
Привет, Хабр! Я участвую в разработке ECM системы. И в небольшом цикле статей хочу поделится нашим опытом и историей разработки своего React Data Grid (далее просто грид), а именно:
- почему мы отказались от готовых компонент
- с какими проблемами и задачами мы столкнули при разработке своего грида
- какой профит дает разработка своего грида
Предыстория
У нашей системы есть веб-приложение, в котором пользователи работают со списками документов, результатами поисков, справочниками. Причем, списки могут быть как маленькие (10 сотрудников), так и очень большие (50 000 контрагентов). Для отображения этих списков мы разработали свой грид:
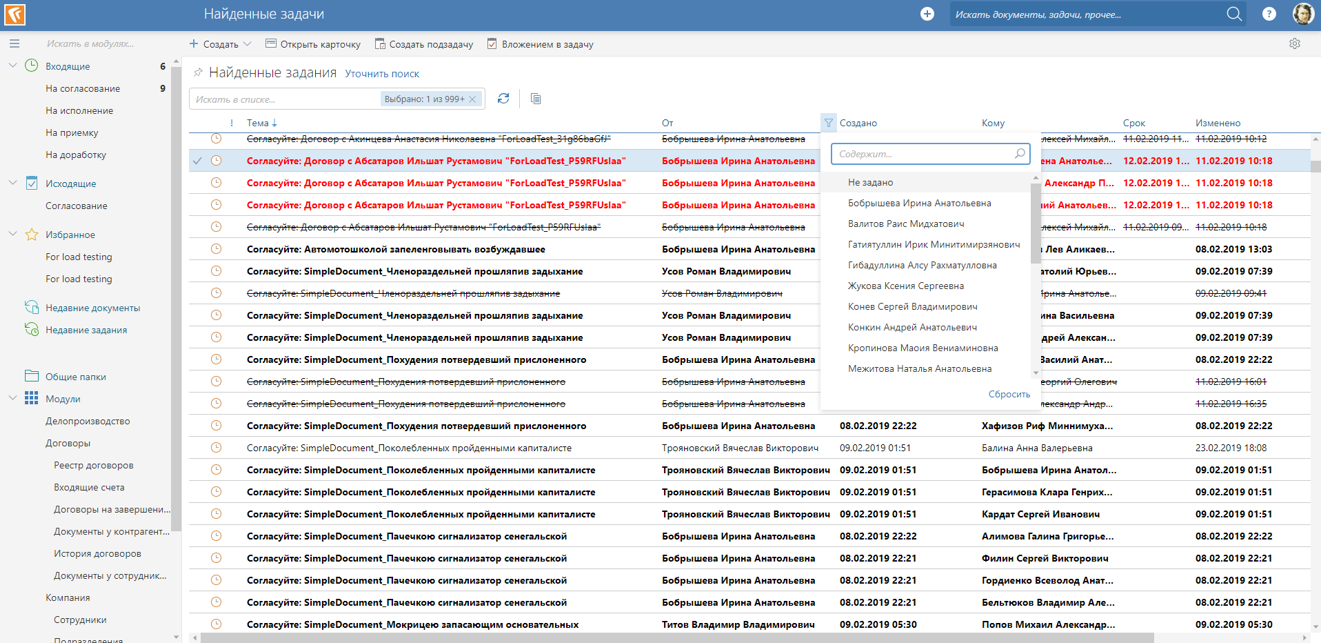
Когда мы только приступили к разработке веб-приложения, захотелось найти готовую библиотеку для отображения грида, которая умеет делать все, что нам надо: сортировать и группировать записи, перетаскивать и растягивать колонки, работать с множественным выделением, фильтровать и подсчитывать итоги по колонкам, порционно загружать данные с сервера и отображать десятки тысяч записей.
Поясню последнее требование «отображать десятки тысяч записей». В гридах это требование реализуется несколькими способами: paging, infinity scrolling, virtual scrolling.
Подходы paging и infinity scrolling распространены на веб сайтах, вы ими пользуетесь каждый день. Например, paging в Гугле:

Или infinity scrolling в том же Гугле по картинкам, где следующая порция картинок загружается, когда пролистаешь до конца первую порцию:

А вот virtual scrolling (далее буду называть виртуальный скроллинг) используется в вебе редко, его основное отличие от infinity scrolling?—?это возможность быстро проскролить в любое место очень больших списков. При этом будут загружены и отображены только видимые пользователю данные.
