
 Привет, Хаброжители! Если вам давно кажется, что вся разработка и развертывание в вашей компании донельзя замедлились — переходите на микросервисную архитектуру. Она обеспечивает непрерывную разработку, доставку и развертывание приложений любой сложности.
Привет, Хаброжители! Если вам давно кажется, что вся разработка и развертывание в вашей компании донельзя замедлились — переходите на микросервисную архитектуру. Она обеспечивает непрерывную разработку, доставку и развертывание приложений любой сложности.Книга, предназначенная для разработчиков и архитекторов из больших корпораций, рассказывает, как проектировать и писать приложения в духе микросервисной архитектуры. Также в ней описано, как делается рефакторинг крупного приложения — и монолит превращается в набор микросервисов.
Предлагаем ознакомиться с отрывком «Управление транзакциями в микросервисной архитектуре»
Почти любой запрос, обрабатываемый промышленным приложением, выполняется в рамках транзакции базы данных. Разработчики таких приложений используют фреймворки и библиотеки, которые упрощают работу с транзакциями. Некоторые инструменты предоставляют императивный API для выполняемого вручную начала, фиксации и отката транзакций. А такие фреймворки, как Spring, имеют декларативный механизм. Spring поддерживает аннотацию @Transactional, которая автоматически вызывает метод в рамках транзакции. Благодаря этому написание транзакционной бизнес-логики становится довольно простым.
Если быть более точным, управлять транзакциями просто в монолитных приложениях, которые обращаются к единой базе данных. Если же приложение задействует несколько БД и брокеров сообщений, этот процесс затрудняется. Ну а в микросервисной архитектуре транзакции охватывают несколько сервисов, каждый из которых имеет свою БД. В таких условиях приложение должно использовать более продуманный механизм работы с транзакциями. Как вы вскоре увидите, традиционный подход к распределенным транзакциям нежизнеспособен в современных приложениях. Вместо него системы на основе микросервисов должны применять повествования.
Но прежде, чем переходить к повествованиям, посмотрим, почему управление транзакциями создает столько сложностей в микросервисной архитектуре.
4.1.1. Микросервисная архитектура и необходимость в распределенных транзакциях
Представьте, что вы — разработчик в компании FTGO и отвечаете за реализацию системной операции createOrder(). Как было написано в главе 2, эта операция должна убедиться в том, что заказчик может размещать заказы, проверить детали заказа, авторизовать банковскую карту заказчика и создать запись Order в базе данных. Реализация этих действий была бы относительно простой в монолитном приложении. Все данные, необходимые для проверки заказа, уже готовы и доступны. Кроме того, для обеспечения согласованности данных можно было бы использовать ACID-транзакции. Вы могли бы просто указать аннотацию @Transactional для метода сервиса createOrder().
Однако выполнить эту операцию в микросервисной архитектуре гораздо сложнее. Как видно на рис. 4.1, данные, необходимые операции createOrder(), разбросаны по нескольким сервисам. createOrder() считывает информацию из сервиса Consumer и обновляет содержимое сервисов Order, Kitchen и Accounting.
Поскольку у каждого сервиса есть своя БД, вы должны использовать механизм для согласования данных между ними.
4.1.2. Проблемы с распределенными транзакциями
Традиционный подход к обеспечению согласованности данных между несколькими сервисами, БД или брокерами сообщений заключается в применении распределенных транзакций. Стандартом де-факто для управления распределенными транзакциями является X/Open XA (см. ru.wikipedia.org/wiki/XA). Модель XA использует двухэтапную фиксацию (two-phase commit, 2PC), чтобы гарантировать сохранение или откат всех изменений в транзакции. Для этого требуется, чтобы базы данных, брокеры сообщений, драйверы БД и API обмена сообщениями соответствовали стандарту XA, необходим также механизм межпроцессного взаимодействия, который распространяет глобальные идентификаторы XA-транзакций. Большинство реляционных БД совместимы с XA, равно как и некоторые брокеры сообщений. Например, приложение на основе Java EE может выполнять распределенные транзакции с помощью JTA.
Несмотря на внешнюю простоту, распределенные транзакции имеют ряд проблем. Многие современные технологии, включая такие базы данных NoSQL, как MongoDB и Cassandra, их не поддерживают. Распределенные транзакции не поддерживаются и некоторыми современными брокерами сообщений вроде RabbitMQ и Apache Kafka. Так что, если вы решите использовать распределенные транзакции, многие современные инструменты будут вам недоступны.
