

Хабр, привет!
В этой статье мы разберем довольно интересную и, на мой взгляд, востребованную тему — проведение простого анализ статистики группы Вконтакте через API с помощью Python. Свою статью я разделю на две части — в первой части анализ группы Вконтакте через Python, во второй напишу бота для Telegram, который будет делать анализ сам, по вводным данным.
Итак, давайте начнем.
В самом начале нам необходимо определиться с группой, которую будем анализировать, и целями, которые сразу определим. Я выбрал одну из популярных групп с большой, накопленной статистикой — vk.com/evil_incorparate.
Цели поставим следующие:
- Понять масштабы выборки (сколько записей на стене, сколько лайков максимально и минимально собирал пост в группе, среднее значение лайков и разделить эти все данные по годам);
- Определить долю комментариев, репостов и лайков в общем количестве всех записей;
- Найти соотношение количества записей на стене и количества лайков;
- Определить зависимость времени и дня недели с количеством записей в группе;
- Подвести итоги и сделать выводы по всем данным.
Теперь мы поняли свои цели и приступаем собственно к анализу данных. После того, как мы выберем нужную нам дату из API (авторизируемся через oauth.vk.com, выбираем метод, как итог — прикрепляю свой файл с кодом), подождем когда загрузятся все данные и мы прочитаем содержимое файла.
import pandas as pd
vkapi = pd.read_csv('.../29246653-2019-01-28.csv', sep=';', low_memory=False)
vkapi.head(10)
Далее оцениваем весь диапазон данных по столбцам выводя их названия, то, с чем мы можем в дальнейшем работать:
vkapi.columns
Как мы видим у нас их 16. Теперь давайте посмотрим общую статистику по всем записям:
max_laik = vkapi['likes'].describe()
Count — Количество записей;
Mean — Среднее значение;
Std — Выборочное стандартное отклонение;
25, 50, 75 % — Процентиль (Квантиль в %);
Max — Максимальное значение;
Min — Минимальное значение.
Изучаем. Идем дальше, и смотрим статистику по максимальному значению лайков за год:
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1,1)
ax.plot(vkapi['year'], vkapi['likes'])
fig.set_size_inches(22,10)
plt.title('Статистика по максимальному значению лайков за год',fontsize=18)
Самые пиковые значения приходились на 2012 и 2015 года, далее значения уменьшаются в 1,5-2 раза к предыдущему году. Это, скорее всего, связано с появлением алгоритма умной ленты и появлением в группе непопулярных постов, собирающих мало лайков.
К этим данным интересно будет посмотреть статистику по репостам, есть ли какая нибудь закономерность:
max_repost = vkapi['reposts'].describe()
print(max_repost)
Изучаем.
fig, ax = plt.subplots(1,1)
ax.plot(vkapi['year'], vkapi['reposts'])
fig.set_size_inches(20,10)
plt.title('Статистика по максимальному значению репостов за год',fontsize=14)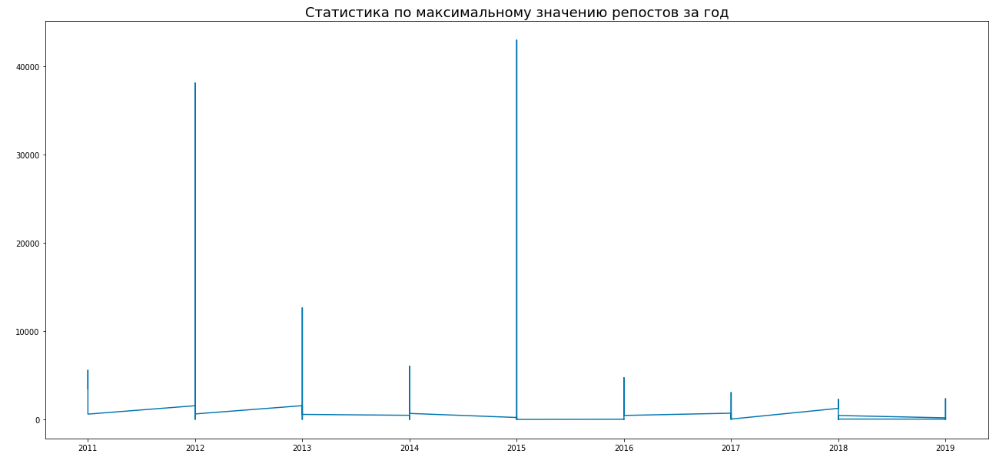
Аномалий нет. Есть стандартная закономерность по лайкам и репостам. Вовлеченность в группе падает, в течении последних лет. В коридоре данных это наглядно видно.
