
Полный курс на русском языке можно найти по этой ссылке.
Оригинальный курс на английском доступен по этой ссылке.

Содержание
- Интервью с Себастьяном Труном
- Введение
- Передача модели обучения (transfer learning)
- MobileNet
- CoLab: Кошки Vs Собаки с передачей обучения
- Погружаемся в свёрточные нейронные сети
- Практическая часть: определение цветов с передачей обучения
- Итоги
Интервью с Себастьяном Труном
— Это 6 урок и он полностью посвящён передаче обучения (transfer learning). Передача обучения это процесс использования существующей модели с небольшими доработками для новых задач. Передача обучения помогает сократить время обучения модели давая некоторый прирост эффективности при обучении в самом начале. Себастьян, а что же вы думаете про передачу обучения? Удавалось ли вам когда-либо использовать методику передачи обучения в своих работах и исследованиях?
— Моя диссертация была посвящена как раз теме передачи обучения и называлась "Пояснение на основе передачи обучения". Когда мы работали над диссертацией идея заключалась в том, что можно на одном объекте (наборе данных, сущности) в различных вариациях и форматах обучить различать все остальные объекты подобного рода. В работе мы использовали разработанный алгоритм, который выделял основные характеристики (признаки) объекта и мог их сравнить с другим объектом. Сейчас такие библиотеки как Tensorflow уже поставляются с заранее обученными моделями.
— Да, в Tensorflow у нас полный набор готов предобученных моделей, которые вы можете использовать при решения практических задач. О готовых наборах мы поговорим немного позже.
— Да-да! Если подумать, то люди занимаются передачей обучения всё время на протяжении всей жизни.
— Можем ли мы утверждать, что благодаря методике пердачи обучения наши новые студенты в какой-то момент не должны будут знать что-то о машинном обучение потому что будет достаточно подключить уже готовую модель и использовать её?
— Программирование — это написание строчки за строчкой, мы даём команды компьютеру. Наша цель сделать так, чтобы все на планеты умели и могли программировать предоставляя компьютеру только примеры входных данных. Согласитесь, если вы хотите научить компьютер отличать кошек от собак, то найти 100к различных изображений кошек и 100к различных изображений собак достаточно затруднительно, а благодаря методике передачи обучения вы можете решить эту задачу в несколько строк.
— Да, это действительно так! Благодарю за ответы и давайте наконец-то перейдём к обучению.
Введение
— Привет и с возвращением!
— В прошлый раз мы с вами обучили свёрточную нейронную сеть классифицировать кошек и собак на изображении. Первая наша нейронная сеть переобучалась, поэтому её результат был не столь высок — примерно 70% точности. После этого мы с вами реализовали расширение данных и dropout (произвольное отключение нейронов), которые позволили увеличить точность предсказаний до 80%.
— Несмотря на то, что 80% могут показаться отличным показателем, 20%-ая ошибка всё ещё слишком велика. Не так ли? Что же мы можем сделать, чтобы увеличить точность классификации? На этом занятии при воспользуемся техникой передачи знаний (передача модели знаний), которая позволит воспользоваться моделью разработанной экспертами и натренированной на огромных массивах данных. Как мы увидим на практике, с помощью передачи модели знаний мы сможем добиться 95% точности классификации. Давайте приступим!
Передача модели обучения
В 2012 году нейронная сеть AlexNet произвела переворот в мире машинного обучения и популяризовала использование свёрточных нейронных сетей для классификации выиграв соревнование ImageNet Large Scale Visual recognition challenge.
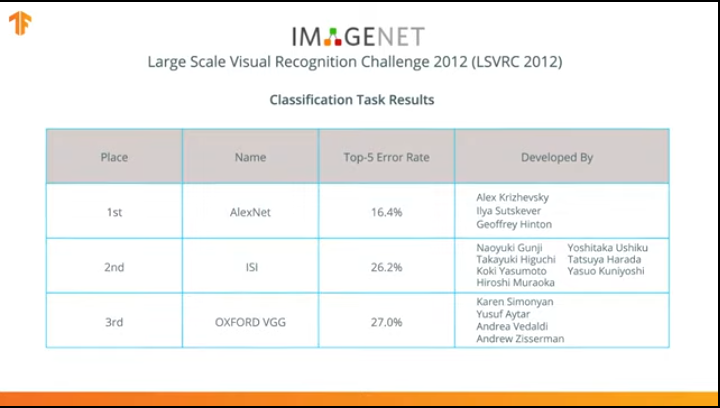
После этого началась борьба за разработку более точных и эффективных нейронных сетей, которые могли бы превзойти AlexNet в задачах классификации изображений из набора данных ImageNet.
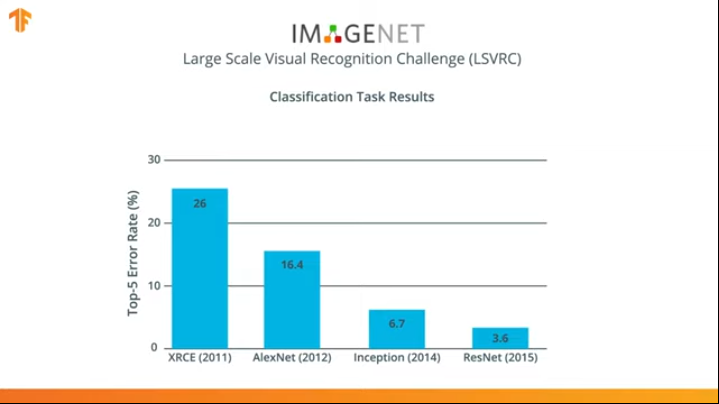
В течение нескольких лет были разработаны нейронные сети, которые справлялись с задачей классификации лучше, чем AlexNet — Inception и ResNet.
Согласитесь, что было бы здорово иметь возможность воспользоваться этими нейронными сетями, уже обученными на огромных массивах данных из ImageNet и использовать их в своём классификаторе кошек и собак?
Оказывается, что мы можем это сделать! Методика называется transfer learning (передача модели обучения). Основная идея метода передачи модели обучения основывается на том, что обучив нейронную сеть на большом наборе данных мы можем применить полученную модели и к набору данных, который раньше эта модель ещё не встречала. Именно поэтому методика называется transfer learning — передача процесса обучения с одного набора данных на другой.
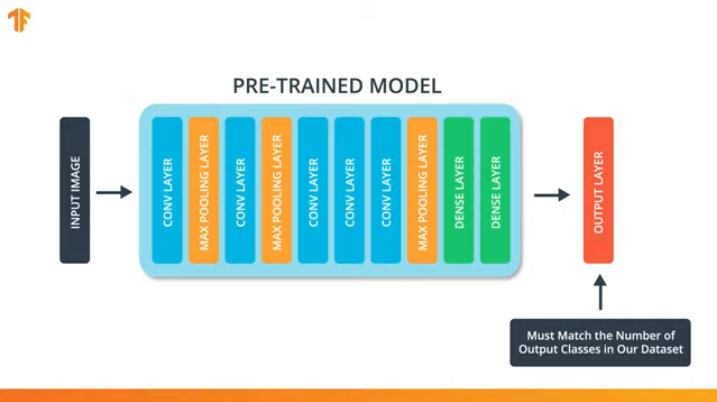
Для того, чтобы мы могли применить методику передачи модели обучения нам понадобится изменить последний слой нашей свёрточной нейронной сети:
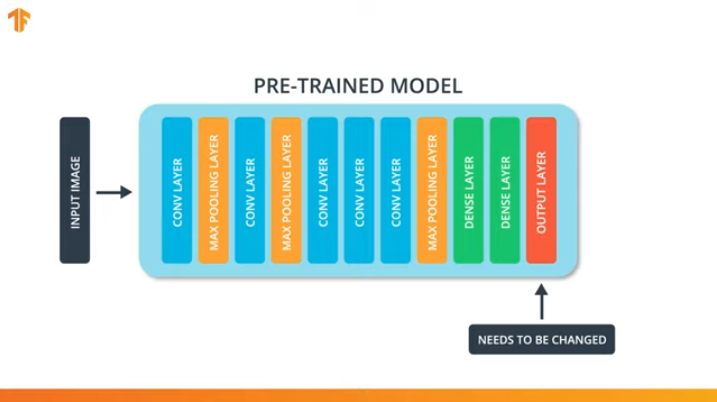
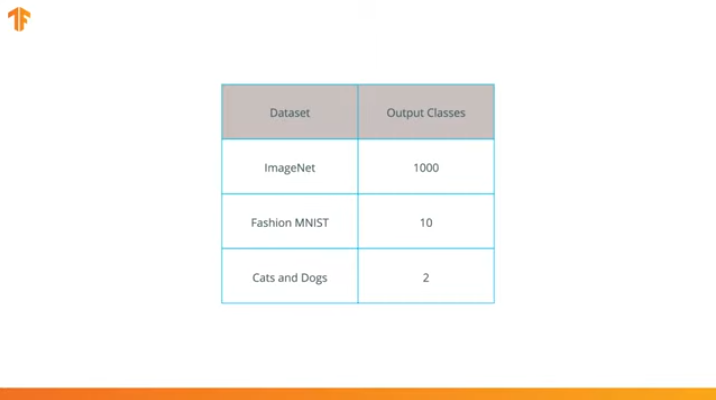
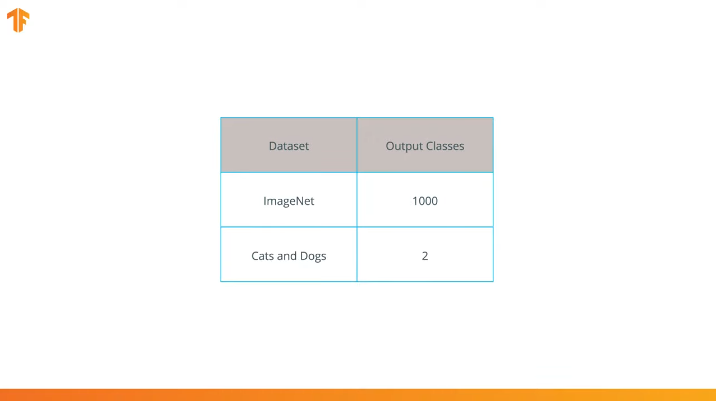
Мы выполняем эту операцию потому, что каждый набор данных состоит из различного количества выходных классов. Например, наборы данных в ImageNet содержат 1000 различных выходных классов. FashionMNIST содержит 10 классов. Наш набор данных для классификации состоит лишь из 2 классов — кошки и собаки.
