
Полный курс на русском языке можно найти по этой ссылке.
Оригинальный курс на английском доступен по этой ссылке.

Выход новых лекций запланирован каждые 2-3 дня.
— Итак, мы снова вместе с вами и с нами по-прежнему Себастьян. Мы как раз хотим обсудить полносвязные слои, те самые Dense-слои. Перед этим мне бы хотелось задать один вопрос. Каковы границы и каковы основные препятствия, которые будут стоять на пути развития глубокого обучения и окажут на него наибольшее влияние в ближайшие 10 лет? Всё меняется настолько быстро! Как вы думаете, что будет той самой следующей «большой вещью» (big thing — прорывом)?
— Я бы назвал две вещи. Первая — общий искусственный интеллект (general AI) для выполнения более чем одной задачи. Это же здорово! Люди могут решать более чем одну задачу и никогда не должны заниматься одним и тем же. Второе — выведение технологии на рынок. Для меня, особенность машинного обучения заключается в том, что оно предоставляет компьютерам возможность наблюдать и находить паттерны в данных, помогая людям становиться лучшими в области — на уровне экспертов! Машинное обучение может быть использовано в юриспруденции, медицине, автономных автомобилях. Разрабатывайте подобные приложения, потому что они могут принести огромное количество денег, но что самое важное в этом всём — у вас есть возможность сделать мир значительно лучше.
— Мне очень нравится то, как всё сказанное вами складывается в единую картину относительно глубокого обучения и его применения — это всего лишь инструмент, который может помочь вам решить определённую задачу.
— Да, именно! Невероятный инструмент, не так ли?
— Да, да, я с вами полностью согласна!
— Почти как человеческий мозг!
— Вы упоминали медицинские приложения в нашем первом интервью, в первой части видео-курса. В каких приложениях, по-вашему мнению, применение глубокого обучения вызывает наибольший восторг и удивление?
— Очень много! Очень! Медицина находится в шорт-листе направлений, которые активно используют глубокое обучение. Я потерял свою сестру несколько месяцев назад, она была больна раком, что очень печально. Я думаю существуют множество заболеваний, которые могли бы быть детектированы ранее — на ранних стадиях, давая возможность от них излечить или замедлить процесс их развития. Идея, по сути, заключается в том, чтобы перенести некоторые инструменты в дом (умный дом), чтобы была возможность детектировать подобного рода отклонения в здоровье задолго до того момента, когда их заметит сам человек. Ещё я бы добавил — всё повторяющееся, любая офисная работа, где вы выполняете однотипные действия снова и снова, например, бухгалтерия. Даже я, как CEO, делаю очень много повторяющихся действий. Было бы здорово автоматизировать их, даже работу с почтовой перепиской!
— Не могу с вами не согласиться! В этом уроке мы познакомим слушателей курса со слоем нейронной сети называемом полносвязным (dense-layer). Могли бы вы рассказать нам подробнее, что вы думаете о полносвязных слоях?
— Итак, начнём с того факта, что каждая сеть может быть связана по-разному. Некоторые из них могут иметь очень плотную связность, которая позволяет получить некоторую выгоду при масштабировании и «выиграть» у больших сетей. Иногда вы не знаете, какое количество связей понадобится, поэтому соединяете всё со всем — это и называется полносвязаным слоем. Добавлю, что у этого подхода куда больше мощи и потенциала, чем у чего-то более структурированного.
— Полностью с вами согласна! Благодарю, что помогли нам узнать немного больше о полносвязных слоях. С нетерпением жду того момента, когда мы наконец-то приступим к их реализации и написанию кода.
— Получайте удовольствие! Будет действительно весело!
— С возвращением! В прошлом уроке вы разобрались с тем, как построить свою первую нейронную сеть с использованием TensorFlow и Keras, как работают нейронные сети и как устроен процесс тренировки (обучения). В частности, мы увидели каким образом можно обучить модель преобразовывать градусы Цельсия в градусы Фаренгейта.

— Мы так же познакомились с понятием полносвязных слоёв (dense-слои), наиболее важный слой в нейронных сетях. Но в этом уроке мы будем заниматься намного более крутыми вещами! В этом уроке мы разработаем нейронную сеть, которая сможет распознавать элементы одежды и изображения. Как мы уже упоминали ранее, машинное обучение использует входные данные называемые «признаками» (features, свойствами) и выходные данные называемые «метками» (labels) по которым модель учится и находит алгоритм преобразования. Поэтому, во-первых, нам понадобится много примеров, чтобы обучить нейронную сеть распознавать различные элементы одежды. Напомню, что примером для обучения является пара значений — входной признак и выходная метка, которые подаются на вход нейронной сети. В нашем новом примере в качестве входных данных будет изображение, а выходной меткой должна быть категория одежды к которой относится изображенный на картинке элемент одежды. К счастью, такой набор данных уже существует. Он называется Fashion MNIST. Мы рассмотрим подробнее этот набор данных в следующей части.
Добро пожаловать в мир набора данных MNIST! Итак, наш набор состоит из изображений размером 28х28, каждый пиксель которого представляет собой оттенок серого.

Набор данных содержит изображения футболок, топов, сандалей и даже ботинок. Вот полный список того, что содержит в себе наш набор данных MNIST:
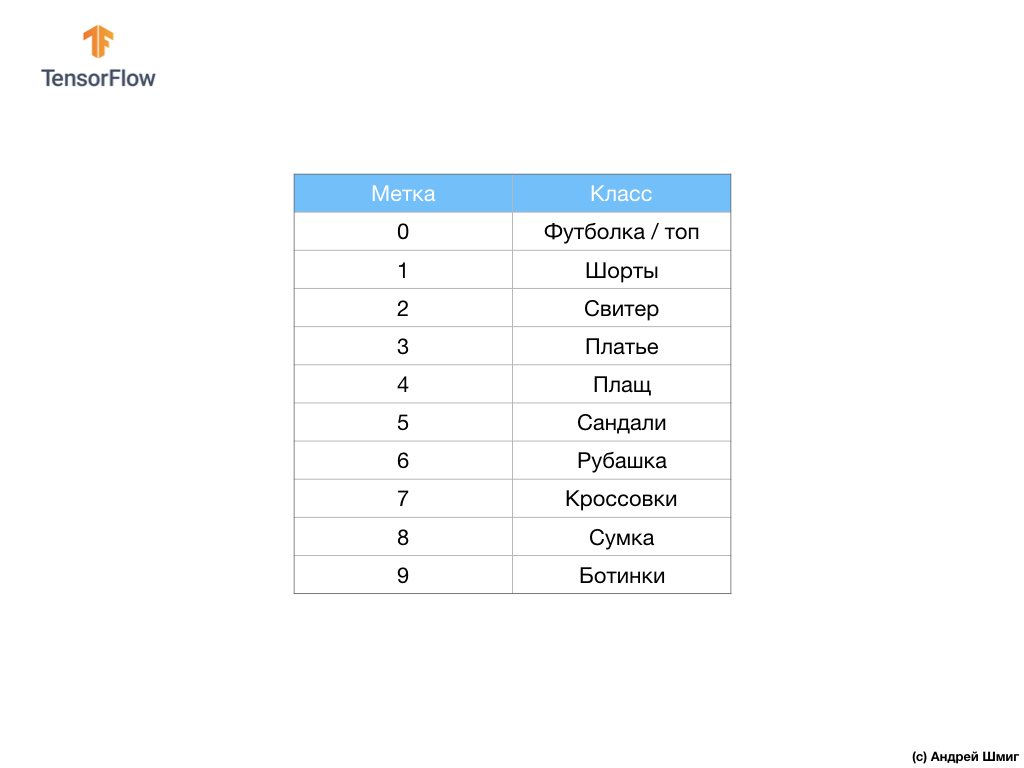
Каждому входному изображению соответствует одна из перечисленных выше меток. Набор данных Fashion MNIST содержит 70 000 изображений, поэтому нам есть с чего начать и с чем работать. Из этих 70 000 мы воспользуемся 60 000 для тренировки нейронной сети.
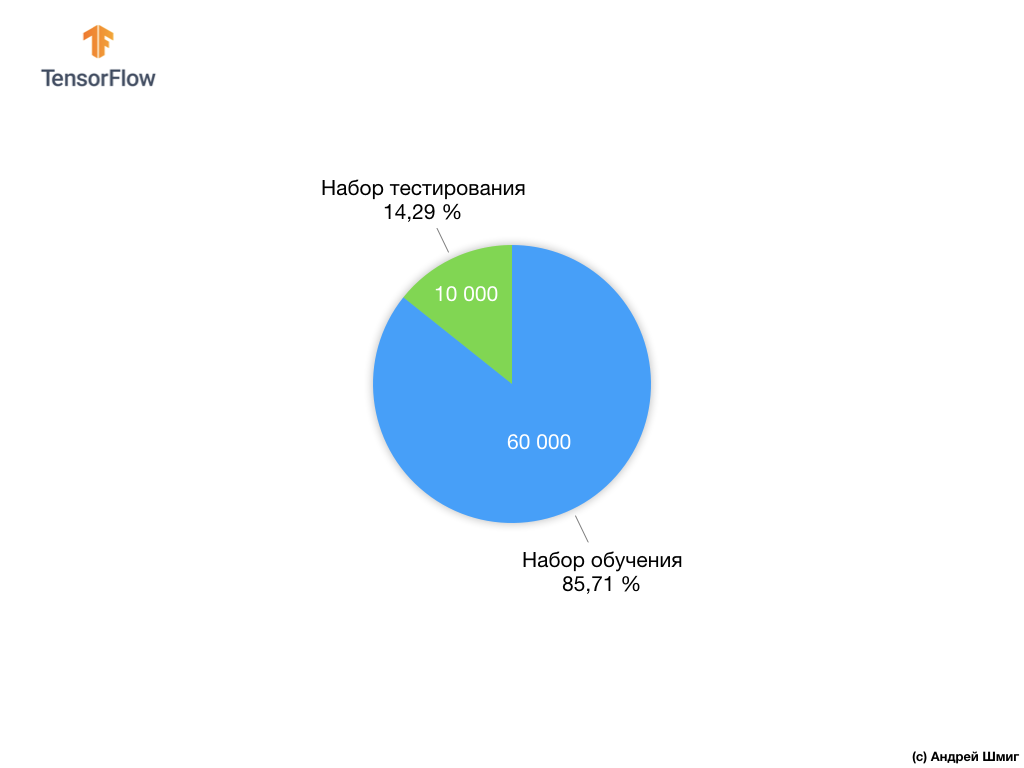
А оставшимися 10 000 элементами мы воспользуемся для того, чтобы проверить насколько хорошо наша нейронная сеть обучилась распознавать элементы одежды. Чуть позже мы поясним, почему разделили набор данных на обучающий набор и на набор тестирования.
