
Оригинальный курс на английском доступен по этой ссылке.

Выход новых лекций запланирован каждые 2-3 дня.
Интервью с Себастьяном Труном, CEO Udacity
— И снова всем привет, с вами я, Пейдж и сегодня со мной гость — Себастьян.
— Привет, я Себастьян!
— … человек у которого невероятная карьера, успевшего сделать множество потрясающих вещей! Вы являетесь со-основателем Udacity, вы основали Google X, вы професcор в Стэнфорде. Вы занимались невероятными исследованиями и глубоким обучением на всём протяжении своей карьеры. Что приносило вам наибольшее удовлетворение и в какой из областей вы получали наибольшее вознаграждение за проделанную работу?
— Скажу честно, я очень люблю находиться в Кремниевой долине! Мне нравится находится рядом с людьми, которые значительно умнее меня, и я всегда рассматривал технологии, как инструмент менющий правила игры различными способами — начиная от образования и заканчивая логистикой, здравохранением и т.д. Всё это меняется настолько быстро, и возникает невероятное желание быть участником этих изменений, наблюдать за ними. Ты смотришь на окружающее тебя и понимаешь, что большинство из того, что ты видишь вокруг, не работает так, как это должно — всегда можно изобрести нечто новое!
— Ну что ж, это очень оптимистичный взгляд на технологии! Какой момент на протяжении всей вашей карьеры был самой большой «эврикой»?
— Господи, их было так много! Помню один из дней, когда Ларри Пейдж позвонил мне и предложил создать автопилотируемые автомобили, которые смогли бы проезжать по всем улицам Калифорнии. В то время я считался экспертом, меня к таковым причисляли и, я был тем самым человеком, который сказал «нет, этого нельзя сделать». После этого Ларри убедил меня, что, в принципе, это возможно сделать, стоит только начать и сделать попытку. И мы сделали это! Это был момент, когда я осознал, что даже эксперты ошибаются и говоря «нет» мы на 100% становимся пессимистами. Я думаю мы должны быть более открыты новому.
— Или, например, если вам звонит Ларри Пейдж и говорит, — «Хэй, сделай крутую вещь вроде Google X» и получается нечто достаточно крутое!
— Да, это точно, жаловаться не приходится! Я имею ввиду, что всё это — процесс, который проходит через множество обсуждений на пути к реализации. Мне, действительно, повезло работать и я горжусь этим, в Google X и над другими проектами.
— Потрясающе! Итак, этот курс полностью о работе с TensorFlow. У вас есть опыт использования TensorFlow или может быть вы знакомы (слышали) с ним?
— Да! Я, в буквальном смысле, люблю TensorFlow, конечно! В моей собственной лаборатории мы используем его часто и много, одна из самых значимых работ на основе TensorFlow вышла около двух лет назад. Мы узнали, что iPhone и Android могут быть эффективнее в определении рака кожи, чем лучшие дерматологи в мире. Своё исследование мы опубликовали в Nature и это произвело своего рода переполох в медицине.
— Звучит потрясающе! Значит вы знаете и любите TensorFlow, что само по себе здорово! Вы уже успели поработать с TensorFlow 2.0?
— Нет, к сожалению пока не успел.
— Он будет просто восхитителен! Все студенты этого курса будут работать с этой версией.
— Я завидую им! Обязательно попробую!
— Прекрасно! На нашем курсе очень много студентов, которые в своей жизни ни разу не занимались машинным обучение, от слова «совсем». Для них область может быть нова, возможно для кого-то само программирование будет вновинку. Какой у вас совет для них?
— Я бы пожелал им оставаться открытыми — к новым идеям, методикам, решениям, позициям. Машинное обучение, на самом деле, проще, чем программирование. В процессе программирования вам необходимо учитывать каждый случай в исходных данных, адаптировать под него логику программы и правила. В это самое время, используя TensorFlow и машинное обучение вы, по сути, тренируете компьютер используя примеры, предоставляя компьютеру самому находить правила.
— Это невероятно интересно! Мне не терпится рассказать студентам этого курса немного больше о машинном обучении! Себастьян, благодарю, что нашел время и пришёл сегодня к нам!
— Благодарю! Оставайтесь на связи!
Что такое машинное обучение?
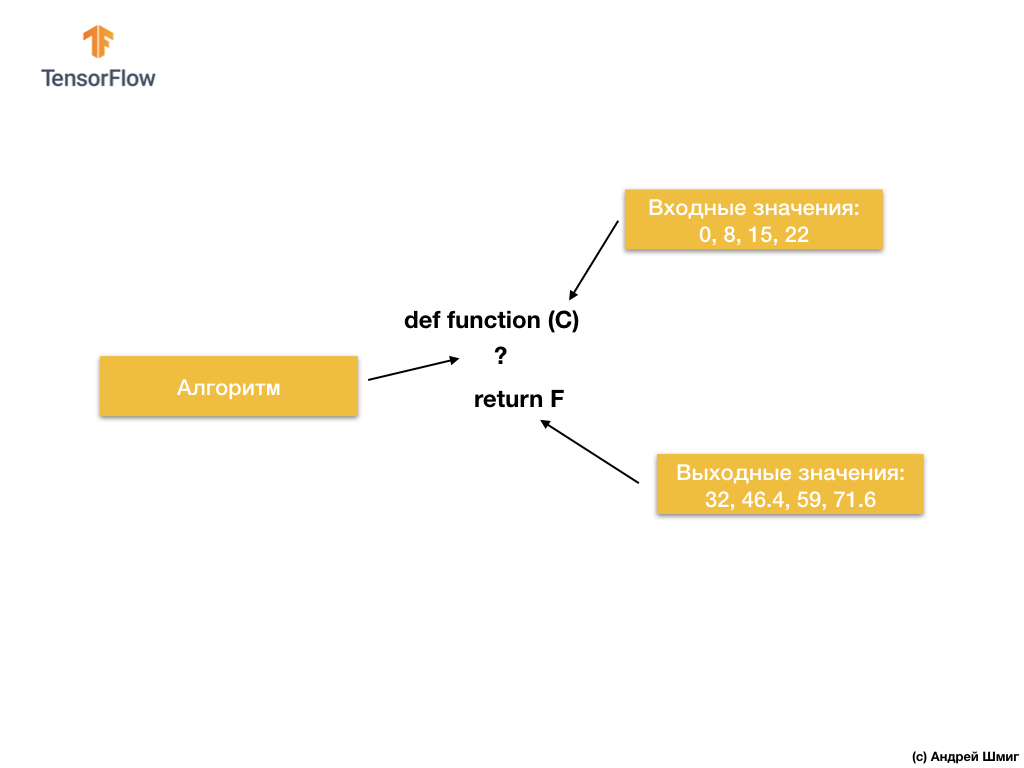
Итак, давайте начнём со следующей задачи — даны входные и выходные значения.

