
У нас Java с разными библиотеками на борту. Запускается всё вне контейнера, через Maven-плагин. В основе — платформа наших партнёров, которая позволяет работать с базой данных и потоками, управлять клиент-серверным взаимодействием и т.д. БД — Redis и PostgreSQL (мой коллега написал о том, как мы переезжаем с одной БД на другую).
С точки зрения бизнес-логики приложение содержит:
- работу с пользовательскими досками и их контентом;
- функционал по регистрации пользователя, созданию и управлению досками;
- генератор пользовательских ресурсов. Он, например, оптимизирует загруженные в приложение большие изображения, чтобы они не тормозили на наших клиентах;
- множество интеграций со сторонними сервисами.
В 2011 году, когда мы только начинали, весь RealtimeBoard находился на одном сервере. На нём было всё: Nginx, на котором крутился php для сайта, Java-приложение и базы данных.
Продукт развивался, росло количество пользователей и контента, который они добавляли на доски, поэтому нагрузка на сервер тоже росла. Из-за большого количества приложений на нашем сервере мы в тот момент не могли понять, что именно даёт нагрузку и, соответственно, не могли это оптимизировать.Чтобы это исправить, мы разнесли всё на разные сервера, и у нас появились веб-сервер, сервер с нашим приложением и сервер с базами данных.
К сожалению, через некоторое время проблемы снова возникли, так как нагрузка на приложение продолжала расти. Тогда мы задумались о том, как масштабировать инфраструктуру.

Дальше расскажу о сложностях, с которыми мы столкнулись при развитии кластеров и масштабировании Java-приложения и инфраструктуры.
Горизонтальное масштабирование инфраструктуры
Мы начали со сбора метрик: использование памяти и CPU, время выполнение пользовательских запросов, использование ресурсов системы, работа с базой. По метрикам было понятно, что генерация пользовательских ресурсов — процесс непредсказуемый. Мы можем нагрузить процессор на 100% и ждать десятки секунд, пока всё будет выполнено. Пользовательские запросы на доски тоже иногда давали непредвиденную нагрузку. Например, когда пользователь выделяет тысячу виджетов и начинает их стихийно перемещать.
Начали думать, как можно масштабировать эти части системы и пришли к очевидным решениям.
Масштабировать работу с досками и контентом. Открытие доски пользователем выглядит примерно так: пользователь открывает клиент > указывает, какую доску хочет открыть > подключается на сервер > на сервере создаётся поток > все пользователи этой доски подключаются к одному потоку > любое изменение или создание виджета происходит в рамках этого потока. Получается, вся работа с доской строго ограничена потоком, а значит мы можем разнести эти потоки между серверами.
Масштабировать генерацию пользовательских ресурсов. Мы можем вынести сервер для генерации ресурсов отдельно, и он будет получать сообщения на генерацию, а затем отвечать, что всё сгенерировано.
Кажется, всё просто. Но как только мы начали глубже исследовать эту тему, оказалось, что нам нужно дополнительно решить некоторые косвенные проблемы. Например, если у пользователей истекает платная подписка, то мы должны уведомить их об этом, на какой бы доске они ни находились. Или, если пользователь обновил версию ресурса, нужно позаботиться о том, чтобы кэш правильно сбросился на всех серверах и мы отдавали нужную версию.
Мы определили требования к системе. Следующий шаг — понять, как это осуществить на практике. По сути, нам была нужна система, которая позволяла бы общаться серверам в кластере между собой и и на основе которой мы бы реализовали все наши задумки.
Первый кластер из “коробки”
Первую версию системы мы не выбирали, потому что она уже была частично реализована в партнёрской платформе, которую мы использовали. В ней все сервера подключались друг к другу через ТСР, и мы с помощью этого соединения могли отправить RPC-сообщения одному или всем серверам сразу.
Например, у нас есть три сервера, они подключены друг к другу через ТСР, и в Redis у нас хранится список этих серверов. Мы запускаем в кластере новый сервер > он добавляет себя в список в Redis > считывает список, чтобы узнать о всех серверах в кластере > подключается ко всем.
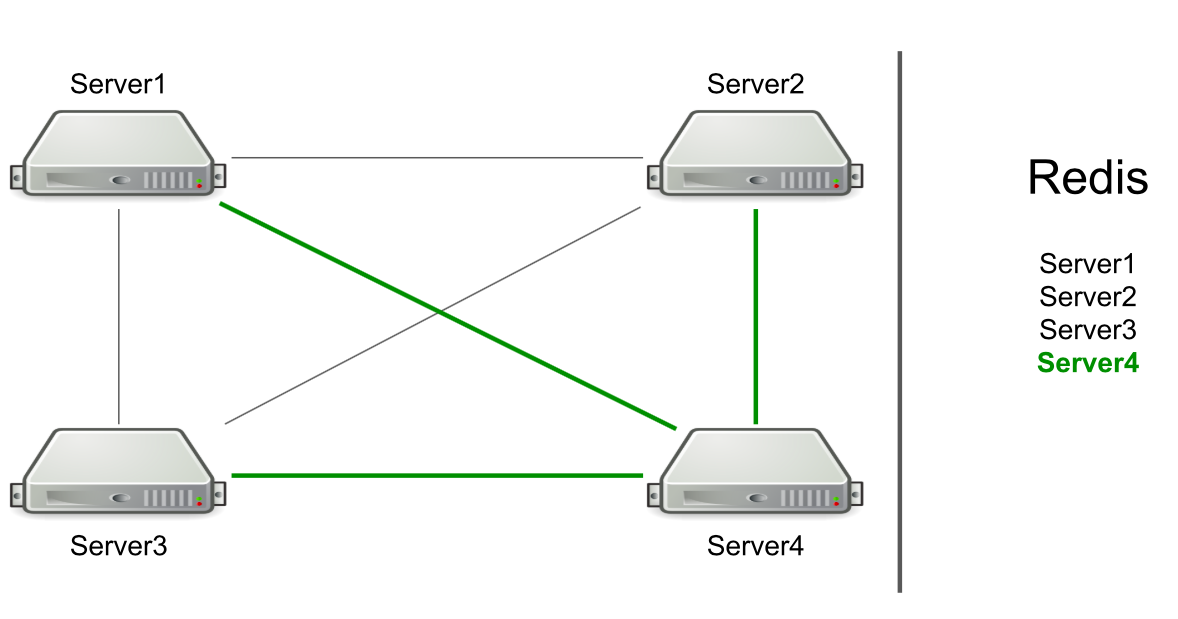
На основе RPC уже была реализована поддержка сброса кэша и перенаправление пользователей на нужный сервер. Нам оставалось сделать генерацию пользовательских ресурсов и уведомление пользователей о том, что что-то произошло (например, истёк аккаунт). Для генерации ресурсов мы выбирали произвольный сервер и отправляли ему запрос на генерацию, а для уведомлений об истечении подписки — отправляли команду всем серверам в надежде, что сообщение достигнет цели.