Еще одна проблема распределенных транзакций связана с тем, что они представляют собой разновидность синхронного IPC, а это ухудшает доступность. Чтобы распределенную транзакцию можно было зафиксировать, доступными должны быть все вовлеченные в нее сервисы. Как описывалось в главе 3, доступность системы — это произведение доступности всех участников транзакции. Если в распределенной транзакции участвуют два сервиса с доступностью 99,5 %, общая доступность будет 99 %, что намного меньше. Каждый дополнительный сервис понижает степень доступности. Эрик Брюер (Eric Brewer) сформулировал CAP-теорему, которая гласит, что система может обладать лишь двумя из следующих трех свойств: согласованность, доступность и устойчивость к разделению (ru.wikipedia.org/wiki/Теорема_CAP). В наши дни архитекторы отдают предпочтение доступным системам, жертвуя согласованностью.
На первый взгляд распределенные транзакции могут показаться привлекательными. С точки зрения разработчика, они имеют ту же программную модель, что и локальные транзакции. Но из-за проблем, описанных ранее, эта технология оказывается нежизнеспособной в современных приложениях. В главе 3 было показано, как отправлять сообщения в рамках транзакции базы данных, не используя при этом распределенные транзакции. Для решения более сложной проблемы, связанной с обеспечением согласованности данных в микросервисной архитектуре, приложение должно применять другой механизм, основанный на концепции слабо связанных асинхронных сервисов. И здесь пригодятся повествования.
4.1.3. Использование шаблона «Повествование» для сохранения согласованности данных
Повествования — это механизм, обеспечивающий согласованность данных в микросервисной архитектуре без применения распределенных транзакций. Повествование создается для каждой системной команды, которой нужно обновлять данные в нескольких сервисах. Это последовательность локальных транзакций, каждая из которых обновляет данные в одном сервисе, задействуя знакомые фреймворки и библиотеки для ACID-транзакций, упомянутые ранее.
Шаблон «Повествование»
Обеспечивает согласованность данных между сервисами, используя последовательность локальных транзакций, которые координируются с помощью асинхронных сообщений. См. microservices.io/patterns/data/saga.html.
Системная операция инициирует первый этап повествования. Завершение одной локальной транзакции приводит к выполнению следующей. В разделе 4.2 вы увидите, как координация этих этапов реализуется с помощью асинхронных сообщений. Важным преимуществом асинхронного обмена сообщениями является то, что он гарантирует выполнение всех этапов повествования, даже если один или несколько участников оказываются недоступными.
Повествования имеют несколько важных отличий от ACID-транзакций. Прежде всего, им не хватает изолированности (подробно об этом — в разделе 4.3). К тому же, поскольку каждая локальная транзакция фиксирует свои изменения, для отката повествования необходимо использовать компенсирующие транзакции, о которых мы поговорим позже в этом разделе. Рассмотрим пример повествования.
Пример повествования: создание заказа
В этой главе в качестве примера используем повествование Create Order (рис. 4.2). Оно реализует операцию createOrder(). Первая локальная транзакция инициируется внешним запросом создания заказа. Остальные пять транзакций срабатывают одна за другой.
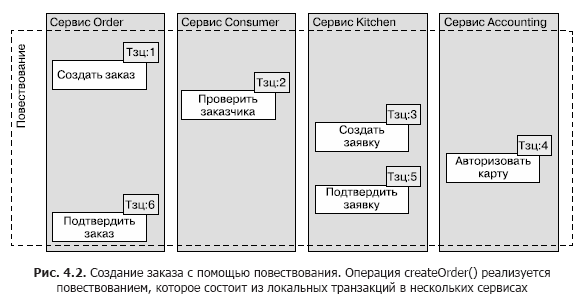
Это повествование состоит из следующих локальных транзакций.
1. Сервис Order. Создает заказ с состоянием APPROVAL_PENDING.
2. Сервис Consumer. Проверяет, может ли заказчик размещать заказы.
3. Сервис Kitchen. Проверяет детали заказа и создает заявку с состоянием CREATE_PENDING.
4. Сервис Accounting. Авторизует банковскую карту заказчика.
5. Сервис Kitchen. Меняет состояние заявки на AWAITING_ACCEPTANCE.
6. Сервис Order. Меняет состояние заказа на APPROVED.