Когда в качестве входного значения у вас значение 0, то в качестве выходного значения — 32. Когда в качестве входного значения у вас 8, то в качестве выходного значения — 46.4. Когда в качестве входного значения у вас 15, то в качестве выходного значения — 59 и так далее.
Присмотритесь к этим значениям и позвольте мне задать вам вопрос. Можете ли вы определить, каким будет выходное значение, если на входе мы получим 38?

Если вы ответили 100.4, то оказались правы!

Итак, как мы могли решить эту задачу? Если присмотреться внимательнее к значениям, то можно заметить, что они связаны выражением:

Где С — градусы Цельсия (входные значения), F — Фаренгейта (выходные значения).
То, что сейчас сделал ваш мозг — сопоставил входные значения и выходные значения и нашел общую модель (связь, зависимость) между ними, — именно это и делает машинное обучение.
По входным и выходным значениям алгоритмы машинного обучения найдут подходящий алгоритм преобразования входных значений в выходные. Это можно представить следующим образом:

Давайте разберём на примере. Представим себе, что мы хотим разработать программу, которая будет преобразовывать градусы Цельсия в градусы Фаренгейта используя формулу
F = C * 1.8 + 32.
Решение, при подходе с точки зрения традиционной разработки программного обеспечения, может быть реализовано на любом языке программирования с использованием функции:

Итак, что мы имеем? Функция принимает входное значение C, затем вычисляет выходное значение F используя явно заданный алгоритм, а затем возвращает вычисленное значение.

С другой стороны, в подходе с машинным обучением, у нас есть только входные и выходные значения, но не сам алгоритм:
Подход с машинным обучением основывается на использовании нейронных сетей для нахождения отношений между входными и выходными значениями.

Вы можете думать о нейронных сетях, как о стопке слоёв, каждый из которых состоит из заранее известной математики (формул) и внутренних переменных. Входное значение поступает в нейронную сеть и проходит сквозь стопку слоёв нейронов. Во время прохождения через слои, входное значение преобразовывается согласно математике (заданным формулам) и значениям внутренних переменных слоёв, производя выходное значение.
Для того, чтобы нейронная сеть смогла обучиться и определить правильные отношения между входными и выходными значениями, нам необходимо её обучить — натренировать.
Мы тренируем нейронную сеть через повторяющиеся попытки сопоставить входные значения выходным.

В процессе тренировки происходит «подгонка» (подбор) значений внутренних переменных в слоях нейронной сети до тех пор, пока сеть не научится генерировать соответствующие выходные значения соответствующим входным значениям.
Как мы увидим в последующем, для того чтобы обучить нейронную сеть и позволить ей подобрать наиболее подходящие значения внутренних переменных, производят тысячи или десятки тысяч итераций (тренировок).