Сервер сам определяет, кому отправлять сообщение
Звучит как фича, а не как проблема. Но сервер ориентируется только на наличие соединения к другому серверу. Если есть соединения, значит есть кандидат на отправку сообщения.
Проблема в том, что сервер №1 не знает, что сервер №4 прямо сейчас находится под высокой нагрузкой и не может ответить ему достаточно быстро. В итоге запросы сервера №1 обрабатываются медленнее, чем могли бы.
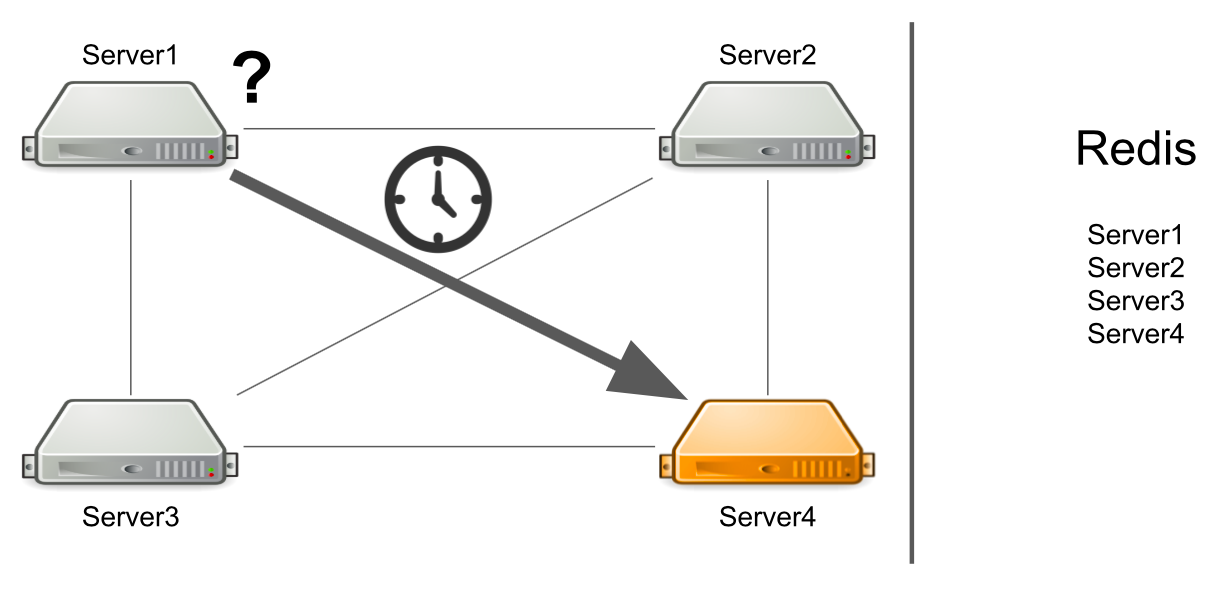
Сервер не знает о том, что второй сервер завис
А что если сервер не просто сильно нагружен, а вообще завис? Причём завис так, что уже больше не оживёт. Например, исчерпал всю доступную память.
В этом случае сервер №1 не знает, в чём проблема, поэтому продолжает ждать ответ. Остальные сервера в кластере тоже не знают про ситуацию с сервером №4, поэтому будут отправлять серверу №4 множество сообщений и ожидать ответа. Так будет до тех пор, пока сервер №4 не умрёт.
