
Прежде всего — немного истории. Работая на должностях тимлида и техлида мне порой приходилось проводить собеседования, соответственно нужно подготовить несколько теоретических вопросов, ну и пару несложных задач, на решение которых не должно было бы уйти больше 2х-3х минут. Если с теорией все просто — мой любимый вопрос это: «чему равен typeof null?», по ответу сразу можно понять, кто сидит перед тобой, джун — просто правильно ответит, а претендент на сеньера, еще и объяснит почему. То с практикой — сложнее. Я долго не мог придумать нормальное задание, не изъезженное, типа fizz-buzz, а что-нибудь свое. Поэтому я на собеседованиях давал задания, которые сам проходил, устраиваясь на текущую работу. О первом из них и пойдет речь.
Текст задачи
Напишите функцию, которая принимает на вход строку, а возвращает эту строку «задом наперед»
function strReverse(str) {};
strReverse('Habr') === 'rbaH'; // true
Очень простая задача, решений для которой масса, самым оптимальным для себя я долго считал такое решение:
const strReverse = str => str.split('').reverse().join('');Но что-то меня в этом решении смущало всегда, а именно ненадежность «split('')». И вот после одного из собеседований, я задумался: «Что же такое я могу передать в строке, что сломает мой способ...?». Ответ пришел очень быстро.
О, да, вы уже могли понять о чем я, emoji! Эти чертовы смайлики, их придумал сам дьявол, вы только посмотрите, во что превращается палец вверх, если его перевернуть (нет, не в палец вниз).
Сразу хочу извиниться, редактор разметки убирает emoji из кода, поэтому вставляю картинки.

Окей, задача простая, нужно просто нормально разбить строку по символам. Вперед, команда, пара часов мозгового штурма команды и у нас есть решение, если честно, удивлен, что раньше так не додумались делать, теперь это будет моя любимая реализация!
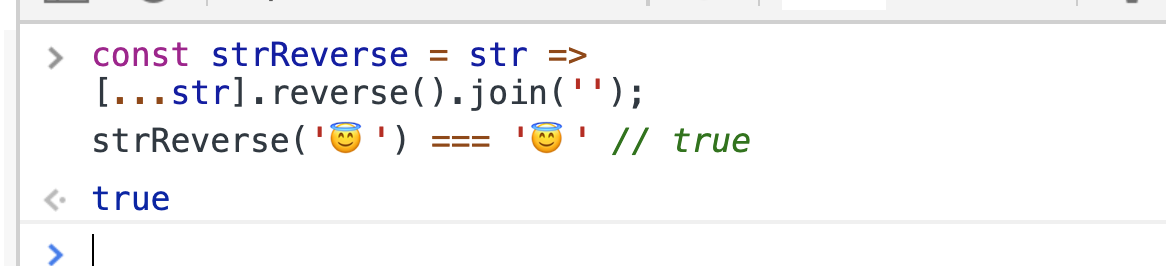
Огонь, работает, супер, но… Подождите ка, с недавних пор мы можем указать цвет для смайла, и что же будет, если мы передадим такой emoji в функцию?
Это фиаско, братан!
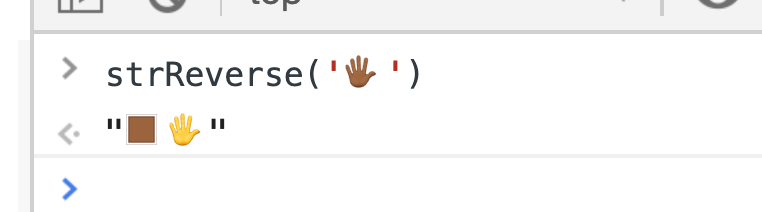
Вот тут то я и сел в лужу. Если честно, я пару раз предлагал еще на собеседованиях решить эту задачу, в основном, надеясь что мне предложат то решение, которое сможет это сделать — нет, претенденты разводили руками и не могли мне ничем помочь.
Помог случай, ну или спортивный интерес. Со словами «Хочешь задачку со специальной олимпиады?» я отправил ее моему бывшему коллеге. «Ок, к вечеру попробую сделать» — последовал ответ, и я напрягся… «А что если сделает? А что если реально сможет? Он сможет, а я — нет? Так дела не пойдут!» — так подумал я и начал шерстить интернет.Тут я перейду к теоретической части, которая некоторым из вас может показаться интересной и полезной, а некоторым — повторением пройденного материала.
Что нам нужно знать о Emoji?
Во первых, это — стандарт! Стандарт, который хорошо описан.
Решающим моментом в жизни emoji можно считать день принятия стандарта unicode 8.0 и стандарта emoji 2.0 в нем, тогда и были описаны первые последовательности юникода и последовательности emoji.
Давайте вот тут остановимся чуть подольше и разберем вопрос подробнее.
Согласно первой версии стандарта emoji является представлением одного символа юникода

И так далее…
Вторая версия стандарта позволяет нам взять несколько симовлов юникода в определенной последовательности, чтобы получить emoji

> Полный список
Это и есть простые последовательности в emoji, но простые они только потому что есть еще и zwj — последовательности.
ZERO WIDTH JOINER (ZWJ) — соединитель с нулевой шириной, это та ситуация, когда между несколькими emoji вставляется специальный символ юникода ZWJ (200D), который «схлопывает» emoji по обе стороны от него и вот что мы получаем в итоге:

> Полный список
В последующих стандартах эти последовательности только дополнялись, так что количество комбинаций emoji только росло со временем.
Что ж, с мат частью разобрались, но что же нам делать, чтобы перевернуть строку и при этом сохранить последовательность?
Регулярные выражения.
Если у вас есть проблема и вы захотели решить ее с помощью регулярных выражений, то теперь у вас две проблемы.Углубляясь в изучение стандарта юникода находим отдельный раздел о последовательностях emoji, в котором говорится о том, как должны быть реализованы последовательности, и все оказывается достаточно просто.
Последовательность может быть составлена по следующей формуле
emoji_sequence :=
emoji_core_sequence
| emoji_zwj_sequence
| emoji_tag_sequence
# по пунктам
emoji_core_sequence :=
emoji_character
| emoji_presentation_sequence
| emoji_keycap_sequence
| emoji_modifier_sequence
| emoji_flag_sequence
emoji_presentation_sequence :=
emoji_character emoji_presentation_selector
emoji_presentation_selector := \x{FE0F}
emoji_keycap_sequence := [0-9#*] \x{FE0F 20E3}
emoji_modifier_sequence :=
emoji_modifier_base emoji_modifier
emoji_modifier_base := \p{Emoji_Modifier_Base}
emoji_modifier := \p{Emoji_Modifier}
# к этому вернемся чуть позже
emoji_flag_sequence :=
regional_indicator regional_indicator
regional_indicator := \p{Regional_Indicator}
emoji_zwj_sequence :=
emoji_zwj_element ( ZWJ emoji_zwj_element )+
emoji_zwj_element :=
emoji_character
| emoji_presentation_sequence
| emoji_modifier_sequence
emoji_tag_sequence :=
tag_base tag_spec tag_term
tag_base :=
emoji_character
| emoji_modifier_sequence
| emoji_presentation_sequence
tag_spec := [\x{E0020}-\x{E007E}]+
tag_term := \x{E007F}
В принципе, этого уже достаточно, чтобы грамотно(нет) составить регулярное выражение, но еще немного слов про юникод.
Unicode Categories
В юникоде определены категории, используя которые мы можем в регулярных выражениях находить, например, все заглавные буквы, или, например, все буквы латинского алфавита. Более подробно со списком можно ознакомиться здесь. Что важно для нас: в стандарте определены категории для emoji: {Emoji}, {Emoji_Presentation}, {Emoji_Modifier}, {Emoji_Modifier_Base}, и казалось бы, все хорошо, давайте использовать, но в реализацию ECMAScript они еще не вошли. Точнее — вошла только одна категория — {Emoji}
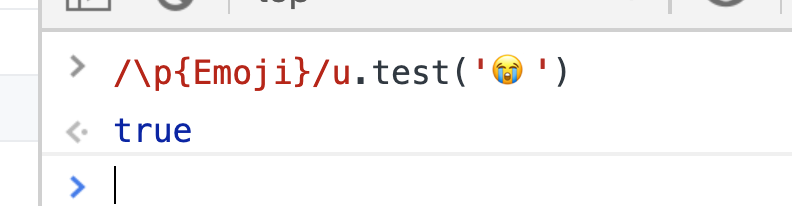
Остальные на данный момент находятся на рассмотрении в tc-39 (stage-2 на момент 10.04.2019).
«Что ж, придется писать регулярку» — подумал и примерно через час мой бывший коллега кидает мне ссылку на гитхаб github.com/mathiasbynens/emoji-regex, ну да, на гитхабе всегда найдется то, что ты только собирался написать… А жаль, но речь не об этом… Библиотека реализует и импортирует регулярное выражение для поиска эмоджи, в принципе то что надо! Наконец то можно попробовать написать реализацию нужной нам функции!
const emojiRegex = require('emoji-regex');
const regex = emojiRegex();
function stringReverse(string) {
let match;
const emojis = [];
const separator = `unique_separator_${Math.random()}`;
const reversedSeparator = [...separator].reverse().join('');
while (match = regex.exec(string)) {
const emoji = match[0];
emojis.push(emoji);
}
return [...string.replace(regex, separator)].reverse().join('').replace(new RegExp(reversedSeparator, 'gm'), () => emojis.pop());
}

Подводя небольшой итог
Я обожаю задачи со "специальной" олимпиады, они заставляют меня узнавать что-то новое, каждый раз расширяя границы знаний. Я не понимаю людей, которые говорят: «Я не понимаю, зачем нужно знать, что null >= 0? Мне это не пригодится!». Пригодится, 100% пригодится, в тот момент, когда ты будешь выяснять причину того-или иного явления — ты прокачаешь себя, как программиста и станешь лучше. Не лучше кого-то, а лучше себя, который еще пару часов назад не знал, как решить какую-то задачу.
Спасибо за прочтение, всем спасибо, буду рад любым комментариям.
Необходимый постскриптум:
Все сломала буква \u{0415}\u{0308}. Это буква ё, состоящая из 2х символов, оказывается в стандарте юникода есть вариант объединения не только emoji, но и просто символов… Но это — совсем другая история.
UPD: Речь идет не о букве «Ё», а о сочетании 2х символов Юникода u{0415}(Е) и u{0308}("?), которые идя друг за другом образуют последовательность юникода и мы видим букву «Ё» на экране.
Комментарии (379)

Danil1404
10.04.2019 20:08+5оказывается в стандарте юникода есть вариант объединения не только emoji, но и просто символов
Подождите. Я ведь правильно понимаю, что точки над 'ё' — это типичная диакритика, и если ваш алгоритм не работает с 'ё', то он также сломается на «и?» (и + ?) и скорее всего не работает с банальными немецким и французским?
Неужели эмодзи используются настолько более часто, чем диакритика?
drch Автор
10.04.2019 21:45+1Я немного ввел в заблуждение, простите. Речь идет не о букве "Ё", а о сочетании 2х символов Юникода u{0415}(Е) и u{0308}("?), которые идя друг за другом образуют последовательность юникода и мы видим букву "Ё" на экране.
\u{0415}\u{0308}' === 'Ё' // false
Alexufo
10.04.2019 23:31Попробуйте тест на арабском нет "??"

balsoft
12.04.2019 00:44Prelude> no = "??" Prelude> putStrLn $ reverse no ?? Prelude> putStrLn $ reverse $ reverse no ?? Prelude> putStrLn $ reverse $ reverse ("Торт " ++ no ++ " Habr") Торт ?? Habr Prelude> putStrLn $ reverse ("Торт" ++ no ++ " Habr") rbaH ?? троТ
Люблю нормальные, продуманные языки.

PsyHaSTe
12.04.2019 01:17Вопрос не а языке, а в библиотеке. С тем же успехом
pub fn reverse(input: &str) -> String { UnicodeSegmentation::graphemes(input, true).rev().collect() }

Serge3leo
11.04.2019 02:18Это вполне себе нормальная и, местами, даже типичная буква 'Ё'! Есть платформы, которые нормализуют Unicode к NFC, например, Windows, на них 'Ё' обычно один символ. А есть платформы, которые нормализуют к NFD, например, macOS, там 'Ё' обычно два символа.

Lynn
11.04.2019 22:38+2И за это разработчиков макос хочется больно пинать ногами
Serge3leo
11.04.2019 23:14Хочется, не хочется, вопрос личный. А вот Линуса нашего Торвальдса и компанию обязательно! 21 век на дворе, а файловые системы Linux поддерживают не Unicode, а хрен знает что (набор байтов и граблей):
[user@linux ~]$ ls -l /tmp/у*
-rw-r--r-- 1 leo staff 31415 апр 11 23:02 /tmp/уй
-rw-r--r-- 1 leo staff 271828 апр 11 22:57 /tmp/уй
К стати, выбор нормализации NFD, принятый в HFS+ обеспечивает наискорейшее обнаружение ошибок работы с файлами в приложениях. Впрочем и NFС неплох, но не так как в Linux это ж точно.Lynn
11.04.2019 23:25+3Они как раз не занимаются всякой самодеятельностью, а пишут байты как передали.
Serge3leo
11.04.2019 23:29-1И это приводило, приводит и будет приводить к труднообнаружимым глюкам и проблемам с безопасностью. Пока не сделают как все нормальные люди на них клеймо.
P.S. Например, habr нормализовал по NFD UTF8 результаты ls и один из этих файлов стал «недоступен». Мало того, ключи ls '-q' или '-b' не изменяют выдачу, т.к. считают значок «кратка» печатным символом.balsoft
12.04.2019 00:34+3Нет уж, кушайте ваши какашки нормализованные сами. Нормализация ещё приемлима в human-to-human интерфейсах, когда машине не нужно интерпретировать текст. В машиночитаемых интерфейсах нормализация неприемлима, ибо она приведёт к ещё более огромной куче проблем и несовместимостей. Как байты записаны — так должны быть и прочитаны, точка. Хумансы для себя должны реализовать удобные средства различения этих байтов — тут не поспоришь.
Serge3leo
12.04.2019 00:57Файловая система, либо поддерживает Unicode, либо нет, если поддерживает, то должна обеспечивать нормализацию. Скажем, ZFS (Solaris, FreeBSD) поддерживает, NTFS (Windows) поддерживает, HFS+ поддерживает (macOS).
А подход файловых систем Linux — набор байтов, это набор граблей.balsoft
12.04.2019 01:05Набор граблей — это когда я записал одни байты, потом прочитал из того же места байты и сравнил с имеющимися у себя. Что дальше? Дальше — исключения, сегфолты или вообще heartbleed, если у нас ФС отнормализовала текст, или всё работает as expected, если не нормализовала.
Serge3leo
12.04.2019 01:09Куда записал? Имя файла, это не место для записи байт, это «имя файла». Кодируется в URL так, человеку показывается этак и т.п. Плюс обязательная возможность задания образцов поиска, удобных для человека. В половине систем оно вообще нечувствительно к регистру символов, и имеет формы зависящее от языка текущего пользователя.
Место для записи байт — бинарный файл.balsoft
12.04.2019 01:25+1Ну так пусть инструмент, занимающийся поиском и нормализует (во всех понятиях этого слова)! Зачем здесь ФС-то приплетать?
Имя файла — это просто поле в его метаданных, и в него можно (и иногда нужно) записывать байты. Мне правда нужно привести пример кода, который будет в абсолютно неочевидном месте сегфолтится из-за нормализации?PsyHaSTe
12.04.2019 01:36Тогда весь софт который хочет работать с файлами должен его нормализовывать самостоятельно. Мы же программисты, зачем нам копировать одно и то же поведение из программы в программу? Может пусть этим все же единая точа занимается?..
balsoft
12.04.2019 01:40Затем, что когда ФС нормализует имена файлов, весь (повторяю, весь) софт, работающий с этой ФС, тоже обязан их нормализовать — иначе кровькишки. Если ФС не нормализует — у нас есть выбор. Для вынесения функционала нормализации можно использовать, например, библиотеки.
Serge3leo
12.04.2019 01:49Вот с чего бы «тоже обязан их нормализовать»? Например, с прошлого века большинство систем имеют ФС с именами, которые не зависят от регистра. Как-то без «кровькишки» обходимся.
Так же как и не одно десятилетие работаем с ФС, у которых имена с разной нормализацией Unicode, а так же без нормализации Unicode гарантировано означают один и тот же файл. И тоже без «кровькишки» обходимся.
В чём проблема?balsoft
12.04.2019 02:00Без «кровькишки», говорите? Первое, что вспомнилось (и что очень больно пнуло меня, когда приходилось подрабатывать вебдевом): github.com/jprichardson/node-fs-extra/issues/565
Сейчас ссылок не дам, но точно вам говорю: кровькишки регулярно встречаются. Особенно, когда привык к идеологии «что прочитал — то и записал». Возможно, это деформация линуксоидов какая-то :)Serge3leo
12.04.2019 02:08Не деформация, детская болезнь, через это многие системы прошли. Мне так кажется.
Встречаются же POSIX системы c EBCDIC именами файлов и locale (z/OS), где даже ASCII — бинарные файлы и невозможные имена. Поэтому инсталляторы Java приложений и jar архивы нужно делать не абы как, а в строгом соответствие со стандартами Java.balsoft
12.04.2019 02:35+1Даже если это болезнь, от неё никуда уже не убежишь. Linux прочно закрепился в истории человечества как одна из самых популярных ОС (в широком смысле слова). Менять в нём стандарт сейчас, а не пятнадцать лет назад — уже поздновато. Смена фс на case-insensetive или нормализующую юникод сломает тысячи приложений и миллионы строк кода. Кто будет это чинить?
Для осознания масштабов поломки, можете попробовать сделать
C:\case-sensetive и не-нормализующей.Serge3leo
12.04.2019 02:44Многие прошли через это. Не проблема, ни сейчас, ни в будущем. Рано ли поздно это неизбежно произойдёт, я так думаю.
«Смена фс на case-insensetive или нормализующую юникод сломает тысячи приложений и миллионы строк кода. Кто будет это чинить?» — linux подсистема Windows является ubuntu и глючит не больше оригинального ubuntu.
Отключить нормализацию на C:\ — тоже без проблем, гарантировано.
P.S.
Ну по популярности, в форме Android — да ;)balsoft
12.04.2019 02:53+1linux подсистема Windows является ubuntu и глючит не больше оригинального ubuntu.
Только вот она и не нормализует названия файлов. https://github.com/Microsoft/WSL/issues/1820
Serge3leo
12.04.2019 01:38Жизнь покажет, думаю и Linux, рано или поздно, тоже придёт к Unicode в файловых системах.
Нет, конечно, можно в ФС ничего не делать, а требовать от всех приложений что б они все идентично нормализовали имена сами ;) Как это сейчас в Linux и происходит, что и позволяет более менее сносно жить. Но такой подход как раз и является тем самым набором граблей ;)
P.S. А ошибки переполнения буферов в неправильных программах они завсегда были и ещё долго будут, причём, что при работе с «вашими» наборами байт, что при работе с нормальными именами Unicode.balsoft
12.04.2019 01:48+2Ну тогда объявляем примерно весь софт под Linux "неправильным" — он ведь опирается на предположение, что читает то же самое, что и пишет.
требовать от всех приложений что б они все идентично нормализовали имена сами
Нет, в случае, когда ФС не лезет не в своё дело, каждая софтина может выбрать свой способ нормализации и он будет работать. Да, мы можем создать два "уй" — файла, но зато мы не требуем от каждого приложения заниматься нормализацией всех UTF-строк, которые потенциально могут оказаться в имени файла.
Serge3leo
12.04.2019 02:00Почему «весь софт под Linux неправильный»? Большинство приложений работающих под Linux отлично работают и под Solaris, FreeBSD, macOS и Windows, поскольку они не опираются на неестественное предположение об именах файлов: «что читает то же самое, что и пишет».
Каким боком выше перечисленные системы требуют у каждого приложения заниматься нормализацией? А? По какому имени файл создал, по такому же его и открыть можно ж и т.п. (да, его же можно открыть и по другим именам, эквивалентным данному имени, но почти для всё приложений это не проблема ж)
Некоторое понимание в делах независимости имён файлов от регистра символов или нормализации требуется лишь небольшому числу приложений, например, cvs или svn.balsoft
12.04.2019 02:07(да, его же можно открыть и по другим именам, эквивалентным данному имени, но почти для всё приложений это не проблема ж)
А ещё его можно попытаться поискать в листинге, например. Возникает проблемка, не так ли?
Serge3leo
12.04.2019 02:20У большинства приложений наоборот, исчезает проблемка. За исключением, ясен перец, выше поименованных исключений.
DistortNeo
12.04.2019 10:40NTFS (Windows) поддерживает
Как раз NTFS вообще ничего не поддерживает, кроме
регистронезависимости. Для него имя файла — это UCS-2. Попробовал создать два файла: и?.txt и й.txt. Прекрасно создались.
А подход файловых систем Linux — набор байтов, это набор граблей.
Я всегда считал, что Unicode — это набор граблей. Это стандарт, который постоянно дополняется и который невозможно реализовать полностью. Плюс затраты процессорного времени на нормализацию.
Так что подход Linux я считаю более адекватным.
Kobalt_x
12.04.2019 17:38>Как раз NTFS вообще ничего не поддерживает, кроме
регистронезависимости.
Регистронезависимость это фича Win32 а не NTFS, причем отключаемая фича.DistortNeo
12.04.2019 20:57Регистронезависимость это фича Win32 а не NTFS, причем отключаемая фича.
Нет. Регистронезависимость — это атрибут директории (кстати, завезли совсем недавно).
В NTFS директория представляется в виде B-TREE, причём ключами этого двоичного дерева являются преобразованные имена файлов (в рассматриваемом случае — преобразованные в lowercase), а чтобы добраться до реального имени файла, нужно лезть в атрибуты записи. Именно возможность быстрого регистронезависимого поиска и позволяет говорить о регистронезависимости NTFS.
P.S. Так-то аболютно любая ФС может быть и регистро-зависимой, и регистро-независимой. Всё зависит от драйвера ФС.
khim
12.04.2019 21:53Регистронезависимость — это атрибут директории (кстати, завезли совсем недавно).
Атрибут директории завезли недавно, флаг в реестре — скорее всего в прошлом веке. Сейчас на Microsoft документацию для Windows NT и даже Windows XP отыскать сложно, но вот тут говорится, что проблема с Case Sensitivity пофикшены в версях .NET 2.0 (sic!), выпущенных после 2006го — а это значит что поддержка явно старше, раз в 2006м (то есть до выхода Windows Vista) её уже фиксили…soniq
14.04.2019 13:43+1Это .net фиксили. Он же не только на винде работает.
А винду чинили в прошлом году только, тогда и флаги привезли все, и ключи.

