

Какое-то время назад мы сделали безагентский (Agentless) мониторинг и алармы к нему. Это аналог CloudWatch в AWS с совместимым API. Сейчас мы работаем над балансировщиками и автоматическим скейлингом. Но пока мы не предоставляем такой сервис — предлагаем нашим заказчикам сделать его самим, используя в качестве источника данных наш мониторинг и теги (AWS Resource Tagging API) как простой service discovery. Как это сделать покажем в этом посте.
Пример минимальной инфраструктуры простого веб-сервиса: DNS -> 2 балансера -> 2 backend. Данную инфраструктуру можно считать минимально необходимой для отказоустойчивой работы и для проведения обслуживания. По этой причине мы не будем "сжимать" еще сильнее эту инфраструктуру, оставляя, например, только один backend. А вот увеличивать число backend серверов и сокращать обратно до двух хотелось бы. Это и будет нашей задачей. Все примеры доступны в репозитории.
Базовая инфраструктура
Мы не будем останавливаться детально на настройке приведённой выше инфраструктуры, покажем лишь, как её создать. Мы предпочитаем разворачивать инфраструктуру с помощью Terraform. Он помогает быстро создать всё необходимое (VPC, Subnet, Security Group, VMs) и повторять эту процедуру раз за разом.
Скрипт для поднятия базовой инфраструктуры:
variable "ec2_url" {}
variable "access_key" {}
variable "secret_key" {}
variable "region" {}
variable "vpc_cidr_block" {}
variable "instance_type" {}
variable "big_instance_type" {}
variable "az" {}
variable "ami" {}
variable "client_ip" {}
variable "material" {}
provider "aws" {
endpoints {
ec2 = "${var.ec2_url}"
}
skip_credentials_validation = true
skip_requesting_account_id = true
skip_region_validation = true
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
resource "aws_vpc" "vpc" {
cidr_block = "${var.vpc_cidr_block}"
}
resource "aws_subnet" "subnet" {
availability_zone = "${var.az}"
vpc_id = "${aws_vpc.vpc.id}"
cidr_block = "${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"
}
resource "aws_security_group" "sg" {
name = "auto-scaling"
vpc_id = "${aws_vpc.vpc.id}"
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"]
}
ingress {
from_port = 8080
to_port = 8080
protocol = "tcp"
cidr_blocks = ["${cidrsubnet(aws_vpc.vpc.cidr_block, 8, 0)}"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_key_pair" "key" {
key_name = "auto-scaling-new"
public_key = "${var.material}"
}
resource "aws_instance" "compute" {
count = 5
ami = "${var.ami}"
instance_type = "${count.index == 0 ? var.big_instance_type : var.instance_type}"
key_name = "${aws_key_pair.key.key_name}"
subnet_id = "${aws_subnet.subnet.id}"
availability_zone = "${var.az}"
security_groups = ["${aws_security_group.sg.id}"]
}
resource "aws_eip" "pub_ip" {
instance = "${aws_instance.compute.0.id}"
vpc = true
}
output "awx" {
value = "${aws_eip.pub_ip.public_ip}"
}
output "haproxy_id" {
value = ["${slice(aws_instance.compute.*.id, 1, 3)}"]
}
output "awx_id" {
value = "${aws_instance.compute.0.id}"
}
output "backend_id" {
value = ["${slice(aws_instance.compute.*.id, 3, 5)}"]
}Все сущности, описываемые в этой конфигурации, кажется, должны быть понятны рядовому пользователю современных облаков. Переменные, специфичные для нашего облака и для конкретной задачи, выносим в отдельный файл — terraform.tfvars:
ec2_url = "https://api.cloud.croc.ru"
access_key = "project:user@customer"
secret_key = "secret-key"
region = "croc"
az = "ru-msk-vol51"
instance_type = "m1.2small"
big_instance_type = "m1.large"
vpc_cidr_block = "10.10.0.0/16"
ami = "cmi-3F5B011E"Запускаем Terraform:
yes yes | terraform apply -var client_ip="$(curl -s ipinfo.io/ip)/32" -var material="$(cat <ssh_publick_key_path>)"Настройка мониторинга
Запущенные выше ВМ автоматически мониторятся нашим облаком. Именно данные этого мониторинга будут являться источником информации для будущего автоскейлинга. Полагаясь на те или иные метрики мы можем увеличивать или сокращать мощности.