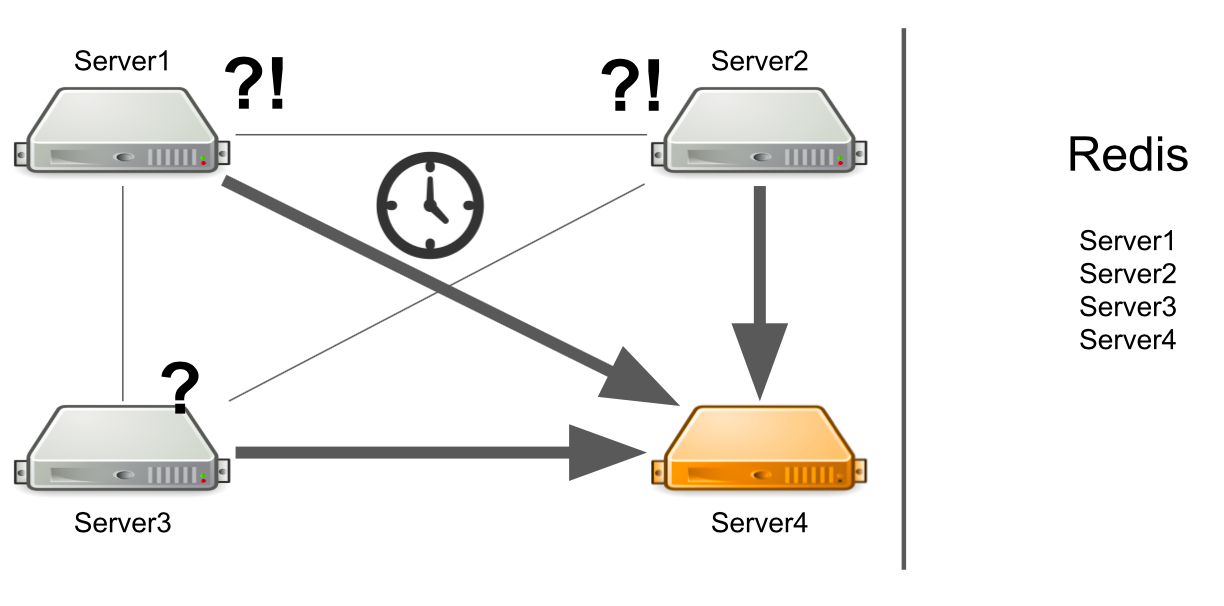
Что делать? Мы можем самостоятельно добавить в систему проверку состояния сервера. Или можем перенаправлять сообщения с “больных” серверов на “здоровые”. Всё это займёт слишком много времени разработчиков. В 2012 году у нас было мало опыта в этой сфере, поэтому мы начали искать готовые решения сразу всех наших проблем.
Message broker. ActiveMQ
Мы решили пойти в сторону Message broker, чтобы грамотно настроить общение между серверами. Выбрали ActiveMQ из-за возможности настраивать получение сообщения на consumer в определённое время. Правда, мы никогда не пользовались этой возможностью, поэтому могли выбрать RabbitMQ, например.
В итоге мы перевели всю нашу кластерную систему на ActiveMQ. Что это дало:
- Сервер больше не определяет сам, кому отправлять сообщение, потому что все сообщения идут через очередь.
- Настроена отказоустойчивость. Для чтения очереди можно запустить не один, а несколько серверов. Даже если один из них упадет, то система продолжит работать.
- У серверов появились роли, что позволило разделить сервера по типу нагрузки. Например, ресурсный генератор может подключиться только к очереди на чтение сообщений на генерацию ресурсов, а сервер с досками — на очередь открытия досок.
- Сделали RPC-общение, т.е. у каждого сервера появилась своя приватная очередь, куда другие сервера отправляют ему события.
- Можно отправлять всем серверам сообщения через Topic, который мы используем для сброса подписок.
Схема выглядит просто: к брокеру подключаются все сервера, а он управляет общением между ними. Всё работает, сообщения отправляются и принимаются, ресурсы создаются. Но появились новые проблемы.
Что делать, когда все нужные сервера лежат?
Допустим, сервер №3 хочет отправить сообщение на генерацию ресурсов в очередь. Он ждёт, что его сообщение будет обработано. Но не знает, что по какой-то причине нет ни одного получателя сообщения. Например, получатели вылетели из-за ошибки.
За всё время ожидания сервер отправляет множество сообщений с запросом, из-за чего появляется очередь из сообщений. Поэтому когда появляются рабочие сервера, они вынуждены сначала обработать накопившуюся очередь, что занимает время. На стороне пользователя это приводит к тому, что загружаемое им изображение не появляется сразу. Ждать он не готов, поэтому уходит с доски.
В итоге, мы тратим серверные мощности на генерацию ресурсов, а результат уже никому не нужен.
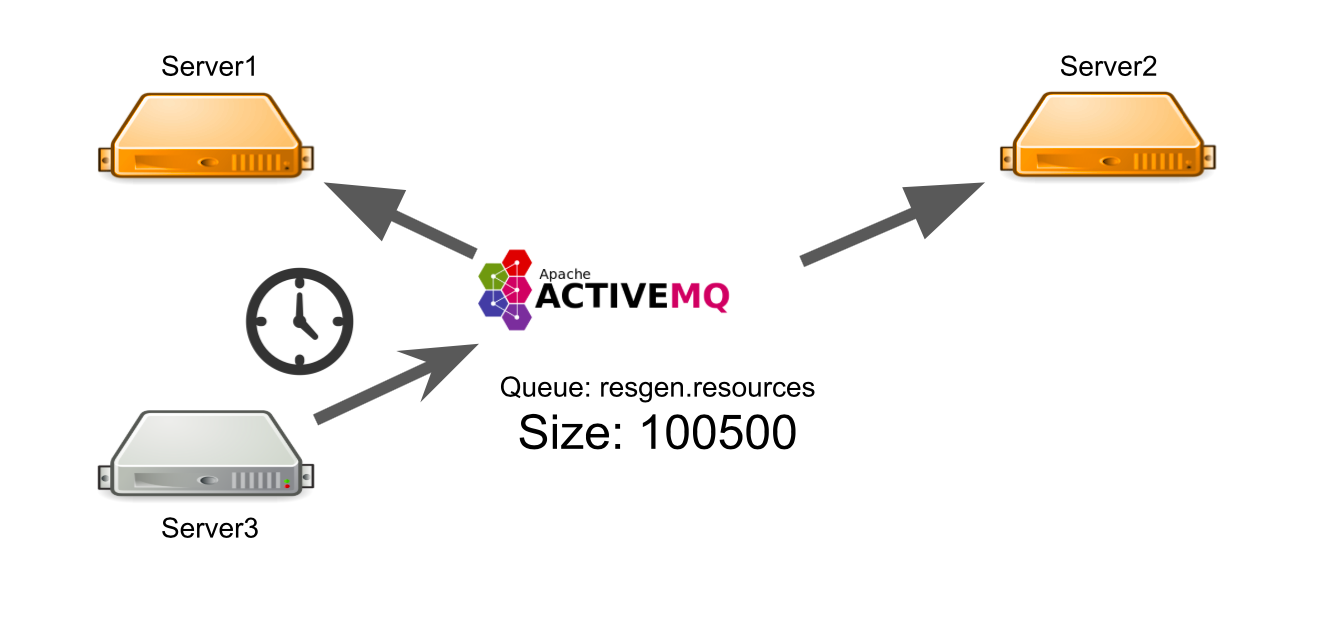
Как можно решить проблему? Мы можем настроить мониторинг, который будет уведомлять о том, что происходит. Но от момента, когда мониторинг что-то сообщит, до момента, когда мы поймём, что нашим серверам плохо, пройдёт время. Нас это не устраивает.
