
Если вы не понимаете, что такое DevOps, то вот краткая шпаргалка. DevOps — это набор практик, которые уменьшают страхи инженеров и сокращают количество сбоев в производстве ПО. Как правило, они же сокращают время выхода на рынок — период от идеи до доставки конечного продукта до клиентов, что позволяет быстро проводить бизнес-эксперименты.
Как начать DevOps трансформацию? Если кратко: выбираем сервис, с которого начнем процесс, выявляем тех, кто имеет отношение к сервису, строим Value Stream Map, создаем временную команду, которая будет заниматься трансформацией первое время и ставим ей задачу. Повторяем цикл нужное число раз.

Подробный план DevOps трансформации с примерами и инструкциями под катом — в расшифровке доклада Андрея Александрова — инженера в компании Express42, которая консультирует по проращиванию DevOps, ускоряя этот процесс, потому что уже построила карту граблей. Если вам кажется, что трансформация вам не нужна, или у вас такая специфика, что DevOps-практики не подходят, — используйте доклад как инструкцию по поиску и устранению ограничений.
Если вас беспокоит вопрос DevOps трансформации, то у вас большая компания, и нужно помаленьку масштабировать этот процесс на всю структуру. До тех пор, пока есть нужда трансформировать команду или устранить какое-то ограничение, алгоритм ниже можно повторять.
План наметили, начнем с первого шага — выбора сервиса. Первый критерий — время жизни: есть старые сервисы — legacy, и новые. Начинать можно и с тех, и с других.
Выбрать молодой сервис логично. Он свежий, нет еще устоявшегося процесса работы в команде, которая им занимается. Вокруг него нет горы технического долга, не нужно его все время чинить. Можем делать с ним все, что хотим.
В случае старого сервиса есть проблемы, связанные с тем, что менять всегда тяжело. Там уже есть набор каких-то серьёзных ограничений, но, возможно, им занимаются люди, которые уже готовы все перелопатить — они устали и хотят что-то сделать по-другому, потому что им больно.
Работа со старым сервисом создает мощный прецедент в вашей компании — можно что-то менять. Если вы изменили новый сервис, он катится на прод 100 раз в час, и все хорошо, то люди в вашей компании могут сказать:
— Это же новый сервис! Там же было все просто, попробуйте с нашей развалюхой что-нибудь сделать.
Legacy-сервис имеет смысл брать в трансформацию, когда вы делаете её с кем-то, например, если пригласили внешнего консультанта. Будем честны, трансформация будет шатать все, что только можно. Вы экспериментируете и не знаете, куда придете, какие технологии и зачем будете использовать, где и какие подводные камни в процессах возникнут. Поэтому новый менять проще.
Есть сервисы, которые представляют собой просто интерфейс для пользователей, например, простенький сайт или мобильное приложение. Но есть серьезные вещи в духе биллинга. Если что-то пойдет не так с биллингом — разбираться будет сложно. Здесь у нас тоже есть выбор.
Мы работаем либо с критичным сервисом, но уже из-за него страдаем, он создает ограничения, либо работаем с интерфейсом. Это второй критерий выбора. Аналогично, есть возможность привлечь опытного консультанта — работаем с тяжелым вариантом.
Но даже в этом случае я бы не советовал так делать, потому что, пока нет понимания с чем работать и в какую сторону трансформировать, брать критичную штуку и ее перетряхивать — не очень хорошая идея. Поэтому в данном случае мы предпочитаем работать с интерфейсом, поломка которого некритична.
Дальше рассмотрим команду сервиса. С теми, кто этим сервисом занимается, нам придется постоянно работать и взаимодействовать в очень тесном контакте.
Люди в команде условно делятся на две категории: консерваторы — живут в старом мире, или просто ничего не знают про DevOps, и инноваторы, которые тащат все модные практики. Вторые не всегда разбираются в теме, но они хотя бы к ней готовы.
С одной стороны консерваторы — опытные люди: давно в компании, разбираются от и до, но не знают как раз про практики. С другой стороны — инноваторы, которые что-то слышали, но в компании, скорее всего, работают не очень давно. С кем из них лучше работать?
С консерваторами придется взаимодействовать в любом случае, так как это их сервис. Придется с ними общаться, выяснять специфику сервиса, что можно сделать так, а что иначе. Мы зависим от их консультаций. Наверняка придётся им что-то поручать, потому что они свой сервис знают лучше. Поэтому важно, с какой командой мы в итоге будем иметь контакт.
На практике часто бывает, что у консервативных людей есть существенный опыт, но нет понимания, как жить дальше. Они просто боятся, что после трансформации и переделки сервиса, их уволят за ненадобностью. Иногда просто из-за непонимания того, что происходит, они саботируют работу.
У меня был случай, когда парень из команды ремонтировал все что угодно, потому что это якобы критичнее, чем то, что мы сейчас делаем. Мы ставим задачу: реализовать сегодня вот этот кусок — нет, на другом конце мира пожар, идем его чинить. С такими людьми работать сложно.
Люди из команды консерваторов часто забивают на задачи, либо откладывают их до последнего. А если, Джон Уиллис вас упаси, вы совершили ошибку и навесили им KPI за количество выполненных задач, а какая-то часть почему-то не включена в KPI, то они вообще ничего делать не будут. В общем-то, будут правы, потому что они тогда теряют премию.
С инноваторами проще — они лояльнее. Они уже что-то слышали, хотят куда-то идти, поэтому будут помогать. Нам нужны люди, которые готовы страдать первое время: если меняется сервис, то все шишки и грабли поймают инноваторы на правах первопроходцев. Инноваторы хотят все самое новое и модное, и пострадать.
Консерваторов позже можно обратить в свою веру. Когда вы покажете, что изменили кусочек и все хорошо работает, скорее всего, они тоже захотят попробовать и примут новую DevOps-религию.
Если есть возможность позвать внешнего консультанта, вместо нового — берем старый сервис, из-за которого уже страдаем. Люди, которые занимались трансформацией достаточно долго в разных компаниях, видели разные случаи и уже понимают, как делать правильно, и в какую сторону вообще идти.