domix32
11.04.2019 12:18R???????????I?????????????D???????????D??????????L??????????E???????? ?????????M????????????E???????????? ?????????T???????H???????????I???????????S????????????

sindzicat
12.04.2019 15:24Как вы это сделали? Расскажите! Интересно!)
domix32
12.04.2019 22:36Кучка комбинирующих диакритиков накладываются друг на друга и в итоге в рисуются над или под символом. Немного js и готово. В итоге народ делает сервисы которые пилят к?р?и?по?в?ый текст. eeemo.net самый легкий, есть и другие, которые попутно могут еще и перевернутый / перечеркнутый / эмоджифицированный текст сделать или какой-нибудь ascii-графикой вывести.
Serge3leo
11.04.2019 02:29Да, на macOS на имени файла 'уй' алгоритм тоже точно сломается. Для Unix/Linux/Windows вероятность поломки невелика есть, если только не использовать unorm, `iconv -t utf-8-mac' или иных явных средств нормализации Unicode.




AllexIn
10.04.2019 20:18+28Внезапно, оказывается, если в строке левая кодировка, то нужно обрабатывать эту левую кодировку.
ВОТ ЭТО ПОВОРОТ.
Да, реверс строки сломается если в строке не строка.И?
А еще меня как Сипипишника ввело в недоумение вот это утверждение:
самым оптимальным для себя я долго считал такое решение:
const strReverse = str => str.split('').reverse().join('');
split и join — это эффективно? Эффективнее чем тупо перебрать половину строки и сплитнуть руками с другой половиной? Ладно, нет возможности модифицировать строку. Но что мешает без сплита сразу писать в массив и его конвертировать в строку? Разве это не будет эффективнее?
Я бы охерел, если бы на вакансию С++ программиста кто-то для реверса строки сначала её в отдельный список/массив конвертировал.
Если в вебе это норма — не удивительно что у нас всё так плохо в браузерах.
Если я не прав в своих суждения — расскажите пожалуйста почему автор считает такой подход правильным и наиболее эффективным.tbl
10.04.2019 20:37+5Там еще и эффективными считаются цепочки из операций filter/map над массивами, которые порождают промежуточные массивы.
staticlab
11.04.2019 11:23Я бы уточнил, что эффективными в разрезе «производительность — стоимость поддержки».

Carduelis
11.04.2019 16:05+1Вообще, насколько мне известно, трюк с
— это что-то вроде шутки в рамках контекста такой задачи..split().reverse().join()
Удивительно, что автор посчитал этот ответ зачетным.nikandr23
11.04.2019 18:46+1ну и потом автор рассказывает что _В_ТОМ_ЯЗЫКЕ_ split() вообщем то неправильно сплитит…

GRaAL
10.04.2019 20:38+9Автор не использовал слово «эффективно». Автор использовал слово «оптимально» без указания критерия оптимальности. Возьмусь предположить, что имелось ввиду «оптимальное по размеру кода и очевидности».
AllexIn
10.04.2019 20:51+4ну так можно дойти до того, что у эффективности тоже не указаны критерии.
эффективно по количеству символов в решении? по количеству затраченного времени? по стоимости часа программиста способного это написать?
Так что ваш довод не принимается. Если заменить в моем тексте слово «эффективно» на «оптимально» суть ни на грамм не поменяется.GRaAL
10.04.2019 21:02+2split и join — это эффективно? Эффективнее чем тупо перебрать половину строки и сплитнуть руками с другой половиной?
Из вашего ответа следует, что вы оцениваете производительность решения. Автор же явно имел ввиду другие критерии. Грубо говоря ваш диалог выглядит так:
Автор: вот короткое решение
Вы: разве это быстрое решение?AllexIn
10.04.2019 21:04+2Разве короткость — это оптимальный критерий для оценки тестового задания?
alexs0ff
10.04.2019 21:17+3В данном случае, java script не предназначен для поиска оптимального решения задачи реверса строк по количеству необходимых операций и размера памяти, а просто демонстрирует способность кандидата использовать стандартные вещи из JS.
В питоне реверс массива выглядит еще короче, что-то типа myarray[::-1], как там «под капотом устроено» нужно смотреть дополнительно.
А вот в c++, данная задача хороший индикатор на некоторую адекватность разработчика. Ну просто не всегда нужно мыслить терминами одного инструмента при использовании другого, тем более они предназначены для разных задач.AllexIn
10.04.2019 21:19+4А вам не кажется что такой подход является причиной того, что веб такое днище в плане потребления памяти и производительности?
Я часто слышу что JS гавно. Но здесь я вижу не проблему языка, а проблему выбора решения внутри языка.alexs0ff
10.04.2019 21:43что JS гавно
Смотря с какой точки зрения.
Производительность, потребление памяти, отсутствие нормальной мультипоточности (да я знаю про webworkers) по сравнению с более низкоуровневыми языками — да я тут согласен.
Но, если смотреть на порог вхождения, умение упрощать некоторые оплошности, отсутствие зубодробительных практик из того же С++ (я про указатели, наследование, темплейты, виртуальные деструкторы и т.д.), он почти идеальный кандидат для массового применения в действительно областях, где требуется большое количество разработчиков. На мой взгляд очевидно, что сайтов бизнесу можно куда больше и быстрее написать на javascript, чем на c++.goldrobot
11.04.2019 11:05C++ в разы проще чем весь этот треш типа пизонов перлов джсов и т.д.
Что написал — то получил. Любое действие можно разобрать до минимальных шагов, а не спотыкаться. А стандартные библиотеки подняли «низкоуровневость» С++ до «среднеуровнего» благодаря своим алгоритмам и контейнерам.
В то же время, я садясь за питон, чуть волосы на голове не вырвал по началу. Он мне понравился, но на сколько же он сложен. По переменной не понятно что она такое. Каждый объект может иметь внутри произвольные переменные. Нет ни удобных указателей что бы изменить внутри функции значение аргумента, или что бы хотя бы не копировать этот аргумент каждый раз.
Деструкторы, наследование, указатели, вот это все есть либо в неявном виде (нужно понимать как работают эти ссылко-указатели в языке) до явного когда деструктор это метод «Деинит» который закрывает соединение корректно, или еще-что то.
В итоге все тоже самое, только в куче.
Хоть и быстрее писать после изучения, не спорю, но «неопределенность» модных в бизнесе языков сильно повышает порог вхождения в программирование в целом
Kanut
11.04.2019 11:19C++ в разы проще чем весь этот треш типа пизонов перлов джсов и т.д.
Это вопрос привычки. Для того кто всю жизнь писал на С++ кажется что он проще, для того кто писал на javascript чтo javascript.
А возьмите человека который пишет на java или C#, так для него что С++, что javascript это неудобный адовый ад.
rmuskovets
11.04.2019 21:15Я пишу на жабе, и вы частично неправы:
С++ для меня ад, а скрипты очень даже хороши…
Hardcoin
11.04.2019 13:30удобных указателей что бы изменить внутри функции значение аргумента
Вообще-то объекты передаются по ссылке. Вы легко можете их изменить внутри функции, но ничего хорошего в таком подходе нет.
С++ не проще. Он сложнее. Писать на нем дольше (вы и сами с этим согласны). Да, он даёт бОльший контроль за некоторыми вещами, но этот контроль часто не нужен. Вы же не контролируете из С++ переключение вентилей напрямую? Абстракции — это крайне полезное изобретение человечества.
goldrobot
11.04.2019 17:30+1Простые объекты не передаются по ссылке, если мы про питон. Кроме того, сделав внутри функции objectExt=objectNew вы принимаемый аргумент не измените и вообще потеряете, по сути, из виду.
Как не проще, если С++ предлагает вам почти тот же уровень абстракций, как и «простые» языки, и, если нужно позволяет вам опуститься на уровень ниже. Разве не это простота?
Для того что бы писать на «простом» языке больше чем HW, нужно все так же понимать как он внутри работает и использовать все теже фичи, что вы будете использовать и в С++. Нужно так же знать что такое ссылка, что такое указатель, без этого никуда не уедешь. Нужно понимать чем List=List+AnotherList (опять питон) будет отличаться от list.extend(AnotherList). Понимать как в зависимости от контекекста происходит каст одного типа к другому, и как будут операторы работать (JS?). Как происходит наследование, что за self. такой вообще. И многое другое.
Не нужно исключать работу с классами и объектами которые зависят от их контекста. Таже библиотека «таблиц» Pandas питоновская. Что бы понять в каком виде она приходит тебе, нужно взять все что происходит с ней до этого, причем я сейчас про структуру (колонки их типы, их названия), а не значения. В С++, если мне не нужна супер пупер гибкость на шаблонах, любой новичек сможет ткнув в структуру понять как она выглядит и какие типы содержит, и при написании кода IDE никогда не позволит ему забыть что там есть благодаря подсказкам.
В С++ все с этим проще, все работает намного более явно. А ногу отстрелить не в пример сложнее, достаточно забыть про с98 и перейти на сxx14+ с shared_ptr.
>Писать на нем дольше (вы и сами с этим согласны).
Да, и не так гибко (если вы не гуру шаблонов). Однако не сложнее точно.Hardcoin
11.04.2019 18:38+1Кроме того, сделав внутри функции objectExt=objectNew вы принимаемый аргумент не измените и вообще потеряете
Это крайне правильно. В идеальном мире объект, передаваемый в качестве аргумента, вообще нельзя поменять, это не сделано просто по соображениям производительности, а не как фича. То, что вы преподносите как плюс (возможность менять аргументы изнутри функции) — это просто плохой стиль написания кода.
если С++ предлагает вам почти тот же уровень абстракций
Почему под веб пишут на php и питоне, если С++ по вашим словам не хуже и гибче? Библиотеки? Половина их написана на си, так почему их пишут на си для питона и php, а не для самого си?
Я не буду предполагать, что разработчики идиоты или сумасшедшие и просто не догадываются, что си++ для их целей лучше. Наоборот, разработчики в среднем обладают высоким интеллектом. И если они (и я в том числе) используют php и питон для веба, значит есть преимущества.
И они на самом деле есть. Мне абсолютно точно не нужно прямое управление памятью, когда я делаю какой-то веб-сервис. Отсутствие такого управления — это преимущество, ускоряющее разработку и облегчающее поддержку старого кода. Потому что обязательно найдется кто-то, кто захочет памятью по-управлять. И если он не сможет этого сделать, значит он не подложит мне мину замедленного действия.
goldrobot
11.04.2019 18:55Это крайне правильно. В идеальном мире объект, передаваемый в качестве аргумента, вообще нельзя поменять
Что, простите? Откуда это странное утверждение появилось?
Почему под веб пишут на php и питоне, если С++ по вашим словам не хуже и гибче?
Покажите пожалуйста где я написал что С++ гибче? Я помойму такого не говорил, а наоборот даже утверждал обратное?
А пишется потому что «простые» языки дают возможность писать гибче и быстрее.
Хочу обратить внимание, мы с вами изначально говорили не о скорости и гибкости, а о простоте. Не нужно смещать фокус, о том что быстрее будет накалякать на динамическом интерпретируемом языке я не спорю.Hardcoin
11.04.2019 19:19Откуда это странное утверждение появилось?
Не все вещи, которые вам кажутся странными, на самом деле такими являются. Чистые функции считаются хорошей практикой. А грязные — ведут к неожиданным багам.
Изменение аргумента функции — это побочный эффект. Такая функция не является чистой.
Это, конечно, не закон природы. Вы вполне можете быть с этим не согласны и писать грязные функции, если хотите. Но чистые или хотя бы не имеющие побочных эффектов функции, повторюсь, очень многими программистами считаются хорошей практикой.
Как пример — в JavaScript есть линтер, ESLint. При попытке изменить аргумент функции он выдает предупреждение.
goldrobot
11.04.2019 20:01-2А какую-то аргументацию к этому, извините, бреду, можно услышать?
Очень многими програмистами считается хорошей практикой «тяп-ляп и в продакшен», поэтому это очень слабый аргумент.Hardcoin
11.04.2019 20:12+2Просьба без истерик. Если у вас есть доводы, что чистые функции "бред", буду рад их услышать. Забавно, что вы не сказали "чистые функции — плохо", вы сказали "бред". Бессмысленное, вздорное, несвязное. Вместо того, что бы загуглить "что такое чистые функции", вы сразу назвали их бессмысленным вздором. Очень забавно.
Если вам нужна аргументация к тезисам, скажите к каким. "Функция с побочными аргументами не считается чистой" — это нужно как-то аргументировать или вы этот "бред" просто в Википедии проверите?
goldrobot
11.04.2019 20:35Эм?
У вас с чтением большие проблемы. Мы говорили о простоте, вы свели к скорости написания кода. И сейчас, опять, вы совсем другое читаете, ведь очевидно что не существование термина чистые функции — бред, термина который даже в институтах преподают, а теория о превосходстве использования только чистых функций.
И вы первый об этом написали, о том что писать на чистых функциях лучше, поэтому и флаг вам в руки в первом шаге аргументации.Hardcoin
11.04.2019 21:13Совсем другое дело. Вы просто не согласны с тем, что чистые функции — хорошо. Ни о каком "бреде" речь уже не идёт.
Вот только не я высказал этот тезис первым. Аргументацию вы можете легко нагуглить, какой смысл в том, что бы я её сюда копировал? Как вы сами сказали, чистые функции даже в институте преподают, значит и их пользу рассказывают.
Пересказывать не вижу смысла, зачем это мне и вам? Тратить время на набор текста. Если вам хочется использовать чистые функции по-реже и постоянно менять аргументы функций, если вы любите побочные эффекты (предположим) — это полностью ваше дело. И тех, для кого вы пишете код.
А поймать меня на слове "только" не получится. У нас же не идеальный мир, поэтому хаскель никогда не станет самым популярным языком.
goldrobot
11.04.2019 21:26-1Почему же не идет речи, если «чистые функции есть хорошо» — бред как он есть?
Это крайне правильно. В идеальном мире объект, передаваемый в качестве аргумента, вообще нельзя поменять, это не сделано просто по соображениям производительности, а не как фича.
Это написали вы. А теперь отправляете в гугл. Удобно.
К слову, идеальный мир, в котором нельзя менять аргумент и будет мир в котором «только» чистые функции. Так что, поймал, хехе.Hardcoin
11.04.2019 21:53+1Так что, поймал, хехе.
Какой ужас. Давайте ещё раз повторю, что наш мир не идеален. А тезис относится только к идеальному миру. В нашем мире грязные функции приемлимы, иногда их нельзя избежать.
бред как он есть?
Удачи вам с таким уровнем ведения диалога. Назовите любой тезис оппонента "бредом" и вам не придется приводить своих доводов. Очень удобно, всегда в выигрыше. Но интереса в этом нет.
balsoft
12.04.2019 00:52В нашем мире грязные функции приемлимы, иногда их нельзя избежать.
На чистых функциональных языках программиста избавляют от этой мучительной муки — грязные функции там только в рантайме языка.

