
— До Яндекса я работал в других продуктовых компаниях. Это не как фрилансер — написал, сдал и забыл. Приходится очень долго работать с одной кодовой базой. И я, собственно, смотрел, читал, писал много кода на разных языках и увидел много чего интересного. В итоге у меня родилась тема этого рассказа.
Например, я увидел, что в разных проектах на разных языках возникают одни и те же или очень похожие задачи — работа с датой, временем. Помимо самой такой работы, это могут всплывшие в коде операции с объектами даты и времени.

Получается, что независимо от того, фронтендер вы или бэкендер, у вас возникают аналогичные задачи по работе с асинхронным кодом. Если вы на бэкенде, это запросы в базу данных, удаленные вызовы. Если фронтендер — у вас, естественно, есть AJAX. Разные люди в разных проектах эти задачи решают почти одинаково, такова суть человека. При похожей задаче вы делаете примерно похожее решение, независимо от языка, на котором вы думаете. И логично, что при этом вы — мы, я — совершаем очень похожие ошибки.
О чем я хочу рассказать в итоге? Об этих повторяющихся паттернах, которые возникают независимо от языка, на котором вы пишете, об ошибках, которые легко совершить, и о том, как их не совершать.
Первая часть посвящена, собственно, времени. Как вы знаете, время движется. Пример: вам надо написать отчет за вчера, за полные прошедшие сутки. Вы делаете запрос в базу, надо получить все записи, у которых дата больше или равна вчерашней и меньше сегодняшней. То есть вы начинаете с даты «сегодня минус одни сутки» и по сегодняшнюю дату, не включая ее.

Так линейно вы, в общем, и пишете код. Дата начала — сегодня минус одни сутки, дата окончания — сегодня. Казалось бы, все работает, но потом ровно в полночь у вас случается странное. У вас дата начала вот здесь. Дата начала минус одни сутки — получается, такая. После этого почему-то дата окончания отчета совершенно другая.

Вы, а точнее ваш начальник получаете отчет за двое суток вместо одних. Технический начальник и менеджер приходят, жалуются и вежливо предлагают вам через шесть месяцев перейти в другую команду.

Но зато вы обогатились новым знанием. Вы поняли, что время не стоит на месте. То есть два раза вызывая Date.now() или получая new Date(), вы не надеетесь получить одно и то же значение. Оно может быть иногда одинаковым, но может быть и не одинаковым. Соответственно, если у вас есть один метод, какой-то один кусочек логики, то в нем, скорее всего, должен быть только один вызов Date.now() или получение new Date(), текущего момента времени.
Или зайдем с другой стороны: в потоке обработки данных все связанные по смыслу значения — начало и окончание отчета — должны вычисляться строго из одного объекта. Не из двух каких-то похожих, к примеру, а точно из одного. Вы обогащаетесь этим новым знанием, переходите в новую команду. Там люди больше озабочены скоростью и производительностью кода.

И вам предлагают обложить код логированием, замерять, сколько времени у вас занимает какая-то операция. Если это тяжелая операция — важно, чтобы она не тормозила на клиенте. Если вы на бэкенде, на Node что-то пишете, тоже тяжелую транзакцию, то вас просят: «Пожалуйста, напиши в лог, сколько она занимает, а мы потом посчитаем, как наши клиенты себя ведут в зависимости от юзер-агента».
Затем к вам приходят два уже новых начальника и показывают вам запись в логе, где у вас внезапно логируются отрицательные времена. И тоже вежливо предлагают вам через шесть месяцев перейти в другую команду.