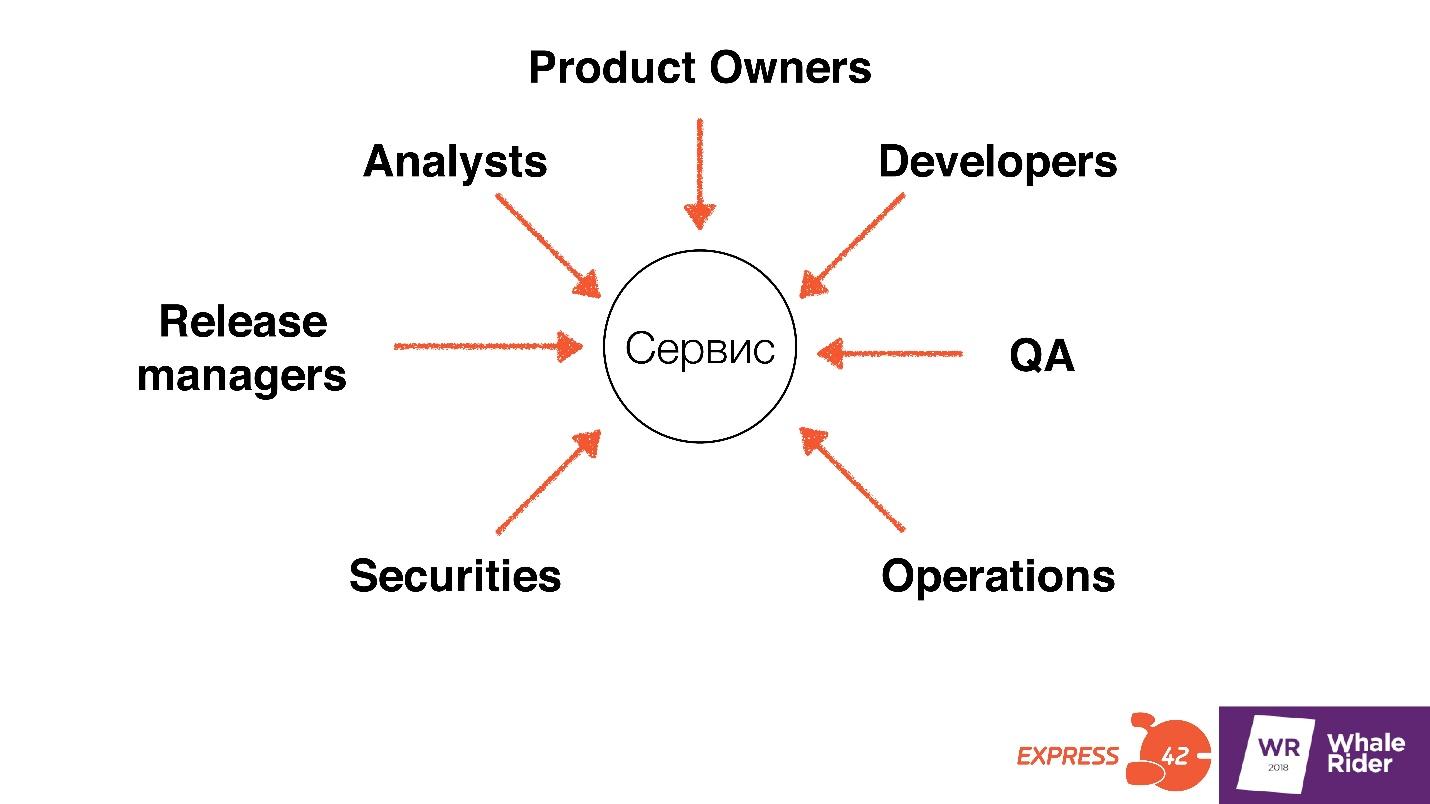
Нам нужно найти вообще всех, кто имеет хоть какое-то отношение к сервису: разработчиков, тестировщиков, админов, безопасников, менеджеров и, возможно, Product Owners. Несмотря на то, что Product Owners не технари, они имеют отношение к сервису: принимают решение, ставят задачу.
Для чего они нам? Чтобы знать, с кем договариваться. Во время трансформации, когда меняется привычный принцип работы с сервисом, его будет трясти все равно. Какое-то время будут сбои, пока мы тестируем новые подходы. Люди должны быть к этому готовы и с этим согласны.
Дальше придется строить Value Stream Map и без этих людей его не построишь, потому что только они все вместе знают полную картину происходящего. Один человек никогда не знает все, что происходит с сервисом.
Они посоветуют людей в команду Позже мы обсудим, почему нужна отдельная команда. В нее придется брать людей из существующих отделов. Те, кто имеет отношение к сервису, смогут порекомендовать коллег, думающих в нашу сторону, которые могут нам помочь и имеют компетенцию в том, что нам нужно.
Дальше мы собираем всех этих людей из разных отделов в одну комнату и начинаем строить Value Stream Map.
Value Stream Map — это схема или карта, которая показывает поток ценностей до клиента. Это весь процесс от придумывания идеи до ее реализации, включая все промежуточные этапы и то, как ценность в итоге попадает к нашим клиентам.
Value Stream Map нужен, чтобы визуализировать все этапы разработки, локализовать проблемы через измерения, которые есть в текущем процессе, и начать эти проблемы устранять, и поставить первоначальную цель. Это место, где мы начнем что-то реально делать.
В литературе по Value Stream Map описано много разных метрик, но для начала нам достаточно всего трех.
Lead Time — задержка/ожидание — время, когда мы чего-то ждем. Например, тестировщик ждет, пока освободится стенд для тестов, и в это время не может ничего делать.
Value Added Time — время полезной работы — то, которое мы затратили на таком-то этапе, чтобы создать конечную ценность для пользователя. Например, тестировщик запустил свой тест и начал что-то проверять. Это и есть время полезной работы, когда мы реально что-то делаем для продукта. Это то, за что клиенты платят — за качественный софт.
%C/A — процент принятой работы. У нас есть один этап — разработка, второй этап — тестирование. Сколько фич тестировщики приняли от разработчиков, и есть этот процент.
Примерно так выглядит наша карта.
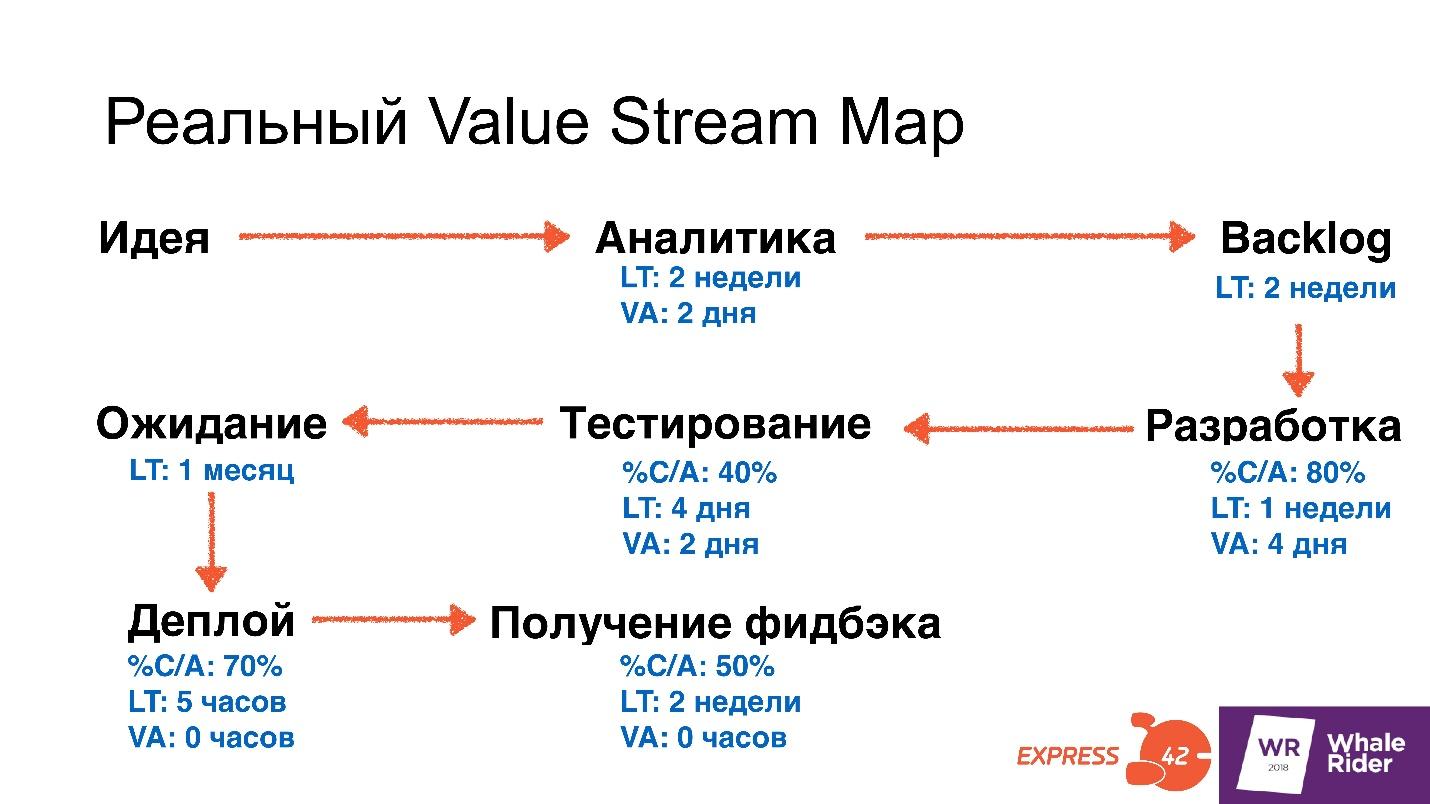
Она может выглядеть иначе в зависимости от структуры организации, количества отделов и того, чем вы занимаетесь. Но в общем случае на карте будет два этапа: идея и аналитика. На этом этапе ожидаются данные, например, Lead Time 2 недели и Value Added Time 2 дня.