Keyten
11.04.2019 02:45Если вы хороший разработчик, вы оптимизируете правильные места.
Это поиск баланса между читаемостью и эффективностью. Если вам нужно реверснуть небольшую строку, то сплит-реверс-джоин работает так же быстро, как и что угодно ещё — там разница на уровне пары миллисекунд. При этом смысл кода понимается беглым взглядом, меньше, чем за секунду. Давайте напишем цикл:
var str = '12345'; var reversed = ''; var l = str.length; while(l--){ reversed += str[l]; }
— и чтобы понять, что делает этот код, понадобится секунд 5.
И так везде. Если вы пишете очень критичное место (вроде сравнения v-dom в таблице на миллион пунктов), то да, его нужно оптимизировать всеми силами и средствами, потому что какая–нибудь мелочь может привести к разницы в полсекунды. Если разницы нет, то и смысла нет — выбирайте, что читаемее.khim
11.04.2019 03:10Не работает этот так. Ну вот просто не работает. Если вы используете неэффективный алгоритм и медленно работающий код — то результатом будет новый GMail. Жрущий на порядок (если не на два) больше ресурсов, чем версия 10-15 летней давности и не дающий при этом никаких новых возможностей!
Keyten
11.04.2019 03:36Если у вас есть массив из 4 элементов, и вы по кнопке его сортируете, то сортируйте хоть перебором, 24 перестановки комп переберёт почти так же быстро, как и отсортирует пузырьком. Место не критичное.
Медленно работающий гмейл — это результат того, что плохой код в критичном месте, понимаете? Критичные места — это то, что нужно оптимизировать.khim
11.04.2019 04:23Критичные места — это то, что нужно оптимизировать.
Если вы прочитаете соответствующую статью, то обнаружите, что… миф таки остался мифом. Судя по тому, что что там осталась куча метрик — критичные места там диагностировались и оптимизировались. Результат — тормоза и дикое потребление памяти.
Медленно работающий гмейл — это результат того, что плохой код в критичном месте, понимаете?
Нет — не понимаю. Более того — не понимаю категорически. Я ещё ни разу не видел ситуации, когда «феншуйный» год, который писали думая об «идеоматичности», «гибкости» и прочим разным баззвордам (но не об эффективности) после оптимизации работал бы хотя сравнимо по скорости с кодом, который писали изначально думая-таки об эффективности.
Если у вас есть массив из 4 элементов, и вы по кнопке его сортируете, то сортируйте хоть перебором, 24 перестановки комп переберёт почти так же быстро, как и отсортирует пузырьком. Место не критичное.
Рассуждение кажется разумным — но он в корне неверно. Ибо предполагает, что вы знаете заранее что там будет 4 элемента. А их там может оказаться, в результате работы какого-нибудь «дезигнера» и 44 и 444444 — ничего заранее предскзать нельзя, если не контролировать что вы делаете на всех этапах.
Я с этим сталкивался неоднократно: когда меня просят что-то оптимизировать и я разрушаю «весь феншуй» путём превращения кода из «торта Наполеон» в 100500 слоёв в что-то гораздо менее «феншуйное» — то у меня часто спрашивают о том, как я собираюсь это профайлить и откуда у меня будет вылезать статистика… и вы знаете… я обычно вообще не собираюсь об этом думать. Того факта, что версия «не по феншую» работает в 3-5-10 раз быстрее оптимизированной в «критических местах» «феншуйной» версии — обычно оказывается достаточно.
P.S. Это, кстати, не значит, что я совсем никогда не пользуюсь профайлером. Это было бы глупо. Но важно всегда понимать заранее — где у вас в программе неэффективности… тогда профайлер подскажет вам — какие из них реально влияют на код, а какие — нет. Если же вы списка неэффективностей не имеете — можете хоть упрофайлится, результатом будет GMail.AlexSky
11.04.2019 08:29Например, есть задача — отсортировать массив интерфейсов устройства USB при обработке события втыкания этого устройства. Вы туда что, квиксорт бы стали пихать?
j8kin
11.04.2019 11:42В этом случае я бы не соритировку писал бы, а пихал бы уже в отортированном порядке.
И вообще может задача найти первый отсортированный, тогда можно не доводить сортировку до конца, а сделать сортировку кучей которая после первого этапа имеет «наверху» самый большой элемент.
0xd34df00d
11.04.2019 15:53И вообще может задача найти первый отсортированный, тогда можно не доводить сортировку до конца, а сделать сортировку кучей которая после первого этапа имеет «наверху» самый большой элемент.
Это вы так поиск минимального или максимального элемента бы так делали?
j8kin
11.04.2019 16:28Конечно нет))) Сортировку кучей хорошо применять, когда не нужно сортировать все, а нужно скажем первые 10 самых маленьких/больших из большого массива данных, т.е. сортировать каждый раз полностью массив данных не требуется, в этом случае сортировка кучей хороша и это будет работать быстрее чем сортировать каждый раз той же быстрой соритровкой.
Если смысл именно найти наибольший, то естественно нет смысла. Наиболее разумно либо класть уже в отсортированном порядке либо класть в конец и вызывать сортировку кучей, если предваритель но массив уже был кучей, то установка нового элемента в нужное место кучи будет быстрой. короче это хороший способ если периодически требуется выдавать несколько самых больших/маленьких элементов, переодически вставляя значения.
AlexSky
12.04.2019 10:15На входе — несортированный список интерфейсов, прилетающий из другой либы. Надо выводить отсортированный список, плюс требуется последовательно пройтись по интерфейсам, найдя первый, удовлетворяющий определенным критериям.
j8kin
12.04.2019 12:13В изначальном вопросе не было сообщения, что массив прилетает из вне.
Исходя из нового описания, без сортировки не обойтись за счет плюса и требования отдавать полностью отсортированный список, а вот если отсортированный список не нужно, а нужно только вернуть записи по критерию, то можно пробежать один раз без сортировки.
Можно в принципе передалать архитектуру, чтобы при подключении/отключени устройства к нам прилетало это событие и мы внутри себя уже хранили бы отсортированный списк, тогда сортировку проводить каждый раз было бы не надо и надо было бы выбрать по критерию и вернуть уже хранимый нами отсортированный список.

nobodyhave
11.04.2019 16:09Почему нет? Правильно написанный квиксорт для небольших размеров подмассивов использует сортировку вставками.
Как результат у нас будут эффективно сортироваться как маленькие массивы, так и большие.
red_andr
11.04.2019 17:06Тогда это уже не квиксорт, а какой то гибридный вариант сортировки. И да, он будет больше и сложнее каждого из этих алгоритмов. Я уж не говорю о том, что для однократной сортировки очень маленьких размеров данных вообще пофиг какой алгоритм выбрать.
j8kin
11.04.2019 17:11Почти во всех библиотеках он именно так и реализован для того, чтобы убыстрить его. Вызывая его совершенно не важно, что он гибридный. Это уже давно так. Нужен чистый — пиши свой, но зачем? Мне, например, бетчера нравится из-за того, что его отлично можно распаралелить.
AlexSky
12.04.2019 10:18Зачем тратить время на реализацию квиксорта для десятка записей, которые сортируются один раз при втыкании устройства USB? Какой в этом смысл? Сделать определение устройства не 15 секунд, а 14.999999?
nobodyhave
12.04.2019 12:04А зачем его тратить? Квиксорт есть в стандартной либе многих языков. В той же жабе как раз таки со встроенной сортировкой вставками. Вот если его нету, тогда другой вопрос. Хотя опять же, простой вариант квиксорта пишется примерно за столько же, за сколько и сортировка вставками/выбором/пузырьком. Может на 5 минут дольше. И это если лень залезть в гугл и найти имплементацию например того же Седжвика.

abar
11.04.2019 12:51Всё это очень здорово, но представте что «не феншуйно, но зато быстро» пишете не Вы, а вчерашний студент, который старается так, как может. Потом пару лет этот код поддерживает команда из нескольких человек с разным уровнем навыков — джависты, эс-ку-эльщики, заскучавший скрам-мастер, который решил что ему между многочисленными митингами неплохо бы и в программировании поупражняться… При этом на команду давят со сроками, поэтому обновлять документацию времени нет, а юнит-тесты поддерживаются лишь так, чтоб те своими падениями не мешали бы деплою.
После чего этот код переходит Вам и Вам надо с ним работать. При этом времени «это всё выкинуть и переписать с нуля» Вам абсолютно точно не дадут, потому что код работает и приносит бизнесу деньги. Ну как, нравиться перспектива, или Вы бы предпочли, что бы код изначально писался бы пусть и не так быстро, но зато «феншуйно», давая возможность даже средним специалистам найти узкие места и оптимизировать только их?AlexSky
12.04.2019 10:46+2О, могу рассказать, как пишут студенты. У нас это хорошо видно.
Начну с того, что у моего руководства есть идея фикс: «сейчас мы наймем новых людей и они сделают все хорошо». Совершенно восхитительная идея, что набивший шишки на предыдущих проектах, опытный работник заведомо хуже любого новичка. Я сам, кстати, так пришел, и был в восторге от возможности разрабатывать архитектуру, делать все так, как хочется, без оглядки на кого бы то ни было. У меня тогда хотя бы лет пять опыта разработки было.
Пару лет назад началась очередная итерация «сделаем все по-новому». Пришли студенты (прям реально студенты, они тогда еще доучивались) и понеслось. Нет, ребята очень умные, вот только опыта никакого. Запилили структуру данных, в которой и десятка тысячи записей никогда не будет. Ни о какой высокой нагрузке речи не идет — по сути это конфиг устройства, обращения к которому достаточно редки. Умудрились впихнуть туда самописные би-деревья и хэш-таблицы. И это не смотря на то, что сам конфиг хранится в JSON, а используемая либа — jansson — сама по себе (сюрприз!) основана на хэш-таблицах. Нет, надо показать, что мы не лыком шиты и знаем алгоритмы.
И такое везде — хитрые операции с указателями, огромные макросы, трюки с gcc. Такие практики имеют право на жизнь, но там, где они необходимы, а не по всему коду, который становится абсолютно нечитаемым.
Самое смешное обнаружилось, когда эта разработка начала внедряться, и с ней пришлось работать остальным. Ребята не сделали НИЧЕГО для синхронизации доступа из разных процессов! После того, как на это им указали, сначала вяло отнекивались, что это должно работать как-то «само по себе», а потом все-таки запилили один big fucking lock на весь конфиг. На предложение сделать ниспадающую блокировку, замораживающую только ветки, растущие из нужной ноды, сказали, что это сложно и долго делать. Вот так: оптимизировали би-деревьями, а потом все процессы ждут, пока один закончит свою работу.
Что имеем в результате. Косую архитектуру, никакую мотивацию у старых работников и постоянное переписывание кода. Зато за это время мы слышали много умных слов про «чистый код» (в реальности весьма кривой), про крутость датамодели (в реальности очень костыльная реализация в JSON) и про оптимизации (в реальности хэш-таблицы на списке из ТРЕХ команд).
Hardcoin
11.04.2019 13:41Похоже, вы разбираете говнокод посредственных программистов. Это нормально, потому что посредственных больше, чем хороших. Но вы ради интереса разберите хороший проект на javascript. Vue.js, например (можете выбрать любой, какой хотите). Ускорить, удалив 80% возможностей вы, без сомнения, сможете. Но сможете ли ускорить, оставив функционал?
khim
11.04.2019 17:30-1Ускорить, удалив 80% возможностей вы, без сомнения, сможете. Но сможете ли ускорить, оставив функционал?
Смотря что понимать под «функционалом». Если мы о бизнес-требованиях — то да, легко. А вот если о метаниях дезигнеров или всякого рода баззвордом — нет, конечно. И не нужно.Hardcoin
11.04.2019 17:50+1Хорошо. То есть если я хочу какие-то дизайнерские особенности, мой дизайнер нарисовал и я хочу заплатить денег, что бы это реализовать, вы не можете и денег не возьмёте. Скажете "не нужно, не делайте так".
А люди, которые делают 20 слоев абстракций — сделают. Что ж, это полностью объясняет, почему у софта, который всё же взяли и сделали, так много слоев, не правда ли?
Более того, это даже в опенсорсе работает. Если люди просят "нам нужна библиотека, которая может делать супер-пупер Х", то есть всего две категории разработчиков. Которые могут сделать быстро, без лишних абстракций, но и без лишнего функционала (потому что "не нужен" и его без слоев просто не получается реализовать) и те, кто реализует весь "ненужный" функционал, библиотека становится популярной, но там много слоев.
PsyHaSTe
11.04.2019 19:46+1Медленно работающий гмейл — это результат того, что плохой код в критичном месте, понимаете? Критичные места — это то, что нужно оптимизировать.
Я думаю, там вопрос не столько в качестве кода, сколько в количестве. Не даром он там 600мб памяти занимает.

Soo
11.04.2019 11:32Почему гмайл не даёт новых возможностей? Новые возможности у товарища Майора и Гугла для впихивания рекламы
Hardcoin
11.04.2019 13:36Он даёт очень много возможностей по сравнению, например, с аутлуком. Не знаю, на чем написан аутлук, но точно не на JavaScript.
Только не спрашивайте, каких. Просто посмотрите, сколько людей пользуются Gmail. Значит у него есть какое-то преимущество перед аутлук. Преимущество именно для них.
staticlab
11.04.2019 14:24Не знаю, на чем написан аутлук, но точно не на JavaScript.
Тот аутлук, который outlook.office.com? Судя по стилю кода, он изначально написан на ES5, а затем просто минифицирован каждый файл в отдельности. Судя по тому, что в коде используется Microsoft AJAX Library, это часть обычного проекта ASP.NET. То есть, там даже TypeScript в основной массе нет.

