
Старо как мир…
Люди всегда стремятся быть в курсе последних событий. Благодаря этому стремлению возникло много media, которым необходимо собственное мобильное приложение для доставки контента своим читателям. Так в магазинах появилось великое множество новостных приложений. Сотни приложений для чтения новостей, газет и журналов.

Практически все новостные приложения имеют похожий иерархический вид хранения и отображения статей: рубрики или разделы, списки новостей, и непосредственно сама статья с содержащимися в ней картинками, видео и так далее. Обычно в мобильном приложении пользователю приходится загружать эти элементы последовательно при навигации по приложению.
 Самый скучный момент для пользователя на этапе навигации начинается, когда загрузка по каким-либо причинам работает медленно. Тогда достаточно часто при переходах к статье в списке или при загрузке картинок он может наблюдать только прогрессбар. Наверное, поэтому разновидностей этих элементов тоже так много?
Самый скучный момент для пользователя на этапе навигации начинается, когда загрузка по каким-либо причинам работает медленно. Тогда достаточно часто при переходах к статье в списке или при загрузке картинок он может наблюдать только прогрессбар. Наверное, поэтому разновидностей этих элементов тоже так много?В статье мы расскажем о новом методе загрузки данных для приложений СМИ, который мы предложили и успешно реализовали с одним из наших заказчиков.
Соль жизни в поисках нового. (с)
Стандартно загрузка, например, списка статей в разделе происходит следующим образом: приложение запрашивает последние N новостей, сводит этот список с тем что было загружено и хранилось локально, формирует новый список и показывает его пользователю. Далее пользователь заходит в статью, загружает контент и так далее. При загрузке списка статей приложение и сервер могут взаимодействовать по двум схемам:
• Приложение просит загрузить список, начиная с момента последней загрузки. Но тогда на сервере запускается операция по поиску нужных данных в базе, что нагружает сервер.
• Приложение всегда грузит последние N статей и сводит список на своей стороне, но тогда это будет проигрышный вариант по траффику при частой загрузке.
Казалось бы, что тут можно изменить? И оказалось, что можно! Но надо применить творческий подход и немного трудолюбия.
Одному из наших заказчиков мы решили предложить оригинальный подход к методу загрузки данных, при котором у пользователя будет быстрая загрузка новостного контента и экономия траффика при частом периодическом использовании приложения.
Наша идея состояла в следующем: на стороне приложения нужно всегда хранить свежий архив новостей. И периодически в фоновом режиме мы будем обновлять его до актуального состояния.

Легко сказать, но сложнее реализовать. Здорово, что новости всегда будут в актуальном состоянии без (иногда длительной) загрузки данных.
Но как синхронизировать архив, который находится в приложении, и подготовленный обновлённый архив, расположенный на сервере. Неужели нужно просто скачать и заменить файл? Это не эффективно…
Схема решения
Итак, у нас есть два файла – на сервере и на клиенте (первоначальную ситуацию, когда в приложении файла нет, рассмотрим позже). И мы не хотим грузить серверный файл целиком при каждом обновлении. Наверняка, многие уже подумали, что можно сравнивать 2 версии файла и загружать только отличающиеся части. Мы подумали так же и поискали готовые решения. В результате пришли к двум самым популярным: bsdiff / bspatch и rsync.
Мы приметили bsdiff из-за его способности находить одинаковые последовательности байтов в двух версиях файлов, но расположенных в разных местах. Посмотрите на две битовые последовательности “0 1 0 1 0 1 0 1” и “0 0 1 0 1 0 1 0”. У них общий только первый бит, однако в них можно найти общую последовательность.