Мониторинг в нашем облаке позволяет настроить алармы по различным условиям на различные метрики. Это очень удобно. Нам не нужно анализировать метрики за какие-то интервалы и принимать решение — это сделает мониторинг облака. В данном примере мы будем использовать алармы на метрики CPU, но в нашем мониторинге их также можно настроить на такие метрики как: утилизация сети (скорость/pps), утилизация диска (скорость/iops).
export CLOUDWATCH_URL=https://monitoring.cloud.croc.ru
for instance_id in <backend_instance_ids>; do aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL cloudwatch put-metric-alarm --alarm-name "scaling-low_$instance_id" --dimensions Name=InstanceId,Value="$instance_id" --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average --period 60 --evaluation-periods 3 --threshold 15 --comparison-operator LessThanOrEqualToThreshold; done
for instance_id in <backend_instance_ids>; do aws --profile <aws_cli_profile> --endpoint-url $CLOUDWATCH_URL cloudwatch put-metric-alarm --alarm-name "scaling-high_$instance_id" --dimensions Name=InstanceId,Value="$instance_id" --namespace "AWS/EC2" --metric-name CPUUtilization --statistic Average --period 60 --evaluation-periods 3 --threshold 80 --comparison-operator GreaterThanOrEqualToThreshold; doneОписание некоторых параметров, которые могут быть непонятны:
--profile — профиль настроек aws-cli, описывается в ~/.aws/config. Обычно в разных профилях задаются разные ключи доступа.
--dimensions — параметр определяет для какого ресурса будет создан аларм, в примере выше — для инстанса с идентификатором из переменной $instance_id.
--namespace — пространство имён, из которого будет выбрана метрика мониторинга.
--metric-name — имя метрики мониторинга.
--statistic — название метода агрегации значений метрики.
--period — временной интервал между событиями сбора значений мониторинга.
--evaluation-periods — количество интервалов, необходимое для срабатывания аларма.
--threshold — пороговое значение метрики для оценки состояния аларма.
--comparison-operator — метод, который применяется для оценки значения метрики относительно порогового значения.
В примере выше для каждого backend инстанса создаётся два аларма. Scaling-low-<instance-id> перейдёт в состояние Alarm при загрузке CPU менее 15% на протяжении 3 минут. Scaling-high-<instance-id> перейдёт в состояние Alarm при загрузке CPU более 80% на протяжении 3 минут.
Настройка тегов
После настройки мониторинга перед нами встаёт следующая задача — обнаружение инстансов и их имён (service discovery). Нам нужно как-то понимать, сколько у нас сейчас запущено backend инстансов, а также нужно знать их имена. В мире вне облака для этого хорошо подошел бы, например, consul и consul template для генерации конфига балансера. Но в нашем облаке есть теги. Теги помогут нам категоризировать ресурсы. Запросив информацию по определённому тегу (describe-tags), мы можем понимать, сколько инстансов у нас сейчас в пуле и какие у них id. По умолчанию уникальный id инстанса используется в качестве hostname. Благодаря внутреннему DNS работающему внутри VPC эти id/hostname резолвятся во внутренние ip инстансов.
Задаём теги для backend инстансов и балансеров:
export EC2_URL="https://api.cloud.croc.ru"
aws --profile <aws_cli_profile> --endpoint-url $EC2_URL ec2 create-tags --resources "<awx_instance_id>" --tags Key=env,Value=auto-scaling Key=role,Value=awx
for i in <backend_instance_ids>; do aws --profile <aws_cli_profile> --endpoint-url $EC2_URL ec2 create-tags --resources "$i" \
--tags Key=env,Value=auto-scaling Key=role,Value=backend ; done;
for i in <haproxy_instance_ids>; do \
aws --profile <aws_cli_profile> --endpoint-url $EC2_URL ec2 create-tags --resources "$i" \
--tags Key=env,Value=auto-scaling Key=role,Value=haproxy; done;Где:
--resources — список идентификаторов ресурсов, которым будут установлены теги.
--tags — список пар ключ-значение.
Пример describe-tags доступен в документации Облака КРОК.
Настройка автоскейлинга
Теперь когда облако занимается мониторингом, и мы умеем работать с тегами, нам остаётся только опрашивать состояние настроенных алармов на предмет их срабатывания. Тут нам нужна сущность, которая будет заниматься периодическим опросом мониторинга и запуском задач по созданию/удалению инстансов. Здесь можно применить различные средства автоматизации. Мы будем использовать AWX. AWX — это open-source версия коммерческого Ansible Tower, продукта для централизованного управления Ansible-инфраструктурой. Основная задача — периодически запускать наши ansible playbook.