Итак, вот наш набор данных Fashion MNIST.
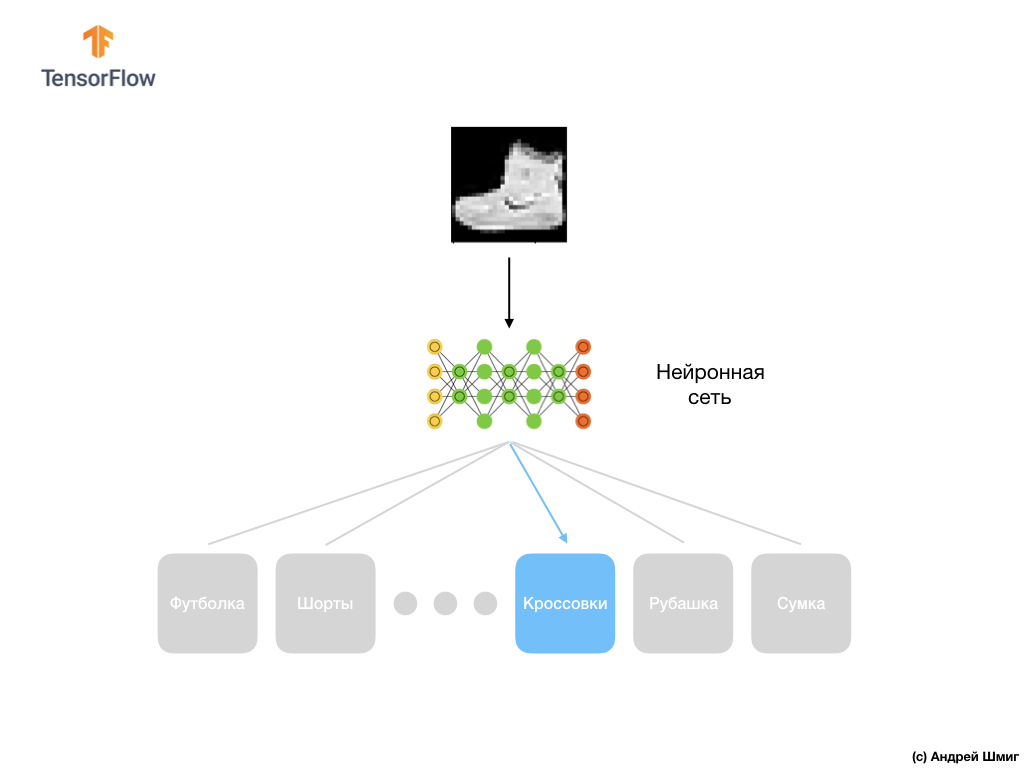
Запомните, каждое изображение в наборе данных представляет собой изображение размером 28х28 в оттенках серого, а это значит, что каждое изображение размером 784 байта. Наша задача заключается в том, чтобы создать нейронную сеть, которая на входе получает эти 784 байта, а на выходе возвращает к какой категории одежды из 10 имеющихся поданый на входе элемент относится.
В этом уроке мы будем использовать глубокую нейронную сеть, которая обучится классифицировать изображения из набора данных Fashion MNIST.
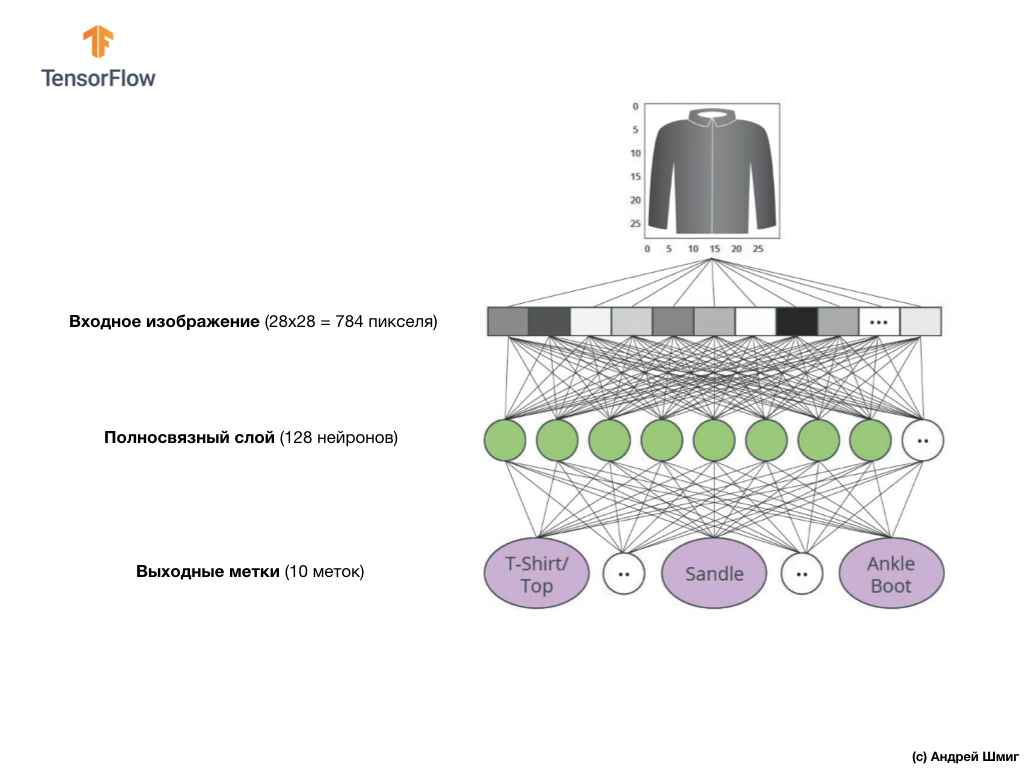
На изображении выше приведено то, как будет выглядеть наша нейронная сеть. Давайте рассмотрим её детальнее.
В качестве входного значения нашей нейронной сети служит одномерный массив длиной 784, массив именно такой длины по той причине, что каждое изображение представляет собой 28х28 пикселей (=784 пикселей всего в изображении), которое мы преобразуем в одномерный массив. Процесс преобразования 2D-изображения в вектор называется сглаживанием (flattening) и реализуется посредством сглаживающего слоя — flatten-слоя.
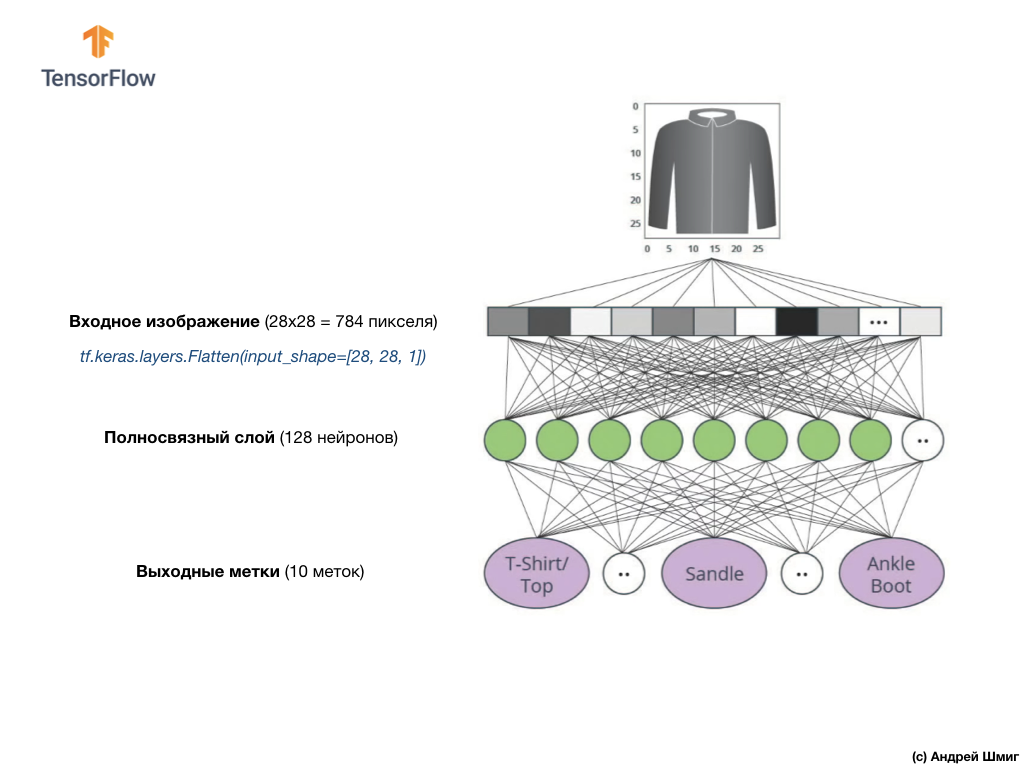
Выполнить сглаживание можно посредством создания соответствующего слоя:
Данный слой преобразует 2D-изображение размером 28х28 пикселей (на каждый пиксель приходится 1 байт для оттенков серого) в 1D-массив состоящий из 784 пикселей.