Другой вариант – запустить Service Discovery, или реестр сервисов, который будет знать, какие сервера с какими ролями запущены. В этом случае мы сразу получим сообщение об ошибке, если нет свободных серверов.
Часть сервисов не может горизонтально масштабироваться
Это проблема нашего раннего кода, а не ActiveMQ. Покажу на примере:
Permission ownerPermission = service.getOwnerPermission(board);
Permission permission = service.getPermission(board,user);
ownerPermission.setRole(EDITOR);
permission.setRole(OWNER);
У нас есть сервис по работе с правами пользователей на доске: пользователь может быть владельцем доски или её редактором. Владелец у доски может быть только один. Предположим, у нас есть сценарий, когда мы хотим передать владение доской от одного пользователя к другому. На первой строчке мы получаем текущего владельца доски, на второй — берём пользователя, который был редактором, а теперь станет владельцем. Дальше текущему владельцу мы ставим роль EDITOR, а бывшему редактору — роль OWNER.
Рассмотрим, как это будет работать в многопоточной среде. Когда первый поток будет устанавливать роль EDITOR, а второй поток попытается взять текущего OWNER, может получиться так — OWNER не существует, но есть два EDITOR.
Причина — в отсутствии синхронизации. Решить проблему мы можем с помощью добавления блока synchronize на доске.
synchronized (board) {
Permission ownerPermission = service.getOwnerPermission(board);
Permission permission = service.getPermission(board,user);
ownerPermission.setRole(EDITOR);
permission.setRole(OWNER);
}
Это решение не будет работать в кластере. Нам бы могла помочь в этом SQL база при помощи транзакций. Но у нас Redis.
Другое решение – добавить в кластер распределённые локи, чтобы синхронизация была внутри всего кластера, а не одного сервера.
Единая точка отказа при заходе на доски
Модель взаимодействия между клиентом и сервером у нас stateful. Значит мы должны хранить состояние доски на сервере. Поэтому мы сделали отдельную роль для серверов — BoardServer, которая занимается обработкой пользовательских запросов, относящихся к доскам.
Представим, что у нас есть три BoardServer, один из которых — главный. Пользователь отправляет ему запрос «Открой мне доску с id = 123 » > сервер смотрит в своей базе, открыта ли доска и на каком она сервере. В данном примере доска открыта.
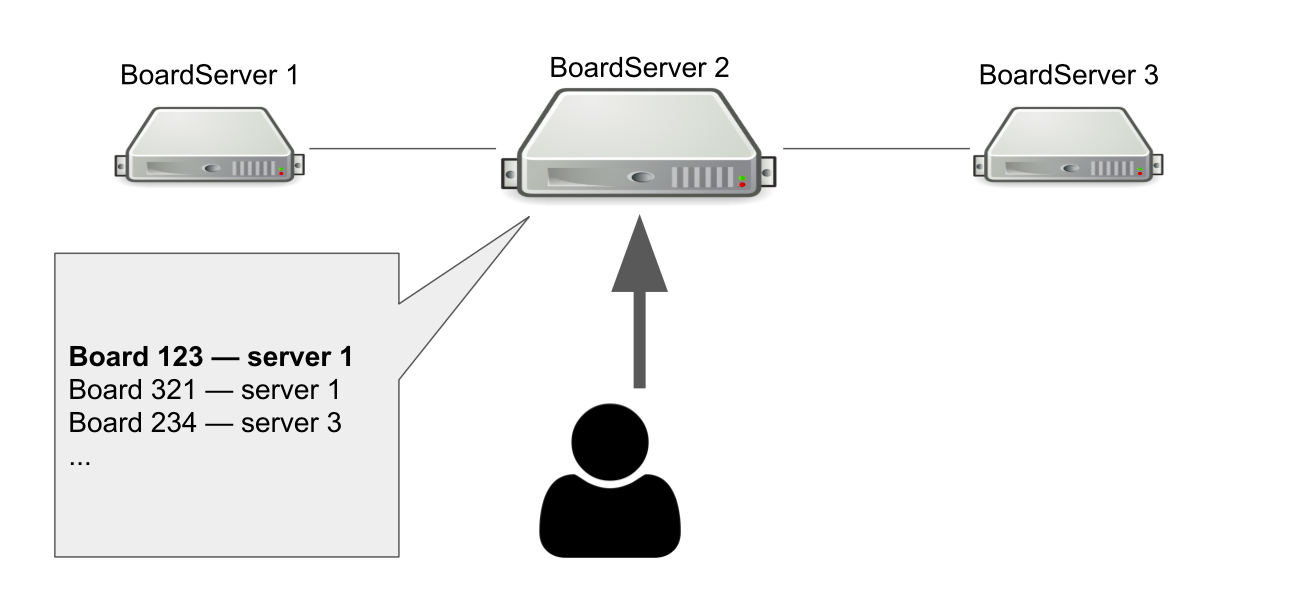
Главный сервер отвечает, что нужно подключиться к серверу №1 > пользователь подключается. Очевидно, что если главный сервер умрёт, то пользователь уже не сможет зайти на новые доски.