Вы извлекаете ценные знания о том, что, на самом деле, методы получения даты, времени, которыми вы пользуетесь — они всего лишь показывают, что у вас в часах операционной системы. И при этом они не гарантируют даже равномерного изменения. То есть у вас за секунду реального времени может ваш Date.now() как прыгнуть на секунду, так и немножко больше — немножко меньше. И в принципе, они вообще не гарантируют монотонности изменения. То есть, как в этом примере, он может внезапно уменьшиться, значение Date.now() может внезапно уменьшиться.
Причина в чем? В синхронизации времени. В Linux-подобных системах есть такая вещь, как NTP daemon, который синхронизирует часы вашей операционной системы с точными часами в интернете. И если у вас есть какое-то отставание или опережение, он может или искусственно замедлять, или ускорять ваши часы, или, если у вас сильно большой разрыв по времени, он поймет, что не сможет нагнать незаметными шажками время правильное, и просто одним скачком изменяет его. У вас в результате получается разрыв в показаниях ваших часов.
Или можно сильно не усложнять: сам пользователь, у которого есть контроль над часами, он тоже может захотеть просто поменять часы. Вот ему так захотелось. И мы не вправе его остановить. А в логах у нас получаются разрывы. И, соответственно, решение этой проблемы тоже уже существует. Все просто: есть поставщики времени. Если вы в браузере, то это есть performance.now(), если вы в Node пишете, то там есть High Resolution Timer, которые, они оба, обладают этими свойствами равномерности и монотонности. То есть вот эти поставщики отметок времени, они всегда только увеличиваются, и при этом равномерно за одну секунду реального времени.
На бэкенде та же самая проблема. Неважно, на каком языке вы пишете. Например, можно поискать о монотонных консистентных часах, и вам выдача дает, в которой представлены практически все языки. Там есть та же проблема в Rust. Там есть и боль программиста, который в Python, и в Java, и в других языках. В этих языках люди тоже уже наступили на грабли, эта проблема известна, решение есть. Например, для Java есть такой вызов, который обладает теми же свойствами равномерности и монотонности.
Если у вас распределенная система, модные микросервисы, например, то там все еще сложнее. Там есть N разных сервисов на N разных машинах, часы на которых, вообще никогда даже могут не сойтись к одному показанию в принципе, нечего даже на это надеяться.
И если у вас есть проблема логировать действия, то вы можете логировать просто вектор времени. У вас, получается, логируется N времен с N систем, участвующих в обработке одного запроса. Или вы просто переходите к абстрактному счетчику, который просто увеличивается: 1, 2, 3, 4, 5, просто на данной машине с каждой операцией тикает равномерно. И вы такие счетчики пишете для того, чтобы связать вот эти все этапы обработки ваших каких-то запросов на разных машинах, и получить какое-то понимание о том, когда, что происходит, в какой последовательности.
Также не забывайте: если вы фронтендеры или бэкендеры, которые работают с фронтендом в тесной связке, то наш фронтенд плюс бэкенд — тоже распределенная система. И если вас тоже интересует какая-то сложная сессия работы клиента, то тоже, пожалуйста, постарайтесь, во-первых, не перепутать, когда вы смотрите в логах, какое время вы видите: «вот запись, что данная операция произошла во столько-то» — это вы видите серверное время или клиентское? И, во-вторых, постарайтесь собирать оба времени, потому что, как я уже говорил, времена могут идти в разные стороны.
Хватит о времени. Вторая часть более беспорядочная.
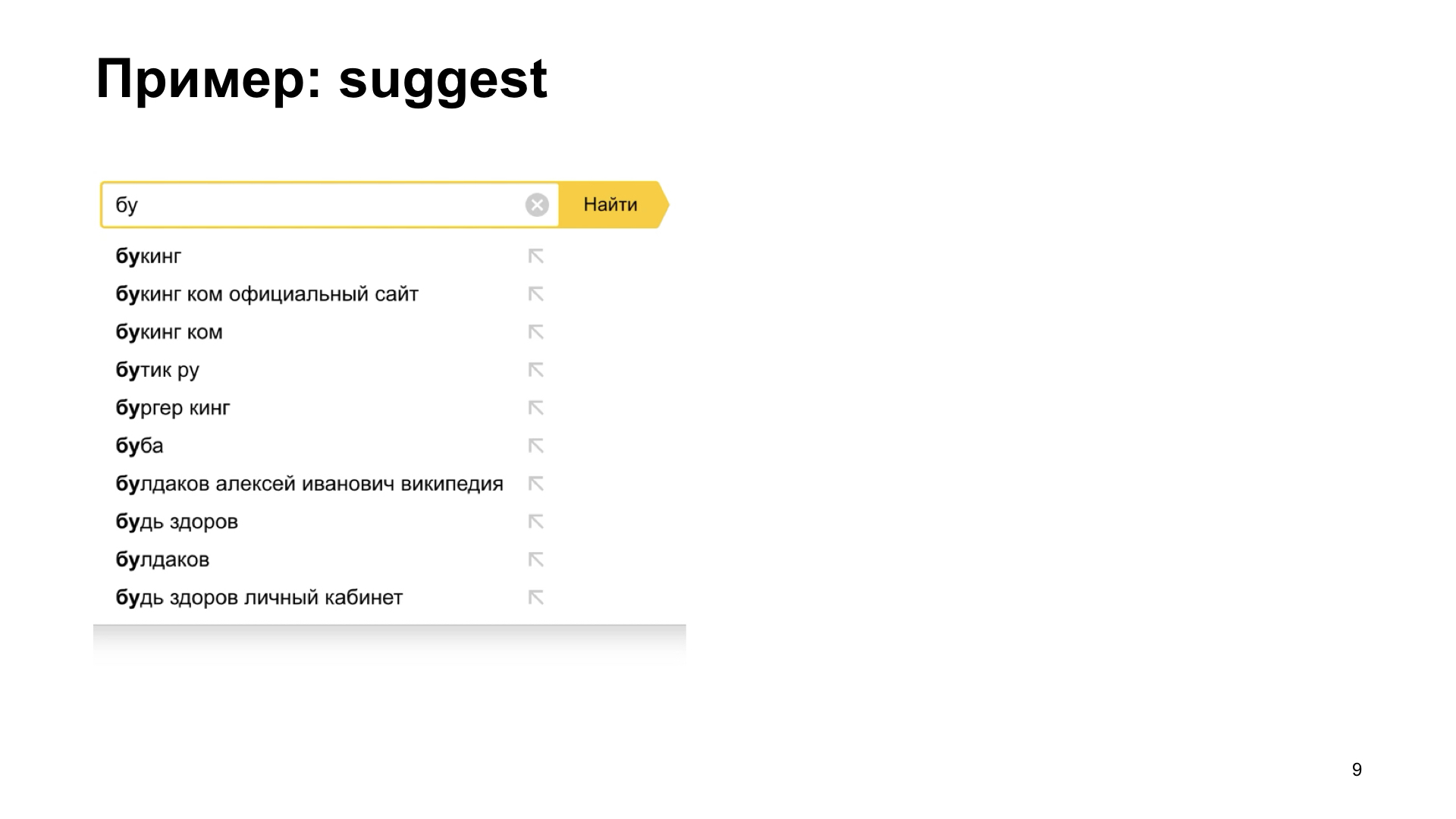
Вот пример. Есть такой очень полезный элемент интерфейса, когда пользователь не знает точно, чего он хочет. Это называется suggest, или autocomplete. Мы можем подсказывать ему варианты продолжения запроса. То есть для пользователя это очень большая польза получается. Намного удобнее ему работать, когда мы сразу показываем ему, что мы знаем, что мы можем дальше набирать.
Но, к сожалению, если у нас получается немножко медленная сеть, или если тормозит бэкенд, который дает ответы, варианты продолжения, то у нас могут получиться вот такие интересные эффекты. Пользователь набирает, набирает, потом приходит правильный ответ, мы его видим, и потом все ломается. Почему-то мы видим совсем не то, что мы хотели увидеть. Вот мы видим правильный ответ, и сразу какая-то ерунда на какое-то промежуточное состояние. Снова сплошная боль и страдание. К нам приходят наши начальники и просят нас починить этот баг.