Backlog — сколько задач лежали после того, как аналитики их придумали.
Разработка — сколько недель разработчики ждали уточнений по задачам, стендам или оборудованию — неважно, но они чего-то ждут. Например, 4 дня они реализуют фичу. Здесь появляется метрика %C/A. Разработчики взяли из Backlog только 80% задач. Они считают, что у остальных 20 % недостаточно четкое ТЗ, и отправили их на доработку.
Тестирование. На схеме LT задан 4 дня. Например, тестировщики ждали освобождения тестового стенда, VA 2 дня они реально что-то тестируют, и %C/A = 40 %. — только 40 % кода или фич, которые прислали разработчики, тестировщики посчитали адекватными. Все остальное им не понравилось по какой-то причине.
Не буду подробно останавливаться на том, как проводить эти измерения, в конце статьи порекомендую литературу, из которой можно про них узнать.
Единственное, что посоветую — не верьте людям, которые будут составлять с вами Value Stream Map. Они представляют, сколько времени занимают разные процессы, но эти оценки не всегда верны, поэтому лучше измерять самому.
У нас был случай, когда мы пришли в отдел Operations, и спросили, сколько времени уходит на доставку новой фичи на продакшн. Нам ответили, что 10 минут, и мы подумали, зачем мы вообще пришли в эту компанию? Выяснилось, что 10 минут — это время работы скрипта, который берет код и доставляет на сервер. Но перед этим релиз лежит три дня на сервере и просто пылится — в Backlog лежит задача, которую надо задеплоить. Получается, что перед стадией деплоя есть стадия ожидания, когда проект просто лежит. Если бы мы не пошли с блокнотом, не зацепились глазами за задачу в Jira и не начали ее отслеживать поэтапно, то считали бы, что все замечательно и никакой проблемы нет.
Поэтому измерения все-таки придется делать самому, желательно не один раз, чтобы иметь близкое к реальности представление. В зависимости от Value Stream Map, вы будете принимать решение о том, с какого места начать и что исправлять в первую очередь.
Многие компании, которые решили внедрить себе DevOps, создают команду, только не временную, а существующую несколько лет. Если вы обратитесь на сервис DevOps apologize, на котором описаны разные паттерны построения организационной структуры в DevOps, то поймете, что это антипаттерн.
Если команда существует между отделами, только чтобы делать что-то еще отдельное, и существует долго, то она создает лишний барьер. Теперь программисту вместо того, чтобы сразу идти к администратору решать вопрос, нужно сначала обратиться в отдел DevOps, а тот уже пойдет дальше.
Поэтому, чтобы начать, нужно создать временную команду. Она просуществует условно полгода, максимум год, в зависимости от поставленной задачи, только чтобы устранить одно ограничение, которое мы выбрали. Дальше она умрет. Если мы выберем следующую точку, где у нас сильно болит, и поймем, что для нее нам тоже нужна отдельная команда, тогда мы снова ее создадим. Но на «постоянке» такие команды не должны существовать — тогда они только нарушают коммуникацию и берут на себя вообще отдельные задачи, только чтобы что-то делать. Эти задачи могут быть вообще не связаны с DevOps и с трансформацией. Почему бы нам не отдать эту задачу существующим отделам?
Конфликт с текущими процессами. DevOps-трансформация — это изменение не только технологий и инструментов, которыми мы пользуемся, но изменение самого процесса работы, мышления и ценностей. Если команда будет работать так, как она уже привыкла, у нее не получится попробовать другие подходы.
Эти люди должны жить по другим правилам: игнорировать все KPI в компании, потому что они пробуют работать по-другому. Временные команды не будут заполнять заявки, чтобы получить сервер, а напрямую пойдут к отделу, который ими заведует, с требованием дать им самым первым то, что нужно, потому что это приоритетная задача и потому что они пытаются жить по-другому. У команды полный конфликт со всеми текущими процессами. Чтобы существующие методы работы не мешали им сейчас, а они не мешали другим, мы изолируем этих людей, выделяя в отдельную команду.
Избегание бюрократии в экспериментах. Во временных командах нет бюрократии, они не заполняют отчеты о рабочих часах, они не отчитываются перед менеджерами. Это абсолютно отдельный мир, в котором люди живут и думают по-другому, и занимаются совершенно другими вещами. Не надо им лишний раз мешать.
Безостановочная работа над сервисом. В первом пункте мы выбрали нечто, над чем будем экспериментировать. Эксперименты и поиск способов работать лучше — это хорошо, но фичи мы тоже хотим делать. Если вся команда вместо фич займется трансформацией, то мы начнем терять доходы, баги будут долго висеть — это нам не нужно. Создание временной команды позволяет экспериментировать, не останавливая при этом работу над продуктом.
Не тратить время на рабочие задачи. Это снова про продукт. На то, чтобы команда попробовала другие инструменты и прочее, требуется много времени. Чтобы люди освоили инструменты, начали их внедрять и нормально использовать, уйдет, как минимум, полгода. Если они будут заниматься еще и продуктом — полгода растянутся космически. Если люди занимаются продуктом, они опять работают со старыми процессами — нам это не нужно.
Поэтому из разных отделов мы выделяем людей в отдельную команду, которая займется трансформацией сервиса. В результате сервис работает, продолжает развиваться, и при этом мы ставим на нем какие-то эксперименты.
Команда состоит из универсальных людей. Это значит, что мы взяли не только разработчиков. Мы не пришли в сервис и не забрали оттуда полкоманды — нет, мы взяли людей из разных отделов. Несколько пунктов назад мы нашли разные отделы и разных сотрудников, которые имеют отношение к трансформируемому сервису. Из них мы набираем команду, потому что она должна быть универсальной — мы будем менять и процесс тестирования, и процесс разработки, и процесс обслуживания сервиса. Нужны разные компетенции.