Тогда зачем нам нужен сервер, который знает, где открыты доски? Чтобы у нас была единая точка принятия решения. Если с серверами что-то случится, мы должны понимать, доступна ли доска на самом деле, чтобы удалить доску из реестра или переоткрыть где-то ещё. Можно было бы организовать это с помощью кворума, когда несколько серверов решают подобную задачу, но на тот момент у нас не было знаний для самостоятельной реализации кворума.
Переход на Hazelcast
Так или иначе, мы справились с возникшими проблемами, но может быть не самым красивым способом. Теперь нам нужно было понять, как их решить правильно, поэтому мы сформулировали список требований к новому кластерному решению:
- Нам нужно то, что будет следить за состоянием всех серверов и их ролями. Назовём это Service Discovery.
- Нам нужны кластерные локи, которые позволят гарантировать консистентность при выполнении опасных запросов.
- Нужна распределённая структура данных, которая будет гарантировать, что доски лежат на определённых серверах и информировать, если что-то пошло не так.
Это был 2015 год. Мы остановили выбор на Hazelcast — In-Memory Data Grid, кластерная система хранения информации в оперативной памяти. Тогда мы думали, что нашли чудо-решение, святой Грааль мира кластерного взаимодействия, чудо-фреймворк, который умеет всё и совмещает в себе распределённые структуры данных, локи, RPC-сообщения и очереди.
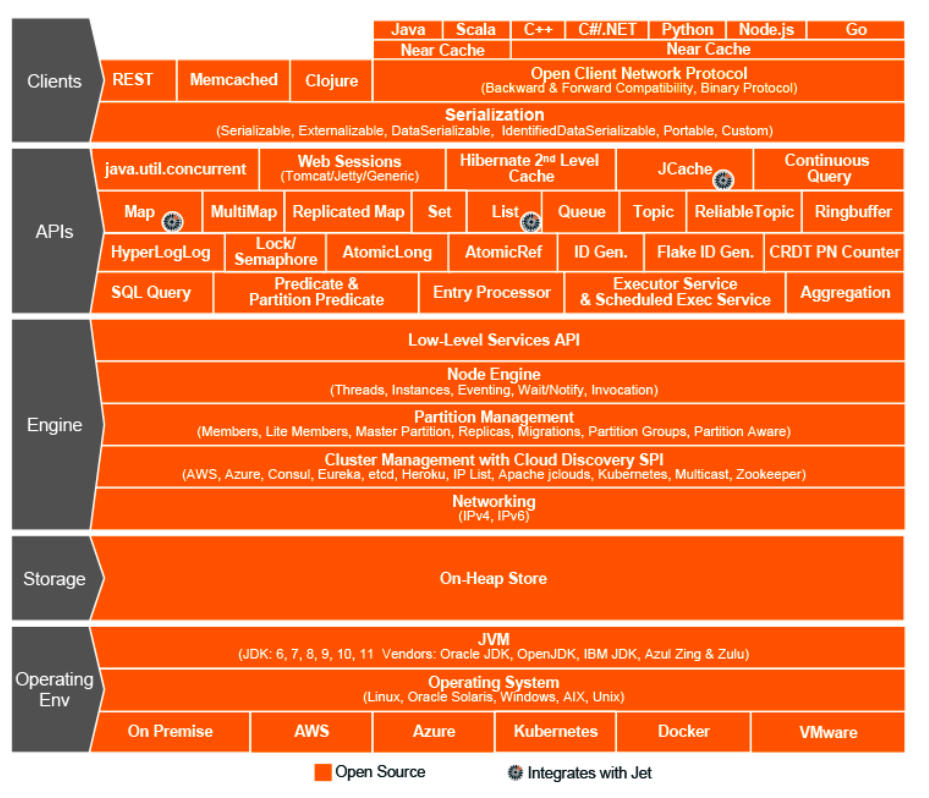
Как и в случае с ActiveMQ, мы перевели на Hazelcast практически всё:
- генерацию пользовательских ресурсов через ExecutorService;
- распределённую блокировку при изменении прав;
- роли и атрибуты серверов (Service Discovery);
- единый реестр открытых досок и т.д.