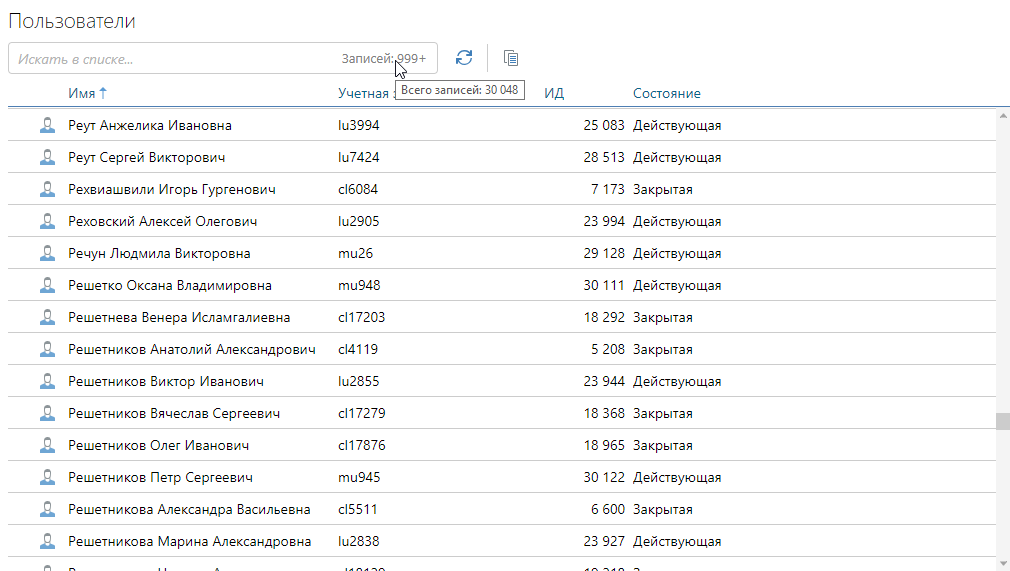
Для нашего веб-приложения хотелось использовать виртуальный скроллинг. Соглашусь, что скроллинг в любое место списка из 10.000 записей — кейс скорее выдуманный. Однако, произвольный скроллинг в пределах 500–1000 записей — кейс живой.
Когда реализуют виртуальный скроллинг, часто реализуют и программное API управления этим скроллингом. Это очень важная фича. Программный скроллинг используют, например, для позиционирования выделенной записи по середине экрана при открытии справочника:
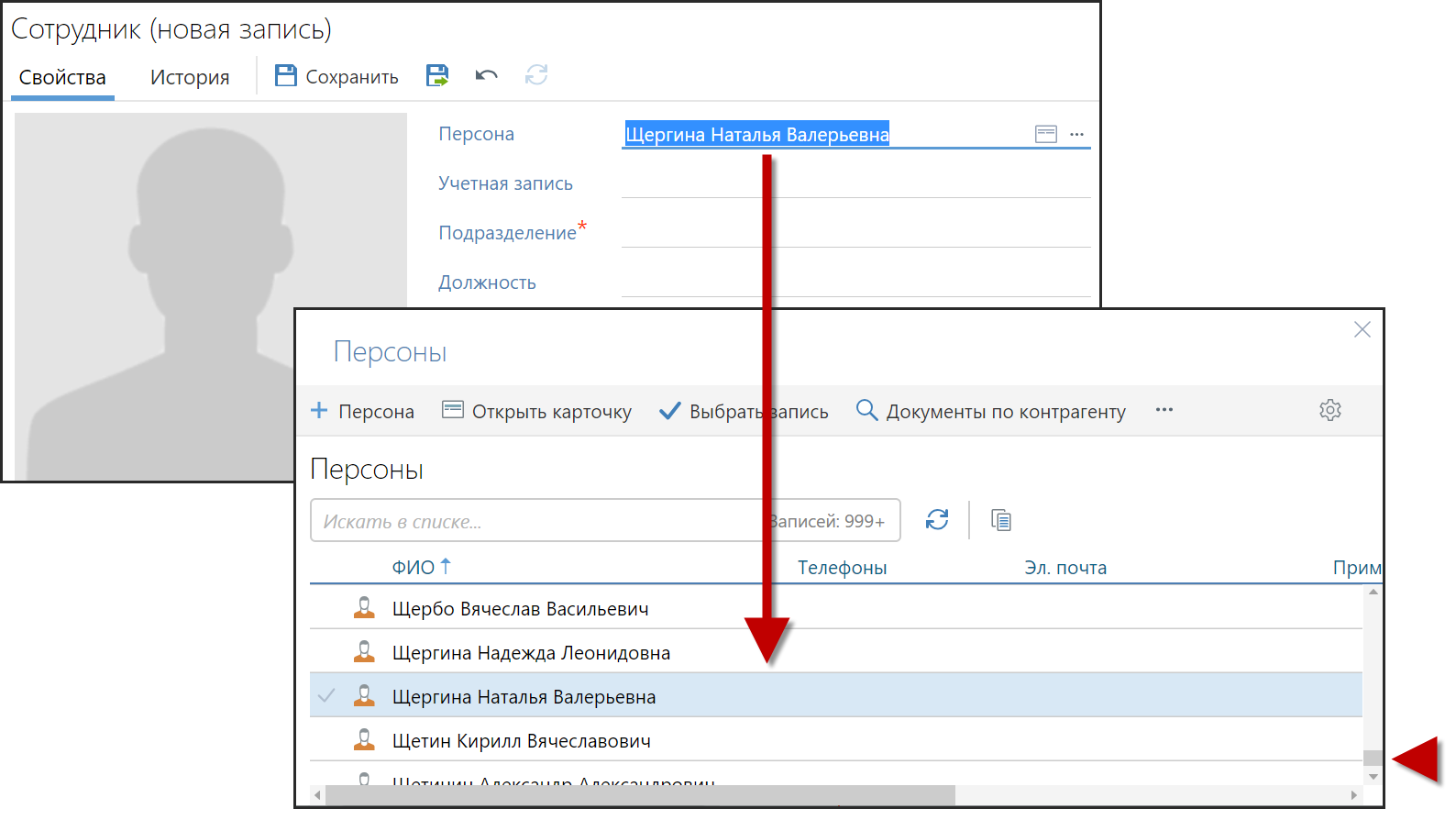
Вернемся к требованиям. Что еще нам было нужно:
- Программное API управления виртуальным скроллингом
- Кастомизация внешнего вида грида (строк, колонок, контекстного меню), чтобы грид не выглядел инородно в нашем приложении
- Поддержка используемых нами технологий: react, redux и flexbox
- Чтобы грид работал в ie11
В общем, требований было много.
Попытка первая (2016 год). DevExtreme JavaScript Data Grid
Не долго исследуя существующие библиотеки, мы наткнулись на DevExtreme JavaScript Data Grid. По функциональным требованиям этот грид закрывал все наши потребности и имел очень презентабельный внешний вид. Однако по технологическим требованиям не подходил (не react, не redux, не flexbox). На тот момент у DevExtreme не было react грида.
Ну и пусть не react, решили мы, за то грид красивый и функциональный, будем использовать его. И добавили библиотеку себе в проект. Оказалось, мы добавили 3 Мб скриптов.
За пару недель мы интегрировали грид в наше веб-приложение и подняли основной функционал:
- Написали обертку над гридом, чтобы подружить его с react и redux
- Подняли виртуальный скроллинг и порционную загрузку данных с нашего веб-сервера
- Реализовали сортировку и выделение
По ходу прикручивания грида выяснились две серьезные проблемы и целый ворох менее серьезных.
Первая серьезная проблема
Подружить DevExtreme JavaScript Data Grid с redux очень сложно. У нас получилось управлять настройками колонок и выделением записей через redux, но хранить порционно загружаемые данные в redux, и выполнять над ними CRUD операции через redux? — ?это нереально. Пришлось делать костыль, который в обход redux манипулировал данными грида. Костыль получился сложным и хрупким. Это был первый тревожный звоночек, что грид нам не подходит, но мы продолжили его вкручивать.
Вторая серьезная проблема
Нет API управления виртуальным скроллингом. От программного управления скроллингом мы не могли отказаться, пришлось перешерстить исходники DevExtreme и найти внутреннее API управления скроллингом. Конечно, у этого API была гора ограничений, ведь оно было рассчитано на внутреннее использование. В итоге мы добились, чтобы внутреннее API более-менее работало на наших кейсах, но, опять в обход redux, и опять куча костылей.
Менее серьезные проблемы
Менее серьезные проблемы всплывали постоянно, потому что стандартный функционал DevExtreme JavaScript Data Grid нам подходил не полностью, и мы пытались его корректировать:
- Растягивание DevExtreme грида по высоте не работает. Пришлось написать хак, чтобы научить DevExtreme это делать (возможно в последних версиях с этим уже нет проблем).