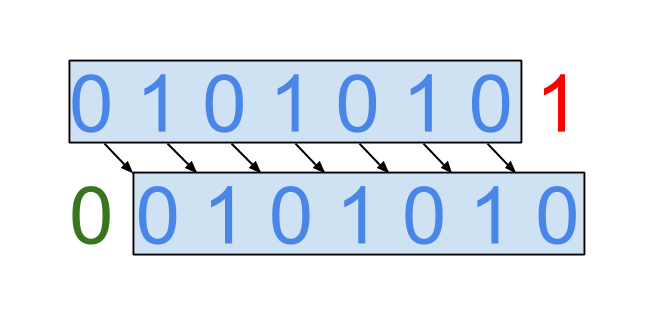
Таким образом, вторую последовательность из первой можно получить сдвинув первые 7 бит вправо на бит, добавить 0 в освободившееся место и удалить последний бит. Эта последовательность операций, записанная в определенном формате и сохраненная в файл, и есть результат работы утилиты bsdiff. Позднее этот файл, называемый патчем, и исходный файл могут быть обработаны утилитой bspatch, чтобы получить новый файл.
Это звучало многообещающе, вот только для высчитывания патча нужны обе версии файла. В итоге концепт выглядел так: на сервере мы храним N именованных версий выпуска за последние несколько дней и еще N-1 предпосчитанных патчей от каждой из них до последней. У клиента тоже есть какая-то из версий выпуска и её id, по которому он получит от сервера нужный патч и обновится.
Хотелось более универсального решения, чтобы можно было обновиться с любой версии и не зависеть от N, но больше всего нас тревожил тот факт, что bspatch использует memory-hungry алгоритм. Чтобы пропатчить файл размером 1МБ патчем размером 0,1МБ нужно потратить 1МБ + 0,1МБ оперативной памяти.
С такими мыслями мы оставили bsdiff, намереваясь никогда к нему не возвращаться, и стали исследовать rsync. Эта клиент-серверная утилита, работающая на уровне TCP,
широко известна в кругах пользователей unix-подобных систем. В общих словах, алгоритм её работы сводится к следующим шагам:
1. Клиент разбивает свой файл на последовательности размером K;
2. Для каждой последовательности клиент считает две контрольные суммы: MD4 и кольцевой хеш и отправляет все суммы серверу;
3. Сервер пытается найти в своей версии файла последовательности размером K, обе суммы которых совпадают с одной из тех, которые прислал клиент;
4. Сервер генерирует набор инструкций для клиента, которые ему нужно выполнить, чтобы превратить его версию файла в нужную.
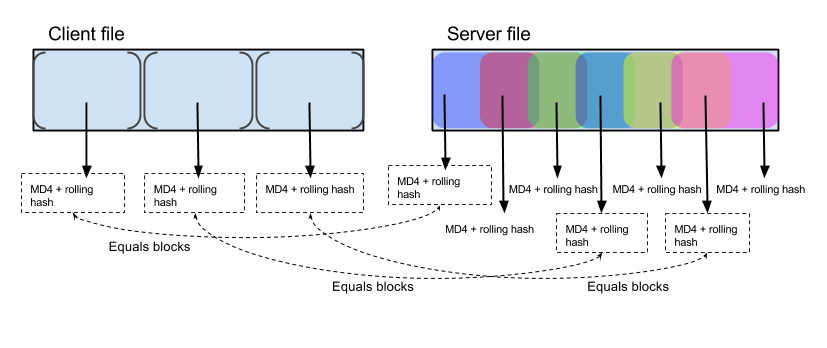
Примечательно, что сервер считает суммы от пересекающихся последовательностей. Это позволяет найти одинаковый блок данных, даже если он стоит на другом месте, при сравнении со старой версией файла.
Выглядит архикруто: синхронизация любой версии файла (в том числе никакой ? ), умный поиск общих частей файла — то, что нужно. Мы провели несколько proof-of-concept тестов утилиты rsync из репозитория Ubuntu, измеряя количество доканчиваемых данных между якобы “вчерашним” и “сегодняшним” выпусками и получили весьма обнадеживающие результаты. Вот только rsync не рассчитан на большое число клиентов. Каждая синхронизация файла — это загрузка серверного процессора вычислениями контрольных сумм. Если бы мы предложили такой концепт, умноженный на наших 200k daily users, ребята из back-end просто покрутили бы пальцем у виска. Поэтому мы этого не предложили.