Топологии Hazelcast
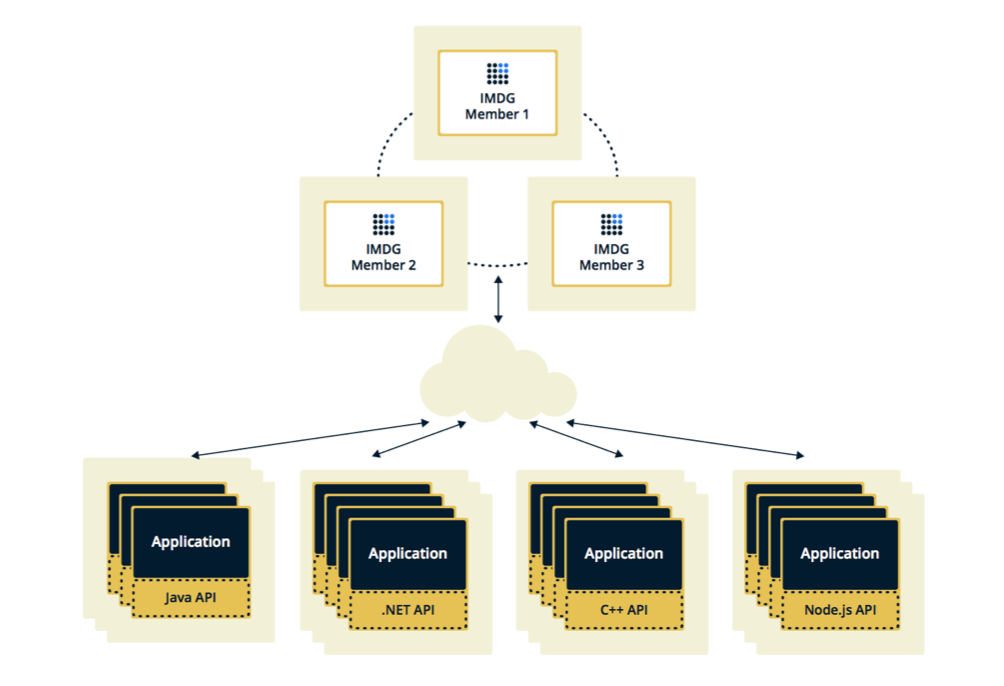
Hazelcast может быть настроен в двух топологиях. Первый вариант – Client-Server, когда мемберы расположены отдельно от основного приложения, сами образуют кластер, а все приложения подключаются к ним как к базе данных.
Вторая топология — Embedded, когда мемберы Hazelcast встроены в само приложение. В этом случае мы можем использовать меньше инстансов, доступ к данным осуществляется быстрее, потому что данные и сама бизнес-логика лежат в одном месте.
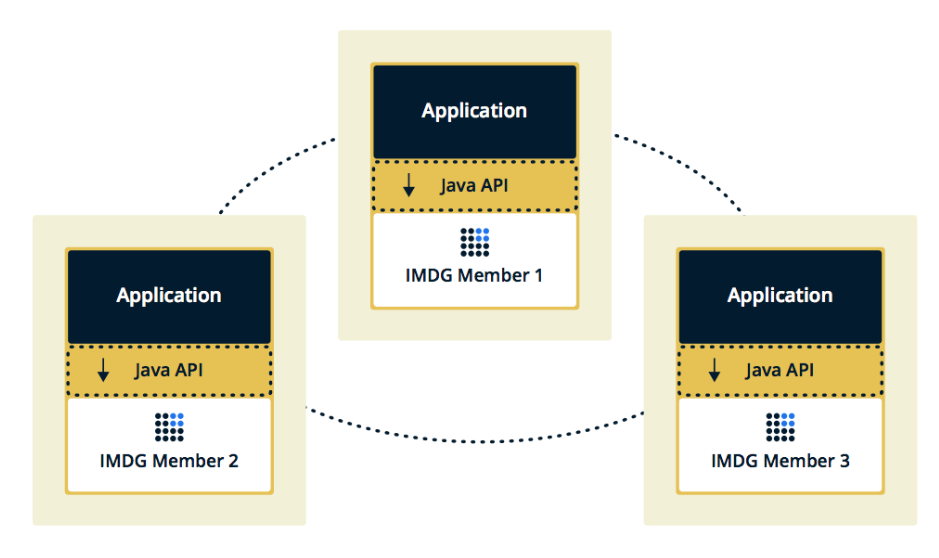
Мы выбрали второе решение, потому что посчитали его более эффективным и экономичным в реализации. Эффективным, потому что скорость обращения к данным Hazelcast будет ниже, т.к. возможно эти данные лежат на текущем сервере. Экономичным, потому что нам не нужно тратить деньги на дополнительные инстансы.
Зависает кластер при зависании member
Через пару недель после включения Hazelcast на проде появились проблемы.
Сначала наш мониторинг показал, что один из серверов начал постепенно перегружать память. Пока наблюдали за этим сервером, остальные сервера тоже начали нагружаться: росло ЦПУ, потом оперативная память, и через пять минут все сервера использовали всю доступную память.
В этот момент в консолях мы видели такие сообщения:
2015-07-15 15:35:51,466 [WARN] (cached18)
com.hazelcast.spi.impl.operationservice.impl.Invocation:
[my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7
2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService',
op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783,
waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0,
tryCount=250, tryPauseMillis=500, invokeCount=1,
callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Здесь Hazelcast проверяет, выполняется ли операция, которая была отправлена на первый — “умирающий” — сервер. Hazelcast старался держать руку на пульсе и проверял состояние операции несколько раз в секунду. В итоге он заспамил все остальные сервера этой операцией, и через несколько минут они вылетели в out of memory, а мы собрали по несколько Гб логов с каждого из них.
Ситуация повторялась несколько раз. Оказалось, что это ошибка в Hazelcast версии 3.5, в которой был реализован механизм heartbeating, проверяющий состояние запросов. В нём не были проверены некоторые граничные кейсы, с которыми мы и столкнулись. Пришлось оптимизировать приложение, чтобы не попадать на эти кейсы, а через несколько недель Hazelcast устранили ошибку у себя.
Частое добавление и удаление members из Hazelcast
Следующая проблема, которую мы обнаружили — добавление и удаление members из Hazelcast.
Сначала коротко расскажу, как работает Hazelcast с партициями. Например, есть четыре сервера, и каждый хранит какую-то часть данных (на рисунке они разного цвета). Единица – это primary партиция, двойка – secondary партиция, т.е. бэкап основной партиции.

При выключении какого-либо сервера партиции отправляются на другие сервера. В случае, если сервер умирает, партиции перегоняются ни с него, а с тех серверов, которые ещё живы и держат бэкап этих партиций.