Эти данные мы можем визуализировать иначе:
sum_like = pd.to_numeric(vkapi['likes']).sum()
sum_comments = pd.to_numeric(vkapi['comments']).sum()
sum_reposts = pd.to_numeric(vkapi['reposts']).sum()
labels = 'Likes', 'Comments', 'Reposts'
sizes = [sum_like, sum_comments, sum_reposts]
colors = ['gold', 'yellowgreen', 'lightcoral']
explode = (0.1, 0.1, 0.1)
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', startangle=155)
plt.title('Доля комментариев, репостов и лайков в сумме всех записей',fontsize=14)
plt.axis('equal')
plt.show()
sum_like = pd.to_numeric(vkapi['likes']).sum()
sum_views = pd.to_numeric(vkapi['views']).sum()
labels = 'Likes', 'views',
sizes = [sum_like, sum_views,]
colors = ['gold', 'yellowgreen']
explode = (0.1, 0.1)
plt.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', startangle=155)
plt.title('Доля общего количества лайков в сумме всех просмотров',fontsize=14)
plt.axis('equal')
plt.show()
По соотношению лайков и репостов средняя конверсия в ~10% это гуд. По параметру view отмечу, что это не уникальный просмотр, а каждый просмотр, поэтому используем её как охватную метрику.
Давайте построим диаграмму по количеству записей и их лайкам:
%matplotlib inline
plt.style.use('bmh')
likes = vkapi.likes
plt.figure(num=5, figsize=(20, 7))
plt.title('Количество записей на стене и количество лайков')
plt.xlabel('count')
plt.ylabel('likes')
plt.plot(likes, '-')
Для примера мы можем построить такой же график, только ограничить выборку до записей, набравших менее 2000 лайков:
likes = vkapi[vkapi['likes'] < 2000 ]['likes']
plt.figure(num=1, figsize=(17, 8))
plt.title('Количество записей на стене и количество лайков < 2000')
plt.xlabel('count')
plt.ylabel('likes')
plt.plot(likes, '.')
plt.style.use('fivethirtyeight')
Посмотрим, когда в группе по часам чаще всего выкладываются посты:
vkapi.time.value_counts()
