

Динамический ремаркетинг (dynrem) в myTarget — это технология направленной рекламы, использующая информацию о действиях пользователей на сайтах и в мобильных приложениях рекламодателей. Например, в интернет-магазине пользователь просмотрел страницы товаров или добавил их в корзину, и myTarget использует эти события для показа рекламы именно тех товаров и услуг, к которым человек уже проявлял ранее интерес. Сегодня я подробнее расскажу о механизме генерирования неперсональных, то есть item2item-рекомендаций, которые позволяют разнообразить и дополнить рекламную выдачу.
В качестве клиентов для dynrem myTarget выступают в основном интернет-магазины, у которых может быть один или несколько списков товаров. При построении рекомендаций пару «магазин — список товаров» нужно учитывать как обособленную единицу. Но для простоты дальше будем использовать просто «магазин». Если говорить о размерности задачи на входе, то рекомендации нужно строить примерно для тысячи магазинов, причем количество товаров может варьироваться от нескольких тысяч до миллионов.
Система рекомендаций для dynrem должна удовлетворять таким требованиям:
- Баннер содержит товары, которые максимизируют его CTR.
- Рекомендации строятся в оффлайн-режиме в течение заданного времени.
- Архитектура системы должна быть гибкой, масштабируемой, устойчивой и работать в условиях «холодного старта».
Отметим, что из требования построения рекомендаций за фиксированное время и описанных начальных условий (будем оптимистично полагать, что число магазинов возрастает) естественно возникает требование экономного использования машинных ресурсов.
Раздел 2 содержит теоретические основы для построения рекомендательных систем, в разделах 3 и 4 рассматривается практическая сторона вопроса, а в разделе 5 подводится общий итог.
Основные понятия
Рассмотрим задачу построения рекомендательной системы для одного магазина и перечислим основные математические подходы.
Singular Value Decomposition (SVD)
Популярным подходом к построению рекомендательных систем является подход на основе сингулярного разложения (SVD). Матрицу рейтингов представляют в виде произведения двух матриц и так, чтобы , тогда оценка рейтинга пользователя для товара представляется в виде [1], где элементы скалярного произведения являются векторами размерности (основной параметр модели). Эта формула служит основой для других SVD-моделей. Задача нахождения и сводится к оптимизации функционала:
(2.1)
где — функция ошибки (например, RMSE как в соревновании Netflix), — регуляризация, а суммирование идет по парам, для которых известен рейтинг. Перепишем выражение (2.1) в явном виде:
(2.2)
Здесь , — коэффициенты L2-регуляризации для представлений пользователя и товара соответственно. Базовая модель для соревнования Netflix имела вид:
(2.3)
(2.4)
где , и — смещения для рейтинга, пользователя и товара соответственно. Модель (2.3) — (2.4) можно улучшить, добавив в неё неявное предпочтение пользователя. На примере соревнования Netflix явным откликом является балл, поставленный пользователем фильму «по нашей просьбе», а неявным откликом выступает прочая информация о «взаимодействии пользователя с товаром» (просмотр фильма, его описания, рецензий на него; т.е. неявный отклик не даёт прямой информации о рейтинге фильма, но при этом указывает на заинтересованность). Учёт неявного отклика реализован в модели SVD++:
(2.5)
где — набор объектов, с которыми неявно взаимодействовал пользователь, — представление размерности для объекта из .
Factorization Machines (FM)
Как видно на примерах с различными SVD-моделями, одна модель отличается от другой набором слагаемых, входящих в формулу оценки. При этом расширение модели каждый раз представляет из себя новую задачу. Мы хотим, чтобы такие изменения (например, добавление нового вида неявного отклика, учёт временных параметров) можно было легко реализовать, не меняя код реализации модели. Модели (2.1) — (2.5) можно представить в удобной универсальной форме, используя следующую параметризацию. Представим пользователя и товар в виде набора признаков:
(2.6)
(2.7)
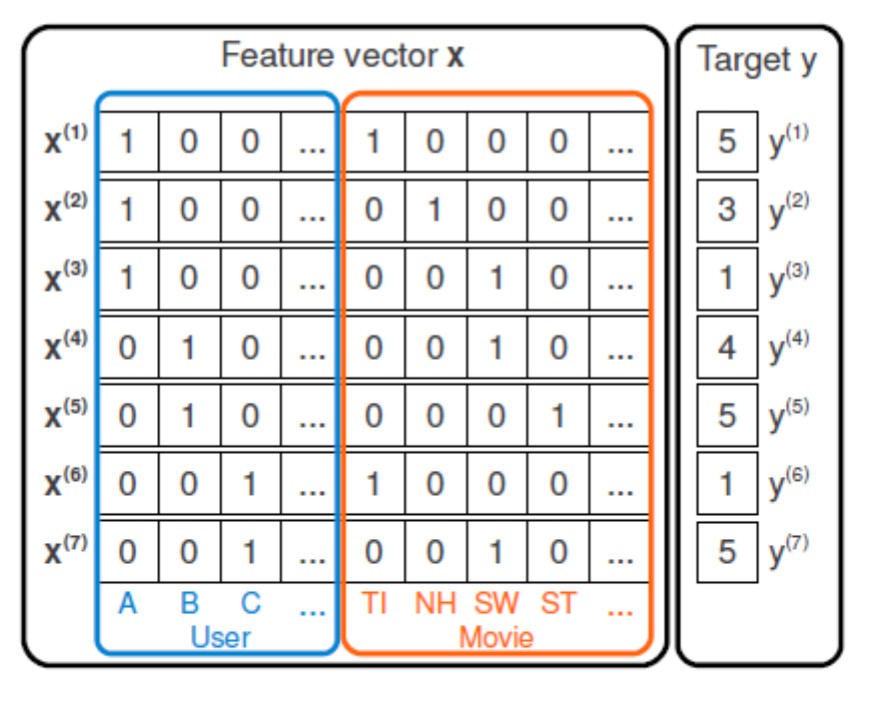
Рис. 1: Пример матрицы признаков в случае CF.