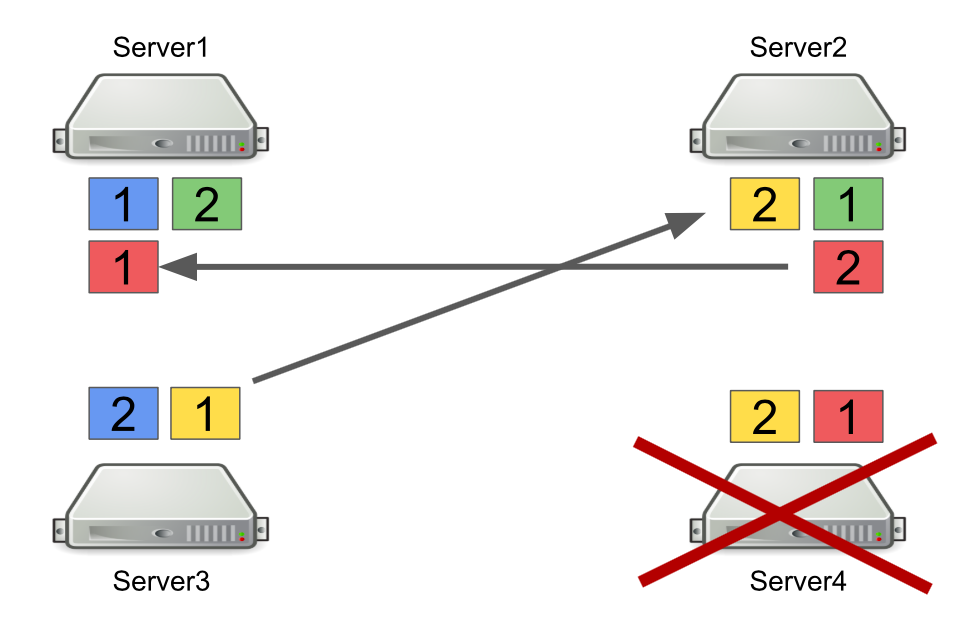
Это надёжный механизм. Проблема в том, что мы часто включаем и выключаем сервера для балансировки нагрузки, а ребалансировка партиций также требует времени. И чем больше серверов работает и чем больше данных мы храним в Hazelcast, тем больше времени нужно на ребалансировку партиций.
Конечно, мы можем уменьшить количество бэкапов, т.е. secondary партиций. Но это небезопасно, так как что-то обязательно пойдёт не так.
Другое решение — перейти к топологии Client-Server, чтобы включение и выключение серверов не влияло на основной кластер Hazelcast. Мы попробовали так сделать, и оказалось, что RPC-запросы нельзя выполнять на клиентах. Давайте разберёмся, почему.
Для этого рассмотрим пример отправки одного RPC-запроса на другой сервер. Мы берём ExecutorService, который позволяет отправлять RPC-сообщения, и делаем submit с новой задачей.
hazelcastInstance
.getExecutorService(...)
.submit(new Task(), ...);
Сама по себе задача выглядит как обычный Java-класс, который имплементирует Callable.
public class Task implements Callable<Long> {
@Override
public Long call() {
return 42;
}
}
Проблема в том, что клиентами Hazelcast могут быть не только Java-приложения, но и с++ приложения, .NET и прочие. Естественно, мы не можем сгенерировать и сконвертировать наш Java-класс на другую платформу.
Один из вариантов — перейти на использование http-запросов в случае, если мы хотим отправить что-то от одного сервера к другому и получить ответ. Но тогда нам придётся частично отказаться от Hazelcast.
Поэтому в качестве решения мы выбрали использование очередей вместо ExecutorService. Для этого мы самостоятельно реализовали механизм ожидания выполнения элемента в очереди, который обрабатывает граничные кейсы и возвращает результат запрашивающему серверу.
Чему мы научились
Закладывать гибкость в систему. Будущее постоянно меняется, поэтому идеальных решений не существует. Сделать сразу “как надо” не получится, но можно постараться быть гибкими и закладывать это в систему. Нам это позволило откладывать важные архитектурные решения до момента, когда не принимать их уже нельзя.
Роберт Мартин в “Чистой архитектуре” пишет об этом принципе:
“Цель архитектора — создать такую форму для системы, которая сделает политику самым важным элементом, а детали — не относящимися к политике. Это позволит откладывать и задерживать принятие решений о деталях”.
Универсальных инструментов и решений не существует. Если вам кажется, что какой-то фреймворк решает все ваши проблемы, то, скорее всего, это не так. Поэтому при внедрении любого фреймворка важно понимать не только какие проблемы он решит но и какие принесёт вместе с собой.
Не надо сразу всё переписывать. Если вы столкнулись с проблемой в архитектуре и кажется, что единственное верное решение — это написать всё с нуля, подождите. Если проблема действительно серьёзная, найдите быстрый фикс и понаблюдайте за тем, как система будет работать в дальнейшем. Скорее всего, это будет не единственная проблема в архитектуре, со временем вы найдёте ещё. И только когда вы наберёте достаточное количество проблемных мест, можно приниматься за рефакторинг. Только в этом случае плюсов от него будет больше, чем его стоимость.
Комментарии (9)

pilot911
25.02.2019 16:51embedded — это Near cache?

63uK Автор
25.02.2019 21:51Можно и так сказать. Но там зависит от того, как настроить Hazelcast. То есть, там можно сделать так чтобы данные шардились по кластеру по определенному принципу, чтобы miss rate низким держать.
pilot911
25.02.2019 23:46понятно, я бы на вашем месте все упаковал в докер-контейнеры, использовал для динамической нагрузки и докер-кластера Marathon + Mesos, в качестве Discovery service использовал Eureka и так далее.