Обычно условно берем разработчика, тестировщика и инженера — каждого по одному, и совместно с ними придумываем решение, которое позволяет жить по-другому.
Желательно, чтобы эти люди имели авторитет в организации. Возможно, придется взять одного консерватора, хоть и не хочется. Если у нас большая компания, далеко не все поверят в нашу затею, а кто-то может вставлять палки в колеса, например, не выделять стенд. Здесь и понадобится «авторитет» — уважаемый человек с большим опытом, который заслужил хорошее отношение коллег. Авторитет сотрудника в команде упростит задачу и работу временной команды. Люди будут думать:
— Ага, этот крутой чувак, которого мы все знаем и любим, туда вписался — видимо, в DevOps есть что-то, на что стоит посмотреть!
Собрали людей, выбрали сервис, посмотрели ограничения, определили, на каких людей мы повлияем. Теперь нужно поставить цель и она должна быть прямо по SMART — все, как мы любим.
Specific — конкретная.
Measurable — измеримая. Это очень важный пункт SMART. Если вы не можете что-то измерить, то не можете это изменить и понять, что и как вы сделали лучше или хуже.
Achievable — достижимая. Сделайте поправку на свою специфику. Если вы enterprise-компания с длинной историей и большим грузом обязанностей, которая выпускает версию продукта раз в год, то не сможете за полгода достичь выпуска новых версий продукта каждый час. Так не получится. Поэтому ставьте реальную цель, которая достижима за приемлемый срок.
Relevant — релевантная. Устраняем только то ограничение, которое действительно преследует наши текущие цели.
Time Limited — ограниченная по времени. Если дедлайна нет — команда будет заниматься чем угодно: пробовать 15 технологий вместо 3, писать огромные отчеты, проводить бесполезные исследования, вылизывать свою реализацию до блеска, когда цель уже достигнута.
Цель берем как раз с помощью Value Stream Map — снова собираем всех людей и рисуем. Но только теперь на основе предыдущей Value Stream Map мы рисуем то, что хотим получить.
Выделяем одно ограничение, которое будем устранять прямо сейчас, — этим и займется команда. Для примера я взял ожидание от готового релиза до его деплоя в продакшн — это самое частое ограничение, с которым люди обращаются к консультантам.
На основе этого ставим задачу: хотим, чтобы ожидание между готовым релизом и выходом в бой, было максимум час.
Примеры задач.
Примеры задач не взяты из головы — они основаны на измерениях, которые мы делали, когда разрабатывали Value Stream Map.
Ставим подобную задачу нашей команде и ограничение по срокам. В зависимости от того, насколько в вашей компании все хорошо, вы ставите разные сроки. В среднем на устранение ограничения, если люди занимаются этим в первый раз и еще не знают, с помощью каких технологий и как конкретно будут решать проблему, обычно уходит полгода.
Итак, наша команда создана, у нее есть цель, люди начинают работать. Важный момент — это короткое планирование работы: спринты одна-две неделии, не больше, измеримые улучшения каждую неделю и корректировка курса.
Например, мы часто используем подход moving-moving, когда вся команда собирается в начале каждой недели, набрасывает в файл, что каждый будет делать. Через неделю отмечаем: что сделано, а что нет, если нет, то почему, и думаем, что делать дальше.
Неделю или две что-то попробовали: технологии, подходы, способы работы, после этого измеряете снова и смотрите — с таким подходом стало лучше или хуже? Если хуже, значит идем не туда, надо корректировать курс: ставить другую задачу, брать другую технологию или что-то еще делать. Короткие спринты на 1-2 недели позволяют лавировать и вовремя уходить от плохих решений.
Команда достигает каких-то успехов, маленьких или больших — неважно, всегда есть какой-то результат. Об этом результате должны знать вообще все: и те, кто причастен к DevOps, и соседние отделы. В идеальном мире желательно, чтобы это дошло вообще до всех людей в компании.
Зачем? Если мы хотим трансформировать не часть компании, устранить не одно ограничение, а вообще все, чтобы компания стала гибкой, код быстро летел до клиента, и ничего не ломалось, нужно, чтобы все были лояльны к идее DevOps. Вы не сможете применить подход к сервисам и командам, которые категорически против.
Чтобы появилась лояльность, мы должны рассказывать всем, что мы попробовали вот это — у нас есть результат, пробуйте тоже! Это повысит интерес и лояльность к тому, чем мы занимаемся, люди начнут пробовать что-то делать прямо сейчас. Как показывает практика, когда мы рассказываем, что попробовали и чего добились, другие команды начинают спрашивать, как и что сделали. Они смотрят реализации, код, документацию, подходят с вопросами и пытаются изменить что-то у себя.
Выбираем сервис, как точку отсчета — то место, где начнем изменения в компании. Выявляем всех, кто имеет какое-либо отношение к сервису и вместе с ними строим Value Stream Map, измеряем и смотрим, где и какие есть ограничения.
Создаем новую временную команду, которая будет решать поставленную задачу. На основе измерений и Value Stream Map рисуем новую карту, где выделяем то ограничение, которое будем решать. На основе этого ограничения ставим задачу, которой будет заниматься команда. Задача должна быть обязательно SMART — конкретной, измеримой, релевантной для текущих задач и ограниченной по времени.
Повторяем процесс, пока не трансформируем абсолютно все наши сервисы до требуемого вида и не устраним все ограничения.
Для тех, кто решил заняться DevOps самостоятельно.
Оригинальное название — «The Phoenix Project: A Novel about It, Devops, and Helping Your Business Win». Это роман про DevOps — история о том, как сотрудника сделали начальником отдела, который все время был в огне. Новому начальнику поставили задачу:
— У тебя есть несколько лет на то, чтобы все исправить, чтобы мы наконец могли быстро и эффективно поставлять наш продукт нашим клиентам.
«Проект “Феникс”. Роман о том, как DevOps меняет жизнь к лучшему» — книга для всех руководителей, потому что как раз эти люди принимают решения о том, что происходит в компании. Если же вы инженер или программист и хотите, чтобы в вашей компании началась движуха и трансформация — купите книжку и подарите руководству. Этот роман объясняет все, а читается быстро и легко.
Книга посложнее. Вышла несколько лет назад на английском под названием «The DevOps Handbook How to create world?class agility, reliability, and security in Technology organizations», но сейчас уже есть на русском. Это настоящий handbook — практическое руководство: как проводить измерения, что такое Value Stream Map и зачем он нужен, куда стоит двигаться, в каком порядке. Книга как раз для тех, кто все хочет сделать самостоятельно. Самое важное, в ней есть примеры опыта других компаний.
Например, там рассказывается, как одна компания построила Value Stream Map и поняла, что у нее ограничение не в продукте, а в том, что кассир ходит от магазина до соседнего офиса, чтобы этим продуктом воспользоваться. Вместо того, чтобы решать проблему с программой, они просто купили своим продавцам планшеты, и теперь никто никуда не ходит, а все действия производят на рабочем месте. Вывод: Value Stream Map можно распространять не только на ПО, но и на все процессы в организации.