В разделе 4.2 я покажу, как сервисы, участвующие в повествовании, взаимодействуют между собой с помощью асинхронных сообщений. Сервис публикует сообщение по завершении локальной транзакции. Это инициирует следующий этап повествования и позволяет не только добиться слабой связанности участников, но и гарантировать полное выполнение повествования. Даже если получатель временно недоступен, брокер буферизирует сообщение до того момента, когда его можно будет доставить.
Повествования выглядят простыми, но их использование связано с некоторыми трудностями, прежде всего с нехваткой изолированности между ними. Решение проблемы описано в разделе 4.3. Еще один нетривиальный аспект связан с откатом изменений при возникновении ошибки. Посмотрим, как это делается.
Повествования применяют компенсирующие транзакции для отката изменений
У традиционных ACID-транзакций есть одно прекрасное свойство: бизнес-логика может легко откатить транзакцию, если обнаружится нарушение бизнес-правила. Она просто выполняет команду ROLLBACK, а база данных отменяет все изменения, внесенные до этого момента. К сожалению, повествование нельзя откатить автоматически, поскольку на каждом этапе оно фиксирует изменения в локальной базе данных. Это, к примеру, означает, что в случае неудачной авторизации банковской карты на четвертом этапе повествования Create Order приложение FTGO должно вручную отменить изменения, сделанные на предыдущих трех этапах. Вы должны написать так называемые компенсирующие транзакции.
Допустим, (n + 1)-я транзакция в повествовании завершилась неудачно. Необходимо нивелировать последствия от предыдущих n транзакций. На концептуальном уровне каждый из этих этапов Ti имеет свою компенсирующую транзакцию Ci, которая отменяет эффект от Ti. Чтобы компенсировать эффект от первых n этапов, повествование должно выполнить каждую транзакцию Ci в обратном порядке. Последовательность выглядит так: T1… Tn, Cn… C1 (рис. 4.3). В данном примере отказывает этап Tn + 1, что требует отмены шагов T1… Tn.
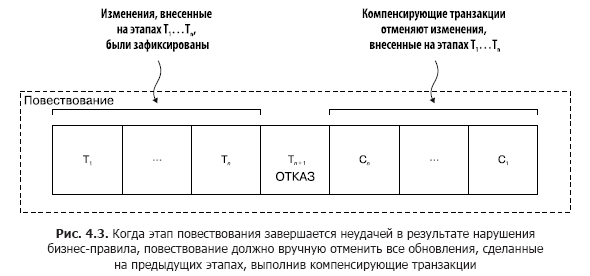
Повествование выполняет компенсирующие транзакции в обратном порядке по отношению к исходным: Cn… C1. Здесь действует тот же механизм последовательного выполнения, что и в случае с Ti. Завершение Ci должно инициировать Ci – 1.
Возьмем, к примеру, повествование Create Order. Оно может отказать по целому ряду причин.
1. Некорректная информация о заказчике, или заказчику не позволено создавать заказы.
2. Некорректная информация о ресторане, или ресторан не в состоянии принять заказ.
3. Невозможность авторизовать банковскую карту заказчика.
В случае сбоя в локальной транзакции механизм координации повествования должен выполнить компенсирующие шаги, которые отклоняют заказ и, возможно, заявку. В табл. 4.1 собраны компенсирующие транзакции для каждого этапа повествования Create Order. Следует отметить, что не всякий этап требует компенсирующей транзакции. Это относится, например, к операциям чтения, таким как verifyConsumerDetails(), или к операции authorizeCreditCard(), все шаги после которой всегда завершаются успешно.
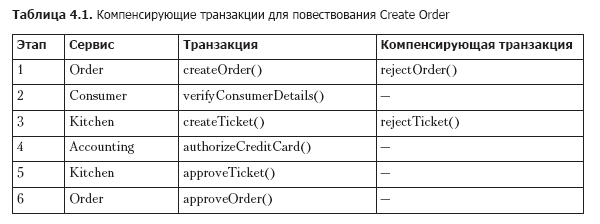
В разделе 4.3 вы узнаете, что первые три этапа повествования Create Order называются доступными для компенсации транзакциями, потому что шаги, следующие за ними, могут отказать. Четвертый этап называется поворотной транзакцией, потому что дальнейшие шаги никогда не отказывают. Последние два этапа называются доступными для повторения транзакциями, потому что они всегда заканчиваются успешно.
Чтобы понять, как используются компенсирующие транзакции, представьте ситуацию, в которой авторизация банковской карты заказчика проходит неудачно. В этом случае повествование выполняет следующие локальные транзакции.