Именно поэтому необходимо изменить последний слой нашей свёрточной нейронной сети, чтобы он содержал то количество выходов, которое бы соответствовало количеству классов в новом наборе.
Так же нам необходимо убедиться, что мы не изменим заранее обученную модель во время процесса тренировки. Решение заключается в отключении переменных предобученной модели — мы просто запретим алгоритму обновляющему значения при прямом и обратно распространении их менять.
Этот процесс называется "заморозкой модели" (freezing the model).
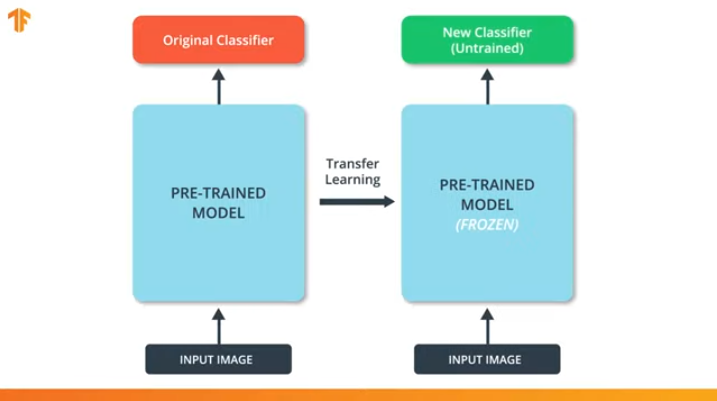
"Замораживая" параметры предобученной модели мы позволяем обучаться только последнему слою сети классификации, значения переменных предобученной остаются неизменными.
Ещё одно неоспоримое преимущество предобученных моделей заключается в том, что мы сокращаем время обучения тренируя только последний слой со значительно меньшим количеством переменных, а не всю модель.
Если мы не "заморозим" переменные предобученной модели, то в процессе обучения на новом наборе данных значения переменных будут меняться. Это происходит потому, что значения переменных на последнем слое классификации будут заполненны случайными значениями. Из-за случайных значений на последнем слое наша модель будет допускать большие ошибки в классификации, что, в свою очередь, повлечёт сильные изменения исходных весов в предобученной модели, что крайне нежелательно для нас.
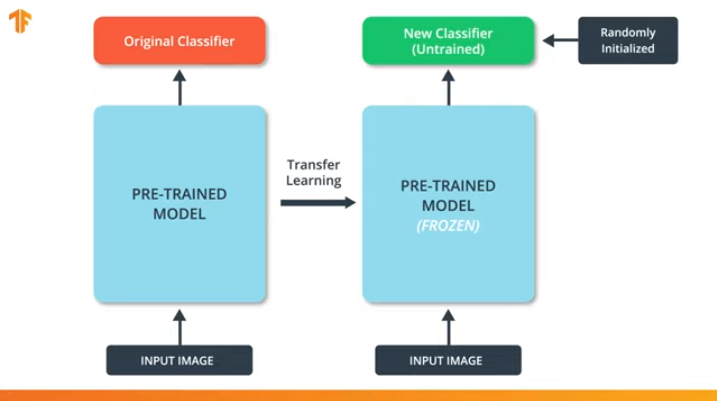
Именно по этой причине мы всегда должны помнить о том, что при использовании существующих моделей значения переменных стоит "замораживать" и отключать необходимость обучения предобученной модели.
Теперь, когда мы знаем как работает передача модели обучения, нам осталось выбрать предобученную нейронную сеть для применения в собственном классификаторе! Этим мы займёмся в следующей части.
MobileNet
Как мы уже упоминали ранее, были разработаны крайне эффективные нейронные сети, которые показывали высокие результаты на наборах данных ImageNet — AlexNet, Inception, Resonant. Эти нейронные сети представляют собой очень глубокие сети и содержит в себе тысячи и даже миллионы параметров. Большое количество парамеров позволяет сети обучиться более сложным паттернам и тем самым добиться повышенной точности классификаций. Большое количество обучающих параметров нейронной сети сказывается на скорости обучения, количестве требуемой памяти для хранения сети и сложности производимых вычислений.
В этом уроке мы воспользуемся современной свёрточной нейронной сетью MobileNet. MobileNet представляет собой эффективную архитектуру свёрточной нейронной сети, которая уменьшает количество используемой памяти для вычислений сохраняя при этом высокую точность предсказаний. Именно поэтому MobileNet является идеальным вариантом для использования на мобильных устройствах с ограниченным количеством памяти и вычислительных ресурсов.
MobileNet была разработана в компании Google и обучена на наборе данных ImageNet.
Так как MobileNet была обучена на 1 000 классах из набора данных ImageNet, то у MobileNet 1 000 выходных классов, вместо двух, которые нам нужны — кошка и собака.
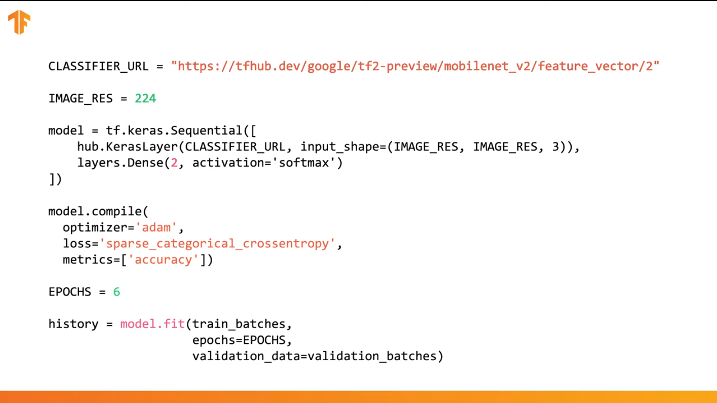
Для выполнения передачи обучения мы предварительно загрузим вектор признаков без слоя классификации:

В Tensorflow загруженный вектор признаков может быть использован как обычный Keras-слой с входными данными определённого размера.
Так как MobileNet была обучена на наборе данных ImageNet, то нам необходимо будет привести размер входных данных к тем, которые были использованы в процессе обучения. В нашем случае MobileNet была обучена на RGB-изображениях фиксированного размера 224х224px.
TensorFlow содержит в себе репозиторий с предобученными моделями, который называется TensorFlow Hub.
TensorFlow Hub содержит некоторые предобученные модели в которых последний слой классификации был исключён из архитектуры нейронной сети для последующего переиспользования.
Использовать TensorFlow Hub в коде можно в несколько строк:

Достаточно указать URL вектора признаков нужной обучающей модели и затем встроить модель в наш классификатор с указанием последнего слоя с нужным количеством выходных классов. Именно последний слой и будет подвергнут обучению и изменению значений параметров. Компиляция и тренировка нашей новой модели осуществляется таким же образом, как мы делали это раньше:
Давайте посмотрим каким образом это будет работать на самом деле и напишем соответствующий код.
CoLab: Кошки Vs Собаки с передачей обучения
Ссылка на CoLab на русском и CoLab на английском.
TensorFlow Hub представляет собой репозиторий с предобученными моделями, которые мы с вами можем использовать.
