
Как-то у меня не получается выражать свою мысль коротко. Прошлой осенью возникло желание рассказать поподробнее про освоенную мною архитектуру PSoC, что вылилось в цикл статей про неё. Сейчас я участвую в подготовке аппаратной части для нашего комплекса удалённой отладки Redd, о котором рассказывалось здесь, и хочется выплеснуть накопившийся опыт в текстовом виде. Пока не уверен, но мне кажется, что снова получится не одна статья, а цикл. Во-первых, так я задокументирую выработавшиеся приёмы разработки, которые могут быть кому-то полезны как при работе с комплексом, так и в целом, а во-вторых, концепция ещё новая, не совсем устоявшаяся. Возможно, в процессе обсуждения статей появятся какие-то комментарии, из которых можно будет что-то почерпнуть, чтобы расширить (или даже изменить) её. Поэтому приступаем.

Я не очень люблю теоретизировать, предпочитая выкладывать сразу какие-то практические вещи. Но в начале первой статьи, без длинного введения никуда. В нём я обосную текущий подход к разработке. И всё будет вертеться вокруг одного: человеко-час — очень дорогой ресурс. И дело не только в сроках, отведённых на проект. Он физически дорог. Если он тратится на разработку конечного продукта, ну что ж поделать, без этого никуда. Но когда он тратится на вспомогательные работы, это, на мой взгляд, плохо. Помню, был у меня спор с одним разработчиком, который говорил, что изготовив прототипы самостоятельно, он сэкономит родной компании деньги. Я же привёл довод, что он на изготовление потратит примерно 3 дня. То есть 24 человеко-часа. Берём его зарплату за эти часы, добавляем социальный налог, который «платит работодатель», а также аренду офиса за эти часы. И с удивлением видим, что заказав платы на стороне, можно получить меньшие затраты. Но это я так, утрирую. В целом, если можно избежать трудозатрат, их надо избегать.
Что такое разработка «прошивок» для комплекса Redd? Это вспомогательная работа. Основной проект будет жить долго и счастливо, он должен быть сделан максимально эффективно, с отличной оптимизацией и т.п. А вот тратить силы и время на вспомогательные вещи, которые уйдут в архив после окончания разработки, расточительно. Именно с оглядкой на этот принцип велась разработка аппаратуры Redd. Все функции, по возможности, реализованы в виде стандартных вещей. Шины SPI, I2C и UART реализованы на штатных микросхемах от FTDI и программируются через штатные драйверы, без каких-либо изысков. Управление релюшками реализовано в формате виртуального COM-порта. Его можно доработать, но по крайней мере, всё сделано для того, чтобы такого желания не возникало. В общем, всё стандартное, по возможности, реализовано стандартным образом. Из проекта в проект разработчики просто должны быстренько писать типовой код для PC, чтобы обращаться к этим шинам. Техника разработки на С++ должна быть очевидна для тех, кто разрабатывает программы для микроконтроллеров (про некоторые технические детали поговорим в другой статье).
Но особняком в комплексе стоит ПЛИС. Она добавлена в систему для случаев, если понадобится реализовывать какие-либо нестандартные протоколы с высоким требованием к быстродействию. Если таковые требуются — для неё «прошивку» делать придётся. Вот про программирование ПЛИС и хочется поговорить особо, как раз всё с той же целью — сократить время разработки вспомогательных вещей.
Чтобы не запутать читателя, сформулирую мысль в рамке:
Давайте рассмотрим структурную схему комплекса