Мы начинаем разбираться. Что у нас получается? Когда пользователь набирает свой текст, у нас получается генерация последовательных асинхронных запросов. То есть то, что он успел набрать, мы посылаем на бэкенд. Он набирает дальше, мы посылаем второй запрос на бэкенд, и при этом никто никогда нам не гарантировал, что наши callback будут вызываться ровно в той же последовательности.
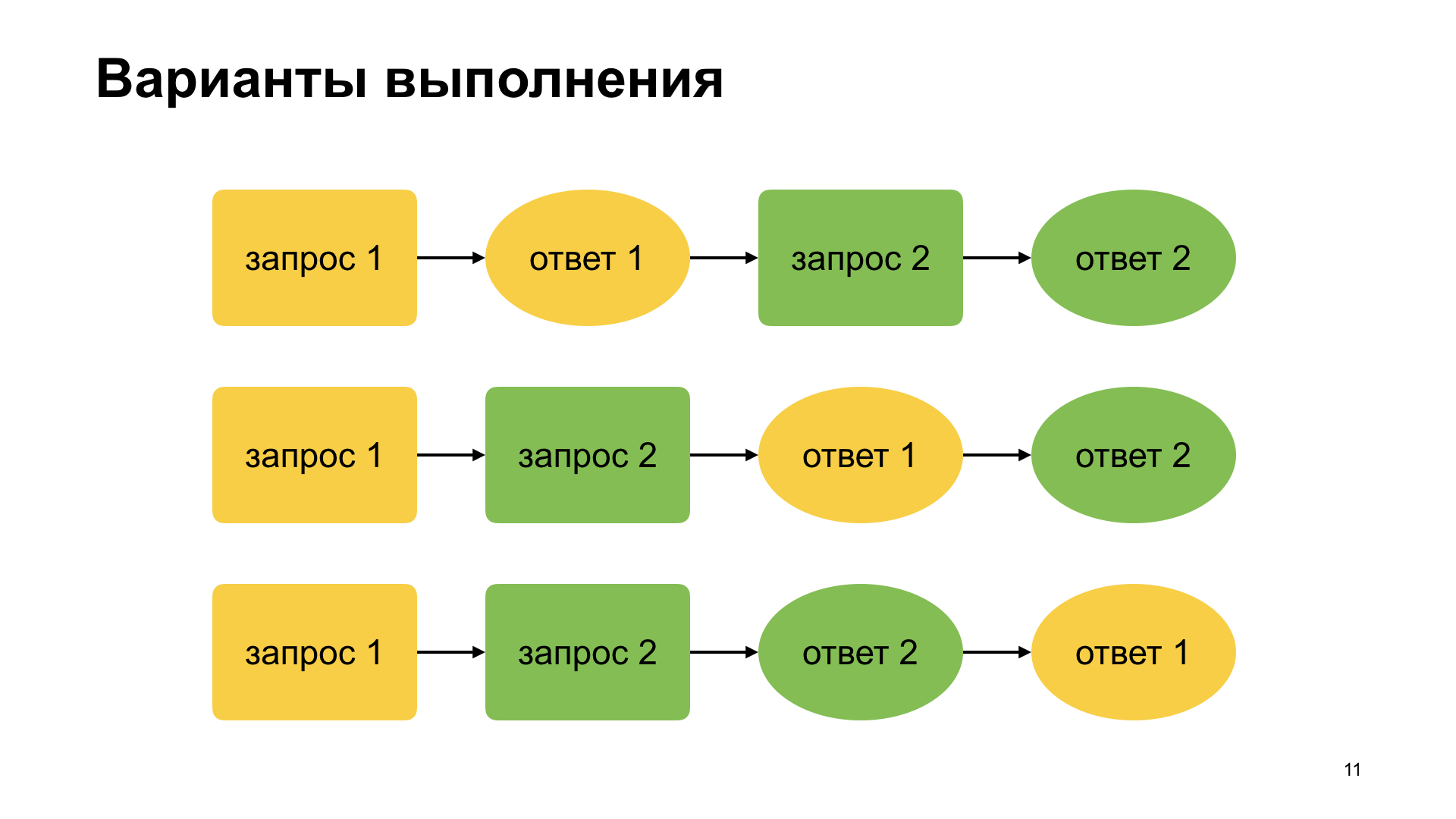
Получаются вот такие возможные варианты запросов и callback. Самое очевидное, когда мы пишем, мы думаем: послали первый запрос, получили первый ответ, послали второй запрос, получили ответ. Если пользователь набирает очень быстро, то мы можем второй вариант придумать, что мы успели послать первый запрос, пользователь успел что-то набрать до получения первого ответа. Потом пришел первый ответ, второй ответ. И вот то, что мы видели на видеозаписи, когда suggest неправильно работал, это третий вариант, про который очень часто забывают, про то, что порядок ответов нам никто не гарантирует, в общем-то.

И у фронтендеров эта проблема очень часто встречается, если вы разрабатываете интерфейсы. В частности, пример с suggest, с autocomplete, который мы только что видели. То есть, есть поток запросов, и есть поток ответов, асинхронно приходящих.
Если у вас есть вкладочки. Поднимите руки, кто на GitHub делал хоть один pull request когда-нибудь? Вы помните, что там, собственно, интерфейс на вкладочках основан, то есть, там есть вкладочка, где последовательность комментариев, есть вкладочка с коммитами, и есть вкладочка с кодом непосредственно. Это такой интерфейс с вкладочками. И если вы переключаетесь на соседнюю вкладочку, то ее содержимое в первый раз подгружается асинхронно.
Если вы быстро накликаете на разные вкладочки, то может так получиться, что вы их попереключали, а потом видите мигание подгружающегося контента. И в конце не факт, что вы увидите содержание правильной вкладки, если вы правильно, конечно же, не напишите свое.
Например, если у вас магазин есть, если вы быстро перетаскиваете товары в корзину. Какой-нибудь быстрый резкий пользователь натаскал десять товаров, и потом видит, как у него цена мигает и, условно говоря, 100 рублей, 10 рублей, 50 рублей, 75 рублей, и останавливается на одном рубле. Он вам не верит, он думает, что вы плохо пишете, хотите его обмануть, и уходит из вашего магазина, ничего не покупая.
Пример. Если у вас есть какой-нибудь скрам или канбан или что-нибудь еще и вы пользуетесь электронными досками для перетаскивания карточек, вы, наверное, хоть раз при перетаскивании карточки промахивались, дропали ее не в ту колонку. Бывало такое? Конечно, вы спохватываетесь и сразу резко ее хватаете и тащите туда, куда положено. При этом вы очень быстро генерируете два запроса. И в разных системах бывают баги, возникающие как раз после этого. Вы перетащили ее в правильную колонку — приходит ответ на первый запрос, и карточка опять прыгает в ту колонку, куда вы ее перебросили. Очень некрасиво получается.