Передача обучения это процесс в котором мы берём заранее предобученную модель и расширяем её для выполнения определенной задачи. При этом часть предобученной модели, которую мы интегрируем в нейронную сеть, мы оставляем нетронутой, а лишь обучаем последние выходные слои для получения нужного результата.
В этой практической части мы протестируем оба варианта.
По этой ссылке можно изучить весь перечень доступных моделей.
В этой части Colab
- Воспользуемся TensorFlow Hub-моделью для предсказаний;
- Воспользуемся TensorFlow Hub-моделью для набора данных кошек и собак;
- Проведём передачу обучения с использованием модели из TensorFlow Hub.
Перед тем как приступать к выполнению текущей практической части рекомендуем сбросить настройки окружения Runtime -> Reset all runtimes...
Импорты библиотек
В этой практической части мы будем использовать ряд возможностей библиотеки TensorFlow, которых ещё нет в официальном релизе. Именно поэтому мы сперва установим версию TеnsorFlow и TensorFlow Hub для разработчиков.
Установка dev-версии TensorFlow автоматически активирует последнюю установленную версию. После того как мы закончим разбираться с этой практической частью, то рекомендуем восстановить настройки TensorFlow и вернуться к стабильной версии через пункт меню Runtime -> Reset all runtimes.... Выполнение этой команды сбросит все настройки окружения до первоначальных.
!pip install tf-nightly-gpu
!pip install "tensorflow_hub==0.4.0"
!pip install -U tensorflow_datasetsВывод:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0)
Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1)
Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7)
Collecting tf-estimator-nightly (from tf-nightly-gpu)
Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB)
|--------------------------------| 450kB 45.9MB/s
Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5)
Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2)
Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0)
Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1)
Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6)
Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0)
Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1)
Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0)
Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6)
Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu
Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821
Collecting tensorflow_hub==0.4.0
Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB)
|--------------------------------| 81kB 5.0MB/s
Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1)
Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5)
Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0)
Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0)
Installing collected packages: tensorflow-hub
Found existing installation: tensorflow-hub 0.6.0
Uninstalling tensorflow-hub-0.6.0:
Successfully uninstalled tensorflow-hub-0.6.0
Successfully installed tensorflow-hub-0.4.0
Collecting tensorflow_datasets
Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB)
|--------------------------------| 2.3MB 4.9MB/s
Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0)
Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2)
Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0)
Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5)
Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0)
Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1)
Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1)
Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8)
Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1)
Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0)
Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0)
Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0)
Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0)
Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4)
Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3)
Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0)
Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0)
Installing collected packages: tensorflow-datasets
Successfully installed tensorflow-datasets-1.2.0Некоторые импорты мы уже с вами видели и использовали раньше. Из нового — импорт tensorflow_hub, который мы установили и который будем использовать в этой практической части.
from __future__ import absolute_import, division, print_function, unicode_literals
import matplotlib.pylab as plt
import tensorflow as tf
tf.enable_eager_execution()
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.keras import layersВывод:
WARNING:tensorflow:
TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0.
Please upgrade your code to TensorFlow 2.0:
* https://www.tensorflow.org/beta/guide/migration_guide
Or install the latest stable TensorFlow 1.X release:
* `pip install -U "tensorflow==1.*"`
Otherwise your code may be broken by the change.import logging
logger = tf.get_logger()
logger.setLevel(logging.ERROR)Часть 1: используем TensorFlow Hub MobileNet для предсказаний
В этой части CoLab мы возьмём предобученную модель, загрузим её в Keras и протестируем.
Модель, которую мы используем — MobileNet v2 (вместо MobileNet может быть использована любая другая совместимая с tf2 модель классификатора изображений с tfhub.dev).
Загрузите классификатор
Загрузите MobileNet-модель и создайте из неё Keras-модель. MobileNet на входе ожидает получить изображение размером 224х224 пикселя с 3 цветовыми каналами (RGB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2"
IMAGE_RES = 224
model = tf.keras.Sequential([
hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
])Запустите классификатор на единственном изображении
MobileNet была обучена на наборе данных ImageNet. ImageNet содержит 1000 выходных классов и один из таких классов — военная форма. Давайте найдём изображение на котором будет находиться военная форма и которая не будет являться частью обучающего набора ImageNet для проверки точности классификации.
import numpy as np
import PIL.Image as Image
grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg')
grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES))
grace_hopperВывод:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg
65536/61306 [================================] - 0s 0us/step
grace_hopper = np.array(grace_hopper)/255.0
grace_hopper.shapeВывод:
(224, 224, 3)Имейте ввиду, что модели всегда на входе получают набор (блок) изображений для обработки. В коде ниже мы добавляем новую размерность — размер блока.
result = model.predict(grace_hopper[np.newaxis, ...])
result.shapeВывод:
(1, 1001)Результатом предсказания стал вектор размером 1 001 элемент, где каждое значение представляет собой вероятность принадлежности объекта на изображении определенному классу.
Позиция максимаьного значения вероятности может быть найдена при помощи функции argmax. Однако есть вопрос на который мы до сих пор не ответили — как мы можем определить, к какому классу относится элемент с максимальной вероятностью?
predicted_class = np.argmax(result[0], axis=-1)
predicted_classВывод:
653Расшифровываем предсказания
Для того чтобы мы могли определить класс к которому относится предсказания загрузим список меток ImageNet и по индексу с максимальной веростностью определим класс к которому относится предсказание.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt')
imagenet_labels = np.array(open(labels_path).read().splitlines())
plt.imshow(grace_hopper)
plt.axis('off')
predicted_class_name = imagenet_labels[predicted_class]
_ = plt.title("Prediction: " + predicted_class_name.title())Вывод:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt
16384/10484 [==============================================] - 0s 0us/step
Бинго! Наша модель корректно определила военную форму.
Часть 2: используйте TensorFlow Hub-модель для набора данных кошек и собак
Сейчас мы воспользуемся полной версией модели MobileNet и посмотрим, каким образом она справится с набором данных кошек и собак.
Набор данных
Мы можем воспользоваться TensorFlow Datasets для загрузки набора данных кошек и собак.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20))
splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits)
(train_examples, validation_examples) = splits
num_examples = info.splits['train'].num_examples
num_classes = info.features['label'].num_classesВывод:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1...
/usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecureRequestWarning)
WARNING:absl:1738 images were corrupted and were skipped
Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
Не все изображения в наборе данных кошек и собак одного размера.
for i, example_image in enumerate(train_examples.take(3)):
print("Image {} shape: {}".format(i+1, example_image[0].shape))Вывод:
Image 1 shape: (500, 343, 3)
Image 2 shape: (375, 500, 3)
Image 3 shape: (375, 500, 3)Поэтому изображения из полученного набора данных требуют приведения к единому размеру, который ожидает на входе модель MobileNet — 224 x 224.
Функция .repeat() и steps_per_epoch здесь не обязательны, но позволяют сэкономить примерно 15 сек на каждую обучающую итерацию, т.к. временный буфер приходится инициализировать лишь один раз в самом начале процесса обучения.
def format_image(image, label):
image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0
return image, label
BATCH_SIZE = 32
train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1)
validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)Запустите классификатор на наборах изображений
Напомню, что на данном этапе у на всё ещё полная версия предобученной MobileNet сети, которая содержит 1 000 возможных выходных классов. ImageNet содержит большое количество изображений собак и кошек, поэтому давайте попробуем подать на вход одно из тестовых изображений из нашего набора данных и посмотреть, какое предсказание нам выдаст модель.
image_batch, label_batch = next(iter(train_batches.take(1)))
image_batch = image_batch.numpy()
label_batch = label_batch.numpy()
result_batch = model.predict(image_batch)
predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)]
predicted_class_namesВывод:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby',
'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier',
'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby',
'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland',
'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby',
'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog',
'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever',
'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')Метки похожи на названия пород кошек и собак. Давайте теперь отобразим несколько изображений из нашего набора данных кошек и собак и над каждым из них разместим предсказанную метку.
plt.figure(figsize=(10, 9))
for n in range(30):
plt.subplot(6, 5, n+1)
plt.subplots_adjust(hspace=0.3)
plt.imshow(image_batch[n])
plt.title(predicted_class_names[n])
plt.axis('off')
_ = plt.suptitle("ImageNet predictions")
Часть 3: реализуйте передачу обучения с TensorFlow Hub
Теперь давайте воспользуемся TensorFlow Hub для передачи обучения от одной модели к другой.
В процессе передачи обучения мы переиспользуем одну предобученную модель изменяя её последний слой, или несколько слоёв, а затем снова запускаем процесс обучения на новом наборе данных.
В TensorFlow Hub можно найти не только полные предобученные модели (с последним слоем), но и модели без последнего классификационного слоя. Последние могут быть с легкостью использованы для передачи обучения. Мы продолжим использовать MobileNet v2 по той простой причине, что в последующих частях нашего курса мы перенесём эту модель и запустим её на мобильном устройстве с помощью TensorFlow Lite.
