
Всем привет. Делимся переводом заключительной части статьи, подготовленной специально для студентов курса «Data Engineer». С первой частью можно ознакомиться тут.
Apache Beam и DataFlow для конвейеров реального времени

Чтобы запустить конвейер, нам нужно немного покопаться в настройках. Тем из вас, кто раньше не пользовался GCP, необходимо выполнить следующие 6 шагов, приведенных на этой странице.
После этого нам нужно будет загрузить наши скрипты в облачное хранилище Google и скопировать их в нашу Google Cloud Shel. Загрузка в облачное хранилище достаточно тривиальна (описание можно найти здесь). Чтобы скопировать наши файлы, мы можем открыть Google Cloud Shel из панели инструментов, щелкнув первый значок слева на рисунке 2 ниже.

Рисунок 2
Команды, которые нам нужны для копирования файлов и установки необходимых библиотек, перечислены ниже.
После того, как мы выполнили все шаги, связанные с настройкой, следующее, что нам нужно сделать, это создать набор данных и таблицу в BigQuery. Есть несколько способов сделать это, но самый простой — использовать консоль Google Cloud, сначала создав набор данных. Вы можете выполнить действия, указанные по следующей ссылке, чтобы создать таблицу со схемой. Наша таблица будет иметь 7 столбцов, соответствующих компонентам каждого пользовательского лога. Для удобства мы определим все столбцы как строки (тип string), за исключением переменной timelocal, и назовем их в соответствии с переменными, которые мы сгенерировали ранее. Схема нашей таблицы должна выглядеть как на рисунке 3.
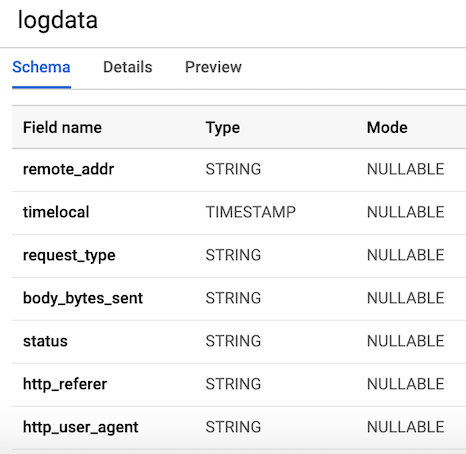
Рисунок 3. Схема таблицы
Pub/Sub является критически важным компонентом нашего конвейера, поскольку позволяет нескольким независимым приложениям взаимодействовать друг с другом. В частности, он работает как посредник, позволяющий нам отправлять и получать сообщения между приложениями. Первое, что нам нужно сделать, это создать тему (topic). Достаточно просто перейти в Pub/Sub в консоли и нажать CREATE TOPIC.
Приведенный ниже код вызывает наш скрипт для генерации данных лога, определенных выше, а затем подключается и отправляет журналы в Pub/Sub. Единственное, что нам нужно сделать, — это создать объект PublisherClient, указать путь к теме с помощью метода
Как только файл запустится, мы сможем наблюдать вывод данных лога на консоль, как показано на рисунке ниже. Этот скрипт будет работать до тех пор, пока мы не используем CTRL+C, чтобы завершить его.

Рисунок 4. Вывод
Теперь, когда мы все подготовили, мы можем приступить к самой интересной части — написанию кода нашего конвейера, используя Beam и Python. Чтобы создать Beam-конвейер, нам нужно создать объект конвейера (p). После того как мы создали объект конвейера, мы можем применить несколько функций одну за другой, используя оператор
В нашем коде мы создадим две пользовательские функции. Функцию
Мы можем запустить конвейер несколькими различными способами. Если бы мы захотели, мы могли бы просто запустить его локально с терминала, удаленно войдя в GCP.
Однако мы собираемся запустить его с помощью DataFlow. Мы можем сделать это с помощью нижеприведенной команды, установив следующие обязательные параметры.
Пока эта команда выполняется, мы можем перейти на вкладку DataFlow в google-консоли и просмотреть наш конвейер. Кликнув по конвейеру, мы должны увидеть что-то похожее на рисунок 4. В целях отладки может быть очень полезно перейти в логи, а затем в Stackdriver для просмотра подробных логов. Это помогло мне разрешить проблемы с конвейером в ряде случаев.