1. Сервис Order. Создает заказ с состоянием APPROVAL_PENDING.
2. Сервис Consumer. Проверяет, может ли заказчик размещать заказы.
3. Сервис Kitchen. Проверяет детали заказа и создает заявку с состоянием CREATE_PENDING.
4. Сервис Accounting. Делает неудачную попытку авторизовать банковскую карту заказчика.
5. Сервис Kitchen. Меняет состояние заявки на CREATE_REJECTED.
6. Сервис Order. Меняет состояние заказа на REJECTED.
Пятый и шестой этапы — это компенсирующие транзакции, которые отменяют обновления, внесенные сервисами Kitchen и соответственно Order. Координирующая логика повествования отвечает за последовательность выполнения прямых и компенсирующих транзакций. Посмотрим, как это работает.
Об авторе
Крис Ричардсон (Chris Richardson) — разработчик, архитектор и автор книги POJOs in Action (Manning, 2006), в которой описывается процесс построения Java-приложений уровня предприятия с помощью фреймворков Spring и Hibernate. Он носит почетные звания Java Champion и JavaOne Rock Star.
Крис разработал оригинальную версию CloudFoundry.com — раннюю реализацию платформы Java PaaS для Amazon EC2.
Ныне он считается признанным идейным лидером в мире микросервисов и регулярно выступает на международных конференциях. Крис создал сайт microservices.io, на котором собраны шаблоны проектирования микросервисов. А еще он проводит по всему миру консультации и тренинги для организаций, которые переходят на микросервисную архитектуру. Сейчас Крис работает над своим третьим стартапом Eventuate.io. Это программная платформа для разработки транзакционных микросервисов.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Microservice Patterns
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Комментарии (21)

vosi
05.08.2019 13:50Насколько сильно книга заточена на Джаву? Судя по описанию на сайте англоязычного издателя — примеры на Джаве.

ph_piter Автор
05.08.2019 14:16Примеры кода в книге написаны на Java, к его же инфраструктуре идут отсылки (например Spring). Однако это всё же книга именно о микросервисах и большая часть содержания универсальна.

qlkvg
05.08.2019 14:06Дошел до 50 страницы и бросил. С переводом огромные проблемы. Two-week sprint переведено как «двухнедельный спурт». Опечатки даже в названиях фреймворков (Sping вместо spring). Со времен «Javascript. Сильные стороны», где опечатка была в регулярке (!!!), к сожалению, ничего не изменилось в лучшую сторону.
SaulG
05.08.2019 14:26Так потому что что то, что это переводили далеко не самые компетентные в вопросе разработки специалисты. И если с «трудностями перевода» все понятно, то для того, чтобы не допускать опечаток, разработчиком быть необязательно
ph_piter Автор
05.08.2019 14:30Мы не нашли примеры опечаток по переводу. Можете указать страницы?
qlkvg
05.08.2019 14:41+1Например, 33 страница, последний абзац раздела 1.2 (Sping вместо Spring), 29 страница, последний абзац раздела 1.1.1 (GpLang вместо Golang).
ph_piter Автор
05.08.2019 15:16Спасибо за помощь в поиске опечаток. Действительно, GpLang и Sping – пропущенные корректором опечатки. Данные ошибки будут исправлены в электронной версии и в бумажных допечатках. Однако «спурт» это не опечатка, а термин. Именно по этой причине он в кавычках.
qlkvg
05.08.2019 15:48С моей точки зрения, это в корне неправильный перевод термина «sprint». Во первых, в русском языке для обозначения коротких временных интервалов разработки вполне устоялся термин «спринт». Во вторых, сам смысл термина «спурт» — это резкое кратковременное увеличение темпа. Двухнедельный спурт — это оксюморон. В третьих, быстрый опрос коллег и гугление показали, что термин «спурт» в контексте разработки либо вообще не употребляется, либо употребляется редко.

terrier
05.08.2019 17:32+4Однако «спурт» это не опечатка, а термин. Именно по этой причине он в кавычках.
И что самое печальное, автор этого «термина» «переводчик» Черников С. В. нагадил еще три десятка переводов технической литературы про GraphQL, kubernetes, React, Scala и прочее. Уверен в этих переводах тоже полно «спуртов» и прочих «гуртовщиков мыши».Spliff-Guru
05.08.2019 21:59Судя Вашей логике, если Вы, как разработчик, допустите баг в одной из своих программ, то Вас по умолчанию следует считать ни на что не годным программистом и все Ваши прошлые и будущие программы недостойными внимания?
terrier
05.08.2019 22:55+2Дело в том, что это не баг, это системная недоработка. Встретив незнакомое для себя словосочетание переводчик (или редактор, здесь не важно) мог посмотреть в словаре. Мог сделать запрос в гугл (одного хватило бы). Вместо этого он предпочел выдумать собственный термин. А потом, видимо, еще стыдливо закавычить его — типа вот такие у айтишников странные слова. Тяжелейший проступок для переводчика.
