многопоточностью поддерживают несколько наборов регистров, по одному для каждого потока, и когда текущий поток ждет данные из памяти во время промаха кэша, то процессор переключается на другой поток. Это происходит мгновенно, за цикл, без прерываний и тысячи циклов обработчика прерываний, который включается при программной (не аппаратной) многопоточности.
Вот идея многопоточности на слайдах с семинаров Чарльза Данчека, преподавателя из University of California Santa Cruz, Silicon Valley Extension. Почему на русском? Потому что Чарльз Данчек проводил лекции в московском МИСиС-е, после чего в питерском ИТМО и в киевском КПИ:


Интересно, что аппаратно-многопоточно можно программировать просто на Си. Вот как это выглядит:
#include "mips/m32c0.h"
#include "mips/mt.h"
#include "mips/mips34k.h"
// Это макро на Си использует GNUшные штучки,
// которые позволяют вставлять параметры прямо в ассемблируемый код.
// С помощью этого параметра поток (thread) будет знать свой ID.
// Обратите внимание на инструкцию FORK. Да, это одна 32-битная инструкция!
#define mips_mt_fork_and_pass_param(thread_function, param) __extension__ ({ void * __thread_function = (thread_function); unsigned __param = (param); __asm__ __volatile ( ".set push; .set mt; fork $4,%0,%z1; .set pop" : : "d" (__thread_function), "dJ" (__param) ); })
void thread (unsigned tc)
{
// Тут можно делать что-нибудь параллельное.
// Потоки могут обмениваться информацией
// через аппаратно-реализованные FIFO и общую память,
// а также синхронизироваться аппаратными семафорами.
}
int main ()
{
// Макросы чтобы поставить аппаратную многопоточность
for (tc = 0; tc < NUM_TCS; tc++)
{
mips32_setvpecontrol (VPECONTROL_TE | tc);
u = mips32_mt_gettcstatus ();
mips32_mt_settcstatus (u | TCSTATUS_DA);
mips32_mt_settchalt (0);
}
mips_mt_emt ();
// Запускаем восемь параллельных потоков выполнения, остаемся в девятом
for (int tc = 1; tc < NUM_TCS; tc ++)
mips_mt_fork_and_pass_param (thread, tc);
thread (0);
}
Вот сбоку на парти стоит устройство Wave для датацентров. Оно пока не вполне работает, хотя чипы доступны некоторым клиентам в рамках бета-программы:

Что это устройство делает? Вы умеете программировать на Питоне? Вот на Питоне можно построить с помощью вызовов библиотеки TensorFlow так называемый Data Flow Graph (DFG). Нейросети — это по-сути специализированные вот такие графы, с операциями над матрицами. В софтверной группе Wave, частью которой руководит Стив Джонсон, есть компилятор с подмножества представления гугловсого TensorFlow в конфигурационные файлы для чипов этого устройства. После конфигурации оно может делать вычисления таких графов очень быстро. Устройство предназначено для датацентров, но тот же принцип можно применить и к небольшим чипам, даже внутри мобильных устройств, например для распознавания лиц:

Chijioke Anyanwu (слева) — много лет является хранителем всей системы тестирования процессорных ядер MIPS. Baldwyn Chieh (в центре) — дизайнер нового поколения процессорообразных элементов в Wave. Раньше Балдвин был старшим дизайнером в Qualcomm. Вот слайды про устройство Wave с конференции HotChips:


В каждой нанометровой цифровой инновационной AI компании Кремниевой Долины должна быть своя девушка с яркими волосами. Вот такая девушка в Wave. Ее зовут Афина, она социолог по образованию, и занимается в офисе офисом:

А вот как выглядит офис снаружи, и его более чем вековая история со времен, когда он был инновационной консервной фабрикой:


А теперь вопрос: как разобраться в архитектуре, микроархитектуре, цифровой схемотехнике, принципах дизайна AI чипов и участвовать в таких парти? Самый простой способ — это проштудировать учебник «Цифровая схемотехника и архитектура компьютера» Дэвида Харриса и Сары Харрис, и пойти в Wave Computing на лето интерном (планируется нанять 15 практикантов на лето). Надеюсь, что это же можно делать и в российских микроэлектронных компаниях, которые заняты подобными разработками — ЭЛВИС, Миландр, Байкал Электроникс, IVA Technologies и ряда других. В Киеве это теоретически можно делать в сотрудничающей с КПИ компанией Melexis.
На днях вышла новая, окончательно исправленная версия учебника Харрис & Харрис, которая должна бесплатно лежать вот здесь www.mips.com/downloads/digital-design-and-computer-architecture-russian-edition-second-edition-ver3, но по-моему эта ссылка не работает, а когда заработает, я напишу про это отдельный пост. С вопросами, которые задают на интервью в Apple, Intel, AMD, и на каких страницах этого учебника (и других источников) можно посмотреть ответы.
Комментарии (14)

valemak
05.02.2019 22:01Стиль Ваших статей мне напоминает творчество Квентина Тарантино. Кинологи скрупулёзно подсчитывают сколько раз встретилось слово f**k в его фильмах, у Вас особым расположением пользуется местоимение вот.


mat300
06.02.2019 03:17Сдается мне Wave усилиями своих дедушек-основателей, смотрящих на технологии в зеркало заднего вида, полезла не в те дебри. Года через 3-4 эти все тяжеловорочающиеся ML/DL прибамбасы уйдут на помойку, и вэйвовские процессоры/прочие причендалы, также компания и немалые мани инвесторов — туда же.