В нижней части схемы расположился «вычислитель». Собственно, это стандартный PC с ОС Linux. Разработчики могут писать обычные программы на языках Си, C++, Python и т.п., которые будут исполняться силами вычислителя. В правой верхней части расположены штатные порты типовых шин. Слева располагается коммутатор стандартных устройств (SPI Flash, SD карта и несколько слаботочных твердотельных реле, которые могут, например, имитировать нажатие кнопок). А по центру размещается именно та часть, работу с которой и планируется рассмотреть в данном цикле статей. Её сердцем является ПЛИС класса FPGA, из которой на разъём выходят прямые линии (могут использоваться как дифференциальные пары либо обычные небуферизированные линии), линии GPIO с задаваемым логическим уровнем, а также шина USB 2.0, реализуемая через микросхему ULPI.
При разработке высокопроизводительной управляющей логики для ПЛИС обычно первую скрипку играет его величество конечный автомат. Именно на автоматах удаётся реализовать быстродействующую, но сложную логику. Но с другой стороны, автомат разрабатывается медленнее, чем программа для процессора, а его модификация — тот ещё процесс. Существуют системы, упрощающие разработку и сопровождение автоматов. Одна из них даже разработана нашей компанией, но всё равно процесс проектирования для сколь-либо сложной логики получается не быстрым. Когда разрабатываемая система является конечным продуктом, имеет смысл подготовиться, спроектировать хороший управляющий автомат и потратить время на его реализацию. Но как уже отмечалось, разработка под Redd — это вспомогательная работа. Она призвана облегчать процесс, а не усложнять его. Поэтому было принято решение, что основным будет разработка не автоматных, а процессорных систем.
Но с другой стороны, при разработке аппаратуры самый модный на сегодняшний день вариант, ПЛИС с ядром ARM, был отвергнут. Во-первых, по ценовым соображениям. Макетная плата на базе Cyclone V SoC стоит средне дорого, но, как ни странно, отдельная ПЛИС намного дороже. Скорее всего, цена на макетные платы демпинговая, чтобы заманить разработчиков на использование данных ПЛИС, а платы продаются штучно. На серию придётся брать отдельные микросхемы. Но кроме того, есть ещё и «во-вторых». Во-вторых, когда я проводил опыты с Cyclone V SoC, оказалось, что не так эта процессорная система и производительна, если речь идёт об единичных обращениях к портам. Пакетные — да, там работа идёт быстро. А в случае единичных обращений при тактовой частоте процессорного ядра 925 МГц, можно получить обращения к портам на частоте единицы мегагерц. Всем желающим я предлагаю повызывать штатную функцию постановки данных в FIFO блока UART, которая проверяет переполненность очереди, но вызывать её, когда очередь заведомо пуста, то есть, операциям ничего не мешает. Производительность у меня вышла от миллиона до пятисот тысяч вызовов в секунду (разумеется, работа с памятью при этом шла на нормальной скорости, все кэши были настроены, даже вариант функции, не проверяющий FIFO на переполненность, работал быстрее, просто в обсуждаемой функции имеются обильно перемешанные записи и чтения из портов). Это FIFO! Вообще-то, FIFO придумано для того, чтобы туда бросить данные и забыть! Быстро бросить! А не с производительностью, менее одной мегаоперации в секунду при тактовой частоте процессора 925 МГц…
Виной всему латентность. Между процессорным ядром и аппаратурой располагается от трёх мостов и более. Причём скорость доступа к портам зависит от контекста (несколько записей подряд будут идти быстро, но первое же чтение остановит процесс до полной выгрузки закэшированных данных, слишком много записей подряд — также замедлятся, так как исчерпаются буферы записи). Наконец, осмотр трасс, накопленных в отладочном буфере, показал, что у архитектуры Cortex A один и тот же участок может исполняться за различное число тактов из-за сложной системы кэшей. В сумме, глядя на все эти факторы (цена, просадки быстродействия при работе с аппаратурой, нестабильность скорости доступа к аппаратуре, общая зависимость от контекста), было решено не ставить такую микросхему в комплекс.
Эксперименты с PSoC фирмы Cypress показали, что там ядро Cortex M даёт более предсказуемые и повторяемые результаты, но логическая ёмкость и предельная рабочая частота этих контроллеров не соответствовали ТЗ, поэтому их тоже отбросили.
Было решено установить недорогую типовую ПЛИС Cyclone IV и рекомендовать использование синтезируемого процессорного ядра NIOS II. Ну, а при необходимости — вести разработки с использованием любых других методов (автоматы, жёсткая логика и т.п.).
Если комплекс Redd работает под управлением ОС Linux, то это не значит, что и разработка должна вестись в этой ОС. Redd — это удалённый исполнитель, а разработку следует вести на своей ЭВМ, какая бы там ОС ни стояла. У кого стоит Linux — тем проще, но кто привык к Windows (когда-то я очень не любил WIN 3.1, но на работе заставили, а где-то ко временам WIN95 OSR2 произошло привыкание, и теперь с этим бороться бесполезно, проще принять), те могут продолжать вести разработку в ней.
Так как у меня с Линуксом дружба не задалась, пошаговых инструкций настройки среды под ним я не дам, а ограничусь общими словами. Кто с этой ОС работает — тому этого будет достаточно, а остальным… Поверьте, проще обратиться к системным администраторам. Я, в итоге, так и сделал. Но тем не менее.
Следует скачать и установить Quartus Prime Programmer and Tools той же версии, что и ваша среда разработки. При несовпадении версий, могут быть сюрпризы. Я потратил целый вечер, чтобы постичь этот факт. Поэтому просто скачивайте средство той же версии, что и среда разработки.
После установки, войдите в каталог, куда установилась программа, подкаталог bin. Вообще, самым главным файлом должен быть jtagconfig. Если запустить его без аргументов (кстати, у меня упорно требовали вводить ./jtagconfig и только так), то будет выдан список программаторов, доступных в системе и подключённых к ним ПЛИС. Там должен быть USB Blaster. И первая проблема, которую подкидывает система, не хватает прав доступа для работы с USB. Как решить её, не прибегая к помощи sudo, описано здесь: radiotech.kz/threads/nastrojka-altera-usb-blaster-v-ubuntu-16-04.1244
Но вот список устройств отображается. Теперь следует написать:
после чего запустится сервер, доступный по сети отовсюду.
Всё бы ничего, но системный фаервол не даст никому этот сервер увидеть. А проверка на Гугле показала, что у каждого вида Линуксов (коих много) порты в фаерволе открываются по-своему, причём надо произнести такое количество заклинаний, что я предпочёл обратиться к админам.
Также стоит учитывать, что если jtagd не был прописан в автозапуск, то при открытии удалённого доступа, вам скажут, что невозможно установить пароль. Чтобы этого не произошло, jtagd обязательно должен быть запущен не средствами самого jtagconfig, а до него.
В общем, шаманство на шаманстве. Давайте я просто зафиксирую тезисы:
Есть, конечно, и аналогичный путь, который проходится через GUI интерфейс, но логичнее делать всё пакетно. Поэтому я описал пакетный вариант. Когда все эти тезисы выполнены (а мне их выполнили сисадмины), на своей машине запускаем программатор, видим сообщение об отсутствии оборудования. Нажимаем Hardware Setup:
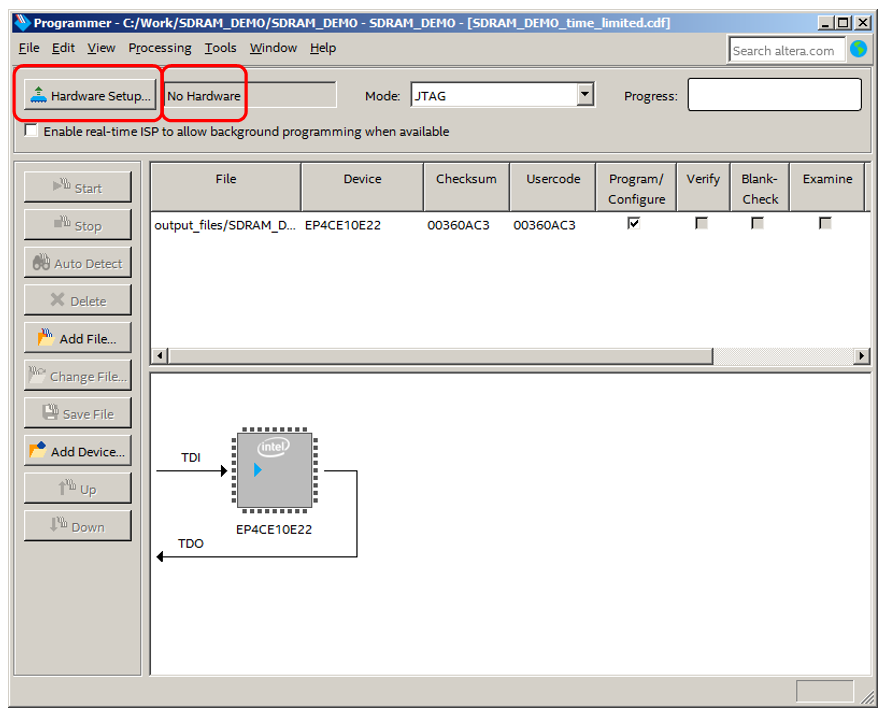
Переходим на вкладку JTAG Settings и нажимаем Add Server:
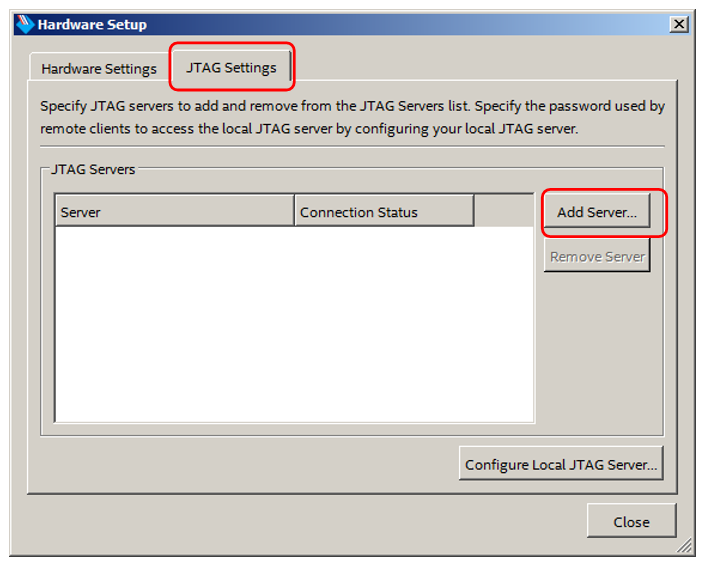
Вводим сетевой адрес Redd (у меня это 192.168.1.100) и пароль:

Убеждаемся, что соединение прошло успешно.
Я потратил три майских праздника на достижение этого, а затем всё решили админы.