Полное название: «Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations». Это следующий уровень — хардкор. Книга вышла в прошлом году, пока только на английском и она про исследования. Авторы — Nicole Forsgren, Jez Humble и Gene Kim — в течение многих лет применяли разные практики в разных компаниях и исследовали, какие практики, как и на что влияют.
Во второй главе, посвященной измерениям, упоминаются Value Stream Map, те метрики, что я называл, и множество других, а также подробно описан процесс измерений. Авторы проводят измерения с помощью опросников и самостоятельного отслеживания задач. Подробно рассказывается, какие метрики правильно измерять, какие не стоит, человеческие ошибки в измерениях. Если у вас есть сложности с измерениями, обращайтесь ко второй главе книги «Accelerate». Если в вашей команде просто много практик, но непонятно, какие практики применить сейчас, какие потом, какие реально действуют, а какие нет — читайте, в книге все рассказано.
Как начать DevOps трансформацию? Если кратко: выбираем сервис, с которого начнем процесс, выявляем тех, кто имеет отношение к сервису, строим Value Stream Map, создаем временную команду, которая будет заниматься трансформацией первое время и ставим ей задачу. Повторяем цикл нужное число раз.
Подробный план DevOps трансформации с примерами и инструкциями под катом — в расшифровке доклада Андрея Александрова — инженера в компании Express42, которая консультирует по проращиванию DevOps, ускоряя этот процесс, потому что уже построила карту граблей. Если вам кажется, что трансформация вам не нужна, или у вас такая специфика, что DevOps-практики не подходят, — используйте доклад как инструкцию по поиску и устранению ограничений.
Если вас беспокоит вопрос DevOps трансформации, то у вас большая компания, и нужно помаленьку масштабировать этот процесс на всю структуру. До тех пор, пока есть нужда трансформировать команду или устранить какое-то ограничение, алгоритм ниже можно повторять.
Выбор сервиса
План наметили, начнем с первого шага — выбора сервиса. Первый критерий — время жизни: есть старые сервисы — legacy, и новые. Начинать можно и с тех, и с других.
Выбрать молодой сервис логично. Он свежий, нет еще устоявшегося процесса работы в команде, которая им занимается. Вокруг него нет горы технического долга, не нужно его все время чинить. Можем делать с ним все, что хотим.
В случае старого сервиса есть проблемы, связанные с тем, что менять всегда тяжело. Там уже есть набор каких-то серьёзных ограничений, но, возможно, им занимаются люди, которые уже готовы все перелопатить — они устали и хотят что-то сделать по-другому, потому что им больно.
Работа со старым сервисом создает мощный прецедент в вашей компании — можно что-то менять. Если вы изменили новый сервис, он катится на прод 100 раз в час, и все хорошо, то люди в вашей компании могут сказать:
— Это же новый сервис! Там же было все просто, попробуйте с нашей развалюхой что-нибудь сделать.
Legacy-сервис имеет смысл брать в трансформацию, когда вы делаете её с кем-то, например, если пригласили внешнего консультанта. Будем честны, трансформация будет шатать все, что только можно. Вы экспериментируете и не знаете, куда придете, какие технологии и зачем будете использовать, где и какие подводные камни в процессах возникнут. Поэтому новый менять проще.
Если вы всё делаете сами, а в компании нет серьезной компетенции — берем новый сервис. Если знаете внешнего консультанта и есть средства — выбирайте старый.
Есть сервисы, которые представляют собой просто интерфейс для пользователей, например, простенький сайт или мобильное приложение. Но есть серьезные вещи в духе биллинга. Если что-то пойдет не так с биллингом — разбираться будет сложно. Здесь у нас тоже есть выбор.
Мы работаем либо с критичным сервисом, но уже из-за него страдаем, он создает ограничения, либо работаем с интерфейсом. Это второй критерий выбора. Аналогично, есть возможность привлечь опытного консультанта — работаем с тяжелым вариантом.
Но даже в этом случае я бы не советовал так делать, потому что, пока нет понимания с чем работать и в какую сторону трансформировать, брать критичную штуку и ее перетряхивать — не очень хорошая идея. Поэтому в данном случае мы предпочитаем работать с интерфейсом, поломка которого некритична.
Дальше рассмотрим команду сервиса. С теми, кто этим сервисом занимается, нам придется постоянно работать и взаимодействовать в очень тесном контакте.
Люди в команде условно делятся на две категории: консерваторы — живут в старом мире, или просто ничего не знают про DevOps, и инноваторы, которые тащат все модные практики. Вторые не всегда разбираются в теме, но они хотя бы к ней готовы.
С одной стороны консерваторы — опытные люди: давно в компании, разбираются от и до, но не знают как раз про практики. С другой стороны — инноваторы, которые что-то слышали, но в компании, скорее всего, работают не очень давно. С кем из них лучше работать?
С консерваторами придется взаимодействовать в любом случае, так как это их сервис. Придется с ними общаться, выяснять специфику сервиса, что можно сделать так, а что иначе. Мы зависим от их консультаций. Наверняка придётся им что-то поручать, потому что они свой сервис знают лучше. Поэтому важно, с какой командой мы в итоге будем иметь контакт.
Логично выбрать в команду инноваторов, потому что консерваторы могут подложить поросенка.
На практике часто бывает, что у консервативных людей есть существенный опыт, но нет понимания, как жить дальше. Они просто боятся, что после трансформации и переделки сервиса, их уволят за ненадобностью. Иногда просто из-за непонимания того, что происходит, они саботируют работу.
У меня был случай, когда парень из команды ремонтировал все что угодно, потому что это якобы критичнее, чем то, что мы сейчас делаем. Мы ставим задачу: реализовать сегодня вот этот кусок — нет, на другом конце мира пожар, идем его чинить. С такими людьми работать сложно.
Люди из команды консерваторов часто забивают на задачи, либо откладывают их до последнего. А если, Джон Уиллис вас упаси, вы совершили ошибку и навесили им KPI за количество выполненных задач, а какая-то часть почему-то не включена в KPI, то они вообще ничего делать не будут. В общем-то, будут правы, потому что они тогда теряют премию.
С инноваторами проще — они лояльнее. Они уже что-то слышали, хотят куда-то идти, поэтому будут помогать. Нам нужны люди, которые готовы страдать первое время: если меняется сервис, то все шишки и грабли поймают инноваторы на правах первопроходцев. Инноваторы хотят все самое новое и модное, и пострадать.
Консерваторов позже можно обратить в свою веру. Когда вы покажете, что изменили кусочек и все хорошо работает, скорее всего, они тоже захотят попробовать и примут новую DevOps-религию.
Подытожим. Если мы делаем всю трансформацию в нашей компании сами, то выбираем: новый сервис, желательно простой интерфейс, чтобы не сильно страдать от его поломки, и команду инноваторов.
Если есть возможность позвать внешнего консультанта, вместо нового — берем старый сервис, из-за которого уже страдаем. Люди, которые занимались трансформацией достаточно долго в разных компаниях, видели разные случаи и уже понимают, как делать правильно, и в какую сторону вообще идти.
Кто причастен?
Нам нужно найти вообще всех, кто имеет хоть какое-то отношение к сервису: разработчиков, тестировщиков, админов, безопасников, менеджеров и, возможно, Product Owners. Несмотря на то, что Product Owners не технари, они имеют отношение к сервису: принимают решение, ставят задачу.