В чем мораль? Предположим, у вас есть источник однотипных запросов. Тогда вы по возможности, если поступает следующий запрос, прерываете все незавершившиеся запросы, чтобы не тратить зря ресурсы, чтобы бэкенд знал — вам это уже не нужно.
Тем самым при обработке ответов вы тоже всё контролируете. И если приходит ответ на более ранний запрос, который вам не нужен, вы тоже его явно игнорируйте.

Соответственно, задача существует уже давно, и решение тоже уже есть. Например, в библиотеке RxJS. Это прямо пример из документации, прямо Hello world, как написать правильный autocomplete. Там прямо из коробки есть такое игнорирование ответов на более старые неправильные запросы.

Если вы пишете на Redux и Redux-Saga, там это тоже есть, в общем-то, и тоже в документации все записано. Но там это глубоко закопано, и явно про это не говорится, что это такой баг и мы его вот так фиксим. Просто описание такое есть.
Раз уж мы перешли к React, подвинемся к нему еще поближе.

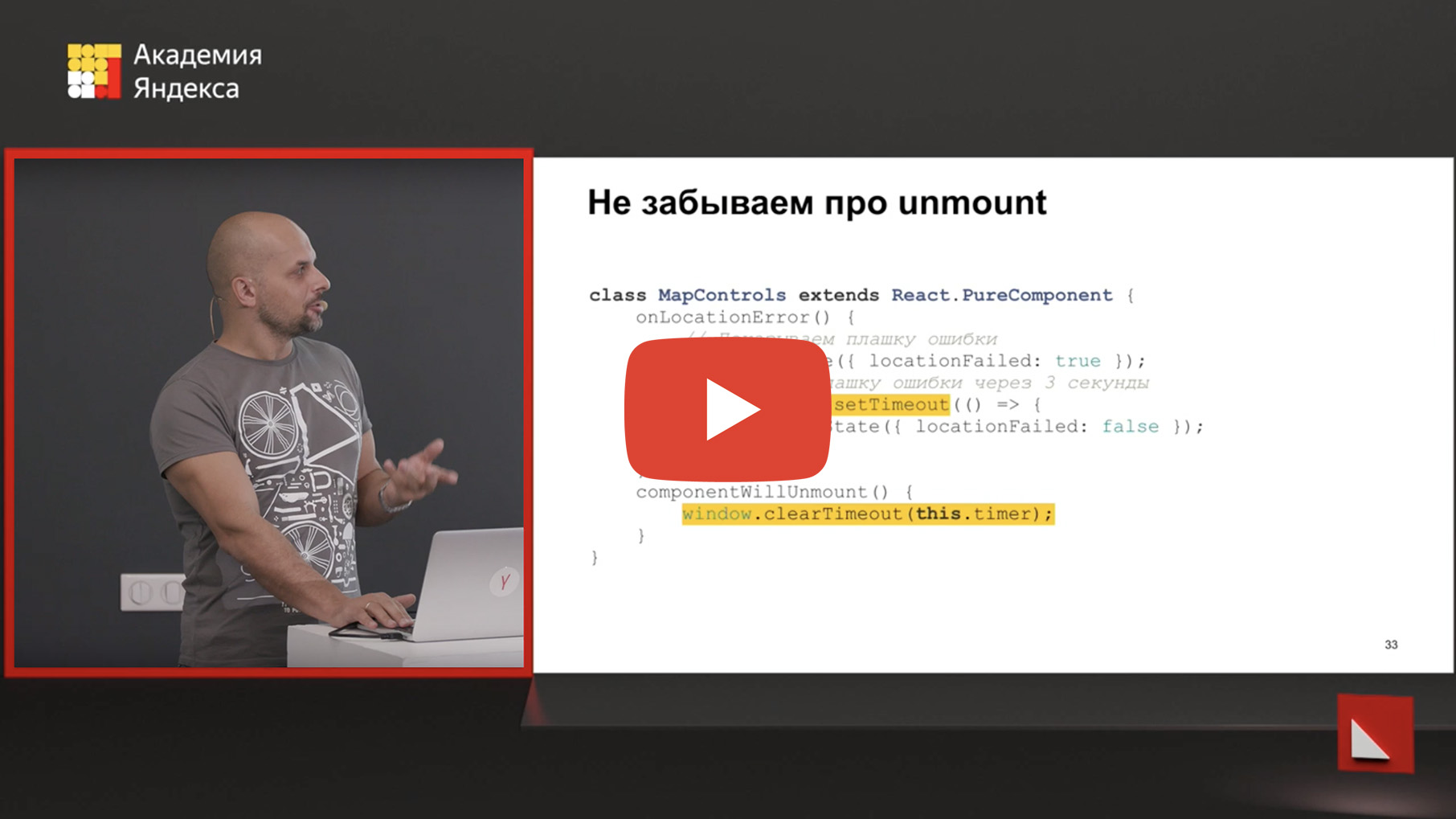
Это кусочек реального кода, который у нас был в нашем репозитории. Кто-то рисует у нас карты. И, пожалуйста, когда у вас получается карта, очень желательно, чтобы на ней показать отметочку, где находится пользователь. Но это все в браузере происходит. То есть, если у вас разрешена геолокация, то мы можем получить ваши координаты, и можем на карте прямо отметить, где вы находитесь.
Если геолокация не разрешена, или там какая-то ошибка произошла, то нам желательно показать какую-то плашечку с ошибкой. То есть вот мы показываем плашечку, что не смогли показать, где ты находишься, чувак, и через три секунды ее убираем, эту плашечку. Ты успел прочитать, наверное. Тем более, движущийся объект, как выдвигающаяся плашка и исчезающая, она привлекает сразу внимание, и вы ее сразу заметите, прочитаете.
Но если внимательно посмотреть, что происходит в этом коде, то мы меняем state нашего компонента через три секунды во времени. За эти три секунды может произойти все что угодно. В том числе пользователь может эту карту давно уже закрыть, и ваш компонент размонтируется, почистит свое состояние.