С примером деплоя AWX можно ознакомиться на странице wiki в официальном репозитории. Настройка AWX также описана в документации Ansible Tower. Чтобы сервис AWX начал запускать пользовательские playbook, его необходимо настроить, создав следующие сущности:
- Сredentials трёх типов:
— AWS credentials — для авторизации операций, связанных с Облаком КРОК.
— Machine credentials — ssh ключи для доступа на вновь созданные инстансы.
— SCM credentials — для авторизации в системе контроля версий. - Project — сущность, которая склонит git репозиторий с playbook.
- Scripts — скрипт dynamic inventory для ansible.
- Inventory — сущность, которая будет вызывать скрипт dynamic inventory перед запуском playbook.
- Template — конфигурация конкретного вызова playbook, состоит из набора Credentials, Inventory и playbook из Project.
- Workflow — последовательность вызовов playbooks.
Процесс автоскейлинга можно разделить на две части:
- scale_up — создание инстанса при срабатывании хотя бы одного high аларма;
- scale_down — терминация инстанса, если для него сработал low аларм.
В рамках scale_up части необходимо будет:
- опросить сервис мониторинга облака о наличии high алармов в состоянии "Alarm";
- досрочно остановить scale_up, если все high алармы находятся в состоянии "OK";
- создать новый инстанс с необходимыми атрибутами (tag, subnet, security_group и т.д.);
- создать high и low алармы для запущенного инстанса;
- настроить наше приложение внутри нового инстанса (в нашем случае это будет просто nginx с тестовой страницей);
- обновить конфигурацию haproxy, сделать релоад, чтобы на новый инстанс начали идти запросы.
---
- name: get alarm statuses
describe_alarms:
region: "croc"
alarm_name_prefix: "scaling-high"
alarm_state: "alarm"
register: describe_alarms_query
- name: stop if no alarms fired
fail:
msg: zero high alarms in alarm state
when: describe_alarms_query.meta | length == 0
- name: create instance
ec2:
region: "croc"
wait: yes
state: present
count: 1
key_name: "{{ hostvars[groups['tag_role_backend'][0]].ec2_key_name }}"
instance_type: "{{ hostvars[groups['tag_role_backend'][0]].ec2_instance_type }}"
image: "{{ hostvars[groups['tag_role_backend'][0]].ec2_image_id }}"
group_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_security_group_ids }}"
vpc_subnet_id: "{{ hostvars[groups['tag_role_backend'][0]].ec2_subnet_id }}"
user_data: |
#!/bin/sh
sudo yum install epel-release -y
sudo yum install nginx -y
cat <<EOF > /etc/nginx/conf.d/dummy.conf
server {
listen 8080;
location / {
return 200 '{"message": "$HOSTNAME is up"}';
}
}
EOF
sudo systemctl restart nginx
loop: "{{ hostvars[groups['tag_role_backend'][0]] }}"
register: new
- name: create tag entry
ec2_tag:
ec2_url: "https://api.cloud.croc.ru"
region: croc
state: present
resource: "{{ item.id }}"
tags:
role: backend
loop: "{{ new.instances }}"
- name: create low alarms
ec2_metric_alarm:
state: present
region: croc
name: "scaling-low_{ item.id }}"
metric: "CPUUtilization"
namespace: "AWS/EC2"
statistic: Average
comparison: "<="
threshold: 15
period: 300
evaluation_periods: 3
unit: "Percent"
dimensions: {'InstanceId':"{{ item.id }}"}
loop: "{{ new.instances }}"
- name: create high alarms
ec2_metric_alarm:
state: present
region: croc
name: "scaling-high_{{ item.id }}"
metric: "CPUUtilization"
namespace: "AWS/EC2"
statistic: Average
comparison: ">="
threshold: 80.0
period: 300
evaluation_periods: 3
unit: "Percent"
dimensions: {'InstanceId':"{{ item.id }}"}
loop: "{{ new.instances }}"В create-instance.yaml происходит: создание инстанса с правильными параметрами, тегирование этого инстанса и создание необходимых алармов. Также через user-data передаётся скрипт установки и настройки nginx. User-data обрабатывается сервисом cloud-init, который позволяет производить гибкую настройку инстанса во время запуска, не прибегая к использованию других средств автоматизации.