Например, в случае коллаборативной фильтрации (CF), когда используются только данные о взаимодействии пользователей и товаров, векторы признаков имеют вид one-hot-кода (Рис. 1). Введём вектор , тогда задача рекомендации сводится к задачам регрессии с целевой переменной :
- Линейная модель:
(2.8)
- Poly2:
(2.9)
- FM:
(2.10)
где — параметры модели, — векторы размерности , представляющие признак в латентном пространстве, и — количество признаков пользователя и товара соответственно. В качестве признаков помимо one-hot-кодов могут выступать контентные признаки (Content-based, CB) (Рис. 2), например, векторизованные описания товаров и профилей пользователей.

Рис. 2: Пример расширенной матрицы признаков.
Модель FM, введенная в [2], является обобщением для (2.1) — (2.5), (2.8), (2.10). Суть FM в том, что она учитывает парное взаимодействия признаков с помощью скалярного произведения , а не с помощью параметра . Преимущество FM относительно Poly2 состоит в существенном уменьшении количества параметров: для векторов нам потребуется параметров, а для потребуется параметров. При и больших порядков первый подход использует значительно меньше параметров.
Обратим внимание: если в обучающей выборке отсутствует конкретная пара , то соответствующее слагаемое с в Poly2 не влияет на обучение модели, и оценка рейтинга формируется только по линейной части. Однако подход (2.10) позволяет устанавливать связи через другие признаки. Иначе говоря, данные об одном взаимодействии помогают оценить параметры признаков, не входящих в этот пример.
На основе FM реализуется так называемая гибридная модель, в которой к CF-признакам добавляются CB-признаки. Она позволяет решить проблему холодного старта, а также учитывает пользовательские предпочтения и позволяет делать персональные рекомендации.
LightFM
В популярной реализации FM сделан акцент на разделение между признаками пользователя и товара. В качестве параметров модели выступают матрицы и представления пользовательских и товарных признаков:
(2.11)
а также смещения . Используя представления пользователя и товара:
(2.12)
(2.13)
получаем рейтинг пары :
(2.14)
Функции потерь
В нашем случае необходимо отранжировать товары для конкретного пользователя так, чтобы более релевантный товар имел больший рейтинг, чем менее релевантный. В LightFM реализовано несколько функций потерь:
- Logistic представляет собой реализацию, требующую негатив, который явным образом не представлен в большинстве задач.
- BPR [3] заключается в максимизации разности рейтингов между позитивным и негативным примерами для конкретного пользователя. Негатив получают с помощью бутстрэп-сэмплирования. Функционал качества, используемый в алгоритме, аналогичен ROC-AUC.
- WARP [4] отличается от BPR методом сэмплирования негативных примеров и функцией потерь, которая тоже является ранжирующей, но при этом оптимизирует топ рекомендаций для пользователя.
Практическая реализация
Для построения рекомендаций в течение заданного времени используется параллельная реализация на Spark. Для каждого магазина запускается независимая задача, исполнение которой контролируется luigi.
Препроцессинг данных
Препроцессинг данных выполняется автоматически масштабируемыми средствами Spark SQL. Отобранные в финальную модель признаки — текстовые описания товаров и каталогов со стандартными преобразованиями.
Что нам помогало при взаимодействии со Spark:
- Партицирование подготовленных данных (матрицы взаимодействий пользователей и товаров, признаки для них) по магазинам. Это позволяет на этапе обучения экономить время на чтении данных из HDFS. В противном случае каждой задаче приходится считывать данные в память Spark и фильтровать их по ID магазина.
- Сохранение/получение данных в/из Spark мы делаем частями. Это связано с тем, что в процессе любого из этих действий данные загружаются в память JVM. Почему просто не увеличить память для JVM? Во-первых, тогда уменьшается доступная для обучения модели память, а во-вторых, не нужно хранить что-либо в JVM, она выступает в данном случае как временное хранилище.
Обучение модели
Модель для каждого магазина обучается в своем Spark-контейнере, благодаря чему можно одновременно запускать произвольное количество задач для магазинов, ограниченное только ресурсами кластера.