Мы так же продолжим использовать набор данных кошек и собак, таким образом у нас будет возможность сравнить производительность этой модели с теми, которые мы реализовывали с нуля.
Обратите внимание, что частичную модель с TensorFlow Hub (без последнего классификационного слоя) мы назвали feature_extractor. Объясняется это наименование тем, что модель принимает на вход данные и преобразуем их до конечного набора выделенных свойств (характеристик). Таким образом наша модель выполнила работу по идентификации содержимого изображения, но не произвела финального распределения вероятностей по выходным классам. Модель извлекла набор свойств из изображения.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2'
feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))Давайте прогоним через feature_extractor набор изображений и посмотрим на результатирующую форму (формат выходных данных). 32 — количество изображений, 1280 — количество нейронов на последнем слое предобученной модели с TensorFlow Hub.
feature_batch = feature_extractor(image_batch)
print(feature_batch.shape)Вывод:
(32, 1280)"Заморозим" переменные в слое извлечения свойств для того, чтобы в процессе обучения менялись только значения переменных слоя классификации.
feature_extractor.trainable = FalseДобавьте слой классификации
Теперь оберните слой из TensorFlow Hub в tf.keras.Sequential-модель и добавьте классификационный слой.
model = tf.keras.Sequential([
feature_extractor,
layers.Dense(2, activation='softmax')
])
model.summary()Вывод:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_1 (KerasLayer) (None, 1280) 2257984
_________________________________________________________________
dense (Dense) (None, 2) 2562
=================================================================
Total params: 2,260,546
Trainable params: 2,562
Non-trainable params: 2,257,984
_________________________________________________________________Обучите модель
Теперь мы обучаем полученную модель так, как мы делали это раньше вызывая compile с последующим fit для тренировки.
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
EPOCHS = 6
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)Вывод:
Epoch 1/6
582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00
Epoch 2/6
582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670
Epoch 3/6
582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666
Epoch 4/6
582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677
Epoch 5/6
582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675
Epoch 6/6
582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668Как вы уже наверняка обратили внимание мы смогли добиться ~97% точности предсказаний на валидационном наборе данных. Потрясающе! Текущий подход значительно увеличил точность классификации в сравнении с первой моделью, которую мы обучали сами и получили точность классификации ~87%. Причина заключается в том, что MobileNet была спроектирована экспертами и тщательно дорабатывалась в течение длинного периода времени, а затем обучена на невероятно большом массиве данных ImageNet.
Как создать собственную MobileNet в Keras можно посмотреть по этой ссылке.
Давайте построим графики изменения значений точности и потерь на обучающем и валидационном наборах данных.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Точность на обучении')
plt.plot(epochs_range, val_acc, label='Точность на валидации')
plt.legend(loc='lower right')
plt.title('Точность на обучающем и валидационном наборах')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Потери на обучении')
plt.plot(epochs_range, val_loss, label='Потери на валидации')
plt.legend(loc='upper right')
plt.title('Потери на обучающем и валидационном наборах')
plt.show()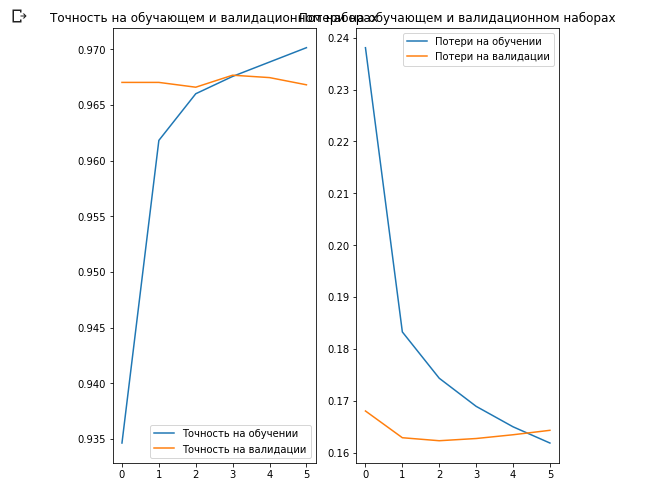
Что интересно здесь, так это то, что результаты на валидационном наборе данных лучше результатов на обучающем наборе данных с самого начала до самого конца процесса обучения.
Одна из причин такого поведения заключается в том, что точность на валидационном наборе данных измеряется в конце обучающей итерации, а точность на тренировочном наборе данных считается как среднее значение среди всех обучающих итераций.
Большей причиной такого поведения является использование предобученной под-сети MobileNet, которая ранее была обучена на большом наборе данных кошек и собак. В процессе обучения наша сеть по прежнему выполняет расширение входного набора тренировочных данных (ту самую augmentation), но не валидационного набора. Это значит что сгенерированные изображения на тренировочном наборе данных сложнее классифицировать чем нормальные изображения из валидационного набора данных.
Проверьте результаты предсказаний
Чтобы повторить график из предыдущего раздела для начала необходимо получить отсортированный список наименований классов:
class_names = np.array(info.features['label'].names)
class_namesВывод:
array(['cat', 'dog'], dtype='<U3')Пропустите блок с изображениями через модель и преобразуйте полученные индексы в имена классов:
predicted_batch = model.predict(image_batch)
predicted_batch = tf.squeeze(predicted_batch).numpy()
predicted_ids = np.argmax(predicted_batch, axis=-1)
predicted_class_names = class_names[predicted_ids]
predicted_class_namesВывод:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat',
'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat',
'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat',
'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')Давайте взглянем на истинные метки и предсказанные:
print("Метки: ", label_batch)
print("Предсказания: ", predicted_ids)Вывод:
Метки: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1]
Предсказания: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]plt.figure(figsize=(10, 9))
for n in range(30):
plt.subplot(6, 5, n+1)
plt.subplots_adjust(hspace=0.3)
plt.imshow(image_batch[n])
color = "blue" if predicted_ids[n] == label_batch[n] else "red"
plt.title(predicted_class_names[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Предсказания модели (синий: верно, красный: неверно)")
Погружаемся в свёрточные нейронные сети
Используя свёрточные нейронные сети мы успели убедиться, что они хорошо справляются с задачей классификации изображений. Однако, на данный момент, мы с трудом представляем себе каким образом они действительно работают. Если бы мы могли понять, каким образом происходит процесс обучения то, в принципе, могли бы улучшить работу по классификации ещё больше. Один из способов понять, каким образом работают свёрточные нейронные сети, заключается в визуализации слоёв и результатов их работы. Мы настоятельно рекомендуем вам изучить материалы по ссылке, чтобы лучше понять, каким образом визуализировать результаты работы свёрточных слоёв.

Область компьютерного зрения увидела свет в конце тонеля и сильно продвинулась вперёд со времён появления свёрточных нейронных сетей. Невероятная скорость с которой осуществляются исследования в этой области и огромные массивы изображений опубликованных в интернете дали невероятные результаты за прошедшие несколько лет. Восход свёрточных нейронных сетей начался с AlexNet в 2012 году, которая была создана Алексом Крижевски, Ильёй Сутскевером и Джеффри Хинтоном и выиграла в известном соревновании ImageNet Large-Scale Visual Recognition Challenge. C тех пор не возникало никаких сомнений в светлом будущем с использованием свёрточных нейронных сетей, а область компьютерного зрения и результаты работы в ней только подтверждали этот факт. Начиная с распознавания вашего лица на мобильном телефоне и заканчивая распознаванием объектов в автономных автомобилях, свёрточные нейронные сети уже успели показать и доказать свою силу и решить множество проблем из реального мира.
Несмотря на огромное количество больших наборов данных и предобученных моделей свёрточных нейронных сетей иногда крайне сложно разобраться в том, каким образом работает сеть и чему именно эта сеть обучается, особенно для людей у которых нет достаточных знаний в области машинного обучения. Изучение базовой информации по статистике и вероятности помогает преодолеть некоторые трудности в понимании работы свёрточных нейронных сетей, однако стоит делу дойти до отладки разрабатываемой и тестируемой свёрточной нейронной сети, например, такой как Inception, то многие сдаются. Цель большинства людей сводится к использованию заранее предобученных моделей для классификации изображений или решению любой другой задачи с получением конечного результата. Меньше всего таким людям хочется погружаться в детали работы свёрточной нейронной сети, несмотря на тот факт, что подобное погружение может сказать им многое о том, как их сеть обучается и чему именно она обучается, а так же где нужно искать ошибки при отладке.
Недавно я наткнулся на потрясающую книгу "Глубокое обучение на Python" от
Francois Chollet. Книга настоящий клад, если вы только начинаете погружаться в глубокое обучение. В ней используется Keras, потрясающая библиотека для глубокого обучения, которая используется "под капотом" TensorFlow, MXNET и Theano. Среди всего того, что я изучил и узнал из этой книги, больше всего меня зацепил вопрос способов визуализации результатов работы свёрточных нейронных сетей. В этой части главы я рассмотрю три способа визуализации и результаты, которые мне удалось получить применяя данные подходы.