В качестве упрощенного варианта понимания машинного обучения вы можете представить себе алгоритмы машинного обучения как функции, которые подбирают значения внутренних переменных таким образом, чтобы соответствующим входным значениям соответствовали корректные выходные значения.
Существует множество типов архитектур нейронных сетей. Однако, вне зависимости от того, какую архитектуру вы выберете, математика внутри (какие вычисления выполняются и в каком порядке) останется неизменной в процессе тренировки. Вместо изменения математики, меняются внутренние переменные (веса и смещения) во время тренировки.
Например, в задаче конвертации из градусов Цельсия в Фаренгейты, модель начинает с умножения входного значения на некоторое число (вес) и добавления другого значения (смещения). Обучение модели заключается в нахождении подходящих значений для этих переменных, без изменения выполняемых операций умножения и сложения.
А вот одна крутая вещь над которой стоит задуматься! Если вы решили задачу преобразования градусов Цельсия в Фаренгейты, которая обозначена в видео и в тексте ниже, вы, вероятно, решили её потому, что обладали неким предыдущим опытом или знанием, как производить подобного рода преобразования из градусов Цельсия в Фаренгейты. Например, вы могли просто знать, что 0 градусов Цельсия соответствуют 32 градусам по Фаренгейту. С другой стороны, системы основанные на машинном обучении не обладают предыдущими вспомогательными знаниями для решения поставленной задачи. Они учатся решать подобного рода задачи не основываясь на предыдущих знаниях и при их полном отсутствии.
Довольно разговоров — переходим к практической части лекции!
CoLab: преобразуем градусы Цельсия в градусы Фаренгейта
Русская версия CoLab исходного кода и английская версия CoLab исходного кода.
Основы: обучение первой модели
Добро пожаловать в CoLab, где мы будем тренировать нашу первую модель машинного обучения!
Мы постараемся сохранять простоту преподносимого материала и ввести только базовые понятия необходимые для работы. Последующие CoLabs будут содержать более продвинутые техники.
Задача, которую мы будем решать — преобразование градусов Цельсия в градусы Фаренгейта. Формула преобразования выглядит следующим образом:
Безусловно, было бы проще просто написать функцию конвертации на Python или любом другом языке программирования, которая бы выполняла непосредственные вычисления, но в таком случае это не было бы машинным обучением :)
Вместо этого мы подадим на вход TensorFlow имеющиеся у нас входные значения градусов Цельсия (0, 8, 15, 22, 38) и их соответствующие градусы по Фаренгейту (32, 46, 59, 72, 100). Затем мы натренируем модель таким образом, чтобы та примерно соответствовала приведённой выше формуле.
Импорт зависимостей
Первым делом импортируем
TensorFlow. Здесь и в последующем мы сокращённо называем его tf. Мы так же настраиваем уровень логгирования — только ошибки.Далее, импортируем
NumPy как np. Numpy помогает нам представить наши данные в виде высокоэффективных списков.from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
tf.logging.set_verbosity(tf.logging.ERROR)
import numpy as np
Подготовка данных для тренировки
Как мы уже видели ранее, методика машинного обучения с учителем основывается на поиске алгоритма преобразования входных данных в выходные. Так как задачей этого CoLab является создание модели, которая может выдать результат преобразования градусов Цельсия в градусы Фаренгейта, создадим два списка —
celsius_q и fahrenheit_a, которые мы используем при обучении нашей модели.celsius_q = np.array([-40, -10, 0, 8, 15, 22, 38], dtype=float)
fahrenheit_a = np.array([-40, 14, 32, 46, 59, 72, 100], dtype=float)
for i,c in enumerate(celsius_q):
print("{} градусов Цельсия = {} градусов Фаренгейта".format(c, fahrenheit_a[i]))
-40.0 градусов Цельсия = -40.0 градусов Фаренгейта
-10.0 градусов Цельсия = 14.0 градусов Фаренгейта
0.0 градусов Цельсия = 32.0 градусов Фаренгейта
8.0 градусов Цельсия = 46.0 градусов Фаренгейта
15.0 градусов Цельсия = 59.0 градусов Фаренгейта
22.0 градусов Цельсия = 72.0 градусов Фаренгейта
38.0 градусов Цельсия = 100.0 градусов Фаренгейта
Некоторая терминология машинного обучения:
- Свойство — входное(ые) значение нашей модели. В данном случае единичное значение — градусы Цельсия.
- Метки — выходные значения, которые наша модель предсказывает. В данном случае единичное значение — градусы Фаренгейта.
- Пример — пара входных-выходных значений используемых для тренировки. В данном случае это пара значений из
celsius_qиfahrenheit_aпод определённым индексом, например, (22,72).
Создаём модель
Далее мы создаём модель. Мы будем использовать максимально упрощенную модель — модель полносвязной сети (
Dense-сеть). Так как задача достаточно тривиальна, то и сеть будет состоять из единственного слоя с единственным нейроном. Строим сеть
Мы назовём слой
l0 (layer и ноль) и создадим его, инициализировав tf.keras.layers.Dense со следующими параметрами:input_shape=[1]— этот параметр определяет размерность входного параметра — единичное значение. Матрица размером 1?1 с единственным значением. Так как это первый (и единственный) слой, то и размерность входных данных соответствует размерности всей модели. Единственное значение — значение с плавающей запятой, представляющее градусы Цельсия.-
units=1— этот параметр определяет количество нейронов в слое. Количество нейронов определяет то, как много внутренних переменных слоя будет использовано для обучения при поиске решения поставленной задачи. Так как это последний слой, то его размерность равна размерности результата — выходного значения модели — единственного числа с плавающей запятой представляющего собой градусы Фаренгейта. (В многослойной сети размеры и форма слояinput_shapeдолжны соответствовать размерам и формам следующего слоя).
l0 = tf.keras.layers.Dense(units=1, input_shape=[1])
Преобразуем слои в модель
Как только слои определены их необходимо преобразовать в модель.
Sequential-модель принимает в качестве аргументов перечень слоёв в том порядке в котором их необходимо применять — от входного значения до выходного значения.У нашей модели всего один слой —
l0.model = tf.keras.Sequential([l0])
Примечание
Достаточно часто вы будете сталкиваться с определением слоёв прямо в функции модели, нежели с их предварительным описанием и последующим использованием:
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1])
])
Компилируем модель с функцией потерь и оптимизаций
Перед тренировкой модель должна быть скомпилирована (собрана). При компиляции для тренировки необходимы:
- функция потерь — способ измерения того, насколько далеко предсказываемое значение от желаемого выходного значения (измеримая разница называется «потерей»).
- функция оптимизации — способ корректировки внутренних переменных для уменьшения потерь.
model.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(0.1))
Функция потерь и функция оптимизации используются во время тренировки модели (
model.fit(...) упоминаемая ниже) для выполнения первичных вычислений в каждой точке и последующей оптимизации значений.Действие вычисления текущих потерь и последующее улучшение этих значений в модели — это именно то, чем является тренировка (одна итерация).
Во время тренировки, функция оптимизации используется для подсчета корректировок значений внутренних переменных. Цель — подогнать значения внутренних переменных таким образом в модели (а это, по сути, математическая функция), чтобы те отражали максимально приближённо существующее выражение конвертации градусов Цельсия в градусы Фаренгейта.
TensorFlow использует численный анализ для выполнения подобного рода операций оптимизации и вся эта сложность скрыта от наших глаз, поэтому мы не будем вдаваться в детали в этом курсе.
Что полезно знать об этих параметрах:
Функция потерь (среднеквадратичная ошибка) и функция оптимизации (Adam), используемые в этом примере, являются стандартными для подобных простых моделей, но кроме них доступно множество других. На данном этапе нам не важно каким образом работают эти функции.
На что стоит обратить внимание, так это на функцию оптимизации и параметр — коэффициент скорости обучения (
learning rate), который в нашем примере равен 0.1. Это используемый размер шага при корректировке внутренних значений переменных. Если значение слишком маленькое — понадобится слишком много обучающих итераций для обучения модели. Слишком большое — точность падает. Нахождение хорошего значения коэффициента скорости обучения требует некоторых проб и ошибок, оно обычно находится в интервале от 0.01 (по-умолчанию) до 0.1.Тренируем модель
Тренировка модели осуществляется методом
fit.Во время тренировки модель получает на вход значения градусов Цельсия, выполняет преобразования используя значения внутренних переменных (называемые «весами») и возвращает значения, которые должны соответствовать градусами по Фаренгейту. Так как первоначальные значения весов установлены произвольными, то и результатирующие значения будут далеки от корректных значений. Разница между необходимым результатом и фактическим вычисляется с использованием функции потерь, а функция оптимизации определяет каким образом должны быть подкорректированы веса.
Этот цикл вычислений, сравнений и корректировки контролируется внутри метода
fit. Первый аргумент — входные значения, второй аргумент — желаемые выходные значения. Аргумент epochs определяет какое количество раз этот обучающий цикл должен быть выполнен. Аргумент verbose контролирует уровень логгирования.history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Завершили тренировку модели")
В последующих видео мы погрузимся в детали того, каким образом это всё работает и как именно работают полносвязные слои (
Dense-слои) «под капотом».Отображаем статистику тренировок
Метод
fit возвращает объект, который содержит информацию об изменении потерь с каждой последующей итерацией. Мы можем воспользоваться этим объектом для построения соответствующего графика потерь. Высокая потеря означает, что значение градусов Фаренгейта, которые предсказала модель, далеки от истинных значений в массиве fahrenheit_a.Для визуализации воспользуемся
Matplotlib. Как вы можете увидеть, наша модель улучшается очень быстро в самом начале, а затем приходит к стабильному и медленному улучшению до тех пор, пока результаты не становятся «около»-идеальными в самом конце обучения.import matplotlib.pyplot as plt
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.plot(history.history['loss'])