Соответственно, вы стреляете себе в ногу, причем стреляете по баллистической траектории, которая закончится через три секунды. И что же надо делать? Не забывайте, что если вы делаете такие отложенные операции, то можно их почистить корректно при unmount. И в других фреймворках с другими методами life cycle то же самое логично. Когда у вас происходит какой-то destruct, destroy, еще что-нибудь, unmount, надо корректно такие вещи не забывать чистить за собой.

Откуда вообще в браузере может так отложенно вызываться ваш код? Есть такие вещи, как throttle и debounce. У них под капотом лежат setTimeout, setInterval, то, про что я уже показывал. Еще есть requestAnimationFrame, еще есть requestIdleCallback. И AJAX-запросы тоже — callback AJAX-запроса может вызываться отложенно. Не забываем про них тоже, их тоже надо чистить.
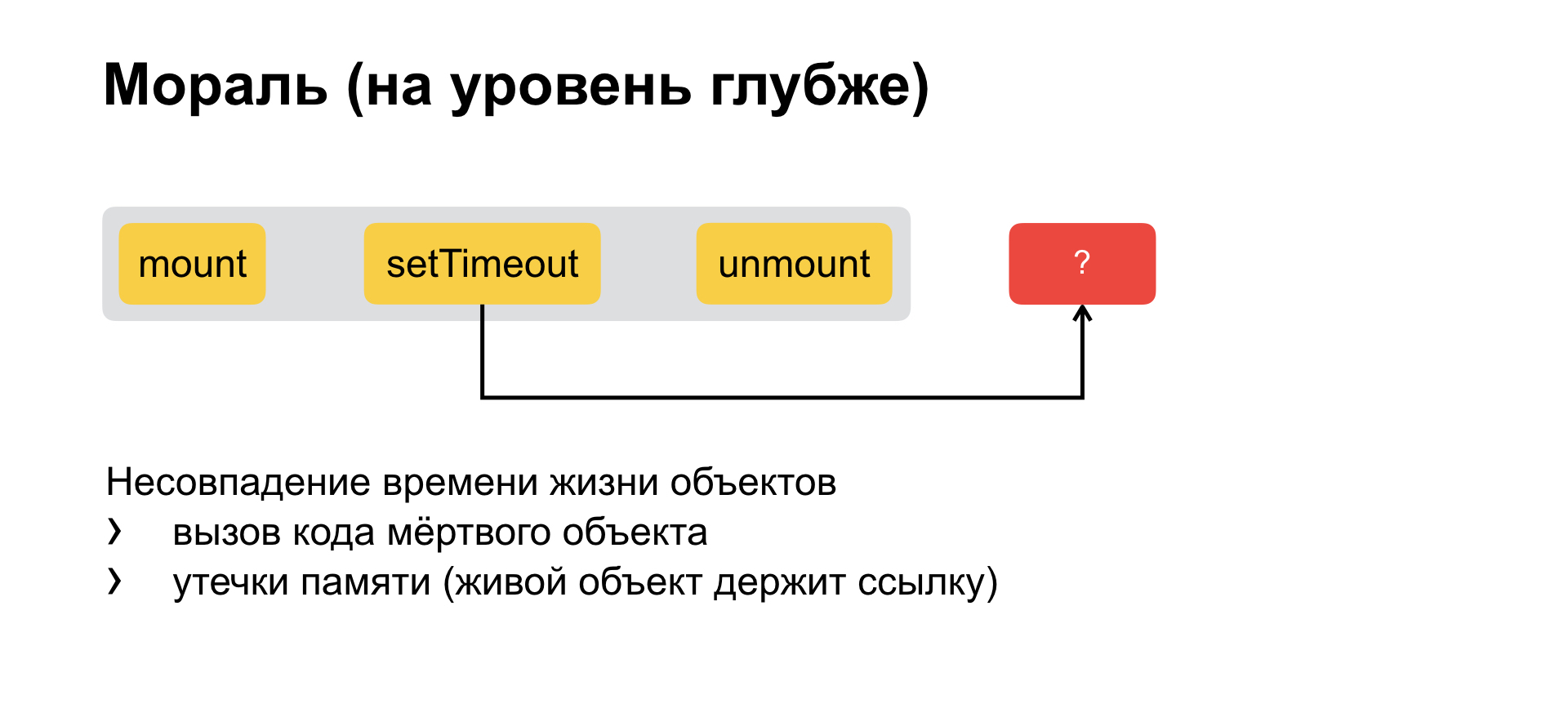
И если мы погрузимся еще на уровень дальше, то поймем, что исходно вся проблема абстрагируется до такой, что у нас есть какой-то компонент с каким-то life cycle и мы откладываем вызов. Мы создаем внутри долгоживущий объект, у которого срок жизни получается больше, чем у исходного. То есть, есть два объекта с несовпадающим life cycle, с несовпадающим сроком жизни. И из этого проистекают сразу два бага.
Первый — это как у нас сейчас: долгоживущий объект держит ссылку на вашу функцию и вызывает ее, хотя вы уже умерли. И второй — это утечка сопутствующей памяти. То есть, опять же, долгоживущий объект держит ссылку на ваш код и не дает ему почиститься, собраться из памяти.
Третья часть противоположна второй. Она, наоборот, про синхронность.