В update-lb.yaml происходит пересоздание /etc/haproxy/haproxy.cfg файла на haproxy инстансе и reload haproxy сервиса:
- name: update haproxy configs
template:
src: haproxy.cfg.j2
dest: /etc/haproxy/haproxy.cfg
- name: add new backend host to haproxy
systemd:
name: haproxy
state: restartedГде haproxy.cfg.j2 — шаблон файла конфигурации сервиса haproxy:
# {{ ansible_managed }}
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend loadbalancing
bind *:80
mode http
default_backend backendnodes
backend backendnodes
balance roundrobin
option httpchk HEAD /
{% for host in groups['tag_role_backend'] %}
server {{hostvars[host]['ec2_id']}} {{hostvars[host]['ec2_private_ip_address']}}:8080 check
{% endfor %}Так как в секции backend конфига haproxy определена опция option httpchk, сервис haproxy будет самостоятельно опрашивать состояния backend инстансов и балансировать траффик только между прошедшими health check.
В scale_down части необходимо:
- проверить стейт low аларма;
- досрочно закончить выполнение play, если отсутствуют low алармы в стейте "Alarm";
- терминировать все инстансы, у которых low alarm находится в стейте "Alarm";
- запретить терминацию последней пары инстансов, даже если их алармы находятся в стейте "Alarm";
- удалить из конфигурации load balancer инстансы, которые мы удалили.
- name: look for alarm status
describe_alarms:
region: "croc"
alarm_name_prefix: "scaling-low"
alarm_state: "alarm"
register: describe_alarms_query
- name: count alarmed instances
set_fact:
alarmed_count: "{{ describe_alarms_query.meta | length }}"
alarmed_ids: "{{ describe_alarms_query.meta }}"
- name: stop if no alarms
fail:
msg: no alarms fired
when: alarmed_count | int == 0
- name: count all described instances
set_fact:
all_count: "{{ groups['tag_role_backend'] | length }}"
- name: fail if last two instance remaining
fail:
msg: cant destroy last two instances
when: all_count | int == 2
- name: destroy tags for marked instances
ec2_tag:
ec2_url: "https://api.cloud.croc.ru"
region: croc
resource: "{{ alarmed_ids[0].split('_')[1] }}"
state: absent
tags:
role: backend
- name: destroy instances
ec2:
region: croc
state: absent
instance_ids: "{{ alarmed_ids[0].split('_')[1] }}"
- name: destroy low alarms
ec2_metric_alarm:
state: absent
region: croc
name: "scaling-low_{{ alarmed_ids[0].split('_')[1] }}"
- name: destroy high alarms
ec2_metric_alarm:
state: absent
region: croc
name: "scaling-high_{{ alarmed_ids[0].split('_')[1] }}"В destroy-instance.yaml происходит удаление алармов, терминация инстанса и его тега, проверка условий запрещающих терминацию последних инстансов.
Мы явно удаляем теги после удаления инстансов в связи с тем, что после удаления инстанса связанные с ним теги удаляются отложенно и доступны ещё в течение минуты.
AWX.
Настройка задач, шаблонов
Следующий набор tasks создаст необходимые сущности в AWX:
---
- name: Create tower organization
tower_organization:
name: "scaling-org"
description: "scaling-org organization"
state: present
- name: Add tower cloud credential
tower_credential:
name: cloud
description: croc cloud api creds
organization: scaling-org
kind: aws
state: present
username: "{{ croc_user }}"
password: "{{ croc_password }}"
- name: Add tower github credential
tower_credential:
name: ghe
organization: scaling-org
kind: scm
state: present
username: "{{ ghe_user }}"