Используем модель для предсказаний
Теперь у нас есть модель, которая была обучена на входных значениях
celsius_q и выходных значениях fahrenheit_a для определения взаимосвязи между ними. Мы можем воспользоваться методом предсказания для вычисления тех значений градусов Фаренгейта по которым ранее нам неизвестны были соответствующие градусы Цельсия.Например, сколько будет 100.0 градусов Цельсия по Фаренгейту? Попробуйте угадать перед тем как запускать код ниже.
print(model.predict([100.0]))
Вывод:
[[211.29639]]
Правильный ответ 100?1.8+32=212, так что наша модель справилась достаточно хорошо!
Ревью
- Мы создали модель с использованием
Dense-слоя - Мы обучили её на 3500 примерах (7 пар значений, 500 обучающих итераций)
Наша модель подогнала значения внутренних переменных (весов) в
Dense-слое таким образом, чтобы возвращать правильные значения градусов Фаренгейта на произвольное входное значение градусов Цельсия. Смотрим на веса
Давайте отобразим значения внутренних переменных
Dense-слоя.print("Это значения переменных слоя: {}".format(l0.get_weights()))
Вывод:
Это значения переменных слоя: [array([[1.8261501]], dtype=float32), array([28.681389], dtype=float32)]
Значение первой переменной близко к ~1.8, а второй к ~32. Эти значения (1.8 и 32) являются непосредственными значениями в формуле конвертации градусов Цельсия в градусы Фаренгейта.
Это действительно очень близко к фактическим значениям в формуле! Мы рассмотрим этот момент подробнее в последующих видео, где мы покажем, каким образом работает
Dense-слой, а пока стоит знать лишь то, что один нейрон с единственным входом и выходом, содержит в себе простую математику — y = mx + b (как уравнение прямой), которая представляет собой не что иное, как нашу с вами формулу преобразования градусов Цельсия в градусы Фаренгейта, f = 1.8c + 32.Так как представления одинаковые, то и значения внутренних переменных модели должны были сойтись к тем, которые представлены в фактической формуле, что и произошло в итоге.
При наличии дополнительных нейронов, дополнительных входных значений и выходных значений, формула становится немного сложнее, но суть остаётся той же.
Немного экспериментов
Ради веселья! Что будет, если мы создадим больше
Dense-слоёв с большим количеством нейронов, которые, в свою очередь, будут содержать больше внутренних переменных?l0 = tf.keras.layers.Dense(units=4, input_shape=[1])
l1 = tf.keras.layers.Dense(units=4)
l2 = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([l0, l1, l2])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
print("Закончили обучение модели")
print(model.predict([100.0]))
print("Модель предсказала, что 100 градусов Цельсия соответствуют {} градусам Фаренгейта".format(model.predict([100.0])))
print("Значения внутренних переменных слоя l0: {}".format(l0.get_weights()))
print("Значения внутренних переменных слоя l1: {}".format(l1.get_weights()))
print("Значения внутренних переменных слоя l2: {}".format(l2.get_weights()))
Вывод:
Закончили обучение модели
[[211.74748]]
Модель предсказала, что 100 градусов Цельсия соответствуют [[211.74748]] градусам Фаренгейта
Значения внутренних переменных слоя l0: [array([[-0.5972079 , -0.05531882, -0.00833384, -0.10636603]],
dtype=float32), array([-3.0981746, -1.8776944, 2.4708805, -2.9092448], dtype=float32)]
Значения внутренних переменных слоя l1: [array([[ 0.09127654, 1.1659832 , -0.61909443, 0.3422218 ],
[-0.7377194 , 0.20082018, -0.47870865, 0.30302727],
[-0.1370897 , -0.0667181 , -0.39285263, -1.1399261 ],
[-0.1576551 , 1.1161333 , -0.15552482, 0.39256814]],
dtype=float32), array([-0.94946504, -2.9903848 , 2.9848468 , -2.9061244 ], dtype=float32)]
Значения внутренних переменных слоя l2: [array([[-0.13567649],
[-1.4634581 ],
[ 0.68370366],
[-1.2069695 ]], dtype=float32), array([2.9170544], dtype=float32)]
Как вы могли уже заметить, текущая модель тоже способна достаточно хорошо предсказывать соответствующие значения градусов Фаренгейта. Однако, если взглянуть на значения внутренних переменных (веса) нейронов по слоям, то никаких значений похожих на 1.8 и 32 мы уже не увидим. Добавленная сложность модели скрывает «простую» форму преобразования градусов Цельсия в градусы Фаренгейта.
Оставайся на связи и в следующей части мы рассмотрим то, каким образом работают Dense-слои «под капотом».
Краткое резюме
Поздравляем! Вы только что обучили свою первую модель. Мы на практике увидели, каким образом по входным и выходным значениям модель научилась умножать входное значение на 1.8 и прибавлять к нему 32 для получения корректного результата.