Входные значения будут полностью связаны с нашим первым
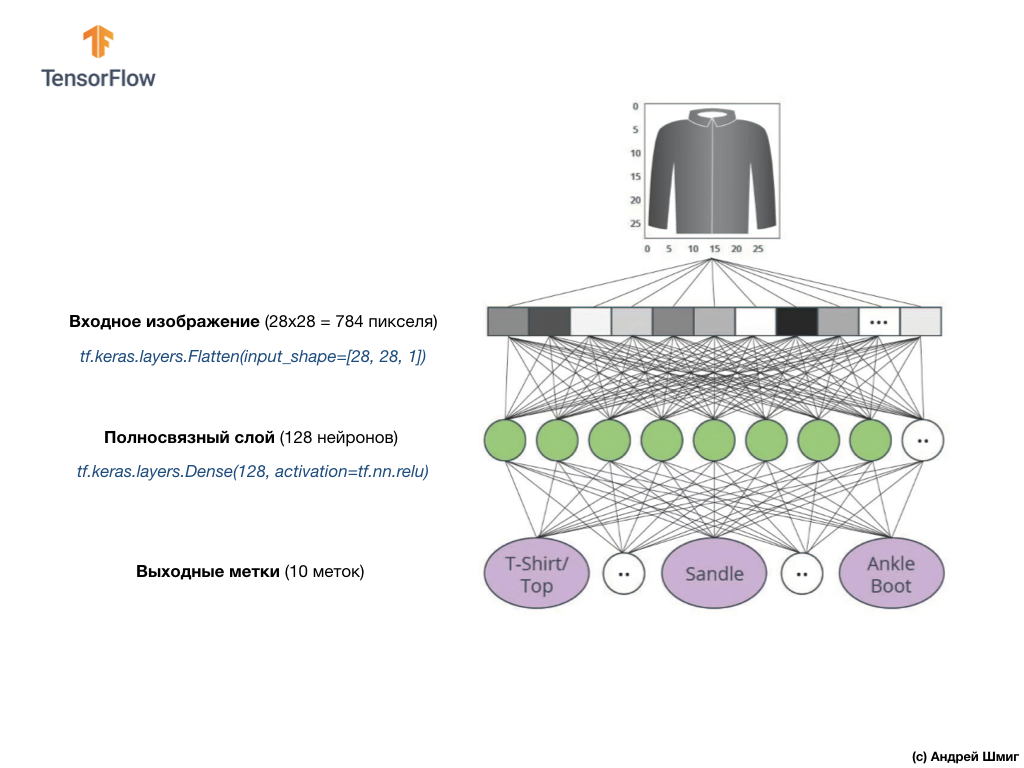
Вот как будет выглядеть создание этого слоя в коде:
Стоп! Что это ещё за
Наконец, наш последний слой, известный так же как выходной слой, состоит из 10 нейронов. Состоит он из 10 нейронов потому, что наш набор данных Fashion MNIST содержит 10 категорий одежды. Каждое из этих 10 выходных значений будет представлять собой вероятность того, что поданое на вход изображение относится к данной категории одежды. Другими словами, эти значения отображают «уверенность» модели в корректности предсказания и соотнесения поданого изображения с определенной из 10 категорий одежды на выходе. Например, какова вероятность того, что на изображении платье, кроссовок, ботинок и т.д.
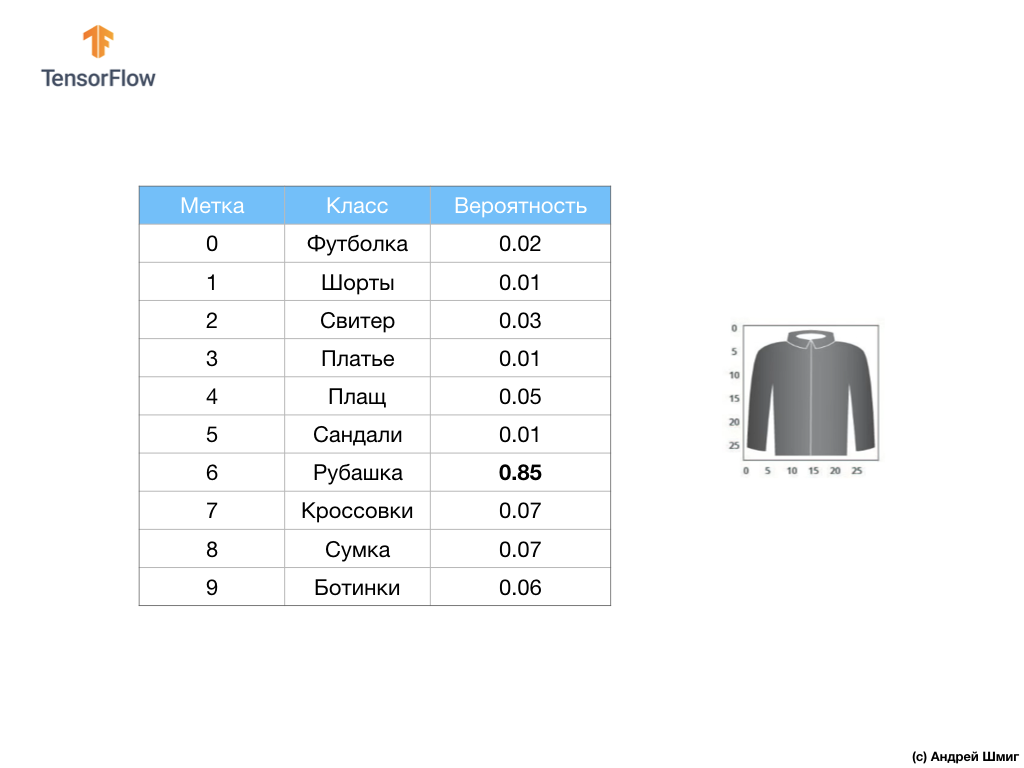
Например, если на вход нашей нейронной сети будет подано изображение рубашки, то модель может выдать нам результаты вроде тех, которые вы видите на изображении выше — вероятности соответствия входного изображения выходной метке.
Если вы обратите внимание, то заметите, что наибольшая вероятность — 0.85 относится к метке 6, которая соответствует рубашке. Модель на 85% уверена, что на изображении рубашка. Обычно те вещи, которые будут похожи на рубашки, так же будут иметь высокую оценку вероятности, а вещи наименее похожие — наименьшую оценку вероятности.
Так как все 10 выходных значений соответствуют вероятностям, то при суммировании всех этих значений мы получим 1. Эти 10 значений ещё называются распределением вероятностей.
Теперь нам необходим выходной слой для вычисления тех самых вероятностей для каждой метки.

И сделаем мы это с помощью следующей команды:
Фактически, когда бы мы не создавали нейронные сети, которые решают задачи классификации, мы всегда используем в качестве последнего слоя нейронной сети полносвязный слой. Последний слой нейронной сети должен содержать количество нейронов равных количеству классов, принадлежность к которым мы определяем и использовать
В этом уроке мы поговорили о
Функция
Преобразование градусов Цельсия в градусы Фаренгейта является линейной задачей, потому что выражение
Давайте пробежимся по новым терминам, которые были введены в этом уроке:
Тренируя модель любую модель в машинном обучении всегда необходимо разделять набор данных на, как минимум, два различных набора — набора данных используемого для обучения и набора данных используемого для тестирования. В этой части мы разберёмся почему стоит так поступать.
Давайте вспомним, каким образом мы распределили наш набор данных из Fashion MNIST состоящих из 70 000 экземпляров.
Мы предложили разделить 70 000 на две части — в первой части оставить 60 000 для обучения, а во второй части 10 000 для тестирования. Необходимость такого подхода вызвана следующим фактом: после того как модель была обучена на 60 000 экземплярах необходимо проверить результаты и эффективность её работы на таких примерах, которых ещё не было в наборе данных на которых модель обучалась.
В своём роде это напоминает сдачу экзамена в школе. Перед тем как сдавать экзамен вы усердно занимаетесь решая задачи определённого класса. Затем, на экзамене, сталкиваетесь с таким же классом задач, но другими входными данными. Подавать на вход те же данные, которые были во время тренировки нет смысла, иначе задача сведётся к запоминанию решений, а не поиску модели решения. Именно поэтому на экзаменах вы сталкиваетесь с таким задачами, которых ранее не было в обучающей программе. Только таким образом можно проверить обучилась ли модель общему решению или нет.
То же самое происходит и при машинном обучении. Вы показываете некоторые данные, которые представляют собой определённый класс задач, который вы хотите научиться решать. В нашем случае, с набором данных из Fashion MNIST, мы хотим чтобы нейронная сеть могла определить категорию к которой относится элемент одежды на изображении. Именно поэтому мы тренируем нашу модель на 60 000 примерах, которые содержат все категории элементов одежды. После тренировки мы хотим проверить эффективность модели, поэтому подаём на вход оставшиеся 10 000 элементов одежды, которые модель ещё «не видела». Если бы мы решили этого не делать, не проводить тестирования на 10 000 примерах, то не смоглы бы с уверенностью сказать обучилась ли наша модель на самом деле определять класс элемента одежды или она запомнила все пары входных + выходных значений.
Именно поэтому занимаясь машинным обучением у нас всегда есть набор данных для обучения и набор данных для тестирования.
Набор набор для TensorFlow предоставляет коллекцию готовых к использованию данных для обучения.
Наборы данных обычно разделены на несколько блоков, каждый из которых используется на определенной стадии тренировки и проверки эффективности работы нейронной сети. В этой части мы говори о:
Рассмотрим ещё один набор данных, который я называю проверочным набором (validation dataset). Этот набор данных не используется для тренировки модели, только во время тренировки. Итак, после того как наша модель прошла несколько циклов тренировок, мы подаём ей на вход наш проверочный набор данных и смотрим на результаты. Например, если во время тренировки значение функции потерь уменьшается, а точность ухудшается на проверочном наборе данных, то это значит что наша модель просто напросто запоминает пары входных-выходных значений.
Проверочный набор данных используется повторно в самом конце тренировки для измерения итоговой точности предсказаний модели.
Более подробно о тренировочных и тестовых наборах данных можно прочитать в Google Crash Course.
Ссылка на оригинальный CoLab на английском и ссылка на русский CoLab.
В этой части урока мы построим и обучим нейронную сеть классифицировать изображения элементов одежды, такие как платья, кроссовки, рубашки, футболки и т.п.
Всё впорядке, если какие-то моменты будут непонятны. Цель этого курса познакомить вас с TensorFlow и параллельно пояснить алгоритмы его работы и выработать общее понимание проектов использующих TensorFlow, а не углубляться в детали реализции.
В этой части мы используем
Нам понадобится набор данных TensorFlow, API который упрощает загрузку и доступ к наборам данных предоставленных несколькими сервисами. Так же нам понадобится несколько вспомогательных библиотек.
В этом примере используется набор данных Fashion MNIST, который содержит 70 000 изображений элементов одежды в 10 категориях в градациях серого. Изображения содержат элементы одежды в низком разрешении (28х28 пикселей), как показано ниже:

Fashion MNIST используется как замена классическому набору данных MNIST — чаще всего используется как «Hello, World!» в машинном обучении и компьютерном зрении. Набор данных MNIST содержит изображения цифр написанных от руки (0, 1, 2 и тд) в таком же формате, каком представлены элементы одежды в нашем примере.
В нашем примере мы используем Fashion MNIST из-за разнообразия и потому, что эта задача более интересна с точки зрения реализации, чем решение типичной задачи на наборе данных MNIST. Оба наборы данных достаточно малы, поэтому используются для проверки корректной работоспособности алгоритма. Отличные наборы данных для старта изучения машинного обучения, тестирования и отладки кода.
Мы воспользуемся 60 000 изображениями для тренировки сети и 10 000 изображениями для проверки точности обучения и классификации изображений. Вы можете напрямую обращаться к набору данных Fashion MNIST через TensorFlow используя API:
Загружая набор данных мы получаем метаданные, обучающий набор данных и тестовый набор данных.