Fuzzyjammer
11.04.2019 16:29Эмм. Очевидное преимущество gmail'а перед outlook'ом — он бесплатный (ну, на поверхности). В плане фич и скорости работы gmail'у до него далеко, но я не вижу причин вообще сравнивать бесплатное веб-приложение и дорогой офисный продукт.
Плюс многие пользуются gmail'ом именно как почтовой службой, а его сверхтяжелый интерфейс им даром не нужен. И, сюрприз, есть люди, которые читают почту своего gmail-ящика через outlook.Hardcoin
11.04.2019 16:41Кому-то не нужен. Кому-то нужен. Вы правильно описали, что у разных людей разные причины пользоваться. А утверждение выше, что "gmail" не даёт новых возможностей, не верно. Раз пользуются, значит им даёт. Благо выбор огромен.
khim
11.04.2019 17:42Раз пользуются, значит им даёт.
Пользуются потому что и раньше пользовались.
А утверждение выше, что «gmail» не даёт новых возможностей, не верно.
Можете назвать хоть одну? Ещё раз: я не про GMail 2004го года (там как раз требований к ресурсам было не так много, а новых фич — много), а про GMail 2018го из анекдота «зачем ты Ролекс за миллион купил, вот там за углом такой же за пять».Hardcoin
11.04.2019 17:57Могу, конечно. Группировка писем по категориям/полезности. Вы скажете, что это можно было реализовать и в старом gmail? В теории — да, можно. На практике разработчики быстрого кода сказали, что "это не нужно" и пришлось gmail перепилить силами любителей абстракций. А что делать? Отказываться от реализации фичи, потому что разработчик опять говорит "не нужно"? Это хуже, чем медленный софт, приходится мириться с тормозами.
Поймите, лично я люблю стремительный софт. Раньше мне вообще от большинства сайтов было больно (теперь привык). Но если кто-то решил проверить бизнес-идею ради увеличения прибыли, а разработчик быстрого софта лезет в бутылку, приходится обращаться к разработчикам медленного софта. А что делать? Просто представьте себя на месте владельца софта.
khim
11.04.2019 19:39Группировка писем по категориям/полезности.
Вот только эта группировака уже была в старом GMail. Она не в 2018м году появилась.
Просто представьте себя на месте владельца софта.
Представляю. Пользователи уже начали уходить в IMAP и прочее. А со временем — могут и к другим провайдерам уйти.Hardcoin
11.04.2019 20:00Видимо я не смог нормально описать, что я имею ввиду. Та группировка, о которой я веду речь, появилась года два назад.
Впрочем, не существенно. У вас, видимо, есть другое объяснение, почему gmail сделан так. Если я вас верно понял, это потому что там одни идиоты и любители специально делать плохо. Что-то я сомневаюсь, что это на самом деле так, но дело ваше.
khim
12.04.2019 00:59+1Та группировка, о которой я веду речь, появилась года два назад.
А я говорю о новом интерфейсе, появившемся в прошлом году.
Если я вас верно понял, это потому что там одни идиоты и любители специально делать плохо.
Ни в коем случае. Этот случай уже разбирали. Просто за 15 лет с момента выхода первой версии GMail изменилась культура внутри компании.
15 лет назад, когда выходила первая версия GMail, её разрабатывали и оценивали инженеры. Сегодня — это делают, как и везде, «эффективные манагеры». Которые ценят «запуски» (launch) и «влияние» (impact). Которые, как известно, сводятся к игре шрифтами (ну и можно ещё баззвардов подсыпать).
Ну а дальше — имеем то, что имеем. Никто не будет писать хороший код, если куда важнее — создать хорошую презентацию и «документ о дизайне» (design doc). То, что в результате получится дерьмо, которое будет жрать ресурсы как не в себя и тормозить (см. GMail) — никого не волнует. За то, что будет порождено 100500 продуктов, ни одним из которых нельзя будет пользоваться (Hangouts, Allo, Duo, какой-там-ещё был высер, якобы конкурирующий с WhatsApp?) — никто «втыка» не получит.
В резльтате — я реально не знаю ни одного пользовательского продукта, сделанного в Google в последние лет 5-7 и получившего популярность. Backend? Всякие TensorFlow? Да — их делают «придурки», не умеющие ублажать «эффективных манагеров» и не получающие много плюшек, но и зато не имеюшие уж очень много манагеров на шее.
Frontend? От плохого к худшему, уж извините.
P.S. Это, впрочем, нормально: Microsoft тоже через этот этап прошёл. Там, чтобы выправить ситуацию пришлось CEO выпереть… посмотрим что в Google потребуется…edogs
12.04.2019 01:04Инжинеры в гмыле себе немного оставили mail.google.com/mail/u/0/h/1pq68r75kzvdr/?v%3Dlui
Сначала пользовались ей иногда, теперь постоянно, т.к. стандартная версия даже на десктопе уже достала тормозить.
Hardcoin
12.04.2019 02:32Тема от подходов к программированию плавно перешла к управлению продуктами. Tensorflow на самом деле хорош. Облачные продукты у них нормальные. Интерфейс, конечно, шлак и документация постоянно устаревшая, но богатство возможностей поражает. Андроид не плох. Конечно он родился больше чем "5-7 лет назад", но новые версии вполне вменяемые.
Впрочем, вашу идею я понял, менеджерская прослойка загнивает. Отрицать не буду, в каждой корпорации это происходит когда-нибудь, кто-то выживает, кто-то нет.
khim
11.04.2019 17:36Он даёт очень много возможностей по сравнению, например, с аутлуком.
Я, вообще-то сказал достаточно однозначно: «не даёт ничего по сравнению с тем же GMail'ом десятилетней давности». Когда уже и чаты и всякие прочие плюшки (даже тот самый Google Buzz) уже были — а таких объемов… добра в кода и таких тормозов — не было и в помине.
И я даже знаю какие вещи (в том числе полезные) за это время появились (скажем Priority Inbox) — но я не знаю ни одной из ничего, что нельзя было реализовать в версии той же десятилетней давности, требующей на порядок меньше ресурсов и на порядок более отзывчивой…
MacIn
11.04.2019 17:49Да, но если вы этот цикл запихнете в функцию reverseString, то чтение вызова оной также займет мгновение. В сплите-джойне вы точно так же кучи циклов прячете за фасадом библиотеки.
PsyHaSTe
11.04.2019 19:42Как я ниже уже сказал, вопросы к языку тоже есть. Например, почему map и filter аллоцируют объекты.
Serge3leo
11.04.2019 02:38Как выяснилось, если применять стандартные вещи без понимания, тестирования, тяп-ляп и коротко — попадёшь на грабли. Автор начал писать за это, но тут же попал на следующие грабли, с составными символами. А, скажем, на macOS, iOS, стандартная нормализация NFD.
mksma
10.04.2019 20:54+1Если под «оптимальностью» имелось ввиду «оптимальное по размеру кода и очевидности», то зачем так извращаться? Можно ведь просто использовать for…
function func(str) { ret = ""; for(i = str.length; i >= 0; i--) ret += str.substr(i, 1); return ret; }AllexIn
10.04.2019 20:57Разве каждую итерацию не будет повторное выделение памяти?
По идее здесь нужен билдер, который будет принимать сразу размер и потом заполнять не меняя размер. но я не знаю как это в JS делается.mksma
10.04.2019 21:09Я тоже не уверен, что с этим будет делать JS. Скорее всего этот способ займет много памяти. Но по своей простоте и очевидности, способ по-моему самый простой. Ведь что конкретно автор имеет ввиду под «оптимально» мы пока не выяснили…
GRaAL
10.04.2019 21:08+6Можно. Но, имхо, однострочник проще и понятнее.
Что касается производительности, то я плохо представляю, в каком сценарии операция реверса строки на веб-странице может стать узким местом, чтобы заниматься ее оптимизацией. Если мы пишем сервис, который должен реверсить гигабайты в секунду — это другой разговор. Но для веб-страницы не так важно, выполнится реверс строки за 1мкс или за 2мкс.
Вот кстати бенчмарк с разными способами: jsperf.com/string-reverse-function-performance
YemSalat
11.04.2019 05:37Ага, особенно учитывая что самый быстрый вариант выглядит вот так:
// only for-loop declaration with concatenation function reverse_06 (s) { for (var i = s.length - 1, o = ''; i >= 0; o += s[i--]) { } return o; }GRaAL
11.04.2019 11:25Да, на моей машине jsperf показывает для этого варианта 2.6 миллионов операций в секунду, а для однострочника — всего 1.6 миллионов операций в секунду.
Поэтому если вдруг (хз правда зачем) я пишу микросервис на js, который должен реверсить строки в промышленных масштабах, то я возьму более быстрый вариант. В прочих случаях я предпочту более компактный и понятный, потому что даже с ним операция занимает меньше 1 микросекунды.
Zenitchik
11.04.2019 20:08А почему не вот так?
function reverse_06 (s) { for (var i = s.length, o = ''; i--; o += s[i]) { } return o; }PsyHaSTe
11.04.2019 20:51+2Почему люди (особенно с сишным бекграундом) так стараюстя уместить максимальное количество сайдэффектов на единицу площади? Если расписать функцию нормально строк в 5 она будет читаться сильно проще, чем этот остроумный вариант использующий все дополнительные свойства операций.
DistortNeo
11.04.2019 22:03Этим страдают джуны, которые хотят показать таким образом своё мастерство в знании ЯП.
Zenitchik
11.04.2019 22:06Этим страдают те, кому нечем заняться, и хочется слегка пошутить на тему кода.
В проект это совать… Комментов больше чем кода напишешь.khim
12.04.2019 01:03Комментов больше чем кода напишешь.
Там не может быть ни одного коммента. Ну никак. Весь кайф он наблюдейния глаз человека узревшего чего-нибудь типа
if any(iter) and not any(iter):(это, правда Python) потеряется…

Barbaresk
12.04.2019 01:04+1Я как программист С++ с большим опытом могу сказать, что это типичная болезнь многих С/С++ программистов. Когда я только научился писать на С++ более-менее хорошо, я тоже так писал. Но со временем приходит понимание, что твой код ещё ВНЕЗАПНО читают другие люди, и тогда начинаешь писать уже нормально, не экономя переносы строк и символы. К сожалению, понимание приходит далеко не всем. Знаю даже опытных людей, с опытом в десятки лет, которые выдают всякие s = i++ + k * ++m; Вроде и не UB и всё работает по стандарту, а хочется плеваться.
PsyHaSTe
12.04.2019 01:34Буквально на днях читал доклад александреску, причем на сишарпе, и там пожалуйста, то же самое… А ведь для кого-то это икона.
Barbaresk
12.04.2019 01:41Глянул пример, подозреваю, что там реально код оптимизировался именно по размеру. Там слайды презентаций, поэтому и приходилось всё умещать всё в 6-8 строк.
MacIn
12.04.2019 18:21Почему не
function reverse_06 (s) { var o = ''; for (var i = s.length; i >= 0; i--) { o += s[i]; }; return o; }
Тогда уже.
Хотя почти это же написали выше.

Yoooriii
12.04.2019 03:18по идее на первой итерации это должно упасть, мы сразу же выходим за границы массива.
i = str.length — это индекс элемента за последним.
eefadeev
11.04.2019 10:00+1Строго говоря «эффективно» и «оптимально» это две формы одного и того же понятия.
Потому что эффективность так же требует критерия как и оптимальность. Реализация может быть эффективна по: тактам процессора, используемой памяти, простоте дальнейшего сопровождения, эффекту производимому на вопрошающего и т.д. и т.п. И вовсе не факт что это будет одна и та же реализация.

pallada92
10.04.2019 20:55+8У браузеров сейчас довольно продвинутые JIT-компиляторы. Я недавно офигел, когда реализовал force-directed алгоритм рисования графа двумя способами:
- Максимально разжеванным для компилятора с циклами вида
for (let i=arr.length-1; i>=0; --i), заранее выделяя все массивы нужной длины, с выносом всего неизменного в константы, явным приведением типов в духе asm.js и хранением всех данных в плоских типизированных массивах. - Модном сейчас функциональном стиле с кучей лямбд, map, созданием десятка промежуточных массивов, хранением данных во вложенных словарях с обращением по строковому идентификатору.
и оказалось, что время их выполнения абсолютно одинаково и примерно равно времени выполнения такого же кода на C.
Относительно кода автора, уже были сделаны бенчмарки, сравнивающие время выполнения обращения строк и выяснилось, что разница примерно в 2 раза по сравнению с обычными циклами: jsperf.com/string-reverse-function-performance (код автора: «in-built functions»). Да, не оптимально, но в рамках допустимого: если это не узкое место в программе, то решение в одну строчку гораздо более читабельное и поддерживаемое. Думаю, если бы не умные оптимизации компилятора, разница была бы раз в десять.
vanxant
10.04.2019 22:39+1А я вот в своё время поржал, что замена const на немодный var может ускорить некий синтетический код раза так в два.

Zoolander
11.04.2019 14:57у меня бывало наоборот — числовой const начал инлайниться по месту употребления, но это происходило нерегулярно и без гарантии. Делал это встроенный минификатор Webpack
YemSalat
11.04.2019 05:42и оказалось, что время их выполнения абсолютно одинаково и примерно равно времени выполнения такого же кода на C.
Надо думать второй вариант будет потреблять больше памяти и чаще дергать сборщик мусора, т.к. функциональный стиль подразумевает иммутабельность aka «создание десятка промежуточных массивов»
Whuthering
11.04.2019 08:26Так о том и речь, что современные компиляторы и интерпретаторы такое понимают и оптимизируют получившийся код, чтобы не плодить промежуточные массивы там где в этом нет необходимости.

Aingis
11.04.2019 12:01Ну, откровенно говоря, бенчмарки такое не показывают. Сборщик мусора подл тем, что «останавливает мир» в непредсказуемые моменты времени когда-то потом. А на каждый прогон теста создаётся свой мир с последующей сборкой мусора. Надо профилировать память в реально работающем коде, что узнать как обстоят дела.
0xd34df00d
11.04.2019 15:56Чаще — это хорошо. Чем больше мусора вычищается из Gen0, не переходя в Gen1, тем лучше. Gen0 быстрый.
balsoft
12.04.2019 01:10«создание десятка промежуточных массивов»
Не обязательно, умные компиляторы/интерпретаторы умеют создавать только изменения или вообще менять in-place при сохранении иммутабельности с точки зрения программиста, т.е. когда это можно делать и выгодно делать.
- Максимально разжеванным для компилятора с циклами вида
straymonk
10.04.2019 21:39-14Мир фронтенда — это апофеоз неэффективности. Само собой, когда туда идут только бракованные программисты.

vintage
10.04.2019 22:17+2Я бы охерел, если бы на вакансию С++ программиста кто-то для реверса строки сначала её в отдельный список/массив конвертировал.
А C++ что ли не умеет в итераторы?
Zoolander
11.04.2019 07:45+2Здравствуйте. Перформанс этого метода конкретно в JS неоднозначен и требует тестирования в конкретных боевых условиях. Еще в 2009 году были проведены тесты, в которых было показано, что если строка превышает 64 символа в длину — метод str.split('').reverse().join(''); внезапно начинает обгонять метод с циклом. Я не говорю — этот тест актуален и сейчас. Я говорю — надо тестировать перформанс в конкретных боевых условиях.
shamasis.net/2009/09/javascript-string-reversing-algorithm-performance
На всякий случай, если ссылка сдохнет.
// быстрее на строках > 64 символов String.prototype.reverse = function() { return this.split('').reverse().join(''); }; // быстрее на строках < 64 символов String.prototype.reverse = function() { var i, s=''; for(i = this.length; i >= 0; i--) { s+= this.charAt(i); } return s; };
gkozlenko
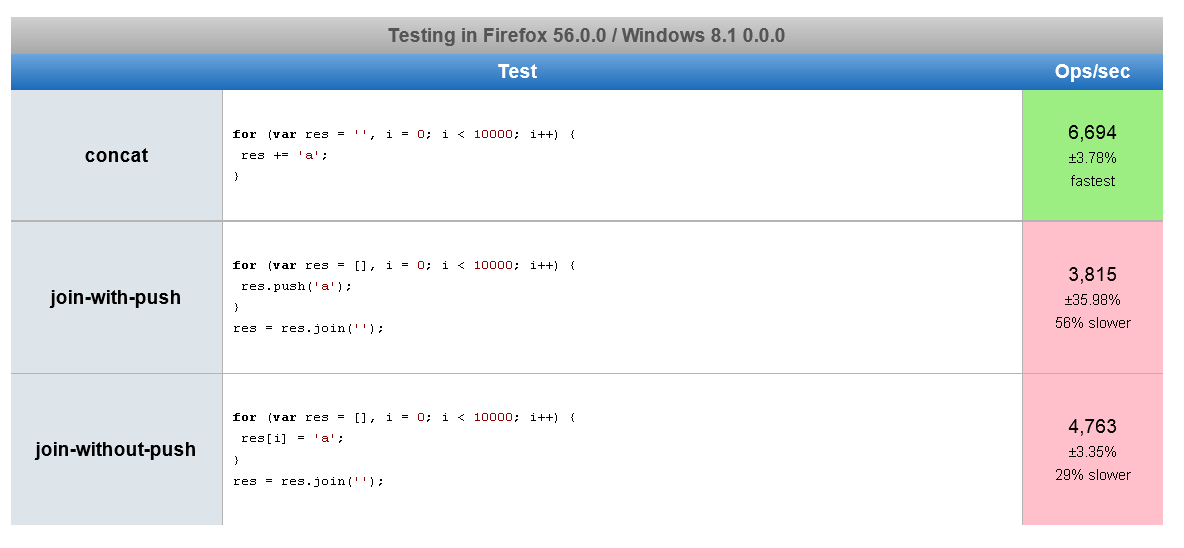
11.04.2019 09:41+1Первый вариант имеет сложность O(n), а второй вариант — O(n^2), так как на каждой итерации происходит конкатенация строк. Правильно было бы сравнивать вариант с цепочкой вызовов с этим:
String.prototype.reverse = function() { var i, a= []; for(i = this.length; i >= 0; i--) { a.push(this.charAt(i)); } return a.join(''); };
Этот вариант так же имеет сложность O(n), но потребляет меньше памяти (с точностью до коэффициента, так как потребление памяти у них одинаковое — O(n)).
Zoolander
11.04.2019 10:57конкатенация строк в JS — не то же, что конкатенация строк в Java
stackoverflow.com/questions/16696632/most-efficient-way-to-concatenate-strings-in-javascript
gkozlenko
11.04.2019 11:27Хм, интересно, не знал. Спасибо за информацию.
Zoolander
11.04.2019 11:53+1Пожалуйста. Я сам постоянно страдаю от желания оптимизировать все эти цепочки, и если копаться в моем коде — наверняка можно найти кучу вещей, которые можно было бы записать короче, а не циклами. Мне до сих пор непривычно, что конкатенация строк плюсом самая быстрая в JS.
Но, как я читал, в Java идут разговоры о том, чтобы в следующих версиях улучшить реализацию String так, чтобы конкатенация по дефолту происходила так же быстро, как сейчас через StringBuilder. Так что, вполне вероятно, лет через 10 мы все забудем про конкатенацию строк как дополнительный n )
Я часто работаю со строками (пишу мини-парсеры для сменного контента в мини-играх), поэтому постоянно ищу, где бы улучшить обработку строк — но пока прихожу к выводу, что оптимизацию надо делать отдельной задачей, после того, как реализован проект — и там уже менять то, что дает заметный для пользователя эффект тормозов
Zenitchik
11.04.2019 11:55+1Круто. В 2011 было наоборот, из-за этого у нас всюду, где код для старых браузеров, join массива.
Cryvage
11.04.2019 19:18+1Похоже что даже в разных версиях SpiderMonkey, оптимизации немного разные. Впрочем, разница невелика. А вот V8 действительно сильно оптимизирован на конкатенацию.
Лиса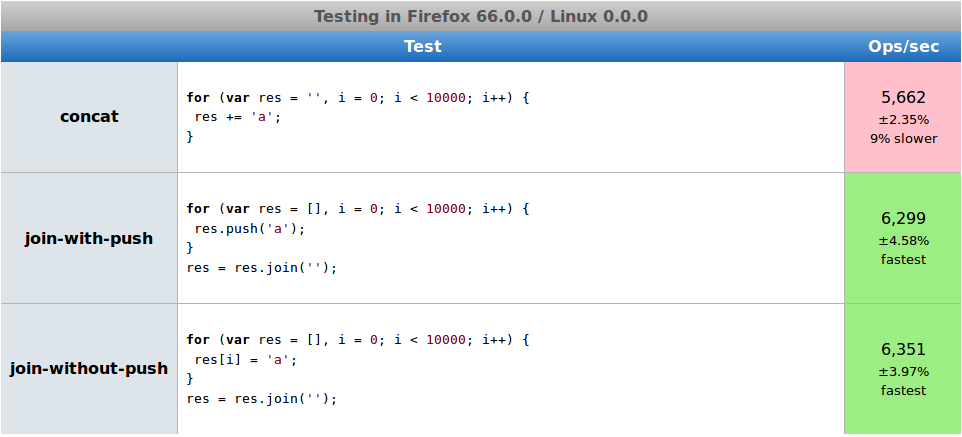
Cryvage
12.04.2019 11:50Как и ожидалось, предварительно выделенный массив работает быстрее, чем обычный. Но оптимизированная конкатенация, там где она есть, всё равно даёт лучшие результаты.
Лиса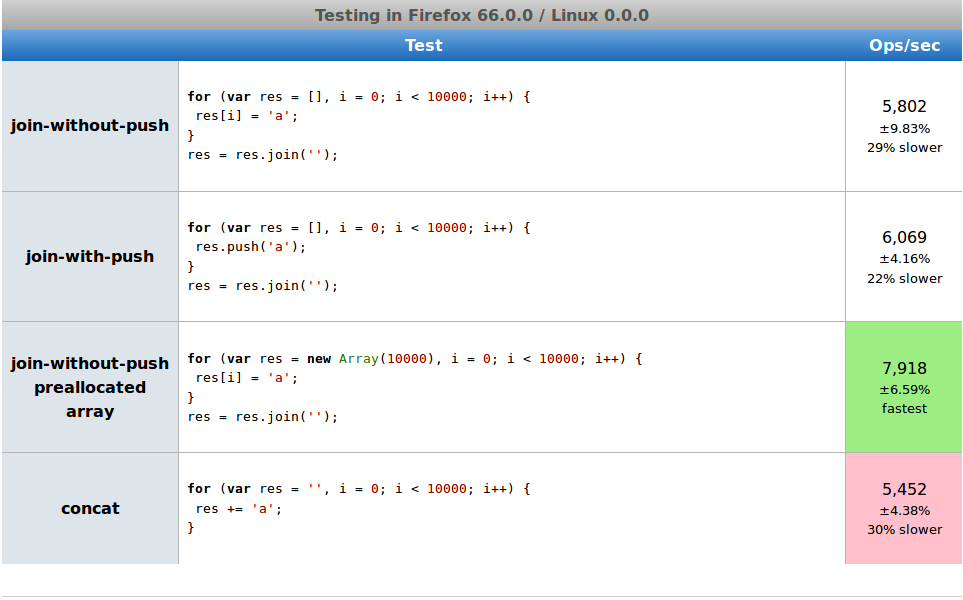