Это было по-настоящему впечатляюще, учитывая то, сколько строчек кода нам понадобилось написать:
l0 = tf.keras.layers.Dense(units=1, input_shape=[1])
model = tf.keras.Sequential([l0])
model.compile(loss='mean_squared_error', optimizer=tf.keras.optimizers.Adam(0.1))
history = model.fit(celsius_q, fahrenheit_a, epochs=500, verbose=False)
model.predict([100.0])
Приведённый выше пример — общий план для всех программ машинного обучения. Вы будете использовать подобные конструкции для создания и обучения нейронных сетей и для решения последующих задач.
Процесс тренировки
Процесс тренировки (происходящий в методе
model.fit(...)) состоит из весьма простой последовательности действий, результатом которых должны стать значения внутренних переменных дающих максимально близкий к исходному результаты. Процесс оптимизации, благодаря которому достигаются такие результаты, называется градиентным спуском, использует численный анализ для поиска максимально подходящих значений для внутренних переменных модели.Чтобы заниматься машинным обучением вам, в принципе, нет необходимости разбираться в этих деталях. Но для тех, кому всё-таки интересно узнать больше: градиентный спуск посредством итераций изменяет значения параметров по-немногу, «вытягивая» их в нужном направлении, до тех пор пока не будут получены наилучшие результаты. В данном случае «лучшие результаты» (лучшие значения) означают, что любое последующее изменение параметра только ухудшит результат модели. Функция, которая измеряет насколько хороша или плоха модель на каждой итерации называется «функцией потерь», и цель каждого «вытягивания» (корректировки внутренних значений) — уменьшить значение функции потерь.
Процесс тренировки начинается с блока «прямое распространение», при котором входные параметры поступают на вход нейронной сети, следуют к скрытым нейронам и затем идут к выходным. Затем модель применяет внутренние преобразования над входными значениями и внутренними переменными для предсказания ответа.
В нашем примере, входным значением является температура в градусах Цельсия и модель предсказывала соответствующее значение в градусах Фаренгейта.