Переключаемся на вкладку Hardware Settings, раскрываем выпадающий список и выбираем там удалённый программатор:
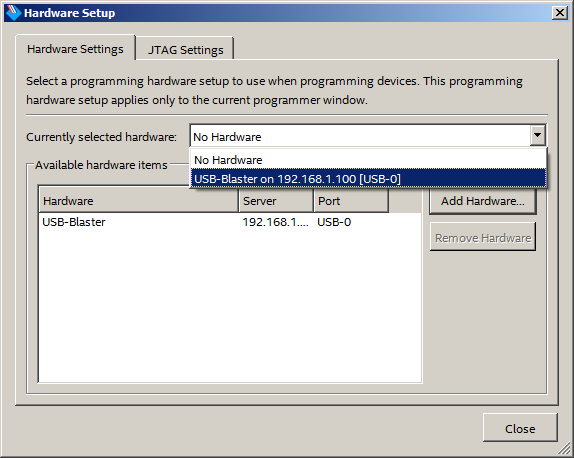
Всё, теперь им можно пользоваться. Кнопка Start разблокирована.
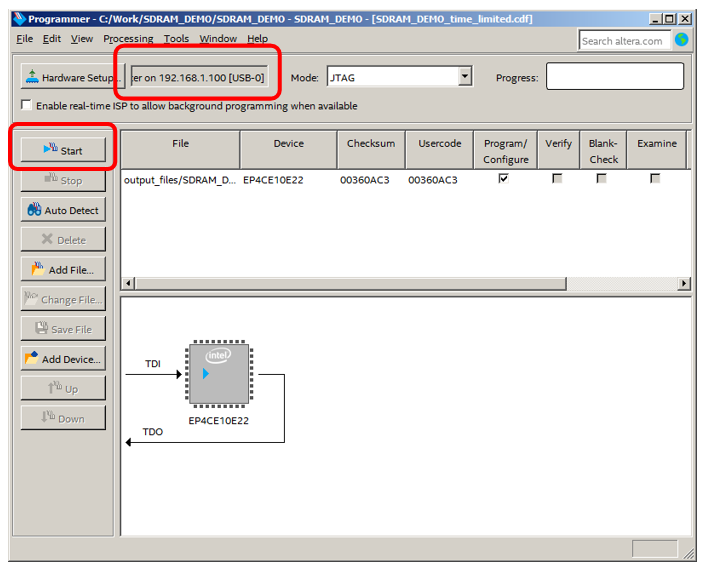
Ну что ж. Чтобы статья имела реальную практическую ценность, давайте разберём простейшую «прошивку», сделанную с применением вышеописанных методов. Самое простое, что мне довелось реально реализовать для комплекса, это тест микросхемы SDRAM. Вот на этом примере и потренируемся.
Имеется ряд любительских ядер для поддержки SDRAM, но они все включаются как-то хитро. А учёт всех хитростей — это трудозатраты. Мы же попробуем воспользоваться готовыми решениями, которые можно вставить в вычислительную систему NIOS II, поэтому воспользуемся стандартным ядром SDRAM Controller Core. Само ядро описано в документе Embedded Peripherals IP User Guide, причём достаточно много места в описании посвящено сдвигу тактовых импульсов для SDRAM относительно тактовых импульсов ядра. Приводятся сложные теоретические выкладки и формулы, но что делать особо не сообщается. О том, что делать, можно узнать из документа Using the SDRAM on Altera’s DE0 Board with Verilog Designs. По ходу разбора я применю знания из этого документа.
Я буду вести разработку в бесплатной версии Quartus Prime 17.0. Акцентирую на этом внимание, так как при сборке, мне сообщают, что в будущем, ядро SDRAM Controller будет выкинуто из бесплатной версии. Если в вашей среде разработки это уже произошло, никто не мешает скачать бесплатную 17-ю версию и установить её на виртуальную машину. Основную работу вести там, где вы привыкли, а прошивки для Redd с SDRAM — в 17-й версии. Ну, это если вы пользуетесь бесплатными вариантами. Из платных никто выкидывать это пока не грозился. Но я отвлёкся. Создаём новый проект:

Назовём его SDRAM_DEMO. Имя следует запомнить: я собираюсь вести сверхбыструю разработку, поэтому на верхнем уровне должна будет оказаться сама процессорная система, без каких-либо Verilog-прослоек. А чтобы это произошло, имя процессорной системы должно будет совпадать с именем проекта. Так что запомним его.

Согласившись со значениями по умолчанию на нескольких шагах, доходим до выбора кристалла. Выбираем применённый в комплексе EP4CE10E22C7.

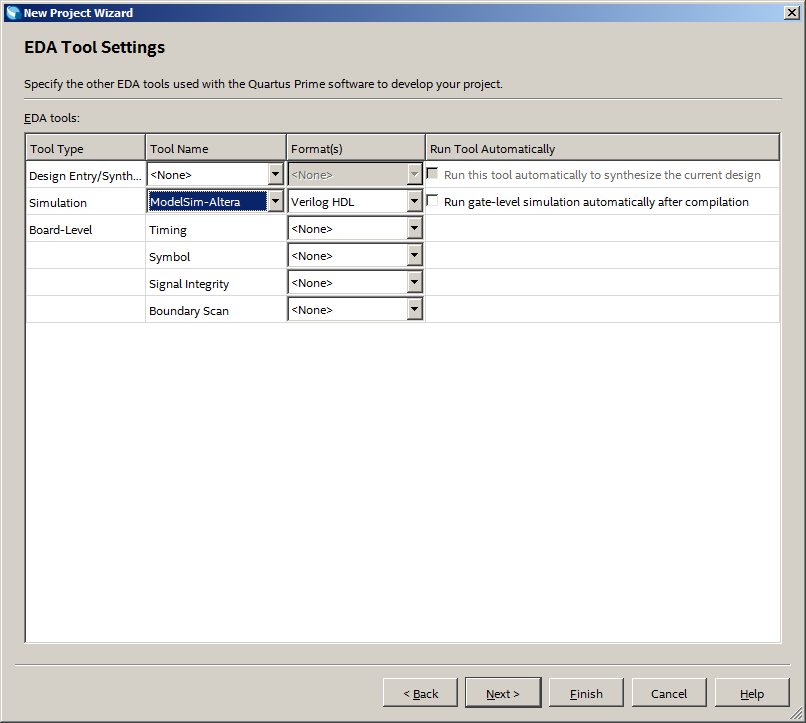
На следующем шаге я чисто по привычке выбираю моделирование в ModelSim-Altera. Сегодня мы не будем ничего моделировать, но всё может пригодиться. Лучше выработать такую привычку и следовать ей:
Проект создан. Сразу же идём в создание процессорной системы (Tools->Platform Designer):
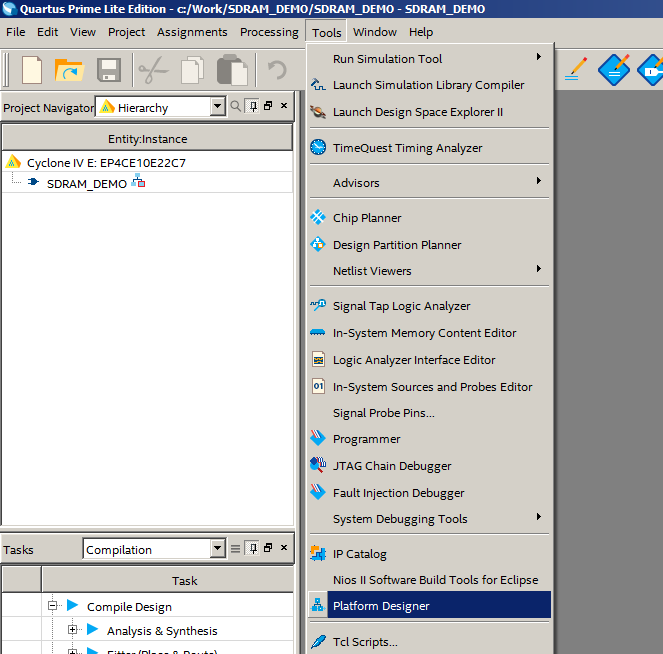
Нам создали систему, содержащую модуль тактирования и сброса:

Но как я уже упоминал, для ядра SDRAM требуется особое тактирование. Поэтому штатный модуль безжалостно выкидываем
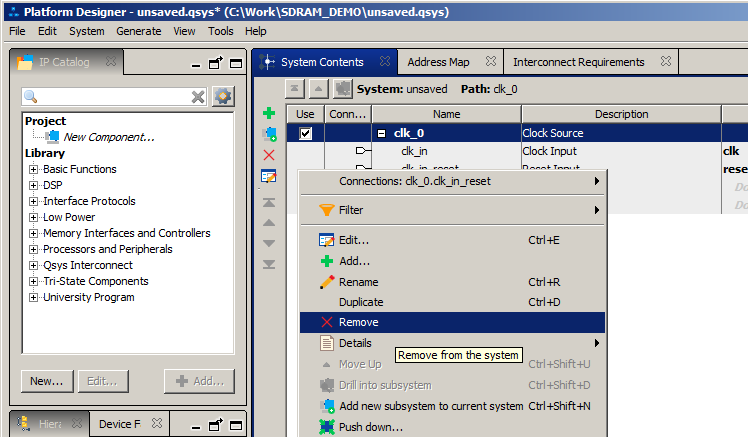
И вместо него добавляем блок University Program->System and SDRAM Clock for DE-series boards:
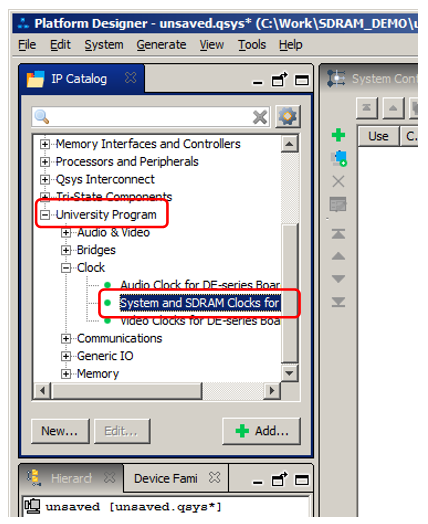
В свойствах выбираем DE0-Nano, так как вдохновение для схемы включения SDRAM черпалось из этой макетной платы:

Начинаем набивать нашу процессорную систему. Разумеется, первым делом в неё следует добавить само процессорное ядро. Пусть это будет Processor And Peripherals->Embedded Processors->NIOS II Processor.
Для него пока не заполняем никаких свойств. Просто нажимаем Finish, хоть у нас и образовался ряд сообщений об ошибках. Пока что отсутствует оборудование, которое позволит эти ошибки устранить.
Теперь добавляем собственно SDRAM. Memory Interfaces and Controllers->SDRAM->SDRAM Controller.
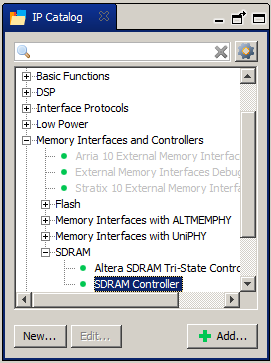
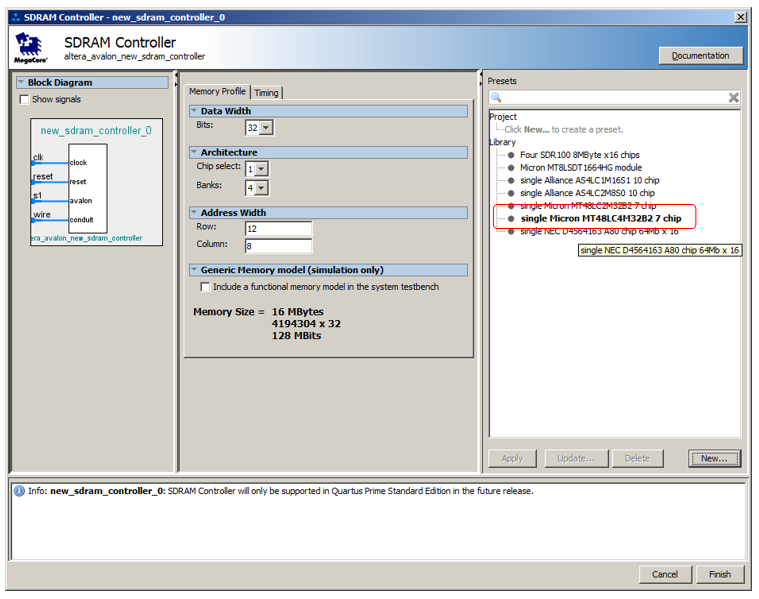
Здесь нам придётся подзадержаться на заполнении свойств. Выбираем ближайшую похожую по организации микросхему из списка и нажимаем Apppy. Её свойства попадают в поля Memory Profile:
Теперь меняем разрядность шины данных на 16, число адресных строк — на 13, а столбцов — на 9.
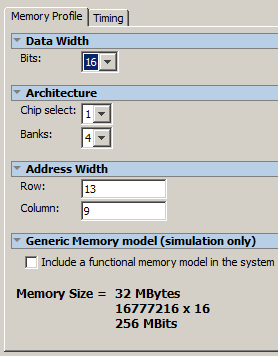
Времянки я пока не правлю, возможно, в будущем данная рекомендация будет изменена.
Процессорная система подразумевает программу. Программа должна где-то храниться. Мы будем проводить проверку микросхемы SDRAM. На данный момент мы не можем ей доверять. Поэтому для хранения программы, добавим память на основе блочного ОЗУ ПЛИС. Basic Functions->On Chip Memory->On-Chip Memory (RAM or ROM):

Объём… Ну пусть 32 килобайта.

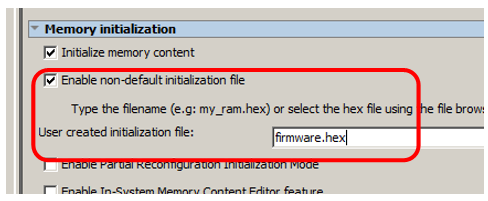
Эта память должна откуда-то загружаться. Чтобы это происходило, установим флажок Enable non-default initialization file и введём какое-нибудь осмысленное имя файла. Скажем, firmware.hex:
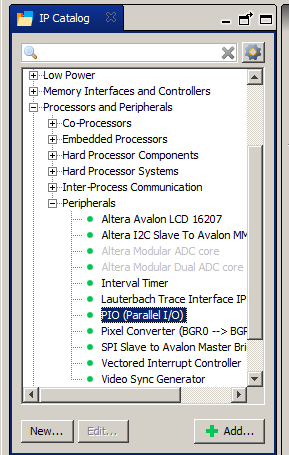
Статья выходит уже и так сложной, поэтому не будем её перегружать. Просто будем выводить физический результат теста в виде линий PASS/FAIL (а логический результат мы увидим при моей любимой JTAG отладке). Для этого добавим порт GPIO. Processors and Peripherals->Peripherals->PIO (Parallel IO):
В свойствах выставляем 2 бита, ещё я люблю устанавливать флажок для индивидуального управления битами. Тоже — просто привычка.

У нас получилась вот такая система с кучей ошибок:

Начинаем их устранять. Для начала разведём тактирование и сброс. У блока тактирования и сброса надо выбросить входы наружу. Для этого имеются поля, на которых написано «Дважды щёлкните для экспорта»:

Щёлкаем, но даём более-менее короткие имена.