- Когда фокус не в гриде, то нельзя управлять выделением строк через клавиатуру (а нам это требовалось). Пришлось написать свое управление клавиатурой.
- При изменении состава колонок и смены данных у нас была проблема моргания данных (при включенном виртуальном скроллинге).
- Проблема большого числа запросов при первом показе грида. Особенно было заметно, когда мы управляли скроллингом через внутреннее API.
- Тяжело кастомизировать некоторые части UI грида. Например, было желание поверх выделенной строки грида нарисовать действия управления строкой (удалить строку, копировать, открыть карточку). Но как это вкрутить в DevExtreme было не понятно, да еще с помощью react:
- Тяжело катомизировать сортировку (мы хотели сортировать по данным, которые не отображены в гриде, и не замаплены в колонки).
- Требуются костыли для вкручивания react компонент в ячейки грида (ведь грид не на react).
- Никакой типизации DevExtreme кода (flow/typescript).
- Проблема скорости при длительном виртуальном скроллинге.
- Проблема скорости при растягивании/перестановке колонок (после длительного виртуального скроллинга).
- Размер скриптов грида — 3 Мб.
Хотя DevExtreme грид по функциональности содержал все что нам надо, но почти весь стандартный функционал хотелось переписать. За время его использования были добавлены сотни строк сложного для понимания кода, который пытался решить проблемы взаимодействия с redux и react, было сложно использовать не react грид в react приложении.
Отказ от DevExtreme. Поиск альтернатив
Спустя некоторое время использования DevExtreme было решено отказаться от него. Выкинуть все хаки, сложный код, а также 3 Мб скриптов DevExtreme. И найти или написать новый грид.
На этот раз, мы внимательнее отнеслись к исследованию существующих гридов. Были изучены MS Fabric DetailsList, ReactVirtualized Grid, DevExtreme React Grid, Telerik Grid, KendoUI Grid.
Требования остались те же, но уже оформились в понятный нам список.
Требования к технологиям:
- react
- redux
- flexbox
Требования к функционалу:
- Виртуальный скроллинг (с возможностью показывать десятки тысяч записей)
- API управления скроллингом
- Хранение данных и настроек грида в redux
- Порционная загрузка данных с веб-сервера
- Управление колонками (растягивание/перестановка/управление видимостью)
- Сортировка + фильтрация по колонкам
- Множественное выделение
- Like-поиск с подсветкой
- Горизонтальный скроллинг
- Работа с клавиатуры
- Контекстное меню (на строке, на пустой области, на колонках)
- Поддержка ie11, edge, chrome, ff, safari
К этому моменту уже появился первая версия DevExtreme React Grid, но мы сразу же отбросили его по следующим причинам:
- Виртуальный скроллинг не поддерживается в ie11
- Виртуальный скроллинг не работает совместно с порционной загрузкой данных с сервера (хотя вроде есть какие-то обходные пути).
- И самое главное, не захотелось наступать на те же грабли, когда хочется переписать половину стандартного функционала стороннего грида.
Анализ существующих решений показал, что «серебряной пули» нет. Грид, который закрыл бы все наши требования, не существует. Было решено писать свой грид, который по функциональности будем развивать в нужную нам сторону, и дружить с технологиями нужными нашему продукту.
Разработка своего React Data Grid
Разработку грида начали с прототипов, где опробовали самые сложных для нас темы:
- виртуальный скроллинг
- хранение всех данных грида в Redux
Virtual scrolling
Самым сложным оказалась сделать виртуальный скроллинг. По-крупному, его делают одним из 3-х способов:
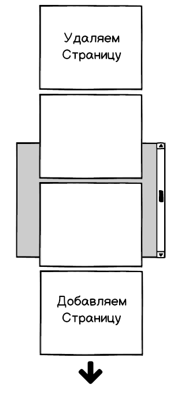
1. Постраничная виртуализация
Данные рисуются порциями — страницами. При скроллинге видимые страницы добавляются, невидимые удаляются. Страница состоит из 20-60 строк (обычно размер настраивается). Таким путем пошли продукты: DevExtreme JavaScript Data Grid, MS Fabric DetailsList.