password: "{{ ghe_password }}"
- name: Add tower ssh credential
tower_credential:
name: ssh
description: ssh creds
organization: scaling-org
kind: ssh
state: present
username: "ec2-user"
ssh_key_data: "{{ lookup('file', 'private.key') }}"
- name: Add tower project
tower_project:
name: "auto-scaling"
scm_type: git
scm_credential: ghe
scm_url: <repo-name>
organization: "scaling-org"
scm_branch: master
state: present
- name: create inventory
tower_inventory:
name: dynamic-inventory
organization: "scaling-org"
state: present
- name: copy inventory script to awx
copy:
src: "{{ role_path }}/files/ec2.py"
dest: /root/ec2.py
- name: create inventory source
shell: |
export SCRIPT=$(tower-cli inventory_script create -n "ec2-script" --organization "scaling-org" --script @/root/ec2.py | grep ec2 | awk '{print $1}')
tower-cli inventory_source create --update-on-launch True --credential cloud --source custom --inventory dynamic-inventory -n "ec2-source" --source-script $SCRIPT --source-vars '{"EC2_URL":"api.cloud.croc.ru","AWS_REGION": "croc"}' --overwrite True
- name: Create create-instance template
tower_job_template:
name: "create-instance"
job_type: "run"
inventory: "dynamic-inventory"
credential: "cloud"
project: "auto-scaling"
playbook: "create-instance.yaml"
state: "present"
register: create_instance
- name: Create update-lb template
tower_job_template:
name: "update-lb"
job_type: "run"
inventory: "dynamic-inventory"
credential: "ssh"
project: "auto-scaling"
playbook: "update-lb.yaml"
credential: "ssh"
state: "present"
register: update_lb
- name: Create destroy-instance template
tower_job_template:
name: "destroy-instance"
job_type: "run"
inventory: "dynamic-inventory"
project: "auto-scaling"
credential: "cloud"
playbook: "destroy-instance.yaml"
credential: "ssh"
state: "present"
register: destroy_instance
- name: create workflow
tower_workflow_template:
name: auto_scaling
organization: scaling-org
schema: "{{ lookup('template', 'schema.j2')}}"
- name: set scheduling
shell: |
tower-cli schedule create -n "3min" --workflow "auto_scaling" --rrule "DTSTART:$(date +%Y%m%dT%H%M%SZ) RRULE:FREQ=MINUTELY;INTERVAL=3"Предыдущий сниппет создаст по template на каждый из используемых ansible playbook'ов. Каждый template конфигурирует запуск playbook набором определённых credentials и inventory.
Построить pipe для вызовов playbook'ов позволит workflow template. Настройка workflow для автоскейлинга представлена ниже:
- failure_nodes:
- id: 101
job_template: {{ destroy_instance.id }}
success_nodes:
- id: 102
job_template: {{ update_lb.id }}
id: 103
job_template: {{ create_instance.id }}
success_nodes:
- id: 104
job_template: {{ update_lb.id }}В предыдущем шаблоне представлена схема workflow, т.е. последовательность выполнения template'ов. В данном workflow каждый следующий шаг (success_nodes) будет выполнен только при условии успешного выполнения предыдущего. Графическое представление workflow представленно на картинке:
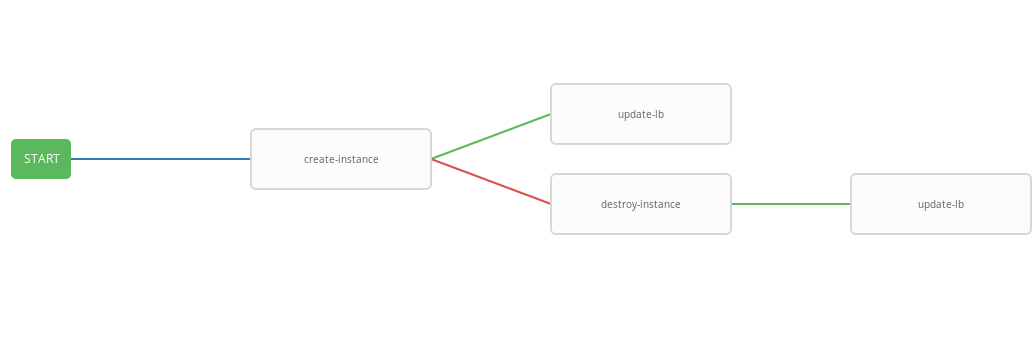
В итоге был создан обобщающий workflow, который выполняет create-instace playbook и, в зависимости от статуса выполнения, destroy-instance и/или update-lb playbook'и. Объединённый workflow удобно запускать по заданному расписанию. Процесс автоскейлинга будет запускаться каждые три минуты, запуская и терминируя инстансы в зависимости от стейта алармов.