Всех, кто принимает хоть какие-то решения и влияет на то, что происходит с сервисом, нужно найти, познакомиться и пообщаться.
Для чего они нам? Чтобы знать, с кем договариваться. Во время трансформации, когда меняется привычный принцип работы с сервисом, его будет трясти все равно. Какое-то время будут сбои, пока мы тестируем новые подходы. Люди должны быть к этому готовы и с этим согласны.
Дальше придется строить Value Stream Map и без этих людей его не построишь, потому что только они все вместе знают полную картину происходящего. Один человек никогда не знает все, что происходит с сервисом.
Они посоветуют людей в команду Позже мы обсудим, почему нужна отдельная команда. В нее придется брать людей из существующих отделов. Те, кто имеет отношение к сервису, смогут порекомендовать коллег, думающих в нашу сторону, которые могут нам помочь и имеют компетенцию в том, что нам нужно.
Дальше мы собираем всех этих людей из разных отделов в одну комнату и начинаем строить Value Stream Map.
Строим Value Stream Map
Value Stream Map — это схема или карта, которая показывает поток ценностей до клиента. Это весь процесс от придумывания идеи до ее реализации, включая все промежуточные этапы и то, как ценность в итоге попадает к нашим клиентам.
Value Stream Map нужен, чтобы визуализировать все этапы разработки, локализовать проблемы через измерения, которые есть в текущем процессе, и начать эти проблемы устранять, и поставить первоначальную цель. Это место, где мы начнем что-то реально делать.
Метрики
В литературе по Value Stream Map описано много разных метрик, но для начала нам достаточно всего трех.
Lead Time — задержка/ожидание — время, когда мы чего-то ждем. Например, тестировщик ждет, пока освободится стенд для тестов, и в это время не может ничего делать.
Value Added Time — время полезной работы — то, которое мы затратили на таком-то этапе, чтобы создать конечную ценность для пользователя. Например, тестировщик запустил свой тест и начал что-то проверять. Это и есть время полезной работы, когда мы реально что-то делаем для продукта. Это то, за что клиенты платят — за качественный софт.
%C/A — процент принятой работы. У нас есть один этап — разработка, второй этап — тестирование. Сколько фич тестировщики приняли от разработчиков, и есть этот процент.
Примерно так выглядит наша карта.
Она может выглядеть иначе в зависимости от структуры организации, количества отделов и того, чем вы занимаетесь. Но в общем случае на карте будет два этапа: идея и аналитика. На этом этапе ожидаются данные, например, Lead Time 2 недели и Value Added Time 2 дня.
Метриками покрываем абсолютно все этапы.
Backlog — сколько задач лежали после того, как аналитики их придумали.
Разработка — сколько недель разработчики ждали уточнений по задачам, стендам или оборудованию — неважно, но они чего-то ждут. Например, 4 дня они реализуют фичу. Здесь появляется метрика %C/A. Разработчики взяли из Backlog только 80% задач. Они считают, что у остальных 20 % недостаточно четкое ТЗ, и отправили их на доработку.
Тестирование. На схеме LT задан 4 дня. Например, тестировщики ждали освобождения тестового стенда, VA 2 дня они реально что-то тестируют, и %C/A = 40 %. — только 40 % кода или фич, которые прислали разработчики, тестировщики посчитали адекватными. Все остальное им не понравилось по какой-то причине.
Не буду подробно останавливаться на том, как проводить эти измерения, в конце статьи порекомендую литературу, из которой можно про них узнать.
Единственное, что посоветую — не верьте людям, которые будут составлять с вами Value Stream Map. Они представляют, сколько времени занимают разные процессы, но эти оценки не всегда верны, поэтому лучше измерять самому.
У нас был случай, когда мы пришли в отдел Operations, и спросили, сколько времени уходит на доставку новой фичи на продакшн. Нам ответили, что 10 минут, и мы подумали, зачем мы вообще пришли в эту компанию? Выяснилось, что 10 минут — это время работы скрипта, который берет код и доставляет на сервер. Но перед этим релиз лежит три дня на сервере и просто пылится — в Backlog лежит задача, которую надо задеплоить. Получается, что перед стадией деплоя есть стадия ожидания, когда проект просто лежит. Если бы мы не пошли с блокнотом, не зацепились глазами за задачу в Jira и не начали ее отслеживать поэтапно, то считали бы, что все замечательно и никакой проблемы нет.
Поэтому измерения все-таки придется делать самому, желательно не один раз, чтобы иметь близкое к реальности представление. В зависимости от Value Stream Map, вы будете принимать решение о том, с какого места начать и что исправлять в первую очередь.
Временная команда
Многие компании, которые решили внедрить себе DevOps, создают команду, только не временную, а существующую несколько лет. Если вы обратитесь на сервис DevOps apologize, на котором описаны разные паттерны построения организационной структуры в DevOps, то поймете, что это антипаттерн.
Когда DevOps-команда существует постоянно в течении нескольких лет — это большая ошибка, потому что DevOps — это про коммуникацию между отделами, про скорость и эффективность.
Если команда существует между отделами, только чтобы делать что-то еще отдельное, и существует долго, то она создает лишний барьер. Теперь программисту вместо того, чтобы сразу идти к администратору решать вопрос, нужно сначала обратиться в отдел DevOps, а тот уже пойдет дальше.
Поэтому, чтобы начать, нужно создать временную команду. Она просуществует условно полгода, максимум год, в зависимости от поставленной задачи, только чтобы устранить одно ограничение, которое мы выбрали. Дальше она умрет. Если мы выберем следующую точку, где у нас сильно болит, и поймем, что для нее нам тоже нужна отдельная команда, тогда мы снова ее создадим. Но на «постоянке» такие команды не должны существовать — тогда они только нарушают коммуникацию и берут на себя вообще отдельные задачи, только чтобы что-то делать. Эти задачи могут быть вообще не связаны с DevOps и с трансформацией. Почему бы нам не отдать эту задачу существующим отделам?
Почему нужна временная команда
Конфликт с текущими процессами. DevOps-трансформация — это изменение не только технологий и инструментов, которыми мы пользуемся, но изменение самого процесса работы, мышления и ценностей. Если команда будет работать так, как она уже привыкла, у нее не получится попробовать другие подходы.
Эти люди должны жить по другим правилам: игнорировать все KPI в компании, потому что они пробуют работать по-другому. Временные команды не будут заполнять заявки, чтобы получить сервер, а напрямую пойдут к отделу, который ими заведует, с требованием дать им самым первым то, что нужно, потому что это приоритетная задача и потому что они пытаются жить по-другому. У команды полный конфликт со всеми текущими процессами. Чтобы существующие методы работы не мешали им сейчас, а они не мешали другим, мы изолируем этих людей, выделяя в отдельную команду.
Избегание бюрократии в экспериментах. Во временных командах нет бюрократии, они не заполняют отчеты о рабочих часах, они не отчитываются перед менеджерами. Это абсолютно отдельный мир, в котором люди живут и думают по-другому, и занимаются совершенно другими вещами. Не надо им лишний раз мешать.