Погружаясь в визуализацию
Визуализация выходных значений модели машинного обучения отличный способ представить себе и увидеть, каким образом обучается модель, будь то модель на основе дерева решений или большая нейронная сеть.
В процессе тренировки большинство пользователей модели заинтересованы только в ошибке на тренировочном (training accuracy) и на валидационном наборах данных. Безусловно эти два параметра крайне важны для понимания того, как проходит процесс обучения и в какую сторону он движется, однако когда речь заходит о свёрточных нейронных сетях, например, таких как Inception, то появляется столько возможностей для визуализации результатов обучение и тем самым лучшего понимания архитектуры самой сети.
В этой части я продемонстрирую несколько способов визуализации выходных значений модели, которые позволят получить лучшее представление о том, как происходит сама работа внутри модели. Я обучил Inception v3 (предобученная версия на наборе данных ImageNet) на наборе данных с цветами, который доступен на Kaggle. Если вам ранее не приходилось сталкиваться с моделью Inception, то я настоятельно рекомендую ознакомиться с исходной статьёй по архитектуре сети, а затем изучить второй документ про архитектуру Inception v3 для понимания теоретической части архитектуры сети.
Я обучил модель за 10 итераций (эпох) с размером обучающего блока 32 изображения, размер каждого изображения 229х229х3. Моя модель смогла достигнуть значения потерь на тренировочном наборе данных 0.3195, на валидационном наборе данных — 0.6377. Я использовал встроенный класс ImageDataGenerator для расширения набора данных изображений, чтобы моя модель быстро не переобучилась. На исходный код можно взглянуть в GitHub репозитории.
Визуализация промежуточных слоёв
Чтобы лучше понять работу глубоких свёрточных сетей при классификации изображений нам необходимо понять, каким образом модель "видит" наши входные изображения, глядя на выходные значения промежуточных слоёв. Изучая выходные результаты модели на промежуточных слоях мы станем лучше понимать сам принцип их работы.
Например, ниже представлены визуализации некоторых значений промежуточных слоёв свёртки с соответствующими активационными слоями обученной Inception v3 модели, при подаче на вход оригинального изображения с цветком.

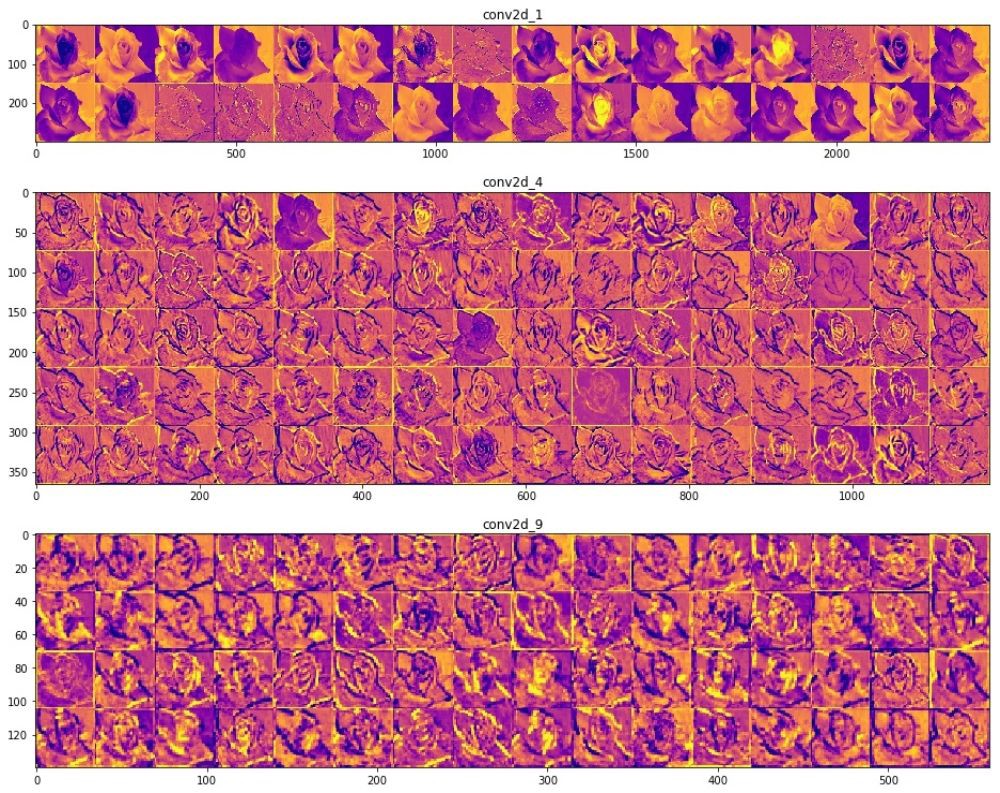
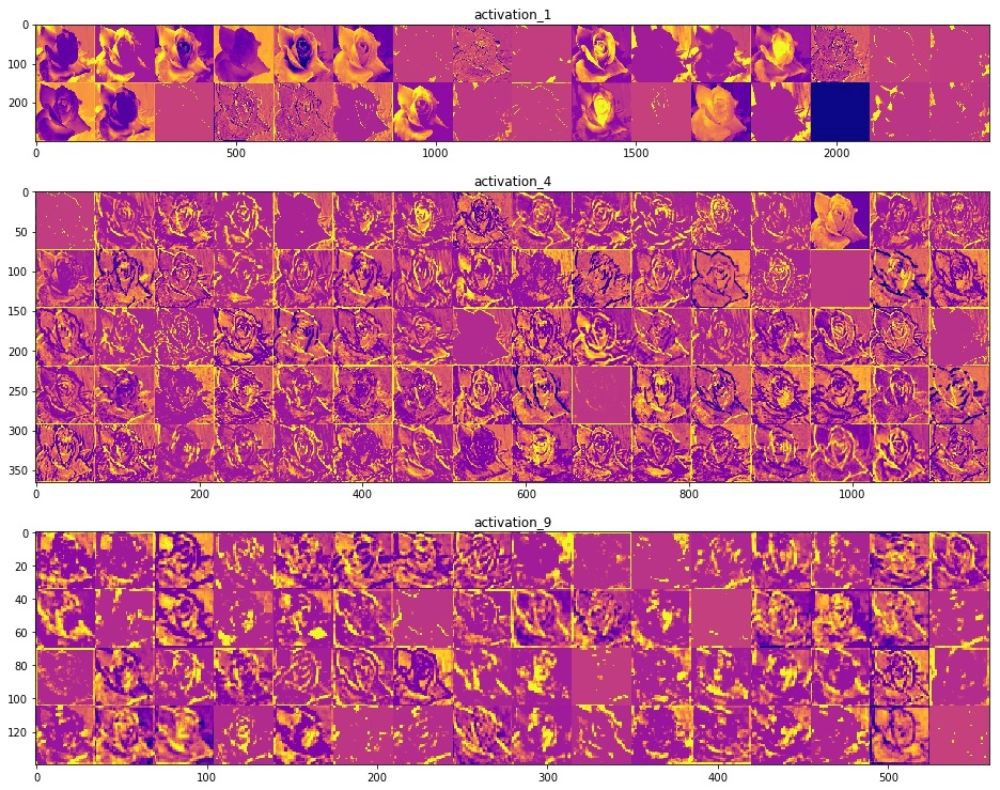
Приведенные выше изображения — результаты работы промежуточных слоёв модели. Я получил их подавая на вход свёрточной нейронной сети одно из тестовых изображений.
Если взглянуть на различные изображения результатов работы свёрточного слоя, то становится достаточно очевидным каким образом различные фильтры на разных слоях пытаются выделить (активировать) разные части изображения. Некоторые фильтры работают как фильтры определения границ (граней), другие определяют конкретную часть цветка на изображении, например, центральную часть, а другие выполняют роль детекторов фона. Легче всего заметить такое поведение свёрточных слоёв на начальных этапах, потому что чем глубже становится сеть, тем разряженнее становится ядро фильтров и некоторые признаки, которые выделены на начальных слоях, могут оказаться нерелевантными на последующих и отброшены.
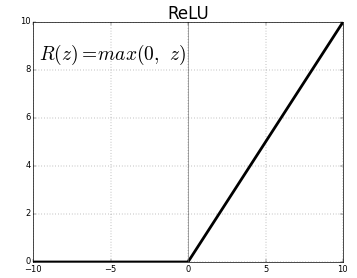
Возвращаемся к ReLU-активации для соответствующих свёрточных слоёв. Всё что они делают, так это применяют функцию ReLU(z) = max(0, z) к значениям каждого пикселя изображения.