Тестирование работы
Теперь проверим работу настроенной системы. Для начала установим wrk-утилиту для http бенчмаркинга.
ssh -A ec2-user@<aws_instance_ip>
sudo su -
cd /opt
yum groupinstall 'Development Tools'
yum install -y openssl-devel git
git clone https://github.com/wg/wrk.git wrk
cd wrk
make
install wrk /usr/local/bin
exitВоспользуемся облачным мониторингом для наблюдения за использованием ресурсов инстанса во время нагрузки:
function CPUUtilizationMonitoring() {
local AWS_CLI_PROFILE="<aws_cli_profile>"
local CLOUDWATCH_URL="https://monitoring.cloud.croc.ru"
local API_URL="https://api.cloud.croc.ru"
local STATS=""
local ALARM_STATUS=""
local IDS=$(aws --profile $AWS_CLI_PROFILE --endpoint-url $API_URL ec2 describe-instances --filter Name=tag:role,Values=backend | grep -i instanceid | grep -oE 'i-[a-zA-Z0-9]*' | tr '\n' ' ')
for instance_id in $IDS; do
STATS="$STATS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch get-metric-statistics --dimensions Name=InstanceId,Value=$instance_id --namespace "AWS/EC2" --metric CPUUtilization --end-time $(date --iso-8601=minutes) --start-time $(date -d "$(date --iso-8601=minutes) - 1 min" --iso-8601=minutes) --period 60 --statistics Average | grep -i average)";
ALARMS_STATUS="$ALARMS_STATUS$(aws --profile $AWS_CLI_PROFILE --endpoint-url $CLOUDWATCH_URL cloudwatch describe-alarms --alarm-names scaling-high-$instance_id | grep -i statevalue)"
done
echo $STATS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t
echo $ALARMS_STATUS | column -s ',' -o '|' -N $(echo $IDS | tr ' ' ',') -t
}
export -f CPUUtilizationMonitoring
watch -n 60 bash -c CPUUtilizationMonitoringПредыдущий скрипт раз в 60 секунд забирает информацию о среднем значении метрики CPUUtilization за последнюю минуту и опрашивает состояние алармов для backend инстансов.
Теперь можно запустить wrk и посмотреть на утилизацию ресурсов backend инстансов под нагрузкой:
ssh -A ec2-user@<awx_instance_ip>
wrk -t12 -c100 -d500s http://<haproxy_instance_id>
exitПоследняя команда запустит бенчмарк на 500 секунд, используя 12 потоков и открыв 100 http соединений.
В течение времени скрипт мониторинга должен показать, что во время действия бенчмарка значение статистики метрики CPUUtilization увеличивается пока не дойдёт до значений 300%. Через 180 секунд после начала бенчмарка флаг StateValue должен переключиться в состояние Alarm. Раз в две минуты происходит запуск autoscaling workflow. По умолчанию, параллельное выполнение одинаковых workflow запрещено. То есть каждые две минуты задача на выполнение workflow будет добавлена в очередь и будет запущена только после завершения предыдущей. Таким образом во время работы wrk будет происходить постоянное наращивание ресурсов, пока high алармы всех backend инстансов не перейдут в состояние OK. По завершению выполнения wrk scale_down workflow терминирует все backend инстансы за исключением двух.
Пример вывода скрипта мониторинга:
# start test
i-43477460 |i-AC5D9EE0
"Average": 0.0 | "Average": 0.0
i-43477460 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"
# start http load
i-43477460 |i-AC5D9EE0
"Average": 267.0 | "Average": 111.0
i-43477460 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"
# alarm state
i-43477460 |i-AC5D9EE0
"Average": 267.0 | "Average": 282.0
i-43477460 |i-AC5D9EE0
"StateValue": "alarm"| "StateValue": "alarm"
# two new instances created
i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0
"Average": 185.0 | "Average": 215.0 | "Average": 245.0 |
i-1E399860 |i-F307FB00 |i-43477460 |i-AC5D9EE0
"StateValue": "insufficient_data"| "StateValue": "insufficient_data"| "StateValue": "alarm"| "StateValue": "alarm"
# only two instances left after load has been stopped
i-935BAB40 |i-AC5D9EE0
"Average": 0.0 | "Average": 0.0
i-935BAB40 |i-AC5D9EE0
"StateValue": "ok"| "StateValue": "ok"Также в Облаке КРОК есть возможность просмотра графиков используемого в посте мониторинга на странице инстанса на соответствующей вкладке.
Просмотр алармов доступен на странице мониторинга на вкладке алармы.
Заключение
Автоскейлинг довольно популярный сценарий, но, к сожалению, в нашем облаке его пока нет (но только пока). Однако у нас достаточно много мощного API, чтобы делать подобные и многие другие вещи, используя популярные, можно сказать почти стандартные, инструменты такие как: Terraform, ansible, aws-cli и прочие.