Есть, как обычно, цепочка promise — then, then, then что-то там. И в этом коде, если посмотреть, если вы пишете чисто, если вы сторонник, или слышали, хотя бы, про функциональный подход, про чистые функции, про отсутствие side-эффектов, то вы можете понять, что в этом коде можно кое-что ускорить.
Потому что вот эти два запроса асинхронных, они явно друг от друга не зависят. Если вы в этом не уверены, значит, вы что-то пишете не так, то есть, там у вас есть явно какие-то side-эффекты, глобальный state, и прочее. Если вы пишете хорошо, то это сразу вам становится очевидным. Вот, кстати, явный профит от чистоты функции, от отсутствия side-эффектов. Потому что сразу здесь, при чтении этого кода, вы понимаете, что их можно распараллелить. Они не зависят друг от друга. И, вообще, их можно поменять даже местами, скорее всего.

Это делается примерно вот так. Мы в параллель запускаем два запроса, ждем их окончания, и дальше выполняем следующий код. То есть профит в чем? В том, что, во-первых, у нас код выполняется быстрее, мы не ждем одного запроса, чтобы начать второй. И мы быстрее упадем. Если у нас ошибка во втором запросе, то мы не будем впустую ждать выполнения первого запроса, чтобы сразу же упасть на втором.

Для полноты информации — что у нас в Promise API ещё есть? Вот Promise.all(), который запускает все запросы в параллель, и ждет выполнения. Есть Promise.race(), который ждет выполнения первого из них, который успел. И, в общем-то, в стандартном API больше ничего нет.

Мы уже понимаем, что раз проблема есть, то кто-то ее уже за нас и до нас решил. Есть библиотека Async, в которой есть довольно богатый выбор для управления асинхронными задачами. Есть методы для запуска асинхронных задач в параллель. Есть методы для запуска последовательно друг за другом. Есть методы для организации асинхронных итераторов. То есть вы знаете, что у вас есть, допустим, массив, на котором можно запустить forEach(). Но если у вас в forEach() надо вызывать асинхронную функцию, то у вас сразу или проблема, и вы отказываетесь от forEach() и пишете что-то сами, или используете готовую библиотеку, которая именно готова к использованию таки асинхронных вещей. Вы понимаете, вызвать map() с асинхронным каким-то итератором, вызвать forEach() — там это уже есть в коробке.

Другая альтернатива — библиотека bluebird. Там есть, как они называют, правильный Promise.any(). То есть, предположим, у вас есть такая задача: вам нужно пропинговать N сайтов, N каких-то урлов, и кто из них первый откликнулся, того использовать. Например, он к вам ближе, для него пинги короче. А остальные могут вообще не ответить.
Если вы используете Promise.race(), то там, если promise режектится, то он, собственно, весь зарежектится. И вы его здесь не сможете использовать. А вот Promise.any() — он игнорирует reject. То есть как раз для такой задачи он подходит. Он все reject проигнорирует, а первый resolve успешный, он его вам вернет дальше, и не будет ждать остальных. Также там есть интересный метод для запуска асинхронных задач в параллель сразу с заданной степенью конкурентности. То есть вы хотите не более пяти параллельных promise — пожалуйста, записали одним параметром.
Для тех же асинхронных итераций и коллекций там есть вещи, которые позволяют сделать map, reduce, each, filter и прочее. То есть API сделано как на массиве, как в Async JS, но еще более мощно. Вы можете туда погрузить promise массива промизов. Он подождет, пока это все не развернется, и проитерируется с асинхронным итератором, который сам возвращает promise. Довольно сложно.
Но зачем нам promise? У нас уже будущее наступило, есть async/await.

Мы как будто отказываемся от этого всего. Мы пишем простой код. Вот пример кода. Это снова наш внутренний инструмент, называется «Гермиона». Предназначена для тестирования в браузере, основана на webdriver. Опять же, мы запускаем браузер, из нашего кода передаем в него какие-то команды, ожидаем их выполнения и получаем результат. Но в основе все выглядит очень похоже. То есть это надстройка над драйвером. В основе все очень похоже с webdriver.
И мы снова пишем на новом модном языке, используем await. То есть команды по определению асинхронны. Мы должны подождать, пока браузер нам что-то ответит. Но мы используем await, и у нас вроде бы все хорошо — кроме того, что мы умудрились с нашими новыми фичами написать медленнее, чем без них! Потому что у нас снова появляется точка ожидания.

И мы уже знаем правильный ответ — Promise.all(). Мы снова можем распараллелить то, что записано у нас в await.

Мораль: await написать проще, чем последовательность then с промизами. Но также проще внести незапланированную дополнительную синхронизацию, которую легко просмотреть и пропустить глазами.
И естественно, следите за вашим кодом. Простое правило: если у вас рядом стоят два await, которые вроде бы не зависят друг от друга, — наверное, можно их распараллелить и ускорить выполнение вашего кода.
Вот интересные ссылки, которые я собрал, ссылки на документацию:
- Описание Promise в Mozilla Developer Network.
- Библиотека Async на GitHub.
- Библиотека Bluebird.
- Библиотека RxJS 4, RxJS 5+.
- Monotonic Clocks in Windows and POSIX — документация по монотонным часам в разных операционных системах, в Windows и в POSIX-совместимых системах.
- Документация о том, как ntpd корректирует время, когда он выбирает, что и как ему делать с вашими часами.
И интересная подборка былинных отказов, эпик-фейлов, когда у людей в продакшене были настоящие грабли:
- Статья о том, как из-за коррекции времени NTP daemon у человека в продакшене упал кластер Hadoop.
- Проблема в Cloudflare DNS, возникшая всего лишь из-за одной секунды, из-за немонотонности времени.
- Еще во «ВКонтакте» интересный баг был. Кука авторизации записывалась со временем истечения на час. И у человека с неправильно выставленным часовым поясом и временем сразу же кука истекала, он не мог авторизоваться, его сразу выбрасывало.
Что я хочу сказать в итоге? Изучайте качественный код, в том числе опенсорс — Lodash, RxJS и т. п. Там много интересного написано, интересные проблемы решаются. Избегайте типичных ошибок, которые уже кому-то встретились и решены. Не изобретайте велосипед. А если будете его изобретать — по крайней мере, знайте, что колеса должны быть круглыми. У меня всё.
Комментарии (30)