Мне кажется, вы возлагаете на Hazelcast неподобающие ему функции Discovery service и распределённую блокировку (здесь лучше использовать Zookeeper)
Throwable
26.02.2019 15:04БД — Redis и PostgreSQL (мой коллега написал о том, как мы переезжаем с одной БД на другую).
Извратнулись вначале, и потом пришлось переделывать и еще больше извращаться. Если бы начали с PostgreSQL, возможно половины проблем бы удалось избежать. Стандартная архитектура процессинга — это share nothing, т.е. кластера ничего не знают друг о друге, а вся синхронизация происходит в БД. С этого и надо было начинать.
Допустим, сервер №3 хочет отправить сообщение на генерацию ресурсов в очередь. Он ждёт, что его сообщение будет обработано.
В асинхронной модели взаимодействия сервер собственно ничего ждать не должен, а просто заново срабатывать на получение ответа. В идеале вы должны были выбрать между синхронной и асинхронной моделями взаимодействия, т.к. переходить потом с одной на другую может затронуть сразу весь стек. Еще хуже — это мешать обе эти модели в одном процессинге.
За всё время ожидания сервер отправляет множество сообщений с запросом, из-за чего появляется очередь из сообщений. Поэтому когда появляются рабочие сервера, они вынуждены сначала обработать накопившуюся очередь, что занимает время.
В любой уважающей себя системе сообщений есть TTL. Плюс в ActiveMQ можно настроить свалку для необработанных сообщений. Если ваш сервер подписан на нее, то по истечении времени он получит обратно свое сообщение как необработанное.
Это решение не будет работать в кластере. Нам бы могла помочь в этом SQL база при помощи транзакций. Но у нас Redis.
Более того, на одном Postgres-е можно реализовать кучу примитивов синхронизации без привлечения сторонних технологий. Ту же самую очередь.
И чем больше серверов работает и чем больше данных мы храним в Hazelcast, тем больше времени нужно на ребалансировку партиций.
Это неверно. Чем больше у вас инстансов, тем меньше соотношение партишнов на инстанс, соответственно меньше данных придется перегонять. А собственно в чем проблема ресинхронизации, кроме того, что может занять определенное время?
Чему мы научились
- Начните с простого стандартного инструмента и усложняйте только по мере необходимости.
- Если вы столкнулись с проблемами производительности, не спешите усложнять архитектуру и подтягивать новые технологии и зависимости. В 90% случаев это проблемы приложения, которые можно устранить. И только после того как возможности оптимизации будут исчерпаны, можно планировать переход на другую архитектуру.
63uK Автор
27.02.2019 19:46Спасибо за такой развернутый комментарий. Попробую ответить по порядку.
Извратнулись вначале, и потом пришлось переделывать и еще больше извращаться. Если бы начали с PostgreSQL, возможно половины проблем бы удалось избежать. Стандартная архитектура процессинга — это share nothing, т.е. кластера ничего не знают друг о друге, а вся синхронизация происходит в БД. С этого и надо было начинать.
На момент старта разработки мы взяли платформу от наших партнеров, которая уже основывалась на Redis. Она позволила нам в короткие сроки написать продукт и развить его до состояния тысяч пользователей в онлайне. Уверен, что на тот момент попытка написать все с нуля не привела бы ни к чему хорошему.
В асинхронной модели взаимодействия сервер собственно ничего ждать не должен, а просто заново срабатывать на получение ответа. В идеале вы должны были выбрать между синхронной и асинхронной моделями взаимодействия, т.к. переходить потом с одной на другую может затронуть сразу весь стек. Еще хуже — это мешать обе эти модели в одном процессинге.
Да, я согласен с вами. Но ожидание нам было нужно, так как мы обрабатывали HTTP запрос на генерацию ресурсов и в ответе возвращали ссылки на файлы. Следовательно мы должны были держать этот HTTP запрос, пока к нам не вернется ответ от генератора.
В любой уважающей себя системе сообщений есть TTL. Плюс в ActiveMQ можно настроить свалку для необработанных сообщений. Если ваш сервер подписан на нее, то по истечении времени он получит обратно свое сообщение как необработанное.
Про TTL писал в комментарии выше. Свалка необработанных сообщений тут бы особой роли не сыграла, так как мы отправляли ответ пользователю по таймауту. Но возможно это позволило бы убрать реакцию на таймаут и оставить только реакцию на приходящие сообщения из очереди.
Это неверно. Чем больше у вас инстансов, тем меньше соотношение партишнов на инстанс, соответственно меньше данных придется перегонять. А собственно в чем проблема ресинхронизации, кроме того, что может занять определенное время?
Во время релиза мы постепенно выключаем старые и включаем новые сервера. Каждый из серверов хранит в себе набор партиций. И когда мы выключаем один из серверов, он может переслать партиции на сервер, который будет выключен следующим. Следовательно при выключении очередного сервера мы вновь перенесем партиции с него. Основная проблема тут в работе с этими партициями. При такой ресинхронизации работа с данными становится медленнее и иногда может влиять на пользователей.
raiSadam
Спасибо, интересный опыт. Единственное, что не понял, так это зачем Вы сообщения в очереди накапливали? Ведь можно было указать время жизни сообщения, тогда в очереди были бы только актуальные.
63uK Автор
Да, мы в итоге указали время жизни, но получается что producer все равно не знает о том, что очередь обрабатывается. На сколько помню, мы еще хотели на системных очередях ActiveMQ определять какие очереди и скольким количеством серверов слушаются, но пришлось бы еще серьезно дорабатывать систему.