Но, к счастью, после экспериментов с rsync мы обнаружили решение, которое наконец-то нам подошло – zsync.
ZSYNC
По сути, zsync — это open source http обёртка над rsync. Она использует те же алгоритмы для поиска общих частей/разницы файлов, что и rsync, но механизм передачи данных между клиентом и сервером совершенно другой.
Первым шагом на стороне сервера целевой файл обрабатывается утилитой zsyncmake, которая сгенерирует одноименный файл с расширением *.zsync со всеми подсчитанными непересекающимися контрольными суммами, размером блока данных, ссылкой на основной файл и прочей полезной информацией для клиента. К обоим файлам — целевому и *.zsync открывается HTTP доступ. Клиент сначала скачивает *.zsync файл, затем пытается найти в своей версии файла блоки с контрольными суммами, идентичными какой-нибудь сумме из метафайла. Теперь клиент знает, каких блоков данных ему не хватает и делает HTTP Range запрос целевого файла, получая только его недостающую часть.
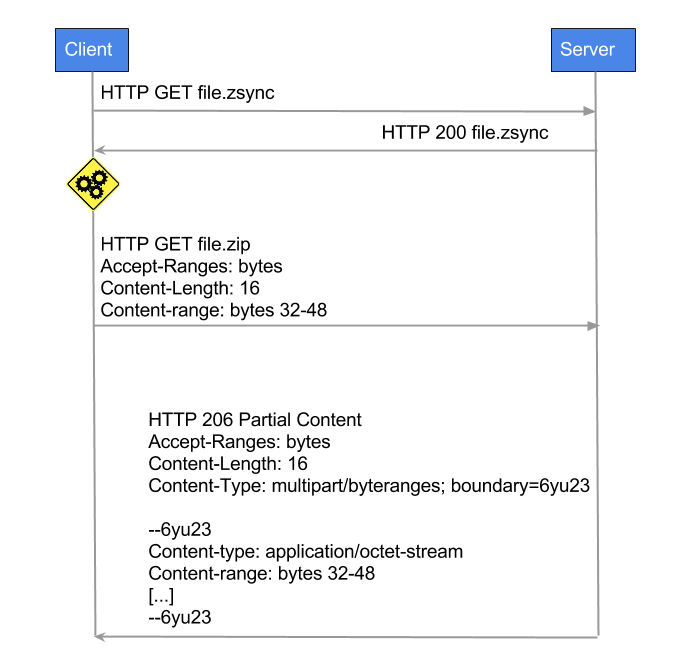
Вы заметили, как ловко на одном из шагов поменялись местами клиент и сервер в реализации zsync по сравнению с rsync? :) Теперь HTTP-сервер как rsync-клиент считает суммы для непересекающихся блоков, а HTTP-клиент как rsync-сервер находит эти блоки в своём файле.
Чтобы заставить zsync работать на нас, сначала пришлось незначительно портировать его под Android. А для интеграции zsync в наш проект, мы написали java-обертку, которая работала с zsync через JNI таким образом, чтобы на стороне C-кода остались только алгоритмические задачи, а скачивание, удаление метафайлов и range-запросы легли на плечи Android API.
Есть еще одно очень важное отличие zsync от rsync, о котором мы до сих пор не упоминали. Дело в том, что изменение даже одного байта исходного файла может привести к изменениям во всем файле его архива, так уж работают алгоритмы сжатия. По этой причине rsync не очень эффективен в синхронизации архивов. Можно попробовать повысить эффективность, уменьшая размер блоков, на которые делится файл. Но это палка о двух концах, потому что это увеличит объем операций по нахождению одинаковых блоков на сервере. Баланс между минимальным размером блока и максимальной эффективностью зависит от конкретных архивов, алгоритмов сжатия и самого контента. К счастью, zsync умеет при необходимости делить на блоки и считать суммы не сам архив, а его распакованное содержимое, но при этом определять недостающие блоки не у распакованного содержимого, а у архива. Вот такая хитрость, подробнее читайте тут в разделе Compressed Content.