В LightFM отсутствуют механизмы ранней остановки, следовательно, мы тратим лишние ресурсы на дополнительные итерации обучения, когда прироста целевой метрики нет. Мы выбрали в качестве метрики AUC, взаимосвязь которого с CTR подтверждается экспериментально.
Обозначим:
— все известные нам взаимодействия между пользователями и товарами, то есть пары ,
— множество всех товаров ,
— множество всех пользователей .
Для конкретного пользователя также введем — множество товаров, с которыми взаимодействовал пользователь. AUC можно вычислить следующим образом [ref]:
(3.1)
(3.2)
В формуле (3.1) нам нужно посчитать рейтинг для всех возможных пар ( фиксировано), а также сравнить рейтинг для элементов из с рейтингами из . Учитывая, что пользователь взаимодействует с мизерной частью ассортимента, сложность расчёта составляет . При этом одна эпоха обучения FM обходится нам в .
Поэтому мы модифицировали расчет AUC. Во-первых, следует разбить выборку на тренировочную и валидационную , причем . Далее мы с помощью сэмплирования формируем множество пользователей для валидации . Для пользователя из элементами позитивного класса будем считать множество , аналогичное . В качестве элементов негативного класса возьмем подвыборку так, чтобы в неё не попали элементы из . Размер подвыборки можно брать пропорциональным размеру , то есть . Тогда формулы (3.1), (3.2) для расчета AUC изменятся:
(3.3)
(3.4)
В итоге получаем константное время на расчет AUC, так как берём только фиксированную часть пользователей, и множества и имеют небольшой размер. Процесс обучения для магазина останавливается после того, как AUC (3.4) перестает улучшаться.
Поиск похожих объектов
В рамках задачи item2item необходимо выбрать для каждого товара (или максимально похожих на него товаров) такие, которые максимизируют кликабельность баннера. Наше допущение: кандидатов для баннера нужно считать из top- ближайших в пространстве эмбеддингов. Мы протестировали следующие методы расчёта «ближайших соседей»: Scala + Spark, ANNOY, SCANNs, HNSW.
У связки Scala + Spark для магазина с 500 тыс. объектов подсчёт честной косинусной метрики занял 15 минут и значительный объём ресурсов кластера, в связи с чем мы протестировали аппроксимальные методы поиска ближайших соседей. При исследовании метода SCANNs варьировались следующие параметры:
bucketLimit, shouldSampleBuckets, NumHashes и setSignatureLength, но результаты получились неудовлетворительными по сравнению с остальными методами (в бакеты попадали сильно различающиеся объекты). Алгоритмы ANNOY и HNSW показали результаты, сравнимые с честным косинусом, но отработали значительно быстрее. | 200к товаров | 500к товаров | 2.2м товаров | ||||
| Алгоритм | ANNOY | HNSW | ANNOY | HNSW | ANNOY | HNSW |
| время построения индекса (сек) |
59.45 | 8.64 | 258.02 | 25.44 | 1190.81 | 90.45 |
| общее время (сек) | 141.23 | 14.01 | 527.76 | 43.38 | 2081.57 | 150.92 |
В связи с тем, что быстрее всех алгоритмов отработал HNSW, на нём мы и решили остановится.
Поиск ближайших соседей мы также осуществляем в Spark-контейнере и записываем результат в Hive с соответствующим партицированием.
Заключение
Напомним: WARP мы используем для обучения модели, AUC — для ранней остановки, а финальная оценка качества проводится с помощью А/Б-теста на живом трафике.
Мы полагаем, что в этом месте — в организации эксперимента и подборке оптимального состава баннера — заканчивается data и начинается science. Здесь мы учимся определять, имеет ли смысл показать рекомендации для товаров, на которые сработал ретаргетинг; сколько именно рекомендаций показать; сколько просмотренных товаров, и т.д. Об этом мы расскажем в следующих статьях.
Дальнейшие улучшения алгоритма — поиск универсальных эмбеддингов, которые позволят поместить товары всех магазинов в одно пространство — мы проводим в рамках парадигмы, описанной в начале статьи.
Спасибо за внимание!
Литература
[ 1 ] Ricci F., Rokach L., Shapira B. Introduction to recommender systems handbook
//Recommender systems handbook. — Springer, Boston, MA, 2011. — С. 147160.
[ 2 ] Rendle S. Factorization machines //2010 IEEE International Conference on Data Mining. — IEEE, 2010. — С. 995-1000.
[ 3 ] Rendle S. et al. BPR: Bayesian personalized ranking from implicit feedback
//Proceedings of the twenty-fifth conference on uncertainty in artificial intelligence.
— AUAI Press, 2009. — С. 452-461.
[ 4 ] Weston J., Bengio S., Usunier N. Wsabie: Scaling up to large vocabulary image annotation //Twenty-Second International Joint Conference on Artificial Intelligence. — 2011.
FreakII
Какой мощный матан на входе, и какие тупые нерелевантные рекламные баннеры на выходе