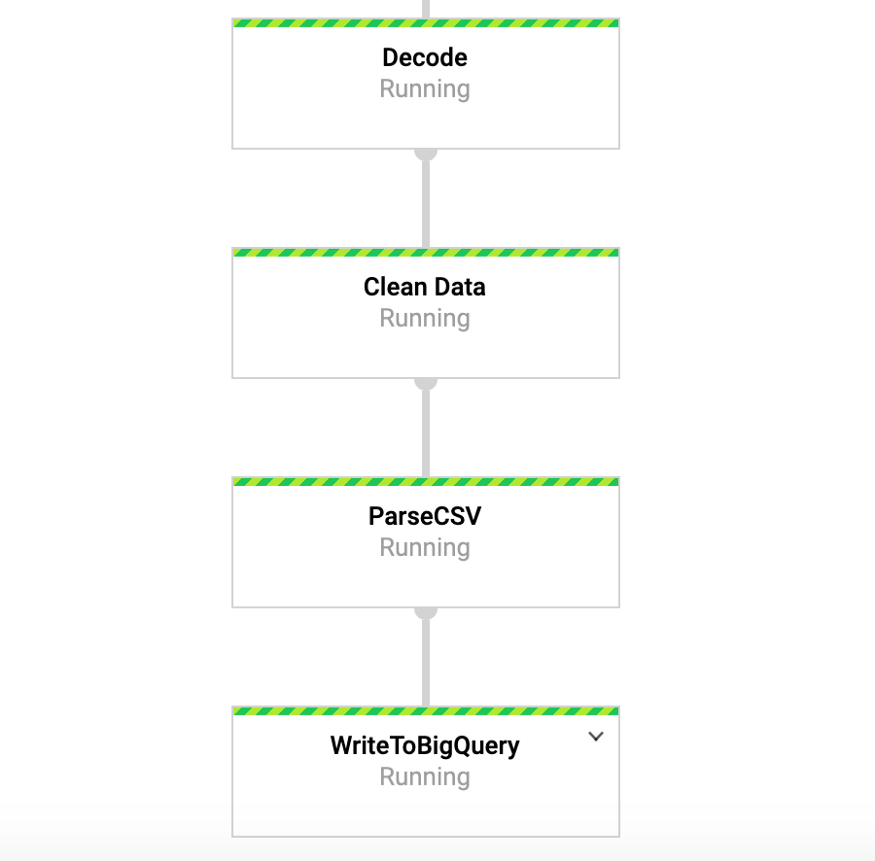
Рисунок 4: Beam-конвейер
Итак, у нас уже должен быть запущен конвейер с данными, поступающими в нашу таблицу. Чтобы проверить это, мы можем перейти к BigQuery и просмотреть данные. После использования команды ниже вы должны увидеть первые несколько строк набора данных. Теперь, когда у нас есть данные, хранящиеся в BigQuery, мы можем провести дальнейший анализ, а также поделиться данными с коллегами и начать отвечать на бизнес-вопросы.

Рисунок 5: BigQuery
Надеемся, что этот пост послужит полезным примером создания потокового конвейера данных, а также поиска способов сделать данные более доступными. Хранение данных в таком формате дает нам много преимуществ. Теперь мы можем начать отвечать на важные вопросы, например, сколько людей используют наш продукт? Растет ли со временем база пользователей? С какими аспектами продукта люди взаимодействуют больше всего? И есть ли ошибки, там где их быть не должно? Это те вопросы, которые будут интересны для организации. На основе идей, вытекающих из ответов на эти вопросы, мы сможем усовершенствовать продукт и повысить заинтересованность пользователей.
Beam действительно полезен для такого типа упражнений, а также имеет ряд других интересных случаев использования. Например, вы можете анализировать данные по биржевым тикам в режиме реального времени и совершать сделки на основе анализа, возможно, у вас есть данные датчиков, поступающие с транспортных средств, и вы хотите вычислить расчет уровня трафика. Вы также можете, например, быть игровой компанией, собирающей данные о пользователях и использующей ее для создания информационных панелей для отслеживания ключевых показателей. Ладно, господа, это тема уже для другого поста, спасибо за чтение, а для тех, кто хочет увидеть полный код, ниже ссылка на мой GitHub.
https://github.com/DFoly/User_log_pipeline
На этом все. Читать первую часть.