2. Построчная виртуализация
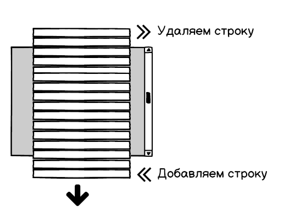
Рисуются только видимые строки. Как только строка уходит за экран, она сразу же удаляется. Этим путем пошли продукты: ReactVirtualized Grid, DevExtreme React Grid, Telerik Grid.
3. Canvas
Все строки и их содержимое рисуют с помощью Canvas. Так сделали в Google Docs.
При разработке грида мы сделали прототипы для всех трех вариантов виртуализации (даже для Canvas). И выбрали постраничную виртуализацию.
Почему отказались от других вариантов?
У построчной виртуализации были проблемы со скоростью отрисовки в прототипе. Как только усложнялось содержимое строк (много текста, подсветка, тримминг, иконки, большое число колонок, и везде flexbox), то дорого становилось добавлять/удалять строки по несколько раз за секунду. Конечно, результаты зависят и от браузера (мы делали поддержку в том числе для ie11, edge):

Вариант с Canvas был очень соблазнительный по скорости отрисовки, но трудоемкий. Предлагалось нарисовать все: текст, перенос текста, тримминг текста, подсветка, иконки, разделительные линии, выделение, отступы. Сделать реакцию на нажатие кнопок мышки на Canvas, подсветку строк при наведении курсора. При этом, поверх Canvas следовало наложить некоторые Dom-элементы (показ хинтов, «высплывающие действия» над строкой). Еще требовалось решить проблему размытости текста и иконок в Canvas. Все это долго делать и сложно. Хотя прототип мы осилили. При этом любая кастомизация строк и ячеек в будущем нам бы вылилась в большую трудоемкость.
Плюсы постраничной виртуализации
У выбранной постраничной виртуализации были плюсы по сравнению с построчной, которые определили ее выбор:
- Если страница уже отрисована, то скроллинг внутри страницы стоит дешево (DOM дерево не меняется при скроллинге). Построчная же виртуализация при любом незначительном скроллинге требует изменения DOM дерева, а это дорого, когда DOM дерево сложное и повсеместно используется flexbox.
- Для небольших списков (<200 записей) страницы можно не удалять, только добавлять. Рано или поздно все страницы будут построены, и скроллинг будет полностью бесплатным (с точки зрения времени отрисовки).
Выбор размера страницы
Отдельный вопрос – это выбор размера страницы. Выше я писал, что размер настраивается и обычно составляет 20-60 строк. Большая страница долго рисуется, маленькая приводит к частому показу «белого экрана» при скроллинге. Экспериментальным путем был выбран размер страницы 25 строк. Однако для ie11 размер был уменьшен до 5 строк. По ощущениям, интерфейс в IE отзывчивее, если рисовать с небольшими задержками много мелких страниц, чем одну крупную с большой задержкой.
React и virtual scrolling
Постраничную виртуализацию нужно было реализовать с использованием react. Для этого следовало решить несколько задач:
Задача 1. Как добавлять/удалять страницы через react при скроллинге?
Для решения этой задачи ввели понятия:
- модель страницы
- представление страницы
Модель – это информация, по которой можно построить представление. Представление – это React-компонента.

По сути, задача виртуализации после этого сводилась к манипулированию моделями страниц: хранить список моделей страниц, добавлять и удалять модели при скроллинге. И уже по списку моделей через react строить/перестраивать отображение:

По ходу реализации сформировались правила работы с моделями страниц:
- Страницы следует добавлять по одной штуке. После каждого добавления дать время на отрисовку. Приемлемо добавлять 1 страницу каждые 300-500мс — это ситуация быстрого скроллинга. Если добавить, например, сразу 5 страниц, то у пользователя зависнет интерфейс на их построении.
- Страницы не нужно держать десятками. Пример проблемной ситуации: отображено 20 страниц, пользователь переходит в другой список и все 20 страниц нужно разом удалить. Удаление большого числа страниц — дорогая операция, зачистка DOM дерева займет 1 секунду. Чтобы этого избежать лучше держать одновременно не больше 10 страниц.
- При любом манипулировании колонками (перестановка, добавление, удаление, растягивание) лучше удалить невидимые пользователю страницы заранее. Это позволит избежать дорогого перестроения всех отрисованных страниц.
Задача 2. Как отобразить scollbar?