Безостановочная работа над сервисом. В первом пункте мы выбрали нечто, над чем будем экспериментировать. Эксперименты и поиск способов работать лучше — это хорошо, но фичи мы тоже хотим делать. Если вся команда вместо фич займется трансформацией, то мы начнем терять доходы, баги будут долго висеть — это нам не нужно. Создание временной команды позволяет экспериментировать, не останавливая при этом работу над продуктом.
Не тратить время на рабочие задачи. Это снова про продукт. На то, чтобы команда попробовала другие инструменты и прочее, требуется много времени. Чтобы люди освоили инструменты, начали их внедрять и нормально использовать, уйдет, как минимум, полгода. Если они будут заниматься еще и продуктом — полгода растянутся космически. Если люди занимаются продуктом, они опять работают со старыми процессами — нам это не нужно.
Поэтому из разных отделов мы выделяем людей в отдельную команду, которая займется трансформацией сервиса. В результате сервис работает, продолжает развиваться, и при этом мы ставим на нем какие-то эксперименты.
Временная команда занимается только DevOps-трансформацией — устранением того ограничения, которое мы нашли, и ничем больше.
Команда состоит из универсальных людей. Это значит, что мы взяли не только разработчиков. Мы не пришли в сервис и не забрали оттуда полкоманды — нет, мы взяли людей из разных отделов. Несколько пунктов назад мы нашли разные отделы и разных сотрудников, которые имеют отношение к трансформируемому сервису. Из них мы набираем команду, потому что она должна быть универсальной — мы будем менять и процесс тестирования, и процесс разработки, и процесс обслуживания сервиса. Нужны разные компетенции.
Обычно условно берем разработчика, тестировщика и инженера — каждого по одному, и совместно с ними придумываем решение, которое позволяет жить по-другому.
Желательно, чтобы эти люди имели авторитет в организации. Возможно, придется взять одного консерватора, хоть и не хочется. Если у нас большая компания, далеко не все поверят в нашу затею, а кто-то может вставлять палки в колеса, например, не выделять стенд. Здесь и понадобится «авторитет» — уважаемый человек с большим опытом, который заслужил хорошее отношение коллег. Авторитет сотрудника в команде упростит задачу и работу временной команды. Люди будут думать:
— Ага, этот крутой чувак, которого мы все знаем и любим, туда вписался — видимо, в DevOps есть что-то, на что стоит посмотреть!
Ставим цель
Собрали людей, выбрали сервис, посмотрели ограничения, определили, на каких людей мы повлияем. Теперь нужно поставить цель и она должна быть прямо по SMART — все, как мы любим.
Specific — конкретная.
Measurable — измеримая. Это очень важный пункт SMART. Если вы не можете что-то измерить, то не можете это изменить и понять, что и как вы сделали лучше или хуже.
Achievable — достижимая. Сделайте поправку на свою специфику. Если вы enterprise-компания с длинной историей и большим грузом обязанностей, которая выпускает версию продукта раз в год, то не сможете за полгода достичь выпуска новых версий продукта каждый час. Так не получится. Поэтому ставьте реальную цель, которая достижима за приемлемый срок.
Relevant — релевантная. Устраняем только то ограничение, которое действительно преследует наши текущие цели.
Time Limited — ограниченная по времени. Если дедлайна нет — команда будет заниматься чем угодно: пробовать 15 технологий вместо 3, писать огромные отчеты, проводить бесполезные исследования, вылизывать свою реализацию до блеска, когда цель уже достигнута.
Цель берем как раз с помощью Value Stream Map — снова собираем всех людей и рисуем. Но только теперь на основе предыдущей Value Stream Map мы рисуем то, что хотим получить.
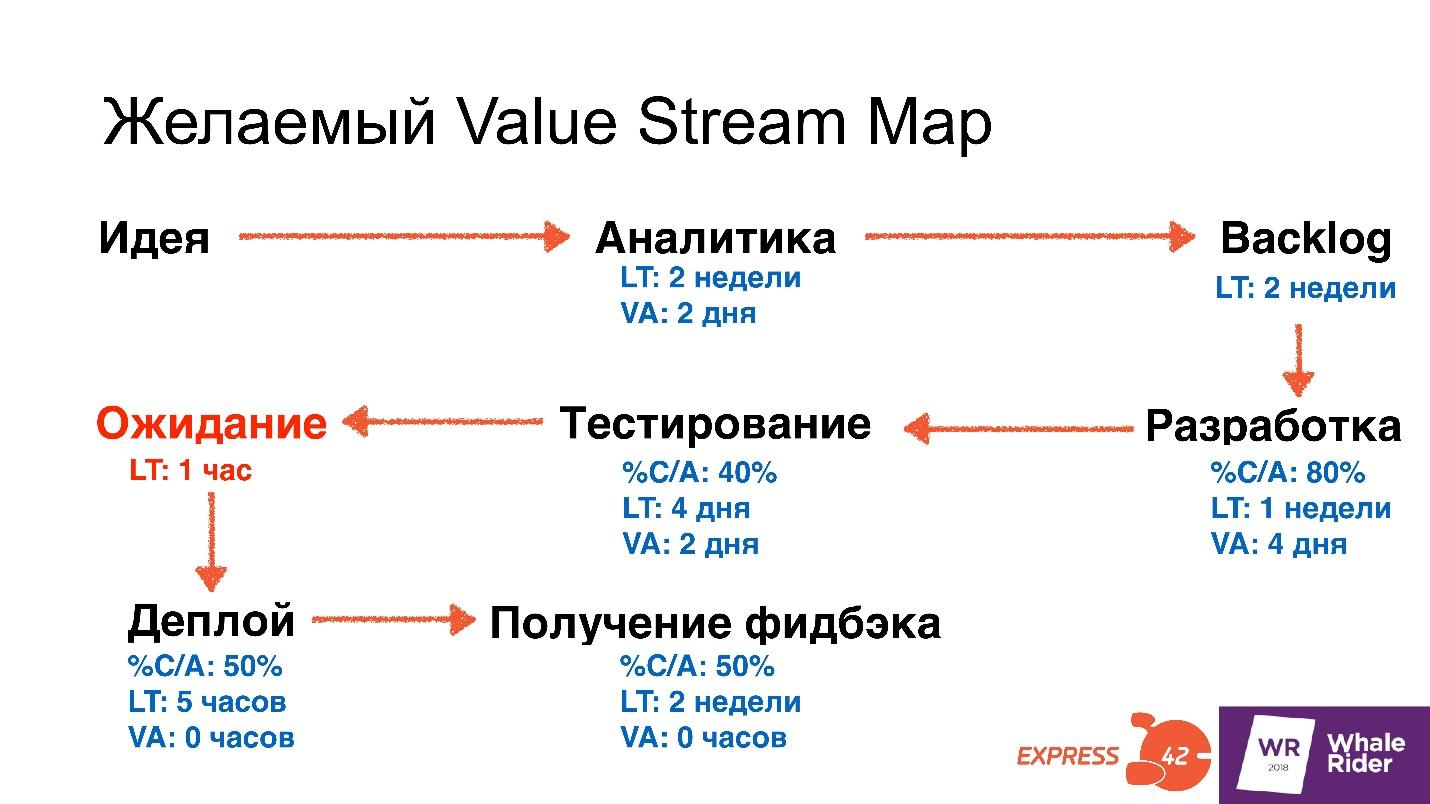
Выделяем одно ограничение, которое будем устранять прямо сейчас, — этим и займется команда. Для примера я взял ожидание от готового релиза до его деплоя в продакшн — это самое частое ограничение, с которым люди обращаются к консультантам.