D1verGW
11.08.2019 12:55Отличная статья, для некоторых вещей, реализованных в этих библиотеках, писались свои велосипеды.
Спасибо.
P.S. Вторая часть очень опосредованно относится к времени)

k12th
11.08.2019 13:04С неправильным временем у пользователя был занятный кейс. Мы делали некий продукт для небогатых, в основном, компаний, и он был сильно завязан на корректное время. Дело было в начале '10-ых, в России недавно переколбасили часовые пояса, а у всех была пиратская винда, которая не обновлялась и в ней не было новой tzdata. Приходилось брать время из ответов сервера, вводить поправку на сетевую задержку, вычислять смещение часового пояса и плясать с бубном, потому что в JS есть
getTimezoneOffset, но нетsetTimeZoneOffset...AndreasCag
13.08.2019 11:22брать время из ответов сервера, вводить поправку на сетевую задержку, вычислять смещение часового пояса и плясать с бубном
А как брали поправку на сетевую задержку?
sand14
11.08.2019 13:07Спасибо за статью!
Работа со временем — очень важная вещь.
Сам давно задумывался над этим и пытался выработать решения на распространенные кейсы, плюс на обработку краевых случаев.
Радует, что одни и те же мысли приходят одновременно разным людям.
Хочется, однако, риторически прокомментировать вот это :
Так линейно вы, в общем, и пишете код. Дата начала — сегодня минус одни сутки, дата окончания — сегодня. Казалось бы, все работает, но потом ровно в полночь у вас случается странное. У вас дата начала вот здесь. Дата начала минус одни сутки — получается, такая. После этого почему-то дата окончания отчета совершенно другая.
Вы, а точнее ваш начальник получаете отчет за двое суток вместо одних. Технический начальник и менеджер приходят, жалуются и вежливо предлагают вам через шесть месяцев перейти в другую команду.Абсолютно типовая ошибка, проистекающая из неаккуратности, нежелании разобраться в природе вещей (времени в данном случае), низкой культуры кодирования, незнания и нежелания разобраться в реализации стандартной библиотеки, и как она (реализация) маппится на ту самую природу вещей.
Но… Скажите, где вы находите компании, где за такое просят покинуть команду или лучше компанию?
Сколько помню, везде в энтерпрайзе попадался именно код такого характера, со временем, включая прямо вот описаную вами ошибку, другие типовые ошибки со временем и другими сущностями.
И что характерно, авторы такого кода были всегда в почете (такой код можно писать быстро, перформанс наше все! — почти ж никто в ИТ не в курсе, что нужно перформанс для разрабов нужно переводить вторым главным значением — "эффективность", а не первым "производительность", интерпретируемую как скорость закрытия тасков на гора, а дальше не волнует).
Другое дело, что, как правило, авторы такого кода были уже далече, только не их попросили, а они на гребне волны славы сами успели уйти на повышение — в другие компании, реже в той же компании.Sioln
11.08.2019 13:44Ведь нет совсем никакой гарантии, что взамен уже знающего, но ушедшего спеца придёт уже знающий.
Вполне вероятно, что попадается человек, ещё не совершивший подобную ошибку и не знающий о ней.

victor-homyakov
12.08.2019 17:55«Перейти через шесть месяцев в другую команду» — это шутка, намёк на доклад с той же конференции об управлении командами разработчиков в большой компании. Прошу не воспринимать серьёзно и не принимать как руководство к действию.

vintage
11.08.2019 13:12И в других фреймворках с другими методами life cycle то же самое логично. Когда у вас происходит какой-то destruct, destroy, еще что-нибудь, unmount, надо корректно такие вещи не забывать чистить за собой.
А ещё можно использвать фреймворки, которые чистят всё автоматически, а не полагаются, что разработчик ничего не забудет..
слышали, хотя бы, про функциональный подход, про чистые функции, про отсутствие side-эффектов
эти два запроса асинхронных, они явно друг от друга не зависятВы бы хоть определение чистой функции почитали..
Изучайте качественный код, в том числе опенсорс — Lodash, RxJS и т. п.
https://github.com/lodash/lodash/blob/master/.internal/createRound.js
https://github.com/ReactiveX/rxjs/blob/master/src/internal/util/ArgumentOutOfRangeError.ts
Очень "качественный" код..victor-homyakov
12.08.2019 17:56использвать фреймворки, которые чистят всё автоматически, а не полагаются, что разработчик ничего не забудет
Есть пример такого фреймворка? Если опишете, как там реализована очистка всего и защита от вызовов после разрушения компонентов — будет отличная статья.

funca
11.08.2019 15:43Часто забывают, что месяцы в Date считаются с 0 и до 11.
Ошибаются в инкрементах на неделю, месяц, год в последних днях месяца. 31-01-2019 + 1 месяц = 31-02-2019 = 03-03-2019. Иногда забывают про високосные годы.
Ошибки инкремента даты делают при переходах между зимним и летним временем. Мы же помним, что время подвластно политикам и правила могут меняться год от года.
Отдельная тема — часовые пояса. Какой сейчас день? А где именно? Вот уж действительно начинаешь понимать, что живёшь в пространственно-временном континууме. Чтобы определить «когда» нужно знать «во сколько» и «где». Хранить информацию о времени в unix timestamp может быть не лучшей идеей. Нужно сто раз взвесить, прежде чем решать приводить все к UTC.
На самом деле, не имея информации о часовом поясе и актуальной версии tzdata вы мало, что можете правильно посчитать. Рассчет на сервере и на клиенте может давать разные результаты. После очередного апдейта tzdata результаты могут сильно измениться.
Так же хлопот доставляют форматы записи дат в разных локалях. 10/11/12 без контекста не распарить.