kahi4
11.04.2019 12:48Ага, а реаллокация массива в таком варианте, значит, не происходит?
Тогда уж лучше так?
String.prototype.reverse = function() { var i, a= this.slice(0); for(i = this.length; i >= 0; i--) { a[this.length - i] = this[i]; } return a; };gkozlenko
11.04.2019 13:02Да, точно, совсем забыл. Можно проинициализировать еще так:
new Array(this.length)
OnYourLips
11.04.2019 08:50А вы видите требования к эффективности или производительности кода? Их нет.
Практика многократно показывала, что любая самодеятельность подобного рода без необходимости оборачивается справедливым негативом к разработчику как со стороны менеджмента, так и со стороны команды: это удлиняет сроки и портит поддерживаемость кода.
Tagire
11.04.2019 10:41Просто так сплитнуть с другой половиной не выйдет, потому что utf8 же и символ может занимать разное количество байт. Да и те же умлауты, у вас немецкий текст может в кашу превратиться.
InChaos
11.04.2019 13:11Если это UTF строка, то по логике, взятие символа b=a[i] или замена a[i]=c, должно обрабатываться корректно, в не зависимости из скольких байт состоит, т.е. с учетом стандарта UTF и этих его эмодзи, не к ночи будут упомянуты.
Tagire
11.04.2019 13:47Только взятие символа в таком случае имеет сложность oN, а обход всей строки посимвольно квадратичную.
Zenitchik
11.04.2019 13:59Простите, почему? Если я читаю всю строку конечным автоматом, то я получаю все символы не совершая для этого никаких лишних действий. И сложность обхода остаётся линейной.
Tagire
11.04.2019 14:16Есть проблема в том, чтобы юникод читать конечным автоматом с конца строки, а вам символы с конца строки тоже нужно читать целиком, а если прочитать её по порядку в массив то по факту решение такое же как в жс было изначально.
Zenitchik
11.04.2019 14:23Есть проблема в том, чтобы юникод читать конечным автоматом с конца строки
Не вижу в этом проблемы. Вторая часть суррогатных пар находится в собственном диапазоне. Прочитав её, я знаю, что это не символ, и перед ней стоит первая часть суррогатной пары.Tagire
11.04.2019 14:31Хм, ну тут я показал свое незнание. Но есть ещё вопрос, сколько по времени займёт поменять местами символ и суррогатную пару?
Zenitchik
11.04.2019 15:32Ну, мы же не в исходной строке меняем, а формируем новую строку.
Вот, мне было нечем заняться, и я написал генератор, перечисляющий кодовые точки в обратном порядке
function* pointsFromEnd(str){ let i = str.length, s=""; for(;i--;){ let a = str[i]; if(s){ yield a+s; s=""; } else if(a>="\uDC00" && a<="\uDFFF"){ s=a; } else{ yield a; } } }Tagire
11.04.2019 16:29А в чем разница тогда? Экономия трети памяти, но более медленный и костыльный код в котором для длинных строк могут быть миллионы вызовов этой функции.
А чтобы сделать обработку эмодзи из поста код придётся вообще целиком выкинуть.
Hardcoin
11.04.2019 13:22Не просто норма, но и рекомендуемый подход. Основной довод — читабельность и простота поддержки кода. С точки зрения скорости вы правы, не самый быстрый способ.
PsyHaSTe
11.04.2019 19:39split и join — это эффективно?
Зависит от реализации.
Но что мешает без сплита сразу писать в массив и его конвертировать в строку? Разве это не будет эффективнее?
если reverse() дает итератор, а не массив, то будет так же эффективно. Другое дело, что в ЖС нет концепции итераторов, и каждый filter/map/..., которые можно было бы выполнять по цепочке каждый раз аллоцируют объекты.
А вообще в ЖС есть намного более печальные способы убить производительность, чем сделать одно лишнее копирование. Держать представление всех объектов в 3 разных местах, например.vintage
11.04.2019 20:02в ЖС нет концепции итераторов
https://developer.mozilla.org/ru/docs/Web/JavaScript/Guide/Iterators_and_Generators
PsyHaSTe
11.04.2019 20:49Их все еще нет, пока 99% проектов транспилятся в ES5.
staticlab
11.04.2019 21:10И что? Внутри транспилированного кода это же будет не конечным массивом после каждой операции представлено, а неким объектом-итератором.
PsyHaSTe
11.04.2019 21:37Объект-итератор скорее всего будет дороже, чем просто скопировать массив.
Смысл итераторов в том, что это по идее zero cost, который развернется оптимальным образом.staticlab
12.04.2019 14:00Итераторы в JS — это тоже объекты: https://www.ecma-international.org/ecma-262/6.0/#sec-createstringiterator
PsyHaSTe
12.04.2019 14:14и? Это никак не опровергает того факта, что работа с итератором может быть чаще дороже чем с массивом.
Смысл итератора в том, чтобы это была абстракция времени компиляции, которая полностью убирается в рантайме.
vintage
11.04.2019 21:11Только те, кому нужна поддержка IE или Opera Mini (одному проценту проектов). Все остальные браузеры уже давно поддеживают.
PsyHaSTe
11.04.2019 21:38Ну давайте проведем опрос. Я уверен, что ES5 таргет основной с большим отрывом.

xeon
11.04.2019 22:20+1Я тоже думаю ES5 основной target. А ещё можно модно написать for… of из ES6 для итерации по массиву и последний Хром будет работать почти так же быстро, как и просто проход по массиву. А вот в Firefox заметно медленнее. Поэтому транспиляция в ES5 даст не только совместимость, но ещё и лучше скорость в некоторых случаях.
ainoneko
11.04.2019 20:56Если в вебе это норма — не удивительно что у нас всё так плохо в браузерах.
Это близко к норме в вебе.
Если посмотреть на пресловутый «leftpad, ломавший интернет своим отсутствием», там тоже был очень неэффективный (а в некоторых _редких_ случаях было бы совсем плохо) код.
(Добавление по одном пробелу слева вместо того, чтобы сразу добавить нужное количество.
Да, это экономит усилия программиста и помогает избежать "третьей из двух проблем программирования". )
bfDeveloper
10.04.2019 20:27+10Как только речь заходит об эмодзи и их сочетаниях, в памяти должны всплывать такие слова, как code point, сурогатная пара, графема. Тысячи статей про отличия букв, байт, нормализацию юникода и прочее. Кстати, при простом гуглении разделения по графемам в js находится, например: github.com/orling/grapheme-splitter
Это всё к тому, что надо знать разные тонкости, а так же иметь банальный IT кругозор чтобы знать, что спросить у гугла. В этом смысле задачка отличная.
tuxi
10.04.2019 20:31+9<ворчание-бурчание>Вот когда вводили юникод, флагами махали, нам нужны «мультиязычные сайты»… ну и где эти миллионы мультиязычных сайтов? Зато куча места на stackoverflow посвящено вопросам «как мне из utf-8 сделать что то однобайтовое», или «помогите! у меня кракозябры в консольке!»… а теперь вот эмодзи эти ваши </ворчание-бурчание> :)
edogs
10.04.2019 21:05где эти миллионы мультиязычных сайтов?
В китае и японии:)
Мы до сих пор активно используем однобайтовые кодировки, если объемы текста для обработки большие и язык в однобайтовую помещается. Мало того что php до сих пор не вполне адекватно работает с утф8 (за другие языки не особо знаем, но наверняка нюансы есть), так еще и на скорости и объемах отражается. Небольшое количество альтернативных символов в тексте вполне решается через &что-нибудь там.tuxi
10.04.2019 21:35Кстати да. Из за двубайтных кодировок сжигается больше электроэнергии при хранении и передаче и портится природа… :)
PS: мы тоже на однобайтовой сидим и чесно говоря не вижу проблем. 2 языка анг и рус легко поддерживаются, а больше у нас нет и не будет :)ainoneko
11.04.2019 21:03Небольшое количество альтернативных символов в тексте вполне решается через &что-нибудь там.
Из за двубайтных кодировок сжигается больше электроэнергии при хранении и передаче и портится природа… :)
А сколько энергии сожглость при передаче русских букв в виде "éô" (это только две буквы) и т.д.? ?\_(?)_/?
Areso
11.04.2019 23:19Когда в системе десятки баз, суммарно на десятки же терабайт, разница между двухбайтовым и однобайтовым хранением строк начинает приобретать ощутимый размер.
К примеру, в организации, где я работаю, было принято именно такое решение. Использовать в базе однобайтные кодировки.
Sabubu
11.04.2019 07:48+1Твиттер, например: я часто там вижу никнеймы с арабскими, китайскими символами, не говоря о русских. Все это прекрасно отображается благодаря Юникоду. Не хочу в убогое 8-битное прошлое с сбивающимися кодировками и невозможностью отображать рядом символы разных языков.
edogs
11.04.2019 12:28невозможностью отображать рядом символы разных языков.
Распространенное заблуждение у тех, кто не застал до-утфную эпоху:)
Неудобство — да, невозможность — нет. Ибо html entitiesSabubu
11.04.2019 14:00Это кривой и неработающий костыль. Простой пример: вам надо посчитать длину строки. Как вы это сделаете? Напишите свою реализацию strlen с поддержкой entities? Другой пример: вам надо отрезать последние 5 символов. А если вам надо сделать поиск регуляркой? Третий пример: а как пользователь введет свое имя, если у вас страница в 8-битной кодировке, а оно у него с арабскими символами? Их нет в вашей кодировке и браузер не может их отправить (кодирование форм с помощью HTML entities не предусмотрено).
Далее, когда вы захотите вставить в одну строку другую, вам надо помнить о том, какие данные в этих строках — сконвертированные в entities или нет, и сконвертировать при необходимости, чтобы например символ & был бы закодирован как & amp ;. и так у вас в программе будет половина строк закодированных. а половина нет, и вы будете делать ошибки или писать типы-обертки для разных видов строк. Плюс, если вы выведете где-то незакодированную строку, возникнет XSS-уязвимость. А понять, есть она у вас или нет, нельзя, так как данные экранируются в самых разных местах кода.
В общем, число граблей тут такое, что разработчики либо будут значительное время тратить на их решение, либо проигнорируют и будут писать кривой код с кучей уязвимостей. Освоить Unicode все же будет выгоднее.
akryukov
11.04.2019 14:17+1Простой пример: вам надо посчитать длину строки. Как вы это сделаете? Напишите свою реализацию strlen с поддержкой entities?
Подозреваю, что strlen тоже неочень дружит с составными emoji.
tuxi
11.04.2019 15:03С вводом утф, одни неудобства, заменили на другие. Плюс траффик и занимаемое место выросли в среднем от 20 до 30%
edogs
11.04.2019 16:36Простой пример: вам надо посчитать длину строки. Как вы это сделаете?
Наш оппонент писал про "невозможность отображать рядом символы разных языков",.
Простой пример: вам надо посчитать длину строки. Как вы это сделаете? Напишите свою реализацию strlen с поддержкой entities? Другой пример: вам надо отрезать последние 5 символов. А если вам надо сделать поиск регуляркой? Третий пример: а как пользователь введет свое имя, если у вас страница в 8-битной кодировке, а оно у него с арабскими символами? Их нет в вашей кодировке и браузер не может их отправить (кодирование форм с помощью HTML entities не предусмотрено).
И чем пример с длиной или отрезанием отличается mb_strlen, mb_substr? Которые как раз свои реализации strlen для утф8? А необходимость использовать ключ u для регулярок с утф8 Вы забыли? Если этого шаманства специально для утф не делать, то ничего работать и не будет.
Далее, когда вы захотите
Да все то же самое, если не делать отдельную обработку утф — будут проблемы, если не делать отдельную обработку хтмл ентитес — будут проблемы. Равноценные вещи.
В общем, число граблей тут такое, что разработчики либо будут значительное время тратить на их решение, либо проигнорируют и будут писать кривой код с кучей уязвимостей. Освоить Unicode все же будет выгоднее.
Поддержка широкого набора символов должна идти идет на уровне языка. Для разработчика на языке нет разницы между mb_substr или html_entites_substr или substr. Для разработчика языка сложность реализации утф8 и хтмл_ентитес примерно на одном уровне, хотя и разного качества — хтмл_ентитес чем-то проще, т.к. каждый атипичный символ начинается предсказуемым образом, а в утф8 даже длину символа не знаешь пока не прочитаешь его. Это уже не говоря о зоопарке utf кодировок — utf8, utf16 и т.д…Zenitchik
11.04.2019 17:35+1хтмл_ентитес чем-то проще, т.к. каждый атипичный символ начинается предсказуемым образом, а в утф8 даже длину символа не знаешь пока не прочитаешь его.
Почему? Чтобы узнать длину символа UTF-8 достаточно прочитать его первый байт.tuxi
11.04.2019 18:51-1Это если по дороге BOM не потерялся, что случается не так уж и редко кстати. И если есть шанс что придет поток с UTF-16 или UTF-32 контентом, то уже надо несколько больше телодвижений сделать.
Zenitchik
11.04.2019 19:14+2UTF-8 не нуждается в BOM.
У меня нет ни одного файла с BOM, и у нас по стандарту проекта «UTF-8 без BOM».tuxi
11.04.2019 19:41Если работать с «зоопарком» внешних систем, данные будут приходить как с ним, так и без него. И на уровне http будут ситуации, когда в заголовке одна кодировка, а внутри другая. Никто не спорит, что все можно решить, но существенная часть этих решений, тратит свое время не на бизнес-логику, а на различные корректировки и приведение к спецификации.
vintage
11.04.2019 19:55Емнип, надо прочитать все, кроме последнего.
Zenitchik
11.04.2019 20:13+2Вообще-то нет. Количество единиц в старших разрядах первого байта однозначно определяют длину символа.
«0XXXXXXX» — однобайтовый символ;
«110XXXXX» — двухбайтовый;
«1110XXXX» — трёхбайтовый;
«11110XXX» — четырёхбайтовый.
Все последующие байты символа имеют вид «10ХХХХХХ».
edogs
11.04.2019 20:03Почему? Чтобы узнать длину символа UTF-8 достаточно прочитать его первый байт.
Сорри, не то имели ввиду. Имели ввиду, что даже если у Вас текст полностью в одной из однобайтовых кодировок, то Вы точно знаете что 1 это 1, а вот в утф8 это не так однозначно. Таким образом утф8 непредсказуем с самого начала, а однобайтовые кодировки непредсказуемы только когда есть атипичные символы.Zenitchik
11.04.2019 20:23однобайтовые кодировки непредсказуемы только когда есть атипичные символы.
UTF-8 тоже. Просто «атипичными символами» считаются все, после 127-го.
UTF-16 — ещё лучше — «атипичные» только суррогатные пары.edogs
11.04.2019 22:26UTF-8 «атипичными символами» считаются все, после 127-го.
Это и есть проблема. Утф8 считает атипичными символами вполне типичные символы типичного сайта, типично сделанного на одном типичном языке. Из-за чего даже банальный природно-однобайтовый сайт даже тупо на немецком/русском/французском вдруг оказывается с точки зрения утф8 атипичным.DistortNeo
11.04.2019 22:30Это не проблема, если вспомнить, что большую часть даннх составляёт HTML/CSS/JS, а не собственно текст на человеческом языке.
А учитывая, что «атипичные» символы что в UTF-8, что в UTF-16 занимают по 2 байта, то никакой проблемы здесь нет.edogs
11.04.2019 23:07Это не проблема, если вспомнить, что большую часть даннх составляёт HTML/CSS/JS, а не собственно текст на человеческом языке.
В БД все же текст, и именно с текстом проводятся все операции — поиск, обрезание, редактирование, анализ.
Но даже если говорить не про хранение, а про распространение — то разница все равно есть и к тому же хотелось бы надеятся, что html не занимает бОльшую часть данных.
«атипичные» символы что в UTF-8, что в UTF-16 занимают по 2 байта, то никакой проблемы здесь нет.
Так речь шла о сравнении однобайтовой национальной с юникодом.
khim
12.04.2019 01:06немецком/русском/французском
Мне больше интересно куда вы свой немецко-русско-французский текст с однобайтовой кодировкой собрались засовывать…
tuxi
11.04.2019 15:12Неудобство — да, невозможность — нет. Ибо html entities
Я в прошлом году занимался интеграцией нашей компании с одним крупным европейским производителем (2 место в мире по производству, годовой оборот 20млрд долларов).
Они используют в своем api для текстовых сущностей не UTF, а html entities

humbug
10.04.2019 20:33+6Я не понимаю людей, которые говорят: «Я не понимаю, зачем нужно знать, что null >= 0? Мне это не пригодится!». Пригодится, 100% пригодится, в тот момент, когда ты будешь выяснять причину того-или иного явления — ты прокачаешь себя, как программиста и станешь лучше.
Потому что махровое легаси, от которо всех тошнит, но починить WTF JS обойдется слишком дорого?
Вы, как тимлид и все такое, можете объяснить логику за этой табличкой? https://getify.github.io/coercions-grid/
drch Автор
10.04.2019 22:05+2С ходу — нет, каждый случай "неочевидного поведения" может быть поводом еще раз заглянуть в спецификацию. А уж там, следуя шаг за шагом, можно выяснить причины этого поведения.
RyDmi
11.04.2019 09:08Нет смысла кидать линк на современную спецификацию, т. к. в табличке приведены как раз таки легаси аспекты, которые тянутся с начала. Не по всем пунктам, но для большинства причиной будет плохой дизайн языка.
PsyHaSTe
12.04.2019 01:43Я вот честно скажу, что 5 лет писал на C#, пока понадобилось заглянуть в ECMA334/335, и то для того чтобы свой интерпретатор написать. А в жсе получается два объекта сложить нельзя чтобы не пришлось знать все нюансы? Такое себе.

diomas
10.04.2019 20:56+1оказывается в стандарте юникода есть вариант объединения не только emoji, но и просто символов… Но это — совсем другая история.
Как по мне, так именно эта история. Обычно юникод перед анализом нормализуют: либо разбивают все разделяемые символы на спец последовательности, либо наоборот собирают все последовательности в соответствующие символы.

ilammy
10.04.2019 21:33+2Далеко не для всех последовательностей есть собранные символы. Большинство из тех что есть, существуют больше по историческим причинам.