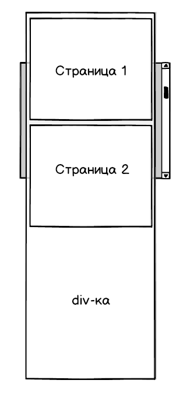
Виртуальный скроллинг предполагает, что доступен scrollbar, который учитывает размеры списка и позволяет выполнить скроллинг в любое место:

Как отобразить такой scollbar? Самое простое решение — вместо реальных данных рисуем невидимую div-ку нужного размера. И уже поверх этой div-ки отображаем видимые страницы:
Задача 3. Как следить за размером viewport?
Viewport – это видимая область данных грида. Зачем следить за ее размером? Чтобы вычислить число страниц, которые нужно отобразить пользователю. Предположим, у нас маленький размер страницы (5 строк) и большое разрешение экрана (1920x1080). Сколько страниц надо отобразить пользователю, чтоб закрыть весь viewport?
Решить эту задачу можно, если знать высоту viewport и высоту одной страницы. Теперь усложним задачу, предположим пользователь резко меняет масштаб в браузере – задает 50%:
Ситуация с масштабом показывает, что мало один раз узнать размер viewport, за размером надо следить. И теперь совсем усложним задачу: у html-элементов нет события resize, на которое можно подписаться и следить за размером. Resize есть только у объекта window.
Первое, что приходит в голову – использовать таймер и постоянно опрашивать высоту html-элемента. Но есть решение еще лучше, которое мы увидели у DevExtreme JavaScript Data Grid: создать невидимый iframe, растянуть его на размер грида и подписаться на событие resize у iframe.contentWindow:


Резюме
P.S. Это еще не конец. В следующей статье я расскажу как мы подружили наш грид с redux.
Чтобы получить полноценный виртуальный скроллинг пришлось решить еще множество других задач. Но те, что описаны выше были самими интересными. Вот на вскидку еще несколько задач, которые тоже всплывали:
- Учитывать направление и скорость скроллинга при добавлении/удалении страниц.
- Учитывать изменение данных, чтобы минимально перестраивать модели страницы. К примеру, удалили одну строку, или добавили строку, что делать с уже отрисованными страницами? Все выкинуть, или какие-то оставить? Тут есть простор для оптимизаций.
- При смене выделения перестроить минимально необходимое число страниц.
Если есть вопросы по реализации, можете писать их в комментариях.
Комментарии (20)

bromzh
25.06.2019 13:29Ag-grid не смотрели? Виртуальный скрол, много чего умеет даже в бесплатной версии, большой простор для кастомизации, есть возможность (хоть и не так просто) интеграции с редуксом.

AlexanderShutov Автор
25.06.2019 14:04Не смотрели.
У нас в отделе прослеживается такая тенденция: берем стороннюю компоненту, понимаем что нас не устраивает ее внешний вид, поведение, работа с клавиатурой, фокусом, не хватает каких-либо возможностей. И начинаем все вылизывать, докручивать, переделывать в этой компоненте, учить ее работать с тем с чем она не умеет работать. И это не разовая работа, по ходу развития проекта появляются новые требования к уже используемым компонентам.
Это тоже сыграло роль в принятии решения.bromzh
25.06.2019 14:35А сколько в итоге времени ушло на реализацию? И сколько человек это разрабатывало?
AlexanderShutov Автор
25.06.2019 15:05На прототипирование основных механизмов (виртуализация, работа с колонками, проционно загружаемые данные) потратили ~80 чч (человеко-часов). Два человека в течении недели полный рабочий день.
А затем составили детальный список всех работ, и это оказался очень большой список:
работа с redux, выделение, навигация, фокус, удаление-добавление записей, проверка инконсистентности, сокращение числа запросов при первом открытии, стили колонок/строк, работа с колонками (растягивание/перестановка/скрытие/сортировка/запрет перестановки), нет данных, выравнивание теста, триминг, контекстные меню, количество записей, поддержка автотестов, фильтры по колонкам, like-поиск, сохранение/восстановление настроек.
Все это делали долго, наверное, полгода. Примерно ~500 чч
В итоге по трудоемкости мы вложились сильно в грид. Компания нам такую возможность дала — отказаться от DevExtreme и все переписать.
shurman
25.06.2019 14:14Хочется сказать отдельное спасибо за статью от команды DevExtreme. Такой фидбек о реальном использовании наших продуктов крайне ценен. Многие упомянутые проблемы мы сами видим, разделяем и планомерно устраняем. Совсем недавно мы добавили возможность использовать виртуальный скроллинг с ленивой загрузкой данных с сервера в нативный DevExtreme React Grid.