Как только значение предсказано, происходит вычисление разности между предсказанным значением и корректным. Разница называется «потерей» и является формой измерения того, насколько хорошо модель сработала. Значение потери вычисляется функцией потерь, которую мы определили одним из аргументов при вызове метода
model.compile(...).После вычисления значения потери, внутренние переменные (веса и смещения) всех слоёв нейронной сети подвергаются корректировке для минимизации значения потери с целью приближения выходного значения к корректному исходному эталонному значению.

Этот процесс оптимизации носит название градиентного спуска. Конкретный алгоритм оптимизации используется для вычисления нового значения для каждой внутренней переменной при вызове метода
model.compile(...). В приведённом выше примере мы использовали алгоритм оптимизации Adam.Для этого курса не является обязательным понимание принципов работы процесса тренировки, однако, если вы достаточно любопытны, то можете найти больше информации в Google Crash Course (перевод и практическая часть всего курса заложены у автора в планах к публикации).
К этому моменты вы уже должны быть знакомы со следующими терминами:
- Свойство: входное значение нашей модели;
- Примеры: пары входное+выходное значений;
- Метки: выходные значения модели;
- Слои: коллекция узлов объединенных вместе в рамках нейронной сети;
- Модель: представление вашей нейронной сети;
- Плотный и полностью связный: каждый узел в одном слое связан с каждым узлом из предыдущего слоя.
- Веса и смещения: внутренние переменные модели;
- Потери: разница между желаемым выходным значением и фактическим выходным значением модели;
- MSE: среднеквадратичное отклонение, тип функции потерь, которые считают малое количество больших ошибок вариантом хуже, чем большое количество малых.
- Градиентный спуск: алгоритм, который изменяет внутренние переменные по-немногу при каждой итерации с целью уменьшения значения функции потерь;
- Оптимизатор: конкретная реализация алгоритма градиентного спуска;
- Коэффициент скорости обучения: размер «шага» при снижении потерь во время градиентного спуска;
- Серия: набор данных для обучения нейронной сети;
- Эпоха: полный проход по всей серии исходных данных;
- Прямое распространение: вычисление выходных значение по входным значениям;
- Обратное распространение: вычисление значений внутренних переменных согласно алгоритму оптимизации, начинающегося с выходного слоя и по направлению к входному слою через все промежуточные слои.
Dense-слои
В предыдущей части мы создали модель, которая конвертирует градусы Цельсия в градусы Фаренгейта, используя простую нейронную сеть для нахождения зависимости между градусами Цельсия и градусами Фаренгейта.
Наша сеть состоит из единственного полносвязного слоя. Но что такое полносвязный слой? Чтобы в этом разобраться давайте создадим более сложную нейронную сеть у которой 3 входных параметра, один скрытый слой с двумя нейронами и один выходной слой с единственным нейроном.

Напомним, что нейронную сеть можно представить себе как набор слоёв, каждый из которых состоит из узлов, называемых нейронами. Нейроны на каждом уровне могут быть соединены с нейронами каждого последующего слоя. Тип слоёв, в котором каждый нейрон одного слоя соединён с каждым другим нейроном следующего слоя, называется полностью связным (полносвязным) или плотным слоем (
Dense-слой).
Таким образом, когда мы используем полносвязные слои в
keras, мы как бы сообщаем, что нейроны этого слоя должны быть связаны со всеми нейронами предыдущего слоя.Чтобы создать приведенную выше нейронную сеть нам достаточно следующих выражений:
hidden = tf.keras.layers.Dense(units=2, input_shape=[3])
output = tf.keras.layers.Dense(units=1)
model = tf.keras.Sequential([hidden, output])
Итак, мы разобрались с тем, что такое нейроны и как они связаны между собой. Но как на самом деле работают полносвязные слои?
Чтобы понять, что же на самом деле там происходит и что они делают, нам понадобится заглянуть «под капот» и разобрать внутреннюю математику нейронов.

Представим, что наша модель принимает на вход три параметра —
х1, х2, х3, а а1, а2 и а3 — нейроны нашей сети. Помните мы говорили, что у нейрона есть внутренние переменные? Так вот, w* и b* являются теми самыми внутренними переменными нейрона, так же известными как веса и смещения. Именно значения этих переменных подвергаются корректировке в процессе обучения для получения максимально точных результатов сопоставления входных значений выходным.
Что обязательно стоит иметь ввиду — внутренняя математика нейрона остаётся неизменной. Другими словами, в процессе тренировки меняются только веса и смещения.
Когда начинаешь изучать машинное обучение это может показаться странным — тот факт, что это действительно работает, но именно так работает машинное обучение!
Давайте теперь вернёмся к нашему примеру конвертации градусов Цельсия в градусы Фаренгейта.