TimonKK
12.08.2019 02:33Про даты я бы добавил про таймзону. Особенно весело когда на фрон приходит дата в timestamp и может показать каку, если таймзона на беке оказалась не та
mmMike
12.08.2019 08:43Странно что не упомянуты еще типичные грабли:
Запрос в БД с указанием ТОЛЬКО дат диапазона, когда в поле в БД включает еще и время. Типично от получается в запросе поле времени по умолчанию 00:00:00 до 00:00:00, а нужно, как правило, от 00:00:00 до 23:59:59. Очень типичная ошибка.
Запрос из браузера выборки по диапазону времени. А времени чего? От TZ браузера? От TZ БД? От Гринвича/MSK? А вообще чего нужно то? Полночь в России наступает в разное время.
Кстати, типично, что в большинстве протоколов "нарисованных" разработчиками из Москвы отсутствует таймзона как сущность воооообще.
А на вопрос "а в какой TZ время то указывать?" вызывает ступор. Как будто другой TZ кроме MSK не бывает и не важно где (TZ) по факту событие произошло. Особенно не важно это для фродмониторинга <сарказм>
Особенно весело, когда встает вопрос про отчеты для банка у которого филиалы и в Москве и Владивостоке и слияние недавно произошло. Вопрос не технический. Организационный.
И по моему мнению, больше всего проблем с TZ возникает.
Например в таком простом вопросе "Хочу видеть транзакции за вчера. Филиалы у нас в Барнауле, Москве и Владивостоке, а терминалы по всей России".
А вам слабо объяснить сотруднику в Барнауле, почему список транзакций за день у него и сотрудника в Москве разный при одном подходе (список исходя из TZ браузера оператора).
Или почему он не видит транзакцию сделанную сегодня ночью (вот же она на чеке) в списке транзакций за сутки при другом подходе (список, исходя из TZ головного филиала в Москве).
И начинается… ваш софт г-но и выдает ерунду. "Хотим кнопку счастья для любого тупого сотрудника."
Иногда кажется что у многих абстрактное мышление отсутствует как класс..
victor-homyakov
12.08.2019 18:11поле времени… нужно, как правило, от 00:00:00 до 23:59:59
Кстати, здесь может быть ещё одна ошибка, если время хранится не округлённым до секунды.
Например, если время хранится с точностью до миллисекунды, то надо задавать диапазон времени от 00:00:00 до 23:59:59.999
Как вариант, чтобы меньше вспоминать о точности хранения времени, можно задавать конечную дату в запросе как "меньше 00:00:00 следующего дня", а не "меньше или равно 23:59:59.999 текущего дня".
TimonKK
13.08.2019 11:33Эволюционно пришли к тому же выводу, иначе от базы к базе нужно каждый раз помнить как там дата и время храниться. Проще делать в WHERE условие datetime < '2019-08-13 00:00:00' чем выяснять про секунды и миллисекунды
zolt85
12.08.2019 10:37Мне тут приходилось объяснять заказчику почему задача сохранения времени пользователя на сервере и построение отчетности в сервисе, расчитаным на весь мир, может занять много времени. А потом ещё разработчикам объяснять, почему мы будем хранить время в UTC, со сдвигом пользователя от UTC. Все (и заказчик, и разработчики) были в смятении, и смотрели на меня как на сказочника. Покажу им эту статью. Это я еще про летнее/зимнее время забыл, блин… Спасибо, что напомнили.

F0iL
12.08.2019 11:31Рекомендую еще по теме.
tuxi
12.08.2019 18:56Не то, чтобы я зануда, но зачем упомянута Java в тегах и списке хабов?
Если уж упомянули ее, было бы неплохо кратко хотя бы пробежаться по особенностям и фичам при работе с временем/календарем. Уж до 8й версии там было о чем рассказать, это точно. А это до сих пор больше половины всех проектов. А может и больше.
rrust
12.08.2019 19:47Микрософт не парится и в своих логах пишет локальное время, которая скачет при синхронизации с NTP и изменении таймзоны.
Можно было бы конечно реализовать временные отметки не в абсолютном времени, а в относительно, типа сколько времени прошло от старта большого процесса.
Но часто удобнее просто поискать по локальному времени, чем искать начало и считать смещение.
tossed
13.08.2019 09:50Есть ещё такая экзотическая штука как "высокосная секунда". Встречается нечасто и мало кому мешает. Но мне как-то изрядно выпила крови при синхронизации времени двух телецентров.
Tantrido
Спасибо! А на C++/Qt что-то такое со временем есть — тоже приходилось костыли писать для монотонного непрерывного времени.
Dim0v
Конечно есть.
Если проект с C++11, то в
chronoестьstd::chrono::steady_clock. Если на более старом стандарте, то нужно использовать системные вызовы целевой ОС (вродеclock_gettimeсCLOCK_MONOTONICна *nix илиQueryPerformanceCounterна винде).К слову, все это легко находится в гугле по запросу "monotonic time c++/c++03/windows/unix".
Tantrido
Здорово, спасибо, мы писали ещё в 2010-2011, тогда этого стандарта ещё не было.
mapron
А boost::chrono уже был)
Tantrido
Возможно, а может не хотели лишнюю библиотеку в инсталлятор тащить.