Apache Beam и DataFlow для конвейеров реального времени
Настройка Google Cloud
Примечание: Для запуска конвейера и публикации данных пользовательского лога я использовал Google Cloud Shell, поскольку у меня возникли проблемы с запуском конвейера на Python 3. Google Cloud Shell использует Python 2, который лучше согласуется с Apache Beam.
Чтобы запустить конвейер, нам нужно немного покопаться в настройках. Тем из вас, кто раньше не пользовался GCP, необходимо выполнить следующие 6 шагов, приведенных на этой странице.
После этого нам нужно будет загрузить наши скрипты в облачное хранилище Google и скопировать их в нашу Google Cloud Shel. Загрузка в облачное хранилище достаточно тривиальна (описание можно найти здесь). Чтобы скопировать наши файлы, мы можем открыть Google Cloud Shel из панели инструментов, щелкнув первый значок слева на рисунке 2 ниже.
Рисунок 2
Команды, которые нам нужны для копирования файлов и установки необходимых библиотек, перечислены ниже.
# Copy file from cloud storage
gsutil cp gs://<YOUR-BUCKET>/ * .
sudo pip install apache-beam[gcp] oauth2client==3.0.0
sudo pip install -U pip
sudo pip install Faker==1.0.2
# Environment variables
BUCKET=<YOUR-BUCKET>
PROJECT=<YOUR-PROJECT>Создание нашей базы данных и таблицы
После того, как мы выполнили все шаги, связанные с настройкой, следующее, что нам нужно сделать, это создать набор данных и таблицу в BigQuery. Есть несколько способов сделать это, но самый простой — использовать консоль Google Cloud, сначала создав набор данных. Вы можете выполнить действия, указанные по следующей ссылке, чтобы создать таблицу со схемой. Наша таблица будет иметь 7 столбцов, соответствующих компонентам каждого пользовательского лога. Для удобства мы определим все столбцы как строки (тип string), за исключением переменной timelocal, и назовем их в соответствии с переменными, которые мы сгенерировали ранее. Схема нашей таблицы должна выглядеть как на рисунке 3.
Рисунок 3. Схема таблицы
Публикация данных пользовательского лога
Pub/Sub является критически важным компонентом нашего конвейера, поскольку позволяет нескольким независимым приложениям взаимодействовать друг с другом. В частности, он работает как посредник, позволяющий нам отправлять и получать сообщения между приложениями. Первое, что нам нужно сделать, это создать тему (topic). Достаточно просто перейти в Pub/Sub в консоли и нажать CREATE TOPIC.
Приведенный ниже код вызывает наш скрипт для генерации данных лога, определенных выше, а затем подключается и отправляет журналы в Pub/Sub. Единственное, что нам нужно сделать, — это создать объект PublisherClient, указать путь к теме с помощью метода
topic_path и вызвать функцию publish с topic_path и данными. Обратите внимание, что мы импортируем generate_log_line из нашего скрипта stream_logs, поэтому убедитесь, что эти файлы находятся в одной папке, иначе вы получите ошибку импорта. Затем мы можем запустить это через нашу google-консоль, используя:python publish.pyfrom stream_logs import generate_log_line
import logging
from google.cloud import pubsub_v1
import random
import time
PROJECT_ID="user-logs-237110"
TOPIC = "userlogs"
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC)
def publish(publisher, topic, message):
data = message.encode('utf-8')
return publisher.publish(topic_path, data = data)
def callback(message_future):
# When timeout is unspecified, the exception method waits indefinitely.
if message_future.exception(timeout=30):
print('Publishing message on {} threw an Exception {}.'.format(
topic_name, message_future.exception()))
else:
print(message_future.result())
if __name__ == '__main__':
while True:
line = generate_log_line()
print(line)
message_future = publish(publisher, topic_path, line)
message_future.add_done_callback(callback)
sleep_time = random.choice(range(1, 3, 1))
time.sleep(sleep_time)Как только файл запустится, мы сможем наблюдать вывод данных лога на консоль, как показано на рисунке ниже. Этот скрипт будет работать до тех пор, пока мы не используем CTRL+C, чтобы завершить его.
