

Изображение: Pexels
Для сайтов-агрегаторов в сфере электронной коммерции крайне важно поддерживать актуальную информацию. В противном случае исчезает главное их преимущество – возможность видеть самые релевантные данные в одном месте.
Для того, чтобы решить эту задачу необходимо использовать технику веб-скрейпинга. Ее смысл в том, что создается специальный софт – краулер, который обходит нужные сайты из списка, парсит информацию с них и загружает ее на сайт-агрегатор.
Проблема в том, что зачастую владельцы сайтов, с которых берут данные агрегаторы, вовсе не хотят так легко предоставлять им доступ. Это можно понять – если информация о цене в интернет-магазине попадет на сайт агрегатор и окажется выше, чем у конкурентов, представленных там же – бизнес потеряет покупателей.
Методы противодействия скрейпингу
Поэтому часто владельцы таких сайтов противодействуют скрейпингу – то есть скачиванию своих данных. Они могут выявлять запросы, которые отправляют боты-краулеры по IP-адресу. Обычно такой софт использует так называемые серверные IP, которые легко вычислить и заблокировать.
Кроме того, вместо блокировки запросов часто используется и другой метод – выявленным ботам показывают нерелевантную информацию. Например, завышают или занижают цены на товары или изменяют их описания.
Пример, который часто приводят в этой связи – цены на авиабилеты. Действительно, довольно часто авиакомпании и турагентства могут показывать разные результаты для одних и тех же перелетов в зависимости от IP-адреса. Реальный случай: поиск авиаперелета из Майами в Лондон на одну и ту же дату с IP-адреса в Восточной Европе и Азии возвращает разные результаты.
В случае IP-адреса в Восточной Европе цена выглядит так:

А для IP-адреса из Азии так:
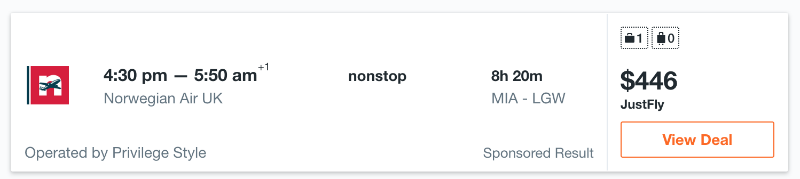
Как видно, цена на один и тот же перелет значительно отличается – разница составляет $76, что действительно много. Для сайта-агрегатора нет ничего хуже этого – если на нем будет представлена неверная информация, то пользователи не будут им пользоваться. Кроме того, если на агрегаторе у конкретного товара одна цена, а при переходе на сайт продавца она меняется – это также негативно влияет на репутацию проекта.
Решение: использование резидентных прокси
Избежать проблем при скрейпинге данных для нужд их агрегации можно с помощью использования резидентных прокси. Cерверные IP предоставляются хостинг-провайдерами. Выявить принадлежность адреса к пулу конкретного провайдера довольно просто – у каждого IP есть ASN-номер, в котором содержится эта информация.
Есть множество сервисов для анализа ASN-номеров. Часто они интегрируются с антибот-системами, которые блокируют доступ краулерам или подтасовывают отдаваемые в ответ на их запросы данные.
Обойти такие системы помогают резидентные IP-адреса. Такие IP интернет-провайдеры выдают владельцам жилья, с соответствующими пометками во всех связанных базах данных. Существуют специальные сервисы резидентных прокси, которвые позволяют пользоваться резидентными адресами. Infatica – как раз такой сервис.
Запросы, которые краулеры сайтов-агрегаторов отправляют с резидентных IP, выглядят так, будто бы они идут от обычных пользователей из определенного региона. А обычных посетителей никто не блокирует – в случае интернет-магазинов это потенциальные клиенты.
В итоге использование ротируемых прокси от Infatica позволяет сайтам-агрегаторам получать гарантированно точные данные и избегать блокировок и трудностей с парсингом.
Другие статьи по теме использования резидентных прокси для бизнеса:
Комментарии (3)

ghost404
20.08.2019 21:10А есть методики идентификации краулеров и ботов?
Ну то есть понятно, что запросы без User-Agent или с корявым User-Agent фальшивка. Запросы без кук вероятно фальшывые. Большое количество запросов с одного IP. Частые запросы с одного IP. Запросы с одного IP с одинаковым интервалом. Запросы из публичного списка прокси. Запросы из Tor exit nodes.
Какие ещё есть методы?

dady_KK
21.08.2019 00:20+1Переход на вторую страницу сайта без реферера, большое количество запросов за определенный промежуток времени (типа 50 запросов за 6 часов, т.е. уход от блокировки по частоте), специфические заголовки (язык, кодировка, сжатие) точнее их наличие и валидность и разница между нормальными браузерами и текущим.
Anselm_nn
Самого главного не указали, какой допустимый объем «естественного» трафика, то есть сайт знает, что обычно покупатель проходит по 5 страницам, а иногда по 20. Но 1000 страниц не проходит никогда, то есть есть количественные метрики. Получается, что для хорошей маскировки таких IP нужно много.
И еще момент, некоторые билетные сайты любят завышать цену при большом количестве просмотров с одного IP, это тоже может влиять