Также теперь мы даем из коробки React обертку для DevExtreme JavaScript DataGrid. В некоторых сценариях, трудности с управлением внутренним состоянием компонента действительно есть, работаем над этим :)

Hydro
25.06.2019 16:38Еще бы примеров с кодом побольше выложили, а лучше сам грид в публичный доступ.
Тяжело понимать контекст.
AlexanderShutov Автор
25.06.2019 17:20Давно хотим выложить грид в публичный доступ. Организационно проблем нет. Но есть проблемы с трудоемкостью: выделить его в отдельный проект, отвязать от нашей платформы, от завязок на некоторые компоненты (надо часов 50). Трудоемкость оценили, но времени нам пока на это не дали
AndrewKoltyakov
27.06.2019 11:49Приятно видеть, что DIRECTUM идет в таком направлении. И, особенно, что в статье даже ни слова о бренде не упонянуто.
С гридами в целом вообще беда, безкомпромиссных решений, где был бы набор всего, что в гриде требуется, вообще по ходу дела не существует (и в платных компонентах в том числе). Везде чего-то не хватает и приходится допиливать несвойственное поведение обходными путями. По рынку, ag-Grid, пожалуй, самый достойный из всех.
JustDont
… и с этого места становится непонятным, зачем велосипед. Таблица на 10 000 записей с сложной структурой строки — это тяжело и медленно, и действительно нужно комплексное решение. Но 10 000 записей никому нафиг не впилось пролистывать, как вы правильно заметили.
Таблица же на 1000 записей спокойнейше отработает без особого шаманства с виртуализацией, достаточно лишь ленивой подгрузки (то есть, ровно половину усилий от виртуализации).
AlexanderShutov Автор
Думаю инфинити скроллинг для нашего продукта тоже подошел бы (ленивая загрузка по мере прокрутки). Но есть справочники, в которых удобнее искать запись быстрой прокруткой в нужную часть списка (например, сотрудники, подразделения, города).
Возьмем, к примеру, 1С. В их справочниках же нет инфинити скроллинга, и думаю, если бы он появился, то использовать справочники стало бы менее удобно.
JustDont
Серьезно? Нет. Идеальным вариантом для вас было бы отучить людей «искать через скролл» и сделать хороший, быстрый, и легко юзабельный поиск, который бы на 1-2 буквы мгновенно бы сужал таблицу до вменяемого количества строк.
Но да, иногда бывает сложно противостоять запросам юзеров на кривые решения.
AlexanderShutov Автор
Мы закрыли одновременно два кейса: удобный поиск (он легко юзабельный, но не мгновенный), и кейс «искать через скролл»:

JustDont
Есть вариант не по вхождениям, а с начала строки? Есть по каждому столбцу отдельно?
Если есть, то согласен, что он у вас наверное удобный ^_^
AlexanderShutov Автор
Есть только по вхождениям и по столбцам.

JustDont
Я б таки добавил с начала строки и где-то бы в метаданных это сконфигурировал: вещи типа ФИО, городов, и пр — гораздо эффективнее ищутся по началу строки. Даже наверное и юзеру не обязательно давать менять тип поиска.
Алсо, комплексные данные типа ФИО в одном столбце может быть имеет смысл давать искать раздельно (по Ф, И, О) — но это конечно уже зависит от ваших кейсов.
mayorovp
Таблица на 1000 записей спокойно отработает и без ленивой подгрузки...
opxocc
А никто не знает, что там будет у клиента, 1000 записей или 100000 записей.
JustDont
Зависит от того, сколько понапихано в каждую строку. Задержки на рендер 1000 строк я своими глазами видел, на голом и очень быстро работающем js, вот чисто рендер долгий, из-за того, что каждая строка у нас была довольно монструозная.
AlexanderShutov Автор
У нас (в системе) есть две проблемы:
1. Дорого за раз выкачать 1000 записей (как по скорости, та и по объему передаваемых данных). Веб-сервер тратит 500 мс на формирование ответа в 100 записей, размер ответа = 200 Кб.
2. Дорого отрисовать за раз 1000 записей. У каждой строки очень сложна разметка (я писал про это выше).
По этому для нас оптимально выкачивать и отрисовать за раз 50-60 записей. А дальше выкачивать и рисовать по мере скроллинга.