YuriPanchul Автор
06.02.2019 03:22А что не пойдет на помойку? Тинейджеры напишут AI на ардуино?

MaM
06.02.2019 07:05Лучше писать под ардуино, чем под эльбрус, у первой хоть ISA открыта, да и не разрабатывались они на деньги налогоплательщиков. Олсо, с автором исходного комментария я не согласен, но объективно не могу не признать провалы итаниума. Последние пол года я активно (я довольно глупый) изучал теорию компиляции. То к чему я пришел выглядить довольно печально, текушие средства просто не годятся для оптимальной компиляции под VLIW. Как мне кажется перспективная область это aot компиляция с последуюшей интерпритаций. Опять же, мне как «тинейджеру» очень неприятно ваше отношение, мол молодняк не осиливает. Молодняк осиливает, включает голову и уходит от харды так далеко как только может. Опять же, скорей всего вы подразумеваете под ардуино экосистему, что конечно верно. Но никто не мешает взять загрузчик, программатор и записать туда что-то свое. В моем виденье ардуина вполне решает свои задачи, привлекая школьников и студентов младших курсов. И да, спасибо за перевод, мы с другом купили и прочитали.
YuriPanchul Автор
06.02.2019 19:57+1Вы зачислили меня в пропоненты VLIW? Это неожиданно.
Вероятно вы невнимательно прочитали мою статью, может просто просканировали ее глазами, выбрали ключевые слова (Эльбрус, нейросети, итаниум), а потом из них что-то додумали. У меня 1) нет вообще никакой привязки Эльбруса к нейросетям, 2) я явно написал про трудности компиляции VLIW и его ограчиненной сферы применения, с разъяснением почему.
*** Молодняк осиливает, включает голову и уходит от харды так далеко как только может. ***
Но где-то же хардвер кому-то нужно проектировать, правильно? Или микросхемы растут на дереве где-то на Альфа Центавра и их оттуда нужно импортировать и потом только программировать правильно?
*** Но никто не мешает взять загрузчик, программатор и записать туда что-то свое ***
Вы говорите про запись прошивки в микроконтроллер типа Ардуино? Прошивка ардуино — это та же программа, цепочка инструкций, она принципиально не может работать быстрее, чем специально спроектированный хардвер.
Или вы говорите про разработки на уровне регистровых передач и прошивку ПЛИС? Но это не ардуино и для этого используется такая же технология разработки на уровне регистровых передач, как и для специализированных микросхем.
*** В моем виденье ардуина вполне решает свои задачи, привлекая школьников и студентов младших курсов. ***
Где я написал, что она не решает свои задачи? Высокоскоростные вычисления нейросетей — это не ее задача, ни с какой прошивкой.
*** И да, спасибо за перевод, мы с другом купили и прочитали. ***
Спасибо
mat300
06.02.2019 20:34Я не о том. ML/DL уже вчерашний день. Просто пока не все знают. Но, вроде, спецы по камням должны держать нос по ветру.
Хотя в свете недавних инициатив по отсечению иностранцев и иностранного капитала от передовых технологий, возможно, Wave еще пару лет будет вообще не в курсах. Они же наверняка процы не в Штатах штампуют, следовательно идут лесом.YuriPanchul Автор
06.02.2019 20:38Я на уровне RTL (Register Transfer Level) спец. У нас тут узкая специализация. Что не вчерашний день, поясните. AI — это вообще циклическая вещь, у этого направления были спады и подъемы в 1950-е, 1970-е, 1980-е и вот в последнее время.
mat300
06.02.2019 22:41Я конкретно, о ML/DL. Не о AI. Но ребята то заточили чип под TensorFlow. А вот это уже вчерашний день. Уже есть куда более эффективный подход. Более подробно — ищите на сайтах научных рабoт. Good luck!
YuriPanchul Автор
06.02.2019 23:08Тут у нас пол-офиса ученые по ML, не только TensorFlow. Чип не заточен чисто под TensorFlow, это dataflow вычислитель общего назначения. Мы как раз сейчас планируем изменения микроархитектуры вычислителя. Вы бы не исторгали мутные фразы в стиле дельфийского оракула, а сказали по-человечески, если есть что сказать.

Wicron
06.02.2019 20:24+3Отличная статья с людьми, чей интеллект и есть фундамент новых компаний, который, к сожалению, по мере роста становится на видно. Но фотка 90 года с бутылкой на столе и первым подключенным компьютером в СССР к сети Интернет всё равно лучшая. Я думаю, очень многим интересен формат статей, где технологии — это люди.
lelik363
Какие планы у Wave Computing на ядро P5600?
YuriPanchul Автор
Продолжать лицензировать и поддерживать экосистему