Визуализируя результаты работы различных свёрточных слоёв подобным образом ключевой момент, который вы заметите, заключается в том, что чем глубже становится слой в нейронной сети, тем более специфичное свойство изображения выделяется, в то время как на начальных слоях происходит выделение обобщенных паттернов, таких как грани, текстуры, фон и т.п. Понимание этого момента крайне важно при использовании передачи обучения с предобученными моделями, заменяете ли вы часть собственной сети готовой моделью или всю модель целиком. Основная идея заключается в "заморозке" (отключении) наиболее ранних слоёв нейронной сети, потому что они уже были обучены и уже содержат информации о том, как выделить определенные свойства объекта, оставляя активными только последние слои на которых происходит сам процесс распознавания и классификации.
Визуализируем фильтры свёрточных слоёв
Ещё один способ лучше понять на что же "смотрят" свёрточные слои в сети это визуализировать их фильтры. Изучая каждый фильтр можно понять на какой паттерн будет реагировать и активироваться каждый из фильтров.
Вот некоторые фильтры, которые я получил обучая Inveption V3 модель на наборе данных с цветами:
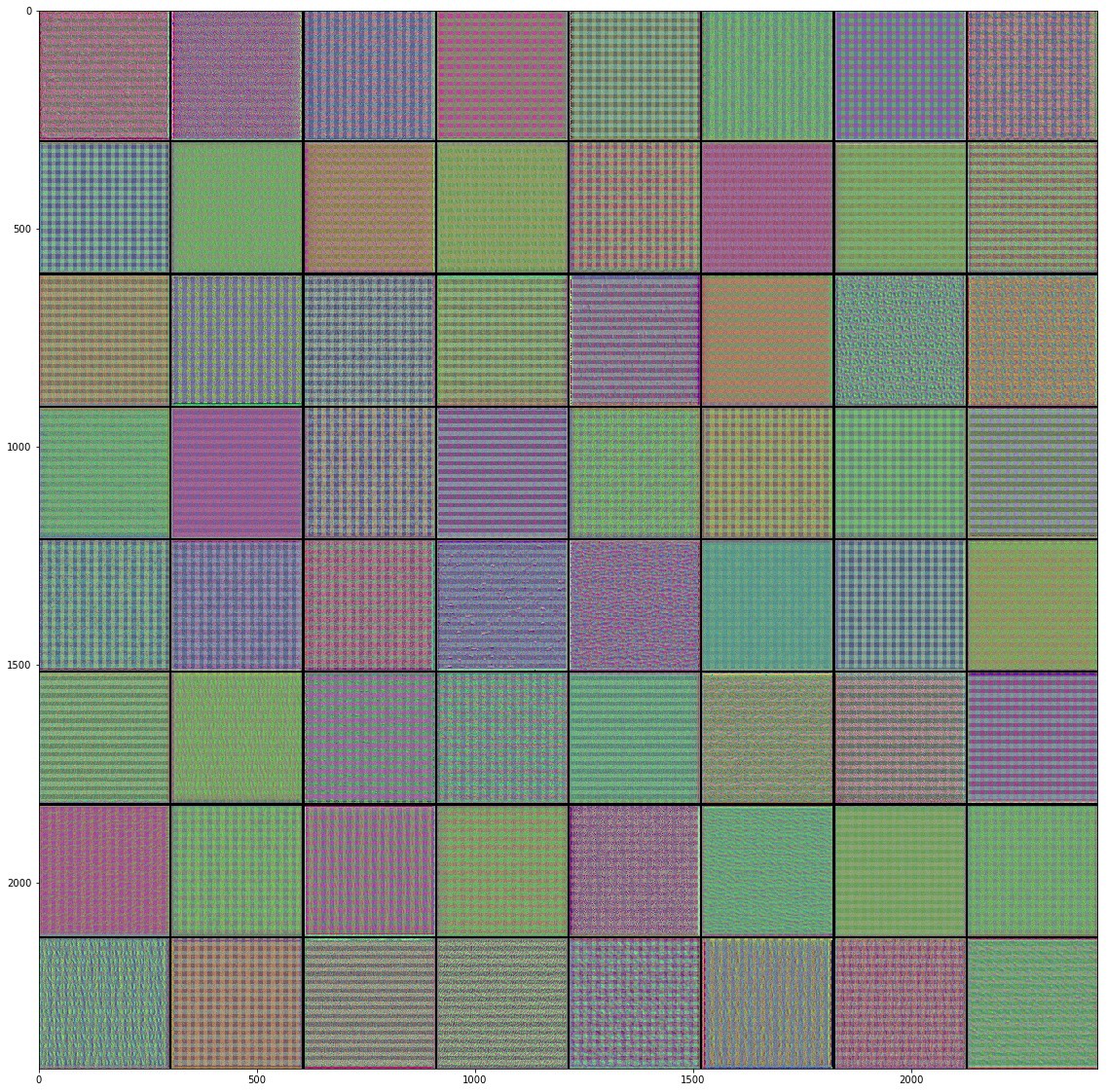
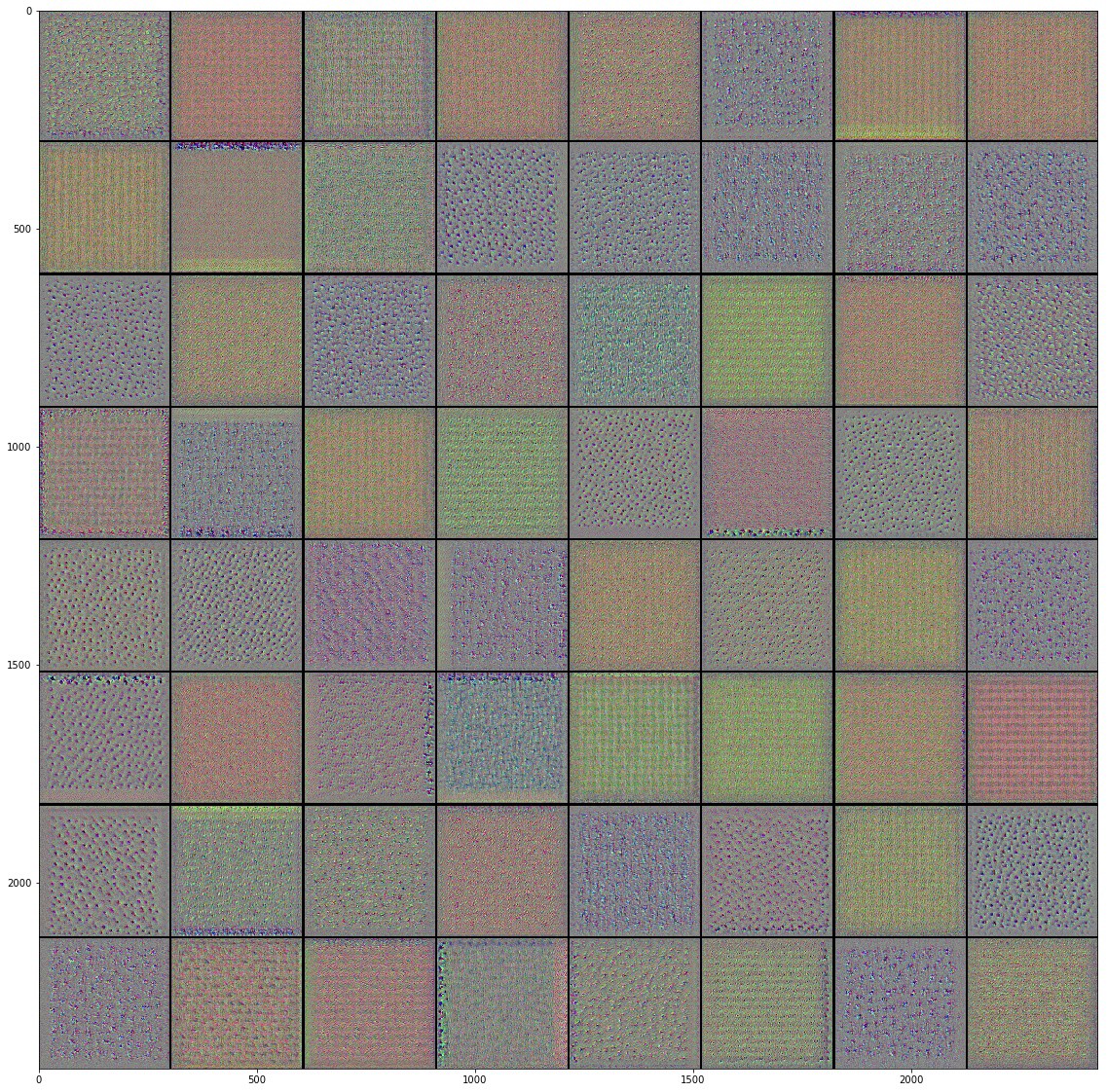

После пристального изучения полученных изображений фильтров с различных свёрточных слоёв нейронной сети становится понятно, что именно они пытаются найти в изображении на входе. Паттерны, которые мы наблюдаем на самых первых словях представляют собой самые простые паттерны состоящие из прямых и других базовых фигур, что в очередной раз доказывает нам, что на начальных слоях происходит выделение базовых свойств изображения вроде границ, цветов и т.п. Но чем сильнее мы отдаляемся от начальных слоёв свёрточной сети, тем сложнее и абстрактнее становятся выделяемые паттерны, а именно они помогают обобщить свойства изображения и отличить один класс объекта от другого на изображениях. Именно поэтому мы видели несколько пустых фильтров на глубинных слоях свёрточной сети, потому что определенные фильтры не были активированы, другими словами, в изображении не было той информации в которой фильтры были "заинтересованы" (попросту говоря, изображение не соответствовало искомому паттерну фильтра).