LazyTalent
10.04.2019 21:18+5Почему-то я сразу споткнулся вот об это:
Если с теорией все просто — мой любимый вопрос это: «чему равен typeof null?», по ответу сразу можно понять, кто сидит перед тобой, джун — просто правильно ответит, а претендент на сеньера, еще и объяснит почему.
А потом я увидел это и желание читать дальше, почему-то, пропало
По этому я на собеседованиях давал задания
Я не знаю кто я. Джун, мидл или кто-то еще, но если меня просят сказать, что будет в результате операции, то я и скажу результат.
Если попросят результат и объяснить почему — они это и получат.
Без ТЗ — результат ХЗ
drch Автор
10.04.2019 22:10-6Простите, я вас, вероятно, неправильно понял. Вы на собеседованиях отказываетесь отвечать на теоретические вопросы и решать небольшие задачки?
Многие не знают, кто они: "Джун, мидл или кто-то еще", это нормально, границы очень условны и размыты, однако в вакансии в 90% случаев указано Junior/Middle/Senior, а значит кандидат, если приходит собеседование сопоставляет свой уровень с указанным.
LazyTalent
11.04.2019 05:14+1Я не отказываюсь решать задачки, я отказываюсь быть телепатом.

Shultc
11.04.2019 13:01Это, кстати, тоже иногда важно. Я работал на нескольких позициях, где умение быть телепатом было чуть ли не основным навыком. Когда ты сам можешь понять, что нужно условному «заказчику» — это может сэкономить уйму времени в будущем.
Я часто вспоминаю цитату Генриха Форда:
Если бы я спросил людей, чего они хотят, они бы попросили лошадь побыстрее.
Когда ко мне приходит менеджер какого-нибудь отдела, и просит написать решение для их проблемы, я слушаю что он от меня хочет, но делаю то, с чем ему будет удобнее и быстрее работать. За последние 5 лет все всегда оставались довольны.
Хотя, разумеется, это зависит от позиции, на которую ты идёшь.
LazyTalent
11.04.2019 14:09Такое возможно, если ты, например, фриласер и тебя душит жаба отдавать процент менеджеру. От компании, особенно с таким пафосным подбором персонала, я ожидаю, что у них уже есть в штате специально обученный человек для работы с клиентом.
У тому же, если я правильно понял, в начале статьи шёл разговор об отборе простых джун/мидл разработчиков, без всяких экстрасенсорных способностей.Shultc
11.04.2019 15:45Ну, это как раз способ проверить, есть у человека эти самые экстрасенсорные способности, или нет. И от этого уже и отталкиваться.

Lexicon
11.04.2019 14:56Это всегда важно, но внезапно, не на техническом интервью.
Например, тестовые задания и руководители их применяющие серьезно надоели IT-сообществу потому(среди прочего), что составить его так, чтобы отсутствие телепатической связи с соискателем не выливалось в часы времени, потраченные на: угадывание целей, критерий оценки, осмысленности бесполезных указаний и пр. достаточно сложно.
И разумеется высокоуважаемый руководитель обычно не готов тратить время на выполнение своей прямой обязанности, растрачивая время соискателей зря.
В вашем примере известно, что коллега некомпетентен и разрешается принять решение за него. Если предположить, что некомпетентен руководитель(который обычно собеседует), собеседование просто теряет смысл.
Shultc
11.04.2019 15:44Как по-мне, то не руководитель некомпетентен, а он лишь даёт пример того задания, которое ты можешь услышать у себя на работе. И смотрят на твою реакцию.
Это как дать слесарю задание на собеседовании что-нибудь выпилить на станке, а он должен ответить, что он не может это сделать сейчас, так как у него нет защитных очков, например.
Всё-таки цель собеседования — проверить, подходит ли человек для работы, на которую он собеседуется, а не просто поставить абстрактную оценку его умениям.

Wesha
11.04.2019 22:33Если бы я спросил людей, чего они хотят, они бы попросили лошадь побыстрее.
И чем ему не нравилось средство передвижения со встроенным автопилотом, которое заправлялось само от экологически чистой солнечной энергии (посредством травы)?..
PsyHaSTe
12.04.2019 01:45Как по мне, вопрос "Разверните строчку" — нормальный вопрос на собеседовании, а нормальные ответ собеседуемого состоит в том, чтобы начать задавать уточняющие вопросы.
А вообще, вспоминаем "Условие как компромисс".
puyol_dev2
11.04.2019 20:27+1Тоже странно. Мне почему-то казалось, что сеньор от джуна отличается скоростью и простой (эффективностью само собой) решения задачи, а не полнотой академических знаний. А то ведь получается, как в школе у плохой училки: своими словами не надо, рассказывай слово в слово, как написано в учебнике

Nomad1
10.04.2019 21:34Окей, эмодзи это по-сути красивости и их объединения это уже крайности. А как вам задача инвертировать строку с текстом арабицей?

tyomitch
10.04.2019 22:39А в чём проблема? Алфавит как алфавит.
Alexufo
10.04.2019 23:24+1Не, там составные буквы, кода два а символ один. Забыл это умное слово. При реверсе у вас будет белиберда.
Например, слово «Нет» по арабски "??" но если вы будете его удалять, нажать backspace придется два раза. Хоть браузер и выделяет его с двух раз, символ все равно один.
Nomad1
10.04.2019 23:58Как писали ниже, там много лигатур и изменений написания в зависимости от порядка символов и положения символа в слове. Если тут найдутся востоковеды, может подскажут, бывают ли вообще у арабов палиндромы и эксперименты с порядком букв.
Zenitchik
11.04.2019 00:08Работа с лигатурами — требует уточнения задания. Нужно ли считать лигатуру одним символом, или наоборот нужно её разбить, а после инверсии, если возможно, составить новые лигатуры.
khim
11.04.2019 03:21Не совсем. Каждая арабская буква существует в пяти видах: «платоническая» буква, отдельно стоящая буква, буква в начале, середине и конце слова.
Соответственно после реверса «буква, стоящая в начале слова» превратится в «букву, стоящую в конце слова» и наоборот.Zenitchik
11.04.2019 13:51Соответственно после реверса «буква, стоящая в начале слова» превратится в «букву, стоящую в конце слова» и наоборот.
Это неочевидное поведение, которое должно быть указано в ТЗ.khim
11.04.2019 17:05А история со смайликами или демпозированной «й» — не должна?
Zenitchik
11.04.2019 17:40Со смайликами — не должна, т.к. это целые символы (хоть и кодируются двумя парами байтов), с декомпозированными символами — должна, но это поведение по крайней мере выглядит логично (декомпозированный символ всё-таки подразумевает собой один символ языка).
А вот приколы типа заглавных букв в начале, парных скобок и т.п. — это уже спецтребование. Потому что реверсируя строку языка — мы не получим валидный текст на этом языке, а гоняться за декорациями в и без того невалидном тексте, без отдельной на той команды, не стоит.khim
12.04.2019 01:20Со смайликами — не должна, т.к. это целые символы (хоть и кодируются двумя парами байтов), с декомпозированными символами — должна
А не объясните чем отличается смыслик от какой-нибудь буквы «о?» в слове «бо?льший».
Ну просто очень-очень интересно что должно быть в голове у человека, который считает то, что описано в статье (и что даже Хабр отказывается за валидный текст признавать) одним символом, а «о?» — двумя.
Потому что реверсируя строку языка — мы не получим валидный текст на этом языке, а гоняться за декорациями в и без того невалидном тексте, без отдельной на той команды, не стоит.
Это правда — но я, как раз, эмодзи бы записал в то, что требует «спецтребований».Zenitchik
12.04.2019 12:54А не объясните чем отличается смыслик от какой-нибудь буквы «о?» в слове «бо?льший».
Тем, что смайлик — это целый юникодный символ (кодируется суррогатной парой), а «о?» — это два юникодных символа.
Это правда — но я, как раз, эмодзи бы записал в то, что требует «спецтребований».
Дело не в том, что они эмодзи, а в том, что они — юникодные символы. Символы, кодируемые суррогатными парами — далеко не только эмодзи.
Вот, например блок unicode-table.com/ru/blocks/mathematical-alphanumeric-symbolskhim
12.04.2019 19:51Тем, что смайлик — это целый юникодный символ (кодируется суррогатной парой), а «о?» — это два юникодных символа.
Вы вообще-то статью читали? Вот начиная со слов Подождите ка, с недавних пор мы можем указать цвет для смайла, и что же будет, если мы передадим такой emoji в функцию?
Там может быть и один кодпоинт и два (см флаги) и больше (вот эти вот, упоминаемые в статье, чёрные руки и всякие школьные учительницы — это 2-3 кодпоинта).
Символы, кодируемые суррогатными парами — далеко не только эмодзи.
Совершенно верно. И именно поэтому возникает вопрос: с какого перепугу мы начали, вдруг, заботится, о «разноцветных» смайликах, но «забили» на диакритику, арабику, корейцев и прочее.
Так-то задача «разверните строку, состоящую из кодпоинтов» — вполне корректна… только она не имеет ничего общего с обсуждаемой статьёй.Zenitchik
12.04.2019 21:23+1Подождите ка, с недавних пор мы можем указать цвет для смайла, и что же будет, если мы передадим такой emoji в функцию?
Да, я, похоже, упустил контекст беседы. Комбинируемые символы нужно либо не обрабатывать вообще, либо обрабатывать все до единого.
Zenitchik
10.04.2019 22:18+2Ну, если влоб, чтобы не было приколов с суррогатными парами:
const strReverse = str=>{ let result = []; for(let a of str){ result.unshift(a); } return result.join(''); }
Получилось коряво, но я не успеваю отредактировать в нормальный вид.
Случаи с декомпозицией — отдельная штука, тут нужно писать функции для нормализации юникода.Zenitchik
10.04.2019 23:10И всё равно я хрень написал… Пардоньте. Отсюда мораль: не надо торопиться.
const strReverse = str=> [...str].reverse().join('');
Так лучше.
Alexufo
10.04.2019 23:23Вроде как то раньше натыкаешься на эмоджи именно в момент сохранения. Я тоже как то удивился почему тип поля utf8_general_ci вроде всепоглощающий не сохраняет эмоджи и требует utf8mb4. А вот так вот.

roller
11.04.2019 00:11-2Какой классный язык, в котором нельзя быть уверенным даже в примитивный функции split() (по словам автора)

nickolaym
11.04.2019 01:25+1Про комбинационную диакритику вы уже всё поняли (кстати, привет эппловцам! некоторые приложения на маке вместо и-краткого делают и+кратка, повбывавбы!!!)
Следующий челлендж — это корректная работа с справа-налево и двусторонним текстом.
И вот тут я хз, какое должно быть ТЗ. То есть — как оно вообще правильно?
В случае с комбинационными символами (где каждому глифу соответствует цепочка кодов) всё просто: нарезаем на цепочки и переставляем их местами, сохраняя внутренний порядок.
А вот в случае с биди… тупое перемещение управляющих кодов расколбасит текст так, что он визуально совсем не будет похож на перестановку глифов на экране.
Oh wait… Самый простой способ перевернуть строку — это добавить управляющие коды биди!!!
Единственно, что такой переворот будет необратимым.
Reverse(Reverse(s)) != s.
Опаньки… А ведь в ТЗ про это не говорилось. Любишь подразумевать — люби и расхлёбывать.
Ах да, на сладкое. Есть такие штуки, как лигатуры. Помимо того, что некоторые лигатуры имеют свои собственные коды (например, ?), а некоторые не имеют (например, ij), — так ещё и от шрифтов зависит, будет ли пара символов f+i отображаться одним глифом или двумя.
Поэтому — следует ли слово "fifi" перевернуть в "i f i f" или в "fi fi" ?
Ну и совсем на сладкое. Загадка для любителей переворота строки.
Очевидно, что предикатIsPalindrome(s) = (s == Reverse(s)).
Вопрос: корректно ли он сработает на строке"(((а роза упала на лапу азора)))"?tuxi
11.04.2019 02:09Любишь подразумевать — люби и расхлёбывать.
вот это, с вашего позволения, я в свой блокнотик утащу, пригодится
Oz_Alex
11.04.2019 04:54Вопрос: корректно ли он сработает на строке "(((а роза упала на лапу азора)))" ?
Не совсем, косяки с пробелами — ароза упал ан алапу азор аrinaty
11.04.2019 11:19еще скобки
nickolaym
11.04.2019 12:43Скобки — это самое главное заподло в этой строчке ;)
Oz_Alex
11.04.2019 13:32Почему западло? Ну будет )))ароза упал ан алапу азор а(((
Задача же стоит просто строку развернуть. Задание выполнено. А функция палиндрома вернёт ошибку даже без скобок, из-за косяков с пробелами.
Если будет отдельно сказано сохранить функцию скобок — круглых, квадратных, фигурных и угловых — тогда будем работать над этимnickolaym
11.04.2019 15:40+1Так в этом и фокус. Цикл разработки:
- Написал функцию проверки на палиндромность.
- Написал юниттесты на чётное и нечётное количество символов, на пустые строки, всё работает, доволен как слон.
- Отдал тестировщику, он скормил типичный палиндром про лапу Азора.
Недолго думал, сделал пробело- и регистронезависимую реализацию, добавил Азора в юниттесты, всё работает, доволен как слон. - Отдал тестировщику, он скормил палиндром с кавычками:
«А роза упала на лапу Азора»(скопипастил из своего чеклиста в ворде).
Долго думал, сломал глаза, понял, пошёл ругаться с тестировщиком и архитектором на предмет ТЗ.
Скобками можно троллить соискателей:
Является ли палиндромом строка
(((((())
Кстати о биди. Алгоритм рендеринга биди-текста должен уметь самостоятельно разворачивать скобки в нужную сторону!
(А умеет ли он разворачивать кавычки с учётом национальной типографики — это хороший вопрос… Русские и английские лапки несовместимы, и это типичная ошибка при дизайне шрифта — вместо верхней bb-лапки сделать верхнюю pp-лапку, а потом русский курсив будет пускать кровь из глаз).
punpcklbw
11.04.2019 03:20Unicode уже давно развивается в неверном направлении. На языке разработчиков feature creep называется. Куча ненужных символов, создающих только путаницу и непоследовательность применения. Отсутствие ряда важных языковых нюансов. Колоссальная избыточность приводит к отсутствию полноценной поддержки со стороны шрифтов и ПО. По-хорошему все эти недоэмодзи нужно заменить полноценным микроязыком разметки со стандартизованными средствами форматирования, вставки изображений и спорадических неконвенциональных знаков…