С единственным нейроном у нас есть только один вес и одно смещение. Знаете что? Это именно то, как выглядит формула конвертации градусов Цельсия в градусы Фаренгейта. Если мы подставим под
w11 значение 1.8, а вместо b1 — 32, то получим конечную модель преобразования!Если мы вернёмся к результатам работы нашей модели из практической части, то обратим внимание на то, что показатели веса и смещения были «откалиброваны» таким образом, что примерно соответствуют значениям из формулы.
Мы целенаправленно создали именно такой практический пример, чтобы наглядно показать точное сопоставление между весами и смещениями. Применяя машинное обучение на практике, мы никогда не сможем подобным образом сопоставить значения переменных с целевым алгоритмом, как в приведённом выше примере. Как мы сможем это сделать? Никак, потому что мы даже не знаем целевого алгоритма!
Решая задачи машинного обучения мы тестируем различные архитектуры нейронных сетей с различным количеством нейронов в них — методом проб и ошибок находим наиболее точные архитектуры и модели и надеемся, что они решат поставленную задачу в процессе обучения. В следующей практической части мы сможем изучить конкретные примеры такого подхода.
Оставайтесь на связи, потому что сейчас начнётся самое интересное!
Итоги
В этом уроке мы научились базовым подходам в машинном обучении и узнали как работают полносвязные слои (
Dense-слои). Вы обучили свою первую модель преобразовывать градусы Цельсия в градусы Фаренгейта. Вы так же изучили основные термины используемые в машинном обучении, такие как свойства, примеры, метки. Вы, ко всему прочему, написали основные строчки кода на Python, которые являются костяком любого алгоритма машинного обучения. Вы увидели, что в несколько строчек кода можно создать, обучить и запросить предсказание у нейронной сети с использованием TensorFlow и Keras.… и стандартные call-to-action — подписывайся, ставь плюс и делай share :)
YouTube: https://youtube.com/channel/ashmig
Telegram: https://t.me/ashmig
ВКонтакте: https://vk.com/ashmig
Комментарии (25)

vvm13
28.05.2019 08:32Когда в качестве входного значения у вас значение 0, то в качестве выходного значения — 32. Когда в качестве входного значения у вас 8, то в качестве выходного значения — 46.4. Когда в качестве входного значения у вас 15, то в качестве выходного значения — 59 и так далее.
Присмотритесь к этим значениям и позвольте мне задать вам вопрос. Можете ли вы определить, каким будет выходное значение, если на входе мы получим 38?
Если вы ответили 100.4, то оказались правы!
Или нет.
Итак, как мы могли решить эту задачу?
Ха-ха-ха. Никак.

qvan
28.05.2019 08:32
оффтоп, а зачем в подборе весов машинное обучение? есть матаппарат для этого, при этом эксель в данном случае выбирает линейную модель, даже если ставишь полином, и не требует 500 итераций на расчет.Tim06ka
28.05.2019 09:31Затем, что это обучение, и приведенная модель хотя бы интерпретируемая, что облегчает понимание.
Можно сразу картинки в какой-нибудь GloVe засовывать и получать лейблы: собака, дом, автомобиль, но это сложнее объяснить.
roryorangepants
28.05.2019 10:04Затем, что это обучение, и приведенная модель хотя бы интерпретируемая, что облегчает понимание.
Линейная модель, разумеется, тоже интерпретируемая.
Можно сразу картинки в какой-нибудь GloVe засовывать и получать лейблы: собака, дом, автомобиль, но это сложнее объяснить.
Может, вы про какой-то другой GloVe, но тот, который я знаю, относится к NLP, а не к computer vision.
x67
29.05.2019 14:03Это простой пример обучения. Кстати, примерно тоже самое будет, если заставить человека переводить г. Цельсия в Фаренгейты, со временем он будет делать это интуитивно и с высокой точностью (не проводите таких экспериментов над детьми!)
А область эффективного применения МЛ и ДЛ совершенно другая. И не стоит использовать эти штуки там, где можно аналитическими методами построить модель или аппроксимировать по имеющимся данным и опытом в предметной области.

IvanGo82
28.05.2019 09:57В каждой статье про нейронные сети одно и то же
Пришлось самому разбираться
В итоге пришёл к выводу что промежуточные слои совсем не нужны
Переход от одного слоя к другому можно описать перемножением входного вектора (размерность N) на матрицу коэффицентов (размерность NxM) в итоге получим вектор выходного слоя (размерность M) => IN x M1 x ....x Mk = OUT
пользуясь ассоциативность матриц IN x (M1 x ....x Mk) = OUT, где обозначим M = M1 x ....x Mk, получим IN x M = OUT
Вообще если упростить НС служит для подбора коэффицентов апроксимирующей функции, ну или как то такroryorangepants
28.05.2019 10:05+1В итоге пришёл к выводу что промежуточные слои совсем не нужны
Боюсь, это «революционный» вывод работает ровно до тех пор, пока у скрытых слоев стоит линейная активация.
Нелинейность уже не позволяет «схлопнуть» слои.IvanGo82
28.05.2019 10:17Недавно где то читал что от этой активации отказались
и как по мне правильно сделали
ибо ни кто не может толком объяснить смысла этой активации
есть мнение что это из за аппоратного устройства первых нейронов
Вообще если взять ручку с бумагой думаю можно будет придти к формулам что то типа
f (IN x M) = OUT или IN x f(M) = OUT
где f зависит от ф-ии активации, слоёв и тдroryorangepants
28.05.2019 10:21Недавно где то читал что от этой активации отказались
От какой? От линейной? Разумеется, десятилетия назад. Причем именно по той причине, которую вы описали.
Сейчас скрытые слои везде идут с нелинейностями семейства ReLU или сигмоид.IvanGo82
28.05.2019 10:49Смысл то их какой?