«Какие ваши доказательства?» (с)
Ничего нет лучше, чем эксперимент с реальными данными. Мы собрали 2 выпуска: субботний и воскресный, размерами 7,8МБ и 8,5МБ, соответственно. В воскресном выпуске исчезли 2 статьи и появились 3 новых, что принесло в архив примерно 2,9МБ новых картинок и примерно 100КБ нового текста и вспомогательных файлов.
Посмотрим, как zsync справится с задачей:
Read topstories.zip. Target 61.8% complete.
downloading from http://[...]/topstoriesweb.zip:
#################### 100.0% 0.0 kBps DONE
verifying download...checksum matches OK
used 5234688 local, fetched 3242306
Трафик составил 3242306 байт. Чуть больше, чем реальный размер новых данных, но это всего ~7% избыточности. Good job, zsync.
One more thing…
Мы уже проделали хорошую работу, чтобы удивить пользователя нашего приложения решениями, о которых он никогда не узнает, но ведь всегда можно сделать что-то чуточку лучше. И мы сделали. Мы подготовили на сервере специальный выпуск из нескольких самых горячих статей, который качается только при первом запуске приложения для того, чтобы уже через несколько секунд пользователь был в курсе событий. А пока он занят, zsync позаботится о том, чтобы этот маленький выпуск превратился в настоящий полноценный.
Уже больше года мы используем схему bundle downloading в связке с zsync взамен привычной “request-per-item” для доставки контента юзерам и пока не собираемся отказываться, потому что нам она кажется удобнее:
• 1 запрос на выпуск или 1 запрос на секцию реализуется проще, чем цепочка: скачать список статей -> скачать контент каждой статьи -> скачать медиа-файлы каждой статьи -> etc;
• из коробки офлайн режим, при условии успешной синхронизации, конечно;
• отлично вписывается в схему эффективной, по мнению Google, синхронизации: синхронизация произойдет в благоприятное для девайса время, с нормальным зарядом батареи и хорошим интернет-соединением.
Но весь интернет скачать не удастся. Такой подход, очевидно, требует гораздо больше локального хранилища и нужно аккуратно подходить к вопросу о том, что мы предзагружаем, а что — нет. К примеру, для экономии места на старых девайсах мы решили научить наш сервер готовить специальные выпуски с картинками меньшего разрешения, а для девайсов с медленным интернет-соединением так вовсе без иллюстраций. Это не значит, что пользователь вовсе не увидит фотографии, они просто не попадут в предзагрузку.
Вот и всё
Данный метод не решает всех задач передачи новостного контента с сервера на многочисленные устройства наших пользователей. Но он помог нам в приложении ускорить загрузку контента, сократив ожидание пользователей, а также значительно уменьшить нагрузку на сервер. Нам удалось применить творческий подход и сделать быстро работающее экономное программное решение, при этом не увеличивать мощность серверного железа.
Всем удачного дня!
Комментарии (9)

zelyony
23.07.2015 17:11+21) В облаках, а 200к daily users вы же не на домашнем компе гоняете, уже давно есть оффлайн синхронизации azure.microsoft.com/en-us/documentation/articles/mobile-services-android-get-started-offline-data. у Гугла и Амазона скорее всего тоже. [SQLite <==> MSSQL or MySQL or...]
2) Вы засунули zsync в Android, что-то бьете на блоки и вычисляете хеши. Вы жрете батарейку! Чем простое скачивание обновлений, которые целиком вычисляются не сервере, вам не угодило?
Patch: { TIMESTAMP, {DEL pos, len}0+, {INS pos, len, [data]}0+, {UPD pos, len, [data]}0+ } и клиент тупо скачивает все апдейты после имеющегося и обновляет ими свой файл. К тому же сервер может оптимизировать несколько последних апдейтов в один и хранить их в каком-нибудь LRU-кеше, чтобы их количество не перешло разумные рамки. /* UPD можно реализовать с помощью DEL и INS, но оно позволяет менять файл in-place. */
forceLain
26.07.2015 18:14Прелесть rsync в том, что алгоритм на определяющей стороне (в нашем случае — девайс) весьма быстрый и позволяет определить блоки только за 1 проход по файлу, при чем даже не загружая его в память целиком. Почему Вы считаете, что это жрет батарею?