Рисунок 4. Вывод
publish_logs.pyНаписание кода нашего конвейера
Теперь, когда мы все подготовили, мы можем приступить к самой интересной части — написанию кода нашего конвейера, используя Beam и Python. Чтобы создать Beam-конвейер, нам нужно создать объект конвейера (p). После того как мы создали объект конвейера, мы можем применить несколько функций одну за другой, используя оператор
pipe (|). В общем, рабочий процесс выглядит как на рисунке ниже.[Final Output PCollection] = ([Initial Input PCollection] | [First Transform]
| [Second Transform]
| [Third Transform])В нашем коде мы создадим две пользовательские функции. Функцию
regex_clean, которая сканирует данные и извлекает соответствующую строку на основе списка PATTERNS, используя функцию re.search. Функция возвращает разделенную запятыми строку. Если вы не являетесь экспертом по регулярным выражениям, я рекомендую ознакомится с этим туториалом и попрактиковаться в блокноте, чтобы проверить код. После этого мы определяем пользовательскую ParDo-функцию под названием Split, которая является вариацией Beam-преобразования для параллельной обработки. В Python это делается особым способом — мы должны создать класс, который наследуется от класса DoFn Beam. Функция Split принимает распаршенную строку из предыдущей функции и возвращает список словарей с ключами, соответствующими именам столбцов в нашей таблице BigQuery. Есть кое-что, что следует отметить про эту функцию: мне пришлось импортировать datetime внутри функции, чтобы она работала. Я получал сообщение об ошибке при импорте в начале файла, что было странно. Этот список затем передается в функцию WriteToBigQuery, которая просто добавляет наши данные в таблицу. Код для Batch DataFlow Job и Streaming DataFlow Job приведен ниже. Единственное отличие между пакетным и потоковым кодом заключается в том, что в пакетной обработке мы читаем CSV из src_path, используя функцию ReadFromText из Beam.Batch DataFlow Job (обработка пакетов)
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
from google.cloud import bigquery
import re
import logging
import sys
PROJECT='user-logs-237110'
schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING'
src_path = "user_log_fileC.txt"
def regex_clean(data):
PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])',
r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])",
r'\"[A-Z][a-z]+', r'\"(http|https)://[a-z]+.[a-z]+.[a-z]+']
result = []
for match in PATTERNS:
try:
reg_match = re.search(match, data).group()
if reg_match:
result.append(reg_match)
else:
result.append(" ")
except:
print("There was an error with the regex search")
result = [x.strip() for x in result]
result = [x.replace('"', "") for x in result]
res = ','.join(result)
return res
class Split(beam.DoFn):
def process(self, element):
from datetime import datetime
element = element.split(",")
d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S")
date_string = d.strftime("%Y-%m-%d %H:%M:%S")
return [{
'remote_addr': element[0],
'timelocal': date_string,
'request_type': element[2],
'status': element[3],
'body_bytes_sent': element[4],
'http_referer': element[5],
'http_user_agent': element[6]
}]
def main():
p = beam.Pipeline(options=PipelineOptions())
(p
| 'ReadData' >> beam.io.textio.ReadFromText(src_path)
| "clean address" >> beam.Map(regex_clean)
| 'ParseCSV' >> beam.ParDo(Split())
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
)
p.run()
if __name__ == '__main__':
logger = logging.getLogger().setLevel(logging.INFO)
main()Streaming DataFlow Job (обработка потока)
from apache_beam.options.pipeline_options import PipelineOptions
from google.cloud import pubsub_v1
from google.cloud import bigquery
import apache_beam as beam
import logging
import argparse
import sys
import re
PROJECT="user-logs-237110"
schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING'
TOPIC = "projects/user-logs-237110/topics/userlogs"
def regex_clean(data):
PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])',
r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])",
r'\"[A-Z][a-z]+', r'\"(http|https)://[a-z]+.[a-z]+.[a-z]+']
result = []
for match in PATTERNS:
try:
reg_match = re.search(match, data).group()
if reg_match:
result.append(reg_match)
else:
result.append(" ")
except:
print("There was an error with the regex search")
result = [x.strip() for x in result]
result = [x.replace('"', "") for x in result]
res = ','.join(result)
return res
class Split(beam.DoFn):
def process(self, element):
from datetime import datetime
element = element.split(",")
d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S")
date_string = d.strftime("%Y-%m-%d %H:%M:%S")
return [{
'remote_addr': element[0],
'timelocal': date_string,
'request_type': element[2],
'body_bytes_sent': element[3],
'status': element[4],
'http_referer': element[5],
'http_user_agent': element[6]
}]
def main(argv=None):
parser = argparse.ArgumentParser()
parser.add_argument("--input_topic")
parser.add_argument("--output")
known_args = parser.parse_known_args(argv)
p = beam.Pipeline(options=PipelineOptions())
(p
| 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes)
| "Decode" >> beam.Map(lambda x: x.decode('utf-8'))
| "Clean Data" >> beam.Map(regex_clean)
| 'ParseCSV' >> beam.ParDo(Split())
| 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema,
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND)
)
result = p.run()
result.wait_until_finish()
if __name__ == '__main__':
logger = logging.getLogger().setLevel(logging.INFO)
main()
Запуск конвейера
Мы можем запустить конвейер несколькими различными способами. Если бы мы захотели, мы могли бы просто запустить его локально с терминала, удаленно войдя в GCP.