time_summary = vkapi.time.value_counts()[[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]]
time_summary = vkapi.time.value_counts().sort_index()
plt.figure(num=1, figsize=(20, 8))
time_summary.plot.barh(stacked=True,alpha=0.7)
plt.style.use('fivethirtyeight')
Как мы видим, ничего необычного, в ночное время постов выходит меньше всего.
При построении графика зависимости дня недели и количества лайков мы видим, что чаще всего посты выкладываются в понедельник:
weekday_summary = vkapi.weekday.value_counts()[['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']]
plt.figure(num=1, figsize=(20, 8))
plt.plot(weekday_summary, '-')
plt.style.use('fivethirtyeight')
Самое популярное время по репостам:
weekday_reposts_summary = vkapi.groupby(['weekday']).reposts.mean()[['Monday', time_reposts_summary = vkapi.groupby(['time']).reposts.mean()
plt.figure(num=1, figsize=(30, 15))
plt.style.use('classic')
plt.plot(time_reposts_summary, '-')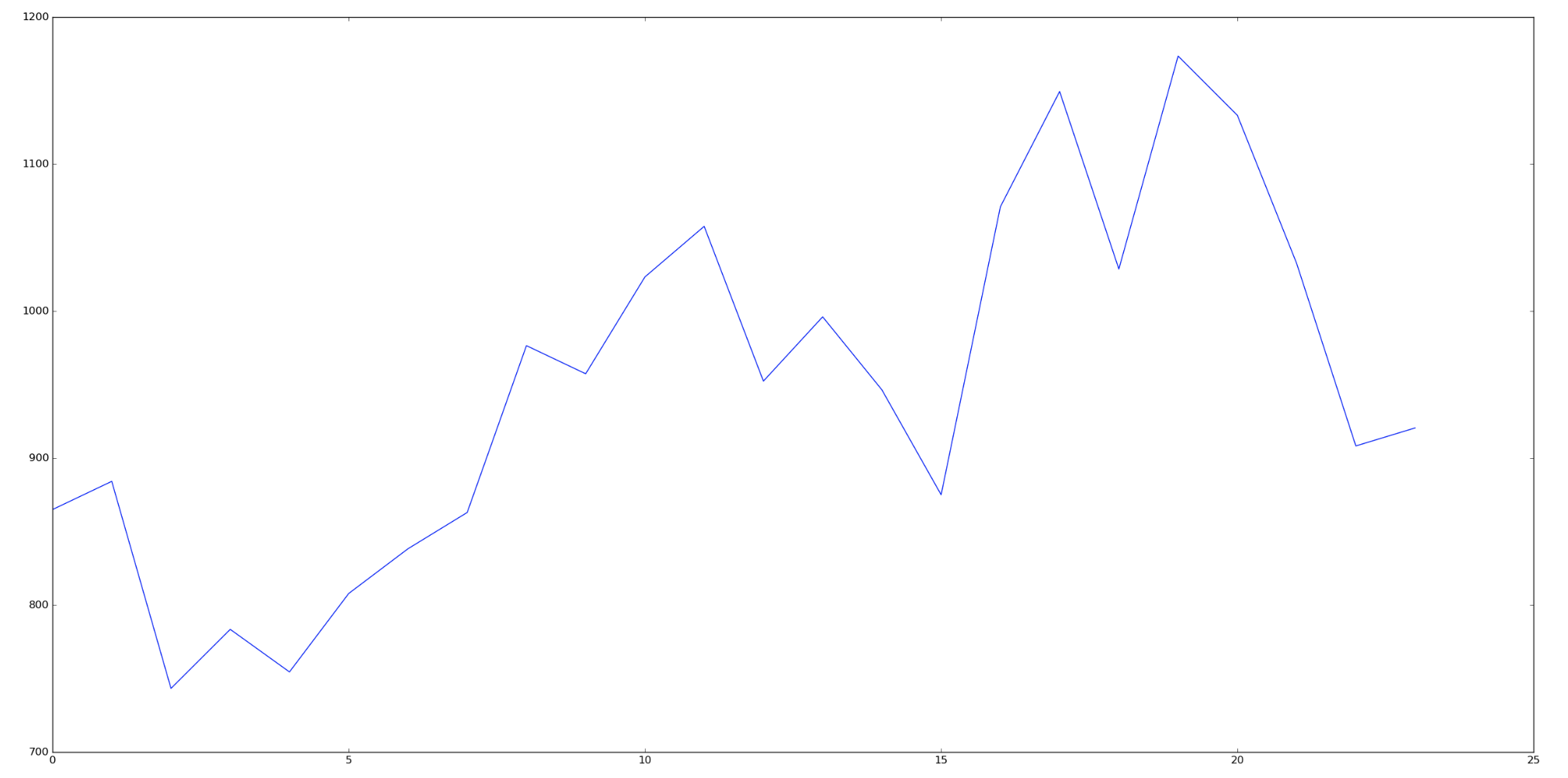
Основные выводы по данным:
- Самое плотные часы по публикациям 15,18,21,22;
- Самый забитый по постам день недели в группе — понедельник (нужно больше удерживать аудиторию и выкладывать посты чаще чем обычно);
- Самое популярное время по лайкам 7,11,16,17,19,20;
- Самое популярное время по репостам 10,11,16,17,19,20,21.
… (свои варианты выводов в комментарии)
Данная статистика будет полезна как владельцам групп (для планирования выхода постов), так и для пользователей покупающих рекламу в пабликах.
Если у вас есть поправки/новые предложения по анализу/срезам данных — велкам в комментарии :)
WLMike
> vkapi.time.value_counts()[[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23]]
Мне кажется лучше просто отсортировать по индексу. В ручную и ошибиться можно, а когда значений больше вообще сложно все вбить будет.
Syurmakov Автор
Все верно, спасибо)