Bringoff
26.07.2015 17:49Честно говоря, тоже не понял всех этих танцев. Реально ведь проще загружать постатейно. Допустим, раз в сутки кидать запрос, что нужны новые данные, и с запросом передавать, скажем, индекс последней имеющейся статьи. В ответ сервер должен отдать все, что новее указанной. Старые через какое-то время трутся с локальной базы. RSS ридеры ведь по такой схеме работают.
forceLain
26.07.2015 18:09Еще нужно проверять каждую из загруженных статей на её актуальность: её могут исправить или удалить. Старые статьи при этом детектируются в тот же момент и не нужно их удалять через «какое-то» время. Определить diff для всех статей — это всего 1 http-запрос, получить сам diff — второй. Не нужно заботиться о консистентности данных внутри статьи и между ними. На мой взгляд, нет не проще :)
Bringoff
26.07.2015 19:03Да нет, проще. Если статью исправили, на сервере добавлять её в «новые», но, скажем, с тем же индексом. В любом случае, это лучше, чем велосипед с побитовыми диффами содержимого архивов в
dyadyaSerezha
А почему вы решили, что:
1. Поиск статей по дате публикации нагружает сервер? Поиск по индексу самая классическая операция любой БД и вполе быстрая.
2. Зачем делать какие-то диффы, если можно просто разбить весь документ (выпуск) на статьи и загружать постатейно? Мне показалось, что вы фактически объединили таблицу БД в один большой объект и теперь изобретаете велосипед, как бы не скачивать ее всю каждый раз.
3. Где сравнения производительности/трафика стандартного решения с БД (с индексом по датам) и ваших диффов?
Или я чего-то не понял?
unlying
Да, тоже не понял, зачем всё хранить в одном файле.
forceLain
Модель данных заказчика не похожа на привычную длинную ленту новостей, которая дополняется новым постом каждые несколько часов и у каждого клиента в телефоне последней статьей может быть любая из них. Она скорее выглядит как выпуск журнала с несколькими секциями и статьями в них за какой-то период (от суток до месяца). Можно было бы догружать свежие новости и по дате публикации, но в таком случае они всё равно грузились бы всей той пачкой, которая публикуется периодически. И можно было бы загружать каждую статью отдельно но зачем, если по статистике он почти всегда и так захочет прочитать их все. Консистентность набора статей позволила добавить много UX улучшений:
* многие статьи ссылаются друг на друга как по содержанию, так и по навигации через ссылки
* т.к. на планшетах юзер может видеть превью сразу 2-х или 3-х статей к ряду, можно подготавливать специальные статьи, картинки в которых будучи поставлены рядом объединяются в одну большую картинку прямо как на развороте журнала. Выглядит очень круто.
* помимо самого контента хотелось получать и кучу мета-информации, такой как соотношение сторон картинок, что бы правильно её позиционировать внутри текста и пр.
и если грузить это всё привычным подходом, пришлось бы дополнительно вводить кучу динамеческих условий на случай fallback-ов, таких как «не показывать статью А, потому что связанная с ней B еще грузится» или «показывать индикатор load more, потому что статьи в этой секции еще есть, но загрузить их еще не удалось» и т.п.
И был еще один важный кейс: уже загруженная новость-статья могла дополнятся/корректироваться после публикации, что заставляло периодически проверять уже загруженные статьи на актуальность и в противном случае опять их скачивать, учитывая всё то, что я уже написал выше :) А получить diff для всего раздела оказалось проще.
Я не хочу сказать, что то, что у нас в итоге получилось это оптимальное по всем параметрам решение, но могу сказать с уверенностью, что раньше у нас было как у всех, а теперь, перейдя на описанный способ, жить стало гораздо проще :)
dyadyaSerezha
Описанная модель только упрощает синхронизацию. Не понимаю вдвойне. )