python -m main_pipeline_stream.py --input_topic "projects/user-logs-237110/topics/userlogs" --streamingОднако мы собираемся запустить его с помощью DataFlow. Мы можем сделать это с помощью нижеприведенной команды, установив следующие обязательные параметры.
project— ID вашего проекта GCP.runner— средство запуска конвейера, которое проанализирует вашу программу и сконструирует ваш конвейер. Для выполнения в облаке вы должны указать DataflowRunner.staging_location— путь к облачному хранилищу Cloud Dataflow для индексировани пакетов кода, необходимых обработчикам, выполняющим работу.temp_location— путь к облачному хранилищу Cloud Dataflow для размещения временных файлов заданий, созданных во время работы конвейера.streaming
python main_pipeline_stream.py --runner DataFlow --project $PROJECT --temp_location $BUCKET/tmp --staging_location $BUCKET/staging
--streaming
Пока эта команда выполняется, мы можем перейти на вкладку DataFlow в google-консоли и просмотреть наш конвейер. Кликнув по конвейеру, мы должны увидеть что-то похожее на рисунок 4. В целях отладки может быть очень полезно перейти в логи, а затем в Stackdriver для просмотра подробных логов. Это помогло мне разрешить проблемы с конвейером в ряде случаев.
Рисунок 4: Beam-конвейер
Доступ к нашим данным в BigQuery
Итак, у нас уже должен быть запущен конвейер с данными, поступающими в нашу таблицу. Чтобы проверить это, мы можем перейти к BigQuery и просмотреть данные. После использования команды ниже вы должны увидеть первые несколько строк набора данных. Теперь, когда у нас есть данные, хранящиеся в BigQuery, мы можем провести дальнейший анализ, а также поделиться данными с коллегами и начать отвечать на бизнес-вопросы.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;Рисунок 5: BigQuery
Заключение
Надеемся, что этот пост послужит полезным примером создания потокового конвейера данных, а также поиска способов сделать данные более доступными. Хранение данных в таком формате дает нам много преимуществ. Теперь мы можем начать отвечать на важные вопросы, например, сколько людей используют наш продукт? Растет ли со временем база пользователей? С какими аспектами продукта люди взаимодействуют больше всего? И есть ли ошибки, там где их быть не должно? Это те вопросы, которые будут интересны для организации. На основе идей, вытекающих из ответов на эти вопросы, мы сможем усовершенствовать продукт и повысить заинтересованность пользователей.
Beam действительно полезен для такого типа упражнений, а также имеет ряд других интересных случаев использования. Например, вы можете анализировать данные по биржевым тикам в режиме реального времени и совершать сделки на основе анализа, возможно, у вас есть данные датчиков, поступающие с транспортных средств, и вы хотите вычислить расчет уровня трафика. Вы также можете, например, быть игровой компанией, собирающей данные о пользователях и использующей ее для создания информационных панелей для отслеживания ключевых показателей. Ладно, господа, это тема уже для другого поста, спасибо за чтение, а для тех, кто хочет увидеть полный код, ниже ссылка на мой GitHub.
https://github.com/DFoly/User_log_pipeline
На этом все. Читать первую часть.