Пользуясь вашей аналогией, если у меня в продакшн-коде километровая копипаста со стековерфлоу, рандомно подправленная без понимания происходящего и дополнительно подхаченная, чтобы проходили тесты, то, скорее всего я не самый выдающийся программист и в остальном коде у меня то же самое. А если еще вспомнить что этот код прошел код-ревью, то можно сделать выводы о качестве разработки в организации.Spliff-Guru
06.08.2019 00:03Вопрос в том, как еще премируется данная работа. В свое время трудился в штате одного из издательств как раз в плане работы с переводчиками. Насколько помню, в среднем 300-страничная книга переводится 1-2 месяца, оплачивается обычно 30-35 тыс рублей (примерно раз в 10 меньше, чем в Европе) (иногда код не учитывается и не оплачивается). Это работа переводчика. Локализовать код, проверить его, сделать иллюстрации, предметный указатель, погуглить или купить словари по теме, внести правку Errata, найденную читателями, подготовить внешние файлы с кодом для выгрузки на сайт издательства — все это (время) не оплачивается. Насколько наслышан, последние лет десять гонорары переводчикам не индексировались. А некоторые издатели стали еще экономить на редакторах — после переводчика книга сразу идет корректору и на верстку. С такими условиями не то что специалисты, любой уважающий переводчик не пойдет работать. Поэтому и огрехи, что переводчики переводят все подряд вне зависимости от сферы знаний и опыта. Работают или энтузиасты или неопытные. Но все же и не значит, что если что-то переведено плохо, то и все переведено плохо.
terrier
06.08.2019 01:22Да, безусловно, первопричина не в какой-то особой порочности господина Черникова, а в низкой оплате. Поэтому издательства не могут привлечь грамотных специалистов, а те кто есть вынуждены спешить, у них не хватает времени даже сделать один запрос к гуглу.
Тем не менее переводчика это не оправдывает, это все равно как если бы учитель математики вместо рассказа о собственно математике бессмысленно бормотал на уроке, а на претензии отвечал бы «А это потому что мне мало платят».
Я посмотрел наугад еще один перевод этого же человека — книжку про kubernetes. И, как и ожидалось, сложная тема переведена кошмарно. Местами просто набор слов, который невозможно понять и чему-нибудь научиться.Spliff-Guru
06.08.2019 09:10Здесь соглашусь. Вероятно, лучше вообще не переводить такие темы, тем более большинство читает в оригинале.
Spliff-Guru
06.08.2019 20:08Помимо книг по программированию у него и другие темы, не заметил столь гневных отзывов. Или Вы все просмотрели? Насчет Kubernetes соглашусь, тот еще хардкор. Но если человек не знает термины из мира программирования, все же не значит, что он совсем плохой переводчик во всех темах. Тем более «гуртовщики мыши» это из мира древних автоматизированных переводов.
А по опыту обратной связи в издательстве с читателями — потребители книг по программированию — самая неблагодарная аудитория, всегда находит к чему придраться.

AstarothAst
05.08.2019 18:32+1В среде программистов никто знать не знает ни о каких «спуртах», даже если в среде спортсменов используется именно это термин.

vsespb
06.08.2019 00:32+1«Спурт»? Вы серьёзно?? Книжки от такого переводчика безопасней отнести сразу на помойку
Spliff-Guru
06.08.2019 20:01В кавычки еще заключают метафоры, но с точки зрения программиста в технической литературе они недопустимы, мыслить надо типами данных.
solver
Эм… может не стоило переводить термин?
OnYourLips
Им постоянно об этом пишут, но они не прислушиваются.
Однако с терминами еще можно догадаться, проведя обратный перевод (однако зачем тогда читать переводы?), в случае аббревиатур же все сложнее: я читал книгу от другого издательства, в которой переводили термин из популярных аббревиатур и использовали первые буквы переведенных слов.
SaulG
Да, в общем случае для перевода терминологии все-таки следует руководствоваться тем же правилом, что и для имен собственных