sumanai
13.04.2019 17:34По-хорошему все эти недоэмодзи нужно заменить полноценным микроязыком разметки со стандартизованными средствами форматирования, вставки изображений и спорадических неконвенциональных знаков…
И получить второй HTML?
immaculate
11.04.2019 03:46+3Судя по комментариям, я один считаю автора снобом?
Начнем с первого вопроса. Буду говорить о Python, так как считаю себя экспертом в Python. Пишу на нем около 20 лет (начинал тогда, когда в России о Python еще никто даже не слышал). Сделал на нем множество проектов самой различной сложности. От CLI утилит до сайтов до десктопных GUI приложений.
Когда я только начинал писать на Python, то проштудировал от корки до корки все, что шло в поставке: Python Tutorial, Python Reference (где описаны формальным языком все конструкции языка), Python Library Reference (а она в Python большая была уже тогда, не то, что отсутствующая stdlib в Javascript).
Конкретно помню, что я заучивал специально, например, таблицу приоритетов операторов.
И вот статья автора заставила задуматься: а что же вернет
type(None). И хотя когда-то я наверное это знал, то сейчас пришлось полезть в консоль, чтобы узнать результат. Хотя это за 20 лет самых разных проектов ни разу мне не пригодилось и с вероятностью 100% никогда не пригодится. Более того, если я увижу этот вопрос спустя год, то скорее всего, мне снова придется лезть в консоль, потому что я уже не буду помнить. Потому что это ненужная в повседневной работе информация, и потому она будет вытеснена другой в течение месяцев.
Значит, по мнению автора, я всего-навсего джуниор?
Или вот точно помню, что учил таблицу приоритетов 20 лет назад. Смогу ли сейчас правильно выписать её по памяти? Уверен, что нет.
Сделал ли я за 20 лет хотя бы одну ошибку, вызванную неправильной расстановкой скобок из-за того, что не помню назубок таблицу приоритетов? Тоже нет.
Более того, представим, что автор статьи передал обязанность проводить собеседования кому-то другому на пару лет (и слава макаронному монстру за это!). Более того, он наконец решил перейти на нормальный язык программирования, пускай, Clojure, и два года писал только на этом языке. А затем вдруг решил перейти в другую компанию и вернуться к Javascript. Пришел на собеседование к копии самого себя двухлетней давности и получил те же самые вопросы. Сможет ли он пройти собеседование и не пасть позорно до джуниора споткнувшись на собственных же вопросах двухлетней давности?..
А если интервьюер еще попросит его привести формальные определения всех нормальных форм? Как в Javascript вычислить
sha256? Приоритет операций?
Да существует миллион способов унизить собеседуемого и показать собственную немерянную крутость. Только не думаю, что это имеет отношение к разделению на джуниоров, миддлов и сениоров.
drch Автор
11.04.2019 05:34Спасибо за комментарий, отвечу вам.
Порой (очень часто) на собеседования приходят молодые люди, претендующие на позицию (и зарплату) сеньера, не имеющие за своими плечами многолетнего багажа опыта — пара курсов, пара стартапов, пофрилансил, потом еще стартап и все, сеньер! Нет, не сеньер!
Я повторюсь — понятие джун/миллди/сеньер — субъективное. В этом комментарии — я говорю о своем восприятии.
Чуть отвлекусь на тему typeof null — нету в js нормального способа проверить является ли значение переменной объектом. Или юзать готовые решения, либо писать функцию самому. Вот оптимальная реализация:
function isObject (value) { return value && typeof value === 'object' && value.constructor === Object; }
И вот здесь и кроется ответ на вопрос: зачем я спрашиваю про typeof null на собеседовании — typeof null === 'object'!
Вот не будет завтра lodash, отрубит нам РКН интернет или еще какой катаклизм случится. Как этот молодой и талантливый специалист будет проверять что ему бекенд вернул? Как проверит, что другой молодой и талантливый не передал в его функцию невалидное значение? Никак, если не будет знать об этой маленькой особенности стандарта. Для меня — это основа основ, которую обязан знать каждый. Не знаешь — иди читай книги, проходи курсы, что угодно, но будь любезен — умей проверять переменные на валидность!
Что касается сеньеров — еще более субъективно, мне кажется, что сеньеру было бы интересно знать, почему это работает именно так, а не как-то иначе, вот и все.
Сможет ли он пройти собеседование и не пасть позорно до джуниора споткнувшись на собственных же вопросах двухлетней давности?
Вероятно да, вероятно нет. На мой взгляд нельзя быть хорошим во всем, если 2 года плотно изучать другой язык и его нюансы — можно что-то, если не позабыть, то отложить в дальние уголки памяти, из того языка, который изучаешь сейчас. Это нормально. Правда тут в том, что имея большой опыт в вашей нынешней специализации — будет проще восстановить знания и заполнить образовавшиеся пробелы.
Искренне надеюсь, что смог донести до вас свою мысль.vintage
11.04.2019 08:20Позвольте я упрощу ваш высокосеньёрный код и поправлю, чтобы он не возвращал что попало вместо boolean:
function isPOJO (value) { return value ? value.constructor === Object : false }
asmln
11.04.2019 08:23+1Порой (очень часто) на собеседования приходят молодые люди, претендующие на позицию (и зарплату) сеньера
Вот это ключевое. Надо сбить зп.
Разве можно этому молодому щеглу платить почти как мне?! Ну ка переверни мне строку с арабскими смайликами и перфокарту прочитай. А то вдруг РКН запретит JS или ещё какой катаклизм случится.
Это я шучу. На самом деле вы имеете право собеседовать как считаете нужным. Вам же потом с результатами собеседований работать.
qrKot
11.04.2019 09:06Вот не будет завтра lodash, отрубит нам РКН интернет или еще какой катаклизм случится. Как этот молодой и талантливый специалист будет проверять что ему бекенд вернул?
Сори, конечно, за откровенность. Но в случае отрубания интернета РКНом «проверить, что там вернул бекенд» в списке приоритетов будет занимать исчислимую на пальцах позицию снизу списка (сначала проблему доступа к репозиториям решите, например). Не говоря уж о катаклизме, в случае которого этой проверке в списке приоритетов места не найдется совсем.

markmariner
11.04.2019 09:50Окей, предположим, что РКН вправду заблокировал lodash и что-то там про типы теперь знать нужно.
Но зачем строку-то переворачивать? Это реально нужно в каком-нибудь проекте? Вы на вашей работе хоть раз переворачивали строку в промышленном коде?
lexey111
11.04.2019 11:26var d = Object.create(null, {'d': {value: 42, writable: true}})
typeof d === 'object'
isObject(d) === falsedrch Автор
11.04.2019 11:29У того же Лодаша — есть целыз 3 ф-и для проверки на объект, и только одна из них обрабатывает ваш кейс.
isObject — нет
isObjectLike — нет
isPlainObject — даlexey111
11.04.2019 13:53как по мне, неплохой вопрос сеньору, большой пласт поднимает
JustDont
11.04.2019 14:37Гораздо более интересный вопрос сеньору (не автору, а нормальному сеньору) — это «A зачем вам нужна проверка isObject()? В какой реальной ситуации вы намерены ей воспользоваться, и как именно? Почему в этой ситуации нельзя будет использовать is<более узкий тип>()?»
PS: А еще меня забавляет ирония ситуации, в которой в ветке комментов два (скорее всего хороших) программиста пишут функции isObject() и isPOJO(), которые возвращают значения, совсем не обязательно соответствующие своему названию.lexey111
11.04.2019 14:42С этим я тоже согласен, практическая применимость такой функции сомнительна. Я больше на тему «хорошо бы знать, как создаются объекты и в чём может вылезти разница» — вот это сеньору неплохо бы понимать.
По мне, если соискатель ответит на вопрос «нет ли подвоха в этой функции», даже без примера, то это прекрасно.vintage
11.04.2019 16:33Ну, вот, например, полезное применение. Позволяет использовать POJO в качестве ключей по значению, а не по ссылке.
vintage
11.04.2019 16:29isPOJO-то чем не угодил?
JustDont
11.04.2019 16:35Да вон же несколькими комментариями выше вам его сломали.
Если копать вглубь, в JS вы всегда дойдете до duck typing — ну и гляньте, что вы проверяете в вашем методе с точки зрения duck typing. Что у него конструктор определенного вида есть? А занафига мне это для POJO? Когда я вижу «POJO» в яваскрипте, я ожидаю, что у меня есть возможность читать и писать свойства — и как вы это проверили в вашем методе? Да никак. Итого у меня есть
var veryMuchPOJO = Object.create(null);
в который я легко могу писать и читать свойства, а вы своей функцией мне говорите «false».
Ваша функция точно не будет вызывать вопросов, если она будет
function surelyIsAPOJO()
Тут по названию видно, что могут быть ложноотрицательные срабатывания ;)vintage
11.04.2019 16:51Object.create(null)
Это не POJO. POJO создаётся через литерал.
JustDont
11.04.2019 16:58С чего бы?
Давайте так: с точки зрения спеки у нас нет типа «POJO», поэтому все измышления о статическом типе можно на этом и закончить.
А с точки зрения duck typing критерий POJO — это возможность читать и писать свойства. Всё.
Как оно создаётся — вообще не важно. Если вы хотите продолжать утверждать, что важно — у вас тогда
var totallyPOJO = Object.create(Object.prototype)
будет не POJO. Не литерал же.vintage
11.04.2019 17:10Есть то, что в индустрии принято называть POJO. Выделяется оно потому, что его удобно создавать прямо в коде без предварительного объявления, и он переживает сериализацию через JSON без плясок с бубном. Так что давайте вы не будете высасывать собственные бесполезные определения из пальца.
JustDont
11.04.2019 17:21Есть то, что в индустрии принято называть POJO.
Yep. И, как я уже говорил, это штука, куда пишутся свойства и откуда читаются свойства. Не просто так, конечно, а с определенным контрактом (а иначе JSON.stringify и прочие не взлетят). И до тех пор, пока этот контракт выполняется — вы имеете дело с POJO.
Как оно при этом создавалось — вообще не имеет значения.
«Так пишут на SO» — аргумент, мягко говоря, не очень хороший. Попробуйте что-нибудь еще.
PS: На всякий случай — созданное через Object.create переживёт сериализацию в JSON просто на ура. Если вдруг вам это не очевидно.
PPS: Вы, я надеюсь, понимаете, что я эту беседу веду совсем даже не с позиций применимости. В мире не больно много любителей посоздавать объекты без Object.prototype в цепочке, и их всегда можно послать подальше, даже если они вдруг вам встретились. Беседа тут о том, что неплохо бы вот этот разрыв в типах осознавать. Просто что он существует. И что когда вы применяете фактически duck typing, но проверяете не нужную функциональность, а какие-то совершенно неважные свойства — вы немножечко так лукавите в коде.vintage
11.04.2019 17:24Я вам по секрету скажу, что
Object.freeze({})— это тоже POJO. Ещё раз — не выдумывайте свою терминологию, иначе вас никто не будет понимать.JustDont
11.04.2019 17:34Конечно. И? Вы всерьез считаете, что я в нескольких словах («читать и писать свойства») вам смогу описать корректно всю спеку? Если вам не нравятся словесные приближения, то я далее начну писать «соотвествует спеке» вместо этого.
Ещё раз — не выдумывайте свою терминологию, иначе вас никто не будет понимать.
И это мне говорит человек с терминологией «POJO — это когда через литерал».vintage
11.04.2019 20:28Для особо одарённых: Любой POJO может быть создан через литерал, либо эквивалентный использованию литерала код.
Для ещё более одарённых: POJO — объект, имеющий тот же прототип, что и любой литерал.
На этом давайте закончим нашу специальную олимпиаду.
Soo
11.04.2019 11:30+1typeof null === 'object'!
— Это официальный признанный баг языка, оставленный для совместимости. Хотя, null, на самом деле, это отдельный тип данных.
Всё, я могу претендовать на зарплату сеньёра?)Zenitchik
11.04.2019 12:06Null — это спецзначение объектного типа, обозначающее отсутствие ссылки. Всё более чем логично.
Так же как NaN это спецзначение типа с плавающей точкой.
GRaAL
11.04.2019 11:35+1Я, возможно, ненастоящий сеньор, но за 12 лет работы мне нужно было определять «объект ли переменная» раза четыре, и задачи это были специфические (типа проверки соответствия произвольного объекта схеме). Даже реверс строки мне чаще пригождался :)
Я, безусловно, держу в голове закладку на тему «в js надо аккуратно с undefined и null», но помнить наизусть все детали (в том числе что там возвращает typeof null) — голова треснет. Это такая вещь, которую я могу в консоли проверить в любой момент. Мне достаточно помнить, что особенности есть, но не вижу смысла зубрить конкретику.
Как бы вы отнеслись к ответу «не помню точных деталей, но если мы обрабатываем произвольное значение заведомо неизвестного типа, то лучше на null и undefined проверить отдельно в самом начале — наверняка у нас какая-то отдельная логика для этого случая должна быть»?drch Автор
11.04.2019 11:41+1Отнесся бы положительно и спросил бы о вашем опыте, когда результат был неочевиден, поделился бы своим.

Perlovich
11.04.2019 11:39Как проверит, что другой молодой и талантливый не передал в его функцию невалидное значение?
Напишет unit тесты и увидит, что для null работает не как ожидалось?
strannik_k
11.04.2019 11:52+1Вот не будет завтра lodash, отрубит нам РКН интернет или еще какой катаклизм случится.
Извиняюсь, но оторванный от реальности дурацкий аргумент.
В том же стиле можно и так рассуждать: «Не будем его нанимать, он же смертный, он можеть умереть завтра.».
Если бы мне кто-то правильно отвечал на все эти тонкости языка, я бы подумал в следующем порядке:
1) Он новичок, только недавно все это выучил.
2) Он недавно хорошо подготовился.
3) Он наверное работает все время с одним и тем же, не развивается, не писал функции, которые упрощает подобные проверки, поэтому хорошо помнит основы, тонкости.
4) Крайне маловероятно, но может он обладает феноменальной памятью.
5) Ладно, ладно. И вправду, крутой специалист. Наверное ботан какой-то, который кроме компьютера ничего в жизни не видел.
Не думаю, что вопросы про тонкости языка покажут опыт.
Есть более полезные вещи, которые будет более полезно и изучить, и спросить.

igrishaev
11.04.2019 14:23Не в ваш адрес, а просто в тему обсуждерия.
Операция
type(None)лишена смысла, потому что для проверки на None используютis None, что очень дешево. И то же самое в других языкак. Поскольку не может быть несколько разных null, nil, None, то проще сравнить значение, а не тип.
puyol_dev2
11.04.2019 20:34Об этом же написал чуть выше — это тот случай, когда теория будет суха, а древо программирования зеленеть будет от тысяч часов практики. Мозг будет выбрасывать со временем ненужные знания, оставляя готовые кейсы. Уже пишешь не задумываясь, просто мозг уже знает, что просто так надо
khim
12.04.2019 01:26Уже пишешь не задумываясь, просто мозг уже знает, что просто так надо
Это неплохой навык, но иногда стоит остановиться, посмотреть на то, что ты написал и подумать на тему «а почему ты так это написал».
Потому что мозг — он каргокультирование любит, и если специально не перепроверять себя, то легко, забыв основы, перейти с написания правильного и хорошего кода перейти к написанию чушь, над которой вы тоже не будете задумываться.
Или, образно: да, практика поливает ваше «древо программирования», но иногда нужно перестать лить воду и убедиться что корни не сгнили…

dipsy
11.04.2019 04:06Всё время пока читал статью думал, что меня тут смущает. Наверное то, что надо для начала определить для себя понятие "строка". Если мы хотим хранить там смайлики, то это уже сериализованная последовательность объектов, для которой должен быть написан соответствующий контейнер, итераторы и всё необходимое, чтобы можно было применить стандартный алгоритм reverse.
С таким же успехом можно считать элементом строки например слово и делать реверс по словам.Wesha
11.04.2019 06:53надо для начала определить для себя понятие "строка".
fukkit
11.04.2019 12:09+1Зря вы так. Вопрос правильный.
Строка задаётся последовательностью элементов строки. Определив, что именно считать «элементом» строки (байт, кодпоинт или непрерывное визуальное представление нескольких кодпоинтов, например, «эмоджи»), можно создать правила выделения элементов из строки, после выделения элементов — определить их порядок, затем переопределить его в соответствии с условиями задачи и создать новую строку с переопределенным порядком элементов.
Проблема в том, что за каким-то чудом последовательности кодпоинтов стали изображать визуально слитно. И если в применении к алфавитным символам это (с большим скепсисом) еще можно принять за необходимость, то составные свистелки «эмоджи» — просто за гранью добра и зла.
Не хотели расширять формальную спецификацию UTF и для этого… барабанная дробь… расширили её, введя составные иероглифы.
Таким образом, реальный парсер UTF теперь в любом случае должен содержать дерево всех допустимых комбинаций в виде структуры или конечного автомата — уже не суть.
Локальные проблемы типа тех, что JS split() не использует правильный парсер, всего лишь следствие того бардака, что устроили с прекрасной кодировкой UTF любители слать картинки непременно негритянской руки текстом.Wesha
11.04.2019 22:23Зря вы так. Вопрос правильный.
Именно! Я про то и говорю: задание было —Напишите функцию, которая принимает на вход строку, а возвращает эту строку «задом наперед»
А теперь мы насмерть умучиваем задающего, заставляя его объяснить, что такое, по его мнению, «задом наперед», иличто именно считать «элементом» строки
с учётом 100500 граничных случаев.
Conung_ViC
11.04.2019 08:55а иврит с огласовками ваш алгоритм обработает?
?????? ?????? ????? ???????, ????? ??????? ?????? ??????
идея в том, что сначала пишется буква, а потом символ огласовки. причем иногда их может быть 2 (как в первой букве). Да, и всё это — справа налево.
Да, а если туда еще и числа вставить, то вообще жуть получится. Потому что числа в иврите пишутся слева направо.
?????? ? -1982
я родился в 1982 году.
ksbes
11.04.2019 09:24Ну с числами-то как раз всё будет нормально, а вот огласовки применяться на другие буквы. Unicode потихоньку превращается в тьюринг-полную хрень (что, в принципе, не так уж и плохо). Потому такие задачи так же потихоньку упираются в задачу остановки (выполнить алгоритм наоборот — равносильно убедится, что он не повиснет) — и, следовательно, становятся принципиально не разрешимыми в общем случае.

impwx
11.04.2019 11:05+2Давать на собеседовании задачу на тонкости юникода — это издевательство.
Zenitchik
11.04.2019 12:15Ну, про суррогатные пары — стыдно не знать. Это классика из классик, на протяжение по крайней мере 10 лет на всех форумах.

vlreshet
11.04.2019 12:32На каких форумах?
Zenitchik
11.04.2019 13:37По JavaScript-у. Всюду, где тусят начинающие JavaScript-еры, эта тема поднимается.
Wesha
11.04.2019 22:39>На каких форумах?
Форумах любителей выражать свои мысли через эмодзи, конечно.
(Кстати, форма отпраки коммента на хабре эмодзи не поддерживает — только что проверил).Zenitchik
12.04.2019 15:44На хабре, как я заметил, не только эмодзи, но и другие суррогатные пары не поддерживаются.
impwx
11.04.2019 13:18Компромисс в данной ситуации — если собеседуемый скажет «вот реализация, но с суррогатными парами она работать не будет», а собеседующий это примет. Если первый не вспомнит, или второй заставит это непосредственно реализовать — вот это уже будет плохо.
fukkit
11.04.2019 11:08+4Простое правило счастливой жизни:
Не ходите в проекты/организации, где разработчикам требуется «typeof null»
Нервы с годового бонуса назад не откупишь.