Ещё надо выбросить наружу тактовый выход SDRAM:

Теперь sys_clk разводим на все тактовые входы, а reset_source — на все линии сброса. Можно аккуратно попадать «мышкой» в точки, соединяющие соответствующие линии, а можно навестись на соответствующий выход, нажать правую кнопку «мыши», а затем — в выпадающем меню перейти в подменю Connections и выбрать связи там.
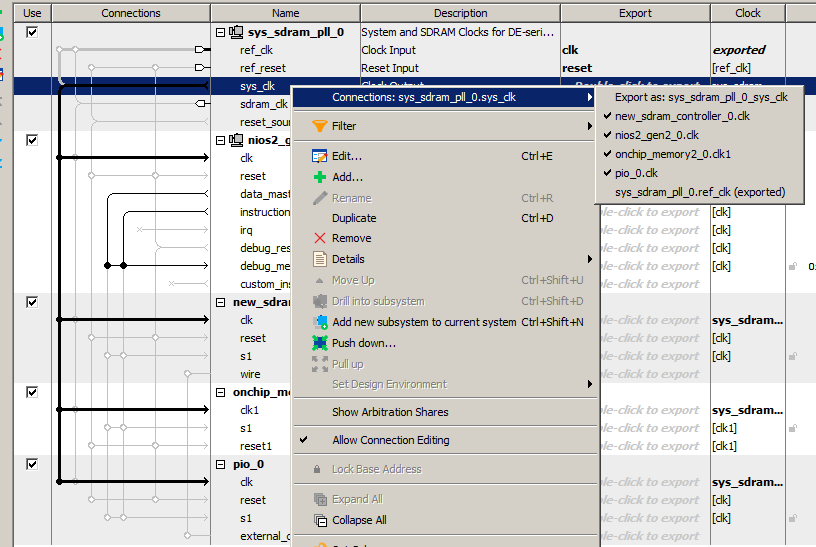

Дальше связываем шины воедино. Data Master подключаем ко всем шинам всех устройств, а Inctruction Master — почти ко всем. К шине PIO_0 его подключать не требуется. Оттуда инструкции считываться точно не будут.

Теперь можно разрешить конфликты адресов. Для этого выбираем пункт меню System->Assign Base Addresses:

А когда у нас появились адреса, можно назначить и вектора. Для этого идём в свойства процессорного ядра (наводимся на него, нажимаем правую кнопку «Мыши» и выбираем пункт меню Edit) и настраиваем там вектора на Onchip Memory. Просто выбираем этот тип памяти в выпадающих списках, цифры подставятся сами.

Ошибок не осталось. Но осталось два предупреждения. Я забыл заэкспортировать линии SDRAM и PIO.

Как уже мы это делали для блока сброса и тактирования, дважды щёлкаем по требуемым ножкам и даём им как можно более короткие (но понятные) имена:

Всё, больше нет ни ошибок, ни предупреждений. Сохраняем систему. Причём имя должно совпадать с именем проекта, чтобы процессорная система стала элементом верхнего уровня в проекте. Ещё не забыли, как он у нас назывался?


Ну, и нажимаем самую главную кнопку — generate HDL.

Всё, процессорная часть создана. Нажимаем Finish. Нам напоминают, что неплохо бы добавить эту процессорную систему к проекту:

Добавляем:

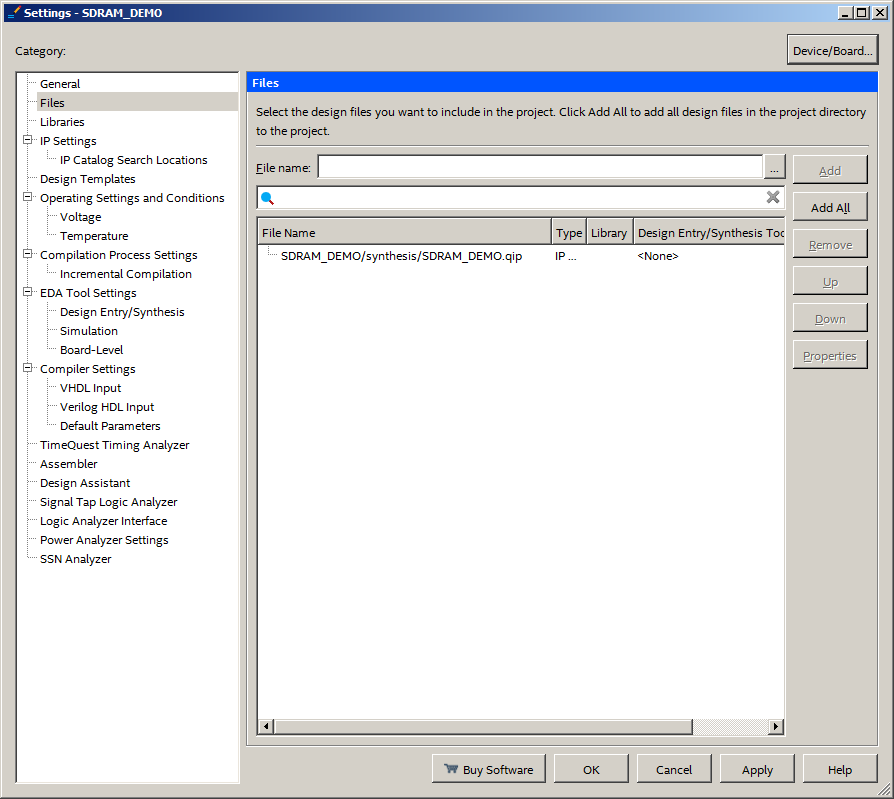
И там, при помощи кнопки Add, добиваемся такой картинки:
SIP файл ещё не создался. Да и не нужен он нам в рамках этой статьи.
Уффф. Первый шаг сделан. Производим черновую сборку проекта, чтобы система выяснила иерархию проекта и используемые ножки. Ошибки компиляции не страшные. Просто в бесплатной версии среды были созданы ядра, которые работают только пока подключён JTAG адаптер. Но в комплексе Redd он всегда и подключён, так как разведён на общей плате, то есть нам нечего бояться. Так что эти ошибки мы игнорируем.

Теперь вернёмся к описанию ядра SDRAM. Там сказано, что линия CKE не используется и всегда подключена к единице. На самом деле, в рамках комплекса ножки ПЛИС не просто дорогой, а драгоценный ресурс. И глупо было бы разводить ножку, которая всегда в единице (причём на плате DE0-NANO она также не разведена). Была бы Verilog-прослойка, соответствующую цепь можно было бы оборвать там, но я экономлю время (нервный смех, глядя на объём уже получившегося документа, но без экономии вышло бы ещё больше). Поэтому нет прослойки. Как быть? Идём в Assignment Editor. Именно в него, так как в Pin Planner, судя по описаниям, подобной функциональности нет.

Там пока что ещё нет ни одной линии. Хорошо. Создаём новую

Выбираем вот такую пиктограмму:

В системе поиска задаём нажимаем List и в результатах поиска находим нашу CKE:
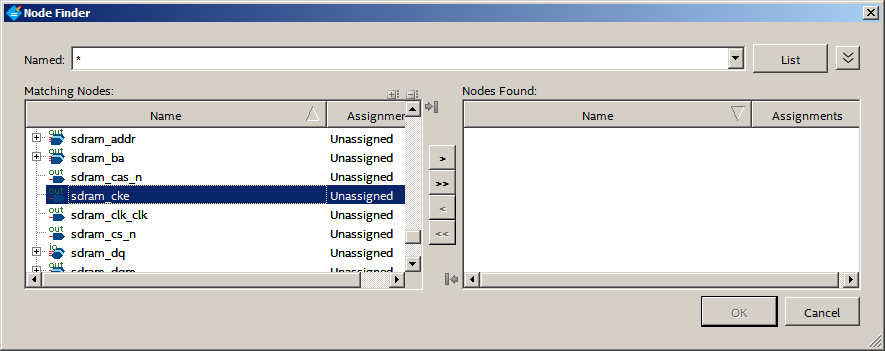
Добавляем её в правый столбец, нажимаем OK.
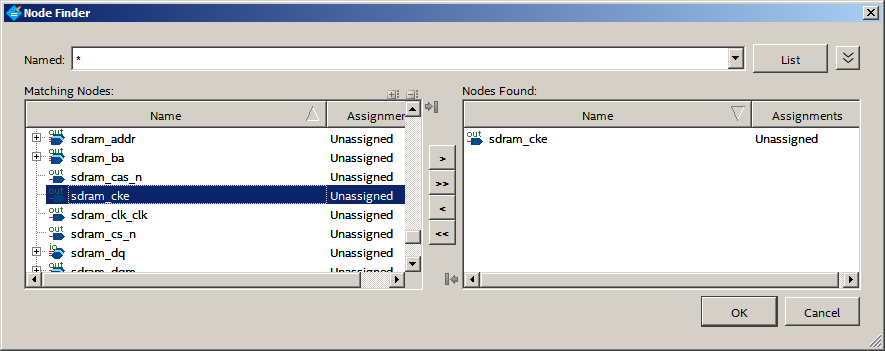
Получаем такой список:

В жёлтом поле щёлкаем по раскрывающемуся списку и находим Virtual Pin. Выбираем. Желтизна переехала в другую клетку:

Там выбираем On:
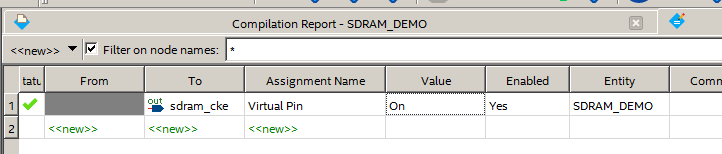
Всё, желтизны больше нет. А цепь у нас теперь отмечена, как виртуальная, а значит, не требующая физической ножки. Поэтому мы можем её не назначать на физический вывод ПЛИС. Закрываем Assignment Editor, открываем Pin Planner. Можно назначить ножки, сверяясь с рисунком, а можно взять список из файла *.qsf, входящего в состав проекта, который я приложу к статье.

Всё, закрываем Pin Planner, выполняем чистовую компиляцию проекта. Аппаратная часть готова, переходим к разработке программной части для полученной процессорной системы. Но статья получилась такая огромная, что это мы сделаем в следующий раз.
Длинное введение
Я не очень люблю теоретизировать, предпочитая выкладывать сразу какие-то практические вещи. Но в начале первой статьи, без длинного введения никуда. В нём я обосную текущий подход к разработке. И всё будет вертеться вокруг одного: человеко-час — очень дорогой ресурс. И дело не только в сроках, отведённых на проект. Он физически дорог. Если он тратится на разработку конечного продукта, ну что ж поделать, без этого никуда. Но когда он тратится на вспомогательные работы, это, на мой взгляд, плохо. Помню, был у меня спор с одним разработчиком, который говорил, что изготовив прототипы самостоятельно, он сэкономит родной компании деньги. Я же привёл довод, что он на изготовление потратит примерно 3 дня. То есть 24 человеко-часа. Берём его зарплату за эти часы, добавляем социальный налог, который «платит работодатель», а также аренду офиса за эти часы. И с удивлением видим, что заказав платы на стороне, можно получить меньшие затраты. Но это я так, утрирую. В целом, если можно избежать трудозатрат, их надо избегать.
Что такое разработка «прошивок» для комплекса Redd? Это вспомогательная работа. Основной проект будет жить долго и счастливо, он должен быть сделан максимально эффективно, с отличной оптимизацией и т.п. А вот тратить силы и время на вспомогательные вещи, которые уйдут в архив после окончания разработки, расточительно. Именно с оглядкой на этот принцип велась разработка аппаратуры Redd. Все функции, по возможности, реализованы в виде стандартных вещей. Шины SPI, I2C и UART реализованы на штатных микросхемах от FTDI и программируются через штатные драйверы, без каких-либо изысков. Управление релюшками реализовано в формате виртуального COM-порта. Его можно доработать, но по крайней мере, всё сделано для того, чтобы такого желания не возникало. В общем, всё стандартное, по возможности, реализовано стандартным образом. Из проекта в проект разработчики просто должны быстренько писать типовой код для PC, чтобы обращаться к этим шинам. Техника разработки на С++ должна быть очевидна для тех, кто разрабатывает программы для микроконтроллеров (про некоторые технические детали поговорим в другой статье).
Но особняком в комплексе стоит ПЛИС. Она добавлена в систему для случаев, если понадобится реализовывать какие-либо нестандартные протоколы с высоким требованием к быстродействию. Если таковые требуются — для неё «прошивку» делать придётся. Вот про программирование ПЛИС и хочется поговорить особо, как раз всё с той же целью — сократить время разработки вспомогательных вещей.
Чтобы не запутать читателя, сформулирую мысль в рамке:
Не обязательно в каждом проекте вести разработку для ПЛИС. Если для работы с целевым устройством хватает шинных контроллеров, подключённых напрямую к центральному процессору, стоит пользоваться ими.
ПЛИС добавлена в комплекс для реализации нестандартных протоколов.
Структурная схема комплекса
Давайте рассмотрим структурную схему комплекса
В нижней части схемы расположился «вычислитель». Собственно, это стандартный PC с ОС Linux. Разработчики могут писать обычные программы на языках Си, C++, Python и т.п., которые будут исполняться силами вычислителя. В правой верхней части расположены штатные порты типовых шин. Слева располагается коммутатор стандартных устройств (SPI Flash, SD карта и несколько слаботочных твердотельных реле, которые могут, например, имитировать нажатие кнопок). А по центру размещается именно та часть, работу с которой и планируется рассмотреть в данном цикле статей. Её сердцем является ПЛИС класса FPGA, из которой на разъём выходят прямые линии (могут использоваться как дифференциальные пары либо обычные небуферизированные линии), линии GPIO с задаваемым логическим уровнем, а также шина USB 2.0, реализуемая через микросхему ULPI.
Продолжение введения про подход к программированию ПЛИС
При разработке высокопроизводительной управляющей логики для ПЛИС обычно первую скрипку играет его величество конечный автомат. Именно на автоматах удаётся реализовать быстродействующую, но сложную логику. Но с другой стороны, автомат разрабатывается медленнее, чем программа для процессора, а его модификация — тот ещё процесс. Существуют системы, упрощающие разработку и сопровождение автоматов. Одна из них даже разработана нашей компанией, но всё равно процесс проектирования для сколь-либо сложной логики получается не быстрым. Когда разрабатываемая система является конечным продуктом, имеет смысл подготовиться, спроектировать хороший управляющий автомат и потратить время на его реализацию. Но как уже отмечалось, разработка под Redd — это вспомогательная работа. Она призвана облегчать процесс, а не усложнять его. Поэтому было принято решение, что основным будет разработка не автоматных, а процессорных систем.
Но с другой стороны, при разработке аппаратуры самый модный на сегодняшний день вариант, ПЛИС с ядром ARM, был отвергнут. Во-первых, по ценовым соображениям. Макетная плата на базе Cyclone V SoC стоит средне дорого, но, как ни странно, отдельная ПЛИС намного дороже. Скорее всего, цена на макетные платы демпинговая, чтобы заманить разработчиков на использование данных ПЛИС, а платы продаются штучно. На серию придётся брать отдельные микросхемы. Но кроме того, есть ещё и «во-вторых». Во-вторых, когда я проводил опыты с Cyclone V SoC, оказалось, что не так эта процессорная система и производительна, если речь идёт об единичных обращениях к портам. Пакетные — да, там работа идёт быстро. А в случае единичных обращений при тактовой частоте процессорного ядра 925 МГц, можно получить обращения к портам на частоте единицы мегагерц. Всем желающим я предлагаю повызывать штатную функцию постановки данных в FIFO блока UART, которая проверяет переполненность очереди, но вызывать её, когда очередь заведомо пуста, то есть, операциям ничего не мешает. Производительность у меня вышла от миллиона до пятисот тысяч вызовов в секунду (разумеется, работа с памятью при этом шла на нормальной скорости, все кэши были настроены, даже вариант функции, не проверяющий FIFO на переполненность, работал быстрее, просто в обсуждаемой функции имеются обильно перемешанные записи и чтения из портов). Это FIFO! Вообще-то, FIFO придумано для того, чтобы туда бросить данные и забыть! Быстро бросить! А не с производительностью, менее одной мегаоперации в секунду при тактовой частоте процессора 925 МГц…