На основе этого ставим задачу: хотим, чтобы ожидание между готовым релизом и выходом в бой, было максимум час.
Примеры задач.
- Сократить Lead Time тестирования с 4 дней до 1 часа.
- Сократить Value Added Time для тестирования с 2 дней до 3 часов.
- Сократить Lead Time деплоя с 5 часов до 10 минут.
- Увеличить C/A c 50% до 95%, то есть увеличить количество фич, которые принимают тестировщики, другими словами, улучшить качество работы разработчиков.
Примеры задач не взяты из головы — они основаны на измерениях, которые мы делали, когда разрабатывали Value Stream Map.
Ставим подобную задачу нашей команде и ограничение по срокам. В зависимости от того, насколько в вашей компании все хорошо, вы ставите разные сроки. В среднем на устранение ограничения, если люди занимаются этим в первый раз и еще не знают, с помощью каких технологий и как конкретно будут решать проблему, обычно уходит полгода.
Короткое планирование
Итак, наша команда создана, у нее есть цель, люди начинают работать. Важный момент — это короткое планирование работы: спринты одна-две неделии, не больше, измеримые улучшения каждую неделю и корректировка курса.
Например, мы часто используем подход moving-moving, когда вся команда собирается в начале каждой недели, набрасывает в файл, что каждый будет делать. Через неделю отмечаем: что сделано, а что нет, если нет, то почему, и думаем, что делать дальше.
Спринты позволяют вовремя корректировать курс.
Неделю или две что-то попробовали: технологии, подходы, способы работы, после этого измеряете снова и смотрите — с таким подходом стало лучше или хуже? Если хуже, значит идем не туда, надо корректировать курс: ставить другую задачу, брать другую технологию или что-то еще делать. Короткие спринты на 1-2 недели позволяют лавировать и вовремя уходить от плохих решений.
Делимся успехом
Команда достигает каких-то успехов, маленьких или больших — неважно, всегда есть какой-то результат. Об этом результате должны знать вообще все: и те, кто причастен к DevOps, и соседние отделы. В идеальном мире желательно, чтобы это дошло вообще до всех людей в компании.
Зачем? Если мы хотим трансформировать не часть компании, устранить не одно ограничение, а вообще все, чтобы компания стала гибкой, код быстро летел до клиента, и ничего не ломалось, нужно, чтобы все были лояльны к идее DevOps. Вы не сможете применить подход к сервисам и командам, которые категорически против.
Чтобы появилась лояльность, мы должны рассказывать всем, что мы попробовали вот это — у нас есть результат, пробуйте тоже! Это повысит интерес и лояльность к тому, чем мы занимаемся, люди начнут пробовать что-то делать прямо сейчас. Как показывает практика, когда мы рассказываем, что попробовали и чего добились, другие команды начинают спрашивать, как и что сделали. Они смотрят реализации, код, документацию, подходят с вопросами и пытаются изменить что-то у себя.
Рассказывать о том, что у вас получилось — важно. Так вы убедите перейти в ваш лагерь консерваторов, которые хотели все делать по-старому и трансформируете их в инноваторов.
Итого
Выбираем сервис, как точку отсчета — то место, где начнем изменения в компании. Выявляем всех, кто имеет какое-либо отношение к сервису и вместе с ними строим Value Stream Map, измеряем и смотрим, где и какие есть ограничения.
Создаем новую временную команду, которая будет решать поставленную задачу. На основе измерений и Value Stream Map рисуем новую карту, где выделяем то ограничение, которое будем решать. На основе этого ограничения ставим задачу, которой будет заниматься команда. Задача должна быть обязательно SMART — конкретной, измеримой, релевантной для текущих задач и ограниченной по времени.
Повторяем процесс, пока не трансформируем абсолютно все наши сервисы до требуемого вида и не устраним все ограничения.
Бонус. Полезные материалы
Для тех, кто решил заняться DevOps самостоятельно.
Проект «Феникс»
Оригинальное название — «The Phoenix Project: A Novel about It, Devops, and Helping Your Business Win». Это роман про DevOps — история о том, как сотрудника сделали начальником отдела, который все время был в огне. Новому начальнику поставили задачу:
— У тебя есть несколько лет на то, чтобы все исправить, чтобы мы наконец могли быстро и эффективно поставлять наш продукт нашим клиентам.
«Проект “Феникс”. Роман о том, как DevOps меняет жизнь к лучшему» — книга для всех руководителей, потому что как раз эти люди принимают решения о том, что происходит в компании. Если же вы инженер или программист и хотите, чтобы в вашей компании началась движуха и трансформация — купите книжку и подарите руководству. Этот роман объясняет все, а читается быстро и легко.
Руководство по DevOps
Книга посложнее. Вышла несколько лет назад на английском под названием «The DevOps Handbook How to create world?class agility, reliability, and security in Technology organizations», но сейчас уже есть на русском. Это настоящий handbook — практическое руководство: как проводить измерения, что такое Value Stream Map и зачем он нужен, куда стоит двигаться, в каком порядке. Книга как раз для тех, кто все хочет сделать самостоятельно. Самое важное, в ней есть примеры опыта других компаний.
Например, там рассказывается, как одна компания построила Value Stream Map и поняла, что у нее ограничение не в продукте, а в том, что кассир ходит от магазина до соседнего офиса, чтобы этим продуктом воспользоваться. Вместо того, чтобы решать проблему с программой, они просто купили своим продавцам планшеты, и теперь никто никуда не ходит, а все действия производят на рабочем месте. Вывод: Value Stream Map можно распространять не только на ПО, но и на все процессы в организации.
Accelerate
Полное название: «Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations». Это следующий уровень — хардкор. Книга вышла в прошлом году, пока только на английском и она про исследования. Авторы — Nicole Forsgren, Jez Humble и Gene Kim — в течение многих лет применяли разные практики в разных компаниях и исследовали, какие практики, как и на что влияют.
Во второй главе, посвященной измерениям, упоминаются Value Stream Map, те метрики, что я называл, и множество других, а также подробно описан процесс измерений. Авторы проводят измерения с помощью опросников и самостоятельного отслеживания задач. Подробно рассказывается, какие метрики правильно измерять, какие не стоит, человеческие ошибки в измерениях. Если у вас есть сложности с измерениями, обращайтесь ко второй главе книги «Accelerate». Если в вашей команде просто много практик, но непонятно, какие практики применить сейчас, какие потом, какие реально действуют, а какие нет — читайте, в книге все рассказано.
Трансформация — вопрос на стыке DevOps и управления. Где-то в той же области пересечения разработки, эксплуатации и тестирования находятся темы, которые мы стараемся обсуждать на DevOpsConf, та же интеграция нужна и для создания качественного продукта – главной темы QaulityConf. Управление на фестивале РИТ++ представлено Whale Rider — значит за идеями для трансформации все туда. Присоединяйтесь 27 и 28 мая, будем интегрироваться и трансформироваться.
xopen
Так и не понял, зачем нужны отдельные люди для этого. Чем там занимаются менеджеры, архитекторы, сами программисты? Они без помощи никак не могут понять, что их задерживает?