iovodov
28.05.2019 13:11+2Чтобы (ха-ха!) вся многослойность не сводилась и к перемножению 2 матриц, а получалась сильно нелинейная функция. Есть теорема, что при достаточном количестве нейронов и слоев нейросеть может сколь угодно точно приблизить любую непрерывную функцию. Если убрать нелинейности, то приблизить можно будет только линейную. Ну, там F в С пересчитать. А люди хотят распознавать котиков на фото.
IvanGo82
28.05.2019 15:19Слышал про эту теорему, но не разу не натыкался
Если убрать нелинейности, то приблизить можно будет только линейную
вовсе нет, достаточно передавать не линейные параметры
скажем не Х, а Х2
как используя не линейную активацию получить на выходе значение зависящее от Х2 или sin(X)?
например чтоб НС определила дальность полёта снаряда от угла наклона пушки?
Используйте вы трижды хитрую активацию, если на вход будете подавать только угол наклона, то на выходе будете получать линейную зависимостьIvanGo82
28.05.2019 15:25Хотя если ещё раз подумать возможно и нет
но это колосальные вычисления по сравнению с перемножением матриц
Вообще желательно любое утверждение подтверждать каким нибудь простеньким примером, а то у большенства адептов ИИ, что не спроси на всё один ответ
Нейронная сеть это чёрный ящик и вообще какая то магияroryorangepants
28.05.2019 15:43Вообще желательно любое утверждение подтверждать каким нибудь простеньким примером
Весь computer vision вам в пример.
Если хочется чего-то более простого и наглядного, можно сгенерировать какие-нибудь простые не разделимые линейно датасеты и сравнить сети с линейными активациями и с нелинейными (например, что-то похожее легко сделать здесь: playground.tensorflow.org ).
то у большенства адептов ИИ, что не спроси на всё один ответ Нейронная сеть это чёрный ящик и вообще какая то магия
Чаще всего люди, разбирающиеся в машинном обучении, не называют это термином «искусственный интеллект».
как используя не линейную активацию получить на выходе значение зависящее от Х2 или sin(X)?
аппроксимация

вовсе нет, достаточно передавать не линейные параметры
скажем не Х, а Х2
Это ручной feature engineering, тогда как глубокая сеть с нелинейными активациями нужные признаки в теории выучивает сама.

atercygnus
28.05.2019 13:11Смысл их в том, что
- они не позволяют функции активации нейрона неограниченно расти.
- это позволяет строить нелинейные разделяющие поверхности в пространстве признаков.
По факту, без них у вас не получится решить сколько-нибудь сложную задачу, например, классификатор изображений на кошек и собак.
Digan
28.05.2019 15:20+1Насколько корретно переводить Feature, как Свойство?
Чаще всего я встречал перевод Feature как Признак.
AndrewShmig Автор
28.05.2019 17:02Решил глянуть англоязычную часть по этому поводу и проверить, правильно ли я перенёс доносимую суть.
По результатам:
- считают термин feature эквивалентным термину measurable property;
- признак = свойство объекта или характеристика явления.
Думаю, что в данном случае слово признак является устоявшимся, а термины могут быть взаимозаменяемы.

st0ne_c0ld
28.05.2019 23:57**offtop для тех кто будет пытаться поставить tensorflow и jupyter в cygwin(надеюсь кому-то сэкономит пару часов жизни): ставите python в windows, делайте там virtualenv, потом переключаетесь в cygwin и там «source Scripts/activate». После чего всё нормально ставится через pip и оттуда же запускается.
oktonion
29.05.2019 09:01+1А где можно что-то такое же внятное почитать, но не про сеть в один Dense слой, а про то как выбирать слои под данные (по каким критериям) и как правильно готовить сами данные?
Потому что все туториалы говорят "возьмите этот слой, добавьте такую функцию активации и ещё вот этот слой, возьмите вот тот датасет подготовленный на 100500 картинок — и вот вам 95% точности распознавания". А почему именно эти слои, почему такая последовательность, как данные подготовили и т.д. все опускают.
Plesser
29.05.2019 09:52+1Видимо будет дальше. Пока идет рассказ об инструментах которые Вам доступны и о принципах их работы.
AndrewShmig Автор
29.05.2019 10:19C учетом того, сколько у меня курсов есть полезных в закладках для публикации и переводов — будет в последующих «сериях». Подписывайтесь, отслеживайте. Если есть пожелания по курсам — напишите в личку, добавлю себе в план.
Материалы перерабатываю полностью, поэтому времени занимает прилично, но зато, надеюсь, качество подачи и понимания темы повышается.oktonion
29.05.2019 12:07Я был бы очень признателен и ссылкам на английские источники по теме моего вопроса, если такие имеются.
decomeron
Спасибо большое за курс на русском языке