Виной всему латентность. Между процессорным ядром и аппаратурой располагается от трёх мостов и более. Причём скорость доступа к портам зависит от контекста (несколько записей подряд будут идти быстро, но первое же чтение остановит процесс до полной выгрузки закэшированных данных, слишком много записей подряд — также замедлятся, так как исчерпаются буферы записи). Наконец, осмотр трасс, накопленных в отладочном буфере, показал, что у архитектуры Cortex A один и тот же участок может исполняться за различное число тактов из-за сложной системы кэшей. В сумме, глядя на все эти факторы (цена, просадки быстродействия при работе с аппаратурой, нестабильность скорости доступа к аппаратуре, общая зависимость от контекста), было решено не ставить такую микросхему в комплекс.
Эксперименты с PSoC фирмы Cypress показали, что там ядро Cortex M даёт более предсказуемые и повторяемые результаты, но логическая ёмкость и предельная рабочая частота этих контроллеров не соответствовали ТЗ, поэтому их тоже отбросили.
Было решено установить недорогую типовую ПЛИС Cyclone IV и рекомендовать использование синтезируемого процессорного ядра NIOS II. Ну, а при необходимости — вести разработки с использованием любых других методов (автоматы, жёсткая логика и т.п.).
Отдельно упомяну (и даже выделю этот абзац), что основной процессор комплекса — это x86 (x64). Именно он является центральным процессором системы. Именно на нём исполняется основная логика комплекса. Процессорная система, о которой речь пойдёт ниже, призвана просто обеспечивать логику работы аппаратуры, «прошиваемой» в ПЛИС. Причём эта аппаратура реализуется только в том случае, если разработчикам не хватает штатных модулей, подключённых напрямую к центральному процессору.
Процесс разработки и отладки «прошивок»
Если комплекс Redd работает под управлением ОС Linux, то это не значит, что и разработка должна вестись в этой ОС. Redd — это удалённый исполнитель, а разработку следует вести на своей ЭВМ, какая бы там ОС ни стояла. У кого стоит Linux — тем проще, но кто привык к Windows (когда-то я очень не любил WIN 3.1, но на работе заставили, а где-то ко временам WIN95 OSR2 произошло привыкание, и теперь с этим бороться бесполезно, проще принять), те могут продолжать вести разработку в ней.
Так как у меня с Линуксом дружба не задалась, пошаговых инструкций настройки среды под ним я не дам, а ограничусь общими словами. Кто с этой ОС работает — тому этого будет достаточно, а остальным… Поверьте, проще обратиться к системным администраторам. Я, в итоге, так и сделал. Но тем не менее.
Следует скачать и установить Quartus Prime Programmer and Tools той же версии, что и ваша среда разработки. При несовпадении версий, могут быть сюрпризы. Я потратил целый вечер, чтобы постичь этот факт. Поэтому просто скачивайте средство той же версии, что и среда разработки.
После установки, войдите в каталог, куда установилась программа, подкаталог bin. Вообще, самым главным файлом должен быть jtagconfig. Если запустить его без аргументов (кстати, у меня упорно требовали вводить ./jtagconfig и только так), то будет выдан список программаторов, доступных в системе и подключённых к ним ПЛИС. Там должен быть USB Blaster. И первая проблема, которую подкидывает система, не хватает прав доступа для работы с USB. Как решить её, не прибегая к помощи sudo, описано здесь: radiotech.kz/threads/nastrojka-altera-usb-blaster-v-ubuntu-16-04.1244
Но вот список устройств отображается. Теперь следует написать:
./jtagconfig --enableremote <password>после чего запустится сервер, доступный по сети отовсюду.
Всё бы ничего, но системный фаервол не даст никому этот сервер увидеть. А проверка на Гугле показала, что у каждого вида Линуксов (коих много) порты в фаерволе открываются по-своему, причём надо произнести такое количество заклинаний, что я предпочёл обратиться к админам.
Также стоит учитывать, что если jtagd не был прописан в автозапуск, то при открытии удалённого доступа, вам скажут, что невозможно установить пароль. Чтобы этого не произошло, jtagd обязательно должен быть запущен не средствами самого jtagconfig, а до него.
В общем, шаманство на шаманстве. Давайте я просто зафиксирую тезисы:
- в системе должен быть открыт входящий порт 1309. Какой протокол, я до конца не понял, для надёжности, можно открыть и tcp, и udp;
- при запуске jtagconfig без аргументов должен отображаться USB Blaster и подключённая к нему ПЛИС, а не сообщение об ошибке;
- перед открытием удалённой работы обязательно должен быть запущен jtagd с достаточными правами. Если ранее уже запустился jtagd с недостаточными правами, его процесс следует завершить перед новым запуском, иначе новый запуск не состоится;
- собственно удалённый доступ открывается строкой
jtagconfig --enableremote <password>
Есть, конечно, и аналогичный путь, который проходится через GUI интерфейс, но логичнее делать всё пакетно. Поэтому я описал пакетный вариант. Когда все эти тезисы выполнены (а мне их выполнили сисадмины), на своей машине запускаем программатор, видим сообщение об отсутствии оборудования. Нажимаем Hardware Setup:
Переходим на вкладку JTAG Settings и нажимаем Add Server:
Вводим сетевой адрес Redd (у меня это 192.168.1.100) и пароль:
Убеждаемся, что соединение прошло успешно.
Я потратил три майских праздника на достижение этого, а затем всё решили админы.
Переключаемся на вкладку Hardware Settings, раскрываем выпадающий список и выбираем там удалённый программатор:
Всё, теперь им можно пользоваться. Кнопка Start разблокирована.
Первая «прошивка»
Ну что ж. Чтобы статья имела реальную практическую ценность, давайте разберём простейшую «прошивку», сделанную с применением вышеописанных методов. Самое простое, что мне довелось реально реализовать для комплекса, это тест микросхемы SDRAM. Вот на этом примере и потренируемся.
Имеется ряд любительских ядер для поддержки SDRAM, но они все включаются как-то хитро. А учёт всех хитростей — это трудозатраты. Мы же попробуем воспользоваться готовыми решениями, которые можно вставить в вычислительную систему NIOS II, поэтому воспользуемся стандартным ядром SDRAM Controller Core. Само ядро описано в документе Embedded Peripherals IP User Guide, причём достаточно много места в описании посвящено сдвигу тактовых импульсов для SDRAM относительно тактовых импульсов ядра. Приводятся сложные теоретические выкладки и формулы, но что делать особо не сообщается. О том, что делать, можно узнать из документа Using the SDRAM on Altera’s DE0 Board with Verilog Designs. По ходу разбора я применю знания из этого документа.
Я буду вести разработку в бесплатной версии Quartus Prime 17.0. Акцентирую на этом внимание, так как при сборке, мне сообщают, что в будущем, ядро SDRAM Controller будет выкинуто из бесплатной версии. Если в вашей среде разработки это уже произошло, никто не мешает скачать бесплатную 17-ю версию и установить её на виртуальную машину. Основную работу вести там, где вы привыкли, а прошивки для Redd с SDRAM — в 17-й версии. Ну, это если вы пользуетесь бесплатными вариантами. Из платных никто выкидывать это пока не грозился. Но я отвлёкся. Создаём новый проект:
Назовём его SDRAM_DEMO. Имя следует запомнить: я собираюсь вести сверхбыструю разработку, поэтому на верхнем уровне должна будет оказаться сама процессорная система, без каких-либо Verilog-прослоек. А чтобы это произошло, имя процессорной системы должно будет совпадать с именем проекта. Так что запомним его.
Согласившись со значениями по умолчанию на нескольких шагах, доходим до выбора кристалла. Выбираем применённый в комплексе EP4CE10E22C7.
На следующем шаге я чисто по привычке выбираю моделирование в ModelSim-Altera. Сегодня мы не будем ничего моделировать, но всё может пригодиться. Лучше выработать такую привычку и следовать ей:
Проект создан. Сразу же идём в создание процессорной системы (Tools->Platform Designer):
Нам создали систему, содержащую модуль тактирования и сброса:
Но как я уже упоминал, для ядра SDRAM требуется особое тактирование. Поэтому штатный модуль безжалостно выкидываем
И вместо него добавляем блок University Program->System and SDRAM Clock for DE-series boards:
В свойствах выбираем DE0-Nano, так как вдохновение для схемы включения SDRAM черпалось из этой макетной платы:
Начинаем набивать нашу процессорную систему. Разумеется, первым делом в неё следует добавить само процессорное ядро. Пусть это будет Processor And Peripherals->Embedded Processors->NIOS II Processor.
Для него пока не заполняем никаких свойств. Просто нажимаем Finish, хоть у нас и образовался ряд сообщений об ошибках. Пока что отсутствует оборудование, которое позволит эти ошибки устранить.
Теперь добавляем собственно SDRAM. Memory Interfaces and Controllers->SDRAM->SDRAM Controller.
Здесь нам придётся подзадержаться на заполнении свойств. Выбираем ближайшую похожую по организации микросхему из списка и нажимаем Apppy. Её свойства попадают в поля Memory Profile:
Теперь меняем разрядность шины данных на 16, число адресных строк — на 13, а столбцов — на 9.
Времянки я пока не правлю, возможно, в будущем данная рекомендация будет изменена.
Процессорная система подразумевает программу. Программа должна где-то храниться. Мы будем проводить проверку микросхемы SDRAM. На данный момент мы не можем ей доверять. Поэтому для хранения программы, добавим память на основе блочного ОЗУ ПЛИС. Basic Functions->On Chip Memory->On-Chip Memory (RAM or ROM):
Объём… Ну пусть 32 килобайта.
Эта память должна откуда-то загружаться. Чтобы это происходило, установим флажок Enable non-default initialization file и введём какое-нибудь осмысленное имя файла. Скажем, firmware.hex:
Статья выходит уже и так сложной, поэтому не будем её перегружать. Просто будем выводить физический результат теста в виде линий PASS/FAIL (а логический результат мы увидим при моей любимой JTAG отладке). Для этого добавим порт GPIO. Processors and Peripherals->Peripherals->PIO (Parallel IO):
В свойствах выставляем 2 бита, ещё я люблю устанавливать флажок для индивидуального управления битами. Тоже — просто привычка.
У нас получилась вот такая система с кучей ошибок:
Начинаем их устранять. Для начала разведём тактирование и сброс. У блока тактирования и сброса надо выбросить входы наружу. Для этого имеются поля, на которых написано «Дважды щёлкните для экспорта»:
Щёлкаем, но даём более-менее короткие имена.
Ещё надо выбросить наружу тактовый выход SDRAM:
Теперь sys_clk разводим на все тактовые входы, а reset_source — на все линии сброса. Можно аккуратно попадать «мышкой» в точки, соединяющие соответствующие линии, а можно навестись на соответствующий выход, нажать правую кнопку «мыши», а затем — в выпадающем меню перейти в подменю Connections и выбрать связи там.
Дальше связываем шины воедино. Data Master подключаем ко всем шинам всех устройств, а Inctruction Master — почти ко всем. К шине PIO_0 его подключать не требуется. Оттуда инструкции считываться точно не будут.
Теперь можно разрешить конфликты адресов. Для этого выбираем пункт меню System->Assign Base Addresses:
А когда у нас появились адреса, можно назначить и вектора. Для этого идём в свойства процессорного ядра (наводимся на него, нажимаем правую кнопку «Мыши» и выбираем пункт меню Edit) и настраиваем там вектора на Onchip Memory. Просто выбираем этот тип памяти в выпадающих списках, цифры подставятся сами.
Ошибок не осталось. Но осталось два предупреждения. Я забыл заэкспортировать линии SDRAM и PIO.
Как уже мы это делали для блока сброса и тактирования, дважды щёлкаем по требуемым ножкам и даём им как можно более короткие (но понятные) имена:
Всё, больше нет ни ошибок, ни предупреждений. Сохраняем систему. Причём имя должно совпадать с именем проекта, чтобы процессорная система стала элементом верхнего уровня в проекте. Ещё не забыли, как он у нас назывался?
Ну, и нажимаем самую главную кнопку — generate HDL.
Всё, процессорная часть создана. Нажимаем Finish. Нам напоминают, что неплохо бы добавить эту процессорную систему к проекту:
Добавляем:
И там, при помощи кнопки Add, добиваемся такой картинки:
SIP файл ещё не создался. Да и не нужен он нам в рамках этой статьи.
Уффф. Первый шаг сделан. Производим черновую сборку проекта, чтобы система выяснила иерархию проекта и используемые ножки. Ошибки компиляции не страшные. Просто в бесплатной версии среды были созданы ядра, которые работают только пока подключён JTAG адаптер. Но в комплексе Redd он всегда и подключён, так как разведён на общей плате, то есть нам нечего бояться. Так что эти ошибки мы игнорируем.
Теперь вернёмся к описанию ядра SDRAM. Там сказано, что линия CKE не используется и всегда подключена к единице. На самом деле, в рамках комплекса ножки ПЛИС не просто дорогой, а драгоценный ресурс. И глупо было бы разводить ножку, которая всегда в единице (причём на плате DE0-NANO она также не разведена). Была бы Verilog-прослойка, соответствующую цепь можно было бы оборвать там, но я экономлю время (нервный смех, глядя на объём уже получившегося документа, но без экономии вышло бы ещё больше). Поэтому нет прослойки. Как быть? Идём в Assignment Editor. Именно в него, так как в Pin Planner, судя по описаниям, подобной функциональности нет.
Там пока что ещё нет ни одной линии. Хорошо. Создаём новую
Выбираем вот такую пиктограмму:
В системе поиска задаём нажимаем List и в результатах поиска находим нашу CKE:
Добавляем её в правый столбец, нажимаем OK.
Получаем такой список:
В жёлтом поле щёлкаем по раскрывающемуся списку и находим Virtual Pin. Выбираем. Желтизна переехала в другую клетку:
Там выбираем On:
Всё, желтизны больше нет. А цепь у нас теперь отмечена, как виртуальная, а значит, не требующая физической ножки. Поэтому мы можем её не назначать на физический вывод ПЛИС. Закрываем Assignment Editor, открываем Pin Planner. Можно назначить ножки, сверяясь с рисунком, а можно взять список из файла *.qsf, входящего в состав проекта, который я приложу к статье.
Всё, закрываем Pin Planner, выполняем чистовую компиляцию проекта. Аппаратная часть готова, переходим к разработке программной части для полученной процессорной системы. Но статья получилась такая огромная, что это мы сделаем в следующий раз.