Визуализируем тепловую карту классов активации
В процесс предсказания классов объектов на изображении, иногда наша модель будет ошибаться и предсказывать некорректные классы, например, вероятность правильной метки будет не максимальной. В подобных случаях будет крайне полезно, если бы мы смогли визуализировать области изображений в свёрточной сети на которые она смотрит для определения класса объекта.
Подобная техника визуализации называется Class Activation Map (карта активаций класса). Один из техник применяемая при CAM это наложение тепловой карты на исходное изображение. Тепловая карта классов активации представляет собой 2D сетку в каждой ячейке которой располагается значение количества баллов связанных с конкретным выходным классом, вычисленное для каждой позиции исходного изображения и отображающего важность вклада каждого участка в классификацию объекта выходного класса.
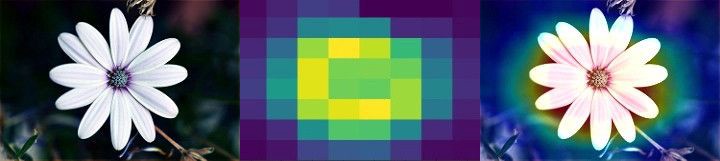

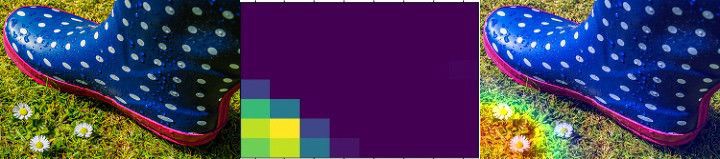
На приведённых выше изображениях вы можете понять, каким образом работает эта техника. Начиная с левого изображения, изображение подаваемое на вход, затем идёт изображение тепловой карты активаций последнего Mixed-слоя в Inception V3-модели, последнее изображение наложение исходного и тепловой карты активаций. Таким образом карта активаций сообщает нам область (участок) изображения, которая произвела максимальный вклад в конечное значение классификации полученного выходного класса.
На первом изображении достаточно очевидно, что трудностей с классификацией наша свёрточная нейронная сеть не наблюдает, так как на изображении больше нет других объектов. На следующем изображении свёрточная нейронная сеть не смогла классифицировать ромашки, но достаточно взглянуть на тепловую карту активаций и становится понятным тот факт, что сеть ищет объект в нужной части изображения. То же относится и к последнему изображению, где сеть корректно определяет участок изображения на котором находятся ромашки. Несмотря на то, что сети не удалось корректно определить ромашки на последних двух изображениях она определила их местоположение на изображении, и дело здесь не в корректности самой сети, а скорее в том, что большую часть исходного изображения занимают другие объекты.
Тепловые карты активаций могут отличаться в зависимости от слоёв свёрточной сети, так как каждый свёрточные слой "видит" изображение по-своему и создаёт собственную уникальную абстракцию изображения основываясь на сгенерированных фильтрах. В этом примере я сконцентрировался на последнем слое модели от которого непосредственно зависит точность классификации. Однако в качестве хорошего эксперимента можно сравнить тепловые карты активации на различных слоях.
В заключение хочу добавить, что визуализация позволяет нам лучше понять происходящее в свёрточной нейронной сети, найти причины ошибочных классификаций и даёт нам возможность повысить эффективность работы сети понимания работу и результаты работы каждого слоя.
Практическая часть: определение цветов с передачей обучения
Colab на русском и Colab на английском.
TensorFlow Hub
TensorFlow Hub представляет собой репозиторий с предобученными моделями, которые мы с вами можем использовать.
Передача обучения это процесс в котором мы берём заранее предобученную модель и расширяем её для выполнения определенной задачи. При этом часть предобученной модели, которую мы интегрируем в нейронную сеть, мы оставляем нетронутой, а лишь обучаем последние выходные слои для получения нужного результата.
По этой ссылке можно изучить весь перечень доступных моделей.
Перед тем как приступать к выполнению текущей практической части рекомендуем сбросить настройки окружения Runtime -> Reset all runtimes...
Импорты
Импортируем библиотеки, которые мы использовали ранее:
from __future__ import absolute_import, division, print_function, unicode_literals
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
tf.enable_eager_execution()
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.keras import layersВывод:
WARNING:tensorflow:
The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
* https://github.com/tensorflow/io (for I/O related ops)
If you depend on functionality not listed there, please file an issue.import logging
logger = tf.get_logger()
logger.setLevel(logging.ERROR)Загрузите набор данных с цветами используя TensorFlow Datasets
В коде ниже мы с вами загрузим набор данных цветов из TensorFlow Datasets. Если посмотреть в документации, то найдём название этого набора данных — tf_flowers. Так же вы можете обратить внимание на то, что набор данных содержит только тренировочный набор. Для того чтобы получить валидационный нам необходимо будет имеющийся единственный тренировочный разбить с помощью метода tfds.splits на тренировочный (70%) и валидационный (30%). Затем полученные наборы загрузить при помощь метода tfds.load. При использовании метода tfds.load убедитесь, что используете все необходимые параметры и метод возвращает информацию о наборе данных, которую мы сможем использовать в дальнейшем.
splits = tfds.Split.TRAIN.subsplit([70, 30])
(training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)Вывод:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0...
Dl Completed...
1/|/100% 1/1 [00:07<00:00, 3.67s/ url]
Dl Size...
218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s]
Extraction completed...
1/|/100% 1/1 [00:07<00:00, 7.05s/ file]
Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.Выведите информацию о цветочном наборе данных
Теперь, когда мы загрузили набор данных цветов, воспользуемся полученной информацией (метаданными) по набору данных и выведем количество классов в наборе, а так же напишем часть кода, который покажет нам сколько элементов в каждом из наборов — тренировочном и валидационном.
num_classes = dataset_info.features['label'].num_classes
num_training_examples = 0
num_validation_examples = 0
for example in training_set:
num_training_examples += 1
for example in validation_set:
num_validation_examples += 1
print('Total Number of Classes: {}'.format(num_classes))
print('Total Number of Training Images: {}'.format(num_training_examples))
print('Total Number of Validation Images: {} \n'.format(num_validation_examples))Вывод:
Total Number of Classes: 5
Total Number of Training Images: 2590
Total Number of Validation Images: 1080 Изображения в цветочном наборе данных различного размера — надо исправлять.
for i, example in enumerate(training_set.take(5)):
print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))Вывод:
Image 1 shape: (226, 240, 3) label: 0
Image 2 shape: (240, 145, 3) label: 2
Image 3 shape: (331, 500, 3) label: 2
Image 4 shape: (240, 320, 3) label: 0
Image 5 shape: (333, 500, 3) label: 1Преобразовываем изображения и создаём блоки обработки
В коде ниже мы приводим изображения к единому размеру — размеру, который используется MobilNet v2 на входе для классификации — 224х224 и нормализуем значения пикселей (grayscale). Функция принимает на входе image (изображение) и label (метку) и возвращает преобразованное изображение и соответствующую метку.
IMAGE_RES = 224
def format_image(image, label):
image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0
return image, label
BATCH_SIZE = 32
train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1)
validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)Применяем передачу обучения с TensorFlow Hub
Давайте теперь воспользуемся TensorFlow Hub для передачи обучения. Напомним, что при передаче обучения мы переиспользуем части предобученной модели в нашей модели и связываем с последним слоем классификации или несколькими слоями модели, а затем обучаем всю модель на обучающем наборе данных.
Создаём метод извлечения свойств
В коде ниже мы создаём feature_extractor используя MobileNet v2. Напоминаем, что часть модели полученной из TensorFlow Hub (без последнего классификационного слоя) называется вектором свойств. Чтобы ознакомиться с полным списком векторов достаточно заклянуть в документацию. Нажмите на tf2-preview/mobilenet_v2/feature_vector, изучите документацию и скопируйте URL по которому можно получить вектор свойств MobileNet v2 модели. Затем создайте feature_extractor с использованием hub.KerasLayer с указанием соответствующего значения параметра input_shape.