un1t
11.04.2019 11:56+3> чему равен typeof null?
Ну наконец то найден вопрос которым сразу можно отличить джуна от сеньора! (нет)
> Вот не будет завтра lodash, отрубит нам РКН интернет или еще какой катаклизм случится.
РКН отрубит доступ разрабов к их жестким дискам что ли? Просто не могу себе представить такого сценария, что lodash там или jquery хоп и пропал. Разьве, что по электромагнитной бомбе на все города сбросить. Но в этом случае, проблема отсутствия lodash вряд ли будет кого-то волновать.
> Что касается сеньеров — еще более субъективно, мне кажется, что сеньеру было бы интересно знать, почему это работает именно так, а не как-то иначе, вот и все.
Кому-то это интересно, кому-то другое, а таких нюансов в каждом языке, фрейморке, БД, протоколе милллион. Всего не изучишь, да и смысла нет, тем более что все это меняется каждые два года. Специфика работы у всех разная. Справшивать, не понимая, чем человек вообще раньше занимался не правильно. Вот например начинаешь спрашивать человека по SQL и он валиться на group by having. Значит ли это что это джун? Нет, не значит, надо для начала спросить, с какими БД он вообще работал или в чем заключалась его работа.
Надо спрашивать не что человек не знает и не умеет, потому что таких вещей бесконечное множество, а что он знает и умеет.
И почему бы не спросить что-то из того что вы используете на работе? Неужели, основная ваша работа заключается в переворачивании сторк? Наймете человека, будет сидеть по 8 часов и переворачивать строки. Почему бы не спросить что-то более приближенное к практике?
Perlovich
11.04.2019 12:18мой любимый вопрос это: «чему равен typeof null?»
Это нечестный вопрос. Пригождается очень редко. Забывает очень быстро. Код, который полагается на такое поведение, должен комментироваться. Я забуду через неделю, что возвращает typeof null и мне за это не стыдно. Я не могу каждые полгода перечитывать спецификации Javascript только для того, чтобы быть способным ответить на этот вопрос или для того, чтобы приготовиться к случаю (цитата) «Вот не будет завтра lodash, отрубит нам РКН интернет или еще какой катаклизм случится».
Вообще, завалить любого человека на edge-кейсах очень просто. Даже если он реально сильный разработчик с богатым опытом.
У меня вот любимые области, с которыми я много работаю и о которых много читаю, — это особенности HTTP протокола и безопасность в вебе. Это огромные темы, на которые написано много материала и в которых происходят постоянные изменения. Браузеры/сервера постоянно меняются. И эти темы имеют непосредственное отношение к веб-разработке.
Я уверен, вам было бы неприятно, если бы я начал собеседование с заковыристых вопросов по хеадерам, потом скажу, что это вот используется в наших проектах, и раз вы не знаете ответ на этот вопрос, то возможно вы даже до джуниора не дотягиваете.vvadzim
11.04.2019 13:55Это нечестный вопрос. Пригождается очень редко.
На самом деле правильный вопрос. typeof null нужен настолько же часто, насколько и сам оператор typeof, потому что обычно после typeof стоит переменная, а не литерал, а дальше какая-то логика. Т.е. если вообще этот оператор в коде используется или может использоваться, то знать про typeof null нужно. Просто чтобы на самом деле понимать, как работает код.schrodenkatzen
11.04.2019 14:11>Результат typeof null == «object» – это официально признанная ошибка в языке, которая сохраняется для совместимости. На самом деле null – это не объект, а отдельный тип данных.
Что может быть лучше чем компания намеренно полагающаяся на обратную совместимость древних багов в интерпретаторе.
Perlovich
11.04.2019 14:12Я с вами не соглашусь.
Во-первых, до использования typeof можно явно проверить на null. Прям через оператор сравнения. Это будет явно и очевидно для всех читающих.
Во-вторых, я такие вещи обязательно покрываю unit тестами. Если есть какое-то не очевидное поведение JS, о которым я забыл, я об этом сразу узнаю. Уж на null в тестах проверить можно.
Возможно, есть специфичные проекты, где проверка typeof null — это нечто обыденное, что встречается часто, и без знания этого с проектом просто нельзя работать. Но я в таких проектах пока не работал (что, конечно, не значит, что их нет). Но даже там при ревью тебе коллеги напомнят/подскажут об этой вещи, если эта такой частый у них кейс.vvadzim
11.04.2019 14:18Вот для того, чтобы явно проверять на null и undefined, и для того чтобы в тестах их писать, и для того чтобы понимать, зачем всё это тут понаписано и нужно знать, что «есть особенности».
Я только написал, что если typeof вообще используется в проекте, то про typeof null уже нужно знать. Часто ведь ставят что-то вродеtypeof x === "object"
fukkit
11.04.2019 14:15+1Проверка на null даст значительно больше информации, чем проверка на typeof null.
Отдельно Вам доставит (скорее всего, проблем) попытка поработать с null как с объектом
a = {}.field //undefined b = null.field //TypeError: null has no properties c = null d = c.field //TypeError: c is nullvvadzim
11.04.2019 15:27Я в курсе :) Именно поэтому особенности работы оператора typeof знать приходится :)
Никто не проверяет typeof null, проверяют typeof x, где x некая переменная. И вот чтобы правильно понять код, приходится знать про typeof null.JustDont
11.04.2019 16:06Гораздо лучше знать, что если typeof кем-то применяется для чего-то кроме === 'string' и === 'number', то скорее всего код делает не совсем то, что от него ждут.
И даже если он применяется для проверки на строку и число, он всё равно может делать не то, что от него ждут (впрочем, этот случай уже куда менее вероятен).
S-trace
11.04.2019 15:10Налицо явный баг в split: developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/String/split#Syntax
str.split([separator[, limit]])
Параметры
Раздел
separator
Необязательный параметр. Указывает символы, используемые в качестве разделителя внутри строки. Параметр separator может быть как строкой, так и регулярным выражением. Если параметр опущен, возвращённый массив будет содержать один элемент со всей строкой. Если параметр равен пустой строке, строка str будет преобразована в массив символов.
То есть, должен был получиться массив символов, а получился массив байтов.
Полагаю, вы уже зарепортили этот баг?
WraithOW
11.04.2019 15:32Загляните в английскую версию, там есть приписочка:
Attention: If an empty string ("") is used as the separator, the string is not split between each user-perceived character (grapheme cluster) or between each unicode character (codepoint) but between each UTF-16 codeunit. This destroys surrogate pairs.
akryukov
11.04.2019 16:16+1Мини-хабра-самоубийство
мой любимый вопрос это: «чему равен typeof null?»
Прекрасная иллюстрация полезности статической типизации
staticlab
11.04.2019 16:42Прекрасная иллюстрация полезности статической типизации
Если null — это не объект, то почему во многих языках со статической типизацией его можно присвоить переменной некоего объектного типа? Можно ли тогда считать их строго статически типизированными?
akryukov
11.04.2019 17:38Если в переменной объектного типа находится нулл, то это значит отсутствие ссылки на объект.
В обычной ситуации "под капотом" в переменных объектного типа находятся не сами объекты, а ссылки на них. Нулл — отсутствие ссылки. Присваивание нулла значит "теперь ссылка в этой переменной никуда не ведет".
В JS же, судя по всему, применен паттерн Null object.
Zenitchik
11.04.2019 17:46Всё встаёт на свои места, если вспомнить, что в JS типизация таки есть. Хоть и динамическая.
Значение null означает, что переменная имеет объектный тип и нуллное значение.akryukov
11.04.2019 18:03+1Что куда встает?
Судя по статье, в JS сеньорам приходится запоминать табличку исключений и помнить, что "есть особенности". Рантайм съест нулл и не подавится.
В этом смысле идеальны языки со строгой типизацией, где компилятор будет тыкать носом разработчика еще на этапе написания кода. Вместо того, чтобы помнить табличку исключений, разработчику нужно думать: всегда ли тут существует значение? Что делать, если оно отсутствует?
staticlab
11.04.2019 18:16в JS сеньорам приходится запоминать табличку исключений и помнить, что "есть особенности"
Это не табличка исключений. Это следствие из особенностей работы оператора + для разных типов. Если вы будете складывать исключительно числа с числами и строки со строками (что в нормальной программе и происходит), то проблем не возникнет.
В этом смысле идеальны языки со строгой типизацией, где компилятор будет тыкать носом разработчика еще на этапе написания кода. Вместо того, чтобы помнить табличку исключений, разработчику нужно думать: всегда ли тут существует значение? Что делать, если оно отсутствует?
А вот и приходится думать, потому что компилятор с null не хочет помогать:
Object obj = null; String s = obj.toString();
Почему не тыкает? Код выполняться не будет. В JS то же самое:
var obj = null; var s = obj.toString();
Что там, что там — Null Pointer Exception. Значит статически типизированные языки не такие уж и статические? :)
akryukov
11.04.2019 19:01Значит статически типизированные языки не такие уж и статические? :)
Статические, но недостаточно строгие.
Почему не тыкает? Код выполняться не будет.
Потому что типизация статическая, но не строгая.
Так то и в scala со строгой типизацией тоже можно NPE поймать, но язык задуман так, чтобы все источники null завернуть в Optional и вывести на периферию I/O. В бизнес-логике нуллов вообще быть не должно. Там, где значение необязательно, используется Optional.
Вот и получается разница: в js/java у вас может что-угодно где-угодно оказаться нуллом и вы не обязаны писать обработку этих случаев.
В scala все что у вас может оказаться null, у вас Optional и вас компилятор заставляет учитывать такие случаи.
PsyHaSTe
12.04.2019 11:16А вот и приходится думать, потому что компилятор с null не хочет помогать:
Да вроде хочет:
staticlab
11.04.2019 18:11Вот у меня есть функция
void foo(SomeObject someObject) { someObject.doAction(); }
На вход я ожидаю получить объект типа SomeObject. Я знаю, что у него есть метод doAction(), который я намереваюсь вызвать. Компилятор подтверждает моё мнение и производит компиляцию. В продакшене внезапно выпадает NullPointerException, потому что программист Вася написал
SomeObject someObject = null; ... this.foo(someObject);
Компилятор ему снова ни слова не сказал, но код в принципе не мог быть выполнен. Получается, что язык вроде бы статически типизирован, но я тоже не могу доверять этой типизации и должен у себя в функции проверять someObject на null? Или Вася должен был проверить свой someObject на null?
В JS же, судя по всему, применен паттерн Null object.
Нет. Null object — это совсем другое.
akryukov
11.04.2019 19:04Получается, что язык вроде бы статически типизирован, но я тоже не могу доверять этой типизации и должен у себя в функции проверять someObject на null?
Все так. Java вроде статически типизирована, но при этом типизация недостаточно строгая, чтобы компилятором выявлять проблемы с null.
Null object — это совсем другое.
Я все таки уверен, что то же самое. Буду признателен, если вы объясните почему я заблуждаюсь.
staticlab
11.04.2019 19:19+1Я все таки уверен, что то же самое. Буду признателен, если вы объясните почему я заблуждаюсь.
Ну как же: https://en.wikipedia.org/wiki/Null_object_pattern
Вкратце: Null object — это специальный объект, имеющий такой же интерфейс, но условно не делающий ничего.
public interface Animal { void makeSound() ; } public class Dog implements Animal { public void makeSound() { System.out.println("woof!"); } } public class NullAnimal implements Animal { public void makeSound() { // silence... } }
Обращение к null object не будет вызывать NPE.
akryukov
11.04.2019 19:23Разница в интерфейсе. Выглядит как будто разработчики js держали в голове не произвольный переопределяемый интерфейс, а какой-то конкретный, в который null вписывается.
staticlab
11.04.2019 21:14Причём тут JS? Null Object — это просто паттерн объектно-ориентированного програмирования не применительно к какому либо языку.
DistortNeo
11.04.2019 17:42У null нет типа. Вы можете присвоить его объекту любого типа, и объект любого типа сравнивать с null.
staticlab
11.04.2019 17:59Вот. Значит в переменной типа SomeType может лежать не только объект, соответствующий интерфейсу SomeType, но и некоторое другое значение, которое не соответствует данному интерфейсу, но компилятор прощает это и позволяет обратиться к нему как будто бы это SomeType, а в рантайме потом выпадет NPE. При этом языки заявляются как строго статически типизированные. Не является ли это введением в заблуждение? JavaScript при всех своих недостатках по крайней мере такого не заявляет.
akryukov
11.04.2019 18:04При этом языки заявляются как строго статически типизированные. Не является ли это введением в заблуждение?
Если под "этими" языками понимать java и c#, то они типизированы статически, но не так уж строго. Есть куда стремиться.
staticlab
11.04.2019 18:18-1То есть на самом деле Java и C# — не строго типизированные языки?
akryukov
11.04.2019 18:44+2Строгость не бинарна. Грубо говоря, это количество правил, в которые компилятор будет вас тыкать носом. Чем больше правил, тем строже.
У java/C# компилятор просто сильно строже, чем в js.
У scala компилятор еще строже, чем в java.staticlab
11.04.2019 18:48Ок, а какое отношение ко всему этому имеет typeof null?
akryukov
11.04.2019 19:08Тем что даже в java и c# null это полное отсутствие значения, противопоставляя тому что в js это значение "ничего".
Zenitchik
11.04.2019 19:21+1Тем что даже в java и c# null это полное отсутствие значения
но не отсутствие типа переменной.
противопоставляя тому что в js это значение «ничего».
А вот тут Вы ошибаетесь. Никакого противопоставления тут нет. А логика в JS точно такая же: null — это отсутствие значения, но не отсутствие типа переменной.
DistortNeo
11.04.2019 20:36Языки разные бывают. В том же C++ можно передавать объект по ссылке, но ссылка не может принимать значение null. Или же non-nullable типы в C# 8. Вот и примеры более строгой типизации.
staticlab
11.04.2019 21:14Однако в том же C++ есть куча случаев неявного преобразования типов. В этом месте его типизация слабее.
puyol_dev2
11.04.2019 20:58Вот здесь очень подходит слово обнулить ) Просто удаляем ссылку на значение переменной, очищая память, присваивая переменной значение null
nerdeek
11.04.2019 18:19Ещё больше смешных вопросов для собеседования:
достаточно ли вы умны чтобы работать в google
P.S. Ну я понимаю, когда просят написать генератор паролей юзеров со встроенной мнемотехникой или сломать что-нибудь. А это и правда немного странно.
Zenitchik
11.04.2019 18:25Эм… Я достаточно умён, чтобы не покупать книгу с подобным дизайном.
nerdeek
11.04.2019 18:30Я не писал слово «покупать». Книга мне понравилась меньше, чем я полагал, но забавная, интеллект развивает.
Zenitchik
11.04.2019 19:33Извините. Это я чисто условно. В последнее время дизайн книг по программированию стал очень неакадемичным. Причём, этот же дизайн приводит к разуплотнению информации. А я в последнее время привык к околонаучной литературе и с большим неудовольствием читаю недостаточно лаконичный или слишком разреженный текст. Это, наверно, разновидность снобизма…
ExplosiveZ
11.04.2019 18:29Я примерно так отвечаю:
"\u202E" + source
и всё. Правда я не JS разработчик.
https://www.fileformat.info/info/unicode/char/202e/index.htm

cypok
11.04.2019 18:30+2Ради расширения кругозора: Swift один из первых (известных мне) языков, кто решился уйти от UTF-16 с его суррогатными парами и по умолчанию работает с юникодной строкой как с набором глифов. Из-за чего привычные способы работы с моноширинными строками у него не работают. Но задачка из топика решается тривиально (
String("...".reversed())).dougrinch
13.04.2019 10:43Помню, когда только начинал знакомство со свифтом через CodinGame, в части задач очень ругался, что не могу «как в нормальных языках» charAt(int) делать. Зато вот на подобных примерах как раз очень хорошо видно, что это действительно не баг, а фича.
nikandr23
11.04.2019 18:35-3> Напишите функцию, которая принимает на вход строку,
> а возвращает эту строку «задом наперед»
мы считаем что спрашиваемый умеет чтитать мысли и сам догадается что
— писать надо на каком то дибильном языке програмирования
— у аффтора вопроса свое болезненное понимание «оптимальности»
— хотя в вопросе вооще ничего нет про оптимальность
— но видимо обычный цикл for (длина строки..) — неправильный ответ
— рекурсивный алгоритм видимо тоже неправилен, (думаю аффтор наверно не понимает такого)
— ОППА сюрприз — аффтор считает что вызов reverse() это Нормально!
— аффтор болезненно влюблен в «const»
(давайте может просто спросим про гольфовые мячики в скулбасе?)
Ritorno
11.04.2019 18:54-2Автор узнал, что такое кодировка, и спешит поделиться этим со всем. Кликбейт-заголовок прилагается.
math_coder
12.04.2019 17:29Math.random()Есть понятие security through obscurity, а это, видимо, пример workability through obscurity?








robert_ayrapetyan
Я бы javascript вынес из тегов в заголовок, иначе когда доходит до задачи, то возникает легкое недоумение…
geisha
А ещё лёгкое недоумение тут вызывают методы собеседования автора. Приходишь ты такой на собеседование, а тебя спрашивают о знании стандарта, который позволяет поменять зелёную и коричневую какашки из юникода местами. [::-1] тоже, внезапно, не переварачивает html-страницу вверх ногами, не возвращает аргументы javascript-кода по return-value
и не делает меня молодым: так может ещё об этом спросить?bopoh13
Не стоит. В Ruby метод reverse выдаёт предсказуемый результат с указанной кодировкой.
NetBUG
В этом случае автор предлагает бороться с проблемами наивного подхода на выбранном стеке.
Мне кажется, что если эта проблема возникнет в продакшне хотя бы у одного разработчика, появится очередной модуль в npm для корректной манипуляции с Unicode-строками. Или уже есть, но никто не поискал.