Изображения представляют собой двумерные массивы
Каждое изображение относится к одной метке. Так как наименования классов не содержатся в исходном наборе данных, давайте сохраним их для дальнейшего использования, когда будем отрисовывать изображения:
Давайте изучим формат и структуру данных представленных в обучающем наборе перед тренировкой модели. Следующий код покажет, что 60 000 изображений находятся в обучающем наборе данных, а 10 000 изображений в тестовом наборе:
Значение каждого пикселя в изображении находится в интервале
Давайте отрисуем изображение, чтобы взглянуть на него:
Отобразим первые 25 изображений из тренировочного набора данных и под каждым изображением укажем к какому классу оно относится.
Убедитесь, что данные в корректном формате и мы готовы приступить к созданию и тренировки сети.

Построение нейронной сети требует настройки слоёв, а затем сборки модели с функциями оптимизации и потерь.
Базовым элементом при построении нейронной сети является слой. Слой извлекает представление из данных, которые поступили ему на вход. Результатом работы связанных нескольких слоёв мы получаем представление, которое имеет смысл для решения поставленной задачи.
Большую часть времени занимаясь глубоким обучением вы будете заниматься созданием связей между простыми слоями. Большинство слоёв, например, такие как tf.keras.layers.Dense имеют набор параметров, которые могут быть «подогнаны» во время процесса обучения.
Сеть состоит из трёх слоёв:
Перед тем как мы приступим к тренировке модели стоит ещё выполнить несколько настроек. Эти настройки производятся во время сборки модели при вызове метода compile:
Во-первых, определяем последовательность действий при обучении на тренировочном наборе данных:
Тренировка происходит посредством вызова метода
(на параметр
А вот и вывод:
В процессе тренировки модели значение функции потерь и метрика точности отображаются для каждой обучающей итерации. Эта модель достигает точности около 0.88 (88%) на тренировочных данных.
Проверим какую точность выдаёт модель на тестовых данных. Воспользуемся всеми примерами, которые у нас есть в тестовом наборе данных для проверки точности.
Вывод:
Как вы можете заметить, точность на тестовом наборе данных оказалась меньше точности на тренировочном наборе данных. Это вполне нормально, так как модель была обучена на train_dataset данных. Когда модель обнаруживает изображения, которые она ранее никогда не видела (из набора данных train_dataset), вполне очевидно, что эффективность классификации снизится.
Можем воспользоваться обученной моделью для получения предсказаний по некоторым изображениям.
Вывод:
В примере выше модель предсказала метки для каждого тестового входного изображения. Давайте посмотрим на первое предсказание:
Вывод:
Напомним, что предсказания модели — это массив из 10 значений. Эти значения описывают «уверенность» модели в том, что входное изображение относится к определённому классу (элементу одежды). Мы можем посмотреть максимальное значение следующим образом:
Вывод:
Это значит, что модель проявила наибольшую уверенность в том, что это изображение относится к классу с меткой 6 (class_names[6]). Можем проверить и убедиться в том, что результат соответствует действительности и он корректен:
Мы можем отобразить все входные изображения и соответствующие предсказания модели по 10 классам:
Давайте взглянем на 0-ое изображение, результат предсказания модели и массив предсказаний.
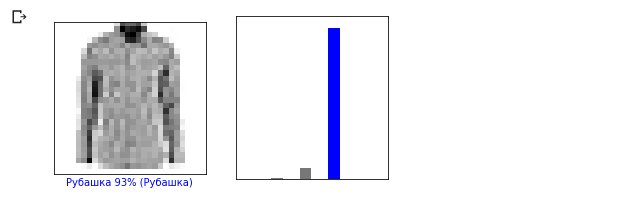
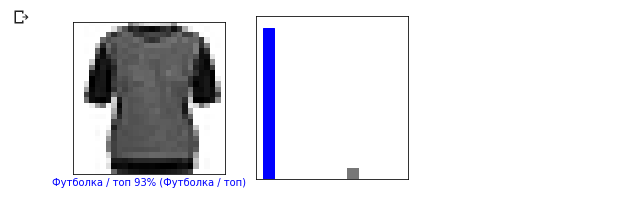
Давайте теперь отобразим несколько изображений с их соответствующими предсказаниями. Корректные предсказания — синие, неверные — красным. Значение под изображением отражает процент уверенности модели в том, что входное изображение соответствует этому классу. Обратите внимание, что результат может быть неверным, даже если значение «уверенности» велико.

Воспользуйтесь обученой моделью, чтобы предсказать метку для единственного изображения:
Вывод:
Модели в
Вывод:
Теперь предскажем результат:
Вывод:
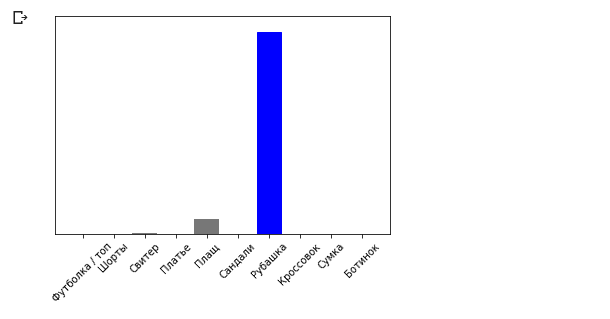
Метод model.predict возвращает список списков (массив массивов), каждый для изображения из блока входных данных. Получим единственный результат для нашего одного входного изображения:
Вывод:
Как и ранее модель предсказала метку 6 (рубашка).
Поэкспериментируйте с различными моделями и посмотрите как будет меняться точность. В частности, попробуйте изменить следующие параметры:
Не забывайте активировать GPU для того, чтобы все вычисления происходили быстрее (
— На данном этапе мы уже столкнулись с двумя типами нейронных сетей. Наша первая нейронная сеть научилась преобразовывать градусы Цельсия в градусы Френгейта, возвращая единственное значение, которое может находиться в широком диапазоне числовых значений.
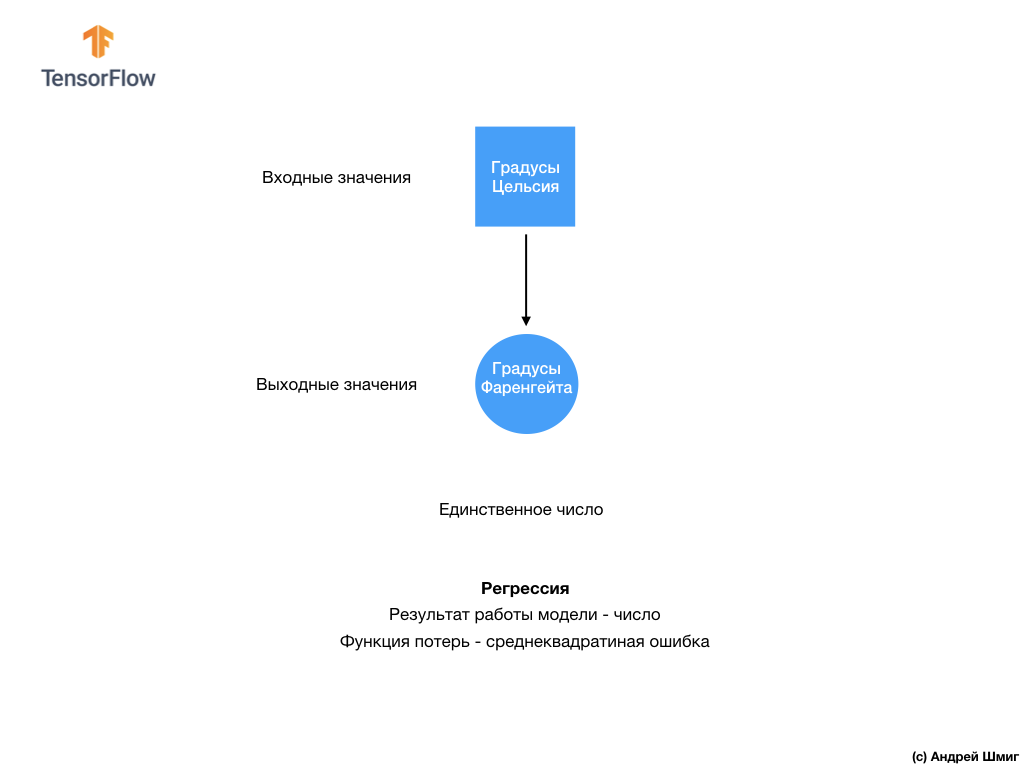
Наша вторая нейронная сеть возвращает 10 значений вероятностей, которые отображают уверенность сети в том, что поданое на вход изображение соответствует определённому классу.
Нейронные сети могут использоваться для решения различного рода задач.
Первый класс задач, который мы решали с предсказанием единственного значения, называется регрессией. Преобразование градусов Цельсия в градусы Фаренгейта это один из примеров задача этого класса. Другим примером данного класса задач может быть задача определения стоимости дома по кличеству комнат, общей площади, местоположению и другим характеристикам.
Второй класс задач, который мы рассмотрели в этом уроке классифицируя изображения по имеющимся категориям, называется классификацией. По входным данным модель вернёт распределение вероятностей («уверенность» модели в том, что входное значение принадлежит данному классу). В этом уроке мы разрабатывали нейронную сеть, которая классифицировала элементы одежды по 10 категориям, а в следующем уроке мы научимся определять, кто изображён на фотографии — собака или кошка, эта задача тоже относится к задаче классификации.
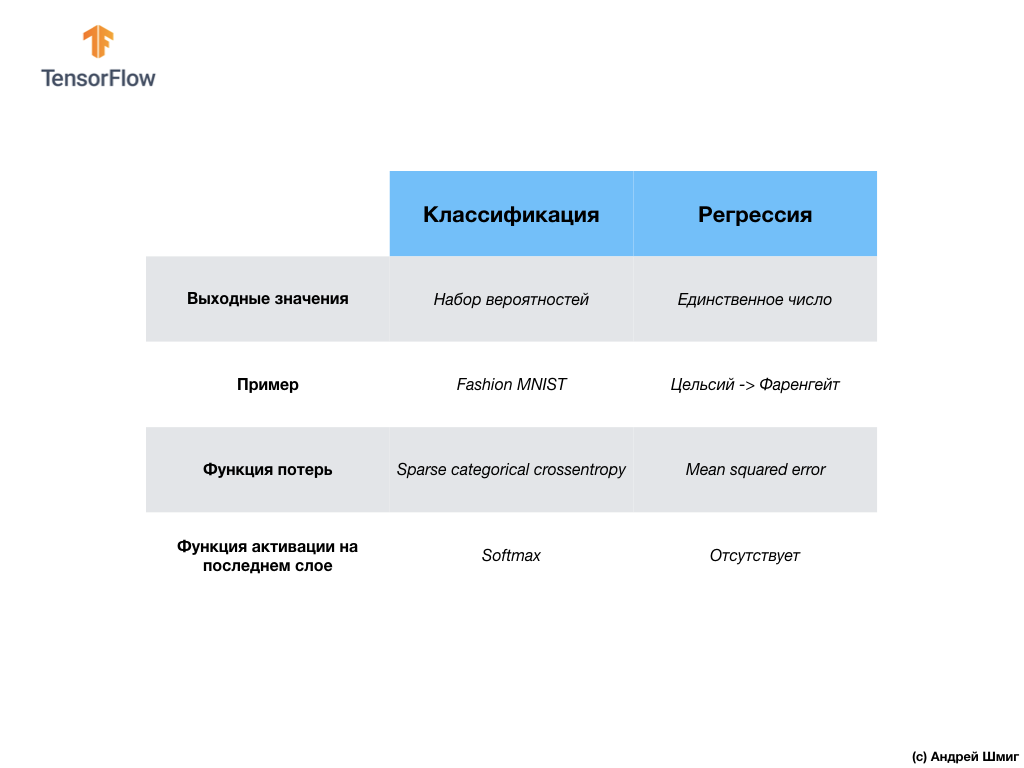
Давайте подведём итоги и отметим разницу между этими двумя классами задач — регрессией и классификацией.
Поздравляю, Вы изучили два типа нейронных сетей! Приготовьтесь к следующей лекции, там мы будем изучать новый тип нейронных сетей — свёрточные нейронные сети (CNN, convolutional neural networks).
На этом занятии мы обучили нейронную сеть классифицировать изображения с элементами одежды. Для этого мы воспользовались набором данных Fashion MNIST, который содержит 70 000 изображений элементов одежды. 60 000 из которых мы использовали для тренировки нейронной сети, а остальные 10 000 для тестирования эффективности её работы. Для того чтобы подать на вход нашей нейронной сети эти изображения нам понадобилось преобразовать их (сгладить) из формата 2D размером 28х28 в формат 1D размером 784 элемента. Наша сеть состояла из полносвязного слоя из 128 нейронов и выходного слоя из 10 нейронов, соответствуя количеству меток (классов, категорий элементов одежды). Эти 10 выходных значений представляли собой распределение вероятностей для каждого класса. Функция активации softmax подсчитывала распределение вероятностей.
Мы так же узнали о различиях между регрессией и классификацией.
… и стандартные call-to-action — подписывайся, ставь плюс и делай share :)
YouTube
Telegram
ВКонтакте
Оригинальный курс на английском доступен по этой ссылке.
Выход новых лекций запланирован каждые 2-3 дня.
Интервью с Себастьяном Труном, CEO Udacity
— Итак, мы снова вместе с вами и с нами по-прежнему Себастьян. Мы как раз хотим обсудить полносвязные слои, те самые Dense-слои. Перед этим мне бы хотелось задать один вопрос. Каковы границы и каковы основные препятствия, которые будут стоять на пути развития глубокого обучения и окажут на него наибольшее влияние в ближайшие 10 лет? Всё меняется настолько быстро! Как вы думаете, что будет той самой следующей «большой вещью» (big thing — прорывом)?
— Я бы назвал две вещи. Первая — общий искусственный интеллект (general AI) для выполнения более чем одной задачи. Это же здорово! Люди могут решать более чем одну задачу и никогда не должны заниматься одним и тем же. Второе — выведение технологии на рынок. Для меня, особенность машинного обучения заключается в том, что оно предоставляет компьютерам возможность наблюдать и находить паттерны в данных, помогая людям становиться лучшими в области — на уровне экспертов! Машинное обучение может быть использовано в юриспруденции, медицине, автономных автомобилях. Разрабатывайте подобные приложения, потому что они могут принести огромное количество денег, но что самое важное в этом всём — у вас есть возможность сделать мир значительно лучше.
— Мне очень нравится то, как всё сказанное вами складывается в единую картину относительно глубокого обучения и его применения — это всего лишь инструмент, который может помочь вам решить определённую задачу.
— Да, именно! Невероятный инструмент, не так ли?
— Да, да, я с вами полностью согласна!
— Почти как человеческий мозг!
— Вы упоминали медицинские приложения в нашем первом интервью, в первой части видео-курса. В каких приложениях, по-вашему мнению, применение глубокого обучения вызывает наибольший восторг и удивление?
— Очень много! Очень! Медицина находится в шорт-листе направлений, которые активно используют глубокое обучение. Я потерял свою сестру несколько месяцев назад, она была больна раком, что очень печально. Я думаю существуют множество заболеваний, которые могли бы быть детектированы ранее — на ранних стадиях, давая возможность от них излечить или замедлить процесс их развития. Идея, по сути, заключается в том, чтобы перенести некоторые инструменты в дом (умный дом), чтобы была возможность детектировать подобного рода отклонения в здоровье задолго до того момента, когда их заметит сам человек. Ещё я бы добавил — всё повторяющееся, любая офисная работа, где вы выполняете однотипные действия снова и снова, например, бухгалтерия. Даже я, как CEO, делаю очень много повторяющихся действий. Было бы здорово автоматизировать их, даже работу с почтовой перепиской!
— Не могу с вами не согласиться! В этом уроке мы познакомим слушателей курса со слоем нейронной сети называемом полносвязным (dense-layer). Могли бы вы рассказать нам подробнее, что вы думаете о полносвязных слоях?
— Итак, начнём с того факта, что каждая сеть может быть связана по-разному. Некоторые из них могут иметь очень плотную связность, которая позволяет получить некоторую выгоду при масштабировании и «выиграть» у больших сетей. Иногда вы не знаете, какое количество связей понадобится, поэтому соединяете всё со всем — это и называется полносвязаным слоем. Добавлю, что у этого подхода куда больше мощи и потенциала, чем у чего-то более структурированного.
— Полностью с вами согласна! Благодарю, что помогли нам узнать немного больше о полносвязных слоях. С нетерпением жду того момента, когда мы наконец-то приступим к их реализации и написанию кода.
— Получайте удовольствие! Будет действительно весело!
Введение
— С возвращением! В прошлом уроке вы разобрались с тем, как построить свою первую нейронную сеть с использованием TensorFlow и Keras, как работают нейронные сети и как устроен процесс тренировки (обучения). В частности, мы увидели каким образом можно обучить модель преобразовывать градусы Цельсия в градусы Фаренгейта.
— Мы так же познакомились с понятием полносвязных слоёв (dense-слои), наиболее важный слой в нейронных сетях. Но в этом уроке мы будем заниматься намного более крутыми вещами! В этом уроке мы разработаем нейронную сеть, которая сможет распознавать элементы одежды и изображения. Как мы уже упоминали ранее, машинное обучение использует входные данные называемые «признаками» (features, свойствами) и выходные данные называемые «метками» (labels) по которым модель учится и находит алгоритм преобразования. Поэтому, во-первых, нам понадобится много примеров, чтобы обучить нейронную сеть распознавать различные элементы одежды. Напомню, что примером для обучения является пара значений — входной признак и выходная метка, которые подаются на вход нейронной сети. В нашем новом примере в качестве входных данных будет изображение, а выходной меткой должна быть категория одежды к которой относится изображенный на картинке элемент одежды. К счастью, такой набор данных уже существует. Он называется Fashion MNIST. Мы рассмотрим подробнее этот набор данных в следующей части.
Набор данных Fashion MNIST
Добро пожаловать в мир набора данных MNIST! Итак, наш набор состоит из изображений размером 28х28, каждый пиксель которого представляет собой оттенок серого.
Набор данных содержит изображения футболок, топов, сандалей и даже ботинок. Вот полный список того, что содержит в себе наш набор данных MNIST:
Каждому входному изображению соответствует одна из перечисленных выше меток. Набор данных Fashion MNIST содержит 70 000 изображений, поэтому нам есть с чего начать и с чем работать. Из этих 70 000 мы воспользуемся 60 000 для тренировки нейронной сети.
А оставшимися 10 000 элементами мы воспользуемся для того, чтобы проверить насколько хорошо наша нейронная сеть обучилась распознавать элементы одежды. Чуть позже мы поясним, почему разделили набор данных на обучающий набор и на набор тестирования.
Итак, вот наш набор данных Fashion MNIST.
Запомните, каждое изображение в наборе данных представляет собой изображение размером 28х28 в оттенках серого, а это значит, что каждое изображение размером 784 байта. Наша задача заключается в том, чтобы создать нейронную сеть, которая на входе получает эти 784 байта, а на выходе возвращает к какой категории одежды из 10 имеющихся поданый на входе элемент относится.
Нейронная сеть
В этом уроке мы будем использовать глубокую нейронную сеть, которая обучится классифицировать изображения из набора данных Fashion MNIST.
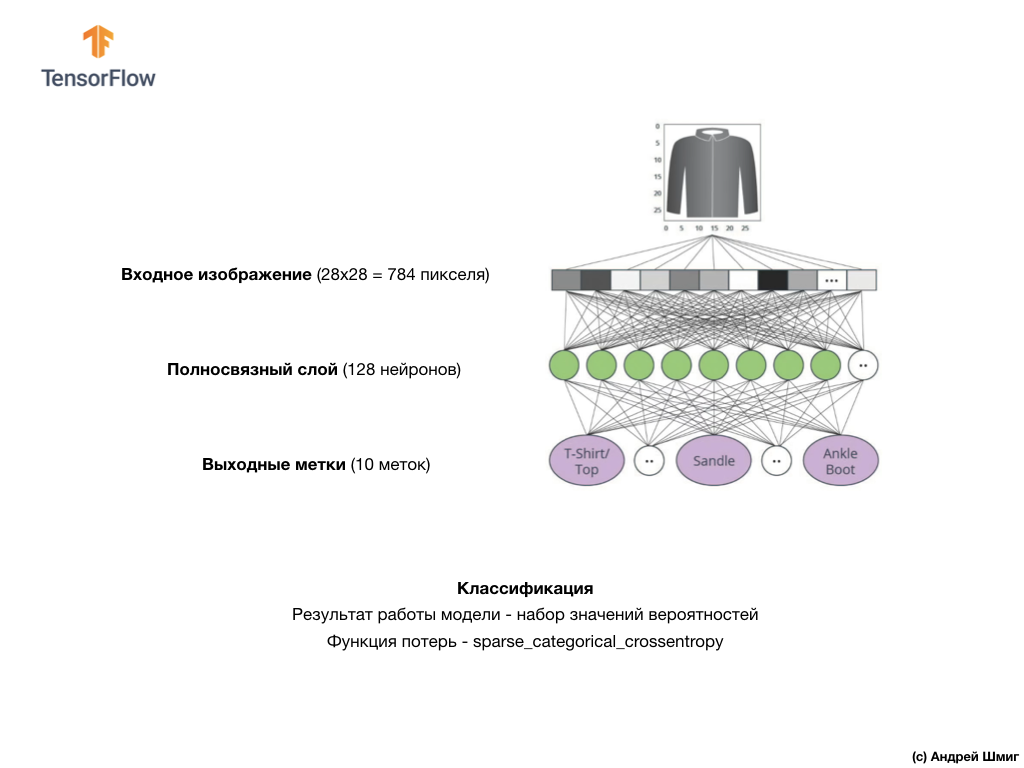
На изображении выше приведено то, как будет выглядеть наша нейронная сеть. Давайте рассмотрим её детальнее.
В качестве входного значения нашей нейронной сети служит одномерный массив длиной 784, массив именно такой длины по той причине, что каждое изображение представляет собой 28х28 пикселей (=784 пикселей всего в изображении), которое мы преобразуем в одномерный массив. Процесс преобразования 2D-изображения в вектор называется сглаживанием (flattening) и реализуется посредством сглаживающего слоя — flatten-слоя.
Выполнить сглаживание можно посредством создания соответствующего слоя:
tf.keras.layers.Flatten(input_shape=[28, 28, 1])
Данный слой преобразует 2D-изображение размером 28х28 пикселей (на каждый пиксель приходится 1 байт для оттенков серого) в 1D-массив состоящий из 784 пикселей.
Входные значения будут полностью связаны с нашим первым
dense-слоем сети, размер которого мы выбрали равным 128 нейронам. Вот как будет выглядеть создание этого слоя в коде:
tf.keras.layers.Dense(128, activation=tf.nn.relu)
Стоп! Что это ещё за
tf.nn.relu? Мы не использовали это в нашем предыдущем примере с нейронной сетью при преобразовании градусов Цельсия в градусы Фаренгейта! Суть в том, что текущая задача значительно сложнее той, которая была в качестве ознакомительного примера — конвертации градусов Цельсия в градусы по Фаренгейту.ReLU — это математическая функция, которую мы добавляем в наш полносвязный слой и которая даёт больше мощи нашей сети. По сути это небольшое расширение для нашего полносвязного слоя, которое позволяет нашей нейронной сети решать более сложные задачи. Мы не будем углубляться в детали, а чуть более подробную информацию вы найдёте ниже. Наконец, наш последний слой, известный так же как выходной слой, состоит из 10 нейронов. Состоит он из 10 нейронов потому, что наш набор данных Fashion MNIST содержит 10 категорий одежды. Каждое из этих 10 выходных значений будет представлять собой вероятность того, что поданое на вход изображение относится к данной категории одежды. Другими словами, эти значения отображают «уверенность» модели в корректности предсказания и соотнесения поданого изображения с определенной из 10 категорий одежды на выходе. Например, какова вероятность того, что на изображении платье, кроссовок, ботинок и т.д.
Например, если на вход нашей нейронной сети будет подано изображение рубашки, то модель может выдать нам результаты вроде тех, которые вы видите на изображении выше — вероятности соответствия входного изображения выходной метке.
Если вы обратите внимание, то заметите, что наибольшая вероятность — 0.85 относится к метке 6, которая соответствует рубашке. Модель на 85% уверена, что на изображении рубашка. Обычно те вещи, которые будут похожи на рубашки, так же будут иметь высокую оценку вероятности, а вещи наименее похожие — наименьшую оценку вероятности.
Так как все 10 выходных значений соответствуют вероятностям, то при суммировании всех этих значений мы получим 1. Эти 10 значений ещё называются распределением вероятностей.
Теперь нам необходим выходной слой для вычисления тех самых вероятностей для каждой метки.
И сделаем мы это с помощью следующей команды:
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
Фактически, когда бы мы не создавали нейронные сети, которые решают задачи классификации, мы всегда используем в качестве последнего слоя нейронной сети полносвязный слой. Последний слой нейронной сети должен содержать количество нейронов равных количеству классов, принадлежность к которым мы определяем и использовать
softmax-функцию активации.ReLU — функция активации нейрона
В этом уроке мы поговорили о
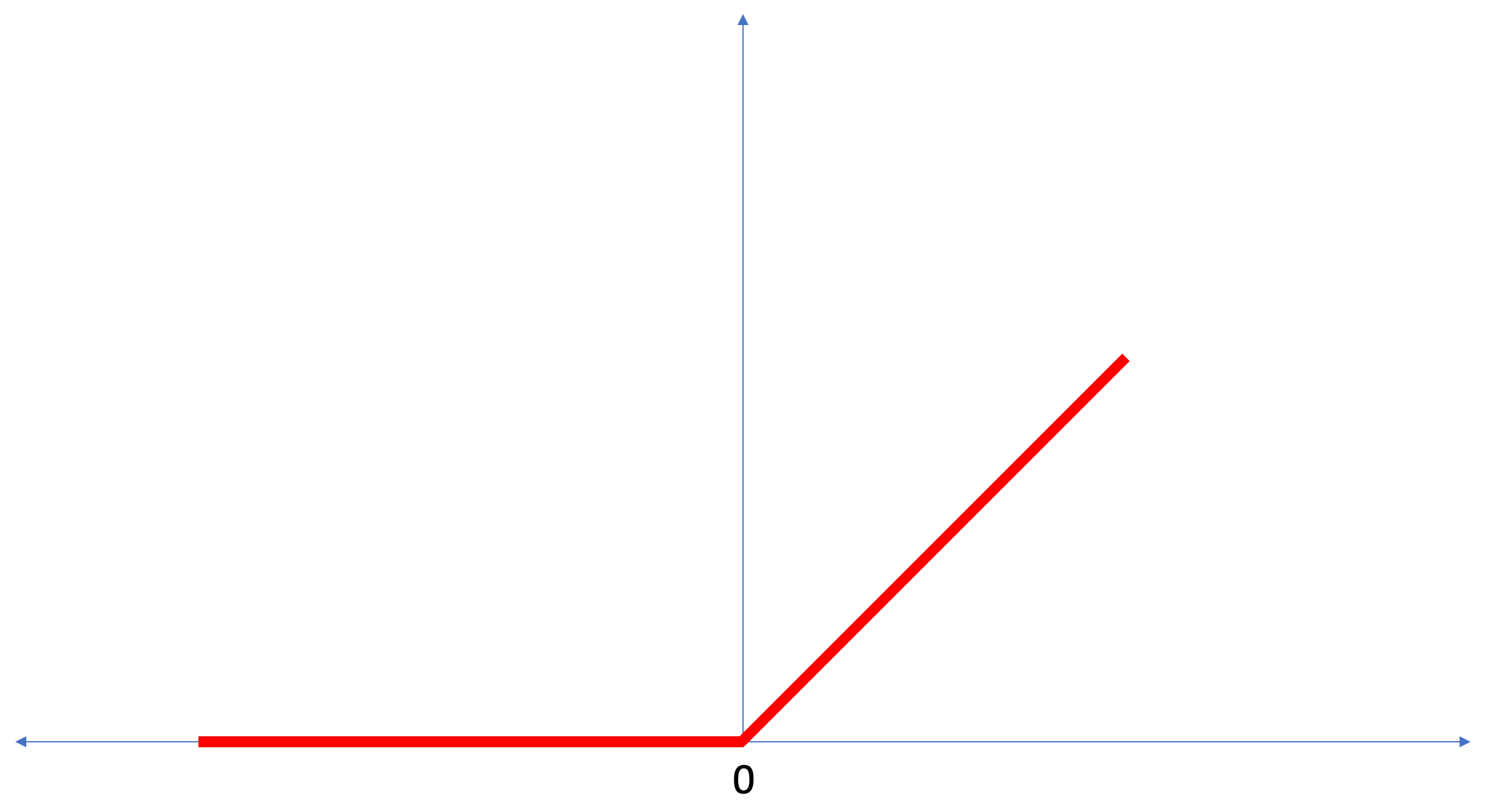
ReLU как о нечто таком, что расширяет возможности нашей нейронной сети и придаёт ей дополнительной мощи.ReLU — это математическая функция, которая выглядит следующим образом:Функция
ReLU возвращает 0, если в качестве входного значения было отрицательное значение или ноль, во всех остальных случаях функция вернёт исходное входное значение.ReLU даёт возможность решать нелинейные задачи.Преобразование градусов Цельсия в градусы Фаренгейта является линейной задачей, потому что выражение
f = 1.8*c + 32 представляет собой уравнение прямой — y = m*x + b. Но большинство задач, которые мы хотим решать являются нелинейными. В таких случаях добавление функции активации ReLU к нашему полносвязному слою может помочь справиться с такого рода задачами.ReLU всего лишь один из видов функций активации. Существуют такие функции активации как сигмоидная, ReLU, ELU, tanh, однако именно ReLU чаще всего используется в качестве функции активации по-умолчанию. Для построения и использования моделей, которые включают ReLU, вам нет необходимости разбираться в том, как она работает внутри. Если вы всё же хотите разобраться лучше, то мы рекомендуем эту статью.Давайте пробежимся по новым терминам, которые были введены в этом уроке:
- Сглаживание — процесс преобразования 2D-изображения в 1D-вектор;
- ReLU — функция активации, которая позволяет модели решать нелинейные задачи;
- Softmax — функция, которая вычисляет вероятности для каждого возможного выходного класса;
- Классификация — класс задач машинного обучения используемый для определения различий между двумя и более категориями (классами).
Обучение и тестирование
Тренируя модель любую модель в машинном обучении всегда необходимо разделять набор данных на, как минимум, два различных набора — набора данных используемого для обучения и набора данных используемого для тестирования. В этой части мы разберёмся почему стоит так поступать.
Давайте вспомним, каким образом мы распределили наш набор данных из Fashion MNIST состоящих из 70 000 экземпляров.
Мы предложили разделить 70 000 на две части — в первой части оставить 60 000 для обучения, а во второй части 10 000 для тестирования. Необходимость такого подхода вызвана следующим фактом: после того как модель была обучена на 60 000 экземплярах необходимо проверить результаты и эффективность её работы на таких примерах, которых ещё не было в наборе данных на которых модель обучалась.
В своём роде это напоминает сдачу экзамена в школе. Перед тем как сдавать экзамен вы усердно занимаетесь решая задачи определённого класса. Затем, на экзамене, сталкиваетесь с таким же классом задач, но другими входными данными. Подавать на вход те же данные, которые были во время тренировки нет смысла, иначе задача сведётся к запоминанию решений, а не поиску модели решения. Именно поэтому на экзаменах вы сталкиваетесь с таким задачами, которых ранее не было в обучающей программе. Только таким образом можно проверить обучилась ли модель общему решению или нет.
То же самое происходит и при машинном обучении. Вы показываете некоторые данные, которые представляют собой определённый класс задач, который вы хотите научиться решать. В нашем случае, с набором данных из Fashion MNIST, мы хотим чтобы нейронная сеть могла определить категорию к которой относится элемент одежды на изображении. Именно поэтому мы тренируем нашу модель на 60 000 примерах, которые содержат все категории элементов одежды. После тренировки мы хотим проверить эффективность модели, поэтому подаём на вход оставшиеся 10 000 элементов одежды, которые модель ещё «не видела». Если бы мы решили этого не делать, не проводить тестирования на 10 000 примерах, то не смоглы бы с уверенностью сказать обучилась ли наша модель на самом деле определять класс элемента одежды или она запомнила все пары входных + выходных значений.
Именно поэтому занимаясь машинным обучением у нас всегда есть набор данных для обучения и набор данных для тестирования.
Набор набор для TensorFlow предоставляет коллекцию готовых к использованию данных для обучения.
Наборы данных обычно разделены на несколько блоков, каждый из которых используется на определенной стадии тренировки и проверки эффективности работы нейронной сети. В этой части мы говори о:
- тренировочный набор данных: набор данных предназначенный для обучения нейронной сети;
- тестовый набор данных: набор данных предназначенный для проверки эффективности работы нейронной сети;
Рассмотрим ещё один набор данных, который я называю проверочным набором (validation dataset). Этот набор данных не используется для тренировки модели, только во время тренировки. Итак, после того как наша модель прошла несколько циклов тренировок, мы подаём ей на вход наш проверочный набор данных и смотрим на результаты. Например, если во время тренировки значение функции потерь уменьшается, а точность ухудшается на проверочном наборе данных, то это значит что наша модель просто напросто запоминает пары входных-выходных значений.
Проверочный набор данных используется повторно в самом конце тренировки для измерения итоговой точности предсказаний модели.
Более подробно о тренировочных и тестовых наборах данных можно прочитать в Google Crash Course.
Практическая часть в CoLab
Ссылка на оригинальный CoLab на английском и ссылка на русский CoLab.
Классификация изображений элементов одежды
В этой части урока мы построим и обучим нейронную сеть классифицировать изображения элементов одежды, такие как платья, кроссовки, рубашки, футболки и т.п.
Всё впорядке, если какие-то моменты будут непонятны. Цель этого курса познакомить вас с TensorFlow и параллельно пояснить алгоритмы его работы и выработать общее понимание проектов использующих TensorFlow, а не углубляться в детали реализции.
В этой части мы используем
tf.keras — высокоуровневый API для построения и тренировки моделей в TensorFlow.Установка и импорт зависимостей
Нам понадобится набор данных TensorFlow, API который упрощает загрузку и доступ к наборам данных предоставленных несколькими сервисами. Так же нам понадобится несколько вспомогательных библиотек.
!pip install -U tensorflow_datasets
from __future__ import absolute_import, division, print_function, unicode_literals
# импортируем TensorFlow и набор данных TensorFlow
import tensorflow as tf
import tensorflow_datasets as tfds
tf.logging.set_verbosity(tf.logging.ERROR)
# вспомогательные библиотеки
import math
import numpy as np
import matplotlib.pyplot as plt
# Улучшим отображение прогрессбара
import tqdm
import tqdm.auto
tqdm.tqdm = tqdm.auto.tqdm
print(tf.__version__)
tf.enable_eager_execution()
Импортируем набор данных Fashion MNIST
В этом примере используется набор данных Fashion MNIST, который содержит 70 000 изображений элементов одежды в 10 категориях в градациях серого. Изображения содержат элементы одежды в низком разрешении (28х28 пикселей), как показано ниже:
Fashion MNIST используется как замена классическому набору данных MNIST — чаще всего используется как «Hello, World!» в машинном обучении и компьютерном зрении. Набор данных MNIST содержит изображения цифр написанных от руки (0, 1, 2 и тд) в таком же формате, каком представлены элементы одежды в нашем примере.
В нашем примере мы используем Fashion MNIST из-за разнообразия и потому, что эта задача более интересна с точки зрения реализации, чем решение типичной задачи на наборе данных MNIST. Оба наборы данных достаточно малы, поэтому используются для проверки корректной работоспособности алгоритма. Отличные наборы данных для старта изучения машинного обучения, тестирования и отладки кода.
Мы воспользуемся 60 000 изображениями для тренировки сети и 10 000 изображениями для проверки точности обучения и классификации изображений. Вы можете напрямую обращаться к набору данных Fashion MNIST через TensorFlow используя API:
dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
Загружая набор данных мы получаем метаданные, обучающий набор данных и тестовый набор данных.
- Модель обучается на наборе данных из `train_dataset`
- Модель тестируется на наборе данных из `test_dataset`
Изображения представляют собой двумерные массивы
28х28, где значения в каждой ячейке могут быть в интервале [0, 255]. Метки — массив целых чисел, где каждое значение в интервале [0, 9]. Эти метки соответствуют выходному классу изображения следующим образом:| Метка | Класс |
|---|---|
| 0 | Футболка / топ |
| 1 | Шорты |
| 2 | Свитер |
| 3 | Платье |
| 4 | Плащ |
| 5 | Сандали |
| 6 | Рубашка |
| 7 | Кроссовок |
| 8 | Сумка |
| 9 | Ботинок |
Каждое изображение относится к одной метке. Так как наименования классов не содержатся в исходном наборе данных, давайте сохраним их для дальнейшего использования, когда будем отрисовывать изображения:
class_names = ['Футболка / топ', "Шорты", "Свитер", "Платье",
"Плащ", "Сандали", "Рубашка", "Кроссовок", "Сумка",
"Ботинок"]
Исследуем данные
Давайте изучим формат и структуру данных представленных в обучающем наборе перед тренировкой модели. Следующий код покажет, что 60 000 изображений находятся в обучающем наборе данных, а 10 000 изображений в тестовом наборе:
num_train_examples = metadata.splits['train'].num_examples
num_test_examples = metadata.splits['test'].num_examples
print('Количество тренировочных экземпляров: {}'.format(num_train_examples))
print('Количество тестовых экземпляров: {}'.format(num_test_examples))
Предобработка данных
Значение каждого пикселя в изображении находится в интервале
[0,255]. Для того, чтобы модель работала корректно эти значения необходимо нормализовать — привести к значениям в интервале [0,1]. Поэтому чуть ниже мы объявляем и реализуем функцию нормализации, а затем применяем её к каждому изображению в тренировочных и тестовых наборах данных.def normalize(images, labels):
images = tf.cast(images, tf.float32)
images /= 255
return images, labels
# метод map применяет функцию нормализации к каждому элементу в массиве
# тестовых и тренировочных наборах данных
train_dataset = train_dataset.map(normalize)
test_dataset = test_dataset.map(normalize)
Изучаем обработанные данные
Давайте отрисуем изображение, чтобы взглянуть на него:
# Берём единственное изображение и удаляем из него цветовую составляющую
# посредством метода reshape()
for image, label in test_dataset.take(1):
break;
image = image.numpy().reshape((28, 28))
# отрисовываем изображение
plt.figure()
plt.imshow(image, cmap=plt.cm.binary)
plt.colorbar()
plt.grid(False)
plt.show()
Отобразим первые 25 изображений из тренировочного набора данных и под каждым изображением укажем к какому классу оно относится.
Убедитесь, что данные в корректном формате и мы готовы приступить к созданию и тренировки сети.
plt.figure(figsize=(10,10))
i = 0
for (image, label) in test_dataset.take(25):
image = image.numpy().reshape((28,28))
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(image, cmap=plt.cm.binary)
plt.xlabel(class_names[label])
i += 1
plt.show()
Строим модель
Построение нейронной сети требует настройки слоёв, а затем сборки модели с функциями оптимизации и потерь.
Настраиваем слои
Базовым элементом при построении нейронной сети является слой. Слой извлекает представление из данных, которые поступили ему на вход. Результатом работы связанных нескольких слоёв мы получаем представление, которое имеет смысл для решения поставленной задачи.
Большую часть времени занимаясь глубоким обучением вы будете заниматься созданием связей между простыми слоями. Большинство слоёв, например, такие как tf.keras.layers.Dense имеют набор параметров, которые могут быть «подогнаны» во время процесса обучения.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
Сеть состоит из трёх слоёв:
- входного
tf.keras.layers.Flatten— этот слой преобразует изображения размером 28х28 пикселей в 1D-массив размером 784 (28 * 28). На этом слое у нас нет никаких параметров для обучения, так как этот слой занимается только преобразованием входных данных. - скрытый слой
tf.keras.layers.Dense— плотносвязный слой из 128 нейронов. Каждый нейрон (узел) принимает на вход все 784 значения с предыдущего слоя, изменяет входные значения согласно внутренним весам и смещениям во время тренировки и возвращает единственное значение на следующий слой. - выходной слой
ts.keras.layers.Dense—softmax-слой состоит из 10 нейронов, каждый из которых представляет определённый класс элемента одежды. Как и в предыдущем слое, каждый нейрон принимает на вход значения всех 128 нейронов предыдущего слоя. Веса и смещения каждого нейрона на этом слое изменяются при обучении таким образом, чтобы результатирующее значение было в интервале[0,1]и представляло собой вероятность того, что изображение относится к этому классу. Сумма всех выходных значений 10 нейронов равна 1.
Компилируем модель
Перед тем как мы приступим к тренировке модели стоит ещё выполнить несколько настроек. Эти настройки производятся во время сборки модели при вызове метода compile:
- функция потерь — алгоритм измерения того, насколько далеко находится желаемое значение от спрогнозированного.
- функция оптимизации — агоритм «подгонки» внутренних параметров (весов и смещений) модели для минимизации функции потерь;
- метрики — используются для мониторинга процесса тренировки и тестирования. Пример ниже использует такую метрику как
точность, процент изображений, которые были корректно классифицированы.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Тренируем модель
Во-первых, определяем последовательность действий при обучении на тренировочном наборе данных:
- Повторяем бесконечное количество раз набор входных данных используя метод
dataset.repeat()(параметрepochs, который описан ниже, определяет количество всех обучающих итераций для выполнения) - Метод
dataset.shuffle(60000)перемешивает все изображения для того, чтобы на обучение нашей модели не влиял порядок подачи входных данных. - Метод
dataset.batch(32)сообщает методу тренировкиmodel.fitиспользовать блоки по 32 изображения и метки при обновлении внутренних переменных модели.
Тренировка происходит посредством вызова метода
model.fit:- Отправляет
train_datasetна вход модели. - Модель учится сопоставлять входное изображение с меткой.
- Параметр
epochs=5ограничивает количество тренировок до 5 полных обучающих итераций по набору данных, что в итоге даёт нам тренировку на 5 * 60000 = 300 000 примерах.
(на параметр
steps_per_epoch можно не обращать внимания, скоро этот параметр будет исключён из метода).BATCH_SIZE = 32
train_dataset = train_dataset.repeat().shuffle(num_train_examples).batch(BATCH_SIZE)
test_dataset = test_dataset.batch(BATCH_SIZE)
model.fit(train_dataset, epochs=5, steps_per_epoch=math.ceil(num_train_examples/BATCH_SIZE))
А вот и вывод:
Epoch 1/5
1875/1875 [==============================] - 26s 14ms/step - loss: 0.4921 - acc: 0.8267
Epoch 2/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3652 - acc: 0.8686
Epoch 3/5
1875/1875 [==============================] - 20s 11ms/step - loss: 0.3341 - acc: 0.8782
Epoch 4/5
1875/1875 [==============================] - 19s 10ms/step - loss: 0.3111 - acc: 0.8858
Epoch 5/5
1875/1875 [==============================] - 16s 8ms/step - loss: 0.2911 - acc: 0.8922
В процессе тренировки модели значение функции потерь и метрика точности отображаются для каждой обучающей итерации. Эта модель достигает точности около 0.88 (88%) на тренировочных данных.
Проверяем точность
Проверим какую точность выдаёт модель на тестовых данных. Воспользуемся всеми примерами, которые у нас есть в тестовом наборе данных для проверки точности.
test_loss, test_accuracy = model.evaluate(test_dataset, steps=math.ceil(num_test_examples/BATCH_SIZE))
print("Точность на тестовом наборе данных: ", test_accuracy)
Вывод:
313/313 [==============================] - 1s 5ms/step - loss: 0.3440 - acc: 0.8793
Точность на тестовом наборе данных: 0.8793
Как вы можете заметить, точность на тестовом наборе данных оказалась меньше точности на тренировочном наборе данных. Это вполне нормально, так как модель была обучена на train_dataset данных. Когда модель обнаруживает изображения, которые она ранее никогда не видела (из набора данных train_dataset), вполне очевидно, что эффективность классификации снизится.
Предсказываем и исследуем
Можем воспользоваться обученной моделью для получения предсказаний по некоторым изображениям.
for test_images, test_labels in test_dataset.take(1):
test_images = test_images.numpy()
test_labels = test_labels.numpy()
predictions = model.predict(test_images)
predictions.shape
Вывод:
(32, 10)
В примере выше модель предсказала метки для каждого тестового входного изображения. Давайте посмотрим на первое предсказание:
predictions[0]
Вывод:
array([3.1365351e-05, 9.0029374e-08, 5.0016739e-03, 6.3597057e-05,
6.8342477e-02, 1.0856857e-08, 9.2655218e-01, 1.8982398e-09,
8.4999456e-06, 1.0296091e-09], dtype=float32)
Напомним, что предсказания модели — это массив из 10 значений. Эти значения описывают «уверенность» модели в том, что входное изображение относится к определённому классу (элементу одежды). Мы можем посмотреть максимальное значение следующим образом:
np.argmax(predictions[0])
Вывод:
6
Это значит, что модель проявила наибольшую уверенность в том, что это изображение относится к классу с меткой 6 (class_names[6]). Можем проверить и убедиться в том, что результат соответствует действительности и он корректен:
test_labels[0]
6
Мы можем отобразить все входные изображения и соответствующие предсказания модели по 10 классам:
def plot_image(i, predictions_array, true_labels, images):
predictions_array, true_label, img = predictions_array[i], true_label[i], images[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img[...,0], cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100 * np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Давайте взглянем на 0-ое изображение, результат предсказания модели и массив предсказаний.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
Давайте теперь отобразим несколько изображений с их соответствующими предсказаниями. Корректные предсказания — синие, неверные — красным. Значение под изображением отражает процент уверенности модели в том, что входное изображение соответствует этому классу. Обратите внимание, что результат может быть неверным, даже если значение «уверенности» велико.
num_rows = 5
num_cols = 3
num_images = num_rows * num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i + 1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i + 2)
plot_value_array(i, predictions, test_labels)
Воспользуйтесь обученой моделью, чтобы предсказать метку для единственного изображения:
img = test_images[0]
print(img.shape)
Вывод:
(28, 28, 1)
Модели в
tf.keras оптимизированы для предсказаний блоками (коллекциями). Поэтому, несмотря на то, что мы используем единственный элемент необходимо его добавить в список:img = np.array([img])
print(img.shape)
Вывод:
(1, 28, 28, 1)Теперь предскажем результат:
predictions_single = model.predict(img)
print(predictions_single)
Вывод:
[[3.1365438e-05 9.0029722e-08 5.0016833e-03 6.3597123e-05 6.8342514e-02
1.0856857e-08 9.2655218e-01 1.8982469e-09 8.4999692e-06 1.0296091e-09]]
plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
Метод model.predict возвращает список списков (массив массивов), каждый для изображения из блока входных данных. Получим единственный результат для нашего одного входного изображения:
np.argmax(predictions_single[0])
Вывод:
6
Как и ранее модель предсказала метку 6 (рубашка).
Упражнения
Поэкспериментируйте с различными моделями и посмотрите как будет меняться точность. В частности, попробуйте изменить следующие параметры:
- установите параметр epochs равным 1;
- измените количество нейронов в скрытом слое, например, от низкого значения 10 до 512 и посмотрите, каким образом будет меняться точность прогноза модели;
- добавьте дополнительные слоя между flatten-слоем (сглаживающим слоем) и конечным dense-слоем, проведите эксперименты с количеством нейронов на этом слое;
- не нормализуйте значения пикселей и посмотрите, что из этого получится.
Не забывайте активировать GPU для того, чтобы все вычисления происходили быстрее (
Runtime -> Change runtime type -> Hardware accelertor -> GPU). Так же, если в процессе работы у вас возникнут проблемы, то попробуйте сбросить глобальные настройки окружения:-
Edit -> Clear all outputs -
Runtime -> Reset all runtimes
Градусы Цельсия VS MNIST
— На данном этапе мы уже столкнулись с двумя типами нейронных сетей. Наша первая нейронная сеть научилась преобразовывать градусы Цельсия в градусы Френгейта, возвращая единственное значение, которое может находиться в широком диапазоне числовых значений.
Наша вторая нейронная сеть возвращает 10 значений вероятностей, которые отображают уверенность сети в том, что поданое на вход изображение соответствует определённому классу.
Нейронные сети могут использоваться для решения различного рода задач.
Первый класс задач, который мы решали с предсказанием единственного значения, называется регрессией. Преобразование градусов Цельсия в градусы Фаренгейта это один из примеров задача этого класса. Другим примером данного класса задач может быть задача определения стоимости дома по кличеству комнат, общей площади, местоположению и другим характеристикам.
Второй класс задач, который мы рассмотрели в этом уроке классифицируя изображения по имеющимся категориям, называется классификацией. По входным данным модель вернёт распределение вероятностей («уверенность» модели в том, что входное значение принадлежит данному классу). В этом уроке мы разрабатывали нейронную сеть, которая классифицировала элементы одежды по 10 категориям, а в следующем уроке мы научимся определять, кто изображён на фотографии — собака или кошка, эта задача тоже относится к задаче классификации.
Давайте подведём итоги и отметим разницу между этими двумя классами задач — регрессией и классификацией.
Поздравляю, Вы изучили два типа нейронных сетей! Приготовьтесь к следующей лекции, там мы будем изучать новый тип нейронных сетей — свёрточные нейронные сети (CNN, convolutional neural networks).
Итоги
На этом занятии мы обучили нейронную сеть классифицировать изображения с элементами одежды. Для этого мы воспользовались набором данных Fashion MNIST, который содержит 70 000 изображений элементов одежды. 60 000 из которых мы использовали для тренировки нейронной сети, а остальные 10 000 для тестирования эффективности её работы. Для того чтобы подать на вход нашей нейронной сети эти изображения нам понадобилось преобразовать их (сгладить) из формата 2D размером 28х28 в формат 1D размером 784 элемента. Наша сеть состояла из полносвязного слоя из 128 нейронов и выходного слоя из 10 нейронов, соответствуя количеству меток (классов, категорий элементов одежды). Эти 10 выходных значений представляли собой распределение вероятностей для каждого класса. Функция активации softmax подсчитывала распределение вероятностей.
Мы так же узнали о различиях между регрессией и классификацией.
- Регрессия: модель, которая возвращает единственное значение, например, стоимость дома.
- Классификация: модель, которая возвращает распределение вероятностей между несколькими категориями. Например, в нашей задаче с Fashion MNIST, выходными значениями были 10 значений вероятностей, каждое из которых было связано с определённым классом (категорией элемента одежды). Напоминаю, что мы воспользовались функцией активации softmax как раз для того, чтобы на последнем слое получить вероятностное распределение.
Видео-версия статьи
Видео выходит через несколько дней после публикации и добавляется к статье.
… и стандартные call-to-action — подписывайся, ставь плюс и делай share :)
YouTube
Telegram
ВКонтакте
Karroplan
Почему в полносвязном слое именно 128 нейронов? Откуда взялось это число?
AndrewShmig Автор
Таких вопросов много будет по ходу курса и ответов конкретных на них не дают. Вся суть — в последнем блоке и выводах. Просто экспериментируйте с количеством нейронов — получите точность выше / ниже, то можно поздравить / огорчиться!
roryorangepants
Это не совсем так. Ширину слоев как и глубину сети в случае обычной полносвязной сетки можно тюнить более эффективно, исходя из bias-variance tradeoff.
AndrewShmig Автор
Интересно, благодарю! Буду обращать на это внимание, если упоминания этой методики будут в курсе.
roryorangepants
На базовом уровне это описывает Ын в специализации deeplearning.ai