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"
feature_extractor = hub.KerasLayer(URL,
input_shape=(IMAGE_RES, IMAGE_RES, 3))Замораживаем переменные предобученной модели
В коде ниже мы блокируем возможность изменения значений переменных предобученной модели и оставляем возможность обучаться только последнему слою классификации, который мы добавим:
feature_extractor.trainable = FalseДобавляем слой классификации
В коде ниже мы добавляем последний слой классификации с количеством нейронов равных количеству классифицируемых классов, которые нам необходимы. Количество выходных нейронов должно быть равно количеству классов в цветочном наборе данных. В последней строке мы выводим информации о полученной архитектуре модели.
model = tf.keras.Sequential([
feature_extractor,
layers.Dense(num_classes, activation='softmax')
])
model.summary()Вывод:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer (KerasLayer) (None, 1280) 2257984
_________________________________________________________________
dense (Dense) (None, 5) 6405
=================================================================
Total params: 2,264,389
Trainable params: 6,405
Non-trainable params: 2,257,984Обучаем модель
В коде ниже мы компилируем и тренируем полученную модель таким же образом, как делали это раньше с полностью созданными нами свёрточными нейронными сетями.
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
EPOCHS = 6
history = model.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)Вывод:
Epoch 1/6
81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00
Epoch 2/6
81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833
Epoch 3/6
81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907
Epoch 4/6
81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917
Epoch 5/6
81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972
Epoch 6/6
81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000Как вы уже обратили внимание мы получили точность ~90% после 6 обучающих итераций, что можно назвать отличным результатом! Это потрясающая точность, если учитывать тот факт, что на созданной нами модели с нуля мы получили точность ~76% после 80 обучающих итераций. Существенная разница в точности классификации объясняется тем фактом, что MobilNet v2 была спроектирована и тщательно дорабатывалась множеством экспертов в области и обучена была на огромном наборе данных.
Отобразите графики точности потерь на тренировочном и валидационном наборах данных
В коде ниже мы отрисовываем графики точности и потерь на тренировочном и валидационном наборах данных.
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(EPOCHS)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()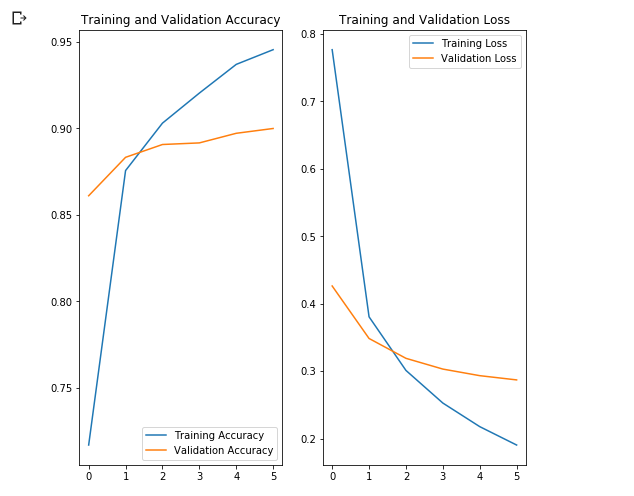
Что интересно здесь, так это то, что результаты на валидационном наборе данных лучше результатов на обучающем наборе данных с самого начала до самого конца процесса обучения.
Одна из причин такого поведения заключается в том, что точность на валидационном наборе данных измеряется в конце обучающей итерации, а точность на тренировочном наборе данных считается как среднее значение среди всех обучающих итераций.
Большей причиной такого поведения является использование предобученной под-сети MobileNet, которая ранее была обучена на большом наборе данных кошек и собак. В процессе обучения наша сеть по прежнему выполняет расширение входного набора тренировочных данных (ту самую augmentation), но не валидационного набора. Это значит что сгенерированные изображения на тренировочном наборе данных сложнее классифицировать чем нормальные изображения из валидационного набора данных.
Проверим предсказания
В коде ниже мы получаем список наименований классов и преобразуем его в массив NumPy. Выводим в консоль значения массива, чтобы убедиться в корректности наименований меток.
class_names = np.array(dataset_info.features['label'].names)
print(class_names)Вывод:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']Сформируем блок изображений и прогоним через модель для предсказаний
Воспользуемся функцией next() для создания image_batch (блок изображений) и соответствующий label_batch (блок меток). Преобразуем и image_batch и label_batch к NumPy массивам при помощи метода .numpy(). Затем воспользуемся методом .predict() для запуска предсказаний по нашей модели. Получить индекс классов предсказаний можно через метод np.argmax() для каждого изображения. В завершении преобразуйте индексы с максимальным значением предсказаний в наименования самих классов.
image_batch, label_batch = next(iter(train_batches))
image_batch = image_batch.numpy()
label_batch = label_batch.numpy()
predicted_batch = model.predict(image_batch)
predicted_batch = tf.squeeze(predicted_batch).numpy()
predicted_ids = np.argmax(predicted_batch, axis=-1)
predicted_class_names = class_names[predicted_ids]
print(predicted_class_names)Вывод:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips'
'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips'
'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses'
'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion'
'dandelion' 'roses' 'dandelion']Выведем истинные метки и предсказанные индексы
print("Labels: ", label_batch)
print("Predicted labels: ", predicted_ids)Вывод:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]Отобразим предсказания модели
plt.figure(figsize=(10,9))
for n in range(30):
plt.subplot(6,5,n+1)
plt.subplots_adjust(hspace = 0.3)
plt.imshow(image_batch[n])
color = "blue" if predicted_ids[n] == label_batch[n] else "red"
plt.title(predicted_class_names[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")
Осуществляем передачу обучения с использованием Inception-модели
Обратимся снова к документации TensorFlow Hub и перейдём в раздел tf2-preview/inception_v3/feature_vector. На этот раз вектор свойств относится к Inception V3 модели. В коде ниже мы создаём модель, которая будет использовать предобученную часть Inception V3 модели для классификации изображений цветов. Обратите внимание, что Inception V3 модель принимает на входе изображения размером 299х299 пикселей. Сравните точность Inception V3 модели и предыдущей MobileNet V2.
IMAGE_RES = 299
(training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1)
validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4"
feature_extractor = hub.KerasLayer(URL,
input_shape=(IMAGE_RES, IMAGE_RES, 3),
trainable=False)
model_inception = tf.keras.Sequential([
feature_extractor,
tf.keras.layers.Dense(num_classes, activation='softmax')
])
model_inception.summary()Вывод:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
keras_layer_1 (KerasLayer) (None, 2048) 21802784
_________________________________________________________________
dense_1 (Dense) (None, 5) 10245
=================================================================
Total params: 21,813,029
Trainable params: 10,245
Non-trainable params: 21,802,784model_inception.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
EPOCHS = 6
history = model_inception.fit(train_batches,
epochs=EPOCHS,
validation_data=validation_batches)Вывод:
Epoch 1/6
81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00
Epoch 2/6
81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657
Epoch 3/6
81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769
Epoch 4/6
81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796
Epoch 5/6
81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824
Epoch 6/6
81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861Итоги
В этом уроке мы с вами научились использовать передачу обучения для создания мощных свёрточных нейронных сетей с минимальными усилиями. Ключевые момент о которых мы говорили и которые стоит помнить:
- Передача обучени: техника, которая позволяет переиспользовать модель созданную экспертами по обучению и которая была предобучена на большом наборе данных. При использовании предобученных моделей мы всегда должны помнить о необходимости изменения последнего классификационного слоя.
- Заморозка параметров: отключение переменных предобученной модели для последующих изменений. "Замораживая" переменные предобученной модели мы гарантируем, что обучаться будет только последний классификационный слой, а значения предобученной модели останутся прежними.
- MobileNet: современная свёрточная нейронная сеть разработанная специалистами Google, которая использует эффективную архитектуру сети для минимизации количества используемой памяти и вычислительных ресурсов сохраняя при этом высокую точность. MobileNet идеально подходит для использования на мобильных устройствах с ограниченным объёмом памяти и вычислительных ресурсов.
Так же мы использовали передачу обучения для создания свёрточной нейронной сети на основе MobileNet для классификации изображений кошек и собак. Вы наверняка смогли убедиться насколько сильно повышается точность классификации при использовании технологии передачи обучения на наборе данных с кошками и собаками. В качестве упражнения мы с вами применили технологию передачи обучения для создания собственной свёрточной нейронной сети на основе MobileNet для классификации изображений цветов.
… и стандартные call-to-action — подписывайся, ставь плюс и делай share :)
YouTube
Telegram
ВКонтакте
при поддержке Ojok.
da-nie
Эх, кто бы расписал бы по действиям всю математику для CNN со всеми нюансами и без кучи производных (по типу, «формула модификации весов такая:», а не «производная dw/dj=..., остальное элементарно» ) Интересно ведь и без Tensor Flow тоже сделать такое. А то я до сих пор борюсь с самодельной CNN и возникающие приколы мне непонятно, как обходить.
